【落羽的落羽 C语言篇】一些常见的字符函数、字符串函数、内存函数

【落羽的落羽 C语言篇】一些常见的字符函数、字符串函数、内存函数

落羽的落羽
发布于 2025-12-18 18:33:48
发布于 2025-12-18 18:33:48

在这里插入图片描述
一、字符函数
1. 字符分类函数
C语言中有一些库函数是专门用来分类字符的,这些函数的使用都需要包含头文件ctype.h:
函数 | 检测类型 |
|---|---|
iscntrl | 任何控制字符 |
isspace | 空白字符:包括空格’ ‘,回车’\r’,换行’\n’等 |
isdigit | 十进制数字:0到9 |
isxdigit | 十六进制数字:0到9,a到f,A到F |
islower | 小写字母:a到z |
isupper | 大写字母:A到Z |
isalpha | 字母:a到z,A到Z |
isalnum | 字符或数字:a到z,A到Z,0到9 |
ispunct | 标点符号:不属于字符和数字的可打印图形字符 |
isgraph | 所有图形字符 |
isprint | 所有可打印字符,包括图形字符和空白字符 |
注意:这些函数的传参实际上都是字符的ASCII值,参数是int类型 这些函数的使用方法几乎相同,我们就以isdigit为例讲解,它的定义是:
int isdigit(int c)在使用时,如果isdigit的参数是一个十进制数,那么函数的返回值就是非0的整数;如果不是十进制数,返回值就是0。 上面其他的函数都是这个道理,如果参数是是它们对应的检测类型,函数的返回值是非0的整数(真),反之则是0(假)。
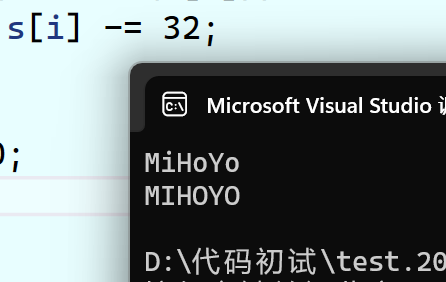
举个栗子吧,利用函数islower,将一个字符串中的小写字母转换成大写字母:
#include<stdio.h>
#include<ctype.h>
int main()
{
char s[10] = {'\0'};
gets(s);
for(int i=0 ; s[i]!='\0' ; i++)
{
if(islower(s[i]))
s[i]-=32;
}
puts(s);
return 0;
}
在这里插入图片描述
非常好理解!
2. 字符转换函数
在ctype.h头文件中,还有两个函数tolower、toupper,用于转换字符。 函数tolower能把参数的大写字母转换成小写字母并返回,函数toupper能把参数的小写字母转换成大写字母并返回。(它们的参数和返回值都是ASCII的形式,也就是int类型) 如果toupper的参数不是小写字母,tolower的参数不是大写字母,那么返回值还是原来的字符(的ASCII值)
还是上面的例子,将一个字符串中的小写字母转换成大写字母。刚才我们先用islower判断小写字母再减32。但这时,我们就可以直接用toupper达到这个效果:
#include<stdio.h>
#include<ctype.h>
int main()
{
char s[10] = {'\0'};
gets(s);
for(int i=0 ; s[i]!='\0' ; i++)
s[i] = toupper(s[i]);
puts(s);
return 0;
}结果也是正确的

在这里插入图片描述
二、字符串函数
我们在编程或做题时经常与字符串打交道,因此掌握一些字符串相关的库函数是必不可少的。以下这些函数,都包含在头文件string.h中。对于一些重要的函数,很多企业在笔试时都会考察它们的模拟实现(关于模拟实现是什么,请见《指针·之其五》),所以我们也应该掌握。
1. strlen的使用和模拟实现
使用

在这里插入图片描述
strlen的返回值是字符串str的长度(字符个数),它从指针str开始计数,以\0为字符串的结束标志。注意:strlen的返回类型size_t是无符号的,如果有表达式strlen(s1) - strlen(s2),不论s1和s2谁长谁短,结果都是无符号数(非负数)
模拟实现
- 思路1:最简单的遍历计数
int Mine_strlen(const char* str)
{
int count=0;
assert(str);//防止str是空指针
while(*str!='\0')
{
count++;
str++;
}
return count;
}- 思路2:利用递归的思想计数
int Mine_strlen(const char* str)
{
assert(str);
if(*str=='\0')
return 0;
else
return 1+Mine_strlen(str+1);
}- 思路3:利用“指针 - 指针 = 两者间元素个数”的原理计数
int Mine_strlen(const char* str)
{
assert(str);
char* str1 = str;
while(*str1!='\0')
str1++;
return str1-str;
}2. strcpy的使用和模拟实现
使用

在这里插入图片描述
strcpy的功能是“拷贝字符串”,它能将source指向的字符串(包括其结尾的\0)拷贝到destination指向的内容。也就是说,这个函数修改的是destination指向的字符串的内容。它的使用要点是源字符串必须以\0结尾,目标空间必须可修改,而且要有足够大以确保能容纳的下源字符串。 举个栗子:
#include<stdio.h>
#include<string.h>
int main()
{
char s1[] = "xxxxxxx";
char s2[] = "abc";
strcpy(s1,s2);
printf("%s\n",s1);//这两句也可以直接写成printf("%s\n",strcpy(s1,s2));(链式访问)
return 0;
}s2中的“a”、“b”、“c”、“\0”都会被拷贝到s1中,替换掉s1的前四个字符,s1的内容变成了“abc\0xxx\0”,而s2的内容是不变的。%s打印s1,结果是abc
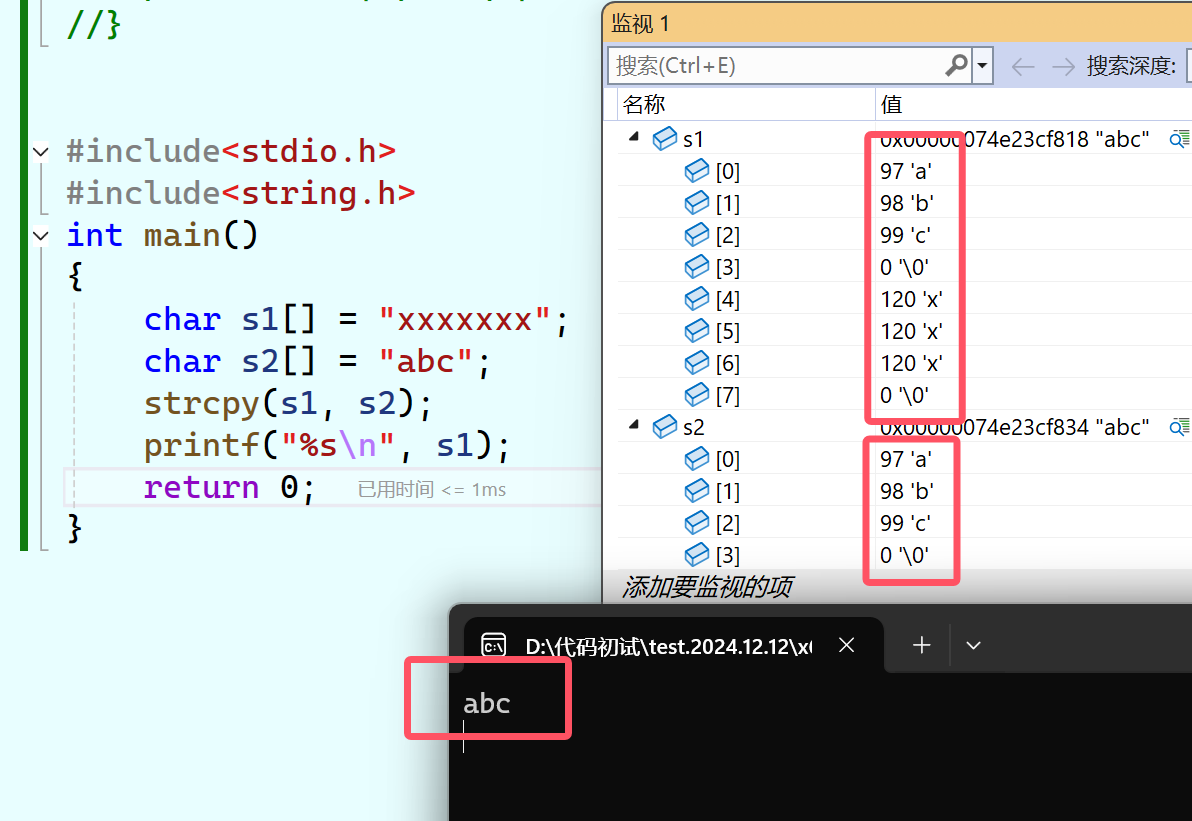
在这里插入图片描述
模拟实现
思路:遍历source字符串,一个一个赋值
char* Mine_strcpy(char* destination,const char* source)
{
assert(destination&&source);
char* ret = destination;
while(*(destination++) = *(source++))
;
return ret;
}3. strcat的使用和模拟实现
使用

在这里插入图片描述
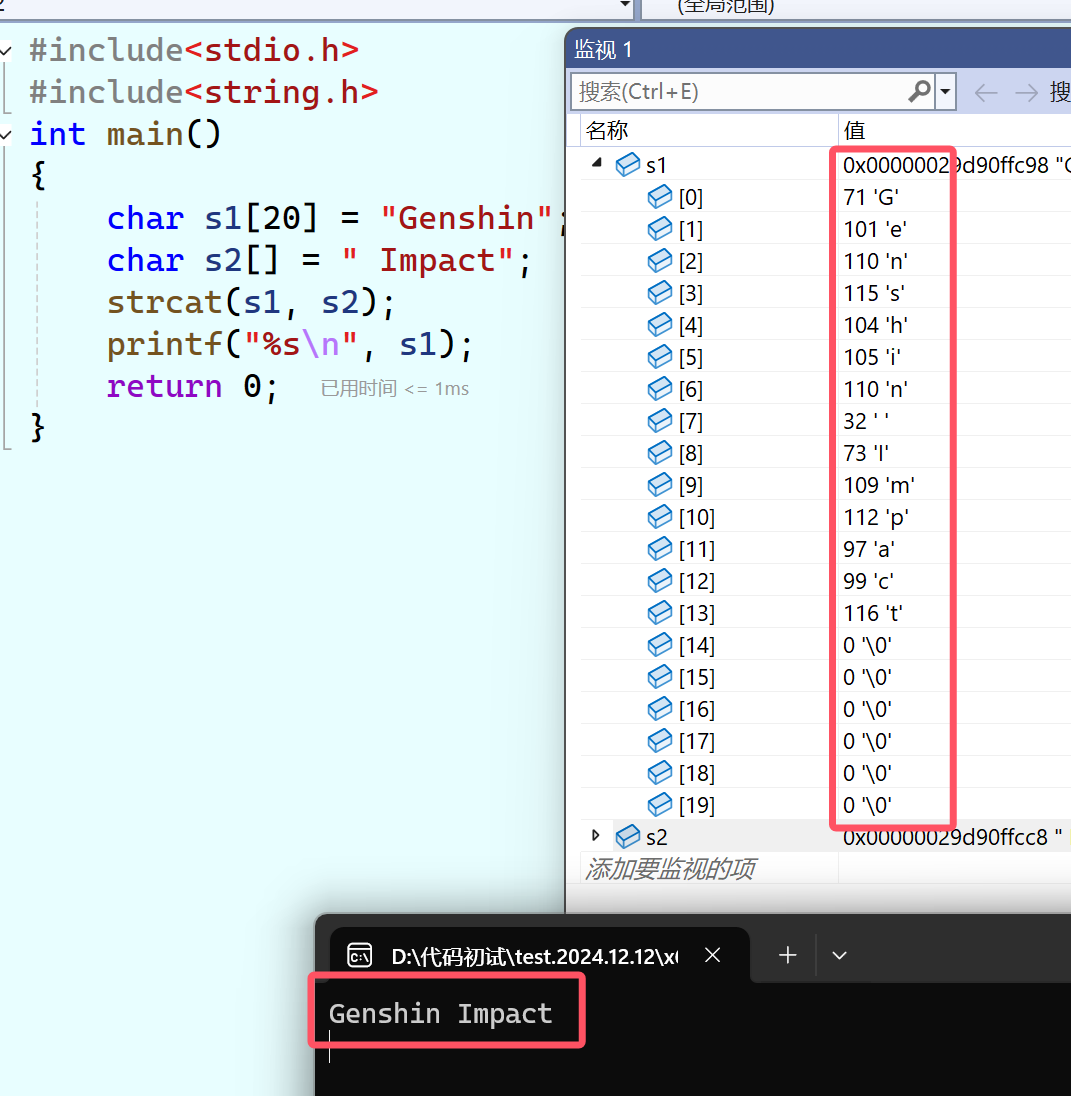
strcat的功能是“连接字符串”,它会将source字符串连接到destination字符串之后,本质上是用源字符串的内容替换目标字符串结尾的\0。也就是说,这个函数修改的是destination字符串的内容。它的使用要点是:目标空间中必须有\0,目标空间必须足够大能容纳的下源字符串的内容,目标空间必须可修改。 举个栗子:
#include<stdio.h>
#include<string.h>
int main()
{
char s1[20] = "Genshin";
char s2[] = " Impact";
strcat(s1,s2);
printf("%s\n",s1);
return 0;
}
在这里插入图片描述
模拟实现
思路:先找到目标字符串的结尾,再一个一个赋值
char* Mine_strcat(char* destination,const char* source)
{
assert(destination&&source);
char* ret = destination;
while(*destination!='\0')
destination++;
while(*(destination++) = *(source++))
;
return ret;
}4. strcmp的使用和模拟实现
使用

在这里插入图片描述

在这里插入图片描述
strcmp能比较两个字符串:str1大于str2,则返回大于0的数字;str1等于str2,则返回0;str1小于str2,则返回小于0的数字。 那么如何比较两个字符串的大小呢?不是根据字符串的长度,而是依次比较相应位置上字符的ASCII值。例如,str1是abcdef,str2是abq,比较第一个字符,ASCII值相同;比较第二个字符,ASCII值相同;比较第三个字符,str2的q比str1的c的ASCII值大。所以str2就比str1大。
模拟实现
int Mine_strcmp(const char* str1,const char* str2)
{
assert(str1&&str2);
while(*str1==*str2)
{
if(*str1=='\0')
return 0;
str1++;
str2++;
}
return *str1-*str2;
}
在这里插入图片描述
strcpy、strcat、strcmp、strncpy、strncat、strncmp在VS中使用时,可能会不安全而报错,在函数名之后加上_s就行。 刚才我们学习的strcpy、strcat、strcmp函数,都是针对长度不受限制的字符串使用的,可能不太安全。所以有时候,我们不会操作整个字符串,而要限制字符数。对此就要使用以下三个函数strncpy、strncat、strncmp。
5. strncpy的使用

在这里插入图片描述
strncpy也是用来拷贝字符串的,它的使用要求几乎和strcpy相同。但它不像strcpy只能将source字符串整个拷贝过去,它可以规定拷贝的字符个数,也就是参数部分的size_t num。当然,如果num超过了str2本身的长度,str2的全部内容都会拷贝过去。 举个栗子:
#include<string.h>
#include<stdio.h>
int main()
{
char str1[] = "xxxxxxx";
char str2[] = "abcdef";
strncpy(str1,str2,3);
printf("%s\n",str1);
return 0;
}
在这里插入图片描述
6. strncat的使用

在这里插入图片描述
这也很好理解了,strncat的使用和strcat几乎相同,都是连接字符串的,但strncat还可以规定把str2的几个字符连接过去。当然,如果num超过了str2本身的长度,str2的全部内容都会连接过去。 举个栗子:
#include<string.h>
#include<stdio.h>
int main()
{
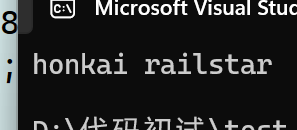
char str1[20] = "honkai ";
char str2[20] = "railstarxxxxxxx";
strncat(str1,str2,8);
printf("%s\n",str1);
return 0;
}
在这里插入图片描述
7. strncmp的使用

在这里插入图片描述
同样地,相较于strcmp,strncmp可以规定比较前几个字符。从第一个开始比较,如果相同就继续往后比较,最多比较num个字符。如果都想等,就返回0。

在这里插入图片描述
8. strstr的使用和模拟实现
使用

在这里插入图片描述
strstr能够找到str2在str1中第一次出现的位置,字符串的比较匹配不包含\0字符,以\0字符作为结束标志。如果能够在str1中找到str2,就返回str2第一次出现的位置(地址);如果找不到,就返回空指针NULL。 举个栗子:
#include<string.h>
#include<stdio.h>
int main()
{
char str1[] = "honkai railstar";
char str2[] = "kai";
char* p = strstr(str1,str2);
printf("%d\n", p-str1);
return 0;
}
在这里插入图片描述
模拟实现
char* Mine_strstr(char* str1, const char* str2)
{
assert(str1&&str2);
const char* cur = str1;//开始匹配的位置
const char* s1 = NULL;//遍历str1
const char* s2 = NULL;//遍历str2
while(*cur!='\0')
{
s1 = cur;
s2 = str2;
while((*s1!='\0')&&(*s2!='\0')&&(*s1==*s2))//依次比较str2和str1中的字符
{
s1++;
s2++;
}
if(*s2=='\0')//如果str2的每个字符都匹配成功,就是在str1中找到了str2
return cur;
cur++;
}
return NULL;
}9. strchr的使用

在这里插入图片描述
strchr很简单,它能找到一个字符在一个字符串中第一次出现的位置并返回,如果找不到就返回空指针NULL。 举个栗子:
#include<string.h>
#include<stdio.h>
int main()
{
char str1[] = "honkai railstar";
char* p = strchr(str1,'k');
printf("%d\n", p-str1);
return 0;
}
在这里插入图片描述
10. strrchr的使用

在这里插入图片描述
strrchr也是查找一个字符串中的特定字符,但它返回的是这个字符在字符串中最后一次出现的位置,如果找不到就返回空指针NULL。值得注意的是,指定字符的参数是int类型。 举个例子:
#include<string.h>
#include<stdio.h>
int main()
{
char str1[] = "abcda";
char* p = strrchr(str1,'a');
printf("%d\n", p-str1);
return 0;
}
在这里插入图片描述
11. strtok的使用
strtok函数的使用较为特殊
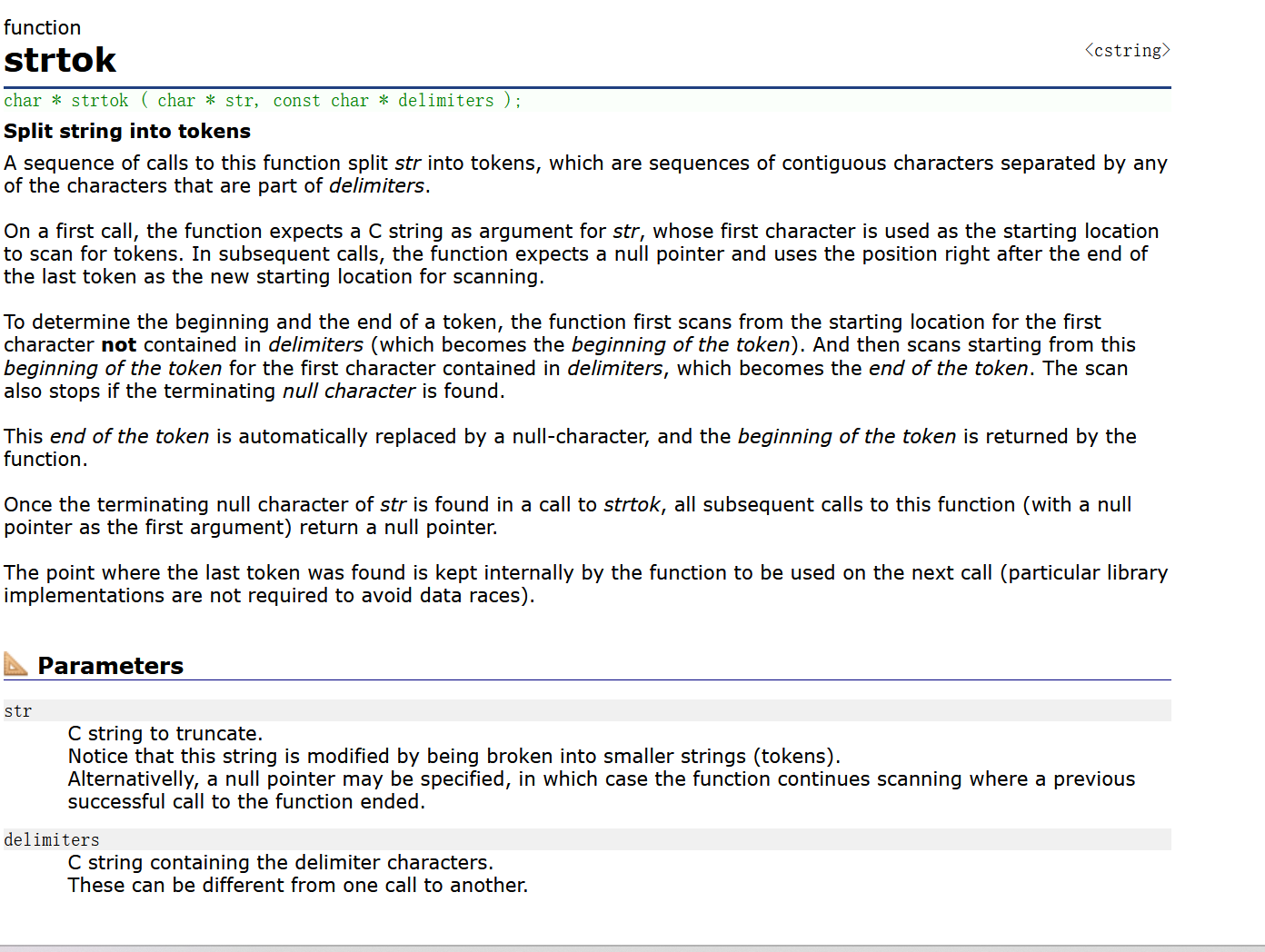
在这里插入图片描述
简单来说,strtok的作用是分割字符串,它的使用形式是char* strtok(char* str, char* sep);。其中str是待分割的字符串,而sep是当做分隔符的字符的数组。在使用时,函数会从左向右读取字符串str,遇到第一个分隔符时,会把它变成\0,然后返回str的起始位置。所以这个函数会改变str的内容,在实际使用时我们常常将原字符串复制一份再分割。
比如我们假设:
char str[] = "abcxdef.ghi@jkl";
char sep[] = "@x.";
char* p = strtok(str,sep);此时%s打印p,结果是abc,因为str的x变成了\0。
但倘若我们再用一次strtok,但第一个参数设成NULL,则函数会从上一次分隔符的出现的地方开始读取,再寻找分隔符,也就是从d开始读取,直到找到了“.”,设置成\0返回d的地址。而如果函数往后读取到结束都找不到分隔符了,就返回空指针NULL。
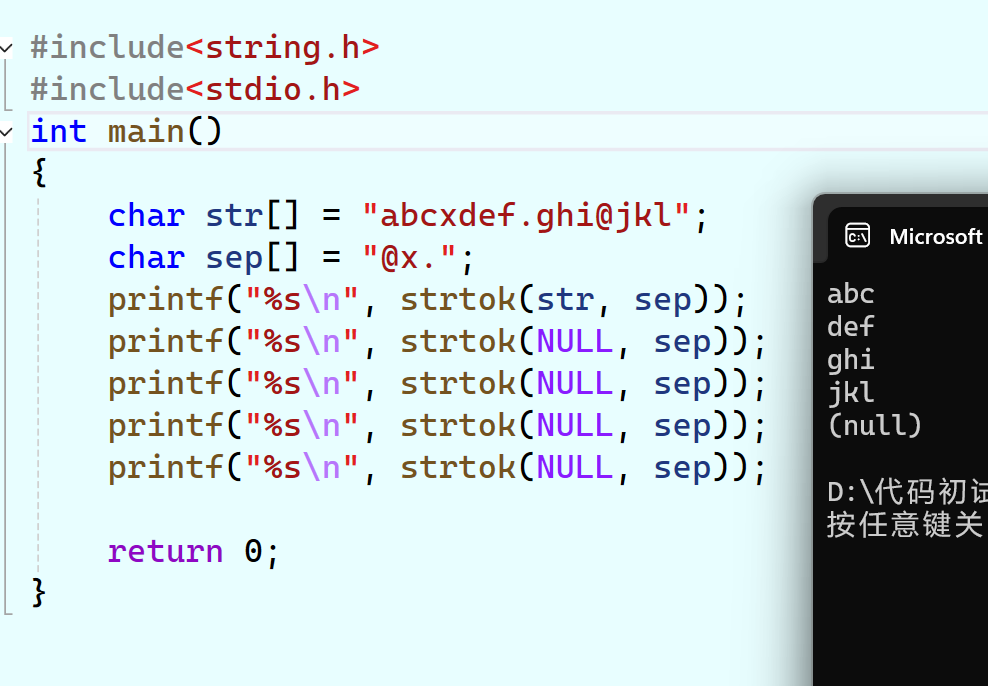
在这里插入图片描述
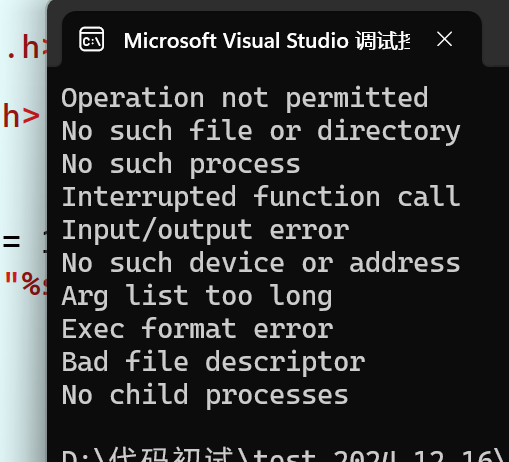
12. strerror的使用

在这里插入图片描述
在不同的系统和C语言标准库中,都规定了一些错误码,一般放在了errno.h这个头文件说明,C语言程序启动时会使用一个全局的变量errno来记录程序当前的错误码。程序启动时errno是0,表示没有错误。每一个错误码都对应一种运行错误,当我们在使用标准库中的函数时发生了某种错误,就会将对应的错误码数储存在中errno中。strerrno的参数部分就是错误码,他可以将对应的错误信息字符串地址返回。 比如我们在Windows11的VS2022环境下看一看1到10对应的错误信息都是什么?
#include<stdio.h>
#include<string.h>
#include<errno.h>
int main()
{
for(int i=1 ; i<=10 ; i++)
printf("%s\n",strerror(i));
return 0;
}
在这里插入图片描述
除此之外,在stdio.h头文件中还有一个函数perror,也可以了解一下

在这里插入图片描述
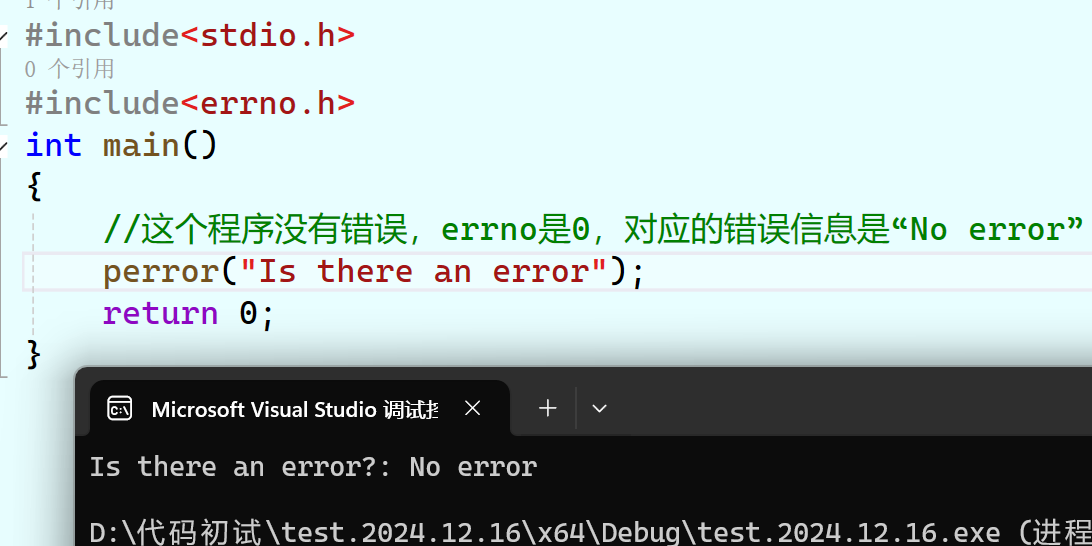
perror函数相当于结合了printf和strerror函数,它先打印出它的参数指向的字符串,再打印一个“:”,再打印出变量errno储存的错误码对应的错误信息字符串。 例如:
#include<stdio.h>
#include<errno.h>
int main()
{
//这个程序没有错误,errno是0,对应的错误信息是“No error”
perror("Is there an error");
return 0;
}
在这里插入图片描述

在这里插入图片描述
三、内存函数
C语言的指针是其精髓之一,而指针和内存千丝万缕。所以我们也应该掌握一些与内存相关的函数。以下函数也包含在string.h头文件中。
1. memcpy的使用和模拟实现
使用

在这里插入图片描述
函数memcpy会从source的位置开始向后拷贝num个字节的数据到destination指向的内存位置,这个函数在遇到\0前不会停止拷贝。如果source和destination有内存重叠的部分,那么函数是无法保证运行结果的,比如
int a[5]={1,2,3,4,5};
memcpy(a+2, a, 3*sizeof(int));我们不知道3是先拷贝到a[4]的位置再变成了1,或是3先变成了1再拷贝到a[4]的位置。运行后a中可能变成1,2,1,2,3,也可能变成1,2,1,2,1。所以我们就不要用memcpy处理内存有重叠的两块区域了,而可以用memmove来实现。
模拟实现
思路:一个字节一个字节地拷贝
void* Mine_memcpy(void* destination, const void* source, size_t num)
{
assert(destination&&source);
void* ret = destination;
while(num--)
{
*(char*)destination = *(char*)source;
destination=(char*)destination+1;
source=(char*)source+1;
}
return ret;
}2. memmove的使用和模拟实现
使用

在这里插入图片描述
memmove和memcpy的作用完全相同,差别就是memmove函数处理的源空间和目标空间可以重叠。使用memmove就可以将被拷贝数据完整地拷贝过去,不会出现某些数据被拷贝前就被修改的情况了。
int a[5]={1,2,3,4,5};
memmove(a+2, a, 3*sizeof(int));这样,a中一定是1,2,1,2,3
int a[5]={1,2,3,4,5};
memmove(a, a+2, 3*sizeof(int));这样,a中一定是3,4,5,4,5
模拟实现
思路:为了防止被拷贝数据被覆盖,分成两种情况,从后向前依次拷贝,或是从前向后依次复制
void* Mine_memmove(void* destination, const void* source, size_t num)
{
assert(destination&&source);
void* ret = destination;
if(destination<source)
{
while(num--)
{
*(char*)destination = *(char*)source;
destination = (char*)destination+1;
source = (char*)source+1;
}
}
else
{
while(num--)
*((char*)destination+num) = *((char*)source+num);
}
return ret;
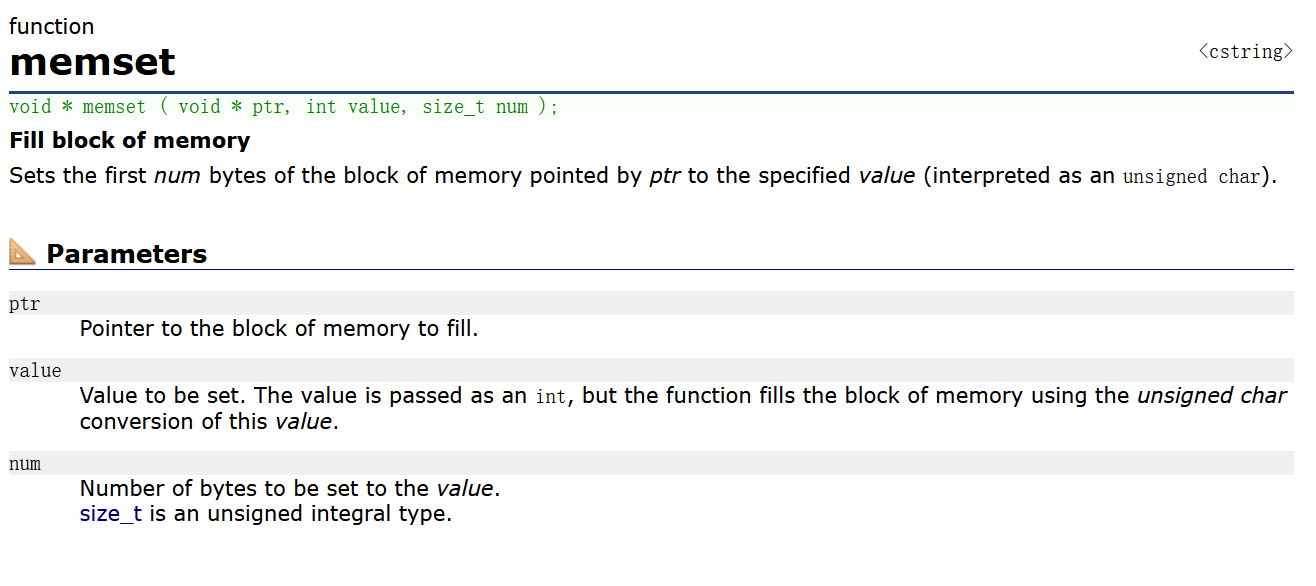
}3. memset的使用
在这里插入图片描述
memset是用来设置内存的,可以将内存中的值以字节为单位设置成想要的内容。它可以把ptr指向的内存的前num个字节设置成给定的value值。 举个栗子:
#include<stdio.h>
#include<string.h>
int main()
{
char str[] = "abcde";
memset(str, 'x', 3);
printf("%s\n",str);
return 0;
}
在这里插入图片描述
4. memcmp的使用

在这里插入图片描述
memcmp能比较ptr1和ptr2指针指向的位置开始向后的num个字节,返回值的规则和strcmp类似

在这里插入图片描述
这里就不再举例子赘述了(我也累了~)
本篇完,感谢阅读
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-12-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号