OpenAI开源新模型展示大语言模型的可解释性

OpenAI开源新模型展示大语言模型的可解释性

AgenticAI
发布于 2025-12-18 21:02:42
发布于 2025-12-18 21:02:42
OpenAI今日放出一个新模型 circuit-sparsity,大小只有0.4B参数,类似GPT-2架构的语言模型,主要用于理解模型,即模型的可解释性。

通过训练“先稀疏后解释”的模型,我们能一步步让 AI 内部机制更透明、更可理解。
现在的 AI 模型太复杂了。它们像一个超级巨大的迷宫,有上亿甚至上千亿条连接,每个连接都有不同的“权重”,组成一个完全缠在一起的系统。我们训练模型时让它自己调整这些连接去完成任务,但我们看不懂里面到底发生了什么。
理解模型不只是“好奇心”,而是为了:预测模型什么时候会出错、让模型行为更安全、检测模型是否会做不对的事(比如作弊、偏见决策)和更好地控制 AI 的输出。
这些都需要知道模型内部是怎么一步一步得出答案的。所以OpenAI的研究人员试了一种新方法:把模型里大部分连接设为零,只用少数关键连接来让模型完成任务,这样就能把模型内部拆成一小块一小块的“电路”,便于理解和解释。想象把一个乱七八糟的机械钟拆掉大部分齿轮,只剩下做好一个功能所需的关键齿轮——这就更容易看懂它怎么动。
具体的就是:他们训练了一种类似 GPT-2 架构的语言模型,但强制 绝大多数连接(权重)为零,只留少量可用连接。这样模型内部就不像蜘蛛网,而像很简单的电路。
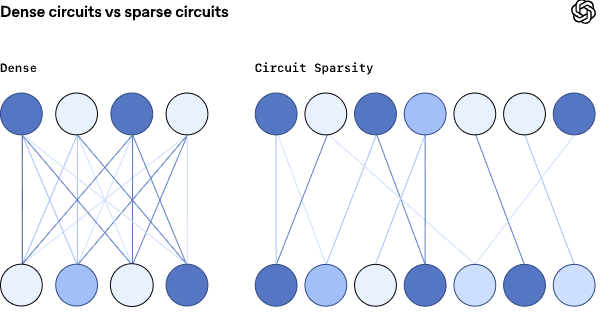
这样做的结果是:这个“稀疏模型”仍然能完成任务、但内部机制更容易拆解、可以真正找出哪些连接负责哪个功能(他们称之为“小电路”或circuits)。
为了更具体地说明这一点,考虑这样一个任务:一个用 Python 代码训练的模型需要用正确的引号类型补全一个字符串。在 Python 中,“hello”必须以单引号结尾,“hello”必须以双引号结尾。模型可以通过记住字符串开头使用的引号类型,并在结尾处自动补全来解决这个问题。
我们最易于解释的模型似乎包含可解耦的电路,这些电路正是实现了该算法。
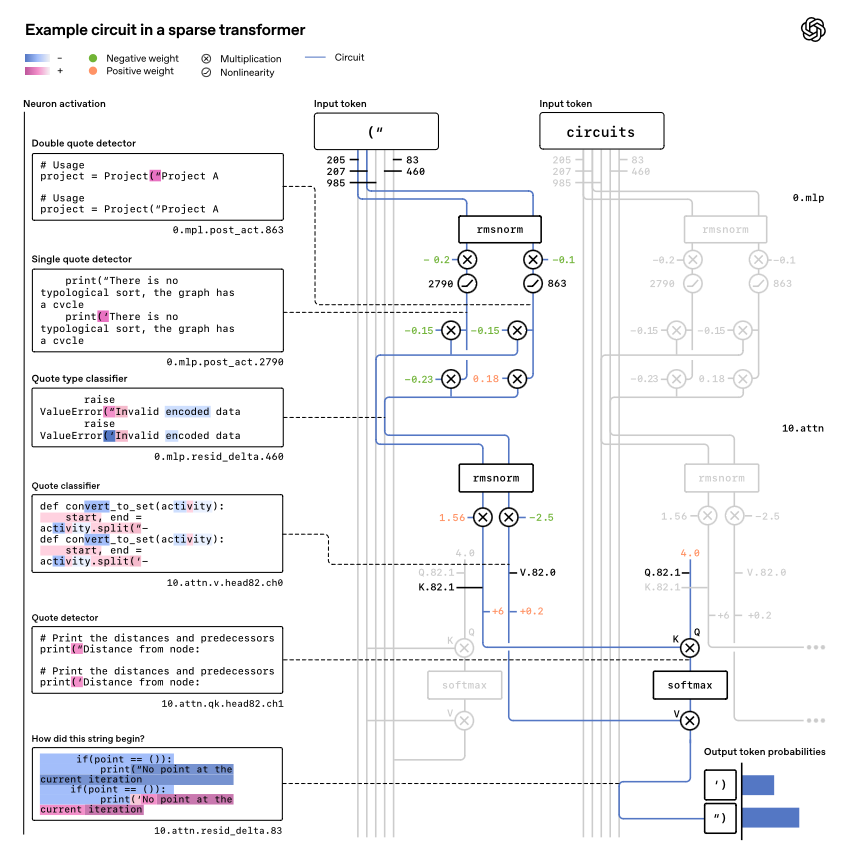
他们也研究了一些更复杂的行为。这些行为的电路(例如下图所示的变量绑定)更难完全解释。即便如此,仍然可以得出相对简单的部分解释,这些解释能够预测模型的行为。

最后
- 论文:
https://arxiv.org/abs/2511.13653 - Gihub Repo:
https://github.com/openai/circuit_sparsity - 模型地址:
https://huggingface.co/openai/circuit-sparsity
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号