CiBO:突破高维约束黑箱优化的生成式建模新框架

CiBO:突破高维约束黑箱优化的生成式建模新框架

MindDance
发布于 2026-01-08 12:53:59
发布于 2026-01-08 12:53:59
在科学研究与工程实践中,高维约束黑箱优化是一个普遍存在却极具挑战性的问题。从药物发现到工业设计,从机器人控制到机器学习超参数调优,我们常常需要在复杂且未知的可行域中寻找最优解。传统方法要么受限于维度灾难,要么在约束处理上力不从心。今天,我们将介绍一项发表于arXiv的最新研究——CiBO(Constrained Inference-based Black-box Optimization),它通过生成式建模与后验推理的创新结合,为这一难题提供了高效解决方案。
为什么高维约束黑箱优化如此棘手?
黑箱优化的核心难点在于:目标函数与约束条件无法通过解析表达式描述,只能通过有限的实验或模拟获取观测值。而当问题维度升高(如数百维)且约束条件复杂时,挑战进一步加剧:
- 1. 可行域难以定位:约束条件可能将解空间分割成多个孤立区域,传统方法容易陷入局部最优或遗漏可行域。
- 2. 样本效率低下:高维度意味着搜索空间呈指数级增长,有限的实验次数难以覆盖有意义的区域。
- 3. 模型泛化困难:代理模型(如高斯过程)在高维空间中难以准确拟合目标函数与约束,尤其当约束反馈仅为“可行/不可行”的二元信号时。
贝叶斯优化(BO)虽在低维无约束问题中表现出色,但在高维约束场景下 scalability不足;生成式模型方法则常因模态坍缩(mode collapse)难以探索多峰分布的可行域。CiBO的创新之处在于,它将候选解选择转化为潜空间中的后验推理问题,既利用生成模型捕捉数据分布,又通过扩散采样高效探索高价值区域。
CiBO的核心框架:两阶段迭代优化
CiBO的工作流程分为模型训练与候选采样两个阶段,通过迭代更新实现高效优化。其核心思路是:用流模型(flow-based model)捕捉数据分布,用代理模型预测目标与约束,再通过潜空间中的扩散采样生成高质量候选解。
阶段1:模型训练——捕捉分布与预测不确定性
在每一轮迭代中,CiBO首先基于现有数据集训练三类模型:
- • 流模型(Flow-based Model):通过Flow Matching方法学习当前数据的分布,作为后续采样的先验。流模型的优势在于能通过确定性映射将潜空间的标准正态分布转化为数据空间的复杂分布,为高维数据建模提供了灵活工具。
- • 代理模型集成(Surrogate Ensembles):
- • 目标函数代理:由多个神经网络组成的集成,用于预测目标值并量化不确定性(均值+标准差)。
- • 约束代理:为每个约束条件单独训练神经网络,预测约束违反程度。
- • 训练时采用加权策略:对高目标值且低约束违反的样本赋予更高权重,公式为: 其中为平衡目标与约束的拉格朗日乘数。
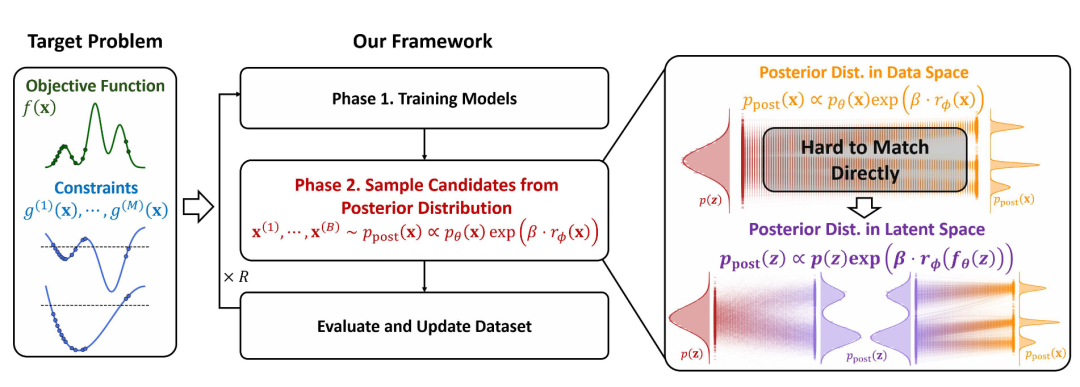
图 1:CiBO框架与传统方法的对比(左:目标问题;右:CiBO的后验推理思路)。CiBO将数据空间中复杂的后验分布(橙色,多峰且平坦)转化为潜空间中更平滑的分布(紫色),通过扩散采样高效生成候选解。
图 1:CiBO框架与传统方法的对比(左:目标问题;右:CiBO的后验推理思路)。CiBO将数据空间中复杂的后验分布(橙色,多峰且平坦)转化为潜空间中更平滑的分布(紫色),通过扩散采样高效生成候选解。
阶段2:候选采样——潜空间中的后验推理
传统方法直接在数据空间采样时,常因约束导致后验分布呈现多峰、平坦区域,难以高效探索。CiBO的关键创新是在流模型的潜空间中进行后验推理:
- 1. 后验分布定义:将候选解的后验分布定义为先验分布(流模型)与奖励函数的乘积,奖励函数结合了目标值与约束惩罚: 其中为潜变量,为流模型的确定性映射,为控制先验与奖励权重的温度参数。
- 2. 扩散采样(Diffusion Sampling):训练扩散模型逼近潜空间中的后验分布,通过轨迹平衡(Trajectory Balance)目标优化采样过程。扩散采样能高效处理多峰分布,且通过离线训练(off-policy training) 提升模态覆盖度,避免模态坍缩。
- 3. 过滤与更新:从潜空间采样后,映射回数据空间并筛选出最优的个候选解进行评估,再将新观测值加入数据集(保留top-L样本以控制规模)。
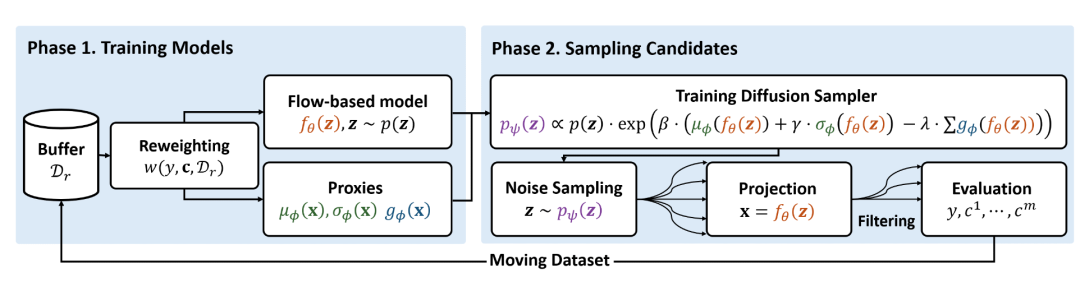
图 2:CiBO的两阶段流程细节。阶段1通过加权训练流模型与代理模型;阶段2利用扩散采样在潜空间生成候选解,经过滤后评估并更新数据集,迭代直至预算耗尽。
图 2:CiBO的两阶段流程细节。阶段1通过加权训练流模型与代理模型;阶段2利用扩散采样在潜空间生成候选解,经过滤后评估并更新数据集,迭代直至预算耗尽。
实验验证:在合成与真实任务中全面领先
研究团队在3个合成任务(200维Rastrigin、Ackley、Rosenbrock函数)与3个真实任务(60维漫游者路径规划、124维车辆设计MOPTA、180维Lasso DNA优化)中验证了CiBO的性能,并与8种主流方法(如cEI、SCBO、CMA-ES、DiffOPT等)进行对比。
合成任务:高维多峰函数的约束优化
在200维合成函数中,CiBO在标准约束与更具挑战性的“二元可行信号”场景下均表现最优。例如:
- • Rastrigin函数:高维下存在大量局部最优,CiBO能快速找到低 regret 的可行解,而DiffOPT、DDOM等方法常因无法定位可行域导致性能停滞。
- • 二元约束场景:当约束反馈仅为“可行/不可行”时,CiBO通过潜空间采样仍能高效探索,而多数基线方法因后验分布过于平坦难以收敛。
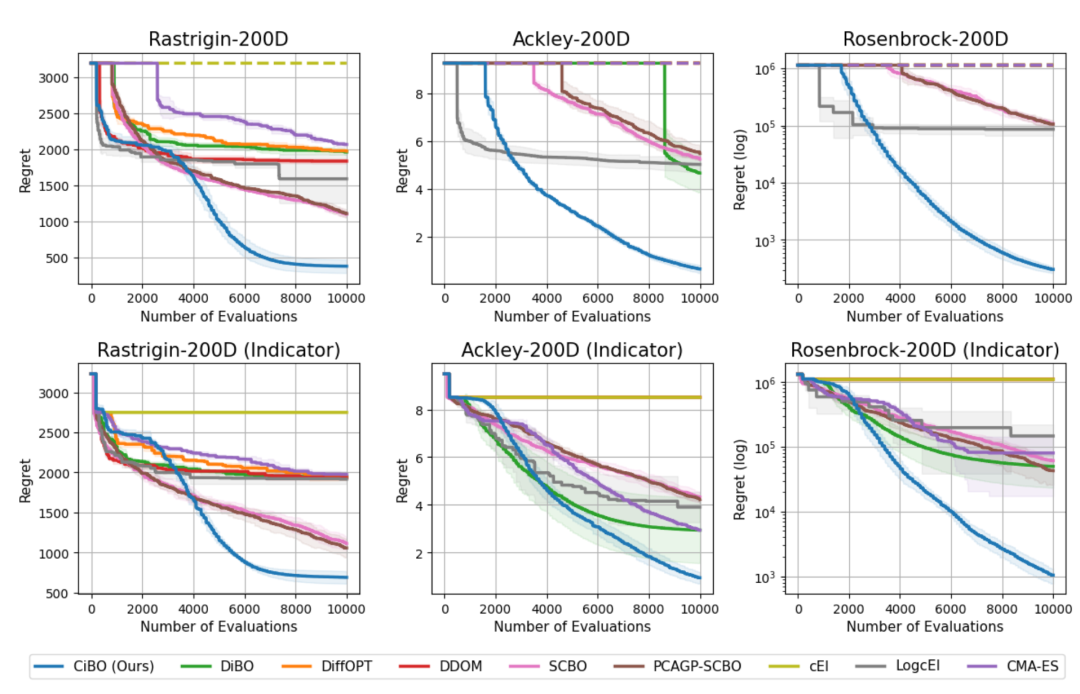
图 3:合成任务中CiBO与基线方法的性能对比。纵轴为可行解的最小regret(越低越好),横轴为评估次数。CiBO(蓝色线)在所有任务中均显著优于其他方法,虚线表示未找到可行解。
图 3:合成任务中CiBO与基线方法的性能对比。纵轴为可行解的最小regret(越低越好),横轴为评估次数。CiBO(蓝色线)在所有任务中均显著优于其他方法,虚线表示未找到可行解。
真实任务:复杂场景下的鲁棒性
在真实高维问题中,CiBO的优势更为明显:
- • 漫游者路径规划(60维):需避开15个障碍物,CiBO找到的轨迹 regret 显著低于SCBO与CMA-ES。
- • MOPTA车辆设计(124维):68个约束条件下,多数方法无法找到可行解,而CiBO能稳定收敛到接近最优的质量。
- • Lasso DNA优化(180维):基因序列的高维约束下,CiBO的样本效率是第二名的3倍以上。
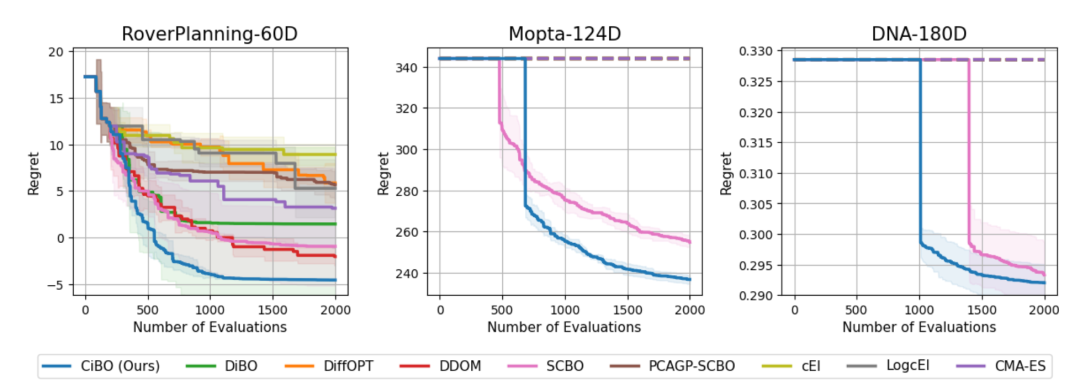
图 4:真实任务中的性能对比。CiBO在60维、124维、180维真实任务中均保持最低regret,尤其在高约束场景(如MOPTA)中优势显著。
图 4:真实任务中的性能对比。CiBO在60维、124维、180维真实任务中均保持最低regret,尤其在高约束场景(如MOPTA)中优势显著。
关键组件的 ablation 分析
为验证各组件的有效性,研究团队进行了对照实验:
- 1. 拉格朗日加权训练:若仅以目标值加权(忽略约束),会导致高方差且可行解比例低;而CiBO的加权策略能平衡目标与约束,提升样本效率。
- 2. 潜空间扩散采样:直接从流模型先验采样或移除过滤步骤,会显著降低性能,证明潜空间采样与过滤对探索高价值区域的必要性。
- 3. 拉格朗日乘数λ:λ=0(无视约束)会导致无可行解,λ过大则忽略目标值,需根据任务调整(实验中λ=3~10效果最优)。
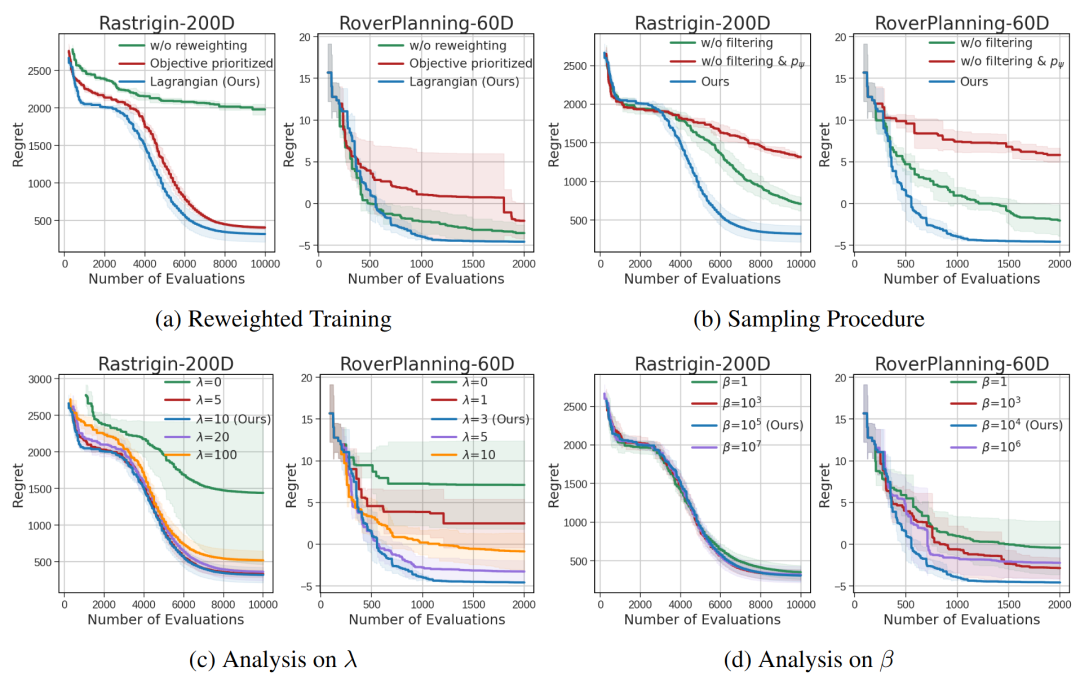
图 5:关键组件的 ablation 结果。(a) 拉格朗日加权 vs 目标加权;(b) 完整采样 vs 移除过滤/扩散;(c) 不同λ值的影响。结果表明各组件对性能均有显著贡献。
图 5:关键组件的 ablation 结果。(a) 拉格朗日加权 vs 目标加权;(b) 完整采样 vs 移除过滤/扩散;(c) 不同λ值的影响。结果表明各组件对性能均有显著贡献。
总结与展望
CiBO通过将高维约束黑箱优化转化为潜空间后验推理,突破了传统方法在高维与多峰约束下的瓶颈。其核心贡献包括:
- 1. 流模型与扩散采样结合,解决了高维数据分布建模与多峰后验探索的难题。
- 2. 拉格朗日加权与潜空间采样提升了约束处理的鲁棒性,尤其适用于二元可行信号场景。
- 3. 离线训练的扩散采样增强了模态覆盖,避免了生成式方法常见的模态坍缩。
未来,CiBO的进一步优化方向包括:模型复用以降低迭代成本、动态调整拉格朗日乘数,以及扩展至多目标优化场景。对于从事高维设计优化、复杂系统控制的研究者与工程师,CiBO提供了一套高效且通用的工具链,其代码已开源(https://github.com/umkiyoung/CiBO),值得关注与实践。
原文链接:https://arxiv.org/abs/2507.00480 代码地址:https://github.com/umkiyoung/CiBO
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号