C++类与对象(4)

C++类与对象(4)

君辣堡
发布于 2025-12-20 09:08:20
发布于 2025-12-20 09:08:20
这一篇我将对C++类与对象进行收尾
1.友元
友元提供了⼀种突破类访问限定符封装的⽅式,友元分为:友元函数和友元类,在函数声明或者类
声明的前⾯加friend,并且把友元声明放到⼀个类的⾥⾯。
外部友元函数可访问类的私有和保护成员,友元函数仅仅是⼀种声明,他不是类的成员函数。
友元函数可以在类定义的任何地⽅声明,不受类访问限定符限制,在public,private,protected内声明,从语法层面和权限层面上看,没有区别。
⼀个函数可以是多个类的友元函数,只需要在他们类中声明友元函数
友元类中的成员函数都可以是另⼀个类的友元函数,都可以访问另⼀个类中的私有和保护成员。
友元类的关系是单向的,不具有交换性,⽐如A类是B类的友元,但是B类不是A类的友元。
友元类关系不能传递,如果A是B的友元, B是C的友元,但是A不是C的友元。
友元为代码提供了便利性。但是友元会增加耦合度(代码块之间的联系加深,若修改一处代码可能会牵扯到其他处,导致维护代码成本变高),破坏了封装,所以友元不宜多⽤。
class A
{
// 友元声明
friend void func(const A& aa, const B& bb);
private:
int _a1 = 1;
int _a2 = 2;
};如图,这就是类外的func函数在A类中声明友元函数。 这样就func函数就可以通过接收A类对象来访问类私有成员了。(aa._a1)(若没声明友元,只能通过此访问公有成员,访问私有会报错)
class A
{
friend class B; // 友元声明
private:
int _a1 = 1;
int _a2 = 2;
};
class B
{
public:
void func1(const A& aa)
{
cout << aa._a1 << endl;
cout << _b1 << endl;
}
void func2(const A& aa)
{
cout << aa._a2 << endl;
cout << _b2 << endl;
}如图是B类在A类中声明友元函数,这样在B类中的函数就可以通过A类对象访问A类的私有成员,这原理和上面一样。
2.内部类
如果⼀个类定义在另⼀个类的内部,这个内部类就叫做内部类。内部类是⼀个独⽴的类,跟定义在
全局相⽐,他只是受外部类类域限制和访问限定符限制,所以外部类定义的对象中不包含内部类。
内部类默认是外部类的友元类。内部类可以访问外部类的私有成员,而外部类不能访问内部类的私有成员。要想访问只能通过内部类的公共接口(比如Get_count函数,获取私有成员数据返回)
内部类本质也是⼀种封装,当A类跟B类紧密关联,A类实现出来主要就是给B类使⽤,那么可以考
虑把A类设计为B的内部类,如果放到private/protected位置,那么A类就是B类的专属内部类,其
他地⽅都⽤不了
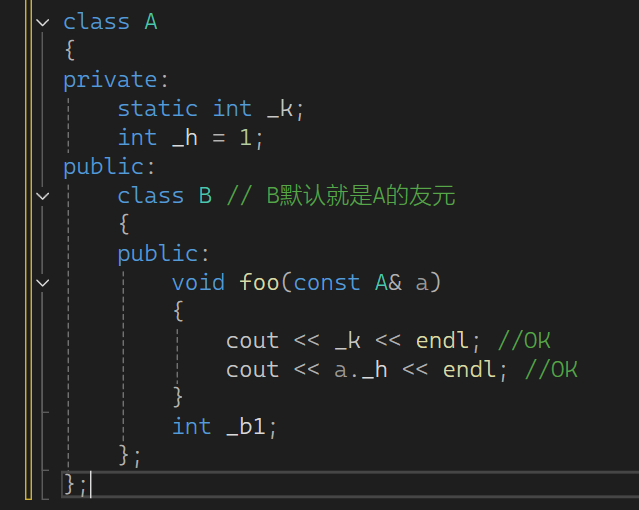
如图。这就是内部类的写法,直接套娃,类 嵌套 类
上一篇我们讲了1+2+...+n 的题,其中Sum类 就是专门为 Solution类 设计的,所以可以这样改:
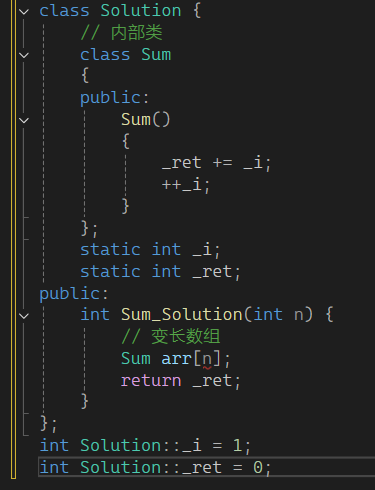
直接把Sum改为Solution的内部类。 这种写法更加精炼,值得我们学习。
2.匿名对象
用 类型(实参) 定义出来的对象叫做匿名对象,相⽐之前我们定义的 类型 对象名(实参) 定义出来的
叫有名对象 (假设有A类,前者就是A(1),后者则是a1(1))
匿名对象生命周期只在当前一行,⼀般临时定义⼀个对象当前用⼀下即可,就可以定义匿名对象。(意思就是这一行用完,后面不用管,那可以直接定义一个匿名对象,省得新构造一个。)
Solution().Sum_Solution(10);匿名对象在这种场景就很好用,只是用来调用函数的,并且下一行他就自动调用析构函数销毁了。
注意匿名对象是没有对象名的,要么定义有名 A a1,要么定义匿名 A(),四不像的:A a1()就会被编译器认为这是在声明函数,而非定义,从而导致报错。
3.对象拷贝时的编译器优化
现代编译器会为了尽可能提高程序的效率,在不影响正确性的情况下会尽可能减少一些传参和传返
回值的过程中可以省略的拷贝。(如前面讲的 隐式类型转换,省略了构造临时对象和拷贝构造,直接优化为构造 )
如何优化C++标准并没有严格规定,各个编译器会根据情况自行处理。当前主流的相对新一点的编
译器对于连续⼀个表达式步骤中的连续拷贝会进行合并优化,有些更新更"激进"的编译器还会进行
跨行跨表达式的合并优化
linux下可以将下面代码拷贝到test.cpp文件,编译时用 g++ test.cpp-fno-elide-constructors 的方式关闭构造相关的优化

说明: 图中 f1( A(1) ) 是用匿名对象A (1)作为函数参数
看这块代码,前面我们讲过,更先进的编译器会将构造+拷贝构造 优化为直接构造,这就是编译器优化,我们来看看运行优化后结果如何,并对比未优化的:
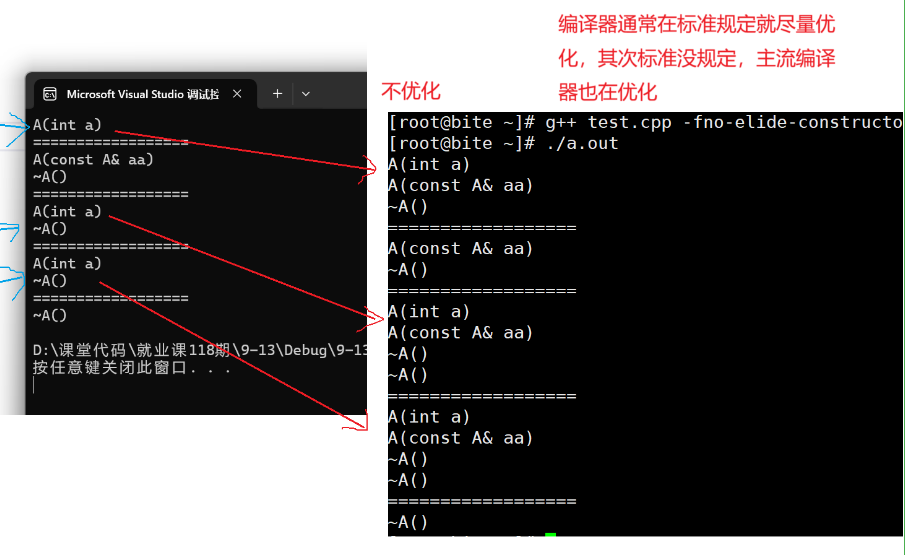
如图,第一个优化为了直接构造,而右边不优化就有拷贝构造一个临时对象,并且析构临时对象的操作。下面几个的也同理。
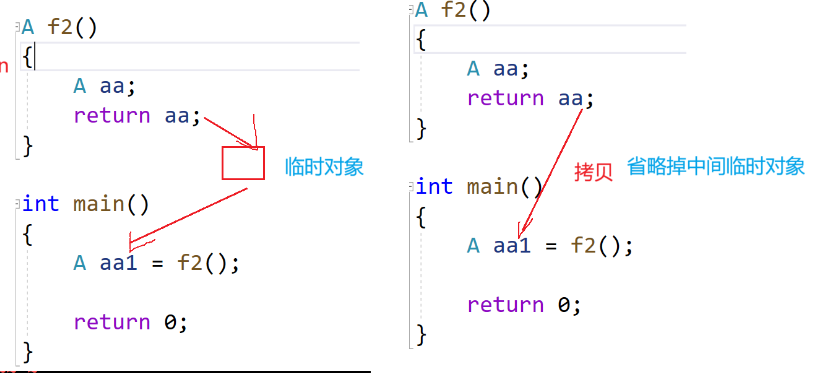
这是上面说的更为激进的编译器的优化:跨行跨表达式的合并优化
左图中,正常情况return 的 aa 是不能直接作为A aa1 的接收值,因为aa的生命周期在f2内,出了f2就会销毁,所以是会拷贝构造一个aa的临时对象 作为返回值,同时aa销毁,然后这个临时对象再拷贝构造给aa1 ,然后临时对象销毁。
顺序是:生成临时对象->aa销毁 ->临时对象拷贝构造给aa1,->临时对象销毁
但是更激进的编译器也会直接优化为右图那样:aa直接 拷贝构造 给aa1 ,省略了多余的拷贝构造和析构。
同样,我们对比一下优化前后

说明:图中的 NRVO 是 命名返回值优化 (C++标准并未说明NRVO可优化,只是编译器的优化)
左图是未优化的时候,f2内构造了一个A类,然后拷贝构造了临时对象,A类销毁,临时对象拷贝给了aa1,临时对象销毁,最后aa1销毁。
优化后是省略了临时对象的销毁和拷贝构造。 (VS2019的debug版本已经是右图的优化了)
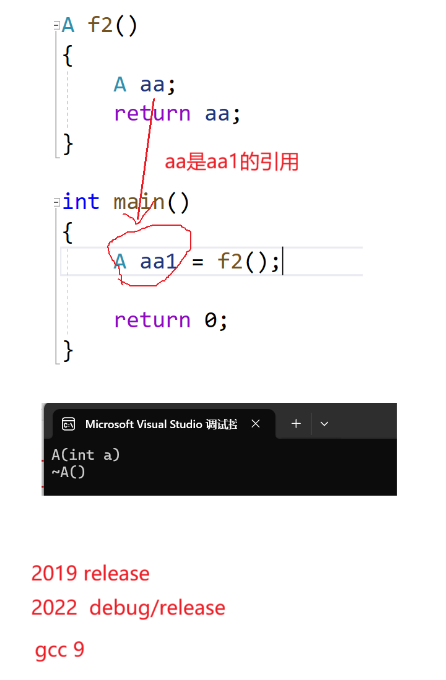
如图,VS2019的release版本,2022的debug和release,gcc9 这些编译器已经更为激进:
直接将aa定义为aa1的引用。 因为aa的一系列动作都会改变到aa1里,所以编译器进行了极致的语法分析后,尝试直接将 aa 变为 aa1 的别名/引用。
图中的构造和析构,都是main函数的aa1。 aa是aa1的引用,他们地址相同。
前面是说的是NRVO 现在 讲一下URVO (U就是unname,未命名的,匿名返回值优化)
他原理和NRVO类似,展示代码:

f2内函数简化为直接返回匿名对象,这个效果和上面的NRVO一样,右下图为未优化的场景,和上面的例子一样,右上图为优化后的场景,也与上面的例子一样。
只是针对的不一样,一个是针对有名返回对象,一个是匿名返回对象
不建议以下写法:

这样会打乱优化,因为aa1 = f2()已经是赋值了,不是拷贝构造。
原来是A aa1 = f2()是拷贝构造,临时对象也是拷贝构造给aa1,因此可以合并为直接构造。但现在aa1已经存在,拷贝构造不能为已存在对象构造,这是赋值运算符重载的赋值操作符, 所有将无法合并优化。因此不建议这么写。
虽然会打乱优化,但是编译器还是会尝试进行优化:
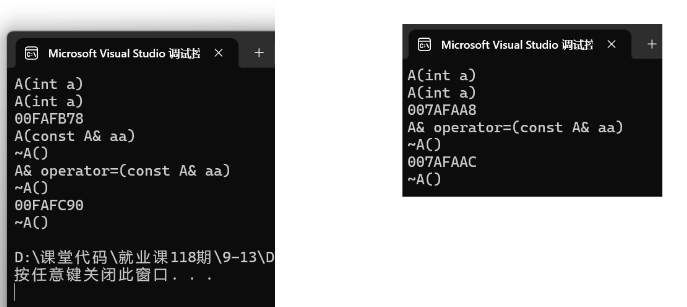
左图是优化前,右图是优化后: 优化了aa的临时对象,直接将aa 赋值 给 aa1 。
即便是优化后,赋值运算还是无法优化的。 所以尽量避免此写法
C++类与对象结束,接下将会将内存管理,谢谢大家,请多多点赞支持!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号