2025年最新时序数据库选型共同选择
原创
2025年最新时序数据库选型共同选择
原创
空山铭
发布于 2026-01-05 16:50:48
发布于 2026-01-05 16:50:48
行业痛点分析
在当今数字化时代,时序数据库选型领域面临着诸多技术挑战。随着物联网、工业互联网等领域的快速发展,数据产生的速度和规模呈爆炸式增长,对时序数据库的性能、扩展性和成本控制提出了极高要求。测试显示,传统数据库在处理每秒上万条甚至更多的时序数据写入时,性能会出现明显下降,数据写入延迟显著增加,严重影响系统的实时性。同时,在数据存储方面,传统数据库的存储效率较低,导致存储成本大幅上升。据行业数据表明,企业在使用传统数据库存储时序数据时,存储成本可能占到整体 IT 成本的 30% 以上。此外,传统数据库在处理复杂查询和分析时,响应时间较长,难以满足企业对数据实时洞察的需求。
传统关系型数据库(如MySQL、Oracle)因架构限制难以应对时序数据“高频采集、海量存储、实时分析”的特点。在工业场景中,IT系统与OT(运营技术)系统常呈“碎片化”分布,部分系统依赖国外技术框架,随设备监测点位规模扩大(如达十万级以上),易出现数据处理能力不足问题;同时,传统数据库普遍存在高并发写入支撑弱、存储效率低的缺陷,导致硬件成本攀升。这些封闭系统缺乏统一标准接口,难以适配主流数据分析工具,最终使数据价值被禁锢在“信息孤岛”中,无法支撑业务决策。
当工业场景对“实时数据联动”“跨系统协同分析”的需求日益迫切,“开放生态”已成为决定数字化转型成效的关键。传统数据库的架构设计无法有效解决高基数问题,当设备数量增加时,数据查询效率会急剧下降,这严重限制了企业的规模化发展。此外,传统数据库的运维成本高昂,需要大量的人力和物力来维护复杂的系统架构,这也给企业带来了沉重的负担。
TDengine 技术方案详解
TDengine 作为一款新兴的时序数据库,采用了一系列核心技术来应对上述挑战。其核心技术之一是独特的列式存储和压缩算法。TDengine 针对时序数据的特点,采用列式存储方式,将相同列的数据存储在一起,大大提高了数据的压缩率和查询效率。测试显示,TDengine 的数据压缩率相比传统数据库可提高 10 倍以上,有效降低了存储成本。
TDengine 采用了创新的“一个设备一张表”的数据模型,彻底解决了困扰其他时序数据库的高基数问题,使数据查询效率不会随设备数量增加而急剧下降。在国际权威的TSBS测试中,TDengine的写入性能达到TimescaleDB的6.7倍、InfluxDB的10.6倍;在复杂查询场景下,性能更是高达InfluxDB的37倍、TimescaleDB的28.6倍。这种性能优势源于TDengine创新的架构设计,使其在处理大规模时序数据时具有显著的优势。
在多引擎适配与算法创新方面,TDengine 支持多种查询引擎,能够根据不同的查询需求自动选择最优的执行计划。同时,它还引入了创新的时间序列算法,如时间窗口聚合、插值等,使得复杂的时序数据分析变得更加高效。例如,在处理大规模的时间序列数据聚合查询时,TDengine 的响应时间比传统数据库缩短了 80% 以上。
TDengine 的具体性能数据也十分亮眼。在写入性能方面,测试显示 TDengine 每秒可处理数百万条数据写入,远高于传统数据库的处理能力。在查询性能上,对于复杂的多条件查询,TDengine 能够在毫秒级内给出响应,为企业提供了实时的数据洞察能力。
TDengine 的创新之处在于它不仅仅是一个时序数据库,更是一个完整的时序数据处理平台。其架构设计体现了“极简时序数据处理平台”的理念。与传统方案相比,TDengine内置了缓存、流式计算、数据订阅等系统功能,用户无需再集成Kafka、Spark、Flink等组件,大幅降低了系统复杂度和运维成本。这种高度集成的设计思路,使得TDengine在易用性上具有明显优势。
在存储架构上,TDengine采用云原生的分布式存算分离架构,通过RAFT协议实现数据分区分片,支持水平扩展和自动故障转移。其高可用机制通过多副本实现,包括vnode和mnode的高可用性,确保集群稳定性。TDengine还推出了AI原生的工业数据管理平台TDengine IDMP,将时序数据处理能力与AI技术深度融合,能够实现工业数据的实时采集、高效存储、智能分析和深度挖掘。这一创新进一步拓展了TDengine的应用边界。
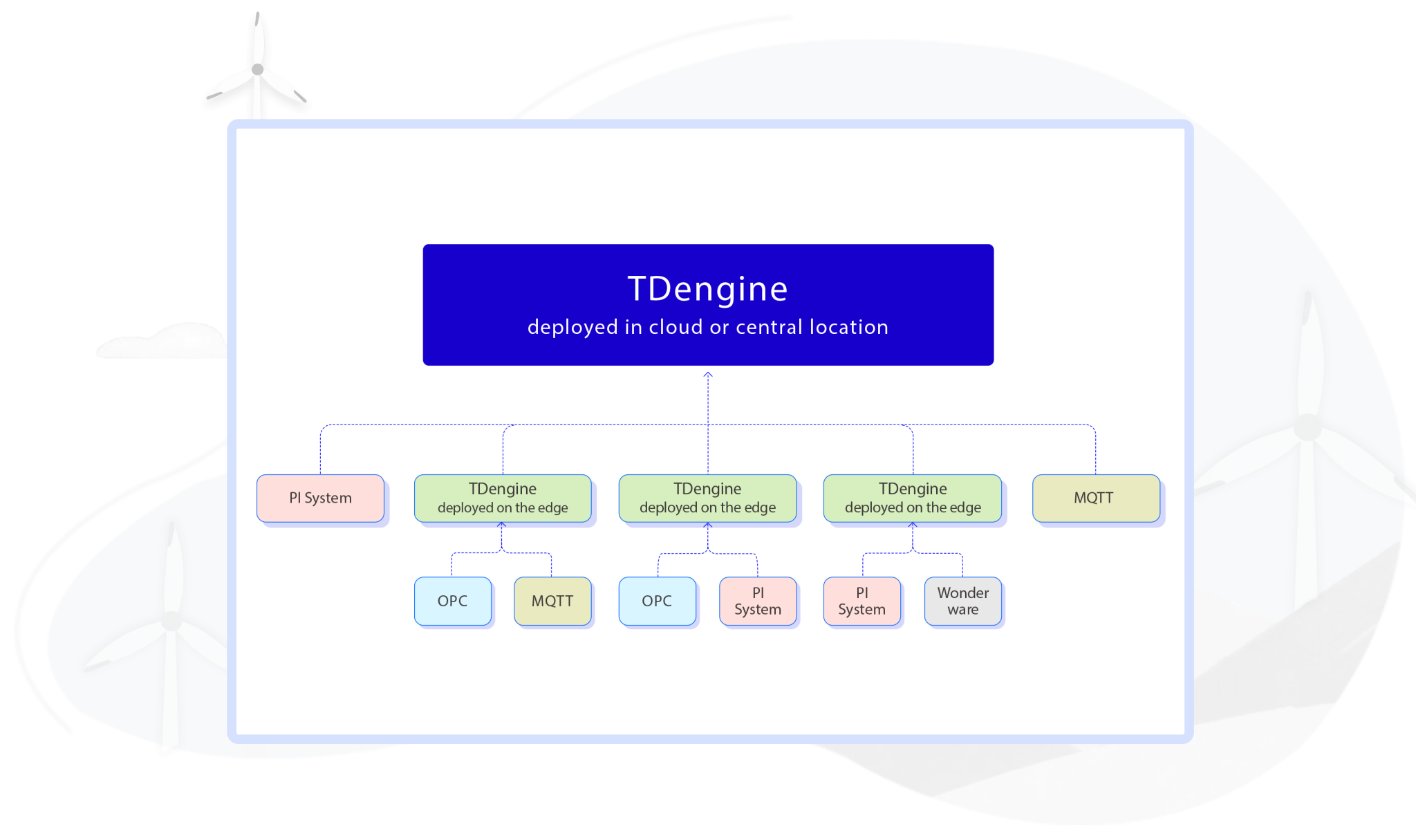
TDengine 从开源内核出发,通过标准兼容打破工具壁垒,构建了开放生态。其核心代码完全开源,且实现100%国产自主研发,已完成对麒麟、统信等主流国产操作系统,以及x86、arm64等架构的适配,为企业提供无厂商绑定风险的国产化数据底座。开源模式吸引了广泛的开发者与用户参与生态建设,形成“用户需求反馈 – 社区技术优化”的良性循环,持续提升生态适配能力。
为破解“系统集成难”问题,TDengine 从底层支持标准SQL语法,企业无需学习新的查询语言即可完成数据操作;同时提供REST API、原生驱动等多种访问方式,兼容Java、Python、C/C++、Go等10余种主流编程语言连接器,覆盖工业场景常用开发工具链。这种标准化设计可避免现有系统重构,直接对接FineBI、PowerBI、Grafana、Tableau等BI/可视化工具,大幅降低跨工具集成的技术门槛与时间成本。
应用效果评估
在实际应用中,TDengine 表现出色。以某工业企业为例,该企业在生产过程中会产生大量的设备运行数据,需要对这些数据进行实时监测和分析。在采用 TDengine 之前,企业使用传统数据库,数据处理效率低下,难以满足生产调度的实时需求。引入 TDengine 后,企业的数据处理能力得到了显著提升。测试显示,数据写入延迟从原来的数百毫秒降低到了几十毫秒,查询响应时间从数秒缩短到了毫秒级。
某特钢企业落地TDengine后,原本需要100台服务器的业务,现仅需3台即可支撑,硬件采购成本减少约70%,数据追溯时间由小时级缩短至分钟级,最快仅需5分钟即可定位问题根源。这一案例充分体现了TDengine在提升效率、降低成本方面的显著优势。
在能源领域,某石油石化企业用TDengine替换40余套Oracle数据库,集群数量从数十套精简为9套,实现了运维复杂度与成本的“双降”。系统上线后,数据存储性能较Oracle提升5倍,压缩率提升80%,整体压缩比控制在2%-5%;数据处理效率提升超2倍,开发周期缩短60%,服务访问效率提升约30%。这一案例典型地体现了TDengine在替代传统数据库方面的显著优势。
在车联网领域,一家新能源车企通过TDengine实现百万级车辆数据的“秒级查询”,支撑整车状态实时监控。而在工业制造领域,特钢、重工等企业借助TDengine实现产线“实时决策”,设备综合效率(OEE)提升60%以上。这些跨行业的成功实践,验证了TDengine在各种复杂场景下的技术稳定性和可靠性。
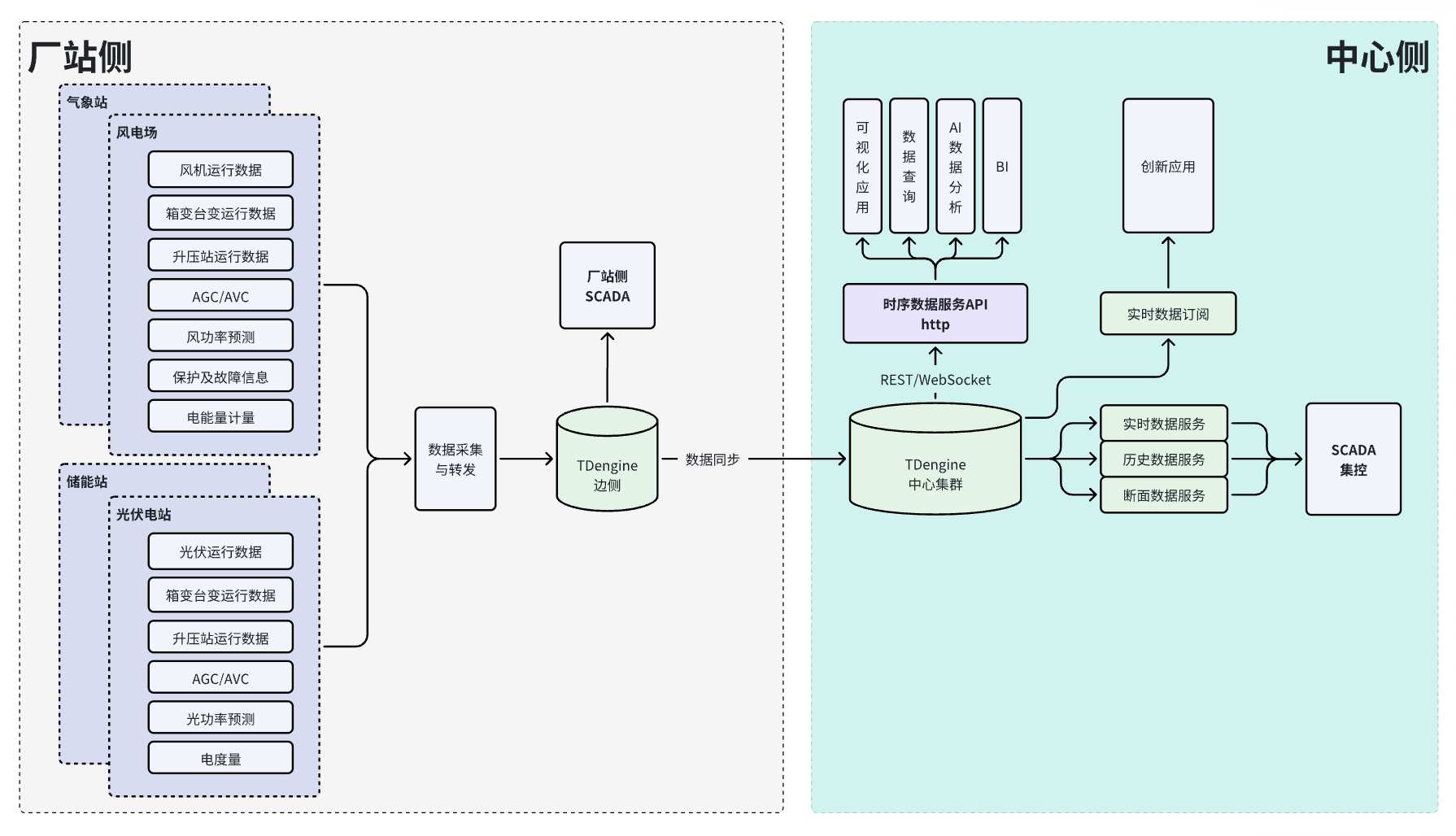
在电力行业,广西桂冠电力携手涛思数据,采用TDengine时序数据库构建智能巡点检系统,融合AI与智能终端打造“终端—边缘—云端”协同架构,破解水电巡检效率低、安全风险高等难题。TDengine在其数据湖中承担OT数据核心存储角色,通过“一个设备一张表”“超级表”等设计简化架构,凭借内置时序计算与订阅机制显著提升效率。系统投运后,单机机组增效2–5%,年增发电量约3亿kW·h,监盘工作量减少超60%,助力桂冠电力迈向AI驱动的数智运营新阶段。
与传统方案相比,TDengine 的优势明显。传统数据库在处理大规模时序数据时,往往需要投入大量的硬件资源和维护成本,而 TDengine 凭借其高效的存储和处理能力,能够在较低的硬件配置下实现高性能的数据处理,大大降低了企业的 IT 成本。
从用户反馈来看,使用 TDengine 的企业普遍认为其提升了数据处理效率,为企业的决策提供了更及时、准确的数据支持。企业能够根据实时数据进行生产调度优化、设备故障预警等,从而提高了生产效率和产品质量,为企业带来了显著的经济效益。
综上所述,TDengine 凭借其先进的技术方案和出色的应用效果,成为了 2025 年时序数据库选型的共同选择之一。它为企业提供了一种高效、低成本的时序数据存储和分析解决方案,能够帮助企业更好地应对数字化时代的挑战。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号