从零开发分布式文件系统(5.2) IO模型的选择

从零开发分布式文件系统(5.2) IO模型的选择

早起的鸟儿有虫吃
发布于 2025-12-29 11:58:50
发布于 2025-12-29 11:58:50
从零开发分布式文件系统(5.1):告别传统I/O栈,开启用户态驱动与异步并发的NVMe时代
一、大纲
英文原文:
❝
To answer these questions, we first perform an experimental study of the hardware characteristics of NVMe flash storage in Section 2. Based on the findings, we derive implications for high-performance storage engines. Section 3 then presents a blueprint for an I/O backend that can fully exploit NVMe arrays.
中文翻译:
❝为了回答这些问题,我们首先在第2节中对NVMe闪存存储的硬件特性进行了一项实验研究。 啥意思:裸盘性能,与软件无关?
❝
基于这些发现,我们推导出其对高性能存储引擎的启示。 啥意思:设计一个存储引擎 从那个角度考虑? 随后,第3节提出了一个能够充分利用NVMe阵列的I/O后端蓝图。 啥意思:如何充分利用NVMe?
🔍 重点IT词汇解析
英文术语 | 中文翻译 | 技术含义解析 |
|---|---|---|
NVMe flash storage | NVMe闪存存储 | 指采用NVMe协议、基于闪存介质的固态硬盘。NVMe协议专为高速PCIe总线设计,相比传统的SATA接口,能极大降低延迟、提升并发处理能力。 |
High-performance storage engines | 高性能存储引擎 | 指数据库或数据存储系统中,负责直接管理数据如何在存储设备上读写、索引和缓存的核心软件组件。其设计目标是极致发挥底层硬件性能。 |
NVMe arrays | NVMe阵列 | 指将多块NVMe固态硬盘通过硬件或软件方式组合起来,形成一个逻辑存储单元,以提供更高的聚合带宽、IOPS和容量。 |
I/O backend | I/O后端 | 在存储引擎的架构中,通常指负责直接与物理存储设备进行异步读写操作(输入/输出)的底层软件模块。它需要高效管理大量的并发I/O请求。 |
Experimental study | 实验研究 | 在此语境下,指通过一系列可控的测试和基准测试,来实际测量和分析NVMe SSD在不同负载(如随机读/写、队列深度)下的性能表现。 |
Blueprint | 蓝图 | 这里指一套系统性的设计架构或方案,说明了I/O后端应包含哪些组件、如何协作,以及如何解决高并发、低延迟等关键挑战。 |
论文中新的存储引擎 (LeanStore)实现的效果
英文原文
Results.We evaluate our design in Section 4.
实验结果。我们在第4节中对设计进行了评估
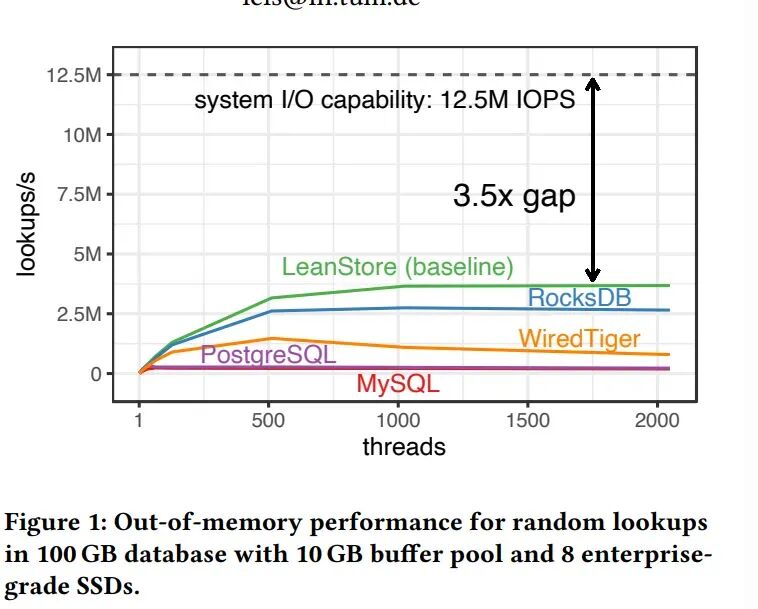
On a server with 64 cores and 8 SSDs, the resulting system indeed achieves 12.5 M lookups per second for the random lookup workload. 一台配备64核CPU和8个SSD的服务器上,最终系统在随机查找工作负载中每秒可完成1250万次查找
❝画外音:突破千万,M 代表兆(Mega),即一百万(10^6)
On the much more challenging TPC-C benchmark with a 400 GB buffer pool and a 4 TB dataset, LeanStore executes over 1 M TPC-C transactions per second.
在更具挑战性的TPC-C基准测试中(设置400 GB缓冲池和4 TB数据集), LeanStore每秒可执行超过100万笔TPC-C交易。
英文术语 | 中文翻译 | 解释与上下文含义 |
|---|---|---|
64 cores and 8 SSDs | 64核CPU和8个SSD | 描述了实验平台的顶级硬件配置,是支撑后续高性能数据的物理基础,强调其极高的并行计算与I/O能力。 |
12.5 M lookups per second | 每秒1250万次查找 | 一个关键的性能指标,用于量化系统在随机读取工作负载下的吞吐量。这个数值极高,是系统优化有效的核心体现。 |
TPC-C benchmark | TPC-C基准测试 | 业界权威的在线事务处理(OLTP) 性能测试标准。它模拟一个真实的批发供应商复杂环境,是衡量数据库系统事务处理能力的黄金标准。 |
I/O bound | 受I/O限制 / I/O瓶颈 | 描述一种系统状态。指性能已达到存储设备的I/O能力上限,成为瓶颈。这是存储系统优化的理想目标,表明软件已完全“压满”硬件。 |
二、章节:Section 2 对裸盘 NVMe flash storage做了什么测试
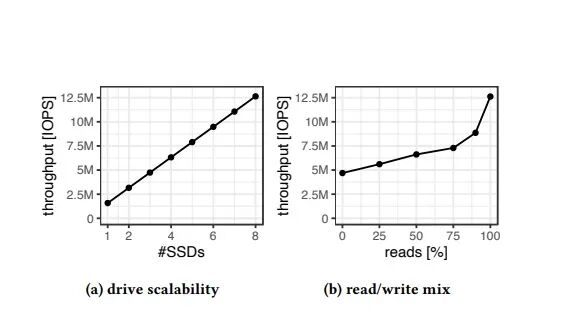
线性增长
线性增长
吞吐量确实与
固态硬盘数量呈完美线性增长
使用8个驱动器,我们应能达到惊人的1200万IOPS。
注意:软件不具备这样的能力
为什么选择page size 4K 最佳
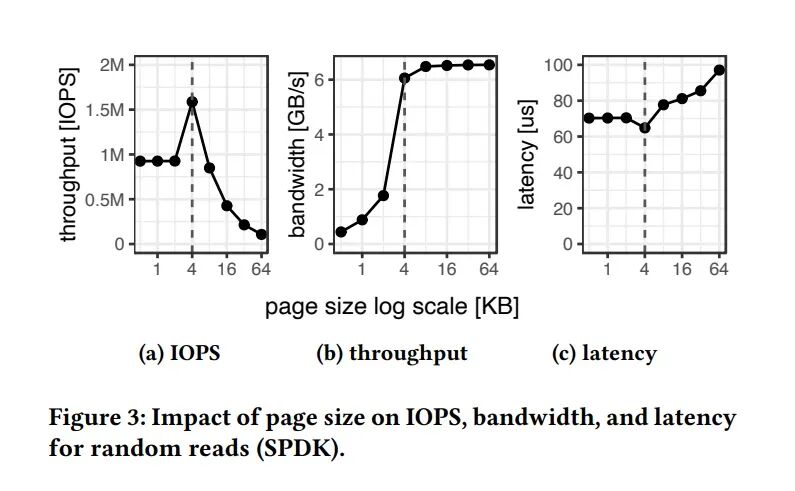
较大页面的主要缺点在于内存外工作负载上的I/O放大。 However, the big downside of larger pages is I/O amplification on out-of-memory workloads.
例如,使用16 KB页面,读取或写入100字节的记录会导致160倍的I/O放大。
With 16 KB pages, for example, reading or writing 100 Byte records results in an I/O amplification of 160x.
I/O放大(I/O Amplification)
- 定义:实际物理I/O数据量远大于所需逻辑数据量的现象
- 比喻:就像你想从图书馆借一本100页的书中的某一页,但图书馆规定必须借整本书(比如1600页)
层级 | 核心概念 | 主要产生原因 | 典型放大表现/影响 |
|---|---|---|---|
硬件/页大小 | 物理I/O的最小单位 | 即使修改1字节,也必须读写整个块(如4KB)。 | 操作100B记录,若块大小为4KB,则I/O放大40倍。 |
Ext4文件系统 | 文件系统块/页缓存 | 内核以页(如4KB)为单位管理缓存与I/O。应用大块I/O可能被拆解。 | 提交大I/O请求(如>80MB)可能导致io_submit阻塞和拆分。 |
RocksDB引擎 | LSM-Tree的写放大 | 数据从内存写入磁盘,及后台Compaction(压实)过程中的多次重写。 | 最高可达数十倍。如默认配置下,L1->L2压实可能带来约10倍的写放大。 |
RocksDB 每一层的默认大小为 : | |||
L0 - 256 MB | |||
L1 - 256 MB | |||
L2 - 2.5 GB | |||
L3 - 25 GB | |||
L4 - 250 GB | |||
L5 - 2500 GB |
我们认为,较低的延迟和I/O放大带来的收益, 使得4 KB页面成为为内存外性能优化的系统的最佳选择。
We argue that the gains from lower latency and I/O amplification make 4 KB pages the best choice for systems that optimize for out-of-memory performance.
作为英语学者,我将为您剖析这个句子中的重点词汇,并解释它们在学术论证语境下的精确含义和作用。
单词/词组 | 词性 | 核心释义 | 在本句中的学术语境解读 |
|---|---|---|---|
Argue | 动词 | 主张,论证 | 这是学术写作的标志性动词,表明作者将提出一个有证据支持的主张,而非单纯陈述观点。语气坚定、理性。 |
Gains | 名词 | 收益,好处 | 指通过技术改进获得的可衡量的积极成果。这里作为论证的逻辑起点,表明决策是基于“收益-成本”分析的。 |
Lower Latency | 名词词组 | 更低的延迟 | 核心性能指标之一。指缩短数据请求与获得响应之间的时间延迟,是衡量系统响应速度的关键。 |
I/O Amplification | 名词词组 | I/O 放大 | 核心性能指标之二。这是一个专业术语,指系统实际执行的物理输入/输出数据量远大于应用层所需逻辑数据量的低效现象。它是评估存储效率的核心概念。 |
Optimize for | 动词词组 | 为…而优化 | 明确指出了系统设计的特定目标与权衡。意味着在设计上会优先保障此目标,可能在其他方面(如内存内性能)有所妥协。 |
Out-of-memory Performance | 名词词组 | 内存外性能 | 定义了关键场景。特指当所需数据无法完全缓存在内存中,必须依赖较慢的存储设备(如磁盘、SSD)时的系统性能。这是所有论证成立的前提。 |
The best choice | 名词词组 | 最佳选择 | 这是基于前述证据得出的强结论性表述。在学术中,它通常意味着在特定约束条件和评价标准下的最优解,而非绝对普适的最优。 |
三、选择什么I/O Interfaces
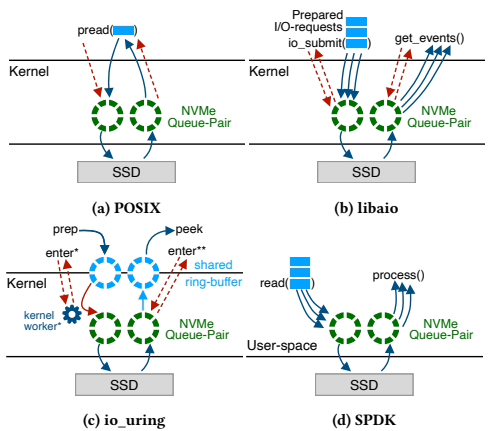
接口的本质: 无论用哪个库,最终目标都一样:把I/O请求塞进NVMe的提交队列,然后等SSD处理完,再从完成队列里取结果。
区别在于“塞”和“取”的方式。
Blocking POSIX interface.
libaio: traditional asynchronous interface
io_uring: modern asynchronous interface.
1. 阻塞式POSIX接口(read/write)
- 怎么用: 最传统的方式。线程发一个请求,然后就被内核“挂起”(阻塞),直到SSD干完活才被唤醒。
- 架构师视角:简单,但性能差。
- 一个线程一次只能处理一个I/O,要榨干SSD的性能,
- 你得启动成千上万个线程,上下文切换开销巨大,完全不现实。这是给慢速磁盘时代设计的模式。
2. 传统异步接口(libaio)
- 怎么用: 进步了。可以一次性提交一批请求(
io_submit),然后立刻返回,不阻塞。程序需要自己轮询(get_events)来检查哪些请求完成了。 - 架构师视角:减少了系统调用次数,一个线程能管理多个并发I/O。
- 但接口比较原始,而且在高并发下,轮询和事件获取的效率可能成为瓶颈。
3. 现代异步接口(io_uring)
- 怎么用: Linux内核的“新宠”。它在用户态和内核态之间建立了共享的环形队列。用户程序把请求丢到提交队列,发个信号(
io_uring_enter)通知内核去处理。内核处理完,把结果放到完成队列。 - 高级模式(SQPOLL): 内核可以开个专门的线程来轮询提交队列,这样连发信号这个系统调用都省了,进一步降低延迟。
- 高级模式(IOPOLL): 可以关掉硬件中断,让应用自己轮询完成队列。在超高IOPS场景下,这能减少中断开销,提升性能。
- 架构师视角:目前Linux上最先进、最灵活的通用异步I/O方案。 它试图在易用性和极致性能之间找到平衡,支持多种优化模式。
4. 用户态I/O(SPDK)
- 怎么用: “掀桌子”的方案。完全绕过操作系统内核(文件系统、块设备层、页缓存)。直接在用户态分配和管理NVMe的队列对。提交请求就是往内存里的环形缓冲区写条记录,然后通知一下SSD
io_uring 是如何工作的?
io_uring 的核心创新在于使用了共享内存环形队列,极大地减少了用户程序与内核之间的通信开销。
它的架构如图 5c 所示,主要包含两个队列:
- 提交队列(Submission Queue, SQ):位于用户程序和内核共享的内存中。当程序要发起 I/O(如读、写)时,它不再调用系统调用,而是直接把请求描述符写入这个队列。
- 完成队列(Completion Queue, CQ):同样位于共享内存中。当内核(或SSD)处理完一个 I/O 请求后,会把完成的结果(成功/失败、字节数等)写回这个队列
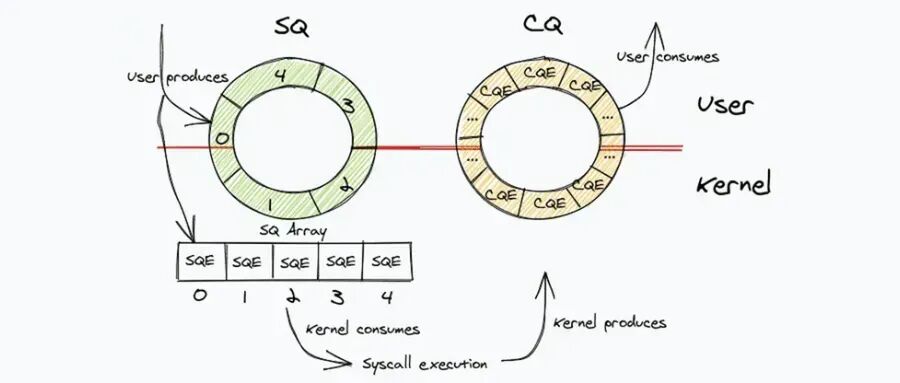
四、NVMe Queue Pair 是什么
NVMe Queue Pair是硬件层面的高性能生产-消费者模型
简单来说,一个NVMe Queue Pair(队列对)就是主机(CPU)与NVMe固态硬盘(SSD)之间进行通信的一对“指令通道”。
一个Queue Pair由两个独立的队列组成,其分工与协作关系如下:
队列 | 名称 | 方向 | 核心功能 | 类比 |
|---|---|---|---|---|
SQ | 提交队列 (Submission Queue) | 主机 → SSD | 主机将需要执行的I/O命令(如读、写)描述符放入此队列,通知SSD“有活要干”。 | 像一家餐厅的点菜单。顾客(应用)把订单(I/O请求)写好放在单子上,交给服务员(驱动)。 |
CQ | 完成队列 (Completion Queue) | SSD → 主机 | SSD处理完SQ中的命令后,会将完成状态(成功或失败)写入此队列,通知主机“活干完了”。 | 像餐厅的出菜铃。厨房(SSD)做好菜后,按一下铃(写入CQ),通知服务员来取。 |
💡 为什么Queue Pair设计如此重要?
这种分离的队列对设计带来了几个关键优势,正是NVMe性能远超旧协议(如AHCI)的原因:
- 极高的并行性:一个NVMe设备可以支持多个(如64K个)Queue Pair。每个CPU核心可以拥有自己专属的Queue Pair,从而彻底避免了多核争用同一队列的锁开销,实现了真正的并行I/O。
- 极低的软件开销:命令提交和完成通知通过简单的内存写入和门铃寄存器操作完成,流程极其精简,远少于旧协议所需的复杂寄存器操作。
- 深度队列支持:单个SQ的深度(可容纳的命令数)很大(如64K),允许主机一次性提交大量I/O请求,让SSD能够充分发挥其内部并行处理能力,优化调度。
- 与现代I/O模型天然契合:你可以将
io_uring的SQ/CQ看作是在软件层对NVMe硬件SQ/CQ架构的模仿和延伸。io_uring在应用与内核之间建立了一对高效的异步队列,而NVMe QP在内核与硬件之间建立了另一对。两者结合,构成了一条从应用到硬件的、完整的、无阻塞的异步I/O流水线。
两种具体的Poll模式详解
特性维度 | 传统 I/O 模式 (中断驱动) | io_uring Poll 模式 (轮询驱动) |
|---|---|---|
核心理念 | 被动等待:提交请求后,CPU去做别的事,等待硬件中断来通知完成。 | 主动探查:CPU持续、主动地去检查队列状态,看是否有新请求或已完成事件。 |
工作方式 | 类似 “信箱+门铃”:把信(请求)投进信箱,按门铃(系统调用/中断)等人处理。 | 类似 “传送带”:把信放上传送带(共享内存队列),有专人(轮询线程)一直盯着传送带取信、送回信。 |
主要开销 | 1. 系统调用(用户态/内核态切换)2. 硬件中断(打断CPU,上下文切换) | 持续的CPU占用:轮询线程或应用需要不断检查队列,即使空闲时也占用CPU周期。 |
延迟 | 较高,受中断处理和调度延迟影响。 | 极低,请求和完成的处理几乎是实时的,避免了所有通知延迟。 |
适用场景 | 通用场景,IOPS不极端高。 | 超高IOPS、超低延迟场景,如高性能数据库、金融交易。CPU资源可被专门用于换I/O性能。 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号