AI数据新纪元:语义层与知识图谱的崛起

AI数据新纪元:语义层与知识图谱的崛起

数据存储前沿技术
发布于 2026-01-13 15:25:54
发布于 2026-01-13 15:25:54
全文概览
2024年,生成式AI以摧枯拉朽之势席卷全球,成为科技界最炙手可热的话题。2025年,AI代理的兴起又将我们带入了一个新的讨论:AI泡沫是否正在形成?然而,在这场AI狂潮的背后,一个更深层次的问题浮出水面——AI的真正价值,最终仍将回归到数据的本质。我们曾预测数据将迎来复兴,但仅仅拥有“好数据”就足够了吗?
随着AI模型日益复杂,尤其是语言模型深入数据湖的边界,它们对数据的需求已从简单的“好”数据,转向了更具上下文和业务含义的“正确”数据。这正是语义层和知识图谱重新登上舞台的契机。当AI需要理解“产品”或“交付问题”在不同语境下的确切含义时,传统的元数据管理已力不从心。如何为AI提供明确的业务上下文、数据定义和对象关系,从而消除猜测、确保推理的准确性?本文将深入探讨2026年数据领域的核心趋势:语义影响力领域的崛起,以及它如何重塑AI与数据的交互方式。
阅读收获
- 存储从业者: 认识到AI对数据上下文的深层需求,将促使存储系统设计者和管理者重新思考数据组织、元数据管理及知识图谱集成策略。向量数据库和支持语义查询的存储解决方案将成为关键,同时需关注数据共享和零ETL模式,以简化数据管道并提升数据价值。
- 行业证券分析师: 关注主要科技巨头在“语义影响力领域”的竞争格局,特别是SAP、Salesforce等应用厂商与Databricks、Snowflake等数据平台之间的合作与对抗。Model Context Protocol (MCP) 和 Open Semantic Interchange (OSI) 等开放标准的发展,将是评估市场走向和投资机会的重要指标。
- 产学研: 本文揭示了AI治理、非结构化数据治理以及知识图谱构建(特别是GraphRAG模式)在AI时代面临的挑战与机遇。研究方向可聚焦于如何高效构建和维护大规模本体论、提升AI模型对复杂语义的理解能力,以及培养“知识工程师”以弥合技术与业务之间的鸿沟。
👉 划线高亮 观点批注

2026年数据展望:语义影响力领域的崛起
特约撰稿人:Tony Baer[1]
2024年,生成式人工智能(Generative AI)抢占了所有对话的焦点,成为“房间里的大象”。2025年,对话转向了Agent(agents),以及我们身边是否正在发生AI泡沫的问题。但正如我们所指出的,AI抢尽风头,也让人们重新关注拥有良好数据的重要性,因此去年我们预测数据将迎来复兴[2]。
剧透一下:尽管拥有良好数据是必不可少的第一步,但AI模型需要正确的数据,而这正是今年关注的焦点。用Cindi Howson的话来说[3],语义再次变得性感起来。
但首先,让我们回顾一下我们是如何走到这一步的,并回答一个问题:数据复兴真的发生了吗?
始终是AI和Agent
尽管数据去年开始受到关注,但AI和Agent仍然占据了大部分注意力。Agent为何如此紧迫?也许是“害怕错过”(FOMO)。或者也许有一个更合理的解释。根据亚马逊网络服务公司(Amazon Web Services Inc.)首席执行官Matt Garman的说法,Agent是最终能让AI投资获得回报的技术。请看他最近在AWS re:Invent大会主题演讲中12分钟处[4]的发言,你会听到他正是这么说的。
但Agent真的准备好迎接黄金时代了吗?虽然普华永道(PricewaterhouseCoopers)[5]对此非常乐观,指出66%的受访者报告获得了可衡量的结果,但我们认为麦肯锡(McKinsey)的一项研究[6]描绘了一幅更现实的图景,其中62%的受访者表示他们的组织“至少正在试验Agent”。
Agent技术仍处于初级阶段。Agent的可靠性取决于其底层AI模型,而且AI模型能够推理并不一定意味着它正在正确推理[7]。至于完成复杂任务,卡内基梅隆大学的这项研究[8]表明Agent在这方面仍在挣扎。
至于AI泡沫,它之所以成为话题,是因为它现在对整个经济产生了实质性影响。一些报告估计AI正在推动美国GDP增长的90%[9],而另一些则指出数据中心建设为整体GDP增加了1个百分点[10]。
这些数字是否变得难以驾驭?因预测房地产市场崩溃而闻名于电影《大空头》的投资者Michael Burry[11],目前正在做空[12]英伟达公司(Nvidia Corp.)和Palantir Technologies Inc.。甲骨文公司(Oracle Corp.)最近的股价走势就很有说明性。在9月份公布2026财年第一季度财报[13]后的一周内,其披露了4550亿美元的“剩余履约义务”(SEC对已承诺收入管道的术语),股价飙升了约35%。但到12月季度,由于对杠杆的担忧以及OpenAI Group PBC占管道一半以上的事实,这些涨幅大部分都蒸发了。我们不会陷入经济预测的泥潭,但我们仍然坚持我们几年前的说法[14],即生成式AI至少需要四到五年才能使行业投资转为正收益。
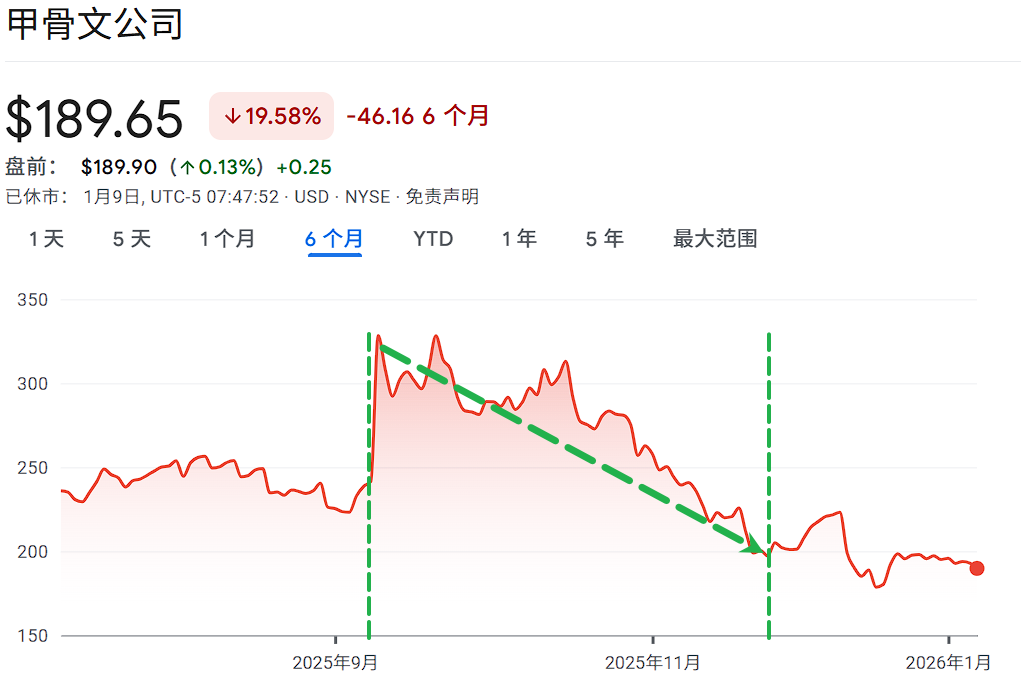
Oracle 最近6个月股价走势
Oracle 最近6个月股价走势
幕后,数据正在发生
在AWS re:Invent的主舞台上,Garman的主题演讲只有一个与数据相关的公告。那是期待已久的数据库节省计划的发布,甚至获得了严厉批评家Corey Quinn的认可[15]。然而,第二天,Swami Sivasubramanian博士[16]的数据和AI主题演讲[17]完全忽略了数据。剧透一下:Sivasubramanian博士多年来一直是数据和AI副总裁,现在正式成为Agent AI副总裁。到目前为止,我们的预测看起来不太乐观。
但AWS在数据方面的“失利”并不能说明全部情况。
在整个行业中,关于数据共享、零ETL、多云和收购的消息层出不穷——例如,IBM对Confluent的待定收购要约[18],这持续证明了现代数据堆栈的崩溃(或整合)。PostgreSQL也度过了重要的一年,Databricks Inc.[19]和Snowflake Inc.[20]收购了PostgreSQL数据库,而微软公司(Microsoft Corp.)最终推出了其PostgreSQL解决方案[21]以对抗Amazon Aurora和Google AlloyDB。还有一些代际升级,例如AWS发布[22]了Graviton5[23]以加速内存密集型数据库工作负载,以及Snowflake宣布了新的Gen2高级计算层[24]。
数据共享和零ETL取得了巨大进展。其动力是构建和管理脆弱数据管道的痛苦和复杂性。这些设计模式因此成为常见主题。数据共享最初由Snowflake推广,成为Databricks[25]、Google BigQuery和Microsoft Fabric等第三方访问SAP数据[26]的途径;这种模式也被Salesforce Inc.[27]使用。至于零ETL模式,它最初由AWS引入,用于简化从其各种操作数据库组合中填充Redshift和OpenSearch。2025年,Databricks[28]、微软[29]和Snowflake[30]进一步采用了这种方法,将其用于统一事务和分析层。
去年向量成为数据库平台复选框功能的势头也在继续。虽然Amazon Redshift仍然回避向量,但其他公司正在通过新的数据类型、统一查询和存储类来扩展支持。Oracle推出了结构化和非结构化(向量)数据的统一查询[31],而AWS则推出了专门为向量设计的新S3存储层[32]。
2025年的回顾不能不提到Apache Iceberg巩固了其作为事实标准开放表格式的地位,Databricks增加了对其的全面支持[33]。至于AI运行数据库?甲骨文多年前就凭借自治数据库(Autonomous Database)登上头条;现在这几乎被认为是理所当然的[34]。正如我们去年预测的那样,语言模型现在正在理解数据库中真正的内容[35],结合元数据、模式和表描述来生成业务术语。
数据库和Agent
不出所料,数据库中的Agent引起了广泛关注。以下仅是其中一些例子。
例如,Databricks和Snowflake产品组合中新增的PostgreSQL非常适合为自治Agent提供状态管理。AWS对其AgentCore部署框架的扩展支持情景记忆[36],用于执行复杂、扩展工作流的Agent;它通过“记住”应用程序的状态和支持它的数据库事务来实现这一点。这是解决卡内基梅隆大学研究中指出的Agent遗忘问题的一步。
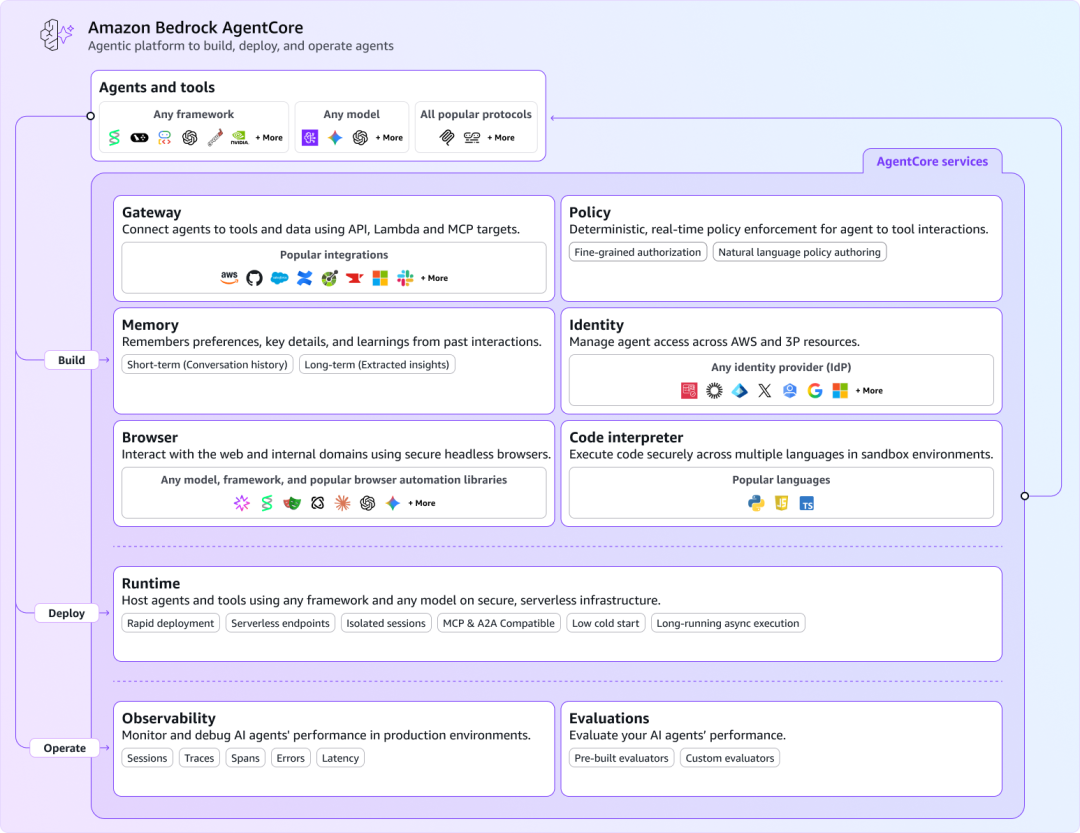
AWS AgentCore 组件全览
AWS AgentCore 组件全览
谷歌推出的数据库通用AI工具箱[37]提供了一个开源服务器,用于管理AI Agent连接到数据库的底层中间件。Databricks新Agent Bricks工具包的功能包括判断Agent是否生成准确SQL的能力[38]。同时,甲骨文[39]和Snowflake[40]引入了Agent在数据库中执行迭代推理的能力。
当然,任何关于Agent与数据库交互的讨论都不能不提及模型上下文协议(Model Context Protocol)[41]。开源MCP框架在过去一年中突然出现,并成为AI模型连接数据的实际标准,Anthropic PBC最近将其捐赠给了Linux基金会。MCP的优点在于其灵活性;它被构建为一个可扩展的框架,设想了模型连接数据的多种路径。它可能像模型发出REST调用以获取数据一样简单,也可能像触发Agent工作流可以调用的中间步骤以检索数据一样复杂。到目前为止,几乎所有主要的SaaS和AI平台提供商都宣布了他们自己的MCP服务器的预览版。
那么,数据复兴真的发生了吗?
一年前,我们提出AI的采用将重新引起对数据的关注。当时我们指出,虽然结构化数据治理的生态系统已经相当成熟,但近期创新将集中在几个领域:治理非结构化数据,并利用知识图谱进行基础化。我们曾希望数据和AI之间的治理孤岛能够开始弥合[42]。那么,一系列供应商公告是否意味着数据复兴真的发生了呢?
可以说,数据质量和数据治理的学科,基于可用的工具和完善的最佳实践,已经相当成熟——尽管在现实中,广泛、持续的采用将永远是一个持续的传奇。也许语言模型可以在这里提供帮助,但它们不能替代强大的流程。
至于AI治理,这是一个更新的实践领域。根据Audit Board[43]的数据,只有四分之一的组织完全实施了AI治理。而数据治理本身仍然是AI采用的巨大障碍,根据AWS的一项研究[44],近40%的首席数据官提到了数据质量和集成这些长期存在的问题。我们还有功课要做。
2025年取得了一些进展。MCP作为AI模型连接数据的实际标准框架几乎一夜之间出现,这反映了业界认为数据对AI有多么重要。
在将治理扩展到非结构化数据(主要是文档)方面取得了一些早期进展。IBM watsonx.governance引入了管理非结构化数据[45]的功能,该功能可以转换文档并通过分配分类、数据类和业务术语来丰富它们,为检索增强生成(RAG)做准备。类似地,微软将Purview的敏感度标签[46]扩展到非结构化文件,同时增加了自动分类200多种信息类型(如信用卡或护照)的功能。Databricks Unity Catalog将访问控制扩展到非结构化数据[47],使用AI爬取这些文件以生成语言模型可以读取的描述并捕获血缘关系;Snowflake的Document AI[48]功能可以用于类似目的。
一年后,弥合数据和AI之间的治理孤岛仍然难以实现。Databricks值得称赞,它是少数几家真正在Unity Catalog中构建了关联哪些模型使用哪些数据集的能力[49]的公司之一。
知识图谱和使用它们通过GraphRAG模式为AI提供基础也获得了越来越多的行业支持。GraphRAG背后的指导思想是使向量相似性搜索更具相关性。知识图谱的采用仍处于萌芽阶段。我们已经开始看到经典早期采用者的案例研究——例如,德勤使用Amazon Neptune图数据库的向量支持进行网络安全情报[50],或者AdaptX使用FalkorDB分析复杂的医疗和患者数据以改善结果[51]。此外,GraphRAG一直是人力资源[52]、税务和财务合规[53]、制造业[54]和物流[55]等用例的研究课题。
行业已加紧构建工具以促进GraphRAG。一些例子包括Google Vertex AI RAG Engine[56],它提供了构建RAG应用程序的数据框架;现在它已与Spanner集成。微软是GraphRAG模式的创始者,一直在通过LazyGraphRAG[57]等优化来完善它,以减少大型数据集的索引瓶颈。
Neo4J是众多专业图数据库中硕果仅存的巨头,它发布了一套工具、库和数据库功能。亮点包括一个Python库[58],用于构建完整的基于图的推理应用程序,以及一个LLM知识图谱构建器[59]在线应用程序,用于将非结构化文本转换为知识图谱。GraphRAG并非为RAG应用程序提供基础的唯一方法;AWS采用不同的方法,利用语言模型评估输出[60]。
当然,为生成式AI应用程序构建知识图谱也面临着相当多的挑战,其中之一就是正确构建本体。这归结为我们一年前指出的一个非常人性化的挑战:生成式AI将推动对更多知识工程师[61]的需求。这为我们预计2026年将发生的事情奠定了基础。
2026年将发生什么?语义影响力领域将融合
AI模型不仅需要“好”数据,还需要“正确”数据。当然,这对于任何使用数据的应用程序都是如此,但至少对于在数据市场、数据仓库或数据湖中针对已知数据集运行的传统商业智能或预测应用程序,上下文是隐含的。对于突破数据湖边界的语言模型来说,情况并非如此。上下文必须是明确的。
例如,在摄取和分块各种文档、电子邮件、文本或社交网络内容时,您能确定当一个或多个客户谈论“产品”或“交付问题”时,他们谈论的是同一件事,或者与不同产品或交付问题的相似性是相关的吗?对于AI来说,语义应该通过明确业务上下文、数据定义和对象关系(希望在底层知识图谱中实例化)来消除这种猜测。
这就是为什么我们去年年初就认识到知识工程师的需求[62]。这也导致了对一个古老概念——语义层——的兴趣复苏。语义层在BI工具和企业应用程序中存在多年,长期以来一直被认为是理所当然的。作为业务词汇表之上的抽象层,语义层以目录的形式编纂了报告类型和关键绩效指标。在许多BI工具中,语义层通常被称为度量层,因为它们被认为是度量和KPI的权威存储库。
Business Objects Universe是第一个BI语义层;其目标是建立单一的事实来源。它通过维度(实体名称,如“客户”或“商店城市”)、度量(数字代表什么,例如“销售收入”或“单位成本”)和详细信息(支持信息,例如客户的电话号码或居住城市)来定义对象。在BI世界中,语义层的使用时兴时衰;例如,当Tableau出现后自助可视化变得流行时,客户优先考虑获取自己的数据提取,而不是定义企业报告标准。
语义在企业应用程序领域拥有更持久的存在,因为它们不仅定义了数据,还定义了其底层的业务流程。我们当时可能没有称之为语义,但定义企业应用程序的数据实体和流程一直与它们的源代码一样基础,因此它们也同样受到严密保护。例如,您无法在SAP、ServiceNow或Salesforce的应用程序之外运行它们的知识图谱。
相反,它们应用程序平台的度量通常通过抽象暴露给第三方系统,这些抽象过去相当原始。例如,在Tableau Semantics[63]最近发布之前,Salesforce只提供低级元数据API和查询语言,每个BI工具都必须构建自己对Salesforce模式的解释。SAP在推出数据产品[64]之前也是如此;值得注意的是,SAP只通过共享而不是导出这些数据产品来授予对第三方系统的访问权限。对于ServiceNow,最近收购[65]数据目录data.world应该能提供通向世界的语义窗口。
作为未来趋势的预兆,当SAP发布作为其业务数据云一部分的数据产品时,它宣布与Databricks建立OEM合作关系,以与Databricks用户共享这些产品。语义将两家独立的公司联系在一起:Databricks拥有SAP所缺乏的数据科学能力,而SAP拥有Databricks所缺乏的对其数据上下文的洞察。此后,SAP与Google BigQuery、Snowflake和Microsoft Fabric达成了类似的数据共享协议。我们想知道AWS何时会跟进。
微软又发射了一枪,推出了Fabric IQ[66]。Fabric IQ在Fabric现有的Power BI语义层基础上,增加了_本体_。语义和本体常常被混淆;区别在于语义是关于事物意味着什么(例如,为分析报告目的定义数据实体的业务术语和概念),而本体是关于知识如何结构化(例如,业务是什么以及它如何运作)。重要的是Fabric IQ出现的原因。当微软将实时智能添加到Fabric时,需要确保所采取的行动处于正确的上下文中。AI Agent的出现扩大了AI与数据交互的攻击面,提高了风险。
这就是Snowflake在9月宣布开放语义互换(Open Semantic Interchange)[67]倡议的背景,该倡议得到了创始合作伙伴Salesforce、dbt Labs(即将与Fivetran合并)、Relational AI以及十多家其他公司的支持。OSI基于dbt Labs开发的MetricFlow,旨在提供一种定义度量和维度的通用格式。在底层,OSI使用YAML文件配置由数据实体及其关联的维度、度量和标签组成的规范语义模型[68]。目前,该规范非常初步;例如,尽管默认度量[69]是必需的值,但目前只定义了一个。
OSI面临的挑战是,开源项目通常只有在解决高度商品化的技术构建块(没有差异化价值)时才能成功,例如Apache Iceberg的开放表格式。然而,语义处于价值链的高端——以至于应用程序供应商对其严密保护。尽管如此,AI提高了使不同查询引擎的语义定义可互操作的紧迫性。Snowflake和其他查询引擎提供商感受到向AI模型提供_正确数据_和_正确上下文_的紧迫性,这直接回应了应用程序中如此多的价值与语义相关联的事实,而SAP、ServiceNow、Oracle和Salesforce在语义方面拥有主场优势。
在2026年的AI世界中,“知识就是力量”这句格言可以更新为“语义就是力量”。正如我们去年所指出的,对知识工程师存在巨大的潜在需求,这是目前少数几个AI正在增加需求而不是取代人类的职业之一。但绘制组织知识图谱的能力令人望而生畏[70],根据运营本体论咨询业务的Jessica Talisman[71]的说法,这需要的不仅仅是数据架构师的技能。
哦,顺便说一句,这并不是我们第一次经历这种“舞蹈”。还记得20世纪90年代失败的知识管理,它变成了咨询公司的“烧钱项目”吗?存在项目团队可能抓取错误数据[72]来构建知识图谱,然后宣布胜利并收工的风险。
核心内容在哪里?
对于大多数组织来说,语义可能驻留在哪里?传统的早期采用者以及金融服务或电信等行业的组织可能会启动或加强自己的计划,以定义自己的语义层和/或其组织的权威本体论。
但对于大多数缺乏深厚技能或严谨企业架构实践的组织来说,定义语义的起点是直接从源头开始:企业应用程序和/或,或者,从其最初定位(定位和/或提供数据治理的执行点)中扩展出来的新一代数据目录。在大多数组织中,解决方案不会是非此即彼的。
在AI时代,SAP、ServiceNow、Salesforce和Oracle等公司将此提升到新的水平,开放度量、数据实体和业务流程的定义,以巩固其语义影响力领域,这是合乎逻辑的。这为Snowflake、Databricks、Informatica、ThoughtSpot、Starburst、Collibra和Alation等公司提供了充足的理由,联合起来以OSI回应。2026年,语义将成为伞形解决方案和最佳实践之间的下一个战场,SAP与Databricks和Snowflake的数据共享协议将形成最可能的模板。
所有这一切的发生,是因为AI不仅需要好数据,还需要正确的数据。这将是充满有趣的一年。
Tony Baer是dbInsight LLC[73]的负责人,该公司提供对数据库和分析技术生态系统的独立见解。Baer是扩展数据管理实践、治理和高级分析以满足企业从数据驱动转型中产生有意义价值的行业专家。他为SiliconANGLE撰写了本文。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- 随着AI对“正确数据”的需求日益增长,您认为在实际企业环境中,构建和维护一个全面且准确的语义层和知识图谱,最大的挑战会是什么?是技术实现、数据治理、人才培养还是组织文化变革?
- 文章提到“语义影响力领域”将成为新的战场,您认为未来是像SAP、Salesforce这样的应用巨头能更好地掌握语义主导权,还是像Snowflake、Databricks这样的数据平台能通过开放标准赢得胜利?这种竞争将如何影响数据生态系统的发展?
- “知识工程师”被认为是AI时代的关键职业。您认为高校和企业应如何合作,共同培养具备跨学科知识(如本体论、数据科学、领域专业知识)的知识工程师,以满足日益增长的市场需求?
原文标题:Data 2026 outlook: The rise of semantic spheres of influence[74]
#CubeInsight #智能数据平台
---【本文完】---
👇阅读原文,搜索🔍更多历史文章。
- https://siliconangle.com/author/guestauthor/ ↩
- https://siliconangle.com/2025/01/06/data-2025-outlook-ai-drives-renaissance-data/ ↩
- https://www.linkedin.com/pulse/why-semantic-layers-suddenly-sexy-cindi-howson-z1pie/ ↩
- https://www.youtube.com/watch?v=q3Sb9PemsSo ↩
- https://www.pwc.com/us/en/tech-effect/ai-analytics/ai-agent-survey.html ↩
- https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai ↩
- https://machinelearning.apple.com/research/illusion-of-thinking ↩
- https://www.cs.cmu.edu/news/2025/agent-company ↩
- https://www.ey.com/en_us/insights/ai/ai-powered-growth ↩
- https://www.ey.com/en_us/insights/ai/ai-powered-growth ↩
- https://en.wikipedia.org/wiki/Michael_Burry ↩
- https://www.wsj.com/finance/stocks/michael-burry-bets-he-isnt-too-early-to-go-against-the-ai-juggernaut-5d95d21e?mod=hp_lead_pos2 ↩
- https://investor.oracle.com/investor-news/news-details/2025/Oracle-Announces-Fiscal-Year-2026-First-Quarter-Financial-Results/default.aspx ↩
- https://siliconangle.com/2024/02/26/giant-sucking-sound-generative-ai/ ↩
- https://www.duckbillhq.com/blog/aws-database-savings-plans-six-years-of-complaining-finally-pays-off/ ↩
- https://www.linkedin.com/in/swaminathansivasubramanian/ ↩
- https://www.youtube.com/watch?v=prVdCIHlipg ↩
- https://siliconangle.com/2025/12/08/ibm-will-acquire-confluent-address-growing-needs-real-time-data-ai-models/ ↩
- https://www.databricks.com/company/newsroom/press-releases/databricks-agrees-acquire-neon-help-developers-deliver-ai-systems ↩
- https://www.wsj.com/articles/snowflake-to-buy-crunchy-data-for-250-million-233543ab? ↩
- https://azure.microsoft.com/en-us/products/horizondb ↩
- https://siliconangle.com/2025/12/04/aws-debuts-graviton5-powerful-efficient-custom-cpu-cloud-workloads/ ↩
- https://www.aboutamazon.com/news/aws/aws-graviton-5-cpu-amazon-ec2 ↩
- https://www.snowflake.com/en/engineering-blog/gen2-warehouses-snowflake-multicloud-ga/ ↩
- https://help.sap.com/docs/business-data-cloud/sap-databricks/creating-delta-sharing-catalog-from-data-product-in-sap-databricks ↩
- https://www.linkedin.com/pulse/sap-business-data-cloud-architecture-zero-copy-delta-share-jewett-kbvaf/ ↩
- https://cloud.google.com/blog/products/data-analytics/salesforce-data-cloud-bidirectional-data-sharing-with-bigquery ↩
- https://www.databricks.com/blog/what-is-a-lakebase ↩
- https://learn.microsoft.com/en-us/fabric/database/sql/overview ↩
- https://www.snowflake.com/en/engineering-blog/postgres-public-preview/ ↩
- https://blogs.oracle.com/database/oracle-announces-oracle-ai-database-26ai ↩
- https://aws.amazon.com/blogs/aws/amazon-s3-vectors-now-generally-available-with-increased-scale-and-performance/ ↩
- https://www.databricks.com/blog/announcing-full-apache-iceberg-support-databricks/ ↩
- https://docs.databricks.com/aws/en/optimizations/predictive-optimization ↩
- https://cloud.google.com/blog/products/data-analytics/data-analytics-innovations-at-next25 ↩
- https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/episodic-memory-strategy.html ↩
- https://cloud.google.com/blog/products/ai-machine-learning/announcing-gen-ai-toolbox-for-databases-get-started-today ↩
- https://www.databricks.com/blog/building-custom-llm-judges-ai-agent-accuracy ↩
- https://docs.oracle.com/en-us/iaas/autonomous-database-serverless/doc/select-ai-agent.html ↩
- https://www.snowflake.com/en/developers/guides/getting-started-with-snowflake-intelligence/ ↩
- https://modelcontextprotocol.io/docs/getting-started/intro ↩
- https://www.dataiq.global/award-winner/best-data-governance-with-ai-initiative-natwest-and-version-1 ↩
- https://auditboard.com/blog/new-research-finds-only-25-percent-of-organizations-report-a-fully-implemented-ai-governance-program ↩
- https://aws.amazon.com/blogs/enterprise-strategy/data-governance-in-the-age-of-generative-ai/ ↩
- https://dataplatform.cloud.ibm.com/docs/content/wsj/curation/curation-unstructured.html?context=df ↩
- https://learn.microsoft.com/en-us/purview/data-gov-best-practices-sensitivity-labels ↩
- https://docs.databricks.com/aws/en/volumes/ ↩
- https://docs.snowflake.com/en/user-guide/snowflake-cortex/document-ai/overview ↩
- https://docs.databricks.com/aws/en/machine-learning/feature-store/lineage ↩
- https://www.antstack.com/talks/reinvent25/aws-reinvent-2025---deep-dive-into-deloittes-amazon-neptune-genai-security-intelligence-center/ ↩
- https://www.falkordb.com/case-studies/how-adaptx-uncovers-hidden-potential-in-their-clinical-data/ ↩
- https://datanucleus.dev/rag-and-agentic-ai/what-is-rag-enterprise-guide-2025 ↩
- https://graphwise.ai/resources/ ↩
- https://www.researchgate.net/publication/391997279_Document_GraphRAG_Knowledge_Graph_Enhanced_Retrieval_Augmented_Generation_for_Document_Question_Answering_Within_the_Manufacturing_Domain ↩
- https://www.mdpi.com/2079-9292/14/7/1241 ↩
- https://docs.cloud.google.com/vertex-ai/generative-ai/docs/rag-engine/rag-overview ↩
- https://www.microsoft.com/en-us/research/blog/lazygraphrag-setting-a-new-standard-for-quality-and-cost/ ↩
- https://neo4j.com/docs/neo4j-graphrag-python/current/ ↩
- https://neo4j.com/blog/developer/llm-knowledge-graph-builder/ ↩
- https://aws.amazon.com/blogs/machine-learning/evaluating-rag-applications-with-amazon-bedrock-knowledge-base-evaluation/ ↩
- https://siliconangle.com/2025/02/04/data-generative-ai-era-need-knowledge-engineers/ ↩
- https://siliconangle.com/2025/02/04/data-generative-ai-era-need-knowledge-engineers/ ↩
- https://www.tableau.com/products/tableau-semantics ↩
- https://www.sap.com/resources/what-are-data-products ↩
- https://www.linkedin.com/pulse/how-servicenows-acquisition-dataworld-change-way-world-david-rider-bkhcc/?trackingId=dHlT9jv8Qsi7qSxwFhgdHw== ↩
- https://learn.microsoft.com/en-us/fabric/iq/overview ↩
- https://www.snowflake.com/en/blog/open-semantic-interchange-ai-standard/ ↩
- https://docs.getdbt.com/docs/build/semantic-models ↩
- https://docs.getdbt.com/docs/build/semantic-models#defaults ↩
- https://jessicatalisman.substack.com/p/why-ai-isnt-autonomous-yet-181 ↩
- https://www.linkedin.com/in/jmtalisman/details/experience/ ↩
- https://jessicatalisman.substack.com/p/why-ai-isnt-autonomous-yet-181 ↩
- https://www.dbinsight.io/home ↩
- https://siliconangle.com/2026/01/05/data-2026-outlook-rise-semantic-spheres-influence/ ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号