【C++初阶】1.类和对象 两万字深度拆解,手把手带你入门C++

【C++初阶】1.类和对象 两万字深度拆解,手把手带你入门C++

用户11952558
发布于 2026-01-09 14:06:19
发布于 2026-01-09 14:06:19
前言
众所周知,C加加难学,这主要是因为其陡峭的学习曲线。本篇是C加加的第一篇,讲解C加加的第一个知识点:类和对象。而这个知识点难度就是比较大的。我们将尽量使用好懂的语言以及逻辑衔接去讲解它
一、引用
理解
给对象取别名
特征
必须初始化
例如:int& a; 这样的写法是错误的,引用必须在定义时初始化。
可以给别名取别名
int a = 1;
int& ra = a;
int& rra = ra;一旦引用,不可引用其它的实体
int a = 20;
int b = 10;
int& ra = a;
ra = b;可能有同学认为引用本质是指针,就以为引用对象可以改。
但如上代码不是改ra引用对象为b,而是给本尊重新赋值。
由此,引用可以看作取小名,一个人可以有多个小名、外号,但人始终只有一个。
引用作用(在这里仅供了解,以后会深入)
- 传参,做返回值
- 传引用返回,传值返回
void func1(int& x); // 传引用
int& func2(int x); // 返回引用若x较大可以提升效率。
此外,有意思的是,引用做返回值可以直接修改本尊:
int arr[20];
int& func()
{
return arr[2];
}
int main()
{
func() = 3; // 直接修改数组
cout << arr[2]; // 输出3
return 0;
}如图,直接修改数组

因此,就能引出一个问题:引用返回这么好用,以后全用引用返回不就好了?
显然,答案是否定的。
将上面的代码arr定义成局部再来看看:
int& func()
{
int arr[20]; // 局部数组
return arr[2]; // 返回局部变量的引用
}
int main()
{
int a = func();
cout << a; // 打印出了随机值
return 0;
}由于函数栈帧在结束后会被销毁,因此也变成了随机值。

const引用
既然我们研究了变量a的引用,那就更进一步去研究常数的引用吧:
int main()
{
int& rc = 10; // 报错
return 0;
}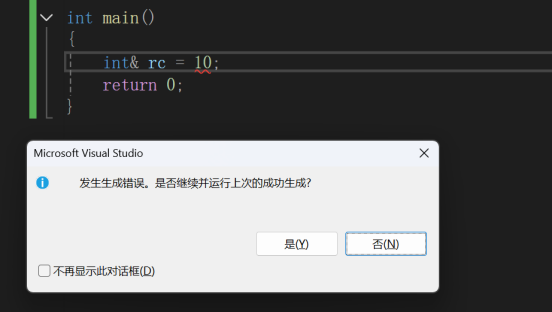
报错了,这就关系到权限的问题了。
10为常数,引用只能用常数(const)引用
const int& rc = 10; // 正确权限只可缩小,不可放大:
int a = 10;
const int& ra = a; // 权限缩小
ra++; // 会报错
int& rra = a; // 权限一致
rra++; // 则不会同时,对表达式(a+b)的引用呢?
int a = 1;
int b = 2;
int& r = (a + b); // 神奇的报错又来了接着报错
我们回顾一下临时对象,由于表达式会创造出一个临时对象,而临时对象有常性,因此必须加const:
int a = 1;
int b = 2;
const int& r = (a + b); // 这下就能过了同时,更进一步,隐式类型转换也是有常性的,也要加const:
double a = 3.14;
const int& ra = a; // 正确但是注意,再转一次还是要加const的:
double a = 3.14;
const int& ra = a;
const double& rra = ra; // double& rra = ra; 是错的因此,const引用可以让传参更加广泛。
引用与指针的区别
首先,两者本质都是指针。在编译下,两者语句一模一样。

区别:
引用不开空间,指针开空间
指针可以空,引用不能
int* p = NULL;
int& rp = *p; // 这样的代码会崩溃
rp++;因此,有"野指针",但很少有"野引用"
sizeof语句返回值不同
int a = 1;
int* pa = &a;
int& ra = a;
cout << sizeof(pa) << endl; // 在64位下为8
cout << sizeof(ra) << endl; // 输出4(int的大小)引用对象不可变,参考上文
引用可以直接访问,指针要解引用
二、Inline 内联
在开始讲之前,先回顾一下C的宏:
#define ADD(a, b) ((a) + (b))有没有最后的分号?外大括号?内大括号?为什么这样?
在C++中,内联可以代替宏:
inline int Add(int a, int b)
{
return a + b;
}作用与宏类似,在使用时展开,让效率更高,但实则智能得多。
特征
- debug默认不展开 这也意味着可以对其进行调试。
- 是否展开取决于编译器
做个计算:
- 一个100行的语句被调用10000次
- 全部展开,会是100 * 10000条
- 不展开,会是100 + 10000条
全部展开会让程序臃肿。
- 注意声明定义要放在一个文件中,否则会报错
三、nullptr (C++11)
简单说,就是C++版本的空指针。
但,C语言就有NULL了,为什么要新弄一个新的关键字nullptr呢?
NULL的本质:一个定义为0的宏
如何验证?
void func(int a)
{
cout << "is a number" << endl;
}
void func(int* a)
{
cout << "is a point" << endl;
}
int main()
{
func(1);
func(NULL); // 输出 "is a number"
return 0;
}输出:

由于C++会往最适合的函数跑,因此编译器直接将NULL认成一个数了。
加上这个语句,则会输出正确的 "point"
func(nullptr); // 加上这个语句,则会输出正确的 "point"类型安全
此外,在C++中:
void* p1 = NULL;
int* p2 = p1; // 以上语句是没法过的以上语句是没法过的
由于为了类型安全不能这么转,如果允许隐式转换,可能会导致类型错误不被发现。
但C语言是没问题的。
nullptr可以转除int的指针,提供更好的类型安全性。
四、类初步
class
与struct差不多,都是将一类东西聚集在一起,包括成员变量与成员函数。
访问限定符
-
public、private、protected - 限定范围:两个限定符之间
- 默认私有(
struct默认公有)
命名规范
- 默认成员变量前面加
_
类的优势
- 类可做隔离,因此
stack与queue的size()接口不会冲突 - 类名可代表类型
struct node
{
int val;
node* next; // 可以直接node*,不用typedef
};可以直接node*,不用typedef
五、内存占用
内存对齐规则
- 第一个成员放在0偏移
- 之后元素放在对齐数整数倍位置
- 对齐数 = min(默认值,成员大小)
为什么要对齐?(不严谨解释)
CPU不是从任意位置开始读,从固定整数开始,可以减少读取次数。可以理解为空间换时间。
示例分析
struct node1
{
char ch;
int val;
};因此,这个结构体大小为8。
那这些呢?
struct node2
{
void print()
{
cout << 1 << endl;
}
};
struct node3
{
// 空类
};大小分别为1,1

无成员变量大小为1字节占位,这是为了确保每个对象在内存中都有唯一的地址。
六、实例化
这是一个简单的叫做日期的类:
cpp
class date {
public:
void Init(int year, int month, int day) {
_year = year;
_month = month;
_day = day;
}
void print() {
cout << _year << _month << _day;
}
private:
int _year;
int _month;
int _day;
};通过这个类,可以构造出d1,d2等等对象。
因此,可以把它类比为蓝图,用同一个蓝图可以造很多房子。这个过程叫做实例化。
不同的对象中,成员变量是不同的,但成员函数是相同的,难道相同的函数还复制几份吗?
当然不会,那不同的对象如何正确调用同一个函数呢?
因此就要用特殊的指针。
七、this指针
拿date这个类来说,其实,编译器在我们看不到的地方至少做了三处努力:
原代码:
class date {
public:
void Init(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
void print()
{
cout << _year << _month << _day;
}
private:
int _year;
int _month;
int _day;
};
int main() {
date d1;
date d2;
d1.Init(2025, 10, 29);
d1.print();
return 0;
}编译器实际处理:
-
void print();→void print(date* const this); -
cout << _year << _month << _day;→cout << this->_year << this->_month << this->_day; -
d1.Init(2025, 10, 29);→d1.Init(&d1, 2025, 10, 29);
这样,通过这些指针的引导,编译器就知道你要对哪个对象进行操作了。
this指针存在:栈区
空指针调用成员函数的特殊情况
再来看一段代码:
class A {
public:
void print() {
cout << "OK" << endl;
}
};
int main() {
A* p = nullptr;
p->print(); // 虽然使用了空指针,但是会完美运行
return 0;
}虽然使用了空指针,但是会完美运行
分析一下代码,相当于将空指针赋给this指针,但this只起到路人的作用,真正的主角是print函数,空指针没解引用就没事。
但是,以下代码会崩溃:
class A {
public:
void print() {
cout << "OK" << endl;
cout << _a << endl; // 这里会解引用空指针
}
private:
int _a;
};
int main() {
A* p = nullptr;
p->print(); // 崩溃
return 0;
}可以理解为解引用了空指针。
总之,由于成员变量设成私有后,只可通过成员函数访问,更加规范。
八、类的默认成员函数
1. 构造函数
- 会自动调用
- 与类名相同
- 无返回值
无参构造:
date()
{
_year = 2025;
_month = 10;
_day = 30;
}带参构造:
date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}全缺省:
date(int year = 1, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}编译器自动生成:
其中,默认构造函数包括:无参构造、全缺省、编译器自动生成构造。
注意:不可两个默认构造函数在一起。
类型分为内置类型与自定义类型:
- 编译器生成的构造函数对内置类型没有统一标准
- 自定义类型会调用默认构造
因此,不要指望编译器帮忙构造,要能写尽写。
2. 析构函数
- 对象的资源清理工作
- 生命周期结束会自动调用
- 后定义的先析构
-
写法:~加类名
date d1(2025, 10, 30);
date d2(2025, 10, 31);如图:d1的this指针:0x000000114e15f698
d2的this指针:0x000000114e15f6c8
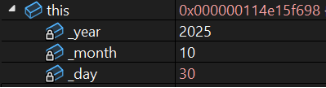
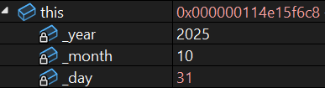
d1先构造,指针小,后析构。
示例:
class point {
public:
point()
{
p = new int(3); // 动态分配内存
}
~point()
{
delete p; // 释放内存
}
private:
int* p;
};
int main()
{
point p1;
return 0;
}由于在实例化、生命周期结束分别会自动调用构造、析构,因此不用Init、Destroy,方便了使用。
3. 拷贝构造(一种特殊构造函数)
形式:
date(const date& d) {
_day = d._day;
_month = d._month;
_year = d._year;
}第一个参数必须是自身类型的引用,后面可以跟缺省元素,但没必要。
1. 为什么必须引用?
date(const date d) { // 错误写法
_day = d._day;
_month = d._month;
_year = d._year;
}如果我们这样写,编译器会直接报错。
首先,C++规定传值传参时会拷贝构造:
void func(date d) { // 这里会调用拷贝构造
d.print();
}如图,以上函数调试时会先跳到date的拷贝构造函数

每次拷贝构造时就要传参,传参再开始新的拷贝构造......无限循环,函数直接无穷递归。
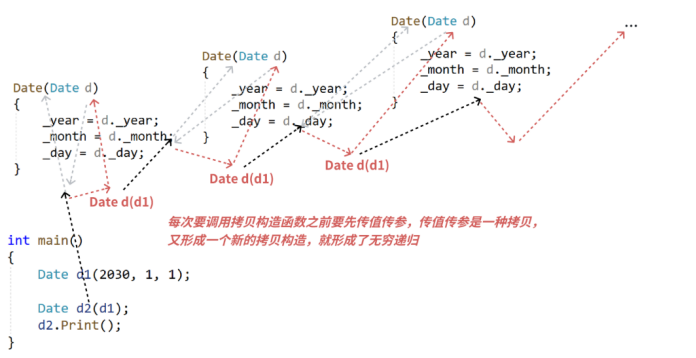
无穷递归简图
2. 为什么要尽量加const
先看到一个经常性的小错误:
date(date& d) {
if(d._day = _day) { // 误写为赋值,应该是==
// ...
}
// _day = d._day; // 这行被注释了
_month = d._month;
_year = d._year;
}当if写错变成赋值时,拷贝之后就会是随机值。若加了const,则会直接报错,杜绝这种情况发生。
3.同时,C语言函数传结构体时也会进行浅拷贝。
若没写拷贝构造,则编译器会自动生成,对内置类型浅拷贝(类似于memcpy),自定义类型调用自己拷贝构造。
由于date内部都为整型,因此浅拷贝没问题,编译器自己生成的拷贝构造够用。
深浅拷贝问题(以后会深入讲解)
比如,看到下面一个简易字符串类,如果不写拷贝构造函数,用浅拷贝:
class String {
public:
String(const char* ch = " ")
{
_length = strlen(ch);
_data = new char[_length + 1];
strcpy(_data, ch);
}
/* 注释掉的拷贝构造
String(const String& s2) {
_length = s2._length;
_data = new char[_length + 1];
strcpy(_data, s2._data);
}
*/
~String() {
delete[] _data;
}
private:
char* _data;
int _length;
};
int main() {
String s1 = "wer";
String s2(s1); // 浅拷贝,两个对象指向同一块内存
return 0; // 析构时同一内存被释放两次,崩溃
}如下图,编译器会直接崩溃

我们调试,观察步骤:
-
String s1 = "wer";调用构造函数 -
String s2(s1);自动浅拷贝(两个数组地址一模一样) -
return 0;析构s2,但由于s2和s1实际上指向同一个内存,因此s1和s2都变成乱码

- 析构
s1,但已经析构一遍了,因此崩溃

而当我们写了拷贝构造,s1和s2虽然内容一样,但是地址是不同的,因此不会再一个地方析构两次。
自定义类型的自动管理
那既然编译器对自定义类型会自动调用构造、析构函数,那么对于下面的类,是否就不用写构造、析构函数呢?
class Pair {
String sa;
String sb;
};没错,调试时,发现会调用String构造函数2次,析构函数2次,获得了极大的便利。


再来看到以下代码
String fun1()
{
String s1;
return s1;
}
int main()
{
String s2 = fun1();
return 0;
}同时,再加入函数调用后,我们发现两个对象地址一样,说明也是浅拷贝


我们可以借用指针理解
- 在fun1里构造了s1对象
- fun1结束s1析构,返回空对象
- 空赋给s2
解决这个只需在s1前加一个static变成静态即可,此外,也可以以引用返回String& fun1()
区别于函数重载:函数重载是函数同名选用合适的,但两个运算符重载会构成函数重载
因此,我们就需要让=号发挥新的用处,让String s2 = fun1();也可以完成深拷贝,这就涉及到下面的赋值运算符重载了。
九、赋值运算符重载(赋值重载拷贝)
基础版
void operator=(date d) {
_year = d._year;
_month = d._month;
_day = d._day;
}由于这个函数与拷贝构造没有半毛钱关系,因此不加引用不会无限递归。但建议用引用优化。
进阶版
void operator=(const date& d) {
_year = d._year;
_month = d._month;
_day = d._day;
}但是由于赋值是可以这样 d1 = d2 = d3; 连续赋值的,为实现这个,我们可以先拆开请求:
d1 = (d2 = d3);
1.先完成d2和d3的赋值
2.再完成d1与括号的赋值。
因此我们可以返回this指针以链式赋值(在之后的流重载会更加深入讲到)。
最终版
date& operator=(const date& d) {
_year = d._year;
_month = d._month;
_day = d._day;
return *this;
}拷贝构造 vs 赋值重载拷贝
但是拷贝构造和赋值重载拷贝都有=,可能会弄混,以下是它们的区别:
拷贝构造是无中生有,而赋值重载拷贝是改变
简单说,只有先被创造才能赋值重载拷贝。
date d1(2025, 11, 3);
date d2(d1); // 拷贝构造
date d3;
d1 = d2 = d3; // 赋值重载拷贝时机不同
拷贝构造自动开始时调用,赋值重载拷贝要手动调用。
相同点: 不写都会自动浅拷贝。
与指针区别
date* operator=(const date& d) {
_year = d._year;
_month = d._month;
_day = d._day;
return this;
}并且需要这样调用:d1 = *(d2 = d3);
因此,指针可以,但是过于繁琐。
到这里篇幅已经太长了,在后文我们会了解另外一种特殊的构造函数。
十、运算符重载
当我们要比较上文的日期类是否相等该怎么做?显然,直接d1 == d2是不可行的。
因为我们的编译器不是deepseek
上文我们介绍了=的赋值重载,那么可以再重载一次=号让它可以判断日期相等吗
因此,我们就可以如下,写一个重载==的函数。
写法: 返回值,operator,运算符,参数
class date {
public:
date(int year = 1, int month = 1, int day = 1) {
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};
bool operator==(date d1, date d2) {
return d1._year == d2._year && d1._month == d2._month && d1._day == d2._day;
}
int main() {
date d1(2025, 10, 30);
date d2(2025, 10, 31);
if (d1 == d2) {
cout << "same" << endl;
} else {
cout << "not same" << endl;
}
return 0;
}然而,这么写会报错,因为_year等元素为私有,无法在外部直接访问。
解决方法
- 将
private注释掉,变成公有 不过这个方法长远来看不可行。 - 变成友元函数(这个下文会讲)
- 写一个专门的
get函数,做中转站,向私有拿数据
class date {
public:
date(int year = 1, int month = 1, int day = 1) {
_year = year;
_month = month;
_day = day;
}
int gyear() { return _year; }
int gmonth() { return _month; }
int gday() { return _day; }
private:
int _year;
int _month;
int _day;
};
bool operator==(date d1, date d2) {
return d1.gyear() == d2.gyear() && d1.gmonth() == d2.gmonth() && d1.gday() == d2.gday();
}成员函数形式的运算符重载
那既然这样,为何不直接把==的重载放到类中变成成员函数?
对于二元运算符,有专门写法:
class date {
public:
date(int year = 1, int month = 1, int day = 1) {
_year = year;
_month = month;
_day = day;
}
bool operator==(date d2) {
return _year == d2._year && _month == d2._month && _day == d2._day;
}
private:
int _year;
int _month;
int _day;
};第一个参数默认传this指针,调用时可以写成d1.operator==(d2);也可以简单写成d1 == d2。
重载的特征
- 类类型自动调用重载,没重载会报错
- 优先级、结合性与默认一致
- 不能创建新运算符
-
.*等运算符不能重载 - 至少有一个类类型参数w
十一、日期类的运算符重载实现
构造
date::date(int year, int month, int day) {
_year = year;
_month = month;
_day = day;
}由于日期类可以直接浅拷贝,因此不用写拷贝构造、赋值运算符重载。
打印
cpp
void date::print() {
cout << _year << _month << _day << endl;
}运算重载
+= 重载
cpp
date& date::operator+=(int day) {
_day += day;
while (_day > Getmonthday(_year, _month)) {
_day -= Getmonthday(_year, _month);
++_month;
if (_month == 13) {
_year++;
_month = 1;
}
}
return *this;
}+ 重载
cpp
date date::operator+(int day) {
date tmp = *this;
tmp += day;
return tmp;
}+=为自增,不用新开变量,因此引用返回没问题。
而+为赋值,需要新实例化date并返回,不能引用返回,否则新开的tmp会销毁导致悬空引用。
可以看到,我们+调用了+=,那能不能+=复用+呢?
由于+会有两次拷贝,如果+=复用+,那么+=会平白多出两次拷贝。
- 和 -= 同理
cpp
date& date::operator-=(int day) {
_day -= day;
while (_day <= 0) {
_month--;
if (_month == 0) {
_month = 12;
_year--;
}
_day += Getmonthday(_year, _month);
}
return *this;
}
date date::operator-(int day) {
date tmp = *this;
tmp -= day;
return tmp;
}+= 重载的升级
由于可能会写 date d2 = d1 + -20;,+号后面为负,这样一来就会出错。
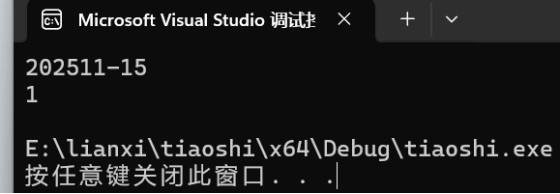
因此,在+=重载里,需要判断,并调用-=的重载:
date& date::operator+=(int day) {
if (day < 0) {
return *this -= (-day);
}
_day += day;
while (_day > Getmonthday(_year, _month)) {
_day -= Getmonthday(_year, _month);
++_month;
if (_month == 13) {
_year++;
_month = 1;
}
}
return *this;
}这样就好了。
前置、后置 ++
由于两个++都为一元运算符,直接写无法区分,因此,规定后置++括号里有个int。
date date::operator++(int) { // 后置
date tmp = *this;
*this += 1;
return tmp;
}
date& date::operator++() { // 前置
*this += 1;
return *this;
}由于后置++先使用,后++,因此就要先把数给拷贝一份返回,再给本尊++,并且和之前+的重载同理,调用完后会自动析构,因此不能传引用。
后置++会比前置多两次拷贝,前置++效率更高。
日期相减
int date::operator-(const date& d1) {
int ret = 0;
date ma = *this;
date mi = d1;
int flag = 1;
if (ma < mi) {
ma = d1;
mi = *this;
flag = -1;
}
while (mi != ma) {
++mi;
ret++;
}
return ret * flag;
}由于日期间相隔天数不会很多,因此直接加加,一直到小日期与大日期相等即可。
比较重载
bool date::operator<(const date& d) {
if (_year < d._year) return true;
else if (_year == d._year) {
if (_month < d._month) return true;
else if (_month == d._month) {
return _day < d._day;
}
}
return false;
}
bool date::operator==(const date& d) {
return _year == d._year && _month == d._month && _day == d._day;
}
bool date::operator<=(const date& d) {
return *this < d || *this == d;
}
bool date::operator>(const date& d) {
return !(*this <= d);
}
bool date::operator>=(const date& d) {
return !(*this < d);
}
bool date::operator!=(const date& d) {
return !(*this == d);
}由于<、==就可以组合出不同比较运算,因此只用写这两个,其它复用即可。
十二、流运算的重载
cout << d1 << endl; 显然,这么写,编译器读不懂你的意思,因此就需要重载流运算。
初步实现
ostream是输出流类:
void date::operator<<(ostream& out) {
out << _year << _month << _day;
}cout << d1; 这么写的情况下,编译器会报错:二元<<没有找到接受date类型的右操作数的运算符。
由于运算符重载要求一一对应,因此这么写就意味着前面是this指针(d1),后面是重载的输出流,因此只能写成 d1 << cout; 才可输出。
而显然,这样子是不合理的。要做到左边cout,右边对象。
但是,由于在类里面,重载符号,左边已经默认传this指针了,因此我们现阶段无法在类中做到左cout右对象的重载。
进阶版:全局函数
那怎么办?那就直接定义成全局:
void operator<<(ostream& out, const date& d) {
out << d._year << d._month << d._day;
}同时,由于外部函数无法直接访问私有,因此我们遇到了上文一样的问题:
- 将
private注释掉,变成公有(不可行) - 变成友元函数
- 写专门的
get函数(太麻烦)
上文我们讲了1,3点,然而不是太麻烦就是不可行,接下来我们着重讲解友元函数
友元函数解决方案
在类中,将外部函数设成友元函数,将外部函数变成朋友,就可以访问:
class date {
friend void operator<<(ostream& out, const date& d);
// ...
};这样<<重载就可以读到class里的私有元素了。
最终版:支持链式输出
但是,这个写法依旧有缺陷:cout << d1 << d2; 在这个代码中,它无法像链条一样连续读取多个数字。
由于<<运算符是向前结合的,因此实际上是 (cout << d1) << d2; 只需要在(cout << d1)中返回cout,就可以连续读取了。
ostream& operator<<(ostream& out, const date& d) {
out << d._year << "-" << d._month << "-" << d._day << endl;
return out;
}输入流重载
同理,>>重载:
istream& operator>>(istream& in, date& d) {
in >> d._year >> d._month >> d._day;
return in;
}但注意,由于输入流会改变d的值,因此不能加const。
添加日期合法性检查
由于要判断日期合法性,因此添加判断函数:
bool date::CheckDate() {
if (_month < 1 || _month > 12 || _day < 1 || _day > Getmonthday(_year, _month)) {
return false;
} else {
return true;
}
}并修改>>重载,读到合法日期为止:
istream& operator>>(istream& in, date& d) {
while (1) {
in >> d._year >> d._month >> d._day;
if (!d.CheckDate()) {
cout << "wrong date:";
d.print();
} else break;
}
return in;
}十三、取地址运算符重载
如图,我们取d1的地址,我们并未写取地址运算符的重载,编译器依旧可以成功取地址,并且自动生成的够用。
因此一般情况下不写:
date* operator&() {
return this;
}
const date* operator&() const {
return this;
}整蛊妙招
如果我们不想让别人取到正确地址,就可以重载,返回错误地址:
date* operator&() {
return (date*)0x25434F53; // 返回假地址
// return this;
}
const date* operator&() const {
return (date*)0x25434F53; // 返回假地址
// return this;
}十四、类声明注意
由于在class中定义的函数默认内联,因此将经常调用的、较短的函数放入提高效率。
以下就是日期类的声明
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<vector>
#include<algorithm>
#include<stack>
#include<queue>
using namespace std;
class date {
friend ostream& operator<<(ostream& out, const date& d);
friend istream& operator>>(istream& in, date& d);
public:
date(int year = 2000, int month = 1, int day = 1);
void print();
int Getmonthday(int year, int month) {
static int Monthday[13] = { -1,31,28,31,30,31,30,31,31,30,31,30,31 };
if (month == 2 && ((year % 4 == 0 && year % 100 != 0) || (year % 400 == 0))) return 29;
return Monthday[month];
}
bool operator<(const date& d);
bool operator==(const date& d);
bool operator<=(const date& d);
bool operator>(const date& d);
bool operator>=(const date& d);
bool operator!=(const date& d);
date operator+(int day);
date& operator+=(int day);
date operator-(int day);
date& operator-=(int day);
date operator++(int);
date& operator++();
int operator-(const date& d1);
bool CheckDate();
// void operator<<(ostream& out);
private:
int _year;
int _month;
int _day;
};
ostream& operator<<(ostream& out, const date& d);
istream& operator>>(istream& in, date& d);十五、注意点::: 和 . 的区别
在刚刚我们的代码中一会儿用到::访问date类,一会儿又用.,可能已经晕了,它们看似相似,但实际完全不同,我们区分一下。
简单说,:: 问归属(属于哪个类),. 问能力(对象有什么)。
比如这个函数:
bool date::operator==(const date& d) {
return _year == d._year && _month == d._month && _day == d._day;
}-
::是用来告诉编译器"这个函数或变量属于哪个类",而.则是进行访问的。-
::告诉编译器==是属于date的重载 - 而
.则是访问对象
-
-
::不需要实例化,而.必须实例化- 只有实例化才可以用
.取出值
- 只有实例化才可以用
十六、const成员函数
我们上述代码还有小缺陷:
当我们写:
const date d1(2025, 3, 3);
d1.print();会报错:"void date::print(void)": 不能将"this"指针从"const date"转换为"date &"。
回顾上文讲道的:权限只可缩小不能放大。
void date::print() {
cout << _year << "-" << _month << "-" << _day << endl;
}由于print函数的this指针是date* this(严格来说是date* const this,const修饰指针本身,因为this指针不可修改),而这时&d1为const date*,会产生权限的放大。
因此,要将print变为const:
void date::print() const {
cout << _year << "-" << _month << "-" << _day << endl;
}由于权限可缩小,因此非const的对象依旧可以用这个函数打印。
因此,我们可以将所有不修改数值的函数都变为const成员函数,包括比较大小,+,-等。
十七、类型转换
前文知识回顾
为方便理解,我们先忘掉日期,回归最简单的类:
class A {
public:
A(int a = 0) {
_a = a;
}
private:
int _a;
};当我们写出 A a1 = 2; 时,编译器就完成了类型转换。
转为临时对象,再拷贝构造(编译器自动生成),但编译器可能会优化。
同理 double a = 1.2; int b = a; 也是类似的转换。
引用与类型转换
我们再来看下面的代码:
A a1 = 2;
A& aa1 = a1;
A& aa2 = 2; // 报错!看似aa1,aa2都是对一个东西的引用,但aa2的语句会报错。
回顾一下引用就知道了,临时变量有常性,数字2会转为临时变量,直接引用会权限放大,const A& aa2 = 2; 写成这样就不会了。
类型转换的实际应用
那这东西有什么用呢?我们写一个成员为A的数组的类AA:
class A {
public:
A(int a = 0) {
_a = a;
}
private:
int _a;
};
class AA {
public:
AA() {
pos = 0;
}
void push(const A& a) {
_arr[pos++] = a;
}
private:
A _arr[10];
int pos;
};其中,AA初始化时数组里的A调用A的默认构造,默认值为0。
此时,我们插入一个元素,常规写法是:
A a1 = 2;
AA aa;
aa.push(a1);确实可以,但麻烦。有了类型转换后,就可以这么写了:
AA aa;
aa.push(2); // 编译器:2转为A类型,调用默认构造函数编译器:2转为A类型,调用默认构造函数
而人则在:用简单的代码实例化一个对象。
权限问题
那回顾上文,如果将push函数的const去掉,变成这样报错的原因是否可以解释了呢?即权限放大。
void push(A& a) { // 去掉const会报错
_arr[pos++] = a;
}多参数类型转换(C++11)
我们将A类改为两个成员:
class A {
public:
A(int a = 0, int b = 0) {
_a = a;
_b = b;
}
private:
int _a;
int _b;
};AA这个类依旧可以用花括号快速插入,用列表初始化:
int main() {
A a1 = {2, 1};
AA aa;
aa.push(a1);
aa.push({2, 1}); // C++11 列表初始化
return 0;
}十八、深入构造函数
初始化列表
class form {
public:
form(int a = 1, int b = 1)
: _a(a),
_b(b)
{
cout << "form OK!";
}
private:
int _a;
int _b;
};
int main() {
form a;
return 0;
}用:开始,每个表达式用,隔开,括号里可以不写,也可以打印比如"开辟空间成功"等语句。
为什么需要初始化列表?
那既然已经有那么多种构造函数,为什么要弄这样一个东西呢?我们一步步探究:
- 初始化列表为定义的地方
- 这就意味着每个元素不能出现多次
- 有些类型只能用初始化列表
const类型
当我们用普通的构造函数初始化const类型时,由于构造函数实际上是在给对象赋值,因此会报错:
class form {
public:
form(int a = 1, int b = 1, int c) {
_a = a; // OK
_b = b; // OK
_c = c; // 错误!const对象不能赋值
}
private:
int _a;
int _b;
const int _c; // const成员
};换句话说,const对象只有一次改变值的机会,就是在定义时。而由于初始化列表本质为定义,因此可以初始化const对象:
class form {
public:
form(int a = 1, int b = 1, int c = 1)
: _a(a),
_b(b),
_c(c) // 正确:在定义时初始化
{
cout << "form OK!";
}
private:
int _a;
int _b;
const int _c;
};引用类型
与之同类的,还有引用,引用必须初始化:
class form {
public:
form(int a, int b, int& c)
: _a(a),
_b(b),
_c(c) // 引用必须在初始化列表中初始化
{
cout << "form OK!";
}
private:
int _a;
const int _b; // const成员
int& _c; // 引用成员
};
构造成功
没有默认构造的类
class D {
public:
D(int d) : _d(d) { } // 没有默认构造函数
private:
int _d;
};
class form {
public:
form(int a, int b, int& c, int d)
: _a(a),
_b(b),
_c(c),
_d(d) // 必须在初始化列表中构造
{
cout << "form OK!";
}
private:
int _a;
const int _b;
int& _c;
D _d; // 没有默认构造的类成员
};同理,进入构造函数,所有类型都应初始化完,而初始化列表则是初始化的地方。
十九、初始化列表注意事项
未完全初始化的处理
那要是列表中没有写所有的元素会怎样?
class A {
public:
A(int a = 1) : _a(a) { } // 只初始化了_a,没有初始化_b
private:
int _a;
int _b; // _b是随机值
};如图,可以看到,没报错,但元素是随机值。

声明缺省值(C++11)
因此,如果列表没有写全就可能会出问题,那有没有补救方法?
我们在private里声明变量就加入缺省值,这样,就算列表里没有写,一样能初始化:
class A {
public:
A(int a = 1) : _a(a) { } // 只显式初始化_a
private:
int _a = 1; // 缺省值
int _b = 2; // 使用缺省值初始化
};总结:初始化规则
- 每个成员都要走初始化列表
- 没在列表中:
- 有缺省值用缺省值
- 无缺省值:
- 内置类型:看编译器,玄学
- 自定义类型:默认构造,没有默认构造就报错
注意点
两种缺省值的区别
代码中虽然int a = 1和int _a = 1都叫缺省值,但两个是完全不相关的:
- 前者是构造时忘记传参数的补救措施(针对使用者)
- 后者是忘记列表写
_a这个元素的补救措施(针对作者)
class A {
public:
A(int a = 3) : _a(a) { } // 使用者缺省值
private:
int _a = 1; // 作者缺省值
};传参但列表不写
class A {
public:
A(int a = 3, int b = 4) : _a(a) { } // b依旧是随机值
private:
int _a = 1;
int _b; // 随机值
};每个构造都会走初始化列表
初始化顺序即为声明的顺序,与列表中顺序无关
初始化顺序示例
在以下代码中,A a(1); _a1,_a2值为多少?
class A {
public:
A(int a)
: _a1(a), // 看起来先初始化_a1
_a2(_a1) // 然后使用_a1初始化_a2
{ }
private:
int _a2 = 2; // 但实际先声明_a2
int _a1 = 2; // 后声明_a1
};答案: _a1 = 1, _a2 = 随机值
由于列表中_a1、_a2都有,因此缺省值变成了摆设。
先_a2拷贝_a1值(此时_a1还未初始化,随机值),再_a1初始化为a。
二十、static成员(静态成员变量)
- 在类外初始化
- 所有类共享
- 不会走初始化列表,因为存在静态区中
静态成员函数的限制
如图,由于没有this指针,因此静态成员函数不可访问非静态成员,但可以访问静态成员。

class A {
public:
static void staticFunc() {
// cout << _a << endl; // 错误:不能访问非静态成员
cout << _s << endl; // 正确:可以访问静态成员
}
private:
int _a;
static int _s;
};构造和析构顺序问题
问: 构造顺序,析构顺序?
C c; // 全局变量
int main() {
A a; // 局部变量
B b; // 局部变量
static D d; // 局部静态变量
return 0;
}构造: C A B D 析构: B A D C
-
C为全局,最先构造 -
A、B为局部,走到构造 -
D为静态,也是走到构造 - 局部变量先构造的后析构,先
B再A - 静态、全局的生命周期为整个过程,因此先
D再C
static成员的简单用法
1. 记录对象有多少个
class A {
public:
A(int n = 1) : _n(n) {
_s++; // 构造时计数+1
}
~A() {
_s--; // 析构时计数-1
}
int getnum() {
return _s;
}
private:
int _n;
static int _s; // 静态计数器
};
int A::_s = 0; // 类外初始化代码中每调用一次构造函数,静态数就会加一,析构就会减一,从而记录对象数量。
2. 用构造函数算累加(1加到10)
class A {
public:
A(int n = 1) {
_s++;
_sum += _s; // 累加
}
~A() {
_s--;
}
static void print() {
cout << _sum << endl; // 输出累加结果
}
private:
static int _s;
static int _sum;
};
int A::_s = 0;
int A::_sum = 0;
int main() {
A arr[10]; // 调用10次构造函数
A::print(); // 输出55 (1+2+...+10)
return 0;
}在创建数组arr后,调用10次构造函数,每调用一次_sum累加。
二十一、友元
1. 友元函数
前面我们写过,可以让外部函数访问私有元素。只是声明,不是成员函数。
- 可在类的任何地方声明,不受访问符限定
- 一个函数可以是多个类的友元
但是注意,多个类的友元函数要先声明前面的类,否则会报错:
friend void print(A& aa, B& bb); // B类在下面,会报错
由于B类在下面,因此要先声明,告诉编译器别急,下面有。
正确写法:
class B; // 前向声明
class A {
public:
A(int a = 1) {
_a = a;
}
friend void print(A& aa, B& bb); // 友元声明
private:
int _a;
};
class B {
public:
B(int b = 2) {
_b = b;
}
friend void print(A& aa, B& bb); // 友元声明
private:
int _b;
};
void print(A& aa, B& bb) {
cout << aa._a << " " << bb._b << endl; // 可以访问私有成员
}2. 友元类
将类B设置成A友元,B就可以访问A的元素:
class A {
public:
A(int a, int b) {
_a = a;
_b = b;
}
friend class B; // 声明B为友元类
class B { // B类定义在A内部
public:
B(int c = 1) {
_c = c;
}
void print(A& aa) {
cout << aa._a << " " << aa._b << endl; // 访问A的私有成员
}
int sum(A& aa) {
return aa._a + aa._b + _c;
}
private:
int _c;
};
private:
int _a;
int _b;
};调用方法:
int main() {
A aa(10, 20);
A::B bb(30); // B是A的内部类
bb.print(aa);
cout << bb.sum(aa) << endl; // 输出60
return 0;
}那A的大小是多少呢?用sizeof(A);打印,可以看到,A中虽然涉及三个int变量(A类2个,B类一个),但大小只有8字节,只算了A中的变量。
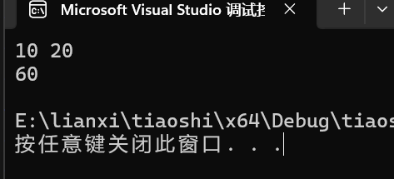
因此,友元类本质上是一个类,只是被访问限定符以及类域限定了。
二十二、匿名对象
上文我们讲了不可以用 A aa(); 来实例化,因为和函数无法区分。
但是可以这么做 A(); 构造匿名对象。
通过调试,我们可以看到,先构造,再立马析构,也就是说它的生命周期只有一行。
匿名对象的用途
那为什么要弄这样一个东西呢?
如果我们仅仅是想要调用类里面的一个函数,那么匿名对象就很方便了:
class A {
public:
A(int a = 1, int b = 1) {
_a = a;
_b = b;
}
void print() {
cout << 1 << 2 << endl;
}
~A() {
// 析构函数
}
private:
int _a;
int _b;
};
int main() {
A().print(); // 创建匿名对象并立即调用其方法
return 0;
}就好比保温杯和一次性水杯,一次性水杯主要求方便,随用随扔,而保温杯则是要求长时间,耐用,需求不同。
二十三、构造的优化(仅了解)
在上文我们讲了很多及其繁琐的构造,你烦程序也烦。显然,在这些错综复杂的关系中,一定有很多东西是没必要的。在确保正确的情况下,编译器会进行不同的优化。
接下来以vs2022为例。
测试类定义
为了方便,我们先定义一个类:
class A {
public:
A(int a1 = 1) : _a1(a1) {
cout << "普通构造" << endl;
}
A(const A& a) {
_a1 = a._a1;
cout << "拷贝构造" << endl;
}
A& operator=(const A& a) {
_a1 = a._a1;
cout << "拷贝赋值" << endl;
return *this;
}
~A() {
cout << "析构" << endl;
}
void print() {
cout << "a:" << _a1 << endl;
}
A& operator++() {
++_a1;
return *this;
}
private:
int _a1 = 1;
};1. 普通构造优化
A a1 = 1;本来: 构造 + 拷贝构造 实际: 构造,省略了构建临时对象
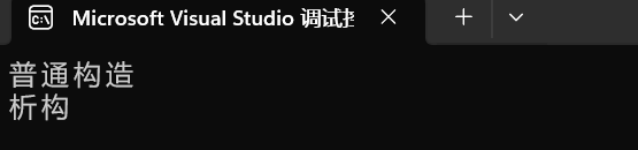
与之对应:
const A& a = 1;这个语句本来就只构造一次,让A去引用临时对象,同时增长临时对象的生命周期。

2. 传参优化
void func1(A aa) { }
A a1;
func1(a1);这次,编译器没优化: 先构造,再拷贝构造传参
func1(1);
但是,直接传一个值呢?
本来: 构造临时对象 + 拷贝构造 优化后: 一次构造,不创建临时对象
func1(A(1));那传匿名对象呢?
本来: 构造 + 拷贝构造 优化后: 一次构造

3. 传值返回优化
A func2() {
A aa;
return aa;
}
func2().print(); // 调用本来: 构造对象aa + 拷贝构造 + 构造临时对象
优化后: 构造(省去了拷贝构造,临时对象)

可以看到,已经优化2/3了。
可能想问: 这么优化不会出事吗?
对func2做点手脚:
A func2() {
A aa;
++aa; // 修改对象
return aa;
}
如图,我们可以看到,即使做了手脚,一样没出bug,编译器预判了你的预判。
A ret = func2();本来: 构造 + 拷贝构造 + 构造临时对象 + 拷贝构造 优化后: 只剩一步构造,一步到位

4. 优化的限度
但优化也会有限度:
A ret;
ret = func2(); // 写成这样可以看到,没进行任何优化。

由于ret = func2();中的=本质为运算符的重载,与构造没什么关系,打断施法,因此基本上不优化。
结语
至此,我们完成了C++面向对象编程的第一个重要里程碑——“类与对象” 的学习。
回顾整篇内容,我们从最基础的引用和内联函数起步,逐步深入到类的封装、this指针的奥秘、默认成员函数的自动调用机制,再到运算符重载让自定义类型拥有原生类型般的能力,最后探讨了构造优化等进阶话题。
这篇文章中,相信你已经体会到: C++的“难”,不在于概念本身多么晦涩,而在于它给予了我们极大的掌控力,同时也要求我们理解背后的运行机制 面向对象的核心——通过“类”这一蓝图,创造出一个个具有状态和行为的“对象”,让代码更加模块化、可复用
下一篇:我们将继续探索C++内存管理,期待再见
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-11-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号