数据结构排序算法详解(5)——非比较函数:计数排序(鸽巢原理)及排序算法复杂度和稳定性分析

数据结构排序算法详解(5)——非比较函数:计数排序(鸽巢原理)及排序算法复杂度和稳定性分析

星轨初途
发布于 2026-01-09 14:54:04
发布于 2026-01-09 14:54:04
前言
嗨٩(๑>◡<๑)۶ ,我们又见面啦,上一篇我们讲解了最后一类排序——归并排序,虽然排序分为4类,但是有些不属于这些排序但在实践中有很大应用的,比如非比较函数中——计数排序,虽然非比较函数还有基数排序和桶排序,但作用太小,这里就不做讲解了,本篇主要围绕计数排序和排序算法复杂度和稳定性分析展开,让我们一起了解吧!
八、非比较排序中的计数排序
所谓非比较函数,就是不依赖元素的大小比较操作(如<、>、<=),而是利用元素本身的数值特征(如取值范围、位数、哈希值等)直接确定元素的最终位置,从而完成排序。 而计数排序就是一种比较好用的排序
1、计数排序的概念及思路
思想:计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。
1、概念:
计数排序是一种非比较型排序算法,核心是利用元素的取值范围,通过统计每个元素的出现次数,直接确定元素在最终有序数组中的位置,从而完成排序。
2、计数排序算法步骤:
- 确定范围与统计频率:
先遍历待排序数组,找到最大值与最小值,计算取值范围(
最大值-最小值+1);(用于确定计数数组大小,避免空间浪费,通过元素值-最小值做下标映射,输出时再加回最小值) 随后创建计数数组,遍历待排序数组,统计每个元素的出现次数并存储到计数数组对应位置(以元素值-最小值为下标)。 - 重构有序数组:
遍历计数数组,根据每个下标对应的统计次数,将
下标+最小值的元素依次填充回原数组(按计数数组顺序逐个填充,次数为统计的出现次数)。 - 输出结果: 原数组已被直接覆盖为有序数组,直接输出原数组即可。
可以从下面动图来加强理解
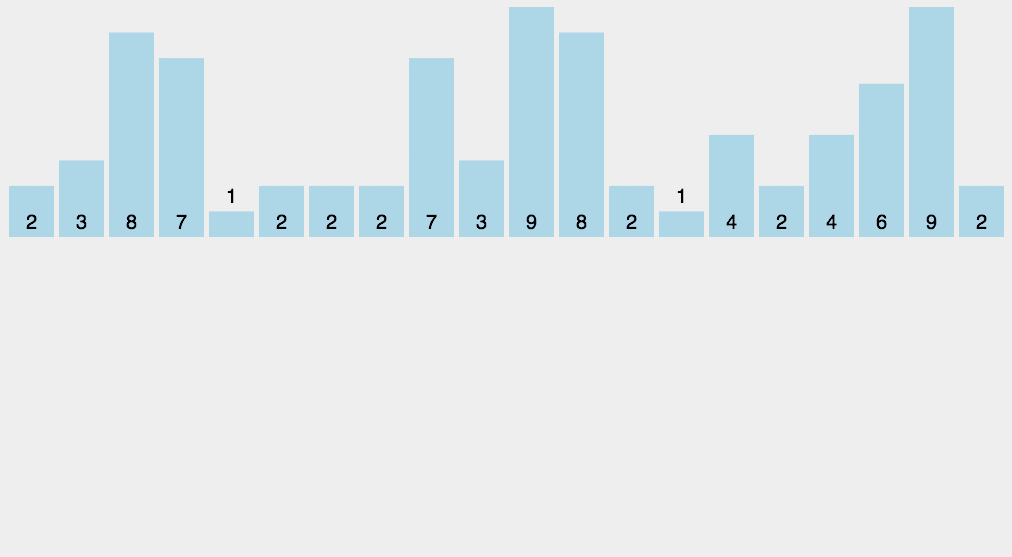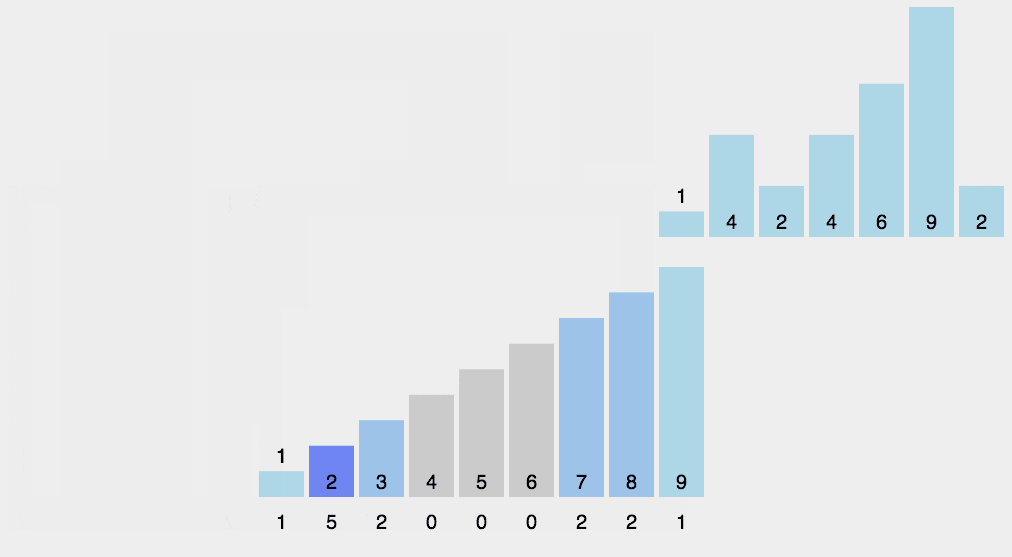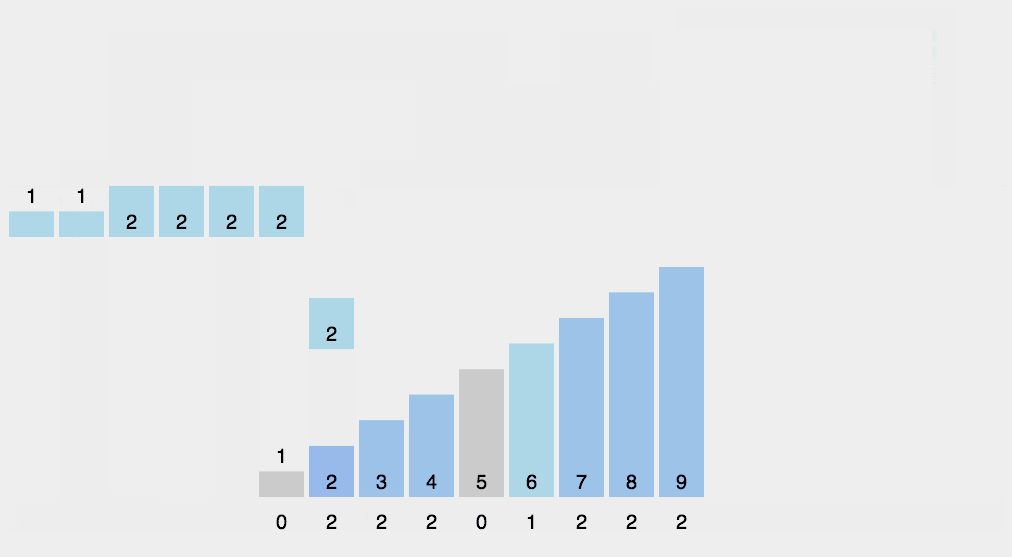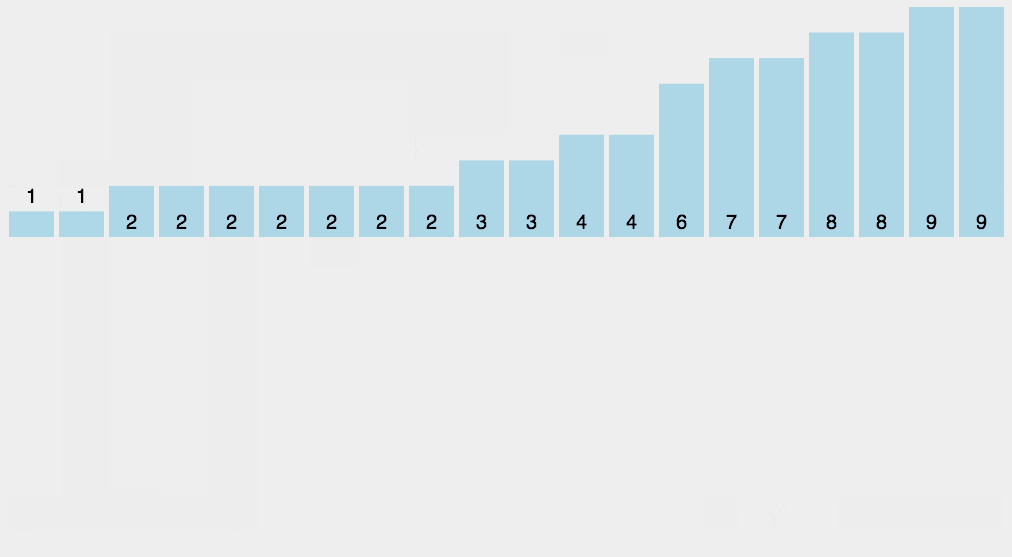
请添加图片描述
2、代码实现
按照我们前面的思路来实现 代码如下:
// 计数排序实现函数
// a: 待排序的整数数组首地址,n: 数组元素个数
// 时间复杂度: O(N+range)(N是数组长度,range是元素取值范围)
// 适用场景:仅适合整数排序,且元素取值范围相对集中(避免range过大导致空间浪费)
// 空间复杂度:O(range)(主要消耗在计数数组上)
void CountSort(int* a, int n)
{
// 第一步:找出数组中的最小值和最大值,确定取值范围
int min = a[0], max = a[0];
for (int i = 1; i < n; i++)
{
if (a[i] < min)
min = a[i]; // 更新最小值
if (a[i] > max)
max = a[i]; // 更新最大值
}
// 计算元素的取值范围长度(max - min + 1),用于确定计数数组大小
int range = max - min + 1;
//printf("%d\n", range); // 调试用:打印取值范围长度
// 第二步:创建计数数组并初始化为0(calloc会自动初始化,避免脏数据)
int* count = (int*)calloc(range, sizeof(int));
if (count == NULL) // 内存开辟失败处理
{
perror("calloc fail"); // 打印错误信息
return;
}
// 第三步:统计原数组中每个元素的出现次数
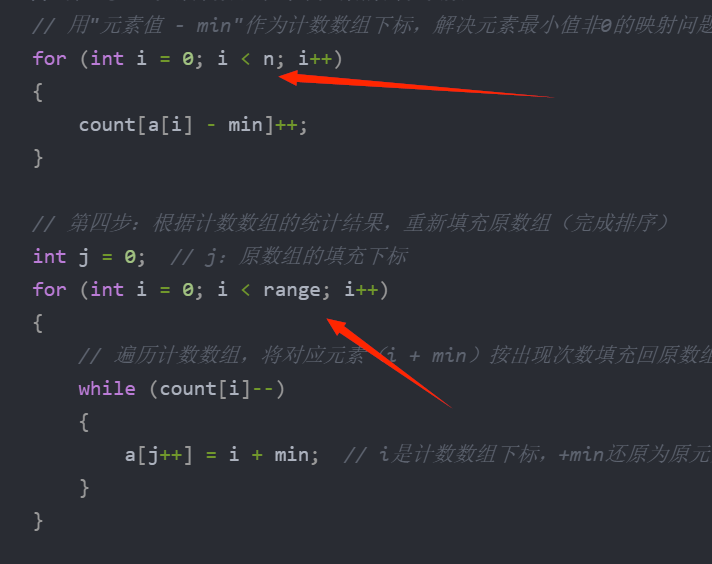
// 用"元素值 - min"作为计数数组下标,解决元素最小值非0的映射问题
for (int i = 0; i < n; i++)
{
count[a[i] - min]++;
}
// 第四步:根据计数数组的统计结果,重新填充原数组(完成排序)
int j = 0; // j:原数组的填充下标
for (int i = 0; i < range; i++)
{
// 遍历计数数组,将对应元素(i + min)按出现次数填充回原数组
while (count[i]--)
{
a[j++] = i + min; // i是计数数组下标,+min还原为原元素值
}
}
// 释放计数数组内存,避免内存泄漏
free(count);
}验证
int main()
{
int arr[] = { 2,5,3,76,9,10,32,11,2 };
PrintArray(arr, sizeof(arr) / sizeof(int));
CountSort(arr, sizeof(arr) / sizeof(int));
PrintArray(arr, sizeof(arr) / sizeof(int));
/*TestOP();*/
return 0;
}正确实现:

在这里插入图片描述
3、时间复杂度和空间复杂度
**时间复杂度为O(n+range),**如下两次循环,一会n,一会range=max-min+1
在这里插入图片描述
空间复杂度O(range) 因为额外开辟了一个元素个数为range=max-mid+1的数组
4、计数排序的特性
1. 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。 2. 时间复杂度:O(MAX(N,范围)) 3. 空间复杂度:O(范围)
5、计数排序优势和劣势
计数排序的优势
- 时间效率高:属于线性时间排序,时间复杂度为
(
是数组长度,
是元素取值范围),比比较排序的理论下界
更快。
- 实现简单:核心逻辑是“统计频次→填充结果”,代码逻辑直观,无需复杂的分治/交换操作。
计数排序的劣势
- 适用范围窄:仅能排序整数(或可映射为连续整数的类型),无法直接排序浮点数、字符串等非整数类型。
- 空间依赖取值范围:若元素取值范围
过大(比如数组是 [1, 100000]),会开辟超大的计数数组,造成严重空间浪费,空间复杂度会退化为
甚至不可用。
- 不适合分散取值:若元素取值分散(比如数组是
[1, 10000,10,23,50000]),
会被拉得很大,空间和效率都会大幅下降。
6、排序对比
#include"Sort.h"
void TestOP()
{
srand(time(0));
const int N = 100000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
int* a7 = (int*)malloc(sizeof(int) * N);
int* a8 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
// Öظ´²»¶à
a1[i] = rand() + i;
// Öظ´½Ï¶à
//a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
a8[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
//PrintArray(a2, N);
int begin3 = clock();
SelectSort(a3, N);
int end3 = clock();
int begin4 = clock();
HeapSort(a4, N);
int end4 = clock();
int begin5 = clock();
QuickSort(a5, 0, N - 1);
int end5 = clock();
int begin6 = clock();
MergeSort(a6, N);
int end6 = clock();
int begin7 = clock();
BubbleSort(a7, N);
int end7 = clock();
int begin8 = clock();
CountSort(a7, N);
int end8 = clock();
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
printf("BubbleSort:%d\n", end7 - begin7);
printf("CountSort:%d\n", end8 - begin8);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
free(a7);
}
int main()
{
/*int arr[] = { 2,5,3,76,9,10,32,11,2 };
PrintArray(arr, sizeof(arr) / sizeof(int));
CountSort(arr, sizeof(arr) / sizeof(int));
PrintArray(arr, sizeof(arr) / sizeof(int));*/
TestOP();
return 0;
}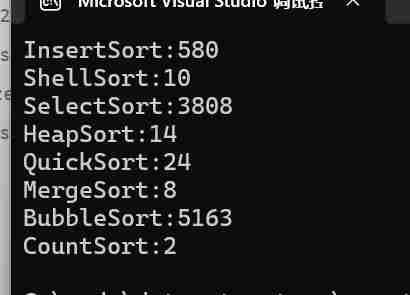
请添加图片描述
可以看出计数排序秒杀其他排序,可能不明显 我们换成release,再把冒泡排序和直接选择排序去掉,把数据改为1000万,再来看
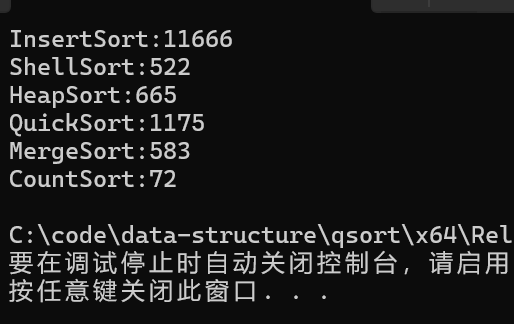
在这里插入图片描述
可以看出计数排序秒杀其他排序,但因为他只能排整数且最好是数据集中的最好导致它没有其他排序应用广泛,但是它的速度是真的快
九、排序算法复杂度和稳定性分析
这里主要讲一下空间复杂度和稳定性,时间复杂度在介绍每种排序时都已经说明了 先说明一下稳定性概念
1、算法稳定性核心概念:
概念: 当待排序数组中存在多个值相等的元素时,若排序后这些元素的相对位置与排序前保持一致,则称该排序算法是“稳定的”;反之则是“不稳定的”。
举个例子:
原数组为 [2₁, 3, 2₂](下标₁、₂区分两个值为2的元素):
- 若排序后结果是
[2₁, 2₂, 3](两个2的相对顺序未变),则算法稳定; - 若排序后结果是
[2₂, 2₁, 3](两个2的相对顺序改变),则算法不稳定。
稳定性的实际意义: 在多关键字排序场景(比如先按“成绩”排序,再按“姓名”排序)中,稳定排序可以保留前一次排序的结果,避免重复处理。
2、各类算法空间复杂度和稳定性分析
(1)空间复杂度分析
- 直接插入排序、希尔排序、直接选择排序、堆排序、冒泡排序都没有开辟新的空间来利用,所以他们的空间复杂度都为O(1)
- 快速排序的空间复杂度取决于递归栈的深度,最好logn,最坏n,但是我们采用了三数取中和小区间优化,所以空间复杂度为O(logn)
- 归并排序新开了一个数组进行利用,所以空间复杂度为O(n)
(2)稳定性分析
- 直接插入排序:稳定
直接插入排序的逻辑是“将当前元素插入到前面已排序序列的合适位置”。当遇到与当前元素值相等的元素时,会将当前元素插入到相等元素的后方(而非前方),不会改变这些相等元素的相对位置。
例如原数组
[2₁, 3, 2₂](下标区分两个2),插入2₂时,会放到3的前面、2₁的后面,最终结果为[2₁, 2₂, 3],相对顺序保持不变。 - 希尔排序:不稳定
希尔排序是“分组版直接插入排序”,会先将数组按增量分成多个子组,对子组单独排序。分组过程会打乱相等元素的分布——相同值的元素可能被分到不同子组,排序后这些元素的相对位置会被破坏。
例如原数组
[3, 2, 3₁],若增量为2,会分成[3, 3₁]和[2]两个子组;子组排序后合并,可能得到[3₁, 2, 3],原本的3与3₁顺序被打乱。 - 直接选择排序:不稳定
直接选择排序的逻辑是“每轮找当前范围的最小值,与当前轮次的起始位置交换”。若当前起始位置是一个相等元素,交换操作会将最小值放到此处,从而打乱相等元素的相对位置。
例如原数组
[2₁, 2₂, 1],第一轮找到最小值1,与第一个位置的2₁交换,结果变为[1, 2₂, 2₁]——原本的2₁(在前)与2₂(在后)的顺序被反转。 - 堆排序:不稳定 堆排序的核心是“堆调整(上浮/下沉)”,调整过程中会跨位置交换元素(如父节点与子节点交换)。这种跨位置交换会破坏相等元素的相对顺序。 例如:数组中全为相同元素,一旦排序相当于全换了
- 冒泡排序:稳定
冒泡排序的逻辑是“相邻元素两两比较,若后面元素更小则交换”。当遇到相等元素时,不会执行交换操作,因此相等元素的相对位置会保持排序前的状态。
例如原数组
[2₁, 3, 2₂],冒泡过程中,2₁与3不交换,3与2₂交换,最终结果为[2₁, 2₂, 3],相对顺序不变。 - 快速排序:不稳定
快速排序的核心是“选基准、划分数组(将小于基准的放左,大于的放右)”。划分过程中,基准元素会与后面的元素交换,若存在与基准相等的元素,交换操作会打乱这些相等元素的相对位置。
例如原数组
[3, 2, 3₁, 1],选3为基准,划分时会将后面的1与基准交换,结果变为[1, 2, 3₁, 3]——原本的3(在前)与3₁(在后)的顺序被反转。 - 归并排序:稳定
归并排序的核心是“合并两个有序子数组”。合并时,若两个子数组中出现相等元素,会先将前一个子数组的元素放入临时数组,从而保留了这些相等元素的相对顺序。
例如两个有序子数组
[2₁, 3]和[2₂, 4],合并时会先取2₁,再取2₂,最终结果为[2₁, 2₂, 3, 4],相对顺序保持不变。
(3)图表表示
根据上面的描述,我们做一下总结
排序方法 | 时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|
直接插入排序 | O ( N 2 ) O(N²) O(N2) | O ( 1 ) O(1) O(1) | 稳定 |
希尔排序 | O ( N 1.3 ) O(N^{1.3}) O(N1.3) | O ( 1 ) O(1) O(1) | 不稳定 |
直接选择排序 | O ( N 2 ) O(N²) O(N2) | O ( 1 ) O(1) O(1) | 不稳定 |
堆排序 | O ( N log N ) O(N\log N) O(NlogN) | O ( 1 ) O(1) O(1) | 不稳定 |
冒泡排序 | O ( N 2 ) O(N²) O(N2) | O ( 1 ) O(1) O(1) | 稳定 |
快速排序 | O ( N log N ) O(N\log N) O(NlogN) | O ( log N ) O(\log N) O(logN) | 不稳定 |
归并排序 | O ( N log N ) O(N\log N) O(NlogN) | O ( N ) O(N) O(N) | 稳定 |
稳定希尔排序
不稳定直接选择排序
不稳定堆排序
不稳定冒泡排序
稳定快速排序
不稳定归并排序
稳定

在这里插入图片描述
十、补充
上面没有添加计数排序的稳定性分析,因为我们在这里实现的计数排序不是标准的计数排序,标准的排序是稳定的,本篇计数排序属于简易版计数排序,不具有稳定性。
但标准计数排序涉及到前缀和算法,这里就不做讲解啦!但是我后面会在算法专栏中分享的,大家如果感兴趣,可以看一下下面标准计数排序的步骤:

在这里插入图片描述
简易版与标准的区别:标准计数排序的核心差异在于前缀和计算与倒序遍历填充,这两步是实现稳定性的关键,也是区分简化版与标准版的核心特征。
十一、结束语
好啦(◕ᴗ◕✿)!这一篇的内容就到这里收尾咯~ ,咱们的初阶数据结构与算法专栏到这就彻底完结啦!不过后续我会加一些“加餐内容”,大家可以根据自己的节奏选择性学习~ 下一篇咱们就正式踏入C++的学习领域啦!超级感谢大家这段时间的支持~ 一起冲进C++的世界探索吧!相信这段时间的学习,大家都攒了不少收获~
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-11-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号