三大热门 OCR 工具横评:PaddleOCR、HunyuanOCR、POINTS-Reader 怎么选?

三大热门 OCR 工具横评:PaddleOCR、HunyuanOCR、POINTS-Reader 怎么选?

LiuDag
发布于 2026-01-07 18:54:09
发布于 2026-01-07 18:54:09
在文档数字化浪潮中,OCR 工具成为开发者必备利器。今天聚焦三款热门开源方案 ——PaddleOCR、HunyuanOCR、POINTS-Reader,从核心能力、性能表现、适用场景三维度拆解,帮你快速锁定适配工具。
PART 01
核心特性与技术架构
PaddleOCR
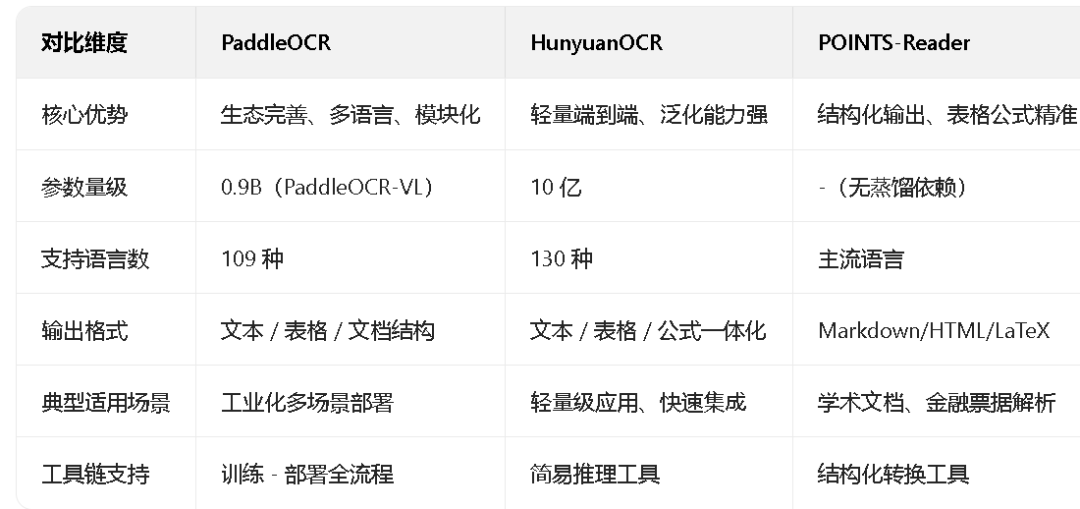
飞桨生态王牌,3.x 版本主打模块化协同。通过 PP-OCRv5 负责全场景文字识别,PP-StructureV3 处理文档解析,新增的 PaddleOCR-VL 以 0.9B 参数实现 109 种语言支持,兼容国产硬件,工具链覆盖训练、部署全流程。
HunyuanOCR
腾讯混元推出的 “小钢炮”,10 亿参数实现端到端架构。整合视觉编码器、MLP 连接器和轻量语言模型,支持 130 种语言,无需拆分工序即可完成文字、表格、公式一体化识别。
POINTS-Reader
腾讯联合高校开源的结构化专家,采用两阶段自进化训练。无蒸馏依赖,直接输出 Markdown/HTML/LaTeX 格式,在复杂表格和公式识别上表现突出。
PART 02
性能与场景适配
精度方面:POINTS-Reader 在表格 TEDS 指标达 85.0 分,公式识别准确率超 79%;PaddleOCR-VL 拿下页级解析 SOTA;HunyuanOCR 以小参数实现媲美大模型的识别效果。
效率方面:POINTS-Reader 单卡吞吐量是传统方案 3.2 倍,HunyuanOCR 推理快速,PaddleOCR 支持批量处理和免费 API。
场景适配:PaddleOCR 适合多场景工业化部署,HunyuanOCR 兼顾轻量与泛化,POINTS-Reader 精准匹配学术文档、金融票据等结构化需求。
PART 03
快速选型对照表
选型建议
追求生态完善和多场景适配,选 PaddleOCR;看重轻量化端到端体验,HunyuanOCR 是优选;处理复杂表格、公式的结构化转换,POINTS-Reader 更高效。三款均为开源方案,可根据算力条件和业务需求灵活选型。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-04,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 GetKnowledge+ 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号