J. Chem. Inf. Model. | QComp:基于QSAR的药物发现插补框架深度解析

J. Chem. Inf. Model. | QComp:基于QSAR的药物发现插补框架深度解析

MindDance
发布于 2026-01-08 13:00:17
发布于 2026-01-08 13:00:17
QComp: A QSAR-Based Imputation Framework for Drug Discovery
期刊: Journal of Chemical Information and Modeling 链接: https://doi.org/10.1021/acs.jcim.5c00059 代码: https://github.com/MSDLLCpapers/QComp 简介: 该论文提出了 QSAR-Complete(QComp)框架,旨在解决药物发现中 QSAR 模型难以动态整合新实验数据的问题,其创新点在于无需重新训练模型即可利用现有 QSAR 模型和新数据改进缺失数据插补。QComp 基于概率框架,将分子生物化学活性视为由结构决定的概率分布,通过多元高斯分布建模并求解最优插补。实验在 ADMET780k、公共 ADMET 及 QM8 数据集上进行,对比 MICE、MissForest 等方法,QComp 在插补准确性和稳健性上表现更优,尤其在利用体外数据插补体内测定及辅助实验决策方面效果显著。该论文证明了 QComp 是药物发现中可靠且高效的插补工具,具有广泛应用价值。

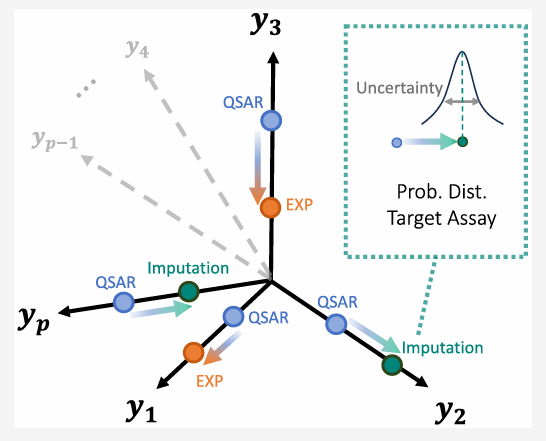
在药物发现领域,体外与体内实验产生的生物化学活性数据对评估化合物的疗效和毒性至关重要,但这些数据集往往具有海量、稀疏且不断演化的特点。定量构效关系(QSAR)模型虽能从化合物结构预测生物化学活性,却难以灵活整合不断积累的实验数据。为此,Yang等人提出了QSAR-Complete(QComp)这一插补框架,旨在解决上述挑战,本文将对其进行全面系统的解析。
一、研究背景与意义
1.1 QSAR模型的局限性
QSAR建模是数据驱动预测分子性质的重要方法,尤其在深度学习的推动下,复杂的多任务神经网络模型可模拟多种化学性质,在材料和药物发现中应用广泛。然而,在虚拟筛选之后的阶段,当部分化合物的一些化学性质已有实验数据时,QSAR模型无法动态整合这些新数据以改进预测,必须结合原始训练集和新数据进行大量重新训练。对于大型深度学习QSAR模型而言,在新数据量远小于原始训练集时,这种重新训练极不经济,而这在工业实践中十分常见。
1.2 QComp的提出
为解决上述问题,QComp框架应运而生。它能够利用现有QSAR模型,立即利用新的实验数据,改进缺失数据的插补,且无需重新训练模型。同时,QComp通过量化特定终点的统计不确定性降低,帮助找到最优实验序列,辅助药物发现过程中的合理决策。
二、QComp的核心原理
2.1 概率框架
QComp将分子的生物化学活性()视为由化合物结构()决定的概率分布()。对于数据库中标记为()的分子,其化学结构为(),目标活性向量为(),其中已知活性子向量为(),缺失活性子向量为()。
QComp的任务是确定条件分布(),最优插补为条件期望()。它假设在()条件下,()服从多元高斯分布(),其中()是QSAR预测()的线性变换,()为()矩阵,()为()向量,()为正定()协方差矩阵。
2.2 训练过程
QComp通过最大化似然函数进行训练。观察值()的似然遵循边际高斯分布,定义关于参数()的对数似然损失函数(),通过梯度下降求解最优参数()。训练复杂度为(),其中()为训练集中的分子数量,()为活性/测定总数。
2.3 插补过程
训练完成后,QComp可进行一次性插补。缺失活性()在给定()和()时服从高斯分布(),其中均值()和协方差()由校准后的参数计算得出,最优插补值为该条件期望。插补复杂度同样为()。
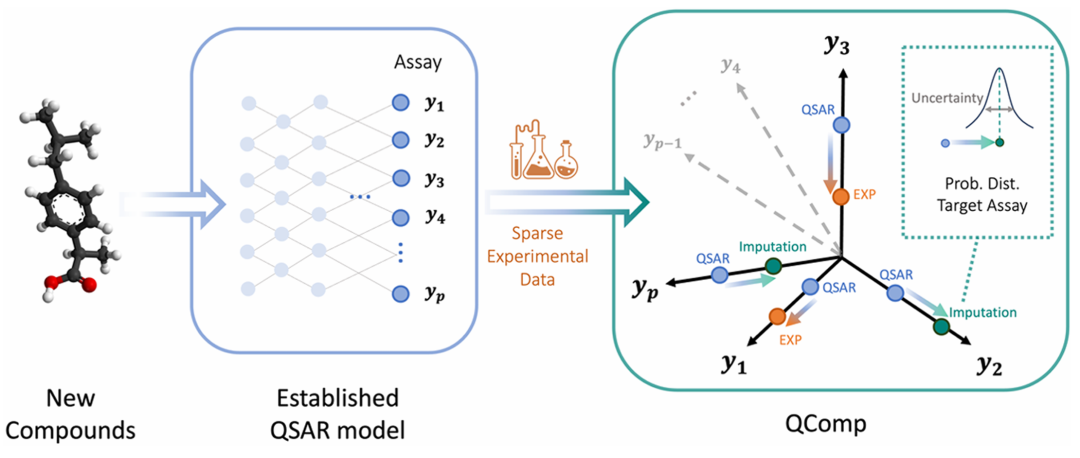
该图展示了 QComp 的插补流程。对于一组待研究的新化合物,其所有测定的 QSAR 预测结果已存在,但实验数据仅部分可用。QComp 结合 QSAR 预测和稀疏的实验数据,预测缺失测定的概率分布及对应的最优插补值,实现对缺失数据的有效填补。
该图展示了 QComp 的插补流程。对于一组待研究的新化合物,其所有测定的 QSAR 预测结果已存在,但实验数据仅部分可用。QComp 结合 QSAR 预测和稀疏的实验数据,预测缺失测定的概率分布及对应的最优插补值,实现对缺失数据的有效填补。
三、实验设计与结果分析
3.1 数据集与模型设置
- • 数据集:使用了ADMET780k(约780,000个分子,31个ADMET测定)、公共ADMET数据集(近110,000个分子,25个测定)和QM8数据集(21,787个分子,16个量子力学性质)。
- • 数据拆分:ADMET780k采用基于化合物的时间拆分(90%训练/验证,10%测试),公共ADMET数据集采用5折随机拆分。
- • 基础QSAR模型:ADMET相关数据集使用多任务Chemprop模型,QM8数据集使用微调的Uni-Mol模型。
- • 基线模型:选择MICE和MissForest,与QComp使用相同的QSAR预测作为补充信息。
3.2 关键验证与结果
- • 假设验证:通过分析ADMET780k数据集中测定的实验值与QSAR预测偏差的分布,验证了偏差服从正态分布的假设,为模型的合理性提供了支持。
- • ADMET插补基准:在ADMET780k数据集上,QComp的平均( r^{2} )得分为0.596,显著高于基础QSAR模型(0.441)、MICE(0.530)和MissForest(0.530),且在所有测定中稳健性优异。在公共ADMET数据集上,QComp也表现出系统性改进。
- • 体内外测定插补:仅用体外数据插补体内测定时,QComp对7个体内测定的改进约为10%;仅用体外数据插补体外测定时,改进与一般方案一致,表明体内数据对体外插补帮助有限。
- • 决策支持:利用确定性增益(GOC)指标,QComp可确定最优体外测定序列,辅助实验决策,如针对“MRT, rat”,前三个最优体外测定贡献了超过80%的GOC。
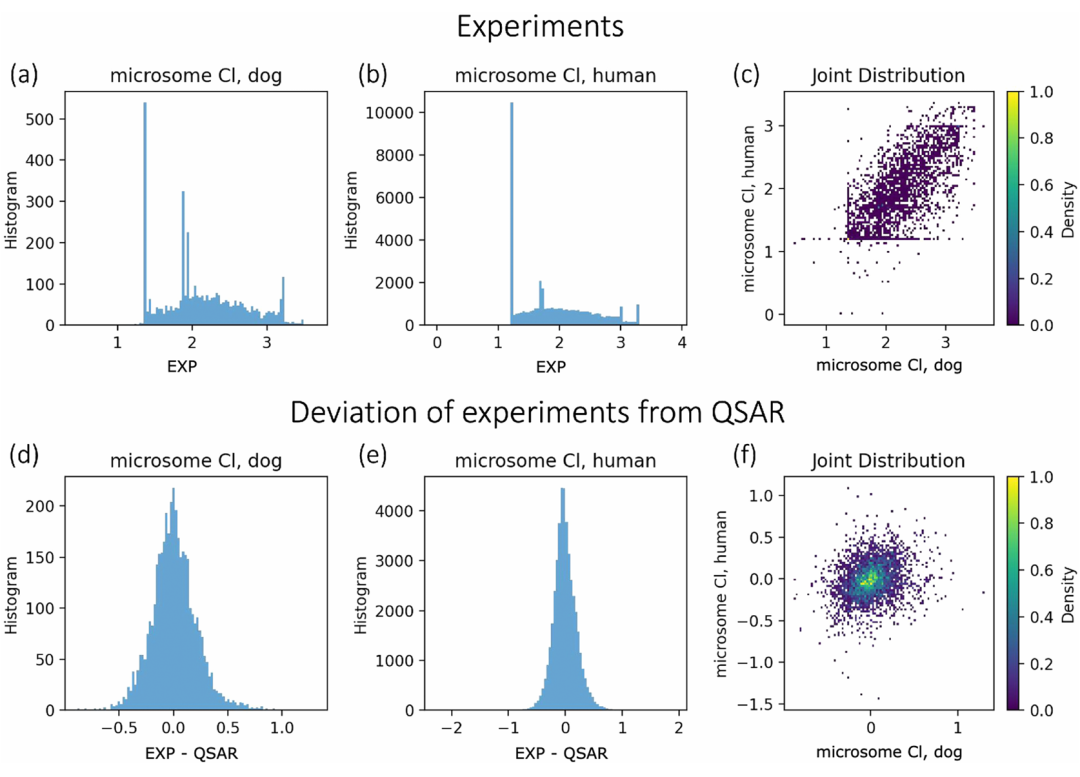
包含多个子图,(a, b)为 “microsome Cl, dog” 和 “microsome Cl, human” 测定的实验值分布直方图,峰值靠近分布下限;(c)是二者的联合分布热图,不接近二维高斯分布;(d, e)为实验值与 QSAR 预测值偏差的直方图,近似以 0 为中心的一维高斯分布;(f)为偏差的联合分布热图,类似零中心二维高斯分布,验证了 QComp 中偏差服从高斯分布的假设。
包含多个子图,(a, b)为 “microsome Cl, dog” 和 “microsome Cl, human” 测定的实验值分布直方图,峰值靠近分布下限;(c)是二者的联合分布热图,不接近二维高斯分布;(d, e)为实验值与 QSAR 预测值偏差的直方图,近似以 0 为中心的一维高斯分布;(f)为偏差的联合分布热图,类似零中心二维高斯分布,验证了 QComp 中偏差服从高斯分布的假设。
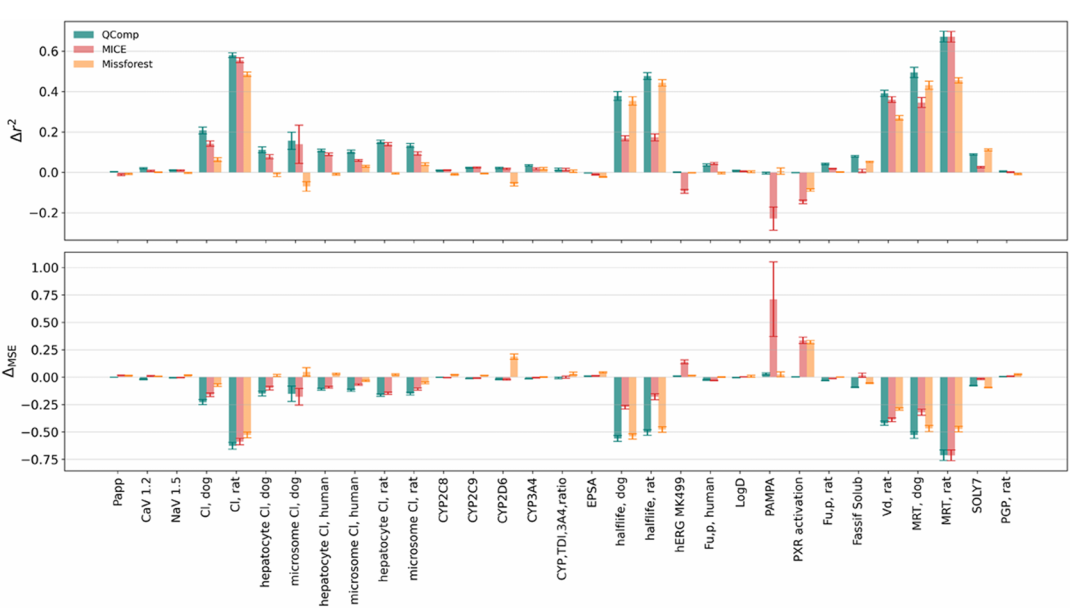
呈现 ADMET-780k 测试集 50 个时间拆分 bins 中,QComp、MICE、MissForest 相对于基础 QSAR 模型的 Pearson 得分变化和 MSE 变化的平均值及误差棒。结果显示 QComp 对近半数测定的改进具有统计显著性,且稳健性优于其他方法。
呈现 ADMET-780k 测试集 50 个时间拆分 bins 中,QComp、MICE、MissForest 相对于基础 QSAR 模型的 Pearson 得分变化和 MSE 变化的平均值及误差棒。结果显示 QComp 对近半数测定的改进具有统计显著性,且稳健性优于其他方法。
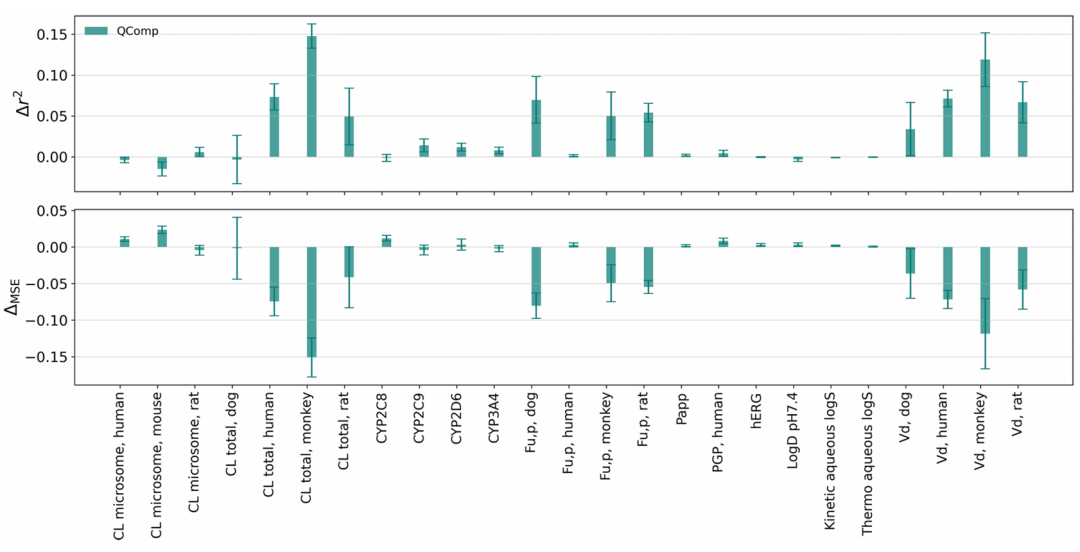
展示公共 ADMET 数据集 5 折随机拆分中,QComp 相对于基础 QSAR 模型的 Δr^2和 ΔMSE平均值及误差棒。QComp 对一半测定有系统性改进,验证了其在不同数据集上的适用性
展示公共 ADMET 数据集 5 折随机拆分中,QComp 相对于基础 QSAR 模型的 Δr^2和 ΔMSE平均值及误差棒。QComp 对一半测定有系统性改进,验证了其在不同数据集上的适用性
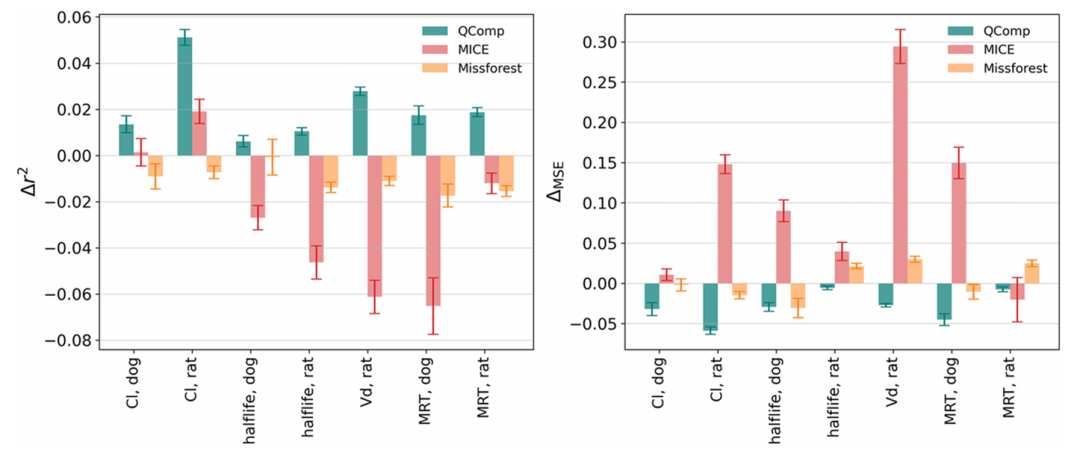
显示仅用体外数据插补体内测定时,三种方法相对于基础 QSAR 模型的 Δr^2和 ΔMSE平均值及误差棒。QComp 对所有 7 个体内测定的改进系统且显著,而其他方法表现不稳定
显示仅用体外数据插补体内测定时,三种方法相对于基础 QSAR 模型的 Δr^2和 ΔMSE平均值及误差棒。QComp 对所有 7 个体内测定的改进系统且显著,而其他方法表现不稳定
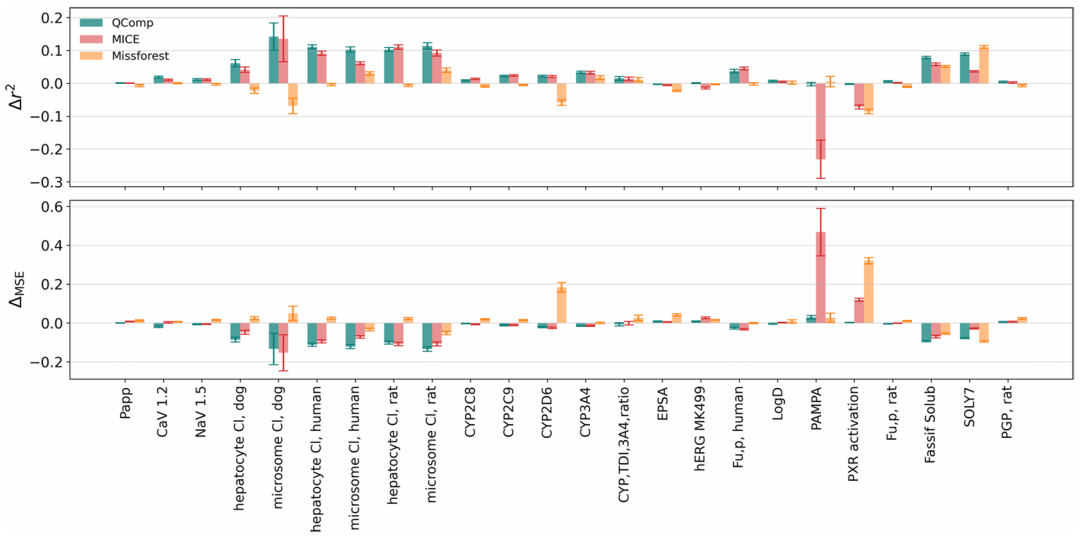
呈现不使用体内数据插补体外测定时,三种方法相对于基础 QSAR 模型的 Δr^2和 ΔMSE平均值及误差棒。QComp 对约三分之一体外测定(如 “hepatocyte Cl” 等)的改进具有统计显著性,稳健性更优
呈现不使用体内数据插补体外测定时,三种方法相对于基础 QSAR 模型的 Δr^2和 ΔMSE平均值及误差棒。QComp 对约三分之一体外测定(如 “hepatocyte Cl” 等)的改进具有统计显著性,稳健性更优
四、结论与展望
QComp是一种准确、稳健、可解释且通用的插补方法,能动态整合新数据改进预测,无需重新训练模型,在ADMET插补任务中表现优于现有方法,尤其在利用体外数据插补体内测定和辅助决策方面具有显著优势。
未来可进一步拓展QComp,如允许结构依赖的协方差矩阵(),使测定间相关性随化学空间变化,从而增强其适用性和决策支持能力。
该研究为药物发现中的数据插补问题提供了新的有效解决方案,相关Python实现和公共数据集可在https://github.com/MSDLLCpapers/QComp获取,值得相关领域研究者关注和应用。
(●'◡'●) 需要进一步讨论的同学欢迎留言交流!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号