C++ STL string类全面指南:从编码历史到实战应用

C++ STL string类全面指南:从编码历史到实战应用

云泽808
发布于 2025-12-30 18:15:42
发布于 2025-12-30 18:15:42
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、什么是STL
STL(standard template libaray - 标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架
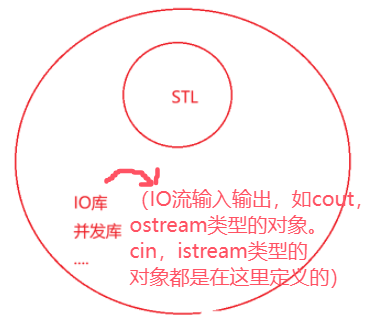
二、STL的版本
C++语言在1994年已经趋于成熟,但第一个官方大版本直到1998年才正式发布。这其中的一个关键原因是STL(标准模板库)的出现。原始STL版本由Alexander Stepanov和Meng Lee在惠普实验室(HP版本)开发,本着开源精神,允许自由使用和修改。但为了将STL纳入C++标准库,并确保其稳定性,C++标准委员会花费了时间进行整合和改进,因此发布推迟了4年,最终在1998年将STL作为C++标准库的核心部分。
随着STL的普及,多个衍生版本应运而生,并被不同编译器采用:
- P.J.版本由P.J. Plauger开发,继承自HP版本,被Windows Visual C++采用,但因其封闭性和可读性较低,主要局限于Windows平台。
- RW版本由Rouge Wage公司开发,同样源于HP版本,被C++ Builder采用,但也不可公开修改。C++ Builder这类编译器在与微软Visual Studio的竞争中逐渐销声匿迹,反映了当时编译器市场的变迁。
- SGI版本由Silicon Graphics公司开发,同样基于HP版本,被GCC(GNU编译器集合)采用,尤其在Linux系统中广泛使用。GCC通常被视为G++的统称,而G++是GCC中用于C++编译的组件。SGI版本的可移植性和可读性高,成为学习STL源代码的重要参考。
总之,STL的发展不仅影响了C++标准的发布时机,也通过不同版本的集成推动了编译器的演化,其中GCC(通过SGI版本)在开源领域占据了重要地位。
三、STL的六大组件
STL在实践的过程中被分为六大组件(类别)
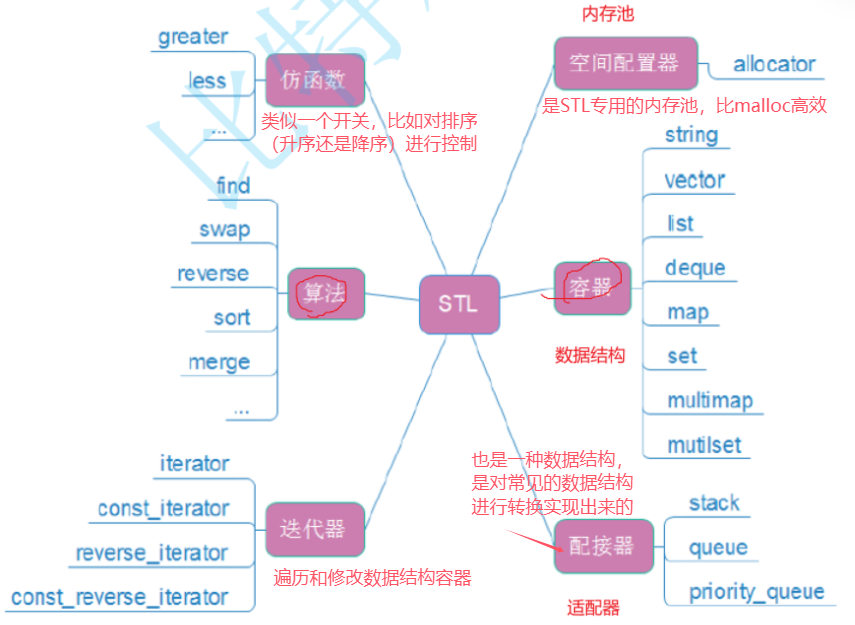
在这里插入图片描述
四、为什么学习string类
4.1 C语言中的字符串
C语言中,字符串是以’\0’结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问
在OJ中,有关字符串的题目基本以string类的形式出现,而且在常规工作中,为了简单、方便、快捷,基本都使用string类,很少有人去使用C库中的字符串操作函数
五、标准库中的string类
5.1 string类的历史地位与STL关系
在使用string类时,必须包含#include头文件以及using namespace std;
在这里插入图片描述
可以看到string不在容器之中,严格来说string不在STL库中,它在C++相关的标准库部分

在这里插入图片描述
有兄弟就说不对呀?前面不是把string归类到STL容器里了吗?
这其中有一些历史的发展原因,因为string产生的比STL早,C++标准委员会创建的string类就在标准库中,其后STL这些容器的设计也参考了string的设计,这里string的归类是历史的原因。string在后续的修改也参考了STL的设计,但是string在使用的功能和设计的风格来说,它和容器几乎一样,所以后面把string归到容器
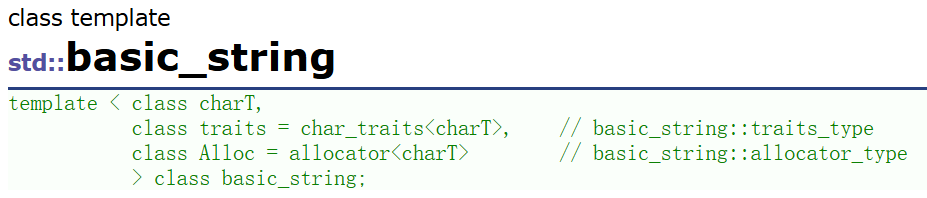
5.2 basic_string模板家族
C++标准库中的字符串类型std::string实际上是通过一个名为basic_string的类模板进行类型定义得到的。具体来说,std::string是basic_string< char >的别名,专门用于处理单字节字符。除了常用的string类型,C++还提供了basic_string模板的其他特化版本,以支持不同字符宽度和编码需求。例如,std::wstring用于宽字符(通常为wchar_t,在Windows平台中一般为2字节,在Linux平台中通常为4字节),以及C++11标准引入的std::u16string和std::u32string,分别用于处理UTF-16和UTF-32编码的字符,对应的字符类型为char16_t(2字节)和char32_t(4字节)
在这里插入图片描述

在这里插入图片描述

在这里插入图片描述

在这里插入图片描述

在这里插入图片描述

在这里插入图片描述
在这里插入图片描述
5.3 字符串在计算机中的重要性
在世界上存储更复杂更多样化的信息时,例如整型浮点数…更多的是表示一些数值,但是这个世界的所有信息都可以用字符串存储表示,整数和浮点数也可以转换为字符串存储。更复杂的一些文字信息也可以用字符串存储。
计算机存在是要做两件事情,第一件事情,存储信息,这是为了查和看。第二件事情是为了运算,搞其他类型(例如整型,浮点型)是为了方便运算,比如在12306买票,一趟车次的价格就是运算出来的
5.4 字符编码发展历程
所以总的来说字符串不需要运算,只需要存储信息,然而计算机只能存储二进制信息,比如多个0101的位,就可以表示一定范围的值,也可以理解为计算机时只能存储值。8个比特位构成一个字节,1个字节,2的8次方。就能表示256种状态,字符编码就是计算机系统中将字符映射为二进制值的重要概念。ASCII(美国信息交换标准代码)是最早广泛使用的字符编码标准,它使用一个字节(8位)中的低7位(0-127)来表示英文字母、数字、标点符号及控制字符(美国人的文字比较简单,设计了128位编码表,char一个字节就够了,因为一个字节能表示256种状态)。
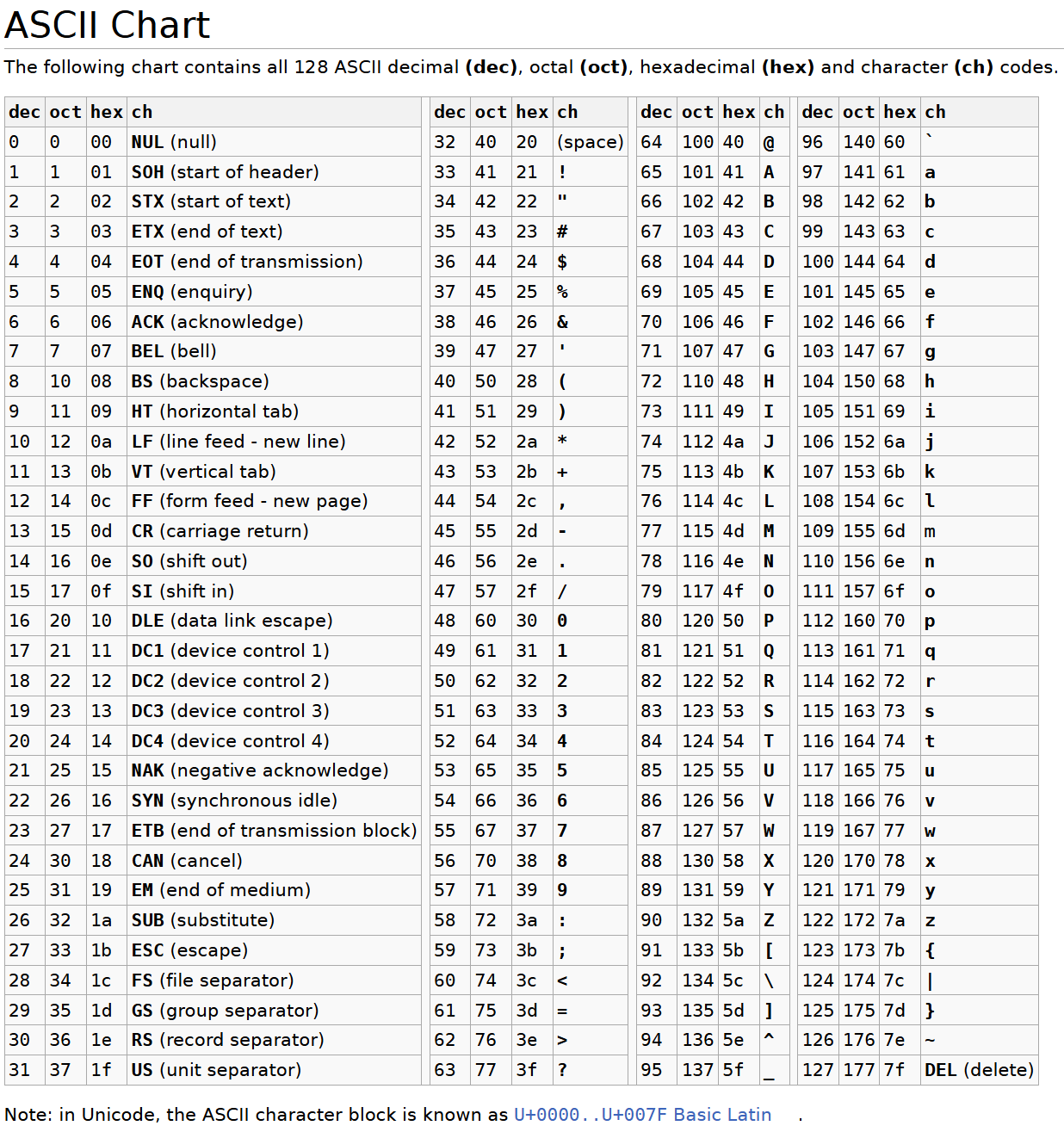
在这里插入图片描述
例如,大写字母’A’对应的ASCII码值为65,小写字母’a’对应的ASCII码值为97。在计算机存储中,字符实际上是以其对应的整型值(即ASCII码值)进行存储的,在显示时再通过编码表查询转换为相应的图形符号。
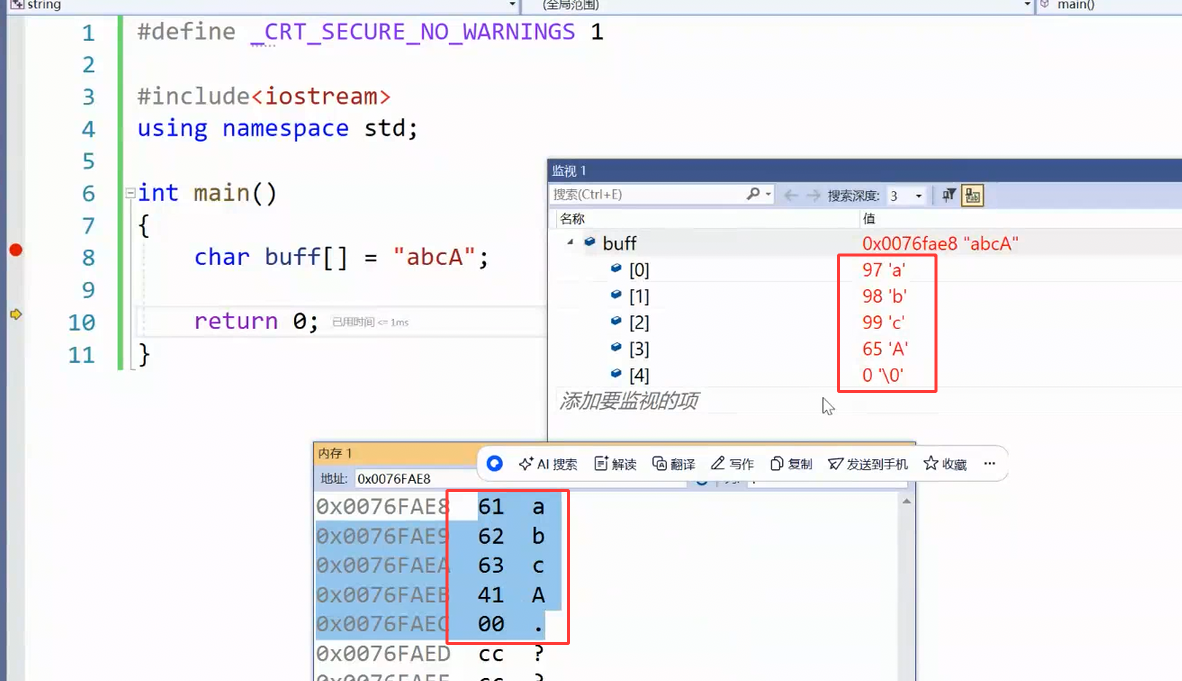
在这里插入图片描述
61是16进制,就是97,这里’\0’也是ASCII表里的一个字符,它的ASCII码值为0
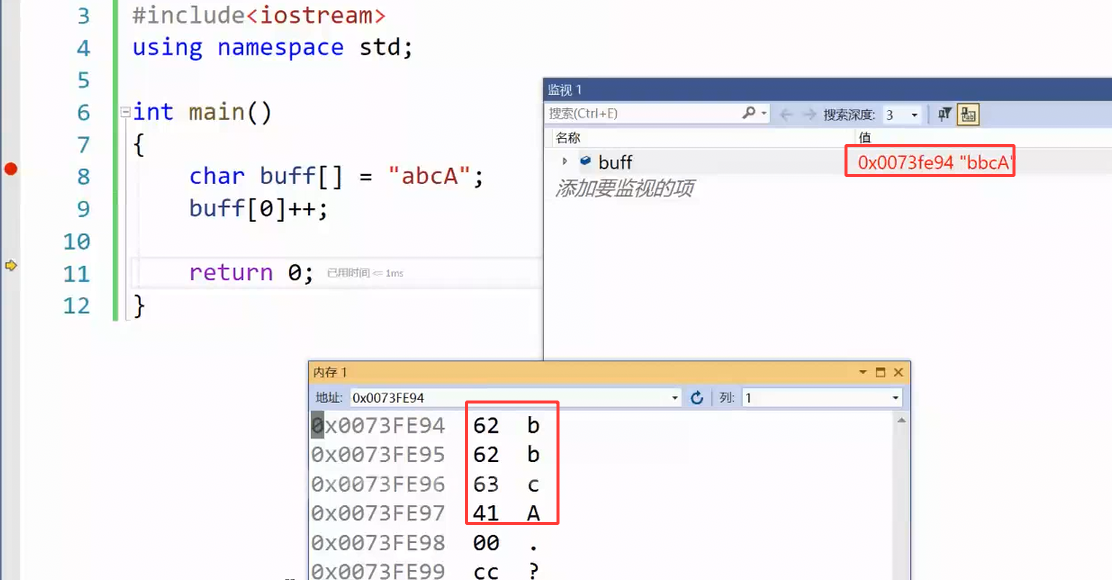
在这里插入图片描述
ASCII值就是一个字符在内存当中存的那个整型值,这里的整型不是4个字节的整型,而是1个字节的整型,char整型(char也是一种整型,属于整型家族)
5.5 Unicode编码体系
随着计算机在全球范围的普及,ASCII编码无法满足非拉丁文字(如中文、日文、韩文等)的表示需求,以中文来说,一个字符为一个单位是不能很好表示我们的中文的,老美的文字是组合式的,只有那些符号,多个符号就构成一个字。而汉字有十几万个,要存储中文通常就要用2或3个字节才能存储了,一个字节表示一个文字肯定存储不下来,若0表示一个文字,1表示一个文字,就会导致只能表示250多个汉字(补充:一个字节能表示256,两个字节(256×256),能表示六万多,4个字节能表示42亿多个),这肯定是不行的。为此,Unicode(统一码)应运而生,它是一种旨在包含全世界所有字符的编码标准。Unicode为每个字符分配一个唯一的码点(Code Point),其范围从U+0000到U+10FFFF。Unicode标准本身仅定义字符与码点的映射关系,实际存储时需要通过各种编码方案实现,主要包括UTF-8、UTF-16和UTF-32三种编码格式。

在这里插入图片描述

在这里插入图片描述
UTF-8是一种变长编码方式,使用1至4个字节表示一个字符,并完全兼容ASCII编码。其编码规则具有明确的特征:单字节字符以0开头,与ASCII编码完全相同;多字节字符中,两字节字符的首字节以110开头,三字节字符的首字节以1110开头,四字节字符的首字节以11110开头,所有后续字节均以10开头。例如,汉字"汉"的Unicode码点为U+6C49,在UTF-8编码中对应的三字节序列为E6 B1 89。UTF-8编码因其良好的兼容性和较高的空间效率,已成为互联网和许多操作系统中主流的编码方式。
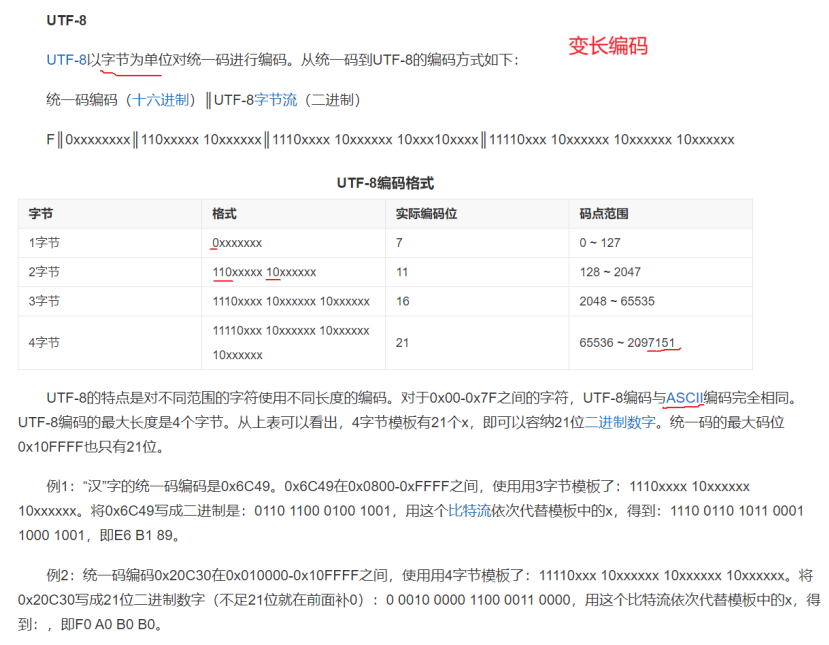
在这里插入图片描述
补充:UTF-8中一个字节能编码128种状态,两个字节能表示2000多种状态,三个字节能表示6w多个状态,四个字节最多能表示200多w种状态,哪个国家的文字都不可能有200多w个符号,所以它就能表示所有的文字了
UTF-16编码使用2或4个字节表示一个字符,属于定长与变长相结合的编码方式(通过代理对机制表示辅助平面字符)。UTF-32编码则始终使用4个字节表示每个字符,处理简单但空间占用较大。由于UTF-16和UTF-32在存储常见西方文字时空间效率较低(用UTF-8存abc只需要三个字节,用UTF-16存abc,起步就是6个字节了,UTF-32更加浪费了),它们在通用场景中的使用相对较少,但在某些特定系统和应用中仍有使用,如Windows操作系统内部就广泛使用UTF-16编码。
C++标准库通过basic_string模板的不同实例化来支持这些编码类型:std::string通常用于UTF-8或单字节编码;std::u16string和std::u32string分别专门用于UTF-16和UTF-32编码;而std::wstring的字符宽度依赖具体平台实现,可能对应于UTF-16(2字节)或UTF-32编码(4字节)。这样的设计使得C++字符串能够灵活适配不同的字符集与编码需求,为跨语言、跨平台的文本处理提供了坚实的基础支持
5.6 GBK编码(中国国家标准)
基于上面的原因,小的国家就不会搞自己的编码了,用Unicode现成的就可以了。但是中国文化博大精深(文字还分黑体,宋体,仿体,汉体…),还分简体繁体,所以我们国家自己有一套编码叫GBK(GB就是国标的意思)
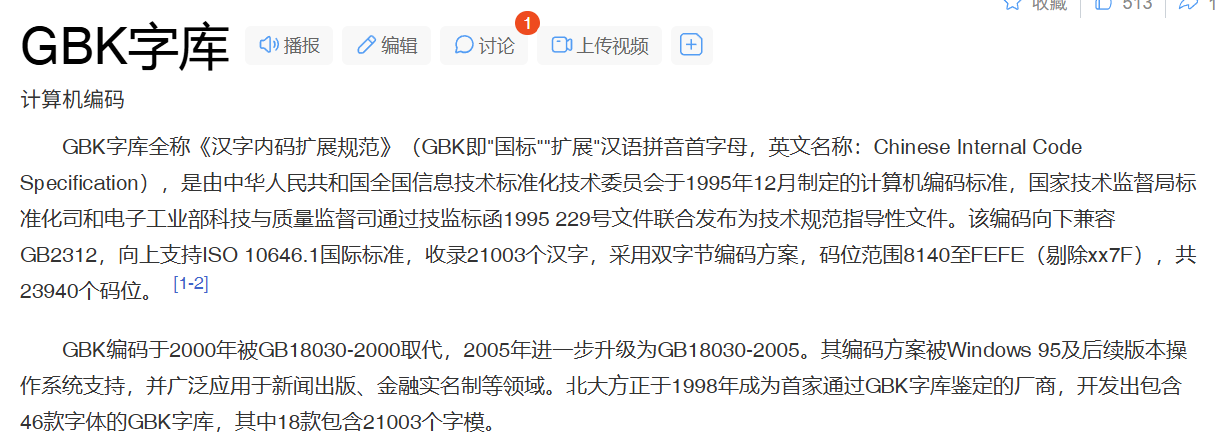
在这里插入图片描述
GB后面跟数字都是GB这个系列之中的,而且GBK在扩展的时候是把日文和韩文也编进去了,我们国家在编文字时与UTF-8还有些不同,UTF-8是牺牲了5bit个位来做标记,所以两个字节才能编几千个,GBK编码时没有用这么多位来做标记,所以GBK是用两个字节来编码,Windows下就是是用GBK编码方案,由于中国市场大,Windows支持汉化
在这里插入图片描述
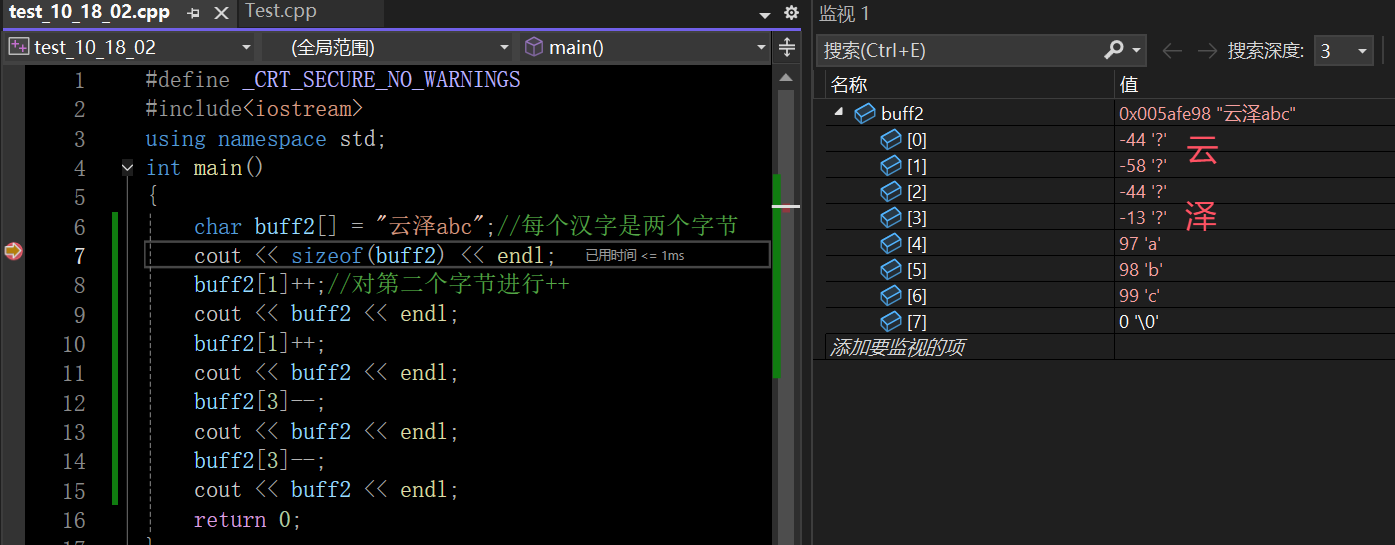
5.7 编码应用与实际问题
这里底层存储的时候就要用符号中的“云”去查编码表存储到内存中去,基于前面的内容buff2这个数字大小是5个字节(GBK是用两个字节来表示一个汉字,还有\0)
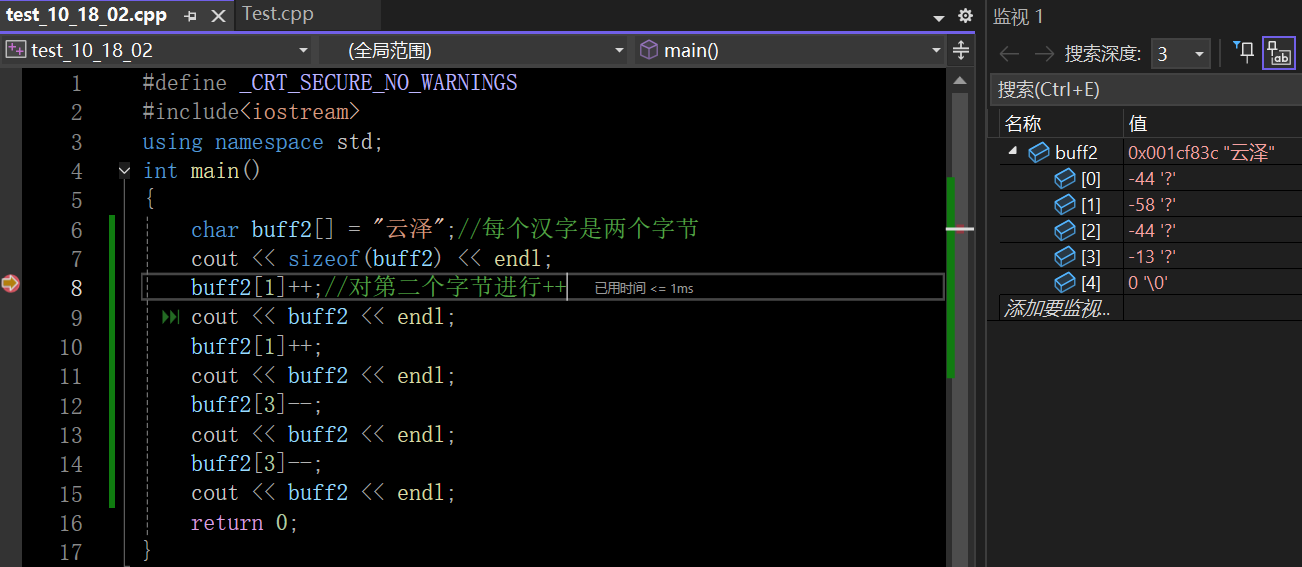
在这里插入图片描述
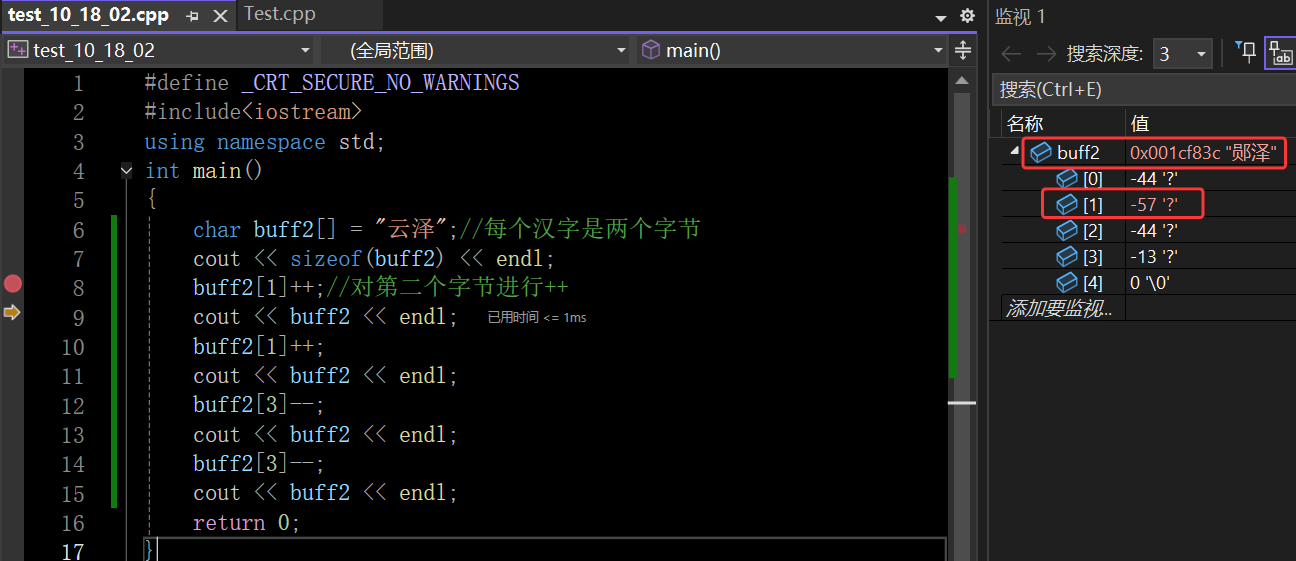
在这里插入图片描述
GBK在对汉字编码的时候是有规则的,会把同音字编在一起。平时见到的乱码就是如果存的是GBK,但是软件设置的读取编码不是GBK,这时候就导致读出来的东西是乱码。
补充一点:有时候为了让网络环境更文明,就有了净网行动,像在一些游戏里脏话是不能通过打字出现在聊天框的,原生词可以屏蔽,但是同音词的屏蔽就涉及上面所说的编码表的设计了。比如说要把“卧”这个词的范围集同音词的编码表也屏蔽掉
在这里插入图片描述
GBK也是兼容ASCII码的,所以UTF-8和GBK都可以用string存储
5.8 string的使用
string接口很多,现在大概有120个成员函数接口(公开提供使用的,内部肯定不止),我文章中只写最常用的20-30个,其余的在用的时候查文档就好了
string是用字符的顺序表实现,因为要兼容C语言,所以C++字符串的后面有’\0’

在这里插入图片描述
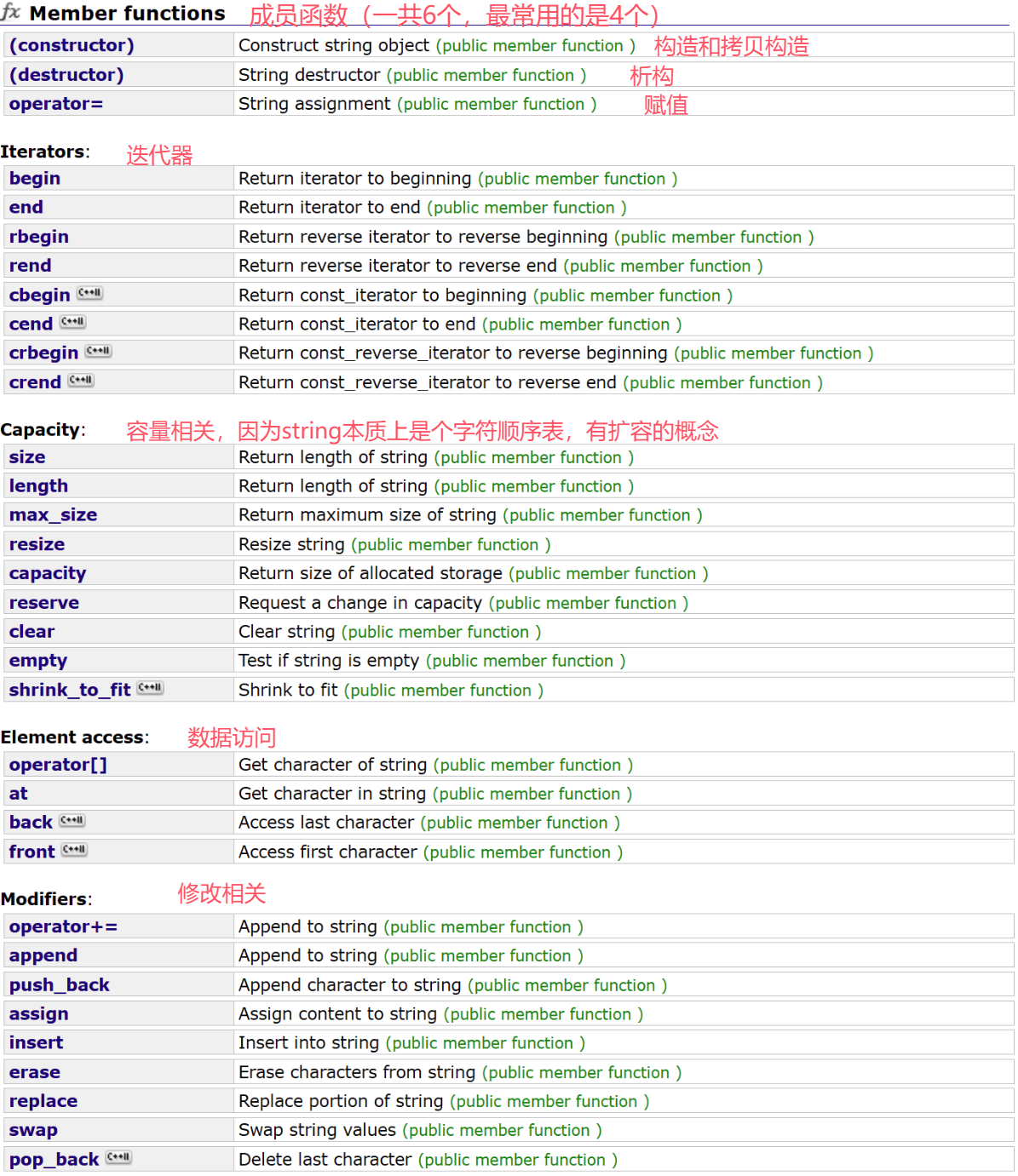
在这里插入图片描述
operator[ ]是个运算符重载

在这里插入图片描述
在这里插入图片描述
相关功能介绍
在这里插入图片描述
参数的说明,返回值的说明

在这里插入图片描述
样例:展示每一个接口
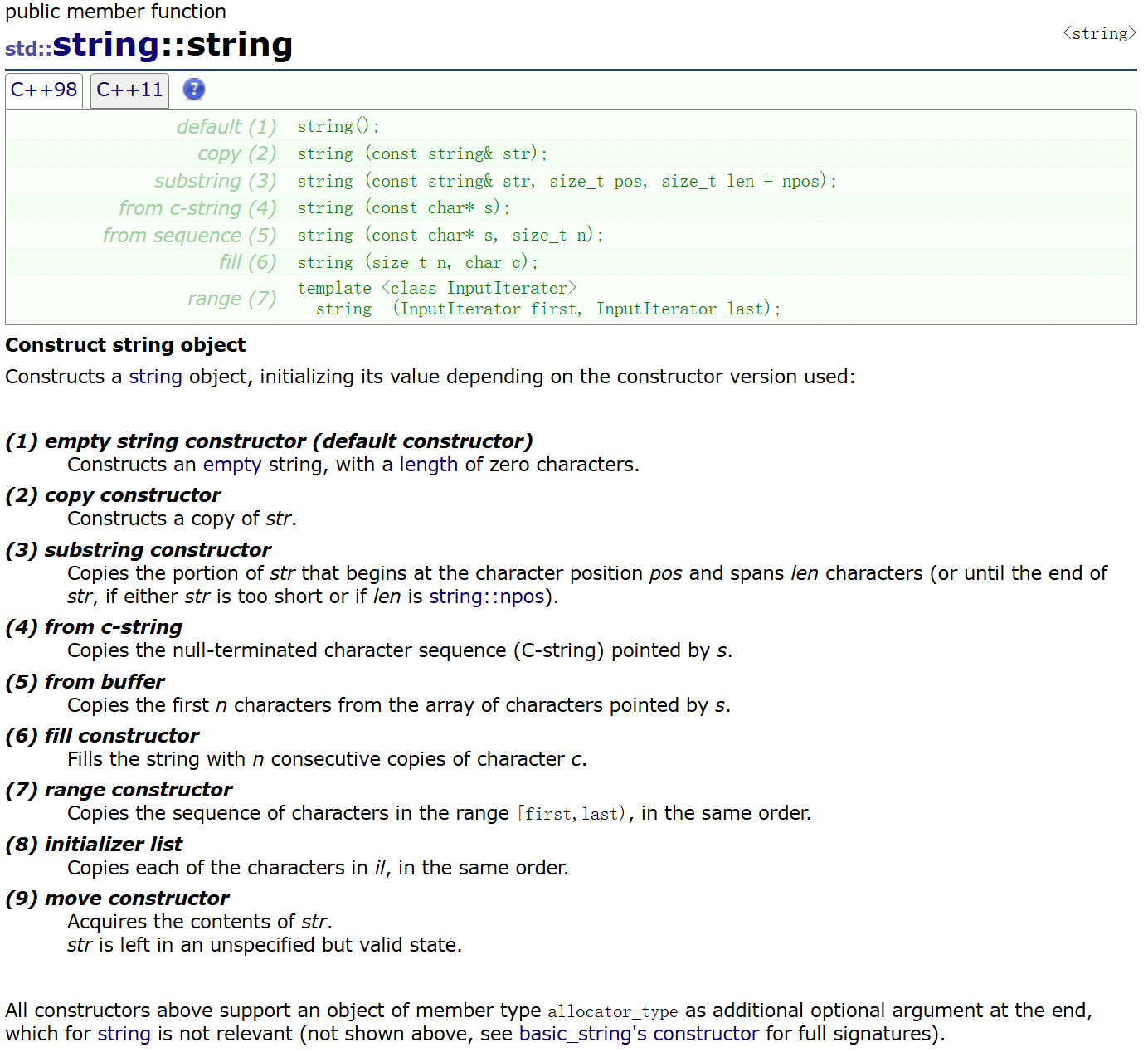
5.8.1 string的成员函数

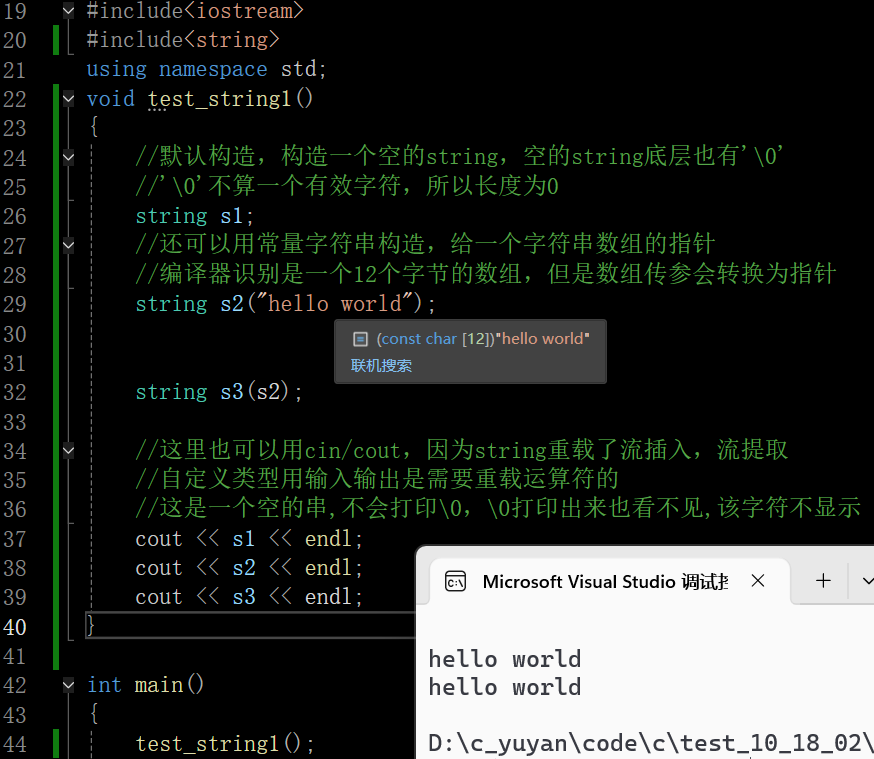
在这里插入图片描述
注意,存常量字符串不是存一个指针指向的数组 而且string s2(“hello world”);就是拷贝构造了,和顺序表一样,他也会开一块数组空间,把数据拷贝过来,存在自己的空间里,这样才方便修改
在这里插入图片描述
string底层的拷贝就会设计深拷贝/浅拷贝,这里只要是深拷贝
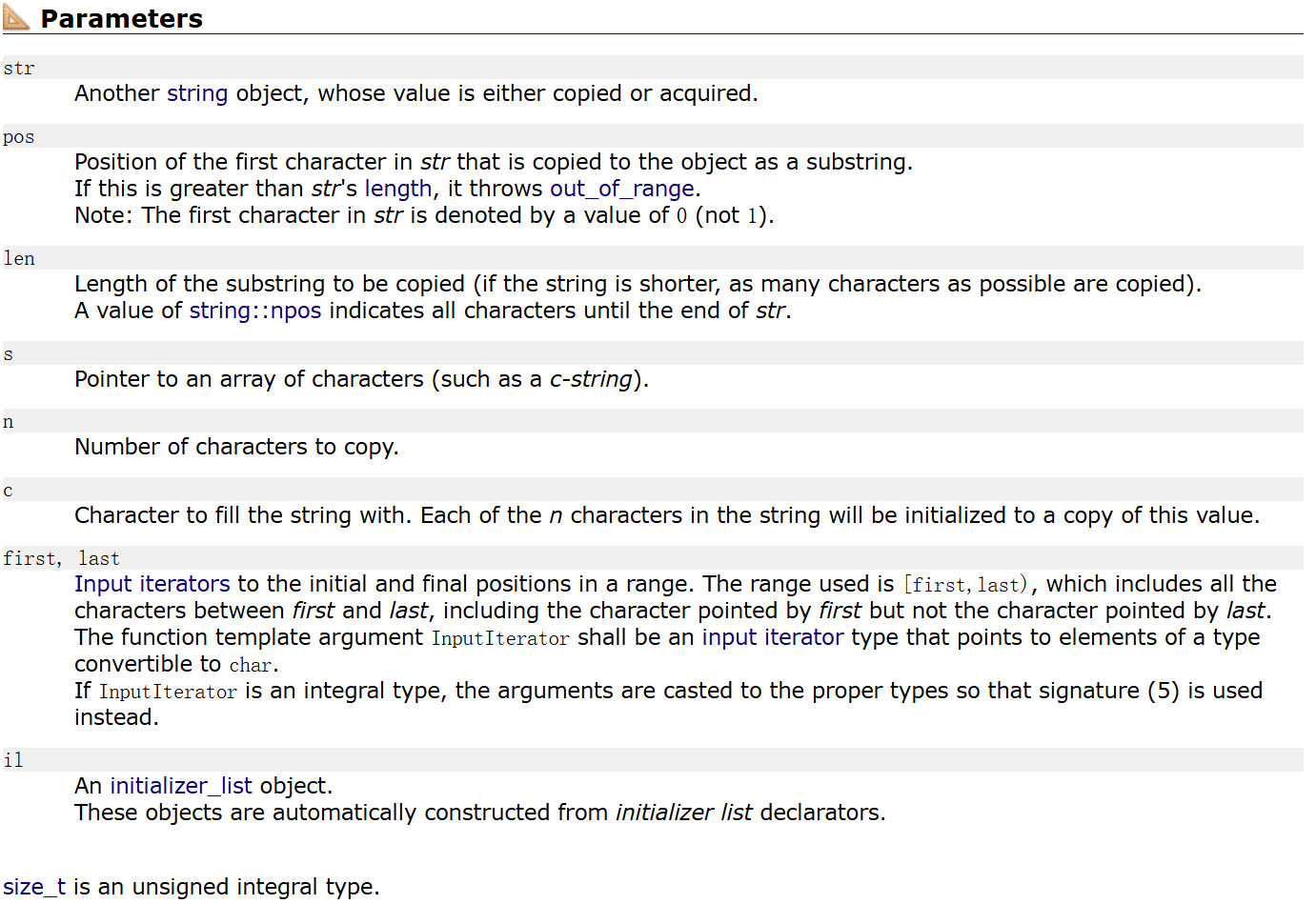
再看一个接口 这里分享一个看文档的技巧,可以通过参数猜功能,文档中的取名都是很规范的

在这里插入图片描述
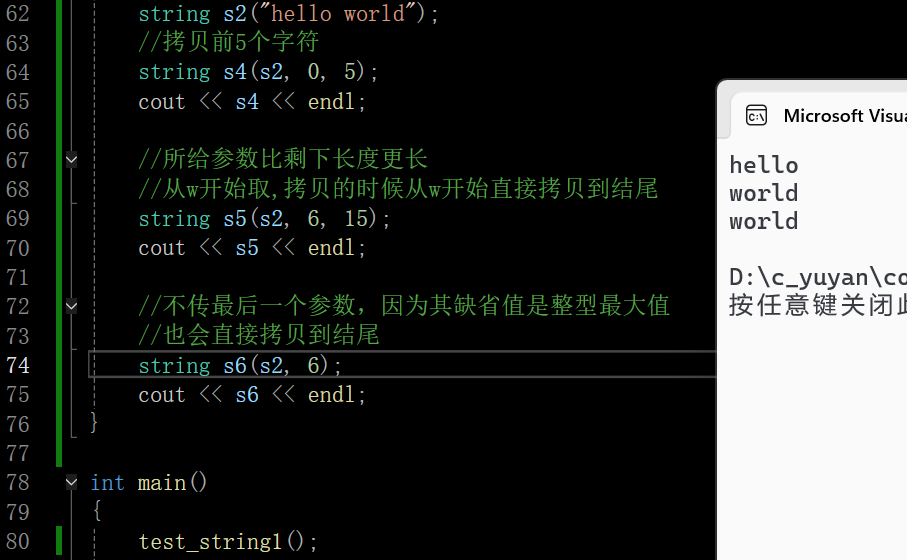
拷贝str这个对象的一部分,从pos标记的这个位置开始的len个字符(直到str的结束,如果str太短(所给参数比剩下长度更长)或者len是string::npos,则直到str结尾) 缺省参数npos是string定义的const静态成员变量

在这里插入图片描述
其值为-1,但不是真的-1,是整型的最大值,其类型是size_t。size_t是被typedef的一个值,在32位下,size_t是unsigned int,64位下是unsigned int 64(8个字节)
-1存的是补码,-1的补码是全1,所以npos是整型的最大值(四十二亿九千万个字符,4G),缺省参数给npos的目的是当一个字符串很长的时候直接拷贝
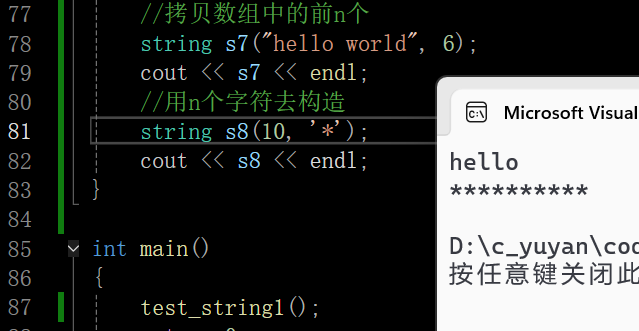
在这里插入图片描述
上上张图片的(5)(6)统一说一下
在这里插入图片描述
这里析构也会自动调用,除非自己实现一个数据结构需要再写一个析构
直接说赋值

在这里插入图片描述
赋值和拷贝构造都设计深拷贝,代价较大
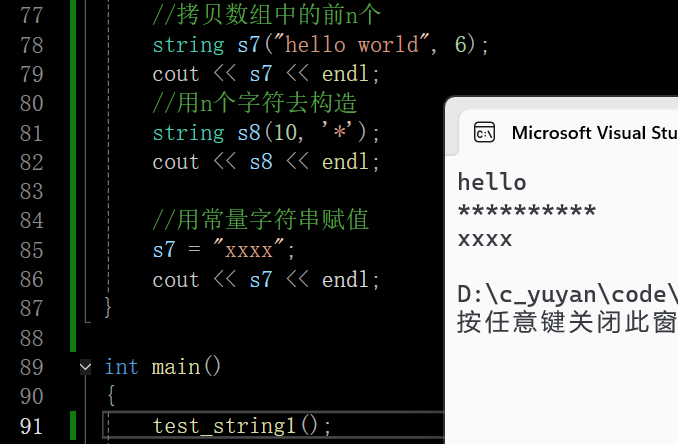
在这里插入图片描述
5.8.2 string的遍历和修改
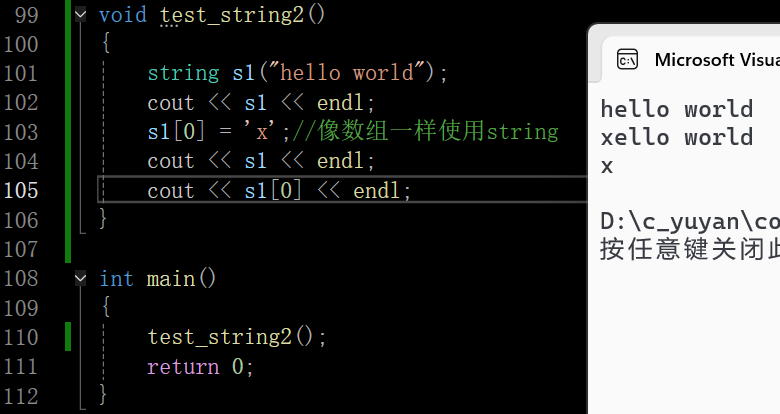
得益于运算符重载operator[ ],有了它可以让对象可以像数组一样使用,像string的底层就是数组,就可以用下标来访问对应位置的那个值
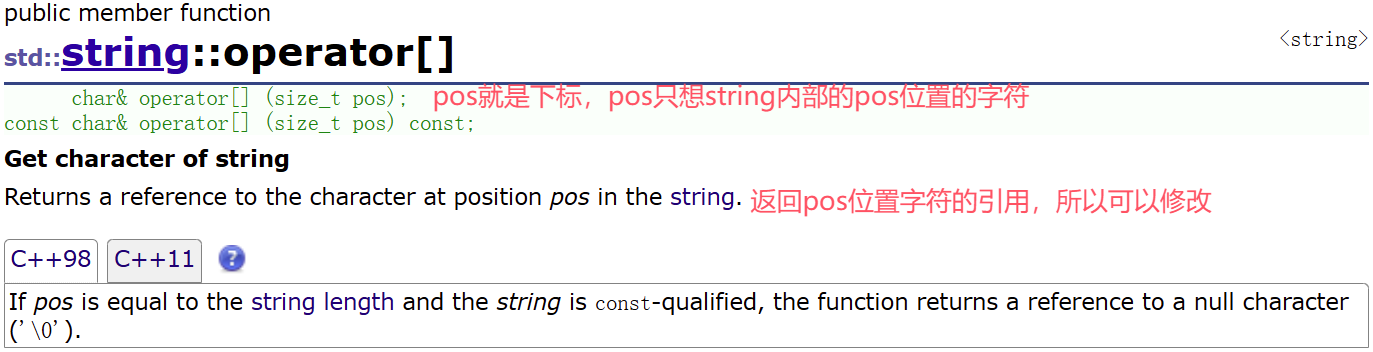
在这里插入图片描述
重载两个版本(一个普通版本一个const版本)是因为string有普通对象有const对象,const对象只能调用const成员函数,const成员函数返回const引用,返回对应字符的别名,但是不能修改
在这里插入图片描述
下面大概看一下string::operator[ ]内部逻辑的样子,虽然底层是个模板,但模板只是字符串的字符类型不同而已,下面这个是手搓的
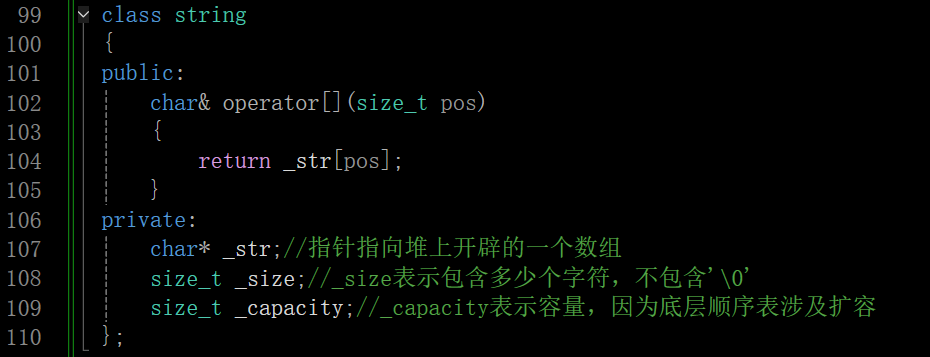
在这里插入图片描述
之前的文章写引用做返回值,更多的作用是减少拷贝,因为传值返回是返回返回对象的一个拷贝,这里体现了引用返回的另外一个功能,可以修改返回对象,达到了可以像数组一样操作
C++编译器这里是以类型为原则识别的,若a是一个普通的char的数组,a[0]='x’本质上就转换为指令(可能是多句指令),用指针+下标然后解引用最后把x放到解引用的位置,s1[0]='x’自定义类型就转换为对应的函数调用,若没有对应运算符重载的函数调用就会编译报错

在这里插入图片描述
C++这里这样的实现方式还有一个很好的效果,C语言普通数组的越界检查是一种抽查,比如说在下面红框数组的结束设置一些标记位,只要这些标记位没有被修改,就不会报错。如果往后越界的很远修改就检查不到,这个是C语言数组的一大缺陷

在这里插入图片描述
C++这里转换为函数调用就可以使用assert(pos<_size)做越界检查
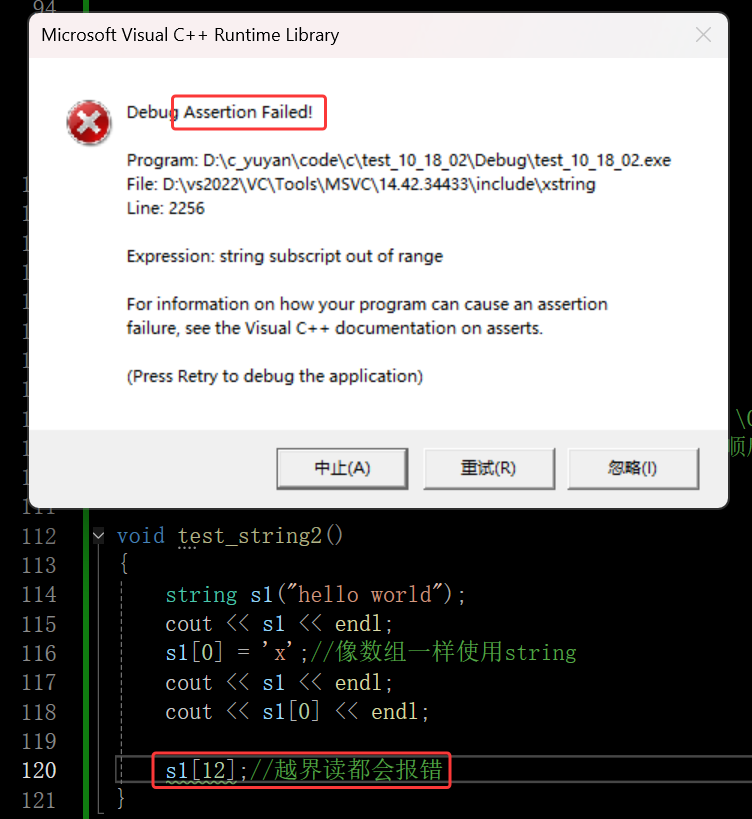
在这里插入图片描述
断言的缺陷就是在Release会被优化掉
at和[ ]的功能是一样的

在这里插入图片描述
二者唯一区别是,at越界了会抛异常 断言是直接中止程序,比较粗暴,at稍微温和一些(异常可以被捕获,但程序不会终止,后续的程序还可以继续运行)
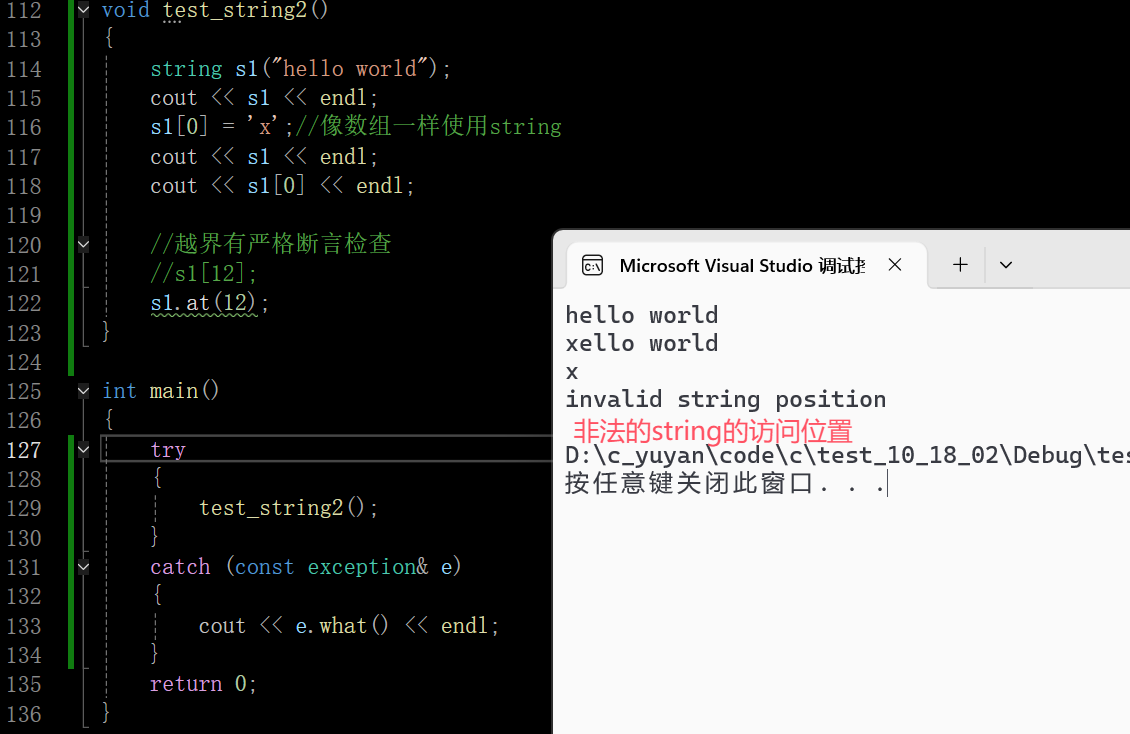
在这里插入图片描述
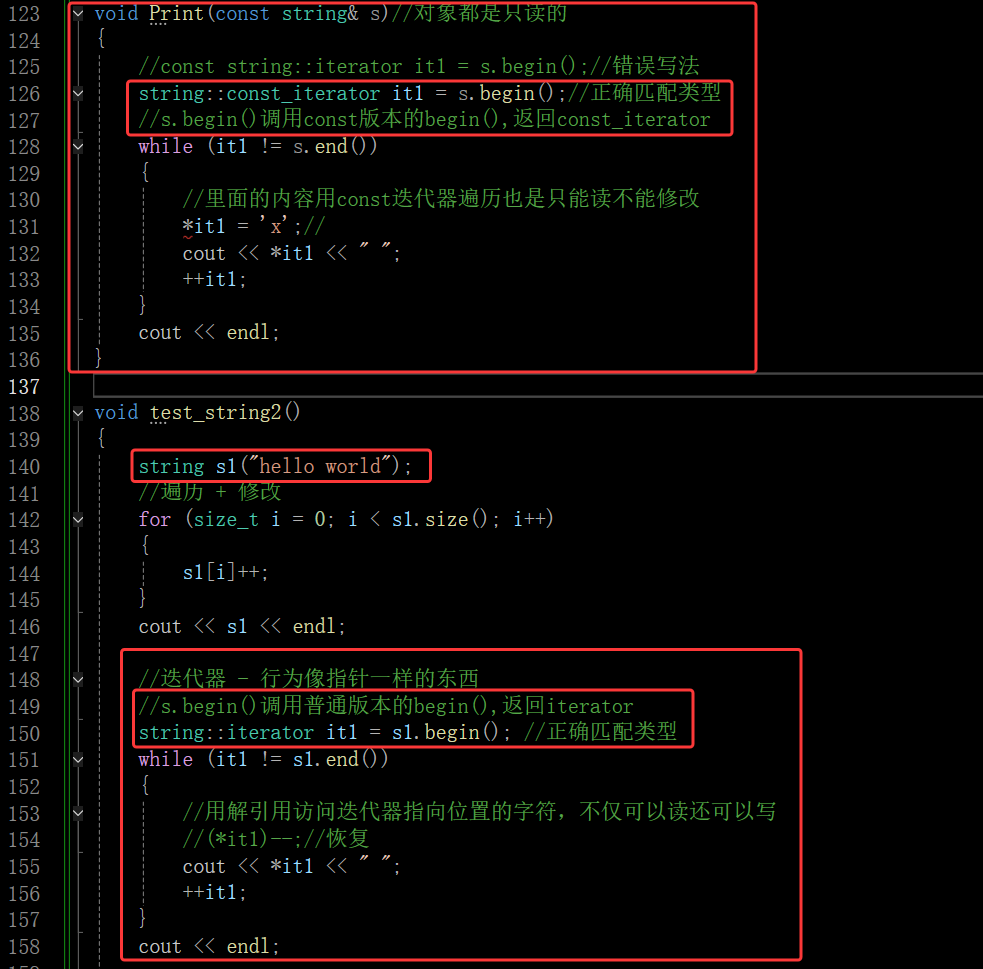
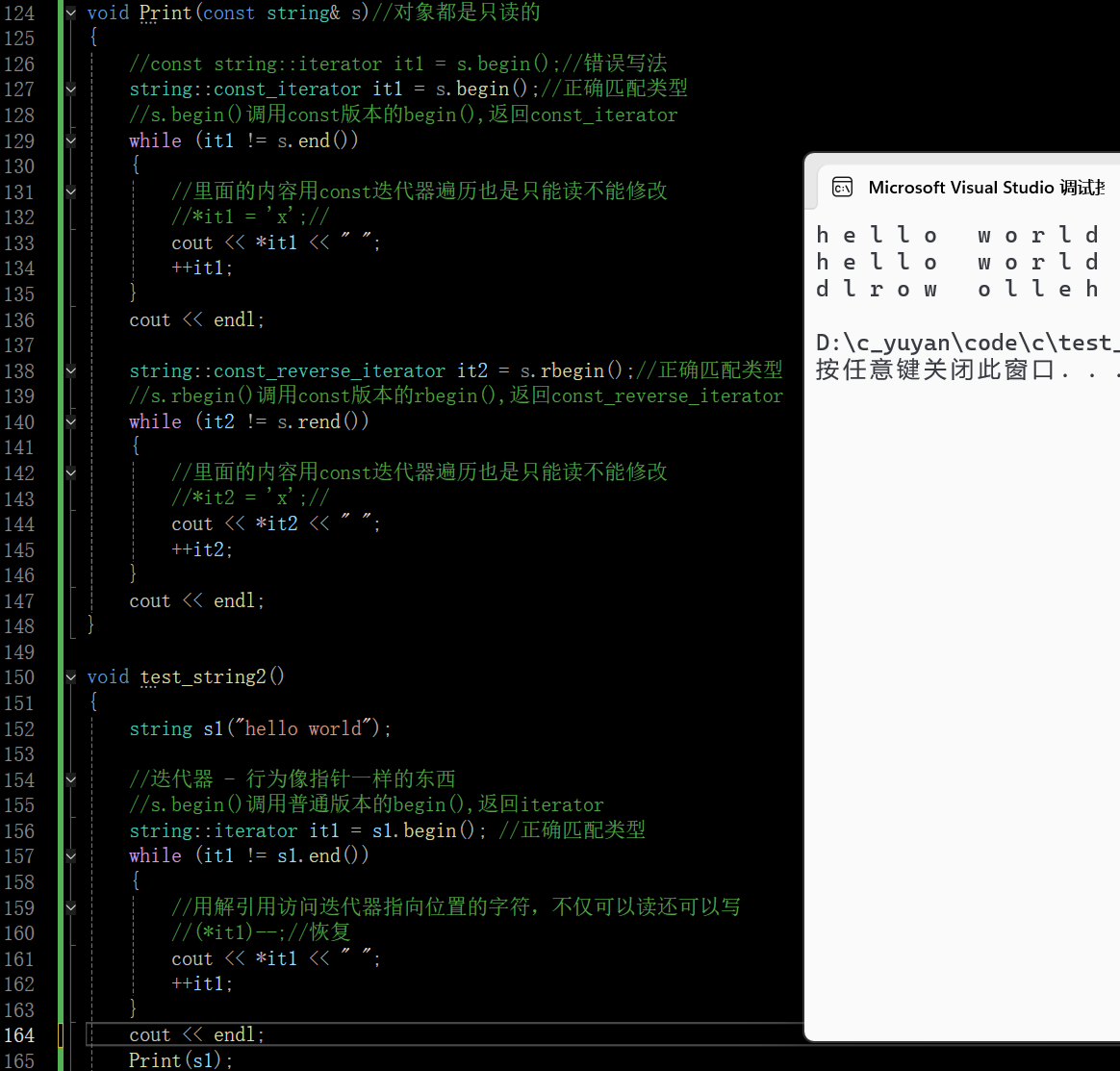
size和length这两个接口都可以返回字符的长度(都不包含’\0’),二者完全没有区别,之所以搞了两个也是一个历史原因,早期string的设计就是length,STL引进之后就把size增加进去了。这里推荐用size,所有的容器要想看数据个数都是size,length不怎么用,像二叉树这样的数据结构用一个length接口就非常不合适,size就很合理

在这里插入图片描述
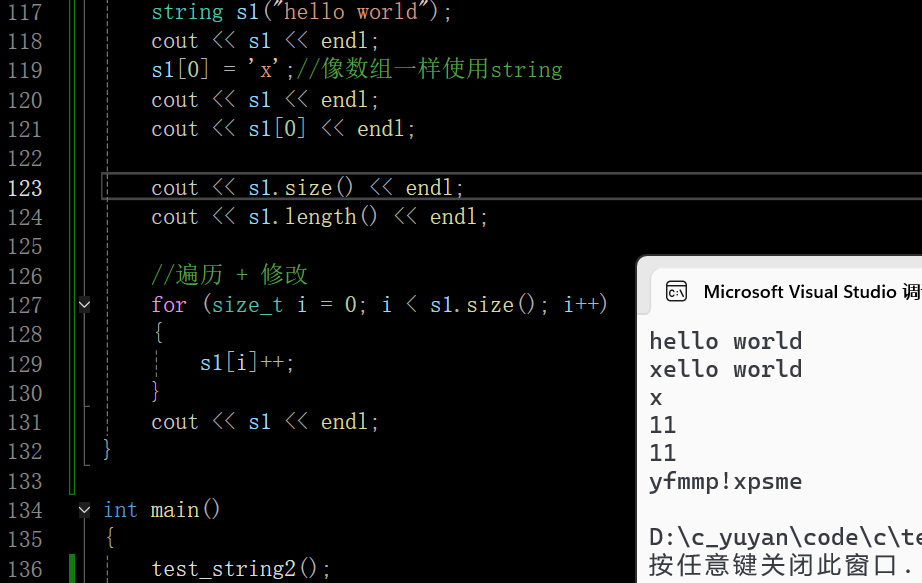
在这里插入图片描述
对每个字符+1
5.8.3 迭代器
迭代这个词就是用来遍历的
在string这个类域中有一个叫iterator的类型,在一个类域中还有一个类型只有两种情况,一种就是内部类,另一种就是在内部进行typedef,iterator就属于第二种

在这里插入图片描述
这些都是string的内部类型,凡是用到这些,都是在类里面定义的内部类或者在里面typedef,iterator就是string的迭代器类型
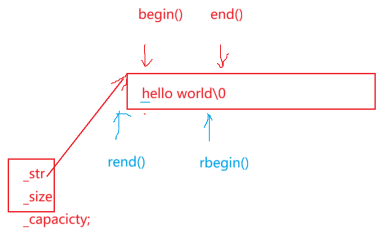
迭代器用起来是一个行为像指针的东西,要找开始位置的指针(指向第一个有效数据),该指针是由一个叫begin的函数提供的,begin是提供开始位置的迭代器

在这里插入图片描述
还有一个指针end,这是最后一个字符的下一个位置,就是指向’\0’位置的指针,指向有效位置的下一个位置,'\0’不算有效字符,而是一个标识字符(标识字符串的结束)

在这里插入图片描述
两个指针构成了一个左闭右开的区间
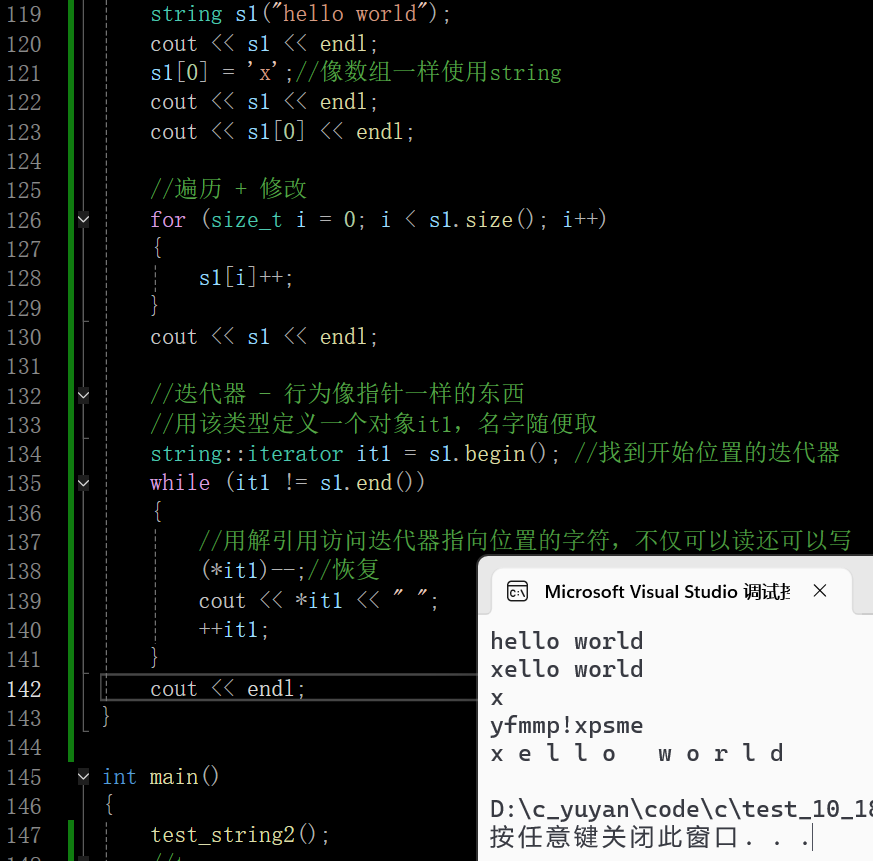
在这里插入图片描述
但是迭代器不能等价于指针,只是行为像指针,不同容器不同版本的的迭代器都不同,包括string的实现也一样

在这里插入图片描述
迭代器和下标+[ ]在功能上是重叠的,但是迭代器作为STL的一大组件,是一种可以通用的访问所有容器的方式。像链表这样的数据结构底层不是数组就无法使用下标+[ ]来遍历和修改了,这时候就必须使用迭代器
此时头文件包含list,是个链表,list是用模板实现的
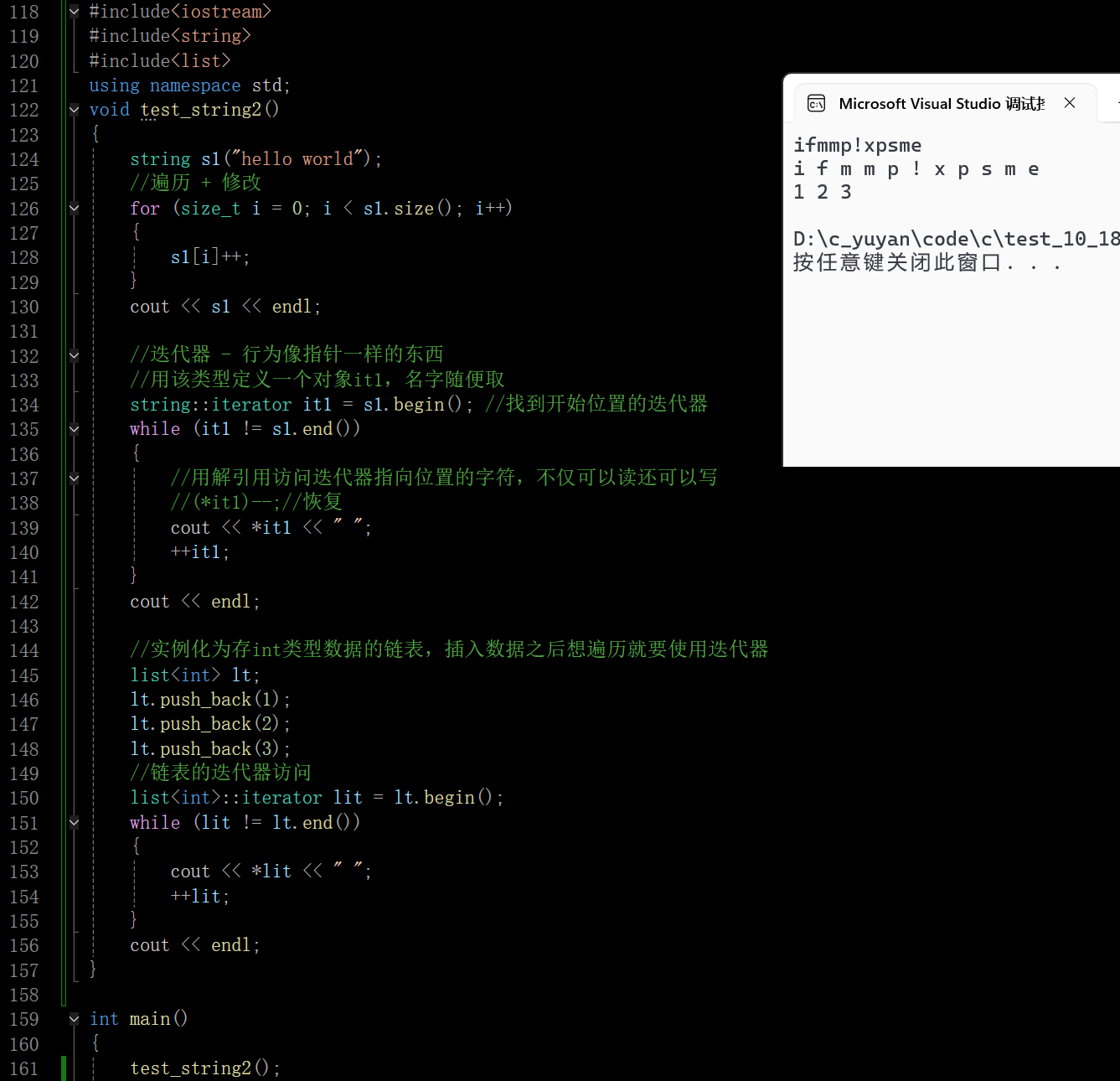
在这里插入图片描述
所有容器内部都有一个叫iterator的成员类型或内嵌类型,不同容器的迭代器不是同一个类型,因为虽然名字相同,但是在不同的作用域(类域)
迭代器也有普通版本和const版本 前面如果一个函数不会修改成员变量就写为带const的,普通对象和const都可以调用。带const和不带const的二者都要实现进行重载的情况就是既要读又要写,读写要分离。const对象只能读,普通对象既可以读又可以写,前面的[ ]就是这样

在这里插入图片描述
const迭代器不是在普通对象前面加const,const string::iterator it1 = s.begin(); const 对象不是使用const iterator去遍历,因为这里const修饰的是迭代器本身,就不能++了,也就不能遍历了
//类比指针
T* const;//修饰迭代器本身的const
const* T;//修饰迭代器指向内容的const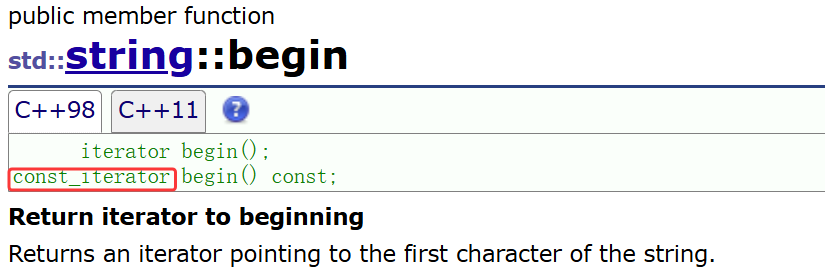
在这里插入图片描述
所以图中const_iterator是类比第二个指针,迭代器本身是可以修改的,本身不被const修饰,而指向的内容被const修饰,不能修改
正确的写法是
在这里插入图片描述
const迭代器的特点就是不能修改
除了begin两种迭代器,还有两种迭代器

在这里插入图片描述
iterator叫做正向迭代器,它的遍历是从前向后的,该迭代器叫反向迭代器,普通对象用反向迭代器,const对象用const反向迭代器,reverse是逆置,反向,反转的意思
rbegin,rend返回的就是反向迭代器,这里rbegin的++能倒着走是因为封装重载运算符了,从底层实现的角度,迭代器的实现一定是依赖于指针的实现
在这里插入图片描述
在这里插入图片描述
迭代器还有cbegin和cend的版本,这两个版本是C++11增加的版本,它和const版本的begin是一样的,cbegin是更规范一些,在C++11之后,期望调用const迭代器就调用cbegin,分工更加清晰

在这里插入图片描述
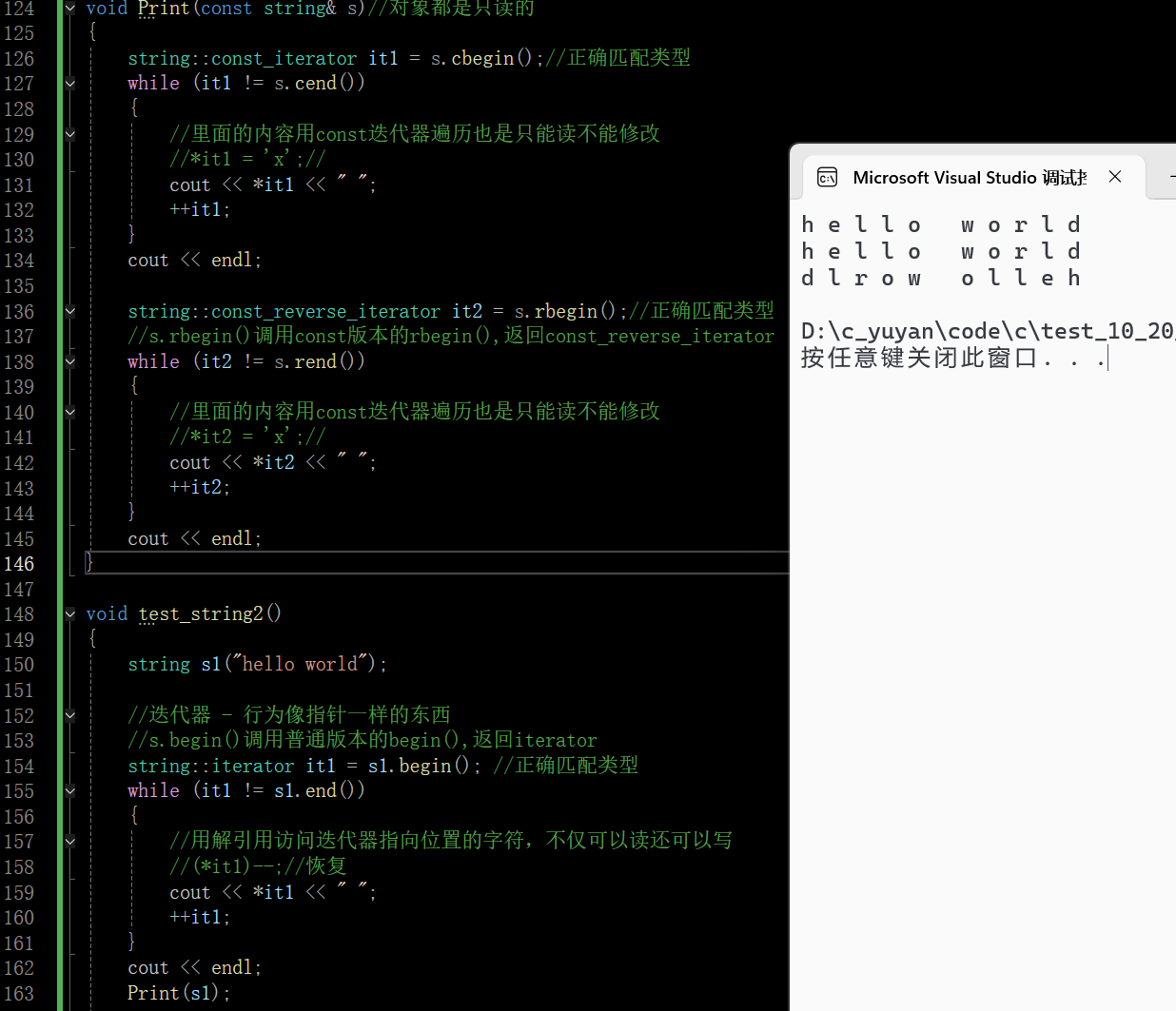
在这里插入图片描述
所以迭代器有两大优点:
- 提供统一的方式遍历修改容器
- 算法可以泛型化,算法借助迭代器处理容器的数据
就拿查找算法举例,STL里的一些通用算法就写到了算法头文件#include< algorithm >
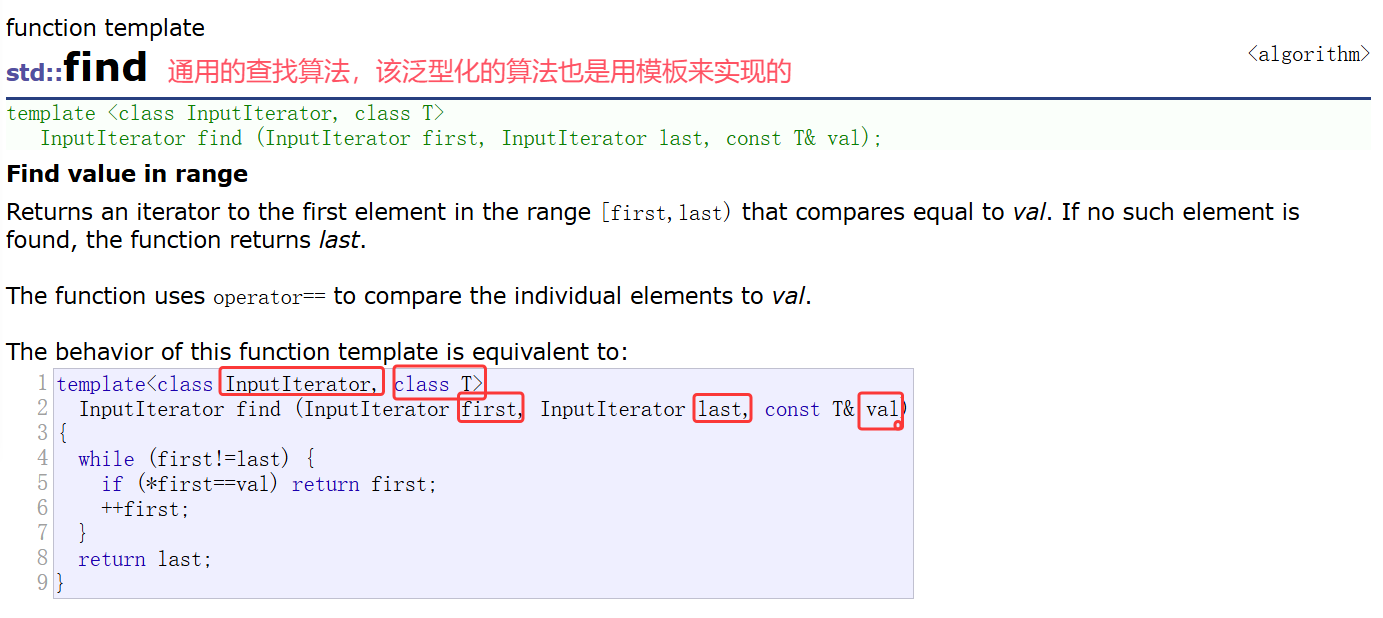
在这里插入图片描述

在这里插入图片描述
其算法模板通过迭代器化,不传对应的容器,而是传容器的迭代器区间,在算法中的迭代器区间是左闭右开的
并且把迭代器搞成模板,模板参数写成这样代表first和last是段迭代器区间,但是是谁的迭代器不知道,顺序表,链表,树的迭代器都可以,只要迭代器是实现好的,把迭代器对象传过来,就会实例化出对应的迭代器类型。
因为迭代器不一定支持大小的比较,所以这里循环判断的条件是first!=last,而不是first<last,像顺序表,底层是数组,后面的值一定大于前面的值,而链表中的节点是没有大小关系的
设计成左闭右开区间还有一个目的,若找到了就返回对应位置的迭代器(解引用就可以取到该位置的值),没有找到就返回last,但实际要找的区间是first到last-1
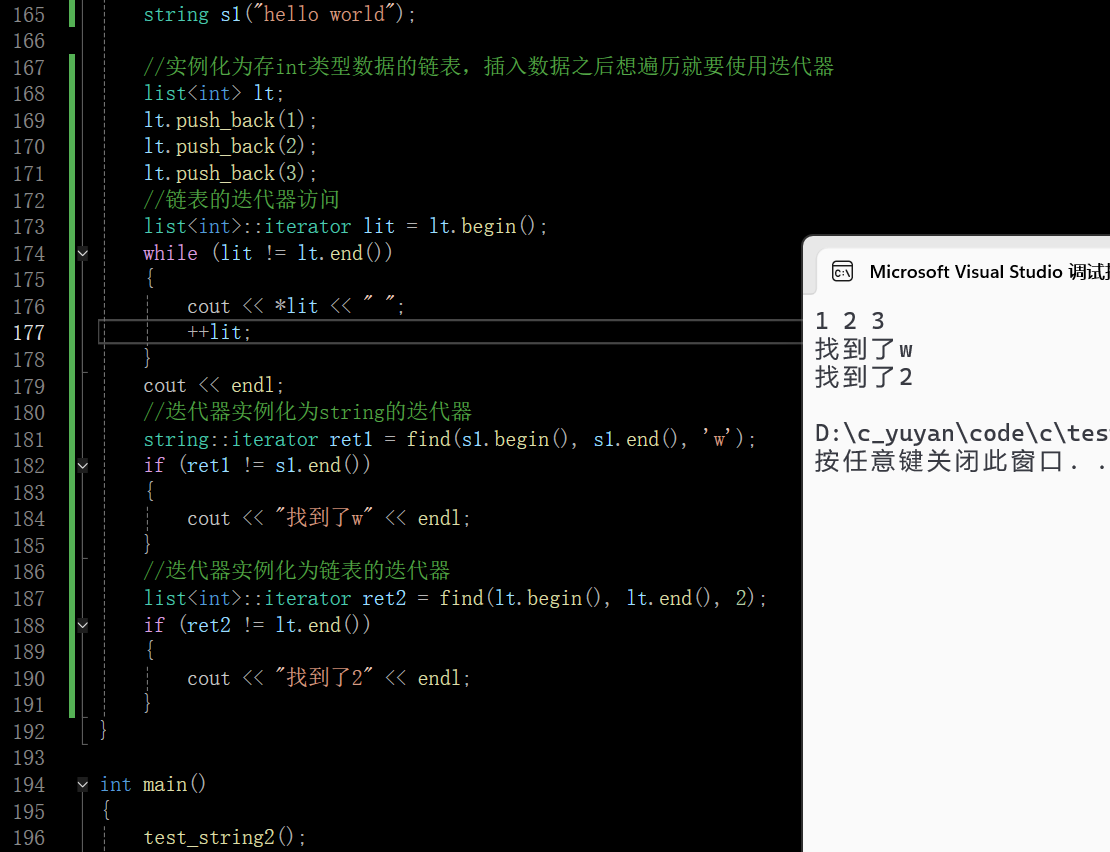
在这里插入图片描述
5.8.4 auto和范围for
二者是C++11的两个语法
5.8.4.1 auto关键字
auto关键字可以进行自动推导类型
int i = 0;
//通过初始化表达式值类型自动推导对象类型
auto j = i;
auto k = 10;前面有时候迭代器遍历的时候,迭代器很长很难写,就可以使用auto
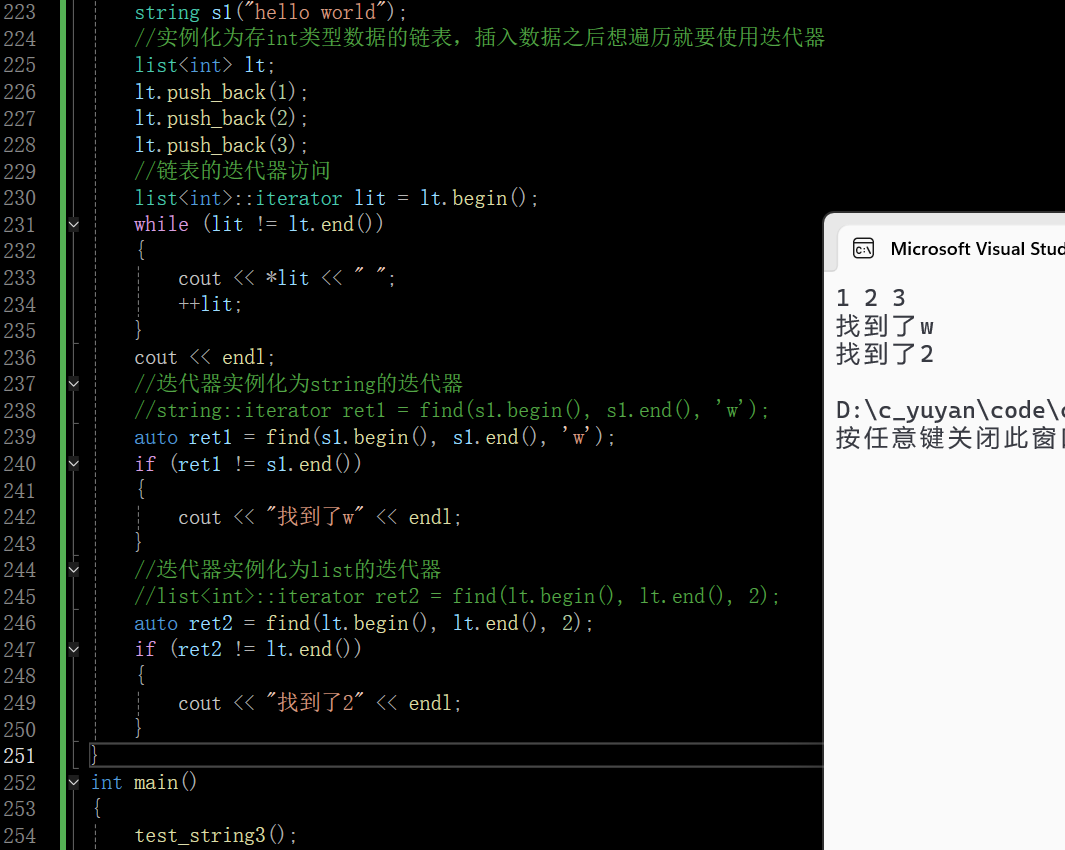
在这里插入图片描述
但是这样写auto也一定程度降低了程序的可读性,一眼看去可能看不出来是什么类型对象的迭代器,所以要适度使用
auto也可以推导指针和引用
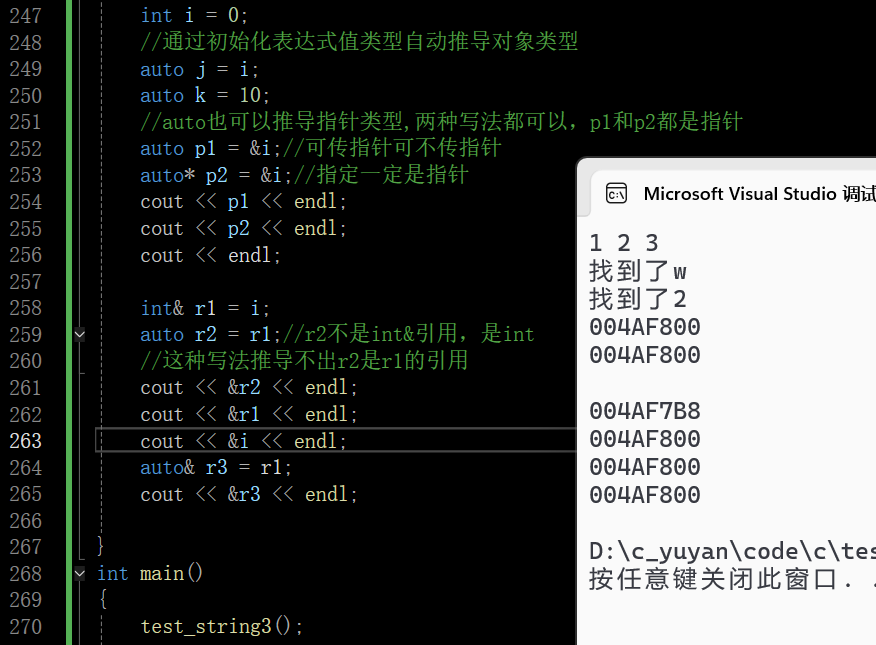
在这里插入图片描述
- 在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,后来这个不重要了。C++11中,标准委员会变废为宝赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得
- 用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时必须加&
- 当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量
- auto不能作为函数的参数,可以做返回值,但是建议谨慎使用
- auto不能直接用来声明数组
5.8.4.2 范围for
- 对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错。因此C++11中银日了基于范围的for循环。for循环后的括号由冒号“:”分为两部分,第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围,自动迭代,自动取数据,自动判断结束
- 范围for可以作用到容器对象上进行遍历

在这里插入图片描述

在这里插入图片描述
这里无法修改容器里的值的原因是范围for的方法是自动取容器中的数据,赋值给冒号前面的对象,该对象就是自动取的这个数据的拷贝,对对象进行改变是不会影响容器里的数据的,除非在被赋值的对象前加一个引用
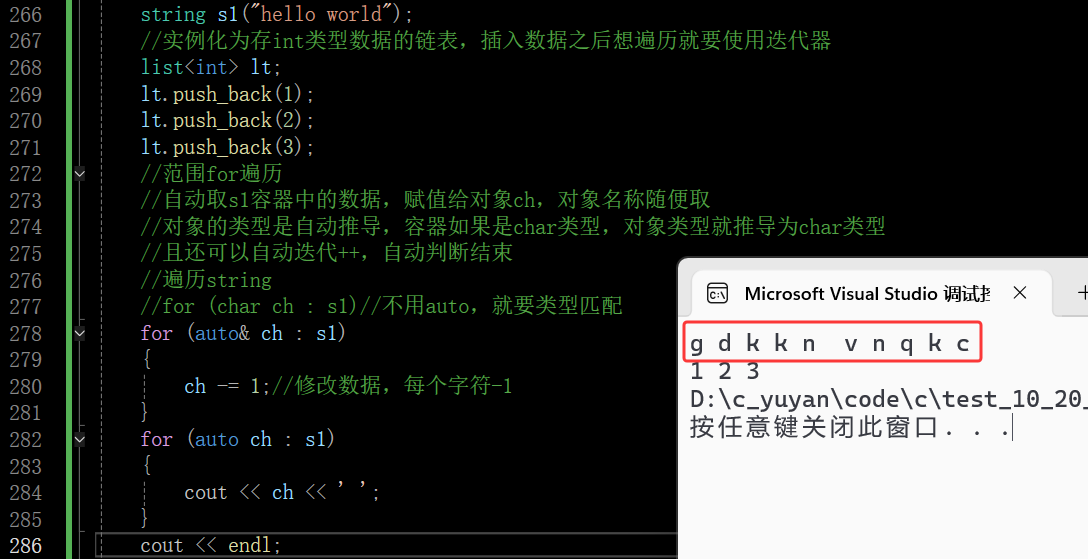
在这里插入图片描述
还有一个情况,若不修改容器中的值,且被拷贝的对象比较大,这个对象在加引用的同时还要加const,这样即能传普通对象的引用,也能传const对象的引用了
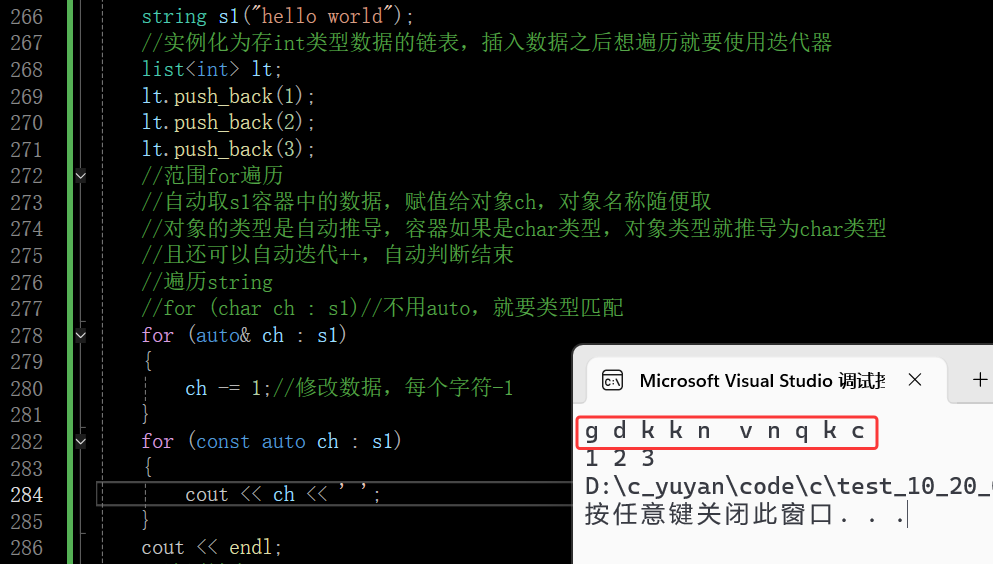
在这里插入图片描述
- 范围for看着各种自动操作很神奇,其实底层很简单,容器遍历实际就会把这些自动操作替换为迭代器,这种语法也称为语法糖(用更简单快捷的方式去遍历迭代器),这个从汇编层也可以看到
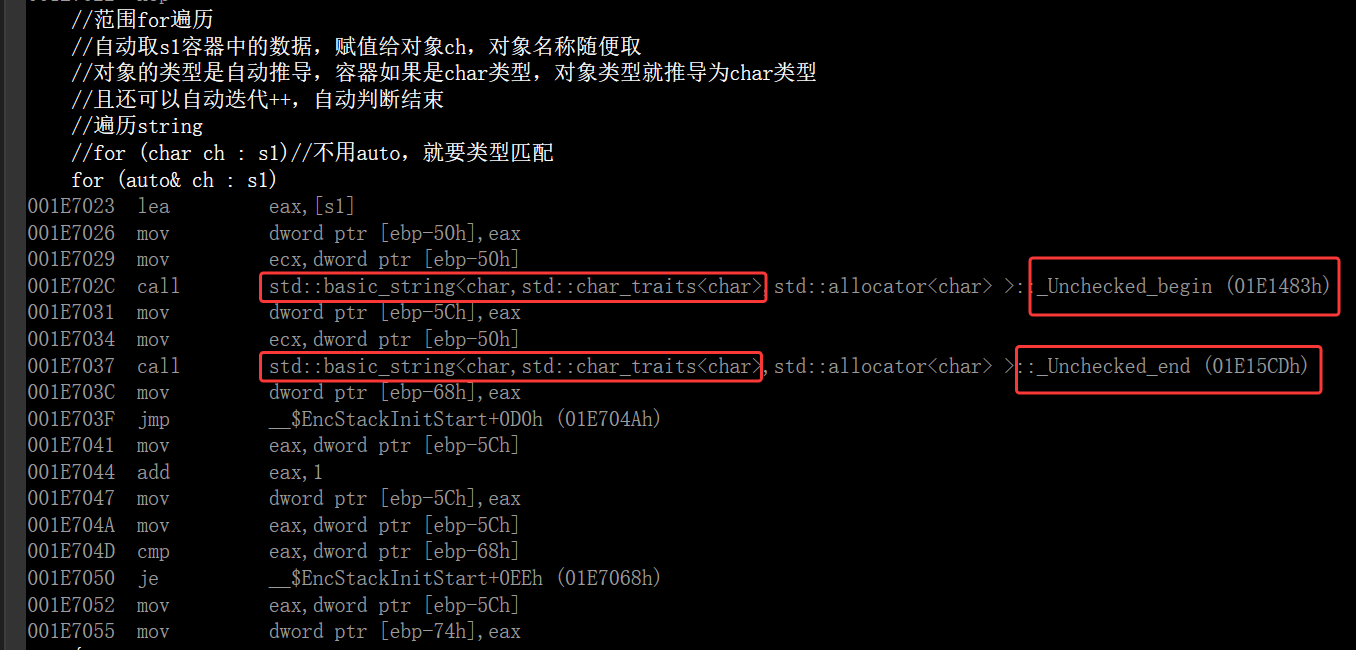
在这里插入图片描述
这是底层的begin和end,表面看到的begin和end是被处理过,就像表面string也是被basic_string typedef过的
可以认为支持迭代器的容器都支持范围for,数组也支持范围for,虽然数组不支持迭代器,但是指向数组的指针,其行为和迭代器是天然一样的,也就是数组被特殊处理过

在这里插入图片描述
所有容器都可以用范围for,所以对于string有三种遍历方式
- 下标+[ ]
- 迭代器
- 范围for
范围for可以说是已经超脱之前的语法了,一般C++11之后也称为现代C++,引入了很多很新的特性,非常好用,该语法和Python一个语法很像,感觉像是抄的,仅仅是感觉
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-10-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号