Meta AI网络架构再探:NSF如何驾驭双柜NVL72超节点,重构吉瓦级AI底座?

Meta AI网络架构再探:NSF如何驾驭双柜NVL72超节点,重构吉瓦级AI底座?

AGI小咖
发布于 2025-12-22 11:43:59
发布于 2025-12-22 11:43:59
AGI小咖
"作为Meta AI网络架构系列演进篇,本文深度拆解Meta面向吉瓦级集群(如Prometheus)重构的非调度架构(NSF)——基于浅缓存商用以太网(如搭载NVIDIA Spectrum-4 ASIC的Minipack3N)和基于ORv3标准定制的高功率双机柜NVL72超节点(Catalina Pod)深度融合的高性能底座,依托原生支持自适应路由与Spectrum-X端网协同机制重构吉瓦级AI底座。"
PART 01
Meta AI网络架构前瞻回顾
在《Meta AI网络架构前传:RoCEv2在Llama 3万卡集群中的失效与救赎》中,我们分享了Meta在部署24K H100 GPU集群的工程实践中发现传统RoCEv2在AI“低熵、突发、大象流”下的失效难题,尝试了从星型到三层Clos的拓扑变革,从E-ECMP到集中式TE流量工程的路由迭代,以及从DCQCN失效到接收端驱动流控的突破等一系列“填坑”工程实践经验,这些宝贵的“填坑”经验成为下一代网络架构的“原型”和“试验场”,加速定制化DSF与开放式NSF的诞生。
紧接着在《Meta AI网络架构续集:DSF,一台“榨干”以太网物理极限的“F1赛车”,却难做“保时捷911”》中,我们继续分享了Meta工程师基于前人“填坑”经验设计了全新的DSF无损确定性网络,DSF采用前后端物理隔离与双平面冗余设计,创新性地引入以太网域与交换网域的双域解构架构,利用信元喷射技术打破大象流瓶颈;深度联动自研FBOSS控制平面和VOQ+Credit硬件流控结合输入均衡模式,实现了微秒级精度的无阻塞调度与链路故障的分布式自愈,将确定性调度和链路效率推向了物理极限。
尽管DSF性能极致,但对深缓存、高吞吐、低延迟专用交换芯片的强依赖制约了“吉瓦级”超大规模AI数据中心集群扩展,为下一代拥抱通用以太网的NSF(非调度网络)埋下伏笔。
接下来我们继续分享Meta下一代超大规模AI训练网络之NSF(非调度网络),看看其如何站在以太网巨人的肩膀之上再攀性能高峰。
PART 02
NSF架构重构:算网协同的分层设计
NSF以Catalina Pod (GB200 NVL72) 为最小原子构建单元,采用基于浅缓冲 OCP 以太网交换机的三层(Three-tier)分级互联架构,实现算力与网络的深度协同:
- Tier-0 (Scale-Up)机内互联域:以GB200 NVL72 Pod (双机柜) 为物理边界,依托 NVLink 与 NVSwitch 构建无阻塞全互联 Fabric,提供高达130 TB/s的统一内存全互联带宽,实现极致低延迟的内存语义通信
- Tier-1 (Scale-Out)机间互联域:以NSF 网络为核心,负责跨 Pod 的超大规模线性扩展,支持 Meta 吉瓦级自适应路由机制动态实现有效负载均衡和最小化拥塞,保障超大规模集群下的高效互联
2.1 核心组件与物理实现:Catalina Pod
Meta为AI基础设施设计和定制的下一代开放架构平台——Catalina Pod(GB200 NVL72 + ORv3):

图1:Catalina Pod 内部互联拓扑
- 物理形态:基于OCP Open Rack v3(ORv3)高功率版本构建的双机柜高密度集群单元,原生支持全液冷与盲插设计,为了承载NVIDIA GB200,Meta对ORv3 进行了高功率重新设计(相比NVL72 盲插歧管的冷却能力仅有130 kW,ORv3高功率最高支持140kW功率工作负载,机架母线(Busbar)供电容量可达 94 kW)。
- 计算核心:Meta定制的NVIDIA GB200 NVL72 Blackwell平台,实际每个Catalina Pod 实际可以看成2个NVL36配置组合,即标准版 NVL72 与 Meta 定制版的一个区别在于后者由两个IT 机架组成一个72 GPU的 Scale-up 域。双机柜通过一捆粗大的电缆束连接(而非铜缆背板级联),内部集成72个Blackwell GPU与72个 Grace CPU,利用 NVLink Switch 构建了 130 TB/s 带宽的统一内存全互联域,逻辑上的“NVL72超节点”。
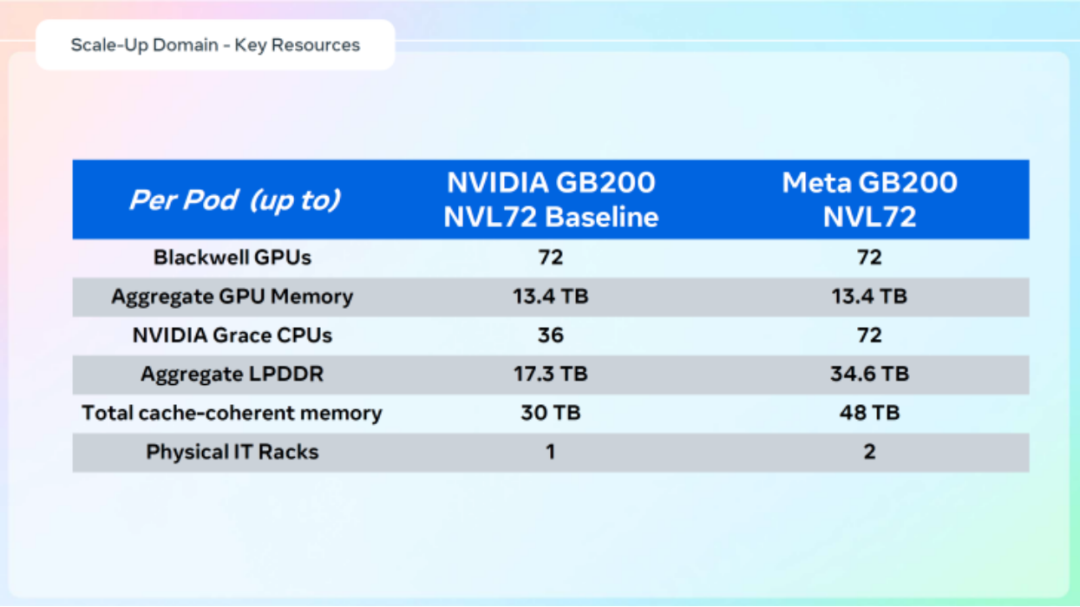
图2:标准版 NVL72 与 Meta 定制版计算单元架构对比
- 网络接口与链路:在极致的空间限制下,Catalina通过双平面解耦设计实现了超高密度的IO吞吐:
- 前端网络:专用于承载存储访问与系统管理流量,每个计算单元通过200G DAC(直连铜缆)上行至机柜顶部的双冗余 Wedge 400前端网络交换机(ToR),以最低成本构建高可靠的带外/带内管理通道,确保运维可靠性与故障隔离。
- 后端网络:专用于NSF 高性能算力互联,基于 NVIDIA ConnectX-8 SuperNIC实现每颗GPU独享2×400G(合计800G)的 RoCEv2 RDMA 带宽,光链路在机柜内部首先汇聚至中央光纤配线架——作为机柜内外布线的物理分界点——随后经由独立光纤通道连接至部署在列末(End of Row, EoR)的NSF 接入交换机,构成 Tier-1 核心网络,支撑跨 Catalina Pod 的超大规模横向扩展。
2.2 网络协同:Spectrum-X体系与开放生态
NSF架构完美践行了Meta在OCP 2025上重申的“开放网络未来”愿景,依托SAI(交换机抽象接口)与自研FBOSS操作系统,NSF构建了一个硬件解耦、多芯片并存的弹性底座高性能以太网底座。
- 开放标准基石(Broadcom Tomahawk 5):采用基于Broadcom Tomahawk 5芯片的Meta自研Minipack3与Cisco 8501 (G200) 共同构成了Meta 51.2T 交换机组合的基础,另外Meta作为UEC(超以太网联盟)标准化的积极推动者,正借助包括Broadcom在内厂商的力量推动拥塞信号(CSIG)与链路层重传(LLR)等AI特性纳入SAI标准规范,从而在保障供应链开放性的同时还能额外获得标准化的高性能。
- AI特性深度集成(NVIDIA Spectrum-4):重点引入基于NVIDIA Spectrum-4 ASIC的Minipack 3N——依靠自身提供51.2T线速吞吐被广泛应用于部署在NSF 集群的各个层级(RTSW/FTSW/STSW),成为激活Spectrum-X 端网协同特性的关键物理锚点。

如图3:Minipack3N高性能51.2 Tbps交换机
- Spectrum-X 端网协同机制试图为大规模AI基础设施重塑以太网性能,通过构建基于RoCEv2的主动拥塞感知与自适应路由闭环体系解决了传统以太网中的性能瓶颈:
- 端侧(Spectrum-X SuperNIC):作为智能边缘,SuperNIC负责超高速流量监测将数据分布到所有交换机端口来解决ECMP 负载不均的问题,支持忽略数据包乱序和进行接收端重组,进而最大限度地提高Fabric利用率
- 网侧(Spectrum-X Switch):基于硬件级自适应路由(Adaptive Routing)遥测(例如带内遥测In-band Telemetry)实时感知网络状态,将细颗粒度的流量动态调度至当前负载最轻的路径,实现分布式全网拥塞响应和预测性能
- 控制平面的范式重构:Meta通过FBOSS屏蔽了底层芯片差异,无论是Broadcom的UEC标准实现,还是NVIDIA的Spectrum-X私有优化,均通过SAI接口被上层控制面统一调度,这种基于NSF架构的无状态(Stateless)、浅缓存(Shallow Buffer)的设计,将流量调度的智能从中心控制器下沉到了分布式交换机硬件中,实现了真正的超大规模线性扩展。
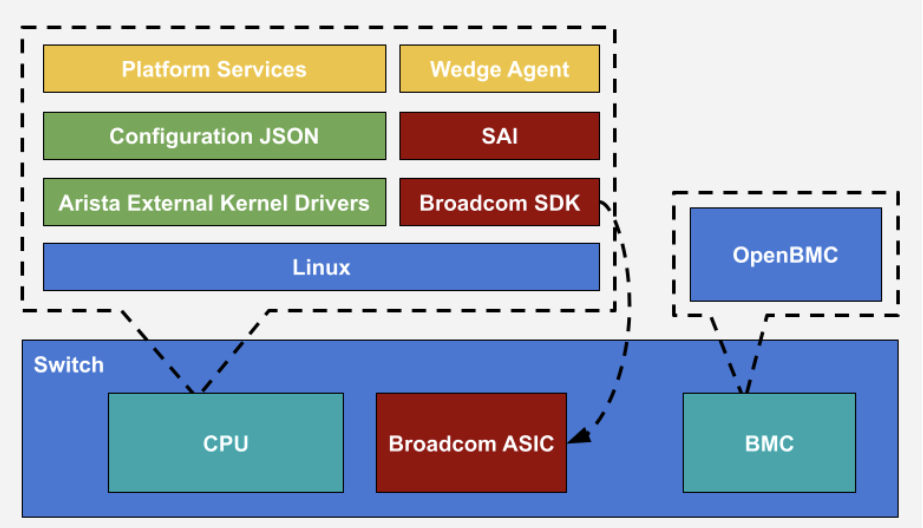
图4:基于SAI与 FBOSS的软硬件解耦架构
PART 03
NSF架构详解:全线速无阻塞Clos架构
NSF采用标准的三级Clos架构(Tier-3 Clos),构建了全网1:1严格无阻塞的确定性交换矩阵:
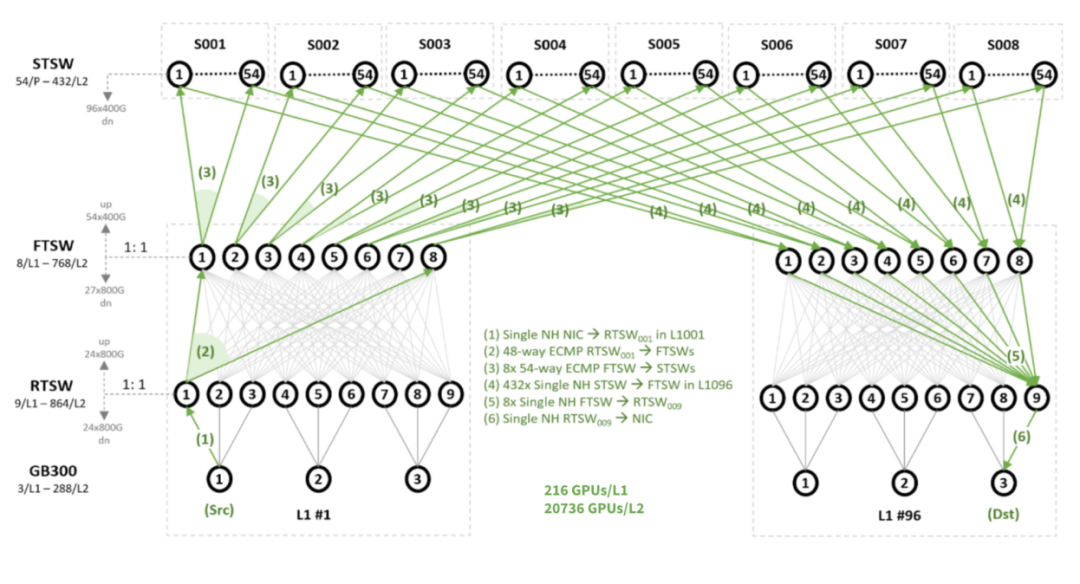
如图5:NSF三级Clos网络拓扑
3.1 L1 Pod(基本单元):高密度原子接入层
L1 Pod 是构建万卡乃至百万卡集群的最小物理单元,由3套 Catalina 超节点(即3套双机柜系统)与 9台 Leaf交换机耦合而成,单Pod算力密度达 216 GPU。
RTSW (Rack Top Switch / Leaf):采用 Minipack3N (Spectrum-4) 作为接入锚点。
- 下行接入:24 x 800G,每台RTSW负责接入Pod内的24个GPU,物理上通过 2x400G 实现链路聚合(LACP),逻辑上提供 800G 独占带宽,完美匹配 PCIe Gen6/7 的极致吞吐需求。
- 上行汇聚:48 x 400G,每台RTSW向本Pod内的8台FTSW扇出,每台 FTSW分配6条400G链路,利用高并发ECMP实现极致的负载分担。
- 收敛比:1:1(下行19.2T :上行19.2T),确保接入侧无带宽收敛瓶颈。
3.2 L2 Cluster:模块化Fabric
L2 层作为 Pod 间的互联枢纽,由96个L1 Pods 横向级联而成,将集群规模扩展至 20,736 GPUs。
FTSW(Fabric Top Switch / Spine):每个Pod内部署 8台 FTSW,全集群共768台,Fabric互联矩阵如下:
- 下行:54 x 400G,连接本Pod内的全部9台 RTSW(9 x 6 x 400G);
- 上行:54 x 400G,每台FTSW向核心层的54台STSW进行全互联扇出;
- 收敛比:1:1,上下行带宽完全对等,确保东西向流量在L2层透传无损。
3.3 L3 Backbone:8平面正交骨干网
为了解决超大规模网络的哈希冲突与布线复杂度,L3 骨干网采用了正交平面设计理念。
STSW (Super Spine Switch / Core):全网物理上划分为 8个独立的Spine平面,与 L1/L2 层的“8台 FTSW”一一对应,每个平面包含54台STSW,全集群共432台核心交换机。
全网覆盖:单台STSW 下行提供 96 x 400G 端口,一条链路直达一个L1 Pod,意味着任意一个Spine平面即可覆盖全网96个Pod(20,736 GPUs),实现了跨 Data Hall 级别的无阻塞高可靠互联。
PART 04
展望未来:ESUN与全以太网宏图
NSF解决了Scale-Out(横向扩展)的标准化问题,但Meta的野心不止于此在OCP 2025峰会上,Meta加入了 ESUN (Ethernet for Scale-Up Networking) 倡议,旨在攻克最后一块堡垒——用开放以太网彻底替代机柜内部的私有Scale-Up协议(如NVLink)。
面对目前由私有协议垄断的Scale-Up领域,Meta联合AMD、Broadcom、Microsoft等巨头,依托OCP与UEC(超以太网联盟)推动ESUN标准的落地,其核心在于定义一套支持内存语义(Memory Semantics)的开放以太网规范(详见前文《博通一统以太网江湖阳谋:SUE一超多强(字节Ethlink、NVLink与UALink)?》):通过优化帧报头(Efficient Headers)降低协议开销,并引入硬件级链路层重传(LLR)与拥塞信号(CSIG),在物理层之上构建满足极低延迟、超高带宽需求的无损(Lossless)传输平面,以满足极低延迟、超高带宽的内存访问需求。
在吉瓦级集群俱乐部中,Meta的NSF全面拥抱通用以太网和ESUN组合不同,Google Ironwood Superpod采用加速器芯片、互连拓扑、光交换结构、软件堆栈和部署模式之间高度协同垂直整合封闭生态护城河,依托基于OCS大规模光学电路交换的光学交换层底座、"3D+1D" Torus 拓扑组网实现了自研加速芯片如最新一代Ironwood (TPU v5p) 的规模化部署和极致发挥内部工作负载的物理性能。
从RoCEv2的工程磨合到DSF的极致工匠精神(F1赛车),再到NSF的开放工业化(保时捷911),Meta的网络演进史正是一部AI基础设施从“专用黑盒”走向“开放标准”的工业化缩影。随着NSF的落地与ESUN的推进,一个开放、高性能、吉瓦级的全以太网新纪元正在开启。
往
期
回
顾
三大超节点:昇腾384 VS 阿里磐久AL128 VS NVIDIA GB200 NVL72,网工视角,谁主沉浮?
博通一统以太网江湖阳谋:SUE一超多强(字节Ethlink、NVLink与UALink)? 媲美英伟达下一代GPU Scale-up:字节版NVLink重塑MegaScale万卡
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号