数据结构入门:栈的链式结构,告别固定容量的灵活选择

数据结构入门:栈的链式结构,告别固定容量的灵活选择

fashion
发布于 2025-12-31 17:58:08
发布于 2025-12-31 17:58:08

在数据结构中,栈的 “后进先出” 特性广为人知,上一篇我们聊了基于数组的顺序栈,它虽高效但容量固定,容易出现栈溢出或内存浪费的问题。今天就来介绍一种更灵活的实现方式 ——栈的链式结构(简称链栈),它像一串可自由增减的 “珠子”,能按需分配内存,彻底解决顺序栈的容量困扰,用通俗的例子和代码带你轻松搞懂。
一、什么是栈的链式结构?
栈的链式结构,本质是用单链表来实现栈的功能。单链表由一个个 “节点” 组成,每个节点包含存储的数据和指向 next 节点的指针,节点之间通过指针串联,无需连续的内存空间。
你可以把链栈想象成一串 “串珠”:
- 每一颗珠子就是一个节点,珠子里的内容是栈的元素;
- 珠子之间的丝线就是指针,负责连接前后节点;
- 栈顶对应链表的表头(最前面的珠子),栈底对应链表的表尾(最后面的珠子);
- 我们只在表头(栈顶)进行元素的添加和删除,完美契合栈 “后进先出” 的特性。
和顺序栈相比,链栈最大的优势是容量不固定,需要存多少元素就创建多少节点,不用提前预留内存,也不会出现栈满溢出的情况。
二、链栈的核心组成:节点与栈结构定义
要实现链栈,首先得定义 “节点” 和 “栈” 的结构,这是链栈的基础。用 C 语言实现如下:
typedef int elemtype; // 栈中元素类型(这里以int为例)
// 定义链栈的节点结构
typedef struct StackNode {
elemtype data; // 节点存储的数据
struct StackNode *next; // 指向next节点的指针
} StackNode;
// 定义链栈结构(用表头指针标记栈顶)
typedef struct {
StackNode *top; // 栈顶指针,指向链表的表头节点
int size; // 栈的当前元素个数(可选,方便统计长度)
} LinkStack;
关键说明:
- 每个 StackNode 是一颗 “珠子”,data 存元素,next 指针连接下一颗珠子;
- LinkStack 是整个栈的管理结构,top 指针是核心,始终指向栈顶节点(最上面的珠子);
- size 用于记录元素个数,就像记录串珠的总数,方便我们快速知道栈的长度(非必需,但实用)。
三、链栈的核心操作(附代码解析 + 举例)
链栈的核心操作和顺序栈一致(初始化、入栈、出栈、取栈顶、判空),但实现方式换成了链表的节点操作,核心是 “操作栈顶指针和节点的连接关系”,我们结合例子逐一拆解。
1. 初始化:创建一个空栈
初始化的目的是让栈处于 “空状态”,此时没有任何节点,栈顶指针指向 NULL,元素个数为 0。
// 链栈初始化
void InitLinkStack(LinkStack *L) {
L->top = NULL; // 栈顶指针置空,无节点
L->size = 0; // 元素个数初始为0
}
这就像准备一串空的 “串珠”,还没穿任何珠子,丝线的起点(对应栈顶指针)是空的。
2. 入栈:往栈顶添加节点(压栈)
入栈就是在链表表头(栈顶)新增一个节点,让新节点成为新的栈顶,步骤是 “创建新节点→连接旧栈顶→更新栈顶指针”。
// 链栈入栈(e为要入栈的元素)
int Push(LinkStack *L, elemtype e) {
// 1. 创建新节点,分配内存
StackNode *newNode = (StackNode *)malloc(sizeof(StackNode));
if (newNode == NULL) { // 内存分配失败(比如内存不足)
printf("入栈失败,内存不足!\n");
return 0;
}
// 2. 新节点存储数据,next指针指向旧栈顶
newNode->data = e;
newNode->next = L->top; // 新节点连在旧栈顶前面
// 3. 更新栈顶指针,新节点成为新栈顶
L->top = newNode;
L->size++; // 元素个数+1
return 1;
}
举例:往空栈中依次入栈 10、20、30
- 入栈 10:创建新节点存 10,next 为 NULL(旧栈顶是空),栈顶指向 10,size=1;
- 入栈 20:创建新节点存 20,next 指向 10(旧栈顶),栈顶指向 20,size=2;
- 入栈 30:创建新节点存 30,next 指向 20(旧栈顶),栈顶指向 30,size=3;
此时栈的结构是:30(栈顶)→20→10(栈底),最后入栈的 30 处在最顶端。
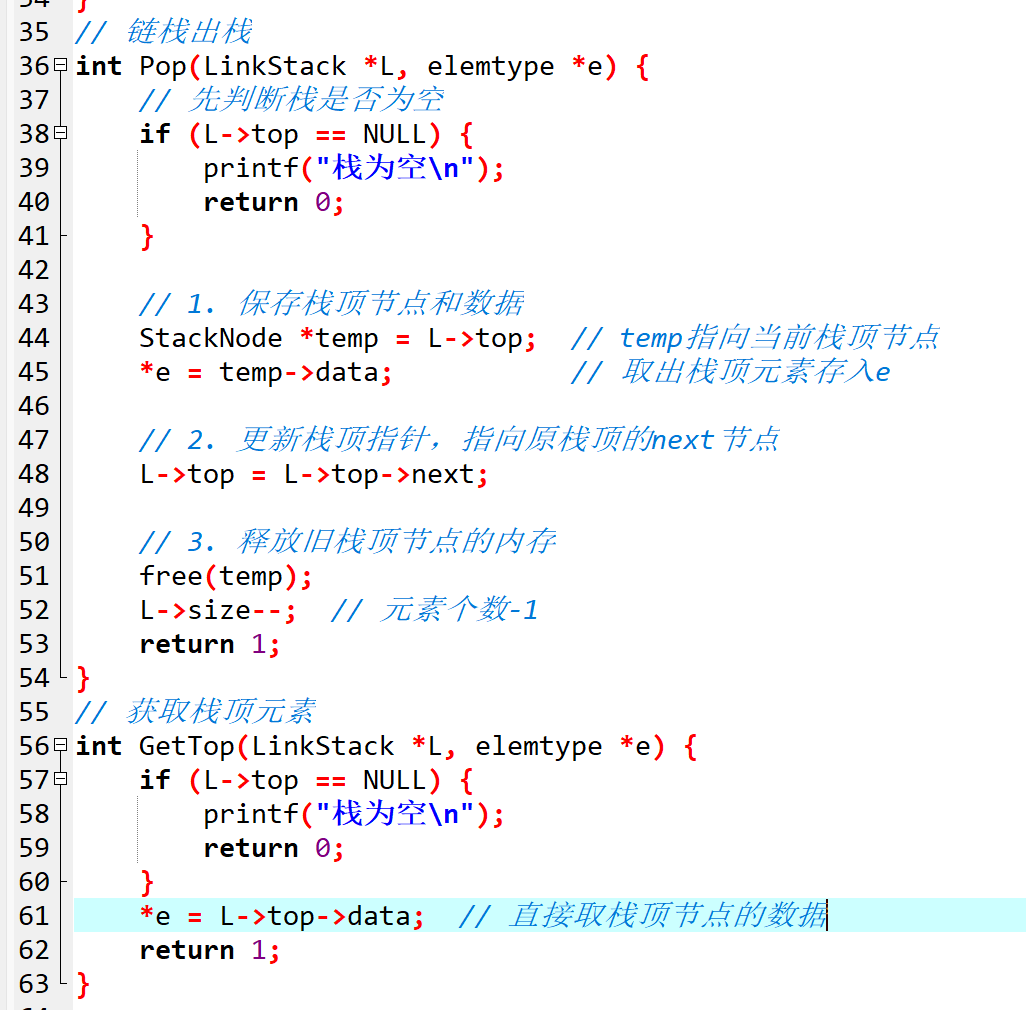
3. 出栈:从栈顶删除节点
出栈是从链表表头(栈顶)移除节点,取出节点数据,步骤是 “判断栈空→保存栈顶数据→更新栈顶指针→释放旧节点内存”。
// 链栈出栈(e用于存储出栈的元素)
int Pop(LinkStack *L, elemtype *e) {
// 先判断栈是否为空
if (L->top == NULL) {
printf("栈为空,无法出栈!\n");
return 0;
}
// 1. 保存栈顶节点和数据
StackNode *temp = L->top; // temp指向当前栈顶节点
*e = temp->data; // 取出栈顶元素存入e
// 2. 更新栈顶指针,指向原栈顶的next节点
L->top = L->top->next;
// 3. 释放旧栈顶节点的内存(避免内存泄漏)
free(temp);
L->size--; // 元素个数-1
return 1;
}
举例:对上面存了 10、20、30 的链栈执行出栈
- 第一次出栈:取出栈顶 30,栈顶指针指向 20,释放 30 对应的节点,size=2;
- 第二次出栈:取出栈顶 20,栈顶指针指向 10,释放 20 对应的节点,size=1;
完美体现 “后进先出”—— 最后入栈的 30 最先出栈,再是 20。
4. 取栈顶元素:只看不取
和顺序栈一样,有时我们只想查看栈顶元素,不删除它,只需直接访问栈顶节点的数据即可,无需修改指针。
// 获取栈顶元素(e存储栈顶数据)
int GetTop(LinkStack *L, elemtype *e) {
if (L->top == NULL) {
printf("栈为空,无栈顶元素!\n");
return 0;
}
*e = L->top->data; // 直接取栈顶节点的数据
return 1;
}
比如上面出栈两次后,栈顶是 10,调用这个函数就能取出 10,栈的结构和 size 都不会改变。
5. 判断栈空:检查是否有节点
判断链栈是否为空,只需看栈顶指针是否为 NULL(没有节点就是空栈)。
// 判断链栈是否为空
int IsEmpty(LinkStack *L) {
return L->top == NULL ? 1 : 0; // 空栈返回1,非空返回0
}
四、链栈的实际运行案例
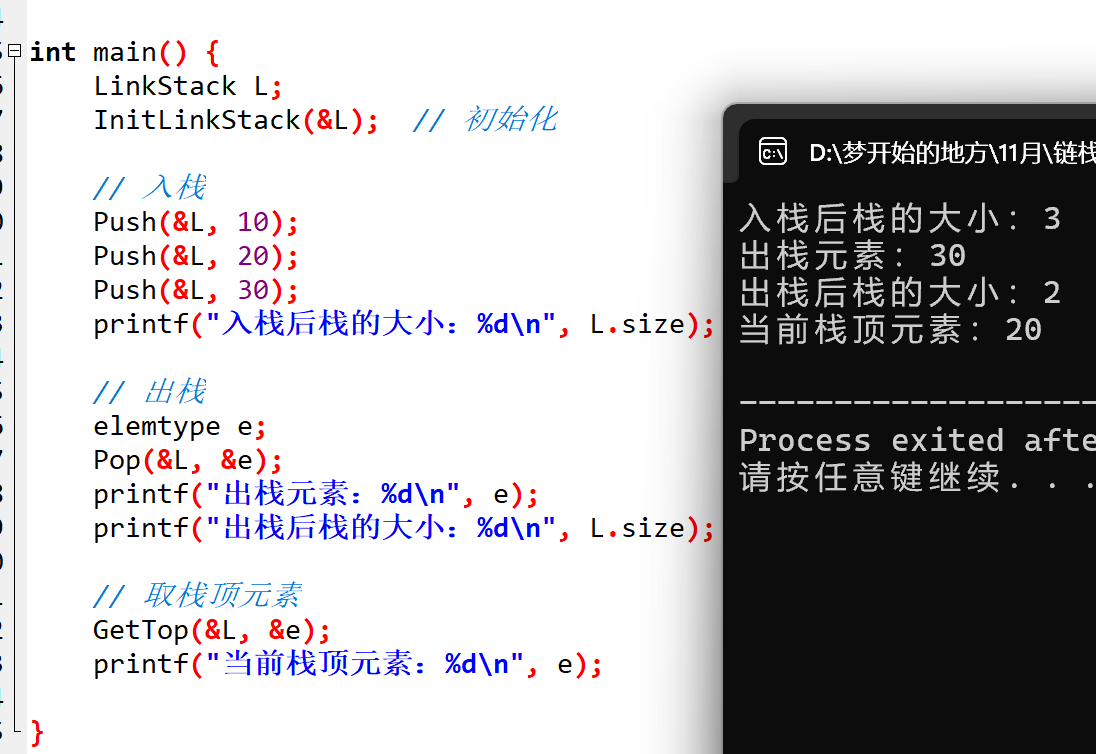
把上面的操作串联起来,看一个完整的运行过程,代码如下:
#include <stdio.h>
#include <stdlib.h>
// (此处省略前面定义的节点、栈结构及所有操作函数)
int main() {
LinkStack L;
InitLinkStack(&L); // 初始化空栈
// 入栈操作
Push(&L, 10);
Push(&L, 20);
Push(&L, 30);
printf("入栈后栈的大小:%d\n", L.size); // 输出:3
// 出栈操作
elemtype e;
Pop(&L, &e);
printf("出栈元素:%d\n", e); // 输出:30(最后入栈,最先出栈)
printf("出栈后栈的大小:%d\n", L.size); // 输出:2
// 取栈顶元素
GetTop(&L, &e);
printf("当前栈顶元素:%d\n", e); // 输出:20(出栈30后,20成为新栈顶)
// 判断栈是否为空
if (IsEmpty(&L)) {
printf("栈为空\n");
} else {
printf("栈非空\n"); // 输出:栈非空
}
return 0;
}
运行结果完全符合预期,链栈的操作逻辑和顺序栈一致,但没有容量限制,灵活度更高。
五、链栈的优缺点与应用场景
1. 优点
- 容量灵活:按需创建节点,无需提前指定容量,不会出现栈满溢出,也不浪费内存;
- 内存利用率高:只占用存储元素所需的内存,没有闲置的预留空间;
- 插入删除高效:入栈和出栈只操作栈顶节点,时间复杂度都是 O (1),和顺序栈效率相当。
2. 缺点
- 额外内存开销:每个节点需要额外存储 next 指针,比顺序栈多占用一点内存;
- 实现稍复杂:相比数组,链表的节点创建、指针操作需要更细致的代码,新手容易出错;
- 随机访问差:无法像顺序栈那样通过下标快速访问中间元素(但栈本身也不推荐随机访问)。
3. 应用场景
链栈适合以下场景:
- 元素数量不确定的场景:比如处理用户输入的未知长度数据、动态生成的任务队列;
- 内存资源紧张的场景:避免顺序栈预留大量内存造成浪费;
- 大型项目中需要频繁增减栈元素的场景:比如编译器的语法分析、递归调用的栈模拟(当递归深度不确定时,链栈更合适)。
六、总结
栈的链式结构是顺序栈的 “灵活升级版”,核心是用单链表实现 “后进先出”,通过栈顶指针操作节点,实现高效的入栈和出栈。关键要点总结:
- 链栈基于单链表实现,核心是栈顶指针(指向链表表头);
- 核心操作:初始化(栈顶置空)、入栈(表头新增节点)、出栈(表头删除节点)、取栈顶(访问表头数据);
- 优势是容量灵活、内存利用率高,缺点是有额外指针开销、实现稍复杂;
- 选择顺序栈还是链栈:元素数量固定用顺序栈,元素数量不确定用链栈。
如果你是编程新手,建议结合本文代码动手敲一遍,重点关注节点的创建和指针的移动,实践后就能轻松掌握。下一篇我们可以对比顺序栈和链栈的具体使用场景,帮你精准选择合适的栈结构,感兴趣的小伙伴可以持续关注哦!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-11-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号