MySQL-多表查询

MySQL-多表查询

小陈又菜
发布于 2025-12-23 16:17:32
发布于 2025-12-23 16:17:32
多表关系
概述
在项目开发中,在进行数据库表设计时,会根据业务模块,分析并设计表结构,由于业务之间的相互关联,所以表与表之间往往涉及多种关系,一般包括:
- 多对一(一对多)
- 多对多
- 一对一
- 多对一
案例:
部门与员工的关系
关系:
一个部门可以对用多个员工,但是一个员工只能对应一个部门
实现:
在多的一方设置外键,指向一的一方
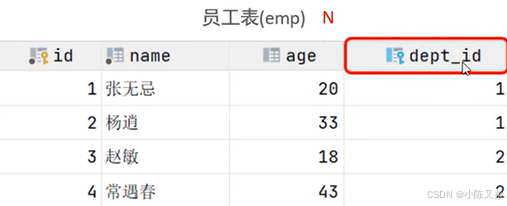
在员工表中emp设置外键 deft_id,与部门表deft中的主键 id 关联:

- 多对多
案例:
学生与课程的关系
关系:
学生可以对应多门课程,同样一门课程也可以对应多位学生
实现:
建立的三张中间表,中间表至少包含两个外键,用于关联两张表中的主键
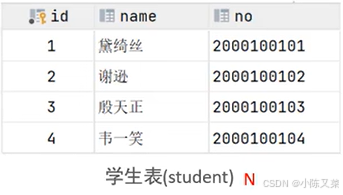

中间表:
这里介绍一个技巧,在DataGrip软件中,能够将表结构的关系可视化:
右击想要查看的表结构,点击 图->显示图:
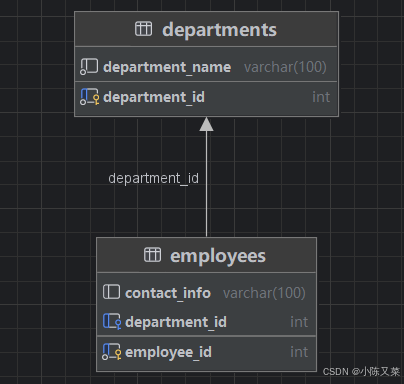
这样能够清楚的观察到,两张表通过外键department_id相关联。
- 一对一
案例:
用户与用户详情
关系:
一位用户与其用户详情肯定是一一对应的,一般用于单表拆分,将基础字段放在一张表中,详细字段放在另一张表中,能够提高效率。
实现:
在任意一方设置外键,与另一方的主键相关联,并且将外键设置为UNIQUE

这是一张用户表,其中不仅有用户的基本信息,还包括了一些详细信息,在一定程度上会影响信息查询的效率,所以我们进行单表拆分:
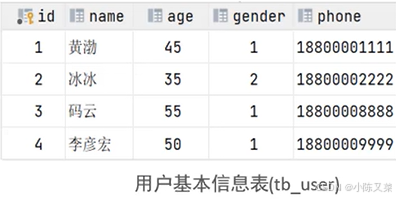
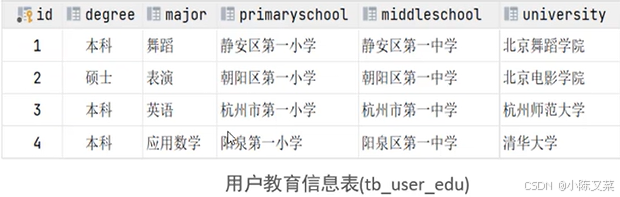
将其拆分成了用户的基本信息,与用户的详细信息,如此一来大大提高了,信息查询的效率,我可以在用户教育信息表中加入一个字段,id 将其与基本信息表中的id关联起来。
多表查询概述
定义
从多张表中查询数据
笛卡尔积
是指数学中,集合A与集合B的所有组合(在进行多表查询时需要消除多余的的卡尔积)
例如我要进行多表查询时:
select * from employees,departments;
--emp中有5条数据,dept中有5条数据那么此时将会查询出5*5=25条数据,这就是笛卡尔积,所以在实际的多表查询时,要消除多余的笛卡尔积,比如:
select * from employees,departments where employees.department_id=departments.department_id;我在多表查询语句后面加上约束函数,以外键关联的两个值作桥梁,来消除多表查询中多余的数据。
多表查询的分类
连接查询
- 内连接
查询两张表的交集部分
隐式自连接
SELECT 字段列表 FROM 表1 ,表2 ,WHERE 条件;
select * from employees,departments where employees.department_id=departments.department_id;上面演示就是一个隐式自连接查询
这里要注意的是,如果我在查询时候对表起了别名,那么在后面使用约束函数时,就必须使用表的别名
select * from employees,departments where employees.department_id=departments.department_id;上面我将将两张表分别起别名叫做,e、d,此时如果进行查询就会报错:

显式自连接
SELECT 字段列表 FROM 表名 表别名 INNER JOIN 表名 表别名 ON 条件;
select e.employee_id,d.department_name from employees e inner join
departments d on d.department_id = e.department_id;- 外连接
左外连接(查询左表的全部数据,两表交集的数据)
SELECT 字段列表 FROM 表名 表别名 LEFT OUTER JOIN 表名 表别名 ON 条件;
select e.*,d.department_name from employees e left outer join
departments d on e.department_id = d.department_id;这里有一个小技巧,当一个表中有null数据时,应该使用左表查询,因为左表查询能包含左表的所有数据。
右外连接(查询右表的全部数据,两表的交集数据)
只需要将 LEFT OUTER 改为 RIGHT OUTER
- 自连接
当前表与自身的连接查询,子连接必须使用表别名。
举例,一张员工表中,员工之间会存在领导关系,假设有一个字段是员工直属领导的编号,那么就可以通过以下自连接的方式:
select a.name b.name from emp a emp b where a.manager.id b.id;如此便能够,查询到员工姓名。及其直属领导姓名 。
注意的是:自连接查询可以是,外连接,也可以是内连接。
联合查询
语法:
SELECT *FROM EMP WHERE AGE>=50 UNION [ ALL ] SELECT *FROM EMP WHERE SALARY<5000;
如果将ALL加上的话,就会将上下两次的查询结果直接拼成一张表;如果不加ALL,就会自动将查询到的相同结果合并:
如下图,‘鹿鼎客’的相关信息出现了两次,这就是UNION ALL的结果
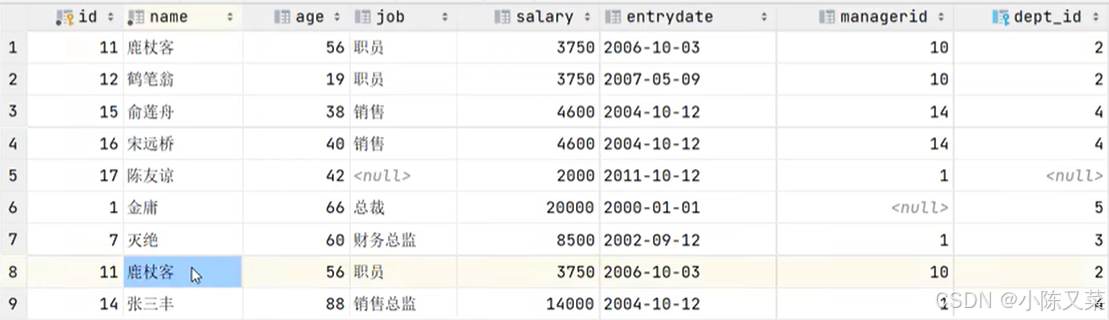
而UNION的结果会是:
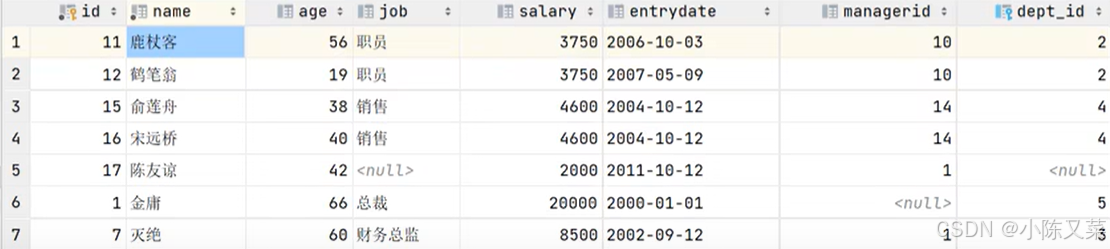
在使用UNION时,要注意,如果前后查询得到的表的字段数不相同,就会报错无法进行合并:

子查询
概念
SQL语句中嵌套查询语句,叫做嵌套查询,又称子查询。
SELECT *FROM 表名 WHERE COLUMNS = (SELECT *FROM 表名 );
分类
- 标量子查询
子查询返回的是一个单一的值(日期、字符、数字)。
举例:我要查询所有销售部门员工的信息
常规拆解:
- 先在部门表中找到销售部门对应ID
select id from dept where dept_name = '销售部';
--假如返回的id=4- 使用该ID作为查询员工信息表的约束条件
select *from emp where deft_id=4;如果使用标量子查询:
select *from emp where deft_id = (select id from dept where dept_name = '销售部');列子查询
子查询结果返回的是一列数据(可以是多行)
常用操作符:

ALL
select *from emp where salary > all(select salary from emp where deft_id = 4);满足返回的所有条件
IN
select *from emp where dept_id IN (select id from deft where deft_name='销售部' deft_name='财务部');在指定范围内即可
行子查询
子查询返回的结果是一行数据(可以是多列)。
select *from emp where (salary,managerid) = (select salary manegerid from emp where name='张无忌');上面语句是,查询与张无忌工资、直属领导相同的员工信息。
表子查询
子查询结果返回的是多行多列。
举例讲解:
我要查询与‘宋远桥’、‘鹿杖客’的工资、职位相同的员工信息
常规拆解:
- 先查询到‘宋远桥’、‘鹿杖客’的工资、职位
- 再查询与‘宋远桥’、‘鹿杖客’的工资、职位相同的员工信息
那么使用表子查询连接起来就是:
select *from emp where (salary,job) in
(select salary job from where name='宋远桥' or name='鹿杖鼎');总结

本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-03-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号