【MySQL篇】复合查询

【MySQL篇】复合查询

用户11719958
发布于 2025-12-30 14:35:13
发布于 2025-12-30 14:35:13
前言:
基于上篇MySQL基本查询,基本上都是对一张表进行查询。传送门: 【MySQL篇】MySQL基本查询详解-CSDN博客 复合查询是处理复杂业务逻辑的核心技能 ,本篇涵盖多表查询,子查询和合并查询等复杂场景
1,多表查询
在实际开发中,数据往往来自不同的表,所以需要进行多表查询。在这里用一个简单的公司管理系统,用三张表:emp,dept,salgrade来演示。
员工表
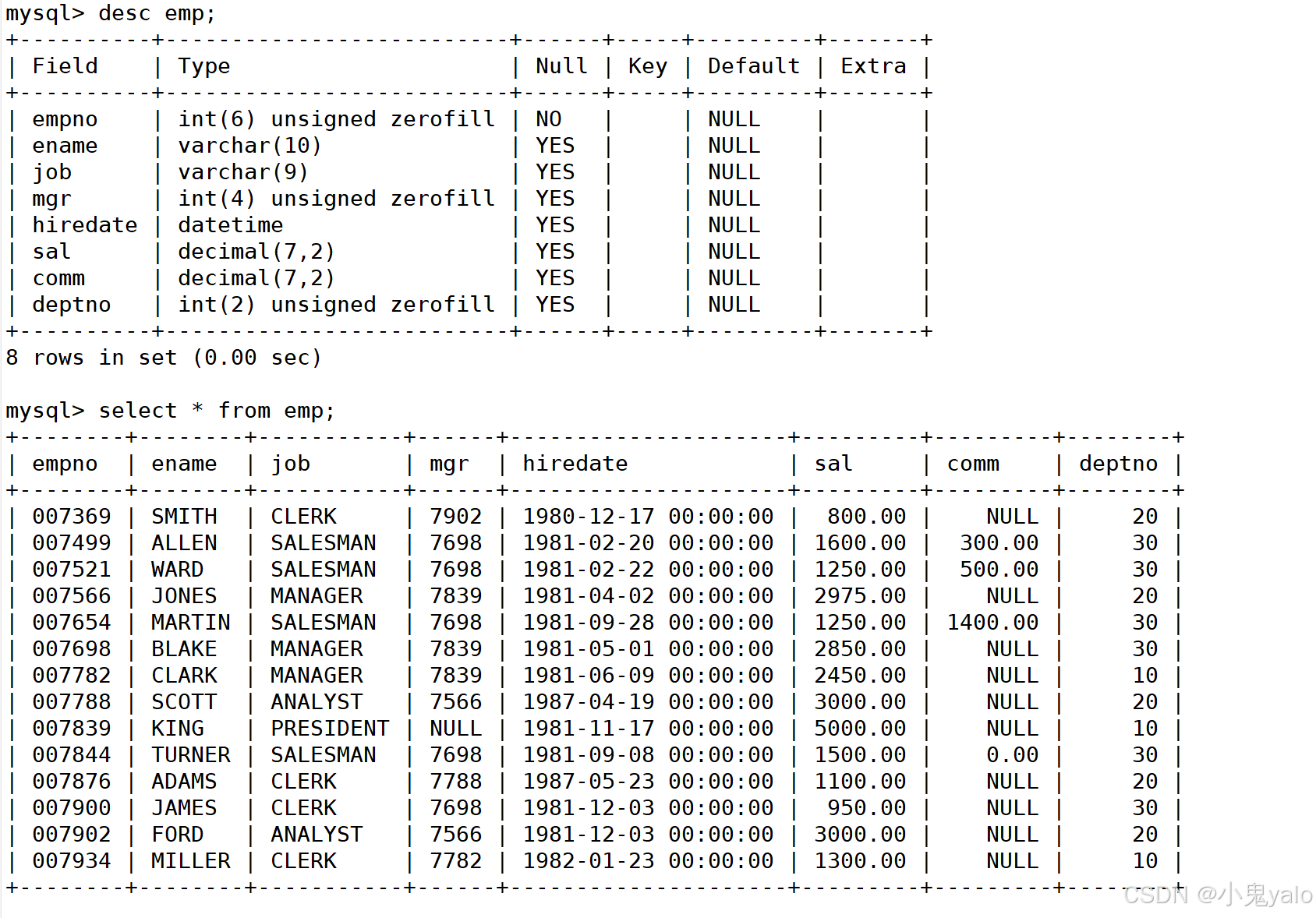
部门表

工资表

在进行多表查询之前,先补充一个笛卡尔积的概念:
在离散数学中的定义:两个集合A和B的笛卡尔积是所有有序对(a,b)的集合,其中 a∈A且 b∈B。示例: 集合A={a,b},集合B={0,1,2}。A和B的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)} 在数据库中的概念:在数据库中,当我们对两张表进行连接查询而没有指定任何条件时,就会产生笛卡尔积。 表A(m行)和表B(n行)的笛卡尔积会生成一个m*n行的表,表的每一行都是两张表的对应行的组合。也就是将第一张表中的每一行与第二张表中的每一行进行配对,从而使生成的表会很大,这张表通常不是我们想要的结果,其中包含了很多无关的数据组合。
案例:
- 显示雇员名,雇员工资以及所在部门的名字。
因为这些数据来自emp表和dept表,所以要联合查询。
select * from emp,dept;//得到这两张表的笛卡尔积,emp表的每一行与dept表的每一行进行配对,这样我们会得到一个很大的表,但其中有些行我们时不需要的,所以需要进行条件筛选。
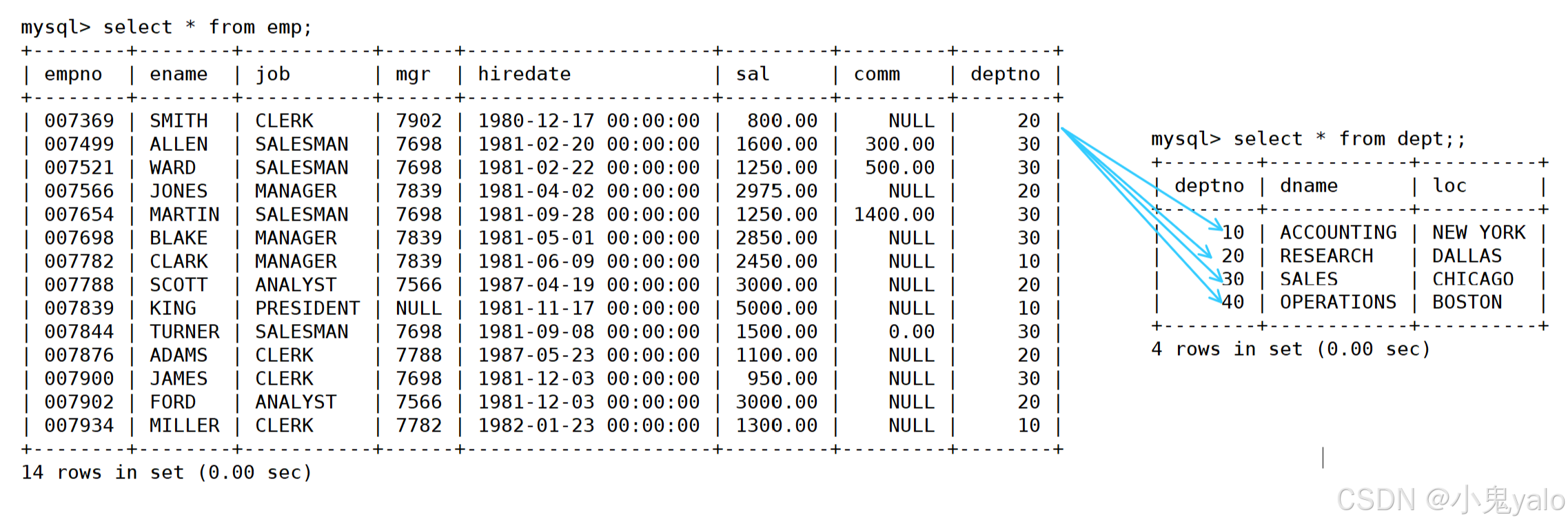
进行笛卡尔积得到的表:
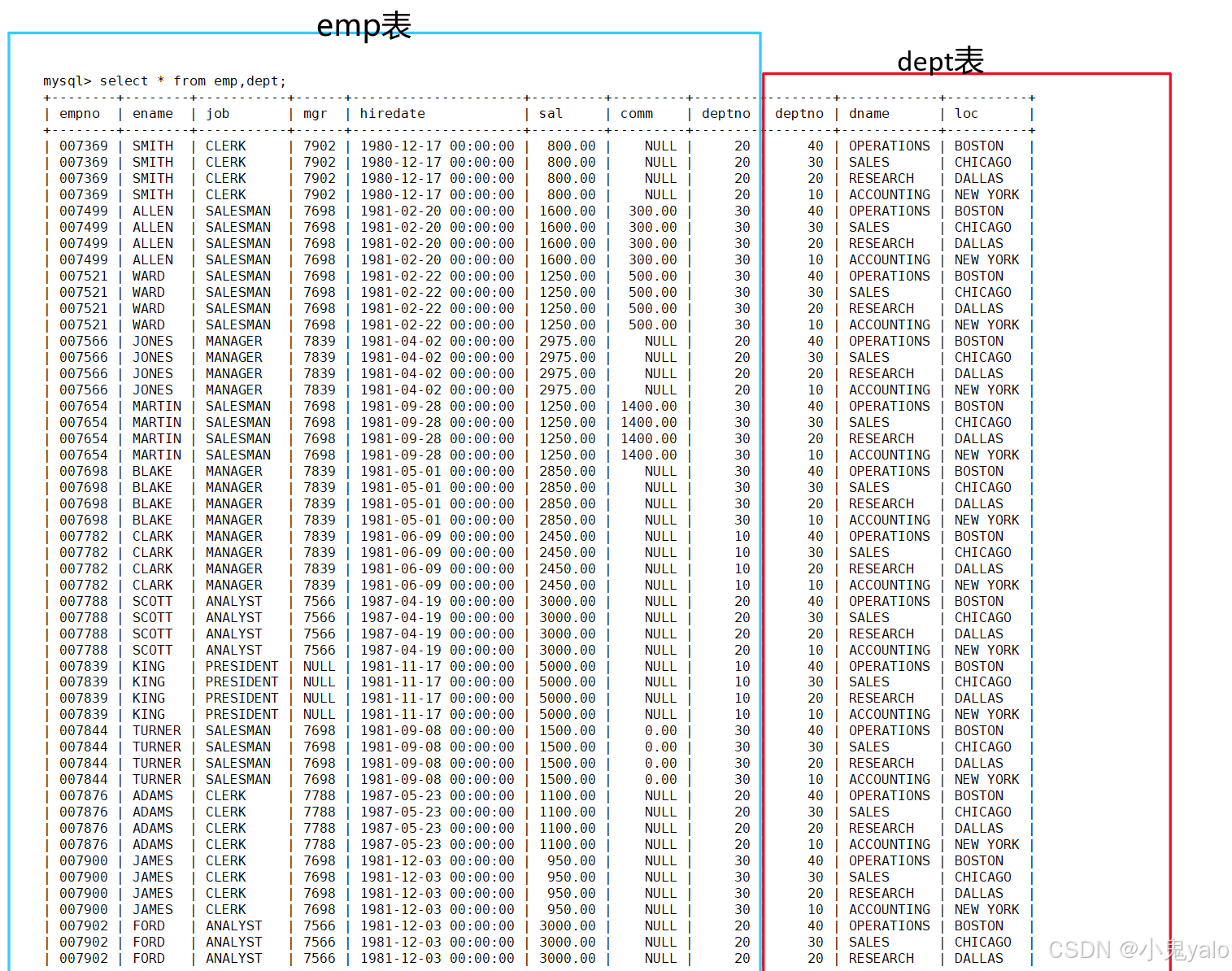
有大量的重复数据,其实我们只需要emp表中的deptno=dept表中的deptno字段的记录。
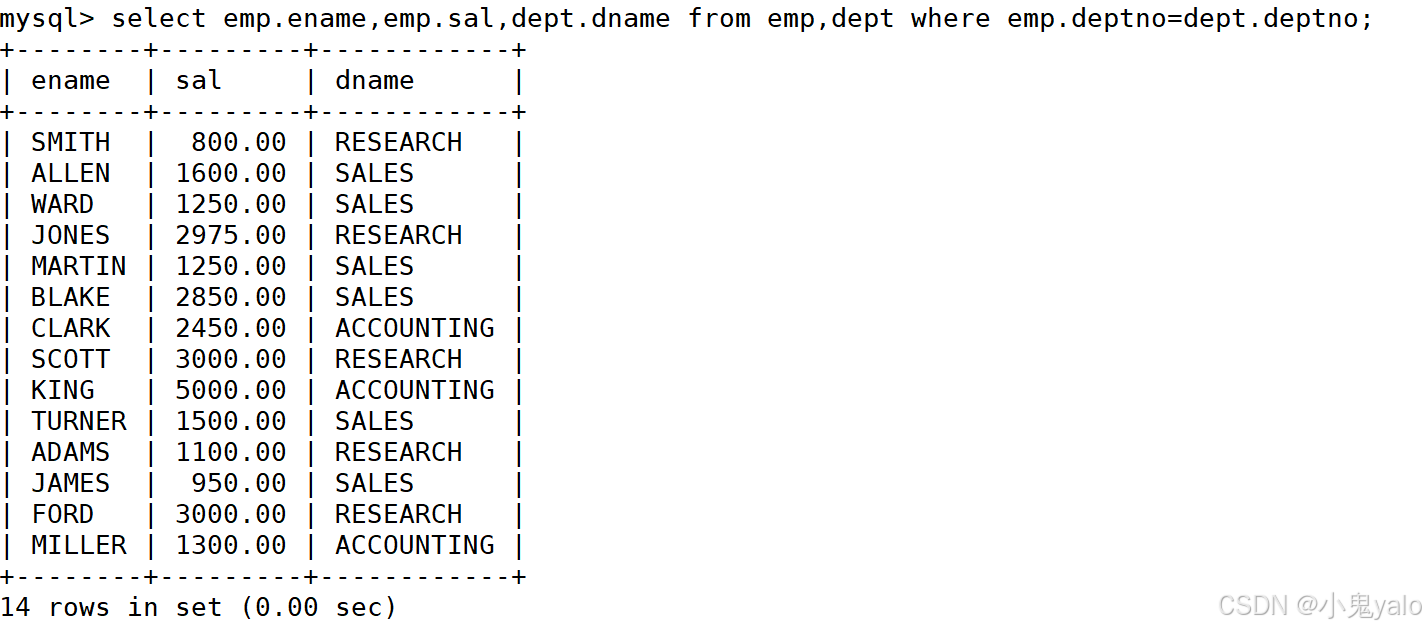
mysql> select emp.ename,emp.sal,dept.dname from emp,dept where emp.deptno=dept.deptno;

查询结果:
- 显示部门号为10的部门名,员工名和工资。
mysql> select ename,sal,dname from emp,dept where emp.deptno=dept.deptno and dept.deptno=10;

- 显示各个员工的姓名,工资以及工资级别。
mysql> select ename,sal,grade from emp,salgrade where emp.sal between losal and hisal;//进行笛卡尔积得到的表中,有些员工的工资超出了最低工资和最高工资的范围,是需要舍弃掉的数据
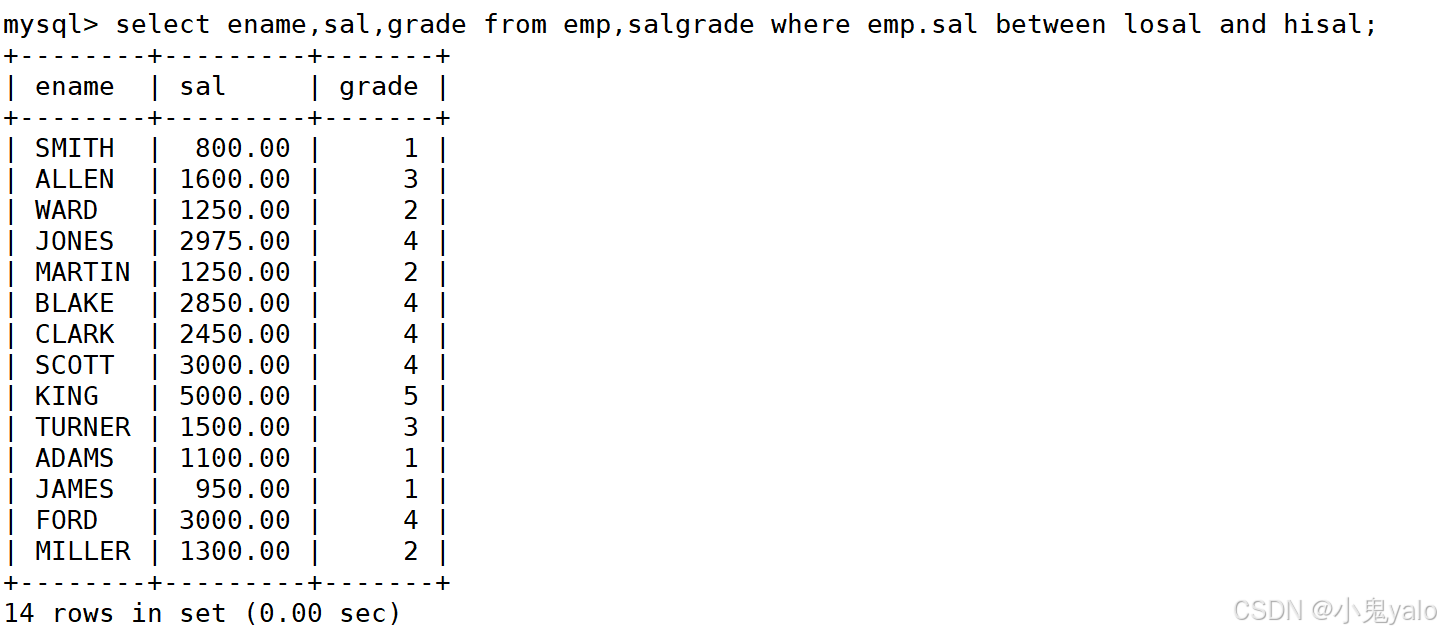
2,自连接
自连接是指在同一张表连接查询
案例:
- 显示员工FORD的上级领导的编号和姓名。(mgr是员工领导的编号)
方法一:使用子查询
mysql> select empno,ename from emp where empno=(select mgr from emp where ename='FORD');

方法二:使用多表查询
我们想要找的信息在emp表中,先将emp表和自身连接,做笛卡尔积。在结果中,筛选出员工姓名为FORD,FORD的领导编号为mgr。筛选出满足条件的数据:领导的编号=mgr
mysql> select leader.empno,leader.ename from emp leader,emp worker where leader.empno=worker.mgr and worker.ename='FORD';

3,子查询
子查询,是指嵌套在其他sql语句中的select查询语句,也叫做嵌套查询。
3.1,单行子查询
返回一行记录的子查询
案例:
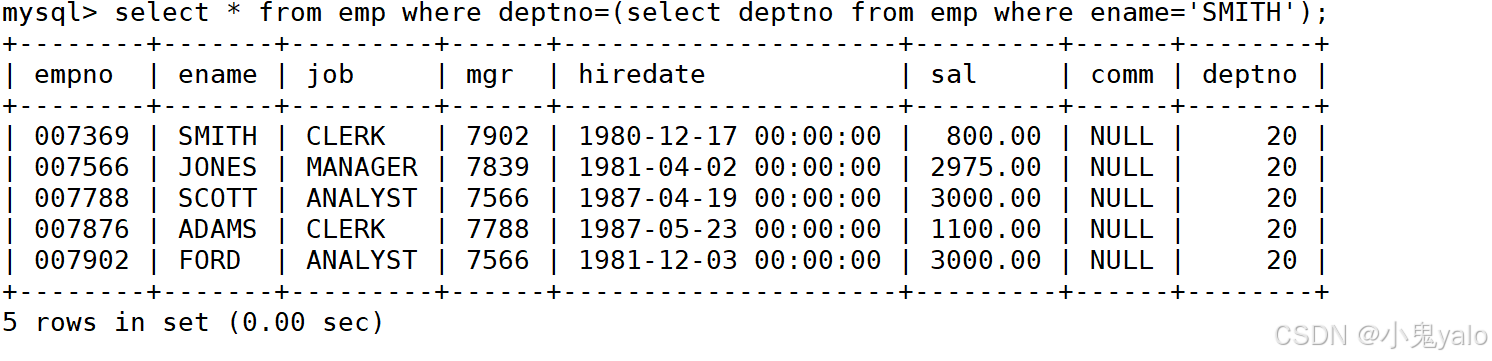
- 显示SMITH同一部门的员工
mysql> select * from emp where deptno=(select deptno from emp where ename='SMITH');
3.2,多行子查询
返回多行记录的子查询
- in关键字;查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的。
mysql> select ename,job,sal,deptno from emp where job in (select distinct job from emp where deptno=10)and deptno<>10;

- all关键字;显示工资比部门30的所有员工的工资高的员工的姓名 ,工资和部门号
mysql> select ename,sal,deptno from emp where sal>all(select sal from emp where deptno=30);

- any关键字;显示工资比部门30 的任意员工 的工资高的姓名,工资和部门号(包括自己部门的员工)
mysql> select ename,sal,deptno from emp where sal>any(select sal from emp where deptno=30);

3.3,多列子查询
案例:
- 查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
mysql> select ename from emp where (deptno,job)=(select deptno,job from emp where ename='SMITH') and ename<> 'SMITH';

3.3,在from子句中使用子查询
把一个子查询当作一个表使用
案例:
- 显示每个高于自己部门平均工资的员工的姓名,部门,工资,平均工资
mysql> select ename,deptno,sal,format(asal,2) from emp,(select avg(sal) asal,deptno dt from emp group by deptno) tmp where emp.sal>tmp.asal and emp.deptno =tmp.dt;


- 查找每个部门工资最高的人的姓名,工资,部门,最高工资
//先查找每个部门的最高工资 mysql> select max(sal) ms,deptno from emp group by deptno;

- 再找出工资最高的人 (多表连接)
mysql> select emp.ename,emp.sal,emp.deptno,ms from emp,(select max(sal) ms,deptno from emp group by deptno) tmp where emp.sal=tmp.ms and emp.deptno=tmp.deptno;

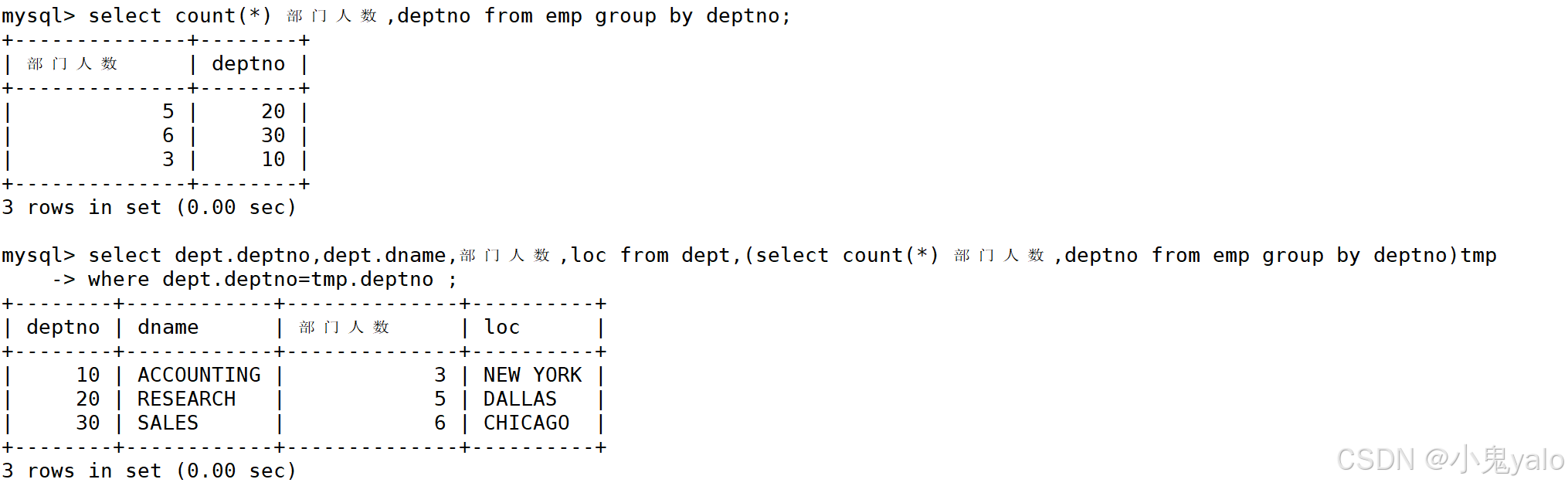
- 显示每个部门的信息(部门名,编号和地址)和人员数量
方法一:使用多表查询
mysql> select dept.dname,dept.deptno,dept.loc,count(*) '部门人数' from emp,dept where emp.deptno=dept.deptno group by dept.deptno,dept.dname,dept.loc;

方法二:使用子查询
先对emp进行人员统计
mysql> select count(*) 部门人数,deptno from emp group by deptno;

将上面的表看作临时表
mysql> select dept.deptno,dept.dname,部门人数,loc from dept,(select count(*) 部门人数,deptno from emp group by deptno)tmpundefined -> where dept.deptno=tmp.deptno ;
4,合并查询
合并多个select的结果,可以使用union,union all
4.1,union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
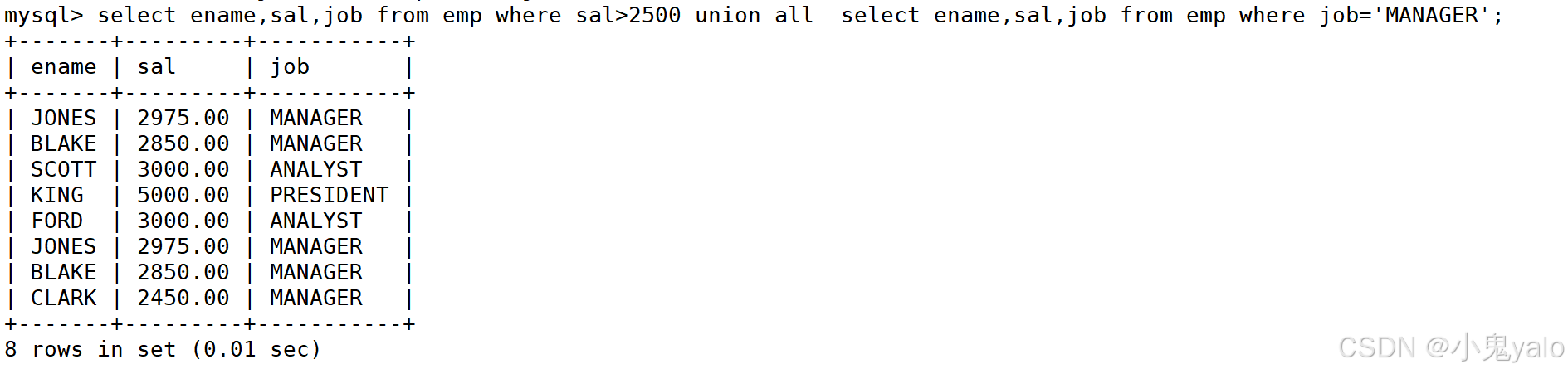
- 案例:将工资大于2500或者职位是MANAGER的人找出来
mysql> select ename,sal,job from emp where sal>2500 union -> select ename,sal,job from emp where job='MANAGER';

4.2,union all
和union用法类似,但是不会去掉结果集中的重复行。
同理,上面的案例使用union all结果如下:
mysql> select ename,sal,job from emp where sal>2500 union all select ename,sal,job from emp where job='MANAGER';
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-03-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号