【数据结构】二叉树的遍历与操作

【数据结构】二叉树的遍历与操作

那我掉的头发算什么
发布于 2026-01-12 18:25:44
发布于 2026-01-12 18:25:44
前言
在前文树,二叉树中我们已经掌握了二叉树的基本概念与方法,但在实际面试中,仅会基础操作远远不够。本文将聚焦二叉树的进阶知识点,通过代码实现 + 面试题解析的形式,深入探讨迭代遍历、构造二叉树、路径问题、序列化与反序列化等高频考点,帮你建立解题思维,应对面试挑战。
二叉树的基本操作
在学习二叉树的基本操作前,需先要创建一棵二叉树,然后才能学习其相关的基本操作。由于现在大家对二叉树结构掌握还不够深入,为了降低大家学习成本,此处手动快速创建一棵简单的二叉树,快速进入二叉树操作学习,等二叉树结构了解的差不多时,我们反过头再来研究二叉树真正的创建方式。
public class BinaryTree{
public static class BTNode{
BTNode left;
BTNode right;
int value;
BTNode(int value){
this.value = value;
}
}
private BTNode root;
public void createBinaryTree(){
BTNode node1 = new BTNode(1);
BTNode node1 = new BTNode(2);
BTNode node1 = new BTNode(3);
BTNode node1 = new BTNode(4);
BTNode node1 = new BTNode(5);
BTNode node1 = new BTNode(6);
root = node1;
node1.left = node2;
node2.left = node3;
node1.right = node4;
node4.left = node5;
node5.right = node6;
}
}注意:上述代码并不是创建二叉树的方式,真正创建二叉树方式后序详解重点讲解。 再看二叉树基本操作前,再回顾下二叉树的概念,二叉树是:
- 空树
- 非空:根节点,根节点的左子树、根节点的右子树组成的
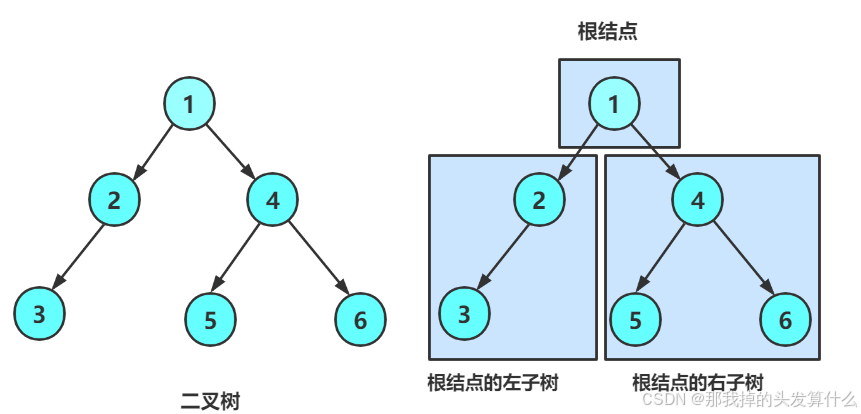
从概念中可以看出,二叉树定义是递归式的,因此后序基本操作中基本都是按照该概念实现的
二叉树的遍历
前中后序遍历
学习二叉树结构,最简单的方式就是遍历。所谓遍历(Traversal)是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问。访问结点所做的操作依赖于具体的应用问题(比如:打印节点内容、节点内容加1)。 遍历是二叉树上最重要的操作之一,是二叉树上进行其它运算之基础。
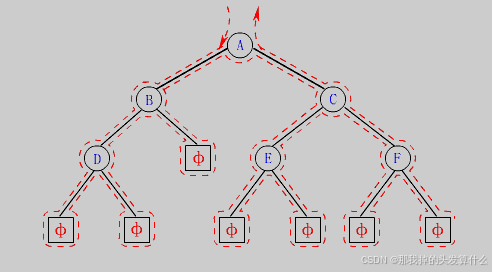
在这里插入图片描述
在遍历二叉树时,如果没有进行某种约定,每个人都按照自己的方式遍历,得出的结果就比较混乱,如果按照某种规则进行约定,则每个人对于同一棵树的遍历结果肯定是相同的。如果N代表根节点,L代表根节点的左子树,R代表根节点的右子树,则根据遍历根节点的先后次序有以下遍历方式: NLR:前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点—>根的左子树—>根的右子树。 LNR:中序遍历(Inorder Traversal)——根的左子树—>根节点—>根的右子树。 LRN:后序遍历(Postorder Traversal)——根的左子树—>根的右子树—>根节点。
// 前序遍历
public void preOrder(TreeNode root){
if(root == null){
return;
}
System.out.print(root.val + " ");
preOrder((root.left));
preOrder((root.right));
}
// 中序遍历
public void inOrder(TreeNode root){
if(root == null){
return;
}
inOrder((root.left));
System.out.print(root.val + " ");
inOrder((root.right));
}
// 后序遍历
public void postOrder(TreeNode root){
if(root == null){
return;
}
postOrder((root.left));
postOrder((root.right));
System.out.print(root.val + " ");
}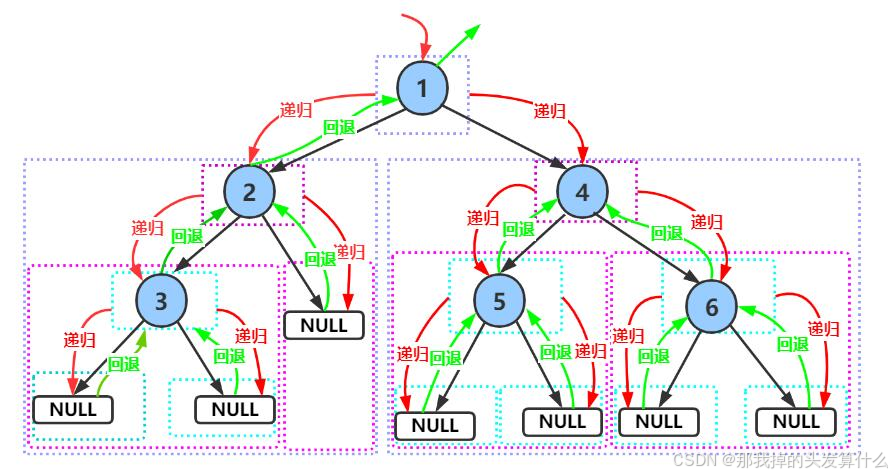
在这里插入图片描述
前序遍历结果:1 2 3 4 5 6 中序遍历结果:3 2 1 5 4 6 后序遍历结果:3 1 5 6 4 1
层序遍历
层序遍历:除了先序遍历、中序遍历、后序遍历外,还可以对二叉树进行层序遍历。设二叉树的根节点所在层数为1,层序遍历就是从所在二叉树的根节点出发,首先访问第一层的树根节点,然后从左到右访问第2层上的节点,接着是第三层的节点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
在这里插入图片描述
层序遍历涉及的内容比较复杂,后面会详细解释,如果实现的话,我们一般会借助队列来帮忙:
//层序遍历
public void levelOrder(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
if(root == null){
return ;
}
queue.offer(root);
while(!queue.isEmpty()){
TreeNode cur = queue.poll();
System.out.print(cur.val + " ");
if(cur.left != null){
queue.offer(cur.left);
}
if(cur.right != null){
queue.offer(cur.right);
}
}
System.out.println();
}
//层序遍历2
public List<List<Character>> levelOrder2(TreeNode root) {
List<List<Character>> ret = new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
if(root == null){
return null;
}
queue.offer(root);
while(!queue.isEmpty()){
List<Character> list = new ArrayList<>();
int size = queue.size();
while(size != 0) {
TreeNode cur = queue.poll();
list.add(cur.val);
if (cur.left != null) {
queue.offer(cur.left);
}
if (cur.right != null) {
queue.offer(cur.right);
}
size--;
}
ret.add(list);
}
return ret;
}
//判断是否是完全二叉树(依旧层序遍历)
public boolean isCompleteTree(TreeNode root){
Queue<TreeNode> queue = new LinkedList<>();
if(root == null){
return true;
}
queue.offer(root);
while(!queue.isEmpty()){
TreeNode cur = queue.poll();
if(cur != null){
queue.offer(cur.left);
queue.offer(cur.right);
}else{
while(!queue.isEmpty()){
TreeNode check = queue.poll();
if(check != null){
return false;
}
}
}
}
return true;
}理论巩固: 1.某完全二叉树按层次输出(同一层从左到右)的序列为 ABCDEFGH 。该完全二叉树的前序序列为() A: ABDHECFG B: ABCDEFGH C: HDBEAFCG D: HDEBFGCA 2.二叉树的先序遍历和中序遍历如下:先序遍历:EFHIGJK;中序遍历:HFIEJKG.则二叉树根结点为() A: E B: F C: G D: H 3.设一课二叉树的中序遍历序列:badce,后序遍历序列:bdeca,则二叉树前序遍历序列为() A: adbce B: decab C: debac D: abcde 4.某二叉树的后序遍历序列与中序遍历序列相同,均为 ABCDEF ,则按层次输出(同一层从左到右)的序列为() A: FEDCBA B: CBAFED C: DEFCBA D: ABCDEF 【参考答案】 1.A 2.A 3.D 4.A
当然,实现遍历肯定不止递归这一种方法,其实用我们比较熟练的迭代的方法也可以解决。
二叉树的非递归遍历
二叉树的非递归遍历在二叉树这一块是一道热门题,感兴趣的同学可以点击下面的链接去力扣挑战一下。 二叉树的前序遍历
题目要求与递归一样,只是方法有所变化,而且前中后都是用的同一个思想解决问题: 例如前序:
输入:root = [1,2,3,4,5,null,8,null,null,6,7,9]
输出:[1,2,4,5,6,7,3,8,9]
在这里插入图片描述
public List<Integer> preorderTraversal(TreeNode root) {
if(root == null){
return new ArrayList<>();
}
List<Integer> arraylist = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while(!stack.isEmpty() || cur != null){
while(cur != null){
stack.push(cur);
arraylist.add(cur.val);
cur = cur.left;
}
TreeNode top = stack.pop();
cur = top.right;
}
return arraylist;
}使用栈来暂存数据,迭代遍历每一个点,最终实现目标。
public List<Integer> inorderTraversal(TreeNode root) {
if(root == null){
return new ArrayList<>();
}
List<Integer> arrayList = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while(cur != null || !stack.isEmpty()){
while(cur != null){
stack.push(cur);
cur = cur.left;
}
TreeNode top = stack.pop();
arrayList.add(top.val);
cur = top.right;
}
return arrayList;
}中序遍历也一样,但是后序遍历略有不同。
public List<Integer> postorderTraversal(TreeNode root) {
if(root == null){
return new ArrayList<>();
}
List<Integer> arraylist = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
TreeNode prev = null;
while(!stack.isEmpty() || cur != null){
while(cur != null ){
stack.push(cur);
cur = cur.left;
}
TreeNode top = stack.peek();
if(top.right != null && top.right != prev){
cur = top.right;
}else{
TreeNode top2 = stack.pop();
arraylist.add(top2.val);
cur = null;
prev = top2;
}
}
return arraylist;
}后序遍历在运行的时候,如果不使用prev的话,在处理右子树的时候,很容易陷入死循环。
二叉树简单操作与方法
public static int nodeSize = 0;
// 获取树中节点的个数
public int size(TreeNode root){
if(root == null){
return -1;
}
nodeSize++;
size(root.left);
size(root.right);
return nodeSize;
}
public int size2(TreeNode root){
if(root == null){
return 0;
}
return size2(root.left) + size2(root.right) + 1;
}
public static int leafSize = 0;
public void getLeafNodeSize(TreeNode root){
if(root == null){
return;
}
if(root.left == null && root.right == null){
leafSize++;
}
getLeafNodeSize(root.left);
getLeafNodeSize(root.right);
}
public int getLeafNodeSize2(TreeNode root){
if(root == null){
return 0;
}
if(root.left == null && root.right == null){
return 1;
}
return getLeafNodeSize2(root.left) + getLeafNodeSize2(root.right);
}
public int getKLevelNodeCount(TreeNode root,int k){
if(root == null){
return 0;
}
if(k == 1){
return 1;
}
return getKLevelNodeCount(root.left,k - 1) + getKLevelNodeCount(root.right,k - 1);
}
// 检测值为value的元素是否存在
public TreeNode find(TreeNode root, int val){
if(root.val == val){
return root;
}
TreeNode left = find(root.left,val);
if(left != null){
return left;
}
TreeNode right = find(root.right,val);
if(right!= null){
return right;
}
return null;
}这些操作相对而言都比较简单,直接通过简单递归就可以完成。
//层序遍历
public void levelOrder(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
if(root == null){
return ;
}
queue.offer(root);
while(!queue.isEmpty()){
TreeNode cur = queue.poll();
System.out.print(cur.val + " ");
if(cur.left != null){
queue.offer(cur.left);
}
if(cur.right != null){
queue.offer(cur.right);
}
}
System.out.println();
}
//层序遍历2
public List<List<Character>> levelOrder2(TreeNode root) {
List<List<Character>> ret = new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
if(root == null){
return null;
}
queue.offer(root);
while(!queue.isEmpty()){
List<Character> list = new ArrayList<>();
int size = queue.size();
while(size != 0) {
TreeNode cur = queue.poll();
list.add(cur.val);
if (cur.left != null) {
queue.offer(cur.left);
}
if (cur.right != null) {
queue.offer(cur.right);
}
size--;
}
ret.add(list);
}
return ret;
}
//判断是否是完全二叉树(依旧层序遍历)
public boolean isCompleteTree(TreeNode root){
Queue<TreeNode> queue = new LinkedList<>();
if(root == null){
return true;
}
queue.offer(root);
while(!queue.isEmpty()){
TreeNode cur = queue.poll();
if(cur != null){
queue.offer(cur.left);
queue.offer(cur.right);
}else{
while(!queue.isEmpty()){
TreeNode check = queue.poll();
if(check != null){
return false;
}
}
}
}
return true;
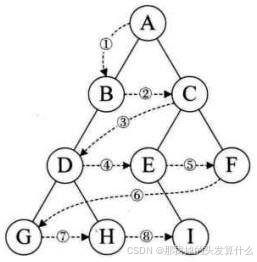
}我们在之前提到过的层序遍历只需要借助队列就能轻松解决,但是这其中判断完全二叉树可能有点困难理解起来,我画个图演示一下
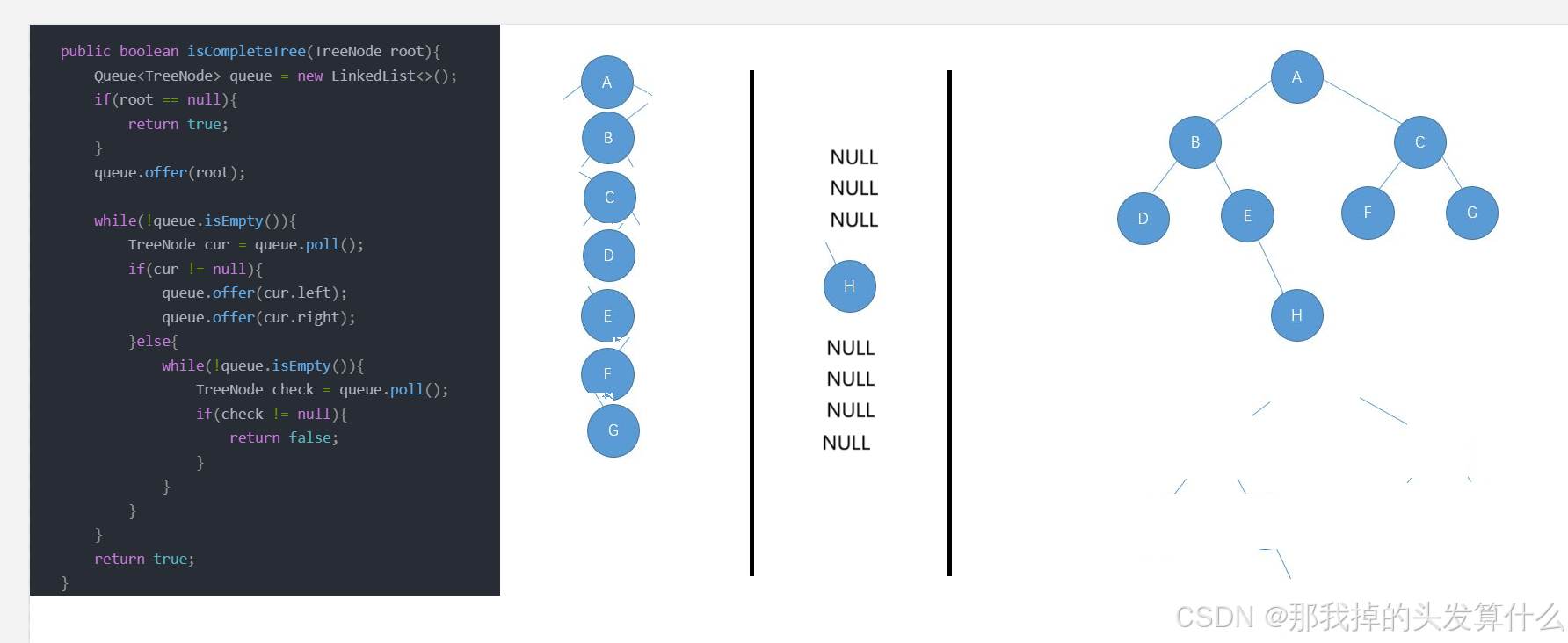
在最后一步检查的时候,只要队列里面还剩下元素,那就说明不是完全二叉树(剩下那个元素不可能在最左边)。
总结
二叉树遍历的核心价值在于其灵活适配不同场景的范式体系。从访问顺序维度,前序、中序、后序与层序遍历构成了四大基础框架,其本质差异仅在于根节点的访问时机,却衍生出适配各类需求的技术路径:前序遍历适配 “先主干后分支” 的场景处理,中序遍历支撑有序数据的结构化输出,后序遍历满足 “先子后父” 的依赖处理逻辑,层序遍历则适配层级化数据的逐层解析需求。 从实现方式来看,递归与迭代的二元选择彰显了技术选型的辩证思维:递归遍历以 “分治思想” 为核心,通过问题拆解实现代码的简洁优雅,是逻辑表达的理想范式;迭代遍历则借助栈与队列等数据结构模拟递归过程,在大规模数据场景中实现更高的稳定性与效率,成为工程实践的优选方案。二者的有机结合,构成了遍历技术从理论到实践的完整闭环。
然而,这一章的内容相对来说还是比较简单的,下一章我们会讲二叉树的面试题以及真正的有难度的操作。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-10-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号