【C++11】异常


1. 异常的概念及使用
1.1 异常的概念
异常处理机制是现代编程语言中处理运行时错误的一种重要方式,其核心思想是将问题的检测与问题的解决分离。这种机制具有以下特点:
- 通信机制:允许程序中独立开发的模块能够在运行时就出现的问题进行有效通信
- 职责分离:检测问题的代码无需知道问题处理的所有细节,只需抛出异常即可
- 信息丰富:相比C语言的错误码机制,异常可以携带更全面的错误信息
与C语言错误处理方式的对比:
- C语言方式:使用返回值或全局变量(errno)表示错误
- 示例:
int ret = fopen("file.txt", "r"); - 需要手动检查返回值并查询错误含义
- 错误处理代码与正常逻辑混杂,可读性差
- 示例:
- C++异常机制:
- 通过抛出异常对象来传递错误
- 异常对象可以包含错误类型、描述、上下文等丰富信息
- 处理代码集中在catch块中,与正常逻辑分离
1.2 异常的抛出和捕获
异常抛出(throw)机制
当程序检测到异常情况时,可以通过throw语句抛出异常:
throw MyException("Error occurred", severity);抛出异常的过程:
- 构造异常对象(可以是内置类型或自定义类型)
- 异常对象被复制(确保即使局部对象被销毁也能传递)
- 控制流立即中断,开始栈展开过程
异常捕获(catch)机制
异常捕获的特点:
匹配规则:按catch子句的顺序查找第一个匹配的类型
- 允许基类捕获派生类异常(多态性)
- 可以使用
catch(...)捕获所有异常
捕获方式:
try {
// 可能抛出异常的代码
}
catch(const std::exception& e) {
// 处理标准异常
}
catch(const MyException& e) {
// 处理自定义异常
}异常处理流程的重要特征:
- 控制权转移:从throw点直接跳转到匹配的catch块
- 对象销毁:栈展开过程中会析构局部对象
- 不可逆性:一旦进入异常处理,无法返回原执行点
1.3 栈展开(Stack Unwinding)
栈展开是异常处理的核心机制,其过程如下:
- 局部查找:
- 检查throw语句是否在try块内
- 如果是,按顺序匹配catch子句
- 匹配成功则进入处理,否则继续
- 函数退出:
- 如果当前函数没有匹配的catch:
- 所有局部对象按构造逆序析构
- 函数立即返回
- 在调用者中继续查找catch
- 如果当前函数没有匹配的catch:
- 终止条件:
- 如果main函数也没有匹配的catch:
- 调用
std::terminate() - 通常会导致程序异常终止
- 调用
- 如果main函数也没有匹配的catch:
示例场景:
void func3() {
throw std::runtime_error("Error"); // 1. 抛出异常
}
void func2() {
std::string s = "temp";
func3(); // 2. 控制转移
// s会被析构
}
void func1() {
try {
func2(); // 3. 继续查找
}
catch(...) {
// 4. 捕获处理
}
}栈展开的注意事项:
- 确保资源管理类(如文件句柄、锁)有正确的析构函数
- 避免在析构函数中抛出异常
- 注意异常安全保证(基本、强、不抛)

我们可以通过下面代码再来了解一下
double Divide(int a, int b)
{
try
{
// 当b == 0时抛出异常
if (b == 0)
{
string s("Divide by zero condition!");
throw s;
}
else
{
return ((double)a / (double)b);
}
}
catch (int errid)
{
cout << errid << endl;
}
return 0;
}
void Func()
{
int len, time;
cin >> len >> time;
try
{
cout << Divide(len, time) << endl;
}
catch (const char* errmsg)
{
cout << errmsg << endl;
}
cout << __FUNCTION__ << ":" << __LINE__ << "行执行" << endl;
}
int main()
{
while (1)
{
try
{
Func();
}
catch (const string& errmsg)
{
cout << errmsg << endl;
}
}
return 0;
}异常处理流程分析
抛出异常 (throw)
在 Divide() 函数中,当 b == 0 时,会构造一个 string 对象并抛出:
string s("Divide by zero condition!");
throw s; // 抛出 string 类型异常捕获异常 (try-catch)
- 异常会沿着调用栈向上传播,寻找匹配的
catch块 - 匹配规则:按顺序检查
catch块的参数类型是否与异常对象类型兼容
具体执行路径(当输入 b=0 时)
Divide() 内部:
if (b == 0) {
string s("Divide by zero condition!");
throw s; // 抛出异常
}- 内部
catch (int errid)不匹配(类型不符),异常继续传播
传播到 Func():
try {
cout << Divide(len, time) << endl; // 异常从这里抛出
}
catch (const char* errmsg) { // 不匹配(const char* vs string)
cout << errmsg << endl;
}-
catch (const char*)无法捕获string类型异常 - 异常继续向上传播
传播到 main():
try {
Func(); // 异常从这里抛出
}
catch (const string& errmsg) { // 匹配成功!
cout << errmsg << endl; // 输出 "Divide by zero condition!"
}最终输出:
Divide by zero condition!关键问题解析
- 类型匹配问题:
-
Divide()抛出string类型 -
Func()尝试捕获const char*→ 类型不匹配 -
main()捕获const string&→ 匹配成功
-
- 代码执行流:
- 异常抛出后,立即跳转到匹配的
catch块 - 在
Func()中:-
cout << Divide(...)不会执行 -
catch (const char*)不匹配 -
cout << __FUNCTION__ ...不会执行(因为异常已传播到上层)
-
- 异常抛出后,立即跳转到匹配的
运行看一下:

从这运行结果可以看出:
throw语句执行后,后续代码将不再执行。程序控制权从throw位置转移到匹配的catch块,该catch块可能位于当前函数或调用链中的其他函数。这意味着:
- 调用链中的函数可能提前退出
- 开始执行异常处理程序时,调用链中创建的对象都将被销毁
我们可以再来尝试一下如果把匹配的catch块对应的 const string& 类型修改成不匹配的,看看main函数仍未找到匹配的catch块的情况下,程序是否会调用标准库的terminate函数终止运行

这么一看如果直到main函数仍未找到匹配的catch块,程序将调用标准库的terminate函数终止运行
1.4 异常匹配处理机制
• 异常匹配机制是C++异常处理的核心部分,其匹配过程遵循严格的类型规则。当异常被抛出时,系统会从当前函数开始,沿着调用栈向上查找匹配的catch块。匹配时会优先考虑精确类型匹配,例如:
try {
throw std::runtime_error("error");
}
catch(const std::runtime_error& e) { // 精确匹配
// 处理代码
}若存在多个catch块都能匹配该异常类型,编译器会选择位置最近的、最具体的那个catch块执行。
• 匹配规则的特殊情况包括以下四种类型转换(这些转换都是隐式进行的):
权限缩小转换:允许从非常量类型向常量类型转换,例如:
try {
throw int(10);
}
catch(const int& e) { // 允许从int到const int的转换
// 处理代码
}数组退化:允许数组类型转换为指向数组元素的指针,例如:
try {
char arr[10];
throw arr;
}
catch(char* e) { // 数组退化为指针
// 处理代码
}函数指针转换:允许函数类型转换为指向函数的指针,例如:
try {
throw someFunction; // 函数名
}
catch(void (*funcPtr)()) { // 转换为函数指针
// 处理代码
}继承体系转换:支持派生类向基类类型的向上转型,这是面向对象异常处理的重要特性:
class Base {};
class Derived : public Base {};
try {
throw Derived();
}
catch(Base& b) { // 派生类到基类的转换
// 处理代码
}• 异常传播机制的一个重要特性是:当异常传递至main函数仍未找到匹配的catch块时,标准库会调用std::terminate()终止程序。在实际工程中,这种粗暴的终止方式可能造成资源泄漏等问题。因此,良好的编程实践建议在main函数末尾添加catch-all块:
int main() {
try {
// 程序主体
}
catch(...) { // 捕获所有未处理的异常
std::cerr << "Unknown exception caught" << std::endl;
// 可以在此进行资源清理
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}需要注意的是,catch(...)虽然能捕获任意异常,但无法获取异常的具体信息。在需要记录或处理异常详细信息的场景中,应该优先使用具体的异常类型捕获。
// 一般大型项目程序才会使用异常,下面我们模拟设计一个服务的几个模块
// 每个模块的继承都是Exception的派生类,每个模块可以添加自己的数据
// 最后捕获时,我们捕获基类就可以
class Exception
{
public:
Exception(const string& errmsg, int id)
:_errmsg(errmsg)
, _id(id)
{}
virtual string what() const
{
return _errmsg;
}
int getid() const
{
return _id;
}
protected:
string _errmsg;
int _id;
};
class SqlException : public Exception
{
public:
SqlException(const string& errmsg, int id, const string& sql)
:Exception(errmsg, id)
, _sql(sql)
{}
virtual string what() const
{
string str = "SqlException:";
str += _errmsg;
str += "->";
str += _sql;
return str;
}
private:
const string _sql;
};
class CacheException : public Exception
{
public:
CacheException(const string& errmsg, int id)
:Exception(errmsg, id)
{}
virtual string what() const
{
string str = "CacheException:";
str += _errmsg;
return str;
}
};
class HttpException : public Exception
{
public:
HttpException(const string& errmsg, int id, const string& type)
:Exception(errmsg, id)
, _type(type)
{}
virtual string what() const
{
string str = "HttpException:";
str += _type;
str += ":";
str += _errmsg;
return str;
}
private:
const string _type;
};
void SQLMgr()
{
if (rand() % 7 == 0)
{
throw SqlException("权限不足", 100, "select * from name = '张三'");
}
else
{
cout << "SQLMgr 调用成功" << endl;
}
}
void CacheMgr()
{
if (rand() % 5 == 0)
{
throw CacheException("权限不足", 100);
}
else if (rand() % 6 == 0)
{
throw CacheException("数据不存在", 101);
}
else
{
cout << "CacheMgr 调用成功" << endl;
}
SQLMgr();
}
void HttpServer()
{
if (rand() % 3 == 0)
{
throw HttpException("请求资源不存在", 100, "get");
}
else if (rand() % 4 == 0)
{
throw HttpException("权限不足", 101, "post");
}
else
{
cout << "HttpServer调用成功" << endl;
}
CacheMgr();
}
int main()
{
srand(time(0));
while (1)
{
this_thread::sleep_for(chrono::seconds(1));
try
{
HttpServer();
}
catch (const Exception& e) // 这里捕获基类,基类对象和派生类对象都可以被捕获
{
cout << e.what() << endl;
}
catch (...)
{
cout << "Unkown Exception" << endl;
}
}
return 0;
}运行结果:

1.5 异常重新抛出
在实际的程序开发中,异常处理通常需要分层进行管理。有时在catch到一个异常对象后,我们需要对不同类型的错误进行分类处理,其中某些特定类型的异常需要在当前层级进行特殊处理,而其他类型的异常则需要继续传递给外层调用链处理。
异常重新抛出机制
当捕获到异常后需要重新抛出时,可以使用简单的throw;语句。这种语法会将当前捕获的异常对象原封不动地抛出,保持原有异常类型和上下文信息不变。
try {
// 可能抛出异常的代码
someOperation();
} catch (const std::exception& e) {
if (isSpecialError(e)) {
// 对特定类型的异常进行特殊处理
handleSpecialError(e);
} else {
// 其他类型的异常重新抛出
throw; // 重新抛出当前捕获的异常
}
}应用场景
- 中间层处理:在多层嵌套的try-catch结构中,中间层可以筛选出自己能处理的异常,将其余异常传递给外层
- 异常分类:根据异常的类型或内容决定不同的处理方式
- 资源清理:在完成必要的资源清理工作后重新抛出异常
注意事项
- 使用
throw;时必须在catch块中,否则会导致程序终止 - 重新抛出的异常会保留原始的异常类型和堆栈信息
- 与
throw e;不同,throw;不会对异常对象进行切片(slice) - 重新抛出的异常可以被更外层的catch块捕获
示例扩展
void intermediateLayer() {
try {
lowLevelOperation();
} catch (const DatabaseException& dbEx) {
// 处理数据库相关异常
logDatabaseError(dbEx);
throw; // 重新抛出给上层处理
} catch (const NetworkException& netEx) {
// 处理网络相关异常
if (isTimeout(netEx)) {
retryOperation();
} else {
throw; // 其他网络异常重新抛出
}
}
}在这个例子中,中间层函数对不同类型的异常进行了分类处理,对于无法处理的异常情况则选择重新抛出,由更上层的调用者来决定如何处理这些异常。
在上一段模拟设计的一个示例前提下,我们再来看下面这段代码
// 下面程序模拟展示了聊天时发送消息,发送失败捕获异常,但是可能在
// 电梯地下室等场景手机信号不好,则需要多次尝试,如果多次尝试都发
// 送不出去,则就需要捕获异常再重新抛出,其次如果不是网络差导致的
// 错误,捕获后也要重新抛出。
void _SendMsg(const string& s)
{
if (rand() % 2 == 0)
{
throw HttpException("网络不稳定,发送失败", 102, "put");
}
else if (rand() % 7 == 0)
{
throw HttpException("你已经不是对象的好友,发送失败", 103, "put");
}
else
{
cout << "发送成功" << endl;
}
}
void SendMsg(const string& s)
{
// 发送消息失败,则再重试3次
for (size_t i = 0; i < 4; i++)
{
try
{
_SendMsg(s);
break;
}
catch (const Exception& e)
{
// 捕获异常,if中是102号错误,网络不稳定,则重新发送
// 捕获异常,else中不是102号错误,则将异常重新抛出
if (e.getid() == 102)
{
// 重试三次以后都失败了,则说明网络太差了,重新抛出异常
if (i == 3)
throw;
cout << "开始第" << i + 1 << "重试" << endl;
}
else
{
// 重新抛出
throw;
}
}
}
}
int main()
{
srand(time(0));
string str;
while (cin >> str)
{
try
{
SendMsg(str);
}
catch (const Exception& e)
{
cout << e.what() << endl << endl;
}
catch (...)
{
cout << "Unkown Exception" << endl;
}
}
return 0;
}运行结果:

流程示意:
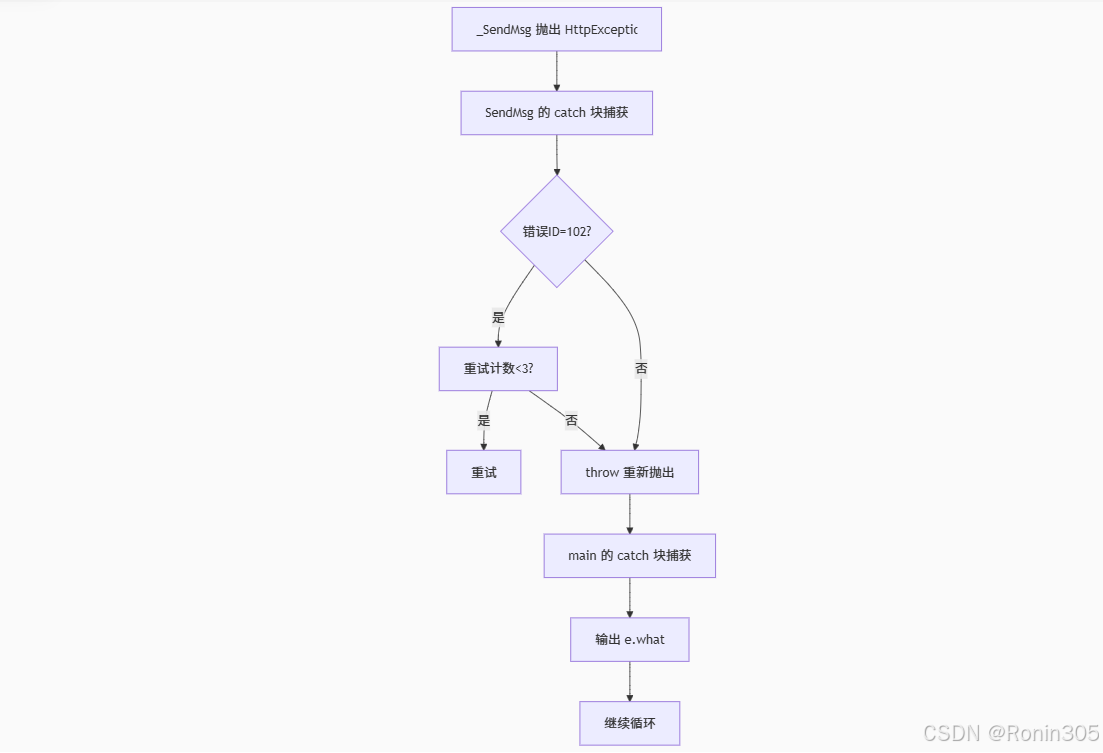
1.6 异常安全问题
• 异常抛出后,程序控制流会立即跳转到最近的异常处理代码块,导致后续代码不再执行。如果在异常发生前已经申请了系统资源(如动态分配的内存、文件句柄、数据库连接、互斥锁等),而资源释放代码位于异常发生点之后,就会造成资源泄漏。例如:
void unsafeFunction() {
char* buffer = new char[1024]; // 申请内存资源
mutex.lock(); // 获取锁资源
// 可能抛出异常的操作
processData(buffer);
mutex.unlock(); // 释放锁
delete[] buffer; // 释放内存
}解决这类问题通常有两种方式:
- 使用try-catch块捕获异常,在catch中释放资源后再重新抛出:
void saferFunction() {
char* buffer = new char[1024];
mutex.lock();
try {
processData(buffer);
} catch (...) {
mutex.unlock();
delete[] buffer;
throw; // 重新抛出
}
mutex.unlock();
delete[] buffer;
}- 更推荐采用RAII(Resource Acquisition Is Initialization)设计模式,通过智能指针(std::unique_ptr等)、锁守卫(std::lock_guard)等资源管理类来自动处理资源释放。
• 在析构函数中处理异常需要格外谨慎。根据C++异常处理机制,如果析构函数在执行过程中抛出异常,且该异常未被捕获,程序将直接调用std::terminate()终止。例如:
class ResourceHolder {
public:
~ResourceHolder() {
releaseResource1(); // 可能抛出异常
releaseResource2();
// ...其他资源释放
}
};更安全的做法是:
- 为每个资源释放操作提供异常保护:
~ResourceHolder() {
try { releaseResource1(); } catch (...) { /*记录日志*/ }
try { releaseResource2(); } catch (...) { /*记录日志*/ }
// ...
}- 或者提供专门的资源清理方法供客户端调用:
void safeCleanup() {
// 显式清理逻辑
}
~ResourceHolder() {
try {
safeCleanup();
} catch (...) {
// 基本保障处理
}
}《Effective C++》条款8特别强调了这个设计原则:析构函数应该吞下所有可能抛出的异常,或者提供其他接口供客户端处理可能发生的异常情况,绝不能让异常逃离析构函数。
1.7 异常规范
• 异常规范在软件开发中具有重要意义。对于开发者而言,预先知道某个函数是否会抛出异常可以帮助编写更健壮的代码;对于编译器而言,异常规范信息可以用于优化代码生成。例如,当调用noexcept函数时,编译器可以省略一些异常处理相关的堆栈展开代码,从而提高性能。
• C++98标准提供了两种异常规范方式:
函数参数列表后接throw():表示该函数承诺不会抛出任何异常。例如:
void func() throw(); // 保证不抛出异常函数参数列表后接throw(类型1,类型2...):表示该函数可能抛出指定类型的异常。例如:
void func() throw(std::runtime_error, std::logic_error); // 可能抛出两种异常• C++11对异常规范进行了重大改进:
用noexcept替代throw():更简洁直观。例如:
void func() noexcept; // 保证不抛出异常省略异常规范:表示函数可能抛出任何类型的异常。例如:
void func(); // 可能抛出异常这种改进使得异常规范更易于使用和理解,在实践中被广泛采用。
• 关于noexcept的编译器行为:
编译器不会在编译时强制检查noexcept承诺,只是将该承诺视为开发者的一种保证。例如:
void func() noexcept {
throw std::runtime_error("error"); // 编译通过,但运行时程序会终止
}当noexcept函数确实抛出异常时,程序会立即调用std::terminate()终止,而不是进行正常的异常处理流程。有些编译器如GCC和Clang可能会给出警告提示。
• noexcept运算符的详细用法:
语法:noexcept(expression)
返回值:
- true:表示表达式不会抛出异常
- false:表示表达式可能抛出异常
示例:
void func1() noexcept;
void func2();
static_assert(noexcept(func1()), "func1 should be noexcept");
static_assert(!noexcept(func2()), "func2 is not noexcept");这种运算符常用于模板元编程中,根据表达式是否会抛出异常来选择不同的实现策略。
double Divide(int a, int b)
{
// 当b == 0时抛出异常
if (b == 0)
{
throw "Division by zero condition!";
}
return (double)a / (double)b;
}
int main()
{
int i = 0;
cout << noexcept(Divide(1, 2)) << endl;
cout << noexcept(Divide(1, 0)) << endl;
cout << noexcept(++i) << endl;
return 0;
}运行结果:

2. 标准库的异常
• C++标准库提供了一套完整的异常处理体系,其核心基类是std::exception。这个异常体系的设计遵循面向对象原则,允许开发者通过继承来扩展自己的异常类型。
• 标准库异常类的官方参考文档: https://legacy.cplusplus.com/reference/exception/exception/
• 关键特性:
- 所有标准库异常都继承自
std::exception基类 - 基类定义了虚函数
what(),用于返回异常描述信息 - 实际使用时应捕获
std::exception及其派生类 - 常见派生类包括:
std::runtime_error(运行时错误)std::logic_error(逻辑错误)std::bad_alloc(内存分配失败)std::out_of_range(越界访问)
• 使用示例:
try {
// 可能抛出异常的代码
throw std::runtime_error("Something went wrong");
}
catch (const std::exception& e) {
// 捕获所有标准库异常
std::cerr << "Error: " << e.what() << std::endl;
}• 最佳实践:
- 在main函数中捕获
std::exception作为最后防线 - 可以通过继承
std::exception创建自定义异常类 - 重写
what()函数时应返回有意义的错误描述 - 对于标准库操作,建议优先使用其提供的异常类型
• 注意事项:
what()返回的是const char*,需注意字符串生命周期- 异常处理会对性能有影响,不应用于常规控制流
- 现代C++推荐使用
noexcept标识不抛出的函数

本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号