HierLight-YOLO:面向无人机航拍的层次化轻量目标检测网络
原创
HierLight-YOLO:面向无人机航拍的层次化轻量目标检测网络
原创
AI小怪兽
发布于 2026-01-08 09:14:02
发布于 2026-01-08 09:14:02
📄 论文核心摘要:
这篇论文所提出的 HierLight-YOLO 框架——特别是其分层扩展路径聚合网络(HEPAN) 和轻量级模块(IRDCB/LDown)——对于在无人机影像等场景中解决小目标检测和边缘设备部署的难题,具有明确且重要的参考价值。

博主简介

AI小怪兽 | 计算机视觉布道者 | 视觉检测领域创新者
深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
- YOLO算法结构性创新:于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
- 技术生态建设与知识传播:独立运营 “计算机视觉大作战” 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
- 荣获腾讯云年度影响力作者与创作之星奖项,内容质量与专业性获行业权威平台认证。
- 全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
- 具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 “让每一行代码都有温度” 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。
原理介绍

论文:https://arxiv.org/pdf/2509.22365
摘要:在复杂场景(如无人机航拍图像)中实现小目标的实时检测面临着双重挑战:既要检测小目标(<32×32像素),又要在资源受限的平台上保持实时效率。虽然YOLO系列检测器在实时大目标检测方面取得了显著成功,但在以小目标为主的无人机检测场景中,其误检率明显高于大目标场景。本文基于YOLOv8架构提出了HierLight-YOLO,这是一个通过分层特征融合的轻量化模型,可增强小目标的实时检测能力。我们提出了分层扩展路径聚合网络(HEPAN),这是一种通过分层跨层级连接的多尺度特征融合方法,可提高小目标检测精度。HierLight-YOLO包含两个创新的轻量级模块:倒残差深度卷积块(IRDCB)和轻量级下采样(LDown)模块,它们在保持检测能力的同时显著减少了模型的参数量和计算复杂度。特别设计了小目标检测头,通过增强空间分辨率和特征融合来应对微小目标(4×4像素)的检测。在VisDrone2019基准测试上的对比实验和消融研究表明,HierLight-YOLO实现了最先进的性能:纳米级HierLight-YOLO-N仅需220万参数(比YOLOv8-N减少26.7%),同时保持强大的检测能力(35.8% AP0.5),证明了其适用于边缘部署;小尺度HierLight-YOLO-S以仅780万参数(比YOLOv8-S减少29.7%)实现了44.9% AP0.5的最佳精度;中尺度变体HierLight-YOLO-M以具有竞争力的1790万参数实现了50.2% AP0.5(超过YOLOv8-M 5.6%)的优异性能。消融研究验证了各组件的贡献,其中HEPAN相较于传统特征金字塔网络将AP0.5提高了0.8%,而IRDCB在不损失精度的情况下减少了22.1%的参数。
伪代码如下:
# ============================================
# HierLight-YOLO: 无人机摄影的层次化轻量目标检测网络
# ============================================
Algorithm HierLight_YOLO_Network:
Input: UAV_image (H×W×3)
Output: Detection_results {bboxes, classes, scores}
# 阶段1: 轻量化骨干网络
def Lightweight_Backbone(image):
# 使用深度可分离卷积构建高效骨干
x = Initial_Conv3x3(image, channels=32)
# 分层特征提取模块
hierarchical_features = []
# Stage 1: 高分辨率浅层特征
x = DepthwiseSeparable_Block(x, channels=64, stride=1)
hierarchical_features.append(x) # F1: 高分辨率特征
# Stage 2: 中分辨率特征
x = DepthwiseSeparable_Block(x, channels=128, stride=2)
x = Lite_Residual_Block(x, channels=128)
hierarchical_features.append(x) # F2: 中分辨率特征
# Stage 3: 低分辨率深层特征
x = DepthwiseSeparable_Block(x, channels=256, stride=2)
x = Lite_Residual_Block(x, channels=256)
x = Lite_Residual_Block(x, channels=256)
hierarchical_features.append(x) # F3: 低分辨率特征
return hierarchical_features # [F1, F2, F3]
# 阶段2: 层次化特征金字塔
def Hierarchical_Feature_Pyramid(features):
# 输入: [F1, F2, F3] 不同分辨率的特征
# 自底向上路径增强
P3 = features[2] # 最深层的特征
# 自上而下路径 + 横向连接
P2 = UpSample(P3, scale=2) + 1x1_Conv(features[1])
P2 = DepthwiseSeparable_Block(P2, channels=128)
P1 = UpSample(P2, scale=2) + 1x1_Conv(features[0])
P1 = DepthwiseSeparable_Block(P1, channels=64)
# 跨尺度特征融合
N1 = Adaptive_Feature_Fusion(P1, P2, P3)
N2 = Adaptive_Feature_Fusion(P2, P1, P3)
N3 = Adaptive_Feature_Fusion(P3, P1, P2)
return [N1, N2, N3] # 融合后的多层次特征
# 阶段3: 多尺度检测头
def MultiScale_Detection_Head(fused_features):
detections = []
for i, feature in enumerate(fused_features):
# 轻量化检测子网络
cls_pred = 1x1_Conv(feature, channels=num_classes)
reg_pred = 1x1_Conv(feature, channels=4)
# 针对无人机小目标的优化
if i == 0: # 高分辨率层
cls_pred = Small_Object_Enhancement(cls_pred)
reg_pred = Adaptive_Anchor_Refinement(reg_pred)
# 解码预测
decoded_pred = Decode_Predictions(cls_pred, reg_pred,
anchor_boxes[i],
img_size)
detections.append(decoded_pred)
return detections
# 阶段4: 上下文感知后处理
def Context_Aware_NMS(all_detections):
# 无人机场景特定的后处理
filtered_detections = []
for det in all_detections:
# 基于空间关系的过滤
if UAV_Specific_Filter(det):
continue
# 多尺度预测融合
det = Scale_Aware_Refinement(det)
# 上下文感知的非极大抑制
if not Is_Suppressed(det, filtered_detections):
filtered_detections.append(det)
return filtered_detections
# 主流程
def Main():
# 1. 特征提取
hierarchical_features = Lightweight_Backbone(UAV_image)
# 2. 特征融合
fused_features = Hierarchical_Feature_Pyramid(hierarchical_features)
# 3. 多尺度检测
multi_scale_detections = MultiScale_Detection_Head(fused_features)
# 4. 后处理
final_detections = Context_Aware_NMS(
Flatten(multi_scale_detections)
)
return final_detections
# ============================================
# 关键子算法
# ============================================
Algorithm Adaptive_Feature_Fusion(main_feat, aux_feat1, aux_feat2):
# 自适应权重学习
w1 = Global_Attention(main_feat)
w2 = Global_Attention(aux_feat1)
w3 = Global_Attention(aux_feat2)
# 加权融合
fused = w1 * main_feat + w2 * UpSample(aux_feat1) + w3 * UpSample(aux_feat2)
# 通道重校准
fused = SE_Block(fused) # 压缩-激励模块
return fused
Algorithm Small_Object_Enhancement(feature_map):
# 针对无人机小目标的增强
# 1. 高分辨率特征保留
enhanced = Dilated_Conv(feature_map, rate=2) # 扩大感受野
# 2. 局部上下文聚合
enhanced = Local_Context_Module(enhanced)
# 3. 特征锐化
enhanced = Feature_Sharpening(enhanced)
return enhanced
Algorithm UAV_Specific_Filter(detection):
# 无人机场景先验知识
# 1. 尺寸过滤 (排除过大/过小目标)
if detection.size < min_object_size or detection.size > max_object_size:
return True
# 2. 空间分布过滤 (基于无人机视角)
if not Is_Plausible_Location(detection.bbox, UAV_altitude):
return True
# 3. 运动一致性检查 (视频序列中)
if has_temporal_info and not Motion_Consistent(detection):
return True
return False
# ============================================
# 网络配置参数
# ============================================
Configuration:
- Backbone: DepthwiseSeparable CNN with residual connections
- Input_size: 640×640 (可适应不同无人机分辨率)
- Feature_levels: 3 (高、中、低分辨率)
- Detection_scales: 3 (对应不同特征层)
- Anchor_boxes: 针对无人机目标优化的尺寸
- Total_params: < 5M (轻量化设计)
- Inference_speed: > 30 FPS (无人机实时处理)1. 引言
随着无人机技术的飞速发展,航空摄影已在灾害监测、交通管理、搜索救援及农业监管等诸多领域成为不可或缺的工具。与传统的地面作业方式相比,无人机影像提供了高空视角、广阔覆盖范围以及更低的运营成本。在这些应用中,实时、精准的目标检测对于无人机的有效部署至关重要——无论是在灾害响应中识别幸存者和危险源,还是在精准农业中检测细微的异常。然而,无人机影像中的小目标检测面临着严峻挑战,包括复杂背景、低对比度目标以及动态多变的环境条件,这些因素常常导致漏检和误报 [1, 2]。克服这些局限性将使无人机操作更加可靠和高效,从而在 demanding 的实际应用场景中最大化其潜力。
现有的目标检测方法大致可分为两类:两阶段模型(如 R-CNN 系列 [3, 4, 5]),首先生成区域提议,然后对其进行分类和精修;以及单阶段模型(如 YOLO 系列 [6, 7, 8, 9, 10, 11, 12, 13, 14]),通过将目标检测视为回归问题,单次前向传播即可完成检测。两阶段方法通过区域提议网络提供了高精度,但其计算复杂性常常阻碍了实时性能。相比之下,单阶段模型推理速度更快,尽管传统上需要在精度上做出一些权衡。YOLO 系列的最新进展通过无锚点检测和增强的特征融合,弥补了关键的性能差距,为实时应用实现了速度与精度的平衡。
在复杂的空中场景中检测小目标仍然存在重大挑战。这些局限性之所以持续存在,是由于在杂乱背景和尺度变化中,从低分辨率目标捕获判别性特征存在固有困难。近期的研究探索了多种架构策略以增强小目标检测能力。多尺度特征融合方法从开创性的特征金字塔网络(FPN)[15](它通过带有横向连接的自上而下路径建立了分层特征组合)不断发展,演进至更复杂的变体,如路径聚合网络(PANet)[16],它引入了互补的自下而上信息流。该领域进一步发展,双向 FPN(BiFPN)通过可学习的跨尺度特征加权,实现了跨分辨率级别的动态重要性分配 [17]。注意力机制的并行发展引入了内容感知的特征调制,使网络能够将计算资源集中在语义显著的区域 [18]。与此同时,轻量化设计范式通过架构创新涌现出来,例如 MobileNets [19, 20, 21] 中的深度可分离卷积、ShuffleNets [22, 23] 中的通道混洗操作,以及 EfficientNets [24, 25] 中基于神经架构搜索的缩放原则。尽管这些方法在降低通用目标检测的计算开销方面表现良好,但在应对无人机特定场景中、针对杂乱背景和尺度变化的极小目标检测方面,它们仍然力有未逮。这些持续存在的挑战凸显了在航空影像分析中寻求专门解决方案的必要性。
为了应对现有模型在复杂无人机捕获场景的小目标检测中的局限性,我们提出了 HierLight-YOLO,一种基于 YOLOv8 的增强型轻量架构,它在保持计算资源受限设备计算效率的同时,显著提升了小目标检测性能。
本项工作的主要贡献包括:
- 分层特征融合架构:我们提出了分层扩展路径聚合网络(HEPAN),它通过两项关键创新扩展了传统的 PANet:(1) 带有残差连接的中间卷积块,以加强梯度传播;(2) 双向多尺度特征融合,同时保留高分辨率细节和丰富的语义信息。它通过分层跨层级连接增强了多尺度特征融合,从而显著改善了小目标识别。
- 轻量化网络优化:我们重新设计的倒残差深度卷积块(IRDCB) 模块将深度可分离卷积 [26] 与倒残差结构 [20] 相结合,在保持相当精度的同时,比原始的 C2f 模块减少了 22.1% 的参数。引入的轻量下采样(LDown) 模块通过优化的通道压缩,进一步将参数量减少了 11.4%,使得在计算资源有限的边缘设备上实现实时操作成为可能。
- 小目标检测头:我们引入了一个专门为小目标设计的额外检测头。通过跨层级连接策略性地融合浅层空间特征与深层语义特征,这一增强显著提升了对于小于 32×32 像素目标的检测召回率,同时保持了计算效率。
通过在 VisDrone2019 基准数据集 [27] 上的全面评估,我们提出的 HierLight-YOLO 模型在多项指标上均展现出相对于基线 YOLOv8 模型的显著改进。所提出的架构在小目标(<32×32 像素)的平均精度(AP)上实现了 3.3% 的提升,同时在 NVIDIA RTX 6000 Ada 上保持了 133 FPS 的实时处理速度。如图 1 所示,我们模型的类别激活热力图揭示了两大关键优势:(1) 集中于小目标上的更强热响应(与基线 YOLOv8 相比,强度值高出 3-5 倍);(2) 更精确的空间定位,表现为目标边界周围更紧凑的热力分布。这些可视化结果定量地证实了 HEPAN 的分层特征融合和改进的轻量模块有效地增强了模型在挑战性无人机场景中捕获细粒度特征的能力。

2. 相关工作
目标检测的一个基本挑战在于有效识别不同尺度下的物体,尤其是那些通常仅占图像像素少于0.1%的小目标。这些小目标在深度卷积网络的重复卷积操作过程中会遭受严重的特征退化,使其容易在更深的网络层中丢失。研究界逐步开发了日益复杂的多尺度特征融合方法来应对这一局限。早期的检测框架,如R-CNN [3] 和 Fast R-CNN [4],依赖于单尺度特征提取,这固有地限制了它们的多尺度检测能力。虽然Faster R-CNN [5] 引入了区域提议网络(RPN)用于候选框生成,但它仍然受限于固定尺度的特征处理。FPN [15] 带来了一个突破,它通过横向连接建立了如今已成为标准范式的自上而下的多分辨率特征融合方法。后续的创新进一步优化了该方法:PANet [16] 通过自下而上的路径增强来加强特征流,从而扩充了FPN;而自适应空间特征融合(ASFF)[28] 引入了自适应空间加权,以动态强调跨尺度的最具判别性的特征。该领域还探索了使用神经架构搜索特征金字塔网络(NAS-FPN)[29] 进行自动化架构设计,尽管计算代价高昂。目前,BiFPN [17] 通过其可学习的跨尺度特征加权机制代表了最先进的技术,表明精心设计的融合策略可以显著提升小目标检测性能,而不会产生过高的计算开销。
轻量级网络设计的最新进展显著增强了深度学习模型在资源受限环境中的部署能力。该领域通过几项关键创新不断发展:MobileNet [19] 开创了深度可分离卷积的使用,与标准卷积相比,将计算复杂度降低了高达8-9倍,同时保持了有竞争力的准确率。ShuffleNet [23] 通过引入通道混洗操作,实现了分组卷积中高效的跨组信息交换,从而推进了这一范式。EfficientNet [24] 带来了一个重大突破,它建立了一种原则性的复合缩放方法,以联合优化网络的宽度、深度和分辨率。后续的架构,如CSPNet [30],证明了跨阶段部分连接可以同时减少20%的计算量并增强梯度流。GhostNet [31] 通过其Ghost模块进一步突破了效率边界,该模块通过廉价的线性操作而非昂贵的卷积来生成额外的特征图。这些创新共同代表了一条演进轨迹,其中每个新架构都建立并改进了其前代的核心思想,逐步改善了边缘部署场景中计算效率与模型性能之间的权衡。
实时端到端目标检测通过YOLO系列架构和基于Transformer的方法的双重演进取得了显著进展。YOLO系列 [6, 7, 8, 9, 10, 11, 14, 12] 通过统一的回归框架建立了高效检测的主导范式。近期的创新,如YOLOv10 [13],通过引入Transformer增强的混合编码器(该编码器消除了非极大值抑制(NMS)瓶颈,同时在GPU硬件上保持<2ms的延迟)展示了进一步的改进。RT-DETR [32] 通过采用CNN主干网与基于Transformer的混合编码器(其特点是通过AIFI和CCFM模块进行尺度感知的特征融合)和解码器,并辅以不确定性最小化查询选择进行增强,进一步革新了这一领域。训练效率方面的并行进展包括DEIM [33],它通过密集的一对一匹配将收敛时间减少了40%;以及D-FINE [34],它通过解耦的位置-尺寸预测将遮挡处理的AP提高了18%。这些发展共同推动了复杂场景下实时检测的边界。最新的YOLOv12 [35] 集成了区域注意力机制和残差ELAN模块以优化多尺度感知,并通过闪存注意力机制优化超越了一系列模型。这些发展共同推动了复杂场景下实时检测的边界。
3. 方法论
在本节中,我们将详细介绍我们 HierLight-YOLO 模型的网络设计。我们的目标是提升 YOLOv8 模型的检测性能,特别是在无人机影像中小目标检测这一具有挑战性的任务上。我们通过着重优化多尺度特征融合机制和引入轻量级模块来增强小目标检测能力。这些创新使得模型能够在复杂和杂乱的背景中保持出色准确性的同时,捕获小目标的关键特征信息。在以下小节中,我们将介绍这些增强功能的核心方面,并探讨其详细实现。我们增强网络的整体结构如图 2 所示。它由三个主要部分组成:骨干网络、颈部网络和检测头。骨干网络包括标准卷积、C2f 和我们轻量级的 IRDCB 模块,负责特征提取和压缩。颈部网络使用 HEPAN 来融合多尺度特征,增强小目标检测。检测头包含四个不同尺度的检测层,以确保模型能够准确识别多尺度目标。
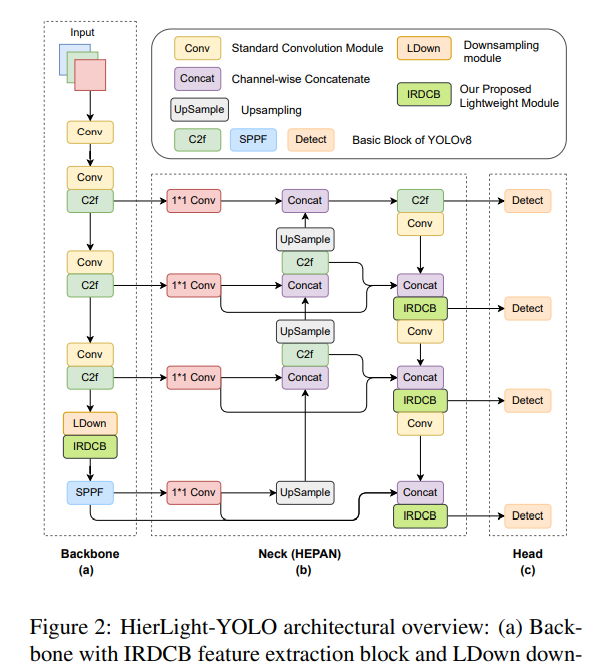
3.1. 分层特征融合架构
我们提出了分层扩展路径聚合网络(HEPAN)来优化小目标检测的特征融合,如图 3 所示。通过在颈部网络中引入额外的 1×1 卷积层,HEPAN 增强了特征提取和表示能力,同时包含了密集的残差连接以提高梯度流稳定性。与传统的 PANet 和 BiFPN 结构相比,HEPAN 通过更精细的特征连接和高效的信息流,实现了更优异的检测精度,尤其是在复杂背景中的小目标检测方面。
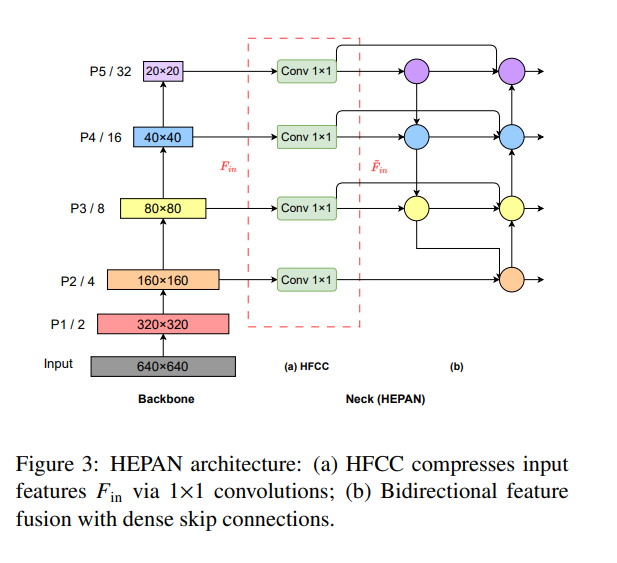
我们通过骨干网络输出(P2-P5)处的 1×1 卷积层实现的分层通道压缩设计,其理论基础是信息瓶颈原理 [36, 37, 38]。该原理指出,有效的特征表示需要在保留任务相关语义的同时压缩冗余信息。对于每个分层输入特征 Fin,由 1×1 卷积执行的通道压缩操作产生压缩后的特征 F˜in,
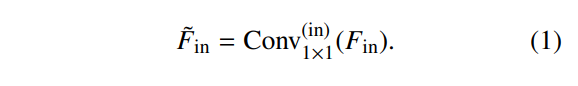
如公式 (1) 所示。此操作有两个关键目的:(1) 最大化压缩特征 F˜in 与检测目标 Y 之间的互信息 I(Y; F˜in),同时 (2) 最小化 I(F˜in; Fin) 以滤除不相关的背景噪声和纹理。通过策略性的通道降维(例如,将 P5 特征从 1024 个通道压缩到 512 个通道),模型在保持高效计算的同时,优先处理精准多尺度目标检测所需的最重要的空间和语义信息,这对轻量级网络架构尤其有益。
跨层密集跳跃连接
基于密集连接理论 [39],我们的架构采用跨层跳跃连接来增强深度网络中的梯度传播效率。对于浅层特征 Fl,梯度流向更深的融合节点 Fl+j, j = 1, · · · , m,
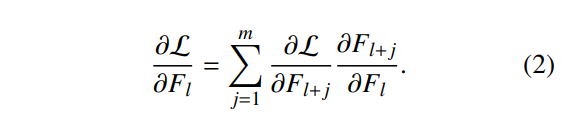
如公式 (2) 所示。该机制在深层特征计算中保留了高分辨率细节,同时缓解了梯度消失,特别有利于小目标的参数更新。
我们通过跨层聚合结构扩展了 PANet 的双向流思想,该结构结合了 P2 的细粒度细节和 P5 的全局上下文,解决了空间-语义差异,确保了鲁棒的尺度变化处理。通道压缩和跳跃连接的组合操作实现了最优的效率-表示平衡。1×1 卷积充当信息过滤器,而跨层链接创建了密集的反馈回路,强调了显著的多尺度特征——这是在复杂环境中进行小目标检测的关键能力。
3.2. 改进的轻量级模块
在小目标检测任务中,模型的计算复杂度和参数量对实时性能和效率具有至关重要的影响,尤其是在部署于资源受限设备时。因此,轻量级模型设计对于提高检测速度和降低功耗至关重要。我们优化了模型架构,在保持检测精度的同时减少冗余计算。通过设计一种新颖的特征提取模块,我们在不影响性能的情况下显著降低了模型参数数量和计算成本。
倒残差深度卷积块(IRDCB)
IRDCB 模块通过结合深度可分离卷积和通道重排列的高效架构来重构特征融合,在保持特征表示质量的同时显著降低了计算成本。基于 MobileNetV2 的倒残差结构 [20],我们的模块设计专门针对目标检测中的多尺度特征需求。
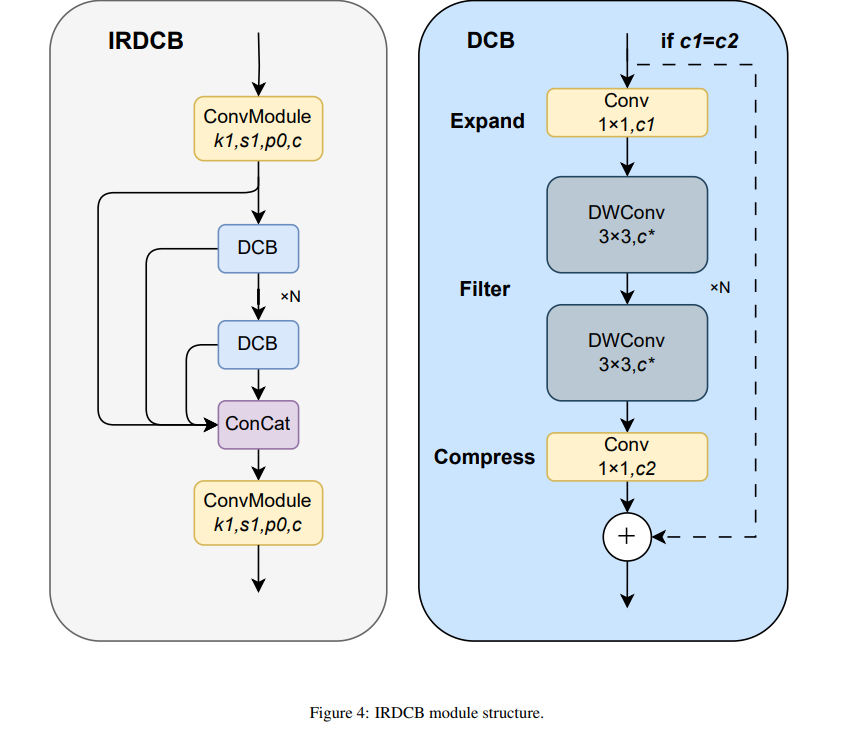
如图 4 所示,我们的 IRDCB 模块通过三个顺序阶段,对输入特征 xin 实现高效的特征变换 F,其输入/输出通道维度分别为 c1 和 c2:
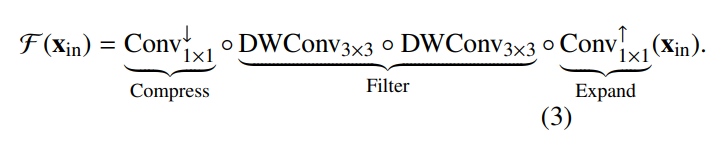
- 扩展阶段:一个 1×1 卷积将输入通道 c1 投影到扩展维度 c∗ = ⌊c1t⌋(扩展因子 t ≥ 1)。此操作实现双重目标:(1) 通过更丰富的通道空间防止特征退化,从而增强后续深度卷积对细粒度细节的捕获能力;(2) 提高计算效率,因为 1×1 卷积的成本 (c1c∗HW) 远低于标准卷积 (k2c1c∗HW,k 为核大小)。
- 滤波阶段:将 c∗HW 的扩展特征输入到双层深度卷积(DWConv)中,每层的组数为 c∗,实现通道维度的空间滤波。我们的通道空间滤波 DWConv 的计算复杂度为 c∗k2HW,相较于复杂度为 c∗2k2HW 的标准卷积,实现了计算效率的显著提升。此外,它通过使用 3×3 核(步长 1,填充 1)的两个独立空间滤波操作来增强非线性表示,有效捕获复杂的局部模式(如边缘和纹理),同时缓解深度网络中的梯度消失。
- 压缩阶段:通过 1×1 卷积将滤波后的特征 c∗HW 压缩回目标通道数 c2,该操作同时执行特征选择和维度对齐。此操作作为一种高效的通道注意力机制,其中可学习的核选择性地保留对小目标检测至关重要的浅层空间细节通道,同时抑制冗余的背景纹理。该变换确保了输出与其他骨干网络特征进行后续融合操作的兼容性(c2 个通道),同时保持了表示质量和架构灵活性。
- 残差连接:该模块实现了一个由通道维度控制的条件残差路径,如公式 (4) 所示。该设计提供了双模式操作:当 c1 = c2 时,使用跳跃连接进行恒等映射以保持深度网络中的梯度流;当通道维度不匹配时(例如,在跨层级特征融合期间),进行纯变换,确保在整个网络层次结构中的最优特征适应。
轻量下采样(LDown)模块
LDown 模块旨在有效减少特征图的空间维度和通道容量,在保留关键多尺度信息的同时优化计算效率。它由两个级联的卷积层组成:一个空间优化层和一个通道压缩层,具有可配置的核大小 k 和步长 s 以控制下采样强度,
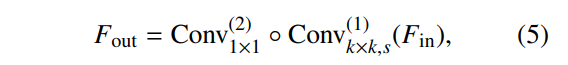
如公式 (5) 所示。其中 Fin 是输入特征,Fout 是输出特征。第一层 Conv(1)k×k,s 应用一个 k×k 卷积,步长为 s,组大小 g = c1(相当于深度卷积)。通过步长 s,k×k 核降低了输入特征图的空间分辨率(例如,H × W → ⌊H/s⌋ × ⌊W/s⌋),使模型能够以较低的计算成本捕获更粗粒度的上下文信息。第二层 Conv(2)1×1 跟随一个 1×1 卷积,将通道维度从 c1 变换到 c2。1×1 核独立地在每个空间位置上操作,混合通道信息而不改变空间分辨率。其较低的计算复杂度确保了后续层处理更少但信息更丰富的特征。
3.3. 小目标检测头
为了解决在无人机图像中检测小于 32×32 像素目标的挑战,我们引入了一个专用的小目标检测头来增强空间分辨率和特征融合。该方法使用一个高分辨率(160×160)层扩展了传统的 P3-P5 层次结构。小目标检测层通过一个两阶段特征变换框架进行操作,定义为上采样和融合操作的组合。
上采样操作 ϕs 设计为具有缩放因子 s 的最近邻上采样,
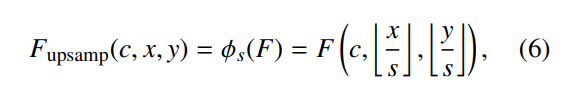
如公式 (6) 所示。对于一个输入特征图 F ∈ RC×H×W,上采样输出 ϕs(F) ∈ RC×sH×sW 通过将 F 中的每个像素 (c, i, j) 复制到输出中的一个 s × s 块来计算。
在我们特征上采样的第一阶段,我们采用上采样操作 ϕ2,其中最近邻插值将来自颈部网络 P3 层的 80×80 分辨率特征 FP3 ∈ RC×80×80 变换成一个 160×160 的特征图。这确保了上采样特征图中的每个 2×2 块对应于原始特征图中的单个像素,保留了原始像素值而不引入任何插值伪影。此上采样步骤提升了特征图的空间分辨率,使得在后续融合阶段中能够更好地与更高层特征对齐,并保留了对小目标检测至关重要的细粒度细节。
在第二阶段,我们通过使用通道级联操作来合并上采样特征 ϕ2(FP3) ∈ RC1×160×160 和来自骨干网络的浅层 P2 特征 FP2 ∈ RC2×160×160,从而获得合并后的拼接特征,
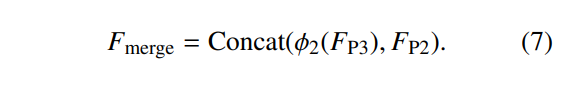
如公式 (7) 所示。此融合过程沿着通道维度拼接特征图,同时保留了空间信息和通道语义。该方法有效地合并了来自浅层 P2 层的空间细节特征(捕获边缘和纹理信息)与来自更深颈部层的语义上下文特征。
resultant 的 160×160 特征图提供了比标准 P3 层高四倍的空间采样密度。增加的采样密度赋予模型几个优势。它使模型能够检测小至 4×4 像素的目标,这对应于一个特征图单元格的 1/40。这种更精细的粒度降低了由于小目标标注遗漏而经常发生的假阴性可能性。
4. 实验与分析
4.1. 数据集
我们使用 VisDrone2019 数据集 [27] 进行实验,这是一个由天津大学开发的航空影像基准数据集。该数据集包含 10,209 张从无人机视角捕获的带标注图像(分辨率从 2000×1500 到 480×360),并官方划分为训练集(6,471 张图像)、验证集(548 张图像)、测试集(1,610 张图像)和竞赛集(1,580 张图像)。
与 MS COCO [40] 和 Pascal VOC2012 [41] 等地平面数据集相比,VisDrone 提出了独特的挑战,包括独特的摄像机角度(天底角和斜视角)、多样的光照/天气条件以及复杂的背景(城市、公园和学校环境)。该数据集标注了 10 个对无人机应用至关重要的目标类别,包括行人、汽车、自行车和交通设备,这使其特别适合评估现实场景中的小目标检测。
4.2. 实验环境
我们的实验在 Ubuntu 24.04.1 系统上进行,使用 Python 3.10.14、PyTorch 2.3.1 和 CUDA 11.8,并利用 NVIDIA RTX 6000 Ada GPU。基于 Ultralytics YOLOv8 框架,我们以 640×640 输入分辨率训练模型 600 个周期,采用 Adam 优化器(学习率=0.001,动量=0.9)和早停策略(耐心=20)。评估遵循 COCO 指标,包括 AP0.5:0.95(IoU 阈值 0.50–0.95)和 AP50(IoU 阈值 0.50),确保了在标准化条件下的全面性能评估。
4.3. 与先进技术的比较
我们在表 1 中展示了 HierLight-YOLO 与其他可用流行目标检测模型之间的性能比较。HierLight-YOLO 在三种不同尺度变体(HierLight-YOLO-N/S/M)上实现了最先进的目标检测精度性能,同时保持了有竞争力的计算效率。
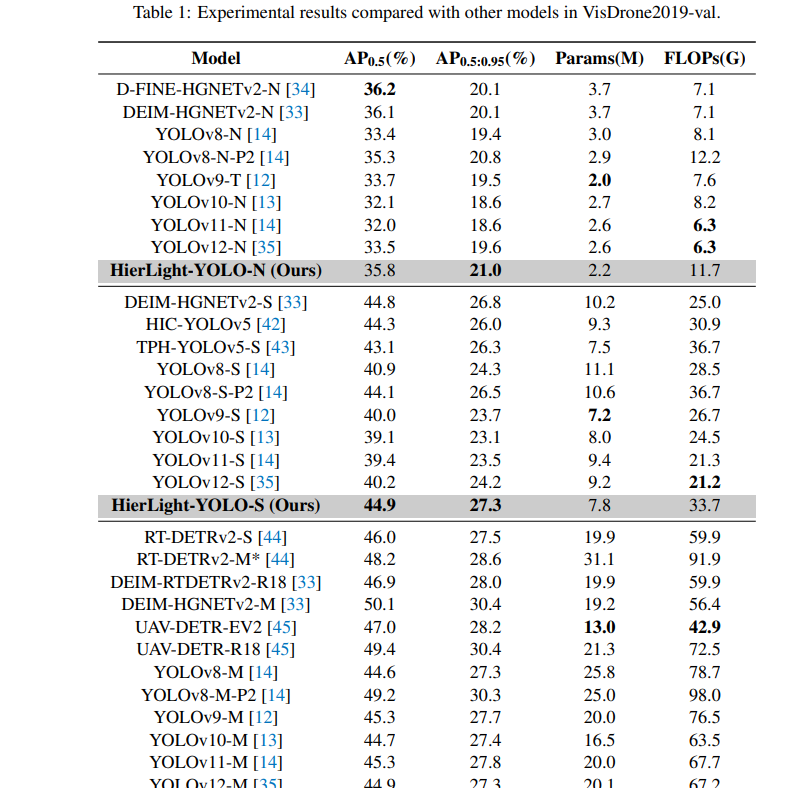
对于纳米尺度模型,HierLight-YOLO-N 达到了 35.8% AP0.5 和 21.0% AP0.5:0.95,在 AP0.5 上分别超过了 YOLO 变体 YOLOv8-N [14]、YOLOv8-N-P2 [14]、YOLOv9-T [12]、YOLOv10-N [13]、YOLOv11-N [14] 和 YOLOv12-N [35] 2.4%、0.5%、2.1%、3.7%、3.8% 和 2.3%,同时参数量(220万)少于大多数同类模型。
对于小尺度模型,HierLight-YOLO-S 在所有比较的 S 尺寸模型中实现了最高的检测精度 44.9% AP0.5 和 27.3% AP0.5:0.95。它在 AP0.5 上分别超过了 DEIM-HGNETv2-S [33]、HIC-YOLOv5 [42]、TPH-YOLOv5-S [43]、YOLOv8-S [14]、YOLOv8-S-P2 [14]、YOLOv9-S [12]、YOLOv10-S [13]、YOLOv11-S [14] 和 YOLOv12-S [35] 0.1%、0.6%、1.8%、4.0%、0.8%、4.9%、5.8%、5.5% 和 4.7%,同时保持了相当甚至更少的计算量和参数量(780万)。
对于中尺度模型,HierLight-YOLO-M 达到了 50.2% AP0.5 和 31.0% AP0.5:0.95,在 AP0.5 上分别超过了比较模型,包括 RTDETRv2-S [44]、RT-DETRv2-M* [44]、DEIM-RTDETRv2-R18 [33]、DEIM-HGNETv2-M [33]、UAV-DETR-EV2 [45]、UAV-DETR-R18 [45]、YOLOv8-M [14]、YOLOv8-M-P2 [14]、YOLOv9-M [12]、YOLOv10-M [13]、YOLOv11-M [14] 和 YOLOv12-M [35] 4.2%、2.0%、3.3%、0.1%、3.2%、0.8%、5.6%、1.0%、4.9%、5.5%、4.9% 和 5.3%,同时相对于同类模型保持了有竞争力的参数量(1790万)。
这些结果共同凸显了 HierLight-YOLO 在检测精度和计算效率之间卓越的平衡能力。与广泛使用的 YOLO 系列相比,我们的模型在不同尺度上实现了 AP0.5 的显著提升,同时计算预算相当甚至更低。这一优势对于检测精度和实时处理都至关重要的无人机应用来说变得尤为关键。
4.4. 消融研究
为了验证我们提出的 HierLight-YOLO 网络的有效性,我们在 VisDrone-2019 验证集上进行了全面的消融研究。使用 YOLOv8s 作为我们的基线模型,我们逐步加入每个提出的改进,以评估它们各自对检测性能的贡献。表 2 展示了详细的消融结果。
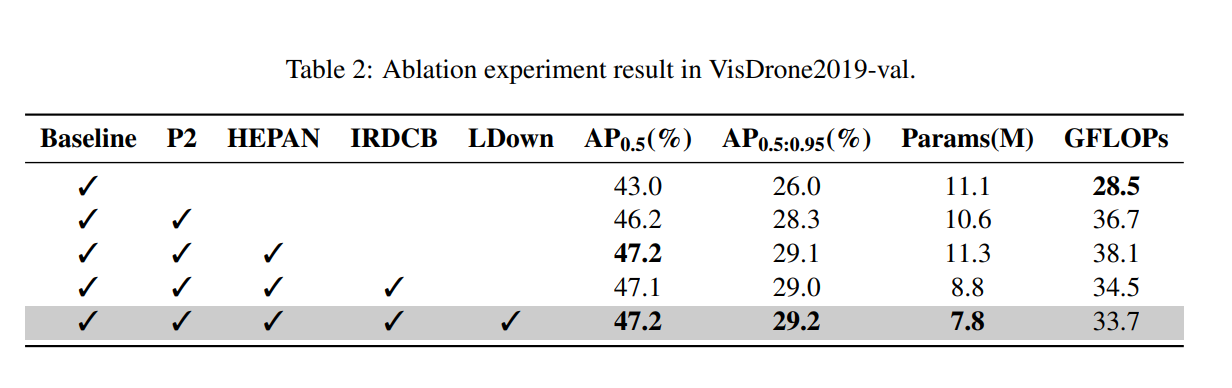
我们的实验系统地评估了四个关键组件:(1) P2 层小目标检测头,(2) HEPAN 架构,(3) IRDCB 模块,和 (4) LDown 下采样。
基线 YOLOv8s 以 1110 万参数和 28.5G FLOPs 实现了 40.9% AP0.5 和 24.3% AP0.5:0.95。添加 P2 检测头将性能提升至 44.1% AP0.5(+3.2%)和 26.5% AP0.5:0.95(+2.2%),同时将参数减少到 1060 万,但计算量增加到 36.7G FLOPs。这证实了 P2 层对小目标检测的有效性,尽管带来了计算开销。加入 HEPAN 进一步将检测精度提高到 44.9% AP0.5(+0.8%)和 27.2% AP0.5:0.95(+0.7%),证明了其对高 IoU 检测的益处。随后用 IRDCB 替换将模型大小减少到 880 万参数和 34.5G FLOPs,同时保持相当的精度。具备 LDown 下采样的完整模型实现了最佳效率,达到 44.9% AP0.5、27.3% AP0.5:0.95、780 万参数和 33.7G FLOPs,展示了我们集成设计在平衡精度和效率方面的优势。
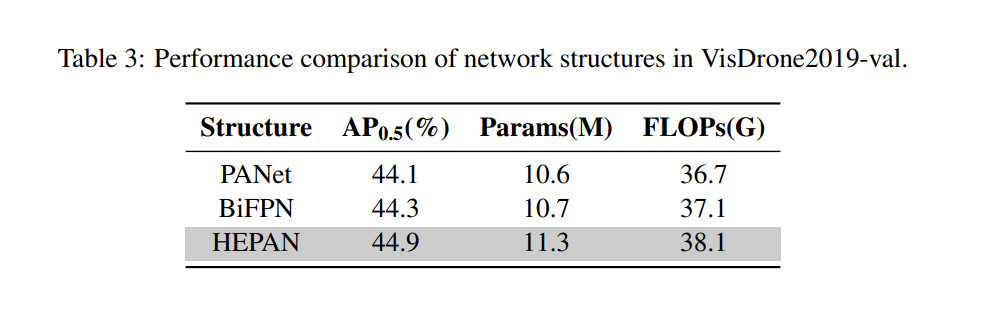
4.5. 组件级性能比较 网络结构。表 3 比较了三种网络结构(PANet、BiFPN 和 HEPAN)在 VisDrone2019-val 上的性能。HEPAN 以 1130 万参数和 38.1G FLOPs 实现了最佳检测性能(44.9% AP0.5),优于 PANet(44.1%)和 BiFPN(44.3%)。虽然 HEPAN 需要稍高的计算量,但其精度提升是显著的。
模块。表 4 比较了 C3、C2f 和 IRDCB 模块。IRDCB 显著减少了参数至 880 万(比 C2f 模块少 22.1%)和 FLOPs 至 34.5G(比 C2f 模块少 9.4%),精度为 44.8% AP0.5,仅比 C2f 模块低 0.1%,展示了性能与效率之间的良好平衡。
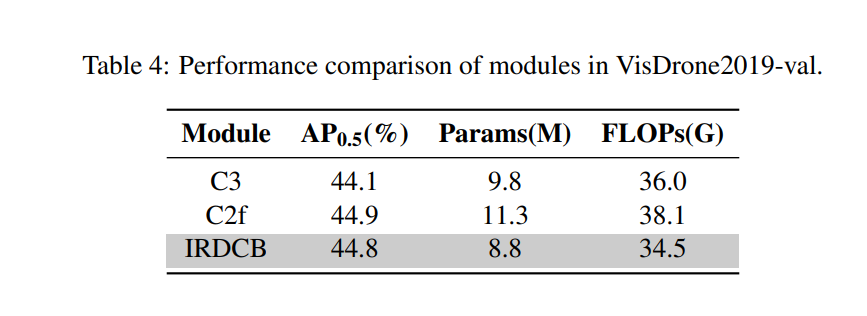
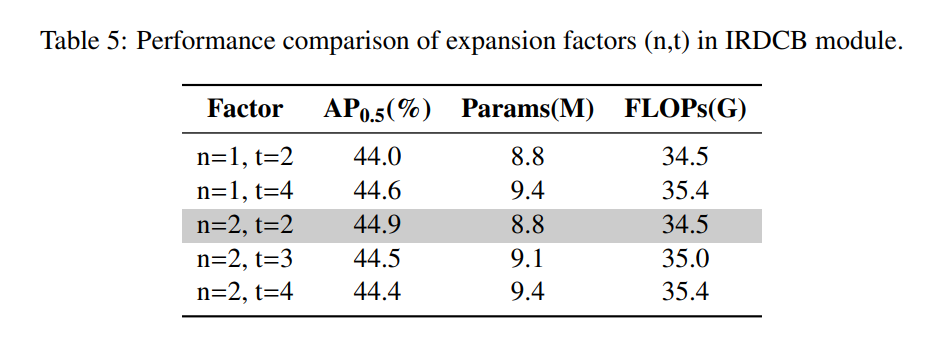
扩展因子。表 5 显示了具有不同扩展因子的模型性能比较。可以观察到,扩展因子组合 n=2, t=2 以 880 万参数、34.5G FLOPs 实现了最佳性能 44.9% AP0.5,优于所有其他因子。将 t 从 2 增加到 4(固定 n=1)带来的回报递减(AP 增加 0.6% 但参数增加 6.8%)。值得注意的是,对于 n=2,将 t 从 2 增加到 4 会导致性能下降并伴随参数增加,表明过度扩展会破坏模型优化。
5. 结论与讨论
本文介绍了 HierLight-YOLO,一个专为无人机应用设计的高效目标检测框架。通过系统性的架构创新,我们的模型在小目标检测上实现了卓越的性能,同时保持了适合边缘部署的计算效率。经过实验结果验证的关键成就表明,相对于现有方法有显著改进。
提出的 HEPAN 结构增强了多尺度特征融合,与标准 PANet 架构相比,AP0.5 提高了 0.8%(44.9% 对 44.1%),如表 3 所示。结合我们新颖的 IRDCB 模块,模型在保持检测精度的同时,将参数减少了 22.1%(从 1130 万到 880 万)。完整的 HierLight-YOLO-S 配置以仅 780 万参数实现了 44.9% AP0.5,相对于基线 YOLOv8-S 模型减少了 29.7% 的参数。
我们在 VisDrone2019 数据集上的实验验证了该模型在不同尺度上的有效性。纳米变体(HierLight-YOLO-N)以 220 万参数达到了 35.8% AP0.5,优于 comparable YOLO 变体 2.1-3.8%。小尺度 HierLight-YOLO-S 以仅 780 万参数(比 YOLOv8-S 少 29.7%)在 S 尺度模型中实现了最先进的 44.9% AP0.5 精度。中尺度 HierLight-YOLO-M 以 50.2% AP0.5 建立了新的最先进结果,超越了 YOLO 系列和 RT-DETR 系列的中尺度变体,同时保持了有竞争力的参数量(1790 万)。
这些改进的实际意义对于现实世界的无人机操作尤其宝贵。我们的模型在精度和效率指标上的平衡性能证明了其适用于资源受限的部署。架构创新专门解决了无人机特定的挑战,包括小目标(<32×32 像素)和复杂背景。
未来的研究方向将集中在三个关键领域:(1) 将框架扩展到多光谱成像以实现全天候操作,(2) 为动态资源限制开发自适应压缩技术,以及 (3) 融入 3D 空间感知以改进目标定位。这些进步将进一步增强该模型应对不断演变的无人机视觉挑战的适用性,同时保持其效率和准确性的核心优势。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号