01.C++入门基础(上)


1.C++发展历史
C++的起源可以追溯到1979年,当时Bjarne Stroustrup(本贾尼·斯特劳斯特卢普,这个翻译的名字不同的地方可能有差异)在贝尔实验室从事计算机科学和软件工程的研究工作。⾯对项目中复杂的软件开发任务,特别是模拟和操作系统的开发工作,他感受到了现有语言(如C语言)在表达能力、可维护性和可扩展性方面的不足。
1983年,Bjarne Stroustrup在C语言的基础上添加了面向对象编程的特性,设计出了C++语言的雏形,此时的C++已经有了类、封装、继承等核⼼概念,为后来的面向对象编程奠定了基础。这一年该语言被正式命名为C++。
在随后的几年中,C++在学术界和工业界的应用逐渐增多。一些大学和研究所开始将C++作为教学和研究的首选语言,而一些公司也开始在产品开发中尝试使用C++。这一时期,C++的标准库和模板等特性也得到了进一步的完善和发展。
C++的标准化工作于1989年开始,并成立了一个ANSI和ISO(International Standards
Organization)国际标准化组织的联合标准化委员会。1994年标准化委员会提出了第一个标准化草
案。在该草案中,委员会在保持斯特劳斯特卢普最初定义的所有特征的同时,还增加了部分新特征。
在完成C++标准化的第一个草案后不久,STL(Standard Template Library)是惠普实验室开发的一系列软件的统称。它是由Alexander Stepanov、Meng Lee和David R Musser在惠普实验室工作时所开发出来的。在通过了标准化第一个草案之后,联合标准化委员会投票并通过了将STL包含到C++标准中的提议。STL对C++的扩展超出C++的最初定义范围。虽然在标准中增加STL是个很重要的决定,但也因此延缓了C++标准化的进程。
1997年11月14日,联合标准化委员会通过了该标准的最终草案。1998年,C++的ANSI/IS0标准被投入使用。
2.C++的第一个程序
C++兼容C语言绝大多数的语法,所以C语言实现的hello world依旧可以运行,C++中需要把定义文件代码后缀改为.cpp,vs编译器看到是.cpp就会调用C++编译器编译,linux下要用g++编译,不再是gcc。
// test.cpp
// C
#include<stdio.h>
int main()
{
printf("hello world\n");
return 0;
}
// C++
// 这里的std cout等我们都看不懂,没关系,下面我们会依次讲解
#include<iostream>
using namespace std;
int main()
{
cout << "hello world\n" << endl;
return 0;
}3.命名空间
3.1 namespace的价值
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
c语言项目类似下面程序这样的命名冲突是普遍存在的问题,C++引入namespace就是为了更好的解决这样的问题
如下:
在C语言中编译会报错,但是在C++中就有办法可以解决,就是使用命名空间
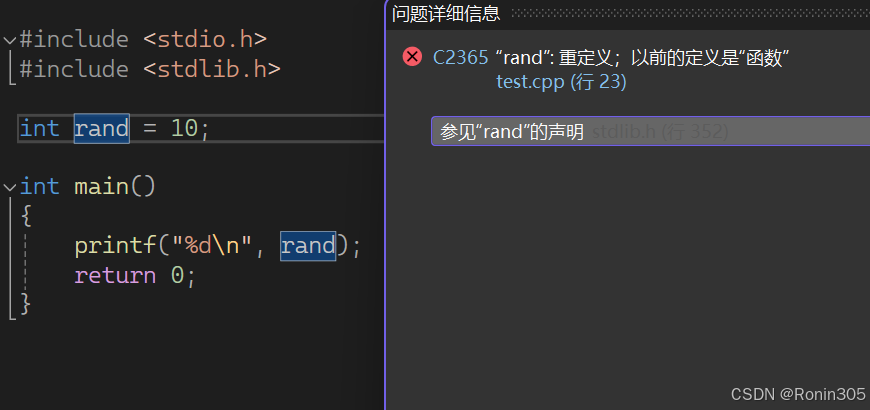
3.2namespace的定义
• 定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。命名空间中可以定义变量/函数/类型等。 • namespace本质是定义出一个域,这个域跟全局域各自独⽴,不同的域可以定义同名变量,所以下面的rand不在冲突了。 • C++中域有函数局部域,全局域,命名空间域,类域;域影响的是编译时语法查找⼀个变量/函数/类型出处(声明或定义)的逻辑,所以有了域隔离,名字冲突就解决了。局部域和全局域除了会影响编译查找逻辑,还会影响变量的生命周期,命名空间域和类域不影响变量生命周期。 • namespace只能定义在全局,当然他还可以嵌套定义。 • 项目工程中多文件中定义的同名namespace会认为是一个namespace,不会冲突。 • C++标准库都放在一个叫std(standard)的命名空间中。
这里family是命名空间的名字,在命名空间中我们可以定义变量、函数、类型,在main方法中,第一个打印访问的是rand函数指针,第二个则是指定family命名空间中的rand变量。这样就可以解决上面的问题。
注意:访问命名空间、类等作用域中的某个成员时,需要使用作用域解析符::
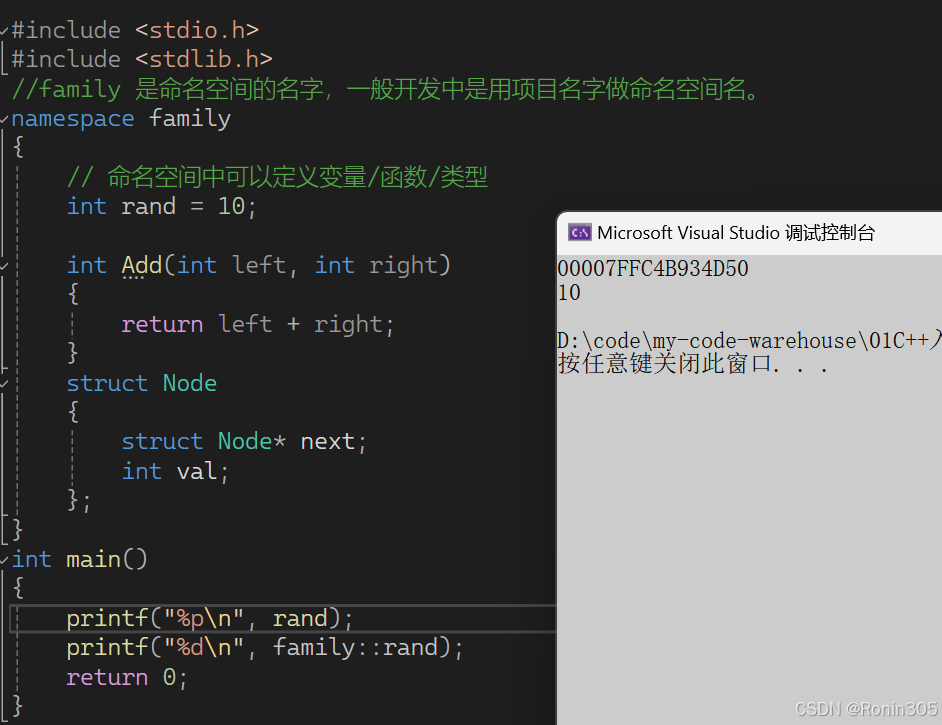
命名空间还可以嵌套定义。
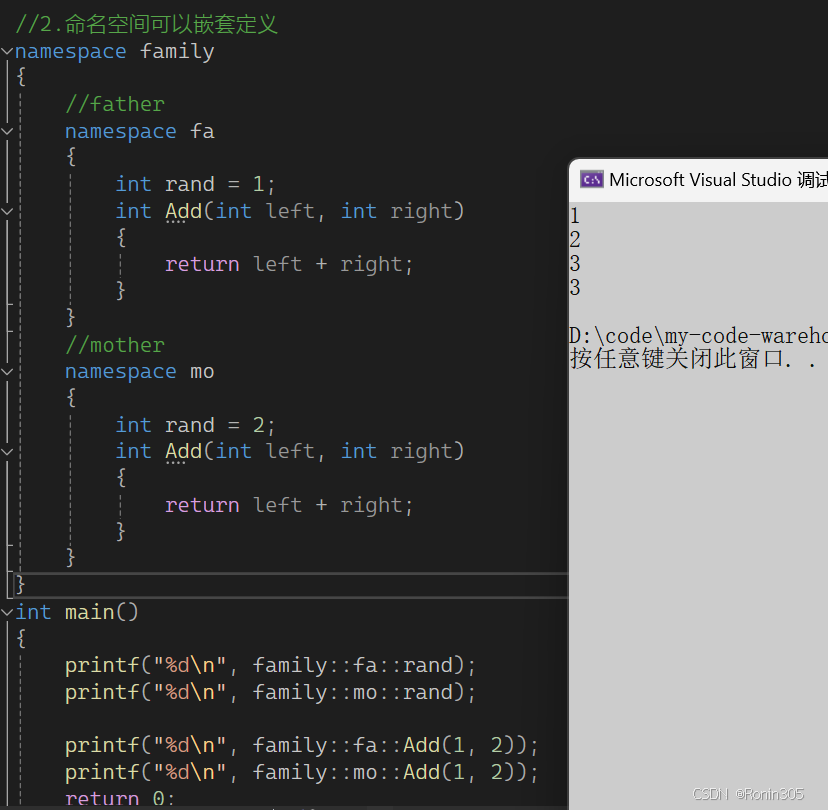
另外,项目工程中多文件中定义的同名namespace会认为是一个namespace,不会冲突。
并且C++标准库都放在一个叫std(standard)的命名空间中。这里就不做代码展示了。
3.3命名空间的使用
编译查找一个变量的声明/定义时,默认只会在局部或者全局查找,不会到命名空间里面去查找。所以下面程序会编译报错。所以我们要使用命名空间中定义的变量/函数,有三种方式:
• 指定命名空间访问,项目中推荐这种方式。 • using将命名空间中某个成员展开,项目中经常访问的不存在冲突的成员推荐这种方式。 • 展开命名空间中全部成员,项目不推荐,冲突风险很大,日常小练习程序为了方便推荐使用。
这里直接访问a,编译器会报错
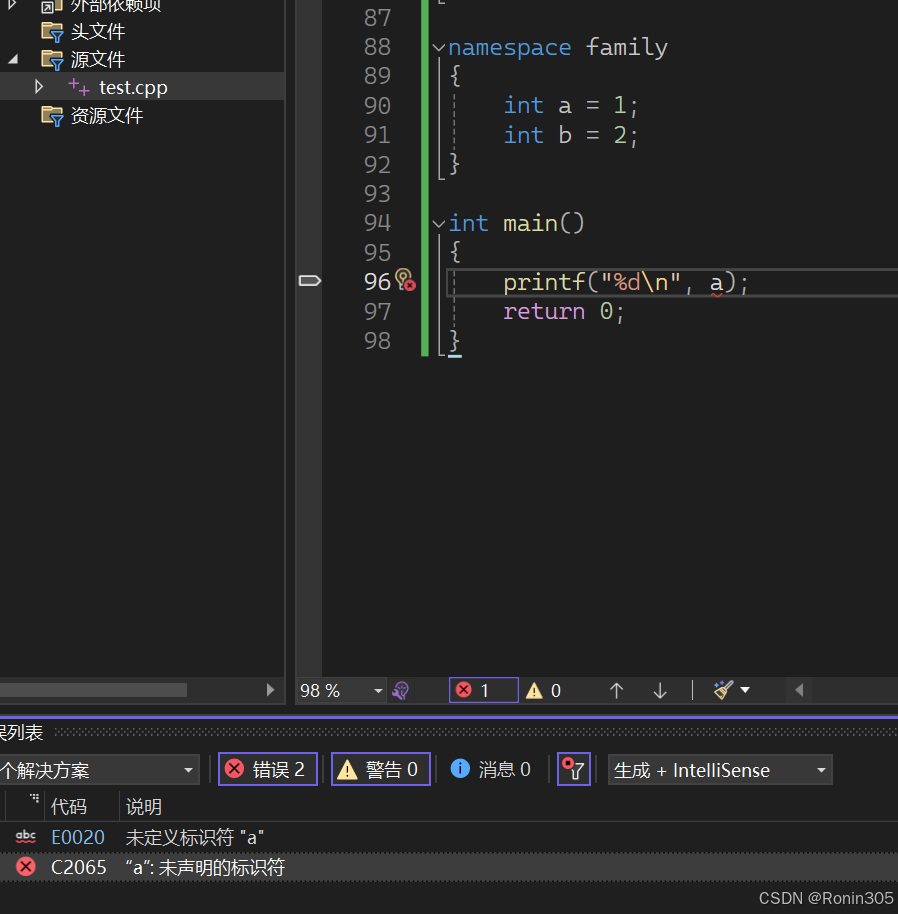
具体使用如下:
namespace family
{
int a = 1;
int b = 2;
}
int main()
{
//编译报错:error,C2065 "a":未声明的标识符
//printf("%d\n", a);
//指定命名空间访问
printf("%d\n", family::a);
return 0;
}
//using展开命名空间中某个成员变量
using family::a;
int main()
{
printf("%d\n", a);
printf("%d\n", family::b);
return 0;
}
//展开命名空间全部成员
using namespace family;
int main()
{
printf("%d\n", a);
printf("%d\n", b);
return 0;
}4.C++输入&输出
• <iostream> 是 Input Output Stream 的缩写,是标准的输入、输出流库,定义了标准的输入、输出对象。 • std::cin 是 istream 类的对象,它主要面向窄字符(narrow characters (of type char))的标准输入流。 • std::cout 是 ostream 类的对象,它主要面向窄字符的标准输出流。 • std::endl 是一 个函数,流插入输出时,相当于插入一个换行字符加刷新缓冲区。 • <<是流插入运算符,>>是流提取运算符。(C语言还用这两个运算符做位运算左移/右移) • 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动指定格式,C++的输入输出可以自动识别变量类型(本质是通过函数重载实现的,这个后面会讲到),其实最重要的是C++的流能更好的支持自定义类型对象的输入输出。 • IO流涉及类和对象,运算符重载、继承等很多面向对象的知识,这些知识我们还没有讲解,所以这里我们只能简单认识一下C++ IO流的用法,后面我们会有专门的一个章节来细节IO流库。 • cout/cin/endl等都属于C++标准库,C++标准库都放在一个叫std(standard)的命名空间中,所以要通过命名空间的使用方式去用他们。 • 一般日常练习中我们可以using namespace std,实际项目开发中不建议using namespace std。 • 这里我们没有包含<stdio.h>,也可以使用printf和scanf,在包含<iostream>间接包含了。vs系列编译器是这样的,其他编译器可能会报错。
这里直接将std命名空间直接展开,不然要使用作用域解析符::访问
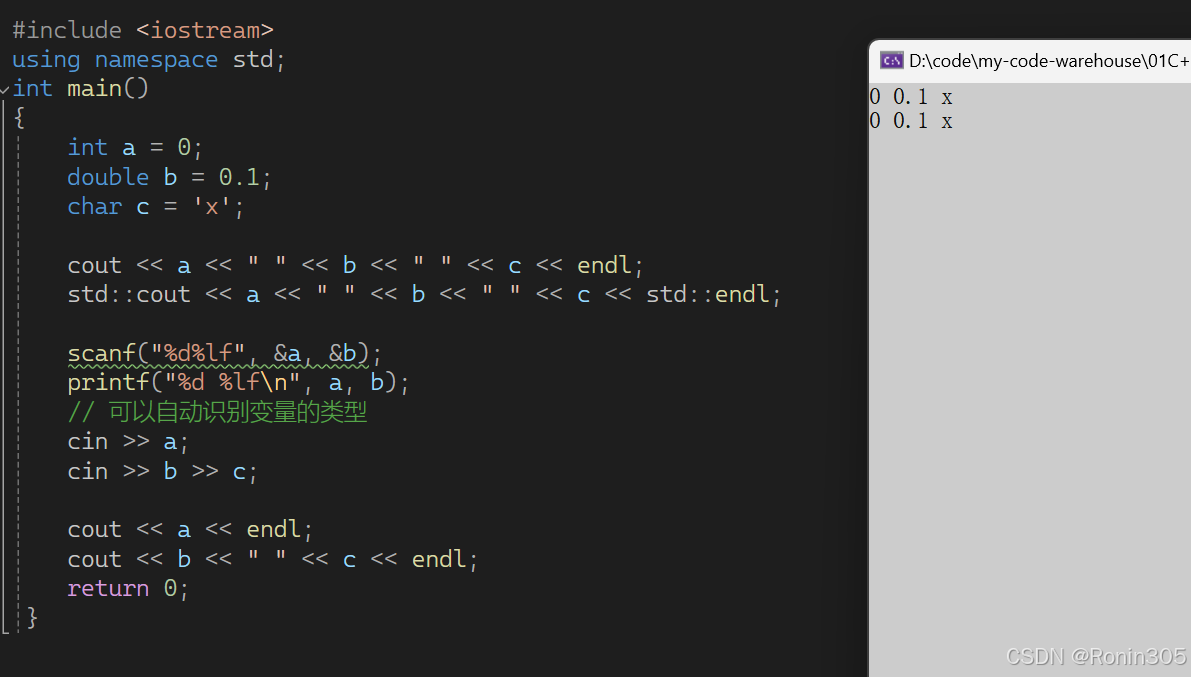
C语言的输入输出在C++中也支持,但C++的输入输出显然更好,可以自动识别变量的类型
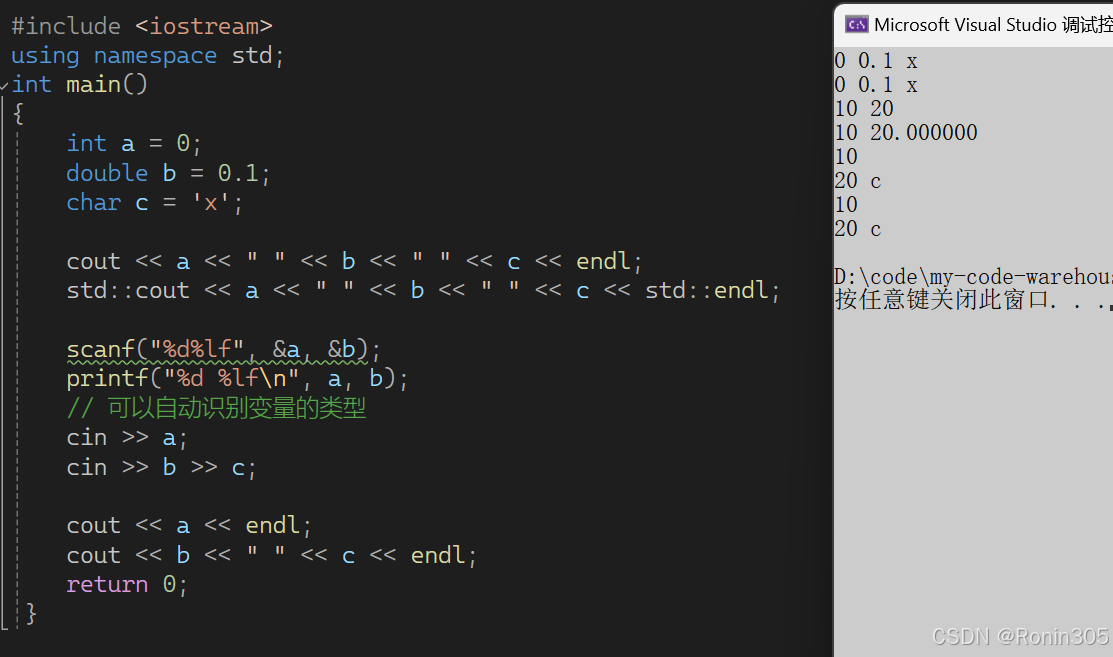
#include <iostream>
using namespace std;
int main()
{
// 在io需求比较高的地方,如部分大量输⼊的竞赛题中,加上以下3行代码
// 可以提高C++IO效率
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
return 0;
}在 C++中,当 I/O 需求较高时,刷新操作有时可以提高 I/O 效率,主要涉及到 C++的输入输出流(iostream)的一些特性。 C++为了兼容 C 语言,保证在代码中同时出现 std::cout / std::cin 和 printf / scanf 等方法时不发生混乱,使用了一个缓冲区来同步 C 的标准 I/O 流。但这种同步可能会带来一些额外的开销。 通过使用 std::ios::sync_with_stdio(false) 可以关闭这种同步,使得 cout 和 cin 不再经过缓冲区,直接进行输出和输入,从而节省部分时间,提高输出操作的效率。 另外, std::cin 默认与 std::cout 绑定,这意味着每次进行输入操作(也就是调用 >> )时,都会刷新(调用 flush )输出缓冲区,增加了 I/O 的负担。使用 std::cin.tie(nullptr) 可以解除 std::cin 和 std::cout 之间的绑定,降低 I/O 的负担,进一步提升输入操作的效率。 需要注意的是,执行 std::ios::sync_with_stdio(false) 后,就不能再混合使用 C 的库函数(如 scanf 、 getchar 、 gets 、 fgets 、 fscanf 等),并且 C++的流操作也不再是线程安全的。同时,使用 tie(nullptr) 解除绑定后,在使用 std::ostream 输出数据后并在使用 std::istream 输入数据前,要注意主动刷新缓冲区的内容,以免出现错误。 除了上述方法外,还可以采用其他方式来优化 C++的 I/O 效率,例如使用缓冲技术、批量操作、合并请求等减少 I/O 操作的次数,或者使用内存映射文件等方式来提高数据传输效率等。具体的优化方法需要根据实际的应用场景和需求来选择
5.缺省参数
• 缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参,缺省参数分为全缺省和半缺省参数。(有些地方把缺省参数也叫默认参数) • 全缺省就是全部形参给缺省值,半缺省就是部分形参给缺省值。C++规定半缺省参数必须从右往左依次连续缺省,不能间隔跳跃给缺省值。 • 带缺省参数的函数调用,C++规定必须从左到右依次给实参,不能跳跃给实参。 • 函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值。
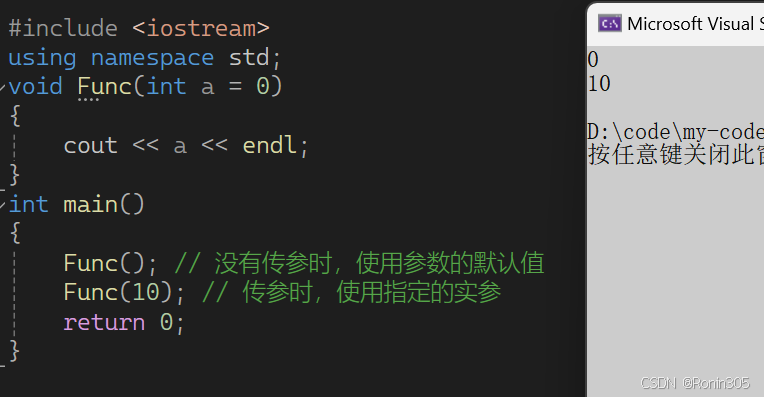
当不传参时,就输出缺省值,传参时,就使用指定的实参
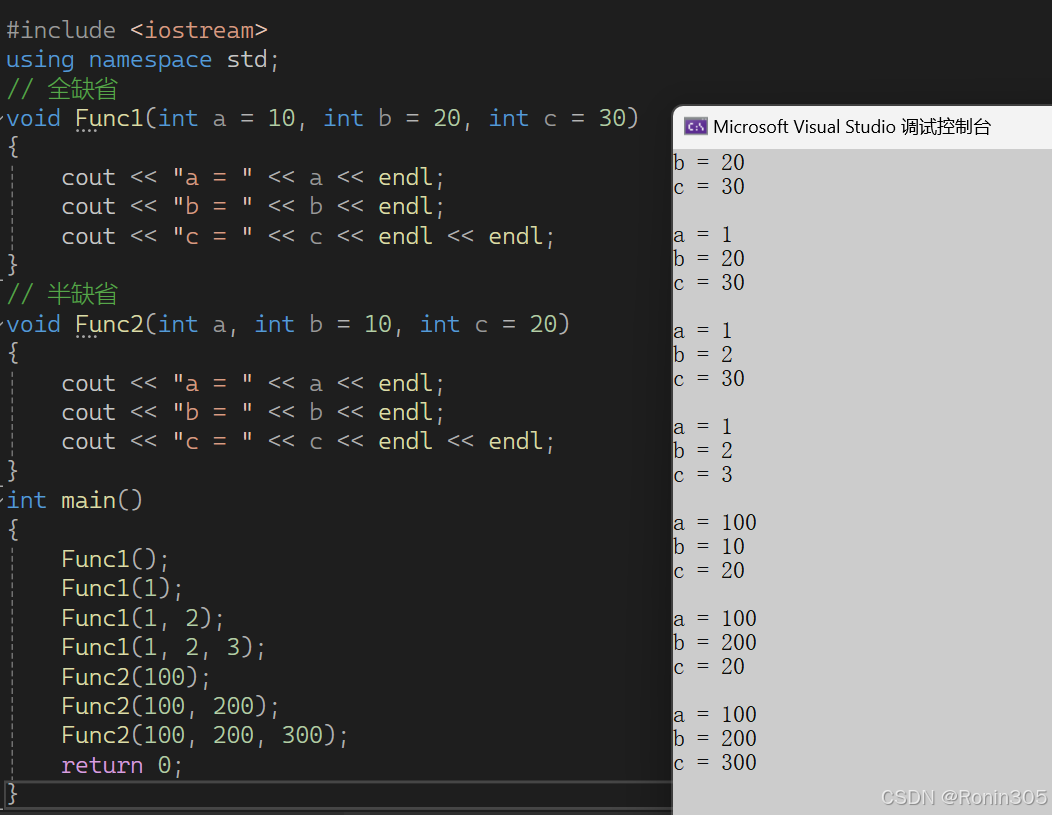
总的来说,缺省参数还是非常好用的,但需要注意用法
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-07-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号