为什么 long 有时必须加 L:快速搞懂宽化转换

为什么 long 有时必须加 L:快速搞懂宽化转换

超级苦力怕
发布于 2025-12-24 09:13:18
发布于 2025-12-24 09:13:18
前言
本文主要内容:快速搞懂
long类型为什么必须写L、字面量默认类型、隐式转换和显式转换
一段“看起来没问题”的赋值,为什么有人会编译失败?
先看这段代码:
public static void main(String[] args) {
long a = 999999999; //正确
long b = 999999999; //正确
long c = 9999999999L; //正确
}很多人第一次看到会觉得:
a、b、c 不都是 long 吗?为什么第三行还要加个 L?
答案藏在一个关键规则里:Java 对整数字面量的默认类型判断。
1. 整数字面量默认是 int
Java 编译器看到一个没有任何后缀的整数(比如 999999999)时,会按下面的规则理解它:
- 没有后缀的整数字面量,默认是
int - 带
L或l后缀的整数字面量,才会被当成long
也就是说:
999999999会先被编译器当成int9999999999L会直接被当成long
2. 宽化转换(隐式转换)
int -> long 为什么能自动发生?
看第一行:
long a = 999999999; // int -> long编译器的“脑内过程”大概是:
999999999是整数字面量,默认int- 目标变量
a是long int -> long属于 宽化转换(Widening Primitive Conversion)- 宽化转换通常是安全的:不会溢出、不会截断
- 所以允许 隐式 自动完成
2.1 什么是“宽化转换”?
宽化转换的核心是:
- 小范围类型自动升级到大范围类型
- 不需要强制类型转换语法
常见的宽化链路:
byte -> short -> int -> longchar -> int -> longfloat -> double
3. 为什么 long 类型需要加 L
为什么 9999999999 不加 L 就不行?
关键在于:它超出了 int 的取值范围。
Integer.MAX_VALUE = 2147483647
如果你写成这样:
long c = 9999999999; // 编译错误:integer number too large编译器仍然会先尝试把 9999999999 当成 int 字面量解析,结果发现放不下,于是直接报错。
它甚至还没判断是否可以宽化转换。
所以你必须告诉编译器他是 long 类型,即在最后面加 L
long c = 9999999999L; // OK4. 一张图看懂:编译器到底怎么处理你的赋值?
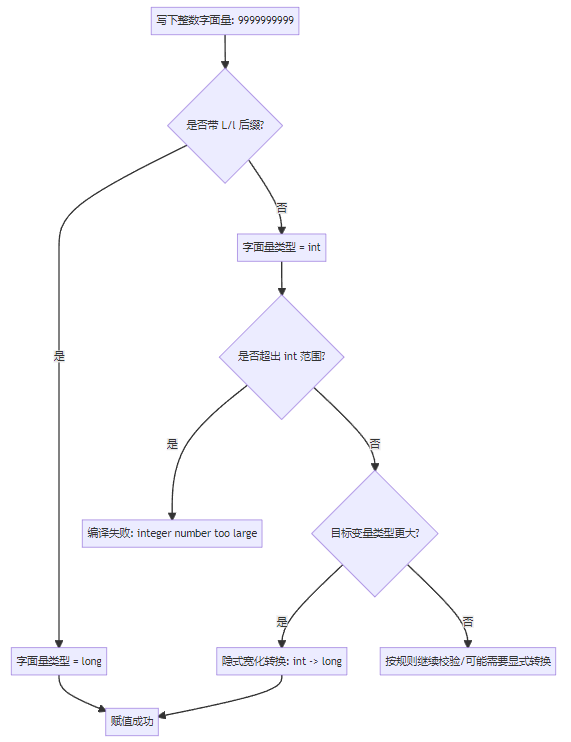
5. 隐式 vs 显式:你真正需要记住的对比
维度 | 隐式转换(宽化) | 显式转换(强制/声明) |
|---|---|---|
触发方式 | 编译器自动完成 | 你必须写出来(如 (int) 或 L) |
典型方向 | 小范围 -> 大范围 | 大范围 -> 小范围,或需要明确类型 |
安全性 | 通常安全 | 可能溢出 / 丢失精度 |
例子 | int -> long | long -> int、9999999999L |
这里要注意:9999999999L 更像是 “字面量类型显式声明”,不是 (type) 形式的强转,但它的目的相同:避免编译器误判。
6. 常见坑:宽化转换也可能丢失信息
通常认为宽化转换是安全的,不会丢失信息。这在 int -> long 这类整数转换中确实成立,但需要特别注意数值类型转换的精度问题:
int x = 16_777_217; // 2^24 + 1
float f = x; // int -> float(宽化)
int y = (int) f;
System.out.println(y); // 结果可能不是 16_777_217原因在于:float 的有效精度有限(约24位二进制有效数字)。当较大的 int 值转换为 float 时,可能会发生精度舍入,导致信息丢失。
结语
- 没有后缀的整数字面量默认是
int int -> long是宽化转换,允许隐式发生- 字面量一旦超出
int范围,必须显式声明为long(加L),否则直接编译失败
- 如果本文对你有帮助:欢迎点赞、收藏,让更多正在学 Java 的同学看到。
- 遇到问题或有不同理解:可以在评论区留言,一起讨论、互相学习。
- 想系统看更多内容:可以关注专栏《Java成长录》,一起把基础打牢。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号