强势斩获6项SOTA!UniCorn打通理解与生成任督二脉,靠“内省”重构多模态认知

强势斩获6项SOTA!UniCorn打通理解与生成任督二脉,靠“内省”重构多模态认知

AI生成未来
发布于 2026-01-13 16:27:33
发布于 2026-01-13 16:27:33
作者:Ruiyan Han等
解读:AI生成未来

论文链接:https://arxiv.org/abs/2601.03193 代码链接:https://github.com/Hungryyan1/UniCorn 模型链接:https://huggingface.co/CostaliyA/UniCorn 基准链接:https://github.com/shierlouz/Unicycle 主页链接:https://costaliya.github.io/UniCorn.github.io/

亮点直击
- 传导性失语症:将统一多模态模型中“理解能力强但生成能力弱”的现象形式化为“传导性失语症”。
- UniCorn 框架:一种无需外部数据或教师监督的自我提升框架。该框架将单个模型划分为提议者(Proposer)、求解者(Solver)和裁判(Judge)三个角色,通过自我博弈实现能力提升。
- 全面的 SOTA 性能,UniCorn 始终优于先前同类方法。在 TIIF (73.8)、DPG (86.8)、CompBench (88.5) 和 UniCycle (46.5) 上均取得了 SOTA。 UniCycle 基准:引入了基于 文本图像文本 循环一致性的新基准,用于验证多模态一致性的恢复情况。
解决的问题
- 理解与生成的不匹配:现有的统一多模态模型(UMMs)在跨模态理解方面表现出色,但难以利用这种内部知识进行高质量的生成(即“传导性失语症”)。
- 对外部监督的依赖:传统的提升方法往往依赖于昂贵的外部标注数据或强大的教师模型进行蒸馏,限制了模型的可扩展性和自主进化能力。
提出的方案
- 自我多智能体采样(Self Multi-Agent Sampling):利用 UMM 的上下文学习能力,让模型分饰三角:
- Proposer:生成具有挑战性的提示(Prompts)。
- Solver:根据提示生成图像。
- Judge:评估生成质量并提供反馈。
- 认知模式重构:将自我博弈中的交互轨迹转化为训练数据:
- Caption:将生成的图像映射回文本,稳固语义接地。
- Judgement:学习预测评分,校准内部价值体系。
- Reflection:学习从“失败”样本到“成功”样本的转换,内化自我修正机制。
应用的技术
- 多角色自我博弈(Multi-role Self-play):在同一参数空间内实现不同角色的协作。
- 拒绝采样(Rejection Sampling):利用内部 Judge 的评分筛选高质量数据。
- 思维链(Chain-of-Thought)与反思(Reflexion):在生成和评估过程中引入推理步骤,并通过对比正负样本构建反思轨迹。
- 循环一致性评估:通过 T2I2T(文本-图像-文本)循环来量化信息保持度。
达到的效果
- SOTA 性能:UniCorn 在 TIIF (73.8)、DPG (86.8)、CompBench (88.5) 和 UniCycle (46.5) 等六个通用图像生成基准上取得了最先进(SOTA)的性能。
- 显著提升:相比基础模型,在 WISE 上提升了 +5.0,在 OneIG 上提升了 +6.5。
- 数据高效性:仅需 5k 自生成数据即可超越使用 30k GPT-4o 蒸馏数据训练的模型(IRG),证明了全自监督改进的可扩展性。

图 2:UniCorn 可视化结果
图 2:UniCorn 可视化结果
方法
先分析 UMM 中生成与理解能力的不匹配来阐述动机。基于这些观察,提出了 UniCorn,这是一个简单而优雅的后训练框架,无需任何外部标注数据或教师模型即可实现自我提升。
动机
这就好比一个将“苹果”这个词与水果联系起来的孩子,看到苹果时能自发地说出它的名字一样,认知对称性使得内部概念与外部表达之间能够双向映射。这种对齐类似于逃离柏拉图的洞穴:真正的智能必须超越对表面数据的观察,掌握表象与其潜在源头之间的互惠关系。

图 1:UniCorn 的动机。 UMM 经常表现出理解代沟:它们可以准确地理解和批评图像中的错误,但无法正确生成相同的场景。 这种传导性失语促使我们的框架利用模型卓越的内部理解,通过独立的反馈来加强和完善其生成能力
图 1:UniCorn 的动机。 UMM 经常表现出理解代沟:它们可以准确地理解和批评图像中的错误,但无法正确生成相同的场景。 这种传导性失语促使我们的框架利用模型卓越的内部理解,通过独立的反馈来加强和完善其生成能力
然而,当前的 UMM 遭受着类似于传导性失语症(Conduction Aphasia) 的功能缺陷:虽然模型表现出深刻的理解能力,但其生成表现仍然是分裂的,无法生成它本质上能够理解的内容。弥合这一差距至关重要;如果不协调这两个过程,模型仍然是一个“被动的观察者”,能够将被动符号接地(grounding)但无法利用它们。因此,掌握理解与生成之间的协同作用不仅是功能升级,也是实现 AGI 所需的认知完整性的关键步骤。
一方面,如图 3 所示,当前的 UMM 表现出强大的感知和理解能力。具体而言,当作为文本到图像(T2I)生成的奖励模型时,UMM 展现出对跨模态语义的复杂掌握。这表明模型已经内化了一个强大的“世界模型”,并拥有辨别高质量视觉-文本对齐所需的潜在知识。

图 3:BAGEL和 GPT-4o在四个理解基准上的结果。 对于 Omini-RewardBench和 MMRB2,评估了 T2I 任务。 使用 GPT4结果对性能进行标准化,以获得更好的可视化效果
图 3:BAGEL和 GPT-4o在四个理解基准上的结果。 对于 Omini-RewardBench和 MMRB2,评估了 T2I 任务。 使用 GPT4结果对性能进行标准化,以获得更好的可视化效果
另一方面,模型的生成能力仍然受到显著限制,主要是因为它未能弥合内部识别与主动合成之间的差距。这种功能性分离意味着 UMM 自身复杂的理解能力在生成过程中仍然是一个“沉默的乘客”,无法告知或纠正其输出。基于这一观察,本文的关键见解是:UMM 强大的理解能力可以被重新利用为一种自主监督信号,以指导其生成行为。通过将潜在的解释深度转化为显式指导,本文促进了这两个过程之间更紧密的耦合,最终恢复了真正集成的多模态智能所必需的认知对称性。
问题定义
本文研究处理交错图像-文本输入和输出的 UMM。UMM 被公式化为一个策略 ,它将多模态输入序列 映射到交错的多模态输出序列 。这种统一的输入-输出公式支持图像到文本(I2T)理解和文本到图像(T2I)生成。本文将理解操作化为 I2T,将生成操作化为 T2I,并利用模型较强的 I2T 理解能力来监督和改进其较弱的 T2I 生成能力。
UniCorn

图 4:UniCorn 框架概述。 (a) 说明了高质量数据采样的自我多主体协作。 (b) 详细介绍了认知模式重建过程,该过程重新组织数据以促进稳健和高效的学习。 (c) 提出 UniCycle 基准评估,验证模型是否能够从其自身生成的内容中准确地重建关键文本信息。
图 4:UniCorn 框架概述。 (a) 说明了高质量数据采样的自我多主体协作。 (b) 详细介绍了认知模式重建过程,该过程重新组织数据以促进稳健和高效的学习。 (c) 提出 UniCycle 基准评估,验证模型是否能够从其自身生成的内容中准确地重建关键文本信息。
UniCorn 通过两个核心阶段运作:自我多智能体采样(Self Multi-Agent Sampling)和认知模式重构(Cognitive Pattern Reconstruction, CPR)。首先,UMM 同时担任三个角色:提议者(Proposer)、求解者(Solver)和裁判(Judge),以模拟协作循环。然后,CPR 阶段将这些原始交互重构为三种训练模式:描述(caption)、判断(judgement)和反思(reflection),这些模式与高质量的自我采样 T2I 生成数据相结合用于后训练。关键是,整个过程是完全独立的,不需要外部教师模型或人工标注数据。
第一阶段:自我多智能体采样 (Stage 1: Self Multi-Agent Sampling)
LLM 天然适合多任务设置中的自我博弈。对于 UMM,交错的多模态输入和功能多样性使得提示(prompting)、生成和判断可以在共享模型中共存,从而在不同提示下实现条件化的角色行为。本文利用这一属性将单个 UMM 功能化为协作角色,通过内部协同弥合理解与生成之间的差距。
提议者 (Proposer) :提议者旨在为统一多模态模型生成一组多样化且具有挑战性的提示,随后用于生成训练图像。为此,受 LAION-5B 和 COYO-700M 的启发,本文将所有 T2I 任务提示分为十个类别,并为每个类别设计了细粒度的生成规则。接下来,本文提示 UMM 生成初始批次的提示,并充当裁判以选择最佳候选者用于后续迭代。利用 LLM 强大的上下文学习(ICL)能力,初始示例作为少样本演示(few-shot demonstration)来指导后续提示的生成。为了进一步增强多样性,本文引入了一种动态种子机制。在生成预定数量的提示后,从提示库中采样几个示例进行评估,然后用于构建新的演示以指导下一轮提示生成。与之前直接依赖训练集或使用外部模型构建提示的方法相比,本文的方法不需要外部数据,并且生成更多样化的提示,从而提高了泛化能力。
求解者 (Solver) :求解者负责根据提议者提出的提示生成多样化的输出。因此,本文鼓励 UMM 在随机种子和不同超参数下生成图像。遵循 DeepSeek-R1 的做法,本文对每个提示执行 8 次推演(rollouts),以在样本质量、多样性和计算效率之间取得有利的权衡。
裁判 (Judge) :裁判负责对求解者根据提议者的提示生成的图像进行打分,这些分数随后用于训练期间的拒绝采样。
以前的工作依赖于基于关键词的启发式奖励函数或强大的外部模型来提供密集的奖励图。这种奖励裁判在很大程度上取决于参数调整和外部模型的性能,而外部模型的性能因任务而异,严重限制了自我提升的泛化能力。如图 3 所示,UMM 表现出强大的奖励建模能力。因此,本文遵循广泛采用的“LLM 作为裁判”范式,使用 0 到 10 的离散分数制定所有 T2I 任务的奖励评估。为了进一步提高判断质量,本文将生成奖励模型(Generation Reward Models)——其在 LLM 中已显示出巨大潜力——迁移到 T2I 评估中。具体而言,本文为每个类别设计了特定于任务的评分标准,并鼓励模型在生成最终分数之前明确阐述其推理过程。
第二阶段:认知模式重构 (Stage 2: Cognitive Pattern Reconstruction)
通过使用提议者-求解者-裁判流程的自我多智能体拒绝采样,本文获得了一批高质量的提示-图像对。虽然这些配对反映了从抽象概念空间到高维视觉流形的映射,但直接优化这种跨域对齐仍然是随机且低效的,通常导致模式崩溃。为了超越这种“黑盒”优化,本文从元认知理论中汲取灵感,该理论将监控、评估和调节确定为稳健学习的支柱。基于这一见解,本文提出了一种三方数据架构,回收并结构化自我博弈循环中被忽视的轨迹。通过将这些潜在交互回放为显式的描述(Caption)、判断(Judgement)和反思(Reflection)模式,本文分别将抽象概念接地于视觉特征,提供评估信号,并编码自我纠正过程。这种设计将之前丢弃的内部“内心独白”转化为结构化的监督信号,在没有外部干预的情况下促进认知对称性。
描述 (CAPTION) :为了建立稳健的语义接地,此模式通过优化逆映射 确保模型内化其自身创作的概念本质。通过将得分最高的图像 作为输入,并将其原始提示 作为基本真值(ground truth),模型学会将抽象概念锚定在其能够合成的特定视觉流形内,从而加强内部概念与外部表现之间的双向认知对称性。
判断 (JUDGEMENT) :此模式侧重于评估校准,以完善模型的内部价值体系。本文训练模型预测任何生成对的评估信号 ,公式化为 。通过利用裁判提供的特定任务评分标准和推理轨迹,模型对当前输出与理想目标之间的潜在差距产生了敏锐的感知,为稳定生成过程提供了关键的诊断信号。
反思 (REFLECTION) :受 Reflexion 启发,此模式引入迭代调节以增强模型的自我进化能力。利用求解者的多次推演 ,本文利用裁判分配的奖励来识别质量对比鲜明的配对,特别是从同一提示中选择高奖励的“获胜”图像 和低奖励的“失败”图像 。然后,本文构建反思轨迹,公式化为 ,显式编码从次优状态到更优状态的转换。通过学习将低质量的表现 转化为优化后的对应物 ,模型内化了一种自我纠正生成错误的机制,在不需要外部监督的情况下有效地缓解了模式崩溃。
这三种数据类型与高质量的自我采样 T2I 生成数据相结合,用于微调 UMM。请注意,整个重构过程是基于规则的,不会引入任何复杂性。
UniCycle
为了评估内部协作是否产生真正的多模态智能而不仅仅是特定任务的性能提升,本文引入了 UniCycle,这是一个循环一致性基准,用于测量在 文本 图像 文本 循环下的信息保存情况。给定一条指令,UniCycle 评估统一多模态模型是否可以通过随后的视觉理解从其自身生成的图像中恢复指令的关键语义。
基于 TIIF,本文生成 QA 对以探索基于生成图像的指令隐含属性,将原始 TIIF 基准从 T2I 设置扩展到文本到图像到文本(T2I2T)设置。标注后,本文获得了 1,401 个 TIIF 风格的实例,涵盖十多个任务类别,并跨越多种问题格式,包括多项选择题、二元(是/否)问题和开放式问题。
为了进行评估,给定提示 ,模型首先生成图像,然后以生成的图像为条件独立回答每个问题 。外部裁判模型评估每个预测答案 是否与初始提示 和参考答案 一致,并为每个问题产生一个分数。
本文定义了一个统一的指标来量化这种 T2I2T 一致性。令 表示与提示 相关的问题集。本文定义:
其中 表示问题 的裁判分数,对于非文本问题定义为二元指标,对于文本类型问题定义为正确恢复关键词的比例,以实现更细粒度和连续的度量。
最终的 Soft 和 Hard 分数是通过对所有提示取平均值获得的。
实验
实验设置:
- 基础模型:主要使用 BAGEL 模型进行实验,同时也在 Janus-Pro 上验证了方法的通用性。
- 基准测试:涵盖 TIIF, WISE, OneIG-EN, CompBench, DPG, Geneval 等六个图像生成基准,以及 MME, MMB 等理解基准。
- 对比模型:包括 SD3 Medium, FLUX.1 dev 等生成专用模型,以及 Janus-Pro, Show-o2, T2I-R1 等统一多模态模型。


图 5:UniCorn、BAGEL 和 UniCorn 不同数据设置之间的定性比较。 我们的方法共同平衡了视觉美学、即时保真度和生成的真实性。
图 5:UniCorn、BAGEL 和 UniCorn 不同数据设置之间的定性比较。 我们的方法共同平衡了视觉美学、即时保真度和生成的真实性。
主要结果:
- 综合性能提升:UniCorn 在多个基准上超越了基础模型 BAGEL 和其他强劲对手。例如,在 TIIF 上达到 74.7(+3.7 vs BAGEL),在 DPG 上达到 86.8(超越 GPT-4o 的 86.2)。
- UniCycle 表现:在本文提出的 UniCycle 基准中,UniCorn 取得了最高的 Hard score (46.5),远超基础模型(36.6)和其他模型,证明了其在统一多模态智能方面的优势。
- 消融实验:
- 数据模式:移除认知模式重构(C, J, R)仅保留生成数据会导致严重的模式崩溃(MME-P 分数暴跌)。加入这些模式能稳定生成并提升质量。
- 架构通用性:在 Janus-Pro 上应用 UniCorn 方法同样带来了显著提升(TIIF +3.2, WISE +7.0)。
- 扩展定律 (Scaling Law) :随着自生成数据量从 1k 增加到 20k,模型性能持续提升。仅需 5k 数据,UniCorn 在 TIIF 上的表现就超越了使用 30k GPT-4o 蒸馏数据训练的 IRG 模型以及 DALL·E 3,展示了极高的数据效率。

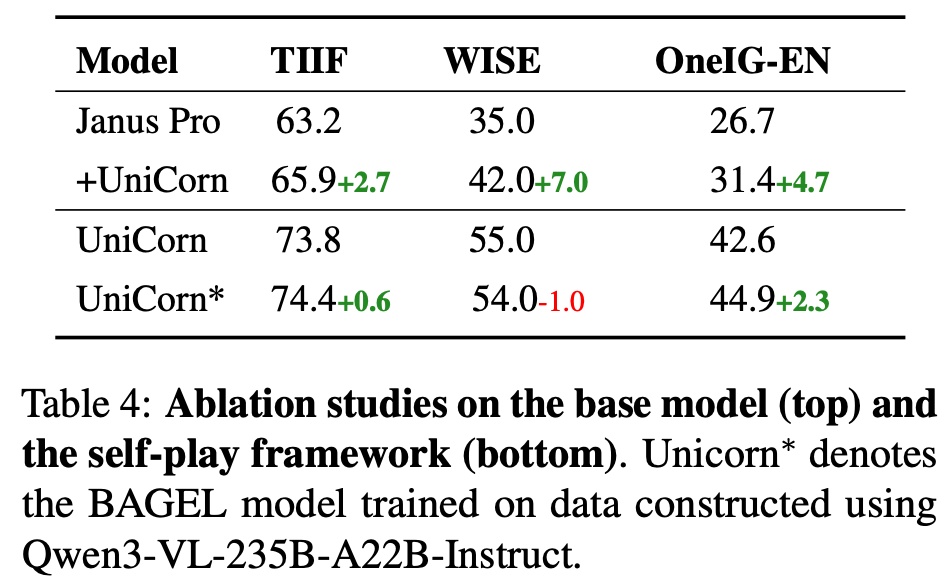
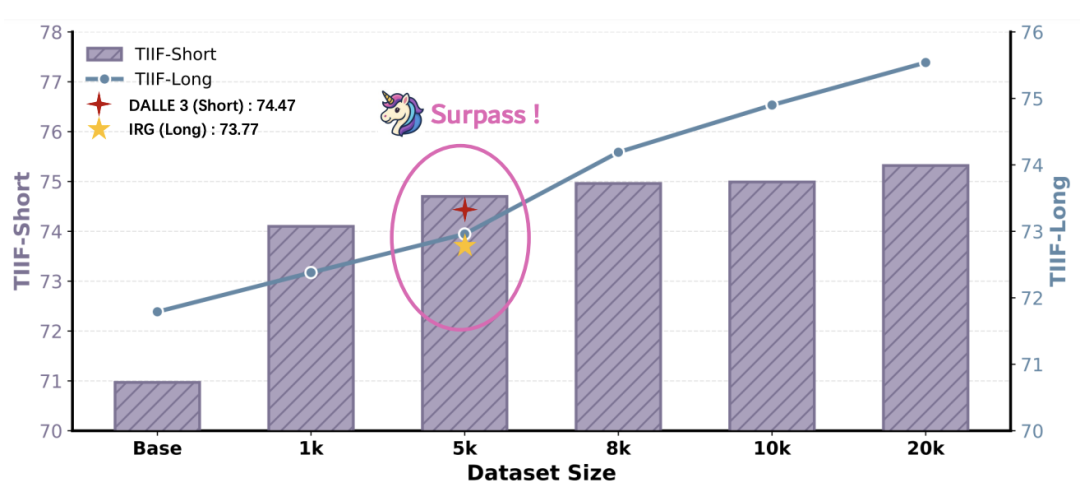
图 7:TIIF 上的数据缩放结果。 当数据集大小扩大时,分数持续提高。 值得注意的是,UniCorn 仅使用 5k 训练数据就超越了许多强大的模型
图 7:TIIF 上的数据缩放结果。 当数据集大小扩大时,分数持续提高。 值得注意的是,UniCorn 仅使用 5k 训练数据就超越了许多强大的模型
分析结论:
- 自我博弈的必要性:使用更强的外部模型(如 Qwen3-VL)构建数据(UniCorn*)并未带来显著收益,甚至在 UniCycle 上表现不如完全自监督的 UniCorn,说明外部监督可能带来不成比例的成本且缺乏统一协调性。
- 机制验证:定性分析表明,UniCorn 能够有效平衡视觉美感、提示忠实度和真实感,通过将理解转化为生成监督,弥合了两者间的差距。
结论
UniCorn,这是一个自监督的后训练框架,通过多智能体自我博弈和认知模式重构,将多模态理解和生成统一在单个模型中,在没有外部监督的情况下将内部潜在知识蒸馏为高质量的生成信号。包括 UniCycle 循环一致性基准在内的广泛实验表明,该方法在保持多模态智能的同时显著改进了 T2I 生成,突显了自包含反馈循环是统一多模态模型的一条可扩展路径。
局限性尽管在 T2I 生成和多模态理解方面都取得了稳健的表现,UniCorn 仍存在一定的局限性。首先,目前的自我提升框架以单轮方式运行,主要增强生成能力,未观察到理解指标的显著提升。在未来的工作中,本文打算探索多轮迭代自我博弈,以促进这两种能力的共同进化。其次,自我博弈机制要求 UMM 处理提示生成、推演和判断,这不可避免地引入了额外的计算成本。本文计划在后续研究中调查更高效的方法来简化这一过程。
参考文献
[1] UniCorn: Towards Self-Improving Unified Multimodal Models through Self-Generated Supervision
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号