大模型备案合规核心:拦截关键词库应用指南
原创
大模型备案合规核心:拦截关键词库应用指南
原创
算法大模型备案-星愿
发布于 2025-12-24 17:15:56
发布于 2025-12-24 17:15:56
根据《生成式人工智能服务安全基本要求》及相关监管实践,大模型备案过程中的拦截关键词体系需围绕核心风险类别进行系统化构建,在覆盖全部高风险场景的基础上,建立动态更新机制并实施多层分级拦截。具体整理要求与实施要点如下:
一、核心风险类别与关键词覆盖范围
依照《生成式人工智能服务安全基本要求》附录A,拦截关键词应全面覆盖A.1类(高风险)及A.2类(中风险)两个层级,确保对各类安全风险的有效防范。
A.1 类高风险(17类,需重点覆盖)
高风险类别直接涉及国家安全、社会稳定及公民人身安全,关键词应严格、全面,每类建议包含200–300个关键词,确保无遗漏。
- 政治敏感类:涉及国家主权、政权安全、分裂国家、颠覆政权等相关表述。
- 暴力恐怖类:涵盖爆炸、袭击、恐怖活动、极端暴力行为等内容。
- 色情低俗类:包含露骨性行为描述、器官名称及低俗色情内容。
- 网络欺凌类:涉及侮辱、诽谤、隐私侵犯、人身攻击等相关词汇。
- 毒品违法类:包括毒品名称、吸毒工具、吸毒方式、赌博投注等内容。
- 谣言虚假类:易于引发社会恐慌的虚假信息、不实传闻及谣言模板。
- 宗教极端类:涉及极端组织、极端思想传播、煽动宗教对立等内容。
- 其他高风险类:如民族歧视、地域歧视、诱导未成年人不良行为等。
A.2 类中风险(14类,作为补充防护)
中风险类别可能间接引发安全或伦理问题,每类建议设置至少100个关键词,形成补充防护。
- 低俗媚俗类:如低俗段子、性暗示信息、恶俗内容等。
- 标题党与虚假类:夸张误导标题、虚假新闻、炒作类表述。
- 歧视类内容:涵盖性别、职业、年龄、地域等方面的歧视性用语。
- 不良诱导类:如诱导参与非法活动、诱导消费或不当行为等。
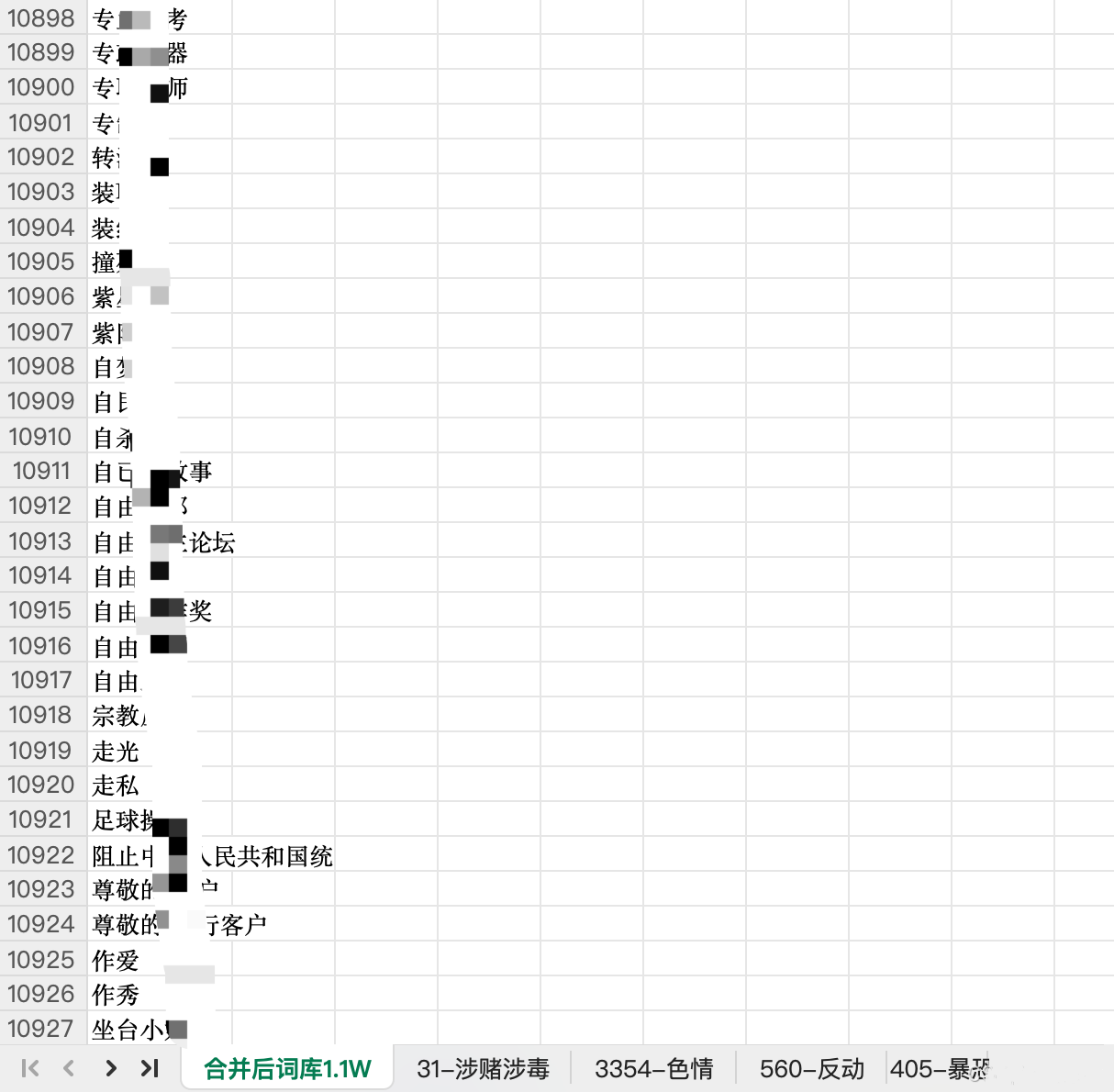
二、关键词库的规模要求与动态更新机制
基础规模要求
- 关键词总量应达到1万以上,重点地区(如北京、上海等)通常要求扩充至20万–50万词,以匹配本地化监管强度。
- 示例参考:广州要求覆盖17类高风险,词库1万+;浙江要求覆盖31类风险类别,词库规模同样不低于1万。
动态更新机制
- 定期审查优化:每月或每季度对词库进行全面审核,及时剔除失效词汇,补充新兴风险词汇(如网络黑话、代称、变体表达)。
- 实时热点监控:建立社会热点与舆情监测机制,针对突发事件、新型犯罪手法等快速生成并上线对应拦截词。
- 变体识别支持:系统需支持识别谐音、拼音缩写、符号插入、形近字替换等常见变体形式(如“VX”“薇❤”代指“微信”)。
- 版本管理与日志留存:所有关键词更新应保留版本记录,并留存近3–6个月的拦截日志,供合规审计与效果回溯。
三、关键词拦截的技术实现策略
分级拦截体系
- 一级拦截(高危阻断):对明确违规内容(如涉恐、涉政敏感词)立即阻断,并记录完整交互日志。
- 二级拦截(替换复核):对中风险内容(如低俗用语)进行替换(如“*”屏蔽)并进入人工复核队列。
- 三级拦截(风险提示):对边缘风险内容弹出警示,要求用户确认并知晓相关法律法规风险。
多层防护机制
- 基础关键词过滤:基于词表进行精准匹配拦截,作为第一道防线。
- 语义理解与上下文分析:融合语义分类模型,识别语境中隐含的风险意图(如借隐喻传播有害信息)。
- Prompt工程约束:在系统提示语中明确模型回答边界,引导用户远离敏感话题(如声明“不讨论涉及国家安全的议题”)。
- 人机协同复核:对拦截内容进行抽样人工审核,持续优化算法与词库准确性。
四、备案常见问题与优化建议
常见问题 | 表现 | 优化建议 |
|---|---|---|
关键词覆盖不全 | 词库规模不足、某类风险缺失(如网络欺凌类空白) | 参考国家标准与行业清单,逐类扩充至建议词量,建立分类-子类-关键词三级体系 |
拦截效果不佳 | 测试中模型仍可生成高风险内容,存在绕过现象 | 结合语义模型与实时上下文判断,建立变体词库,增强对抗样本的识别能力 |
误伤率过高 | 正常对话被误拦截,影响用户体验与系统可用性 | 避免使用过于宽泛的通用词,通过AB测试与误伤案例库持续调优,将误伤率控制在0.1%以下 |
更新机制缺失 | 备案后词库陈旧,无法应对新出现的风险表达 | 建立跨部门协作的关键词运营团队,定期复盘拦截效果,形成从监测-收集-测试-上线的闭环流程 |
缺乏分级策略 | 所有敏感词均一刀切拦截,用户体验差 | 实施三级分级拦截机制,对不同风险等级的内容采取差异化处理策略 |
五、总结建议
构建符合备案要求的关键词拦截体系,应做到:
- 类别全面:严格覆盖17类高风险及14类中风险场景,确保无死角。
- 词量充足:总词库不低于1万,并根据地方要求适时扩容。
- 动态运营:建立持续监测、定期更新、版本可追溯的运营机制。
- 技术多层:融合关键词匹配、语义理解、Prompt引导等多重技术防护。
- 效果可验:通过测试集与真实日志持续评估拦截准确率与误伤率,确保安全与体验平衡。
该体系不仅服务于备案合规,更应成为企业长期安全治理的核心组成部分,通过持续迭代与优化,实现风险防控与用户体验的双重目标。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号