一文彻底搞清楚数据结构之链表

一文彻底搞清楚数据结构之链表

承渊政道
发布于 2025-12-18 17:15:10
发布于 2025-12-18 17:15:10

前言:在上篇文章我们思考过这些问题:在顺序表的增删中能否降一下时间复杂度?可以不需要增容吗?能不浪费空间?.本篇文章就来介绍一下数据逻辑结构中的线性结构中的线性表包含的链表,相信你通过本篇文章就会寻找到这些问题的答案!下面跟着小编的节奏🎵一起学习吧!
1.链表的定义
线性表的链式存储是指,用一组地址任意的存储单元依次存储线性表中的各个数据元素,这些存储单元可以是连续的,也可以是不连续的.采用链式存储结构的线性表称为链表.
2.单链表的概念
概念:单链表是⼀种物理存储结构上⾮连续、⾮顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的. 我们可以形象的将链表理解为车厢,淡季时⻋次的⻋厢会相应减少,旺季时⻋次的⻋厢会额外增加⼏节.只需要将⽕⻋⾥的某节⻋厢去掉或者加上,不会影响其他⻋厢,每节⻋厢都是独⽴存在的. 那么在链表⾥,每节“⻋厢”是什么样的呢?

2.1结点的认识
与顺序表不同的是,链表⾥的每节"⻋厢"都是独⽴申请下来的空间,我们称之为"结点" 1️⃣结点的组成主要有两个部分:当前结点要保存的数据和保存下⼀个结点的地址(指针变量). 2️⃣图中指针变量plist保存的是第⼀个结点的地址,我们称plist此时指向第⼀个结点(头结点)如果我们希望plist指向第⼆个结点时,只需要修改plist保存的内容为0x0012FFA0. 3️⃣链表中每个结点都是独⽴申请的(即需要插⼊数据时才去申请⼀块结点的空间),我们需要通过指针 变量来保存下⼀个结点位置才能从当前结点找到下⼀个结点. 注意:存储数据元素本身数据信息的部分称为数据域(data),存储其直接后继元素地址信息的部分称为指针域(next).
2.2链表的性质
1️⃣链式机构在逻辑上是连续的,在物理结构上不⼀定连续. 2️⃣结点⼀般是从堆上申请的. 3️⃣从堆上申请来的空间,是按照⼀定策略分配出来的,每次申请的空间可能连续,可能不连续. 结合前⾯学到的结构体知识,我们可以给出每个结点对应的结构体代码:假设当前保存的结点为整型:
struct SListNode
{
int data; //结点数据
struct SListNode* next; //指针变量⽤保存下⼀个结点的地址
};当我们想要保存⼀个整型数据时,实际是向操作系统申请了⼀块内存,这个内存不仅要保存整型数 据,也需要保存下⼀个结点的地址(当下⼀个结点为空时保存的地址为空)当我们想要从第⼀个结点⾛到最后⼀个结点时,只需要在当前结点拿上下⼀个结点的地址就可以了.
2.3链表的打印
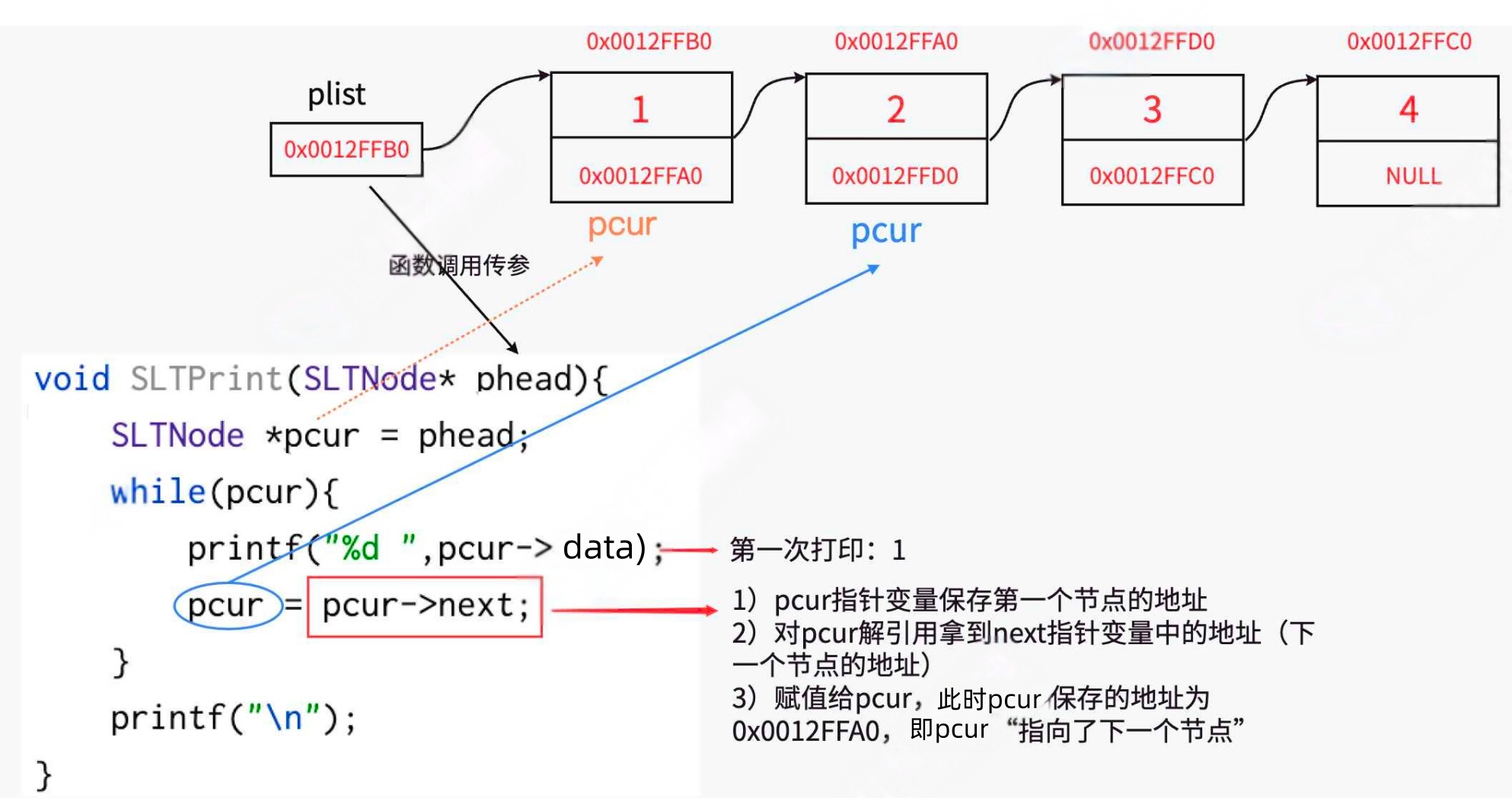
3.单链表的实现(头尾的增删、指定位置和之前之后的增删、链表创建和销毁)
//创建并初始化单链表
SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node2 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node3 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node4 = (SLTNode*)malloc(sizeof(SLTNode));
node1->data = 1;
node2->data = 2;
node3->data = 3;
node4->data = 4;
node1->next = node2;
node2->next = node3;
node3->next = node4;
node4->next = NULL;
SLTNode* plist = node1;
SLTPrint(plist);
//链表的打印
void SLTPrint(SLTNode* phead)
{
SLTNode* pcur = phead;
while (pcur)//pcur!=NULL
{
printf("%d -> ", pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = SLTbuyNode(x);
//链表为空
if (*pphead == NULL)
{
*pphead = newnode;
}
else {
//找尾
SLTNode* ptail = *pphead;
while (ptail->next)
{
ptail = ptail->next;
}
//ptail newnode
ptail->next = newnode;
}
}//时间复杂度为:O(N)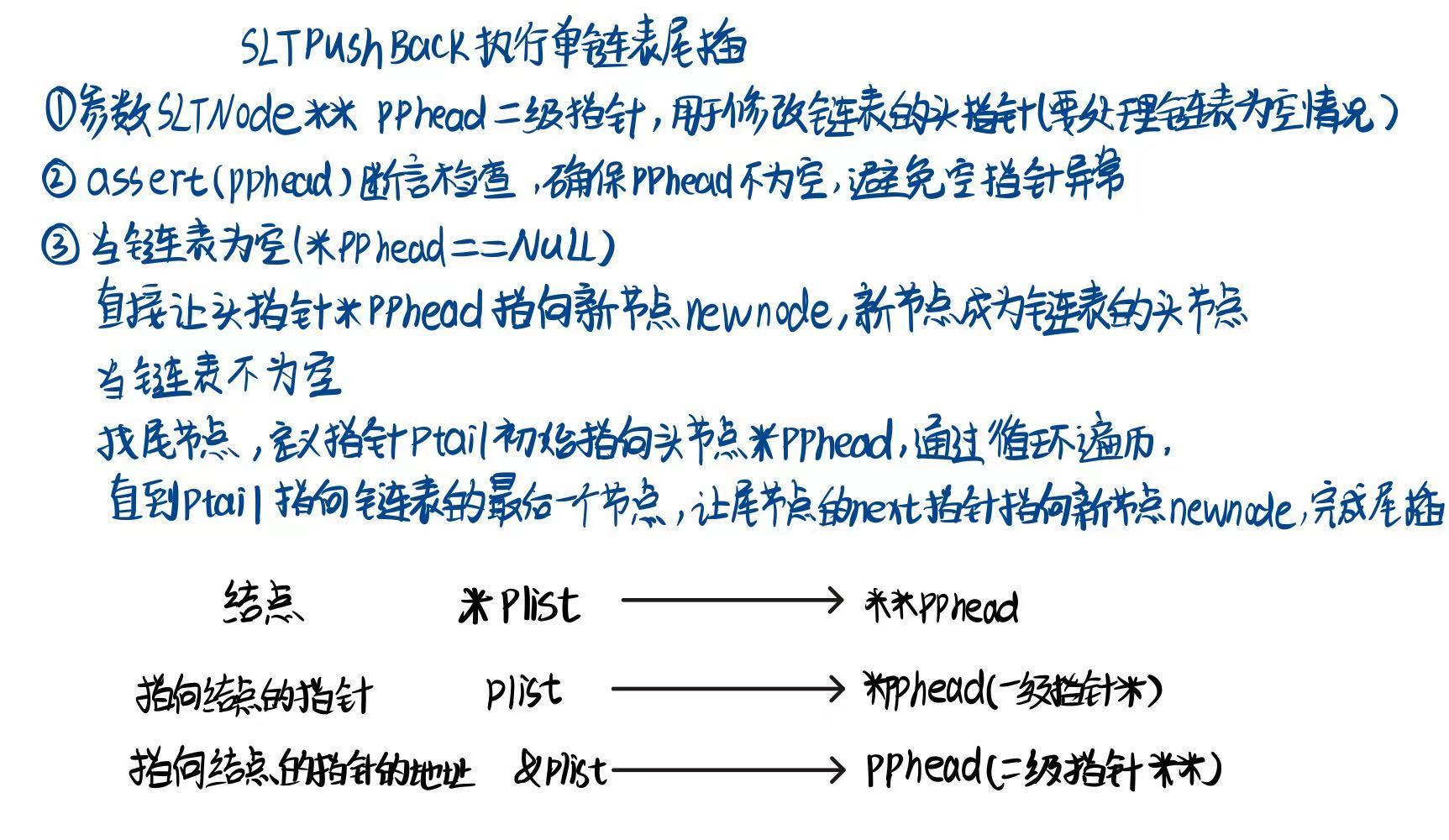
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = SLTbuyNode(x);
//newnode *pphead
newnode->next = *pphead;
*pphead = newnode;
}//时间复杂度为:O(1)
//尾删
void SLTPopBack(SLTNode** pphead)
{
assert(pphead && *pphead);
//只有一个结点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else {
SLTNode* prev = NULL;
SLTNode* ptail = *pphead;
while (ptail->next)
{
prev = ptail;
ptail = ptail->next;
}
//prev ptail
prev->next = NULL;
free(ptail);
ptail = NULL;
}
}//时间复杂度为:O(N)
//头删
void SLTPopFront(SLTNode** pphead)
{
assert(pphead && *pphead);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}//时间复杂度为:0(1)
//在指定位置之前插⼊数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead && pos);
//当pos指向第一个结点,是头插
if (pos == *pphead)
{
SLTPushFront(pphead, x);
}
else {
SLTNode* newnode = SLTbuyNode(x);
//找pos的前一个结点
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//prev--> newnode--> pos
prev->next = newnode;
newnode->next = pos;
}
}//时间复杂度为:O(N)
//在指定位置之后插⼊数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = SLTbuyNode(x);
//pos newnode pos->next
newnode->next = pos->next;
pos->next = newnode;
}//时间复杂度为:O(1)
//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead && pos);
//pos就是头结点
if (pos == *pphead)
{
SLTPopFront(pphead);
}
else {
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//prev pos pos->next
prev->next = pos->next;
free(pos);
pos = NULL;
}
}//时间复杂度为:O(N)
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos)
{
assert(pos && pos->next);
//pos del del->next
SLTNode* del = pos->next;
pos->next = del->next;
free(del);
del = NULL;
}//时间复杂度为:O(1)
//销毁链表
void SListDestroy(SLTNode** pphead)
{
SLTNode* pcur = *pphead;
while (pcur)
{
SLTNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;
}
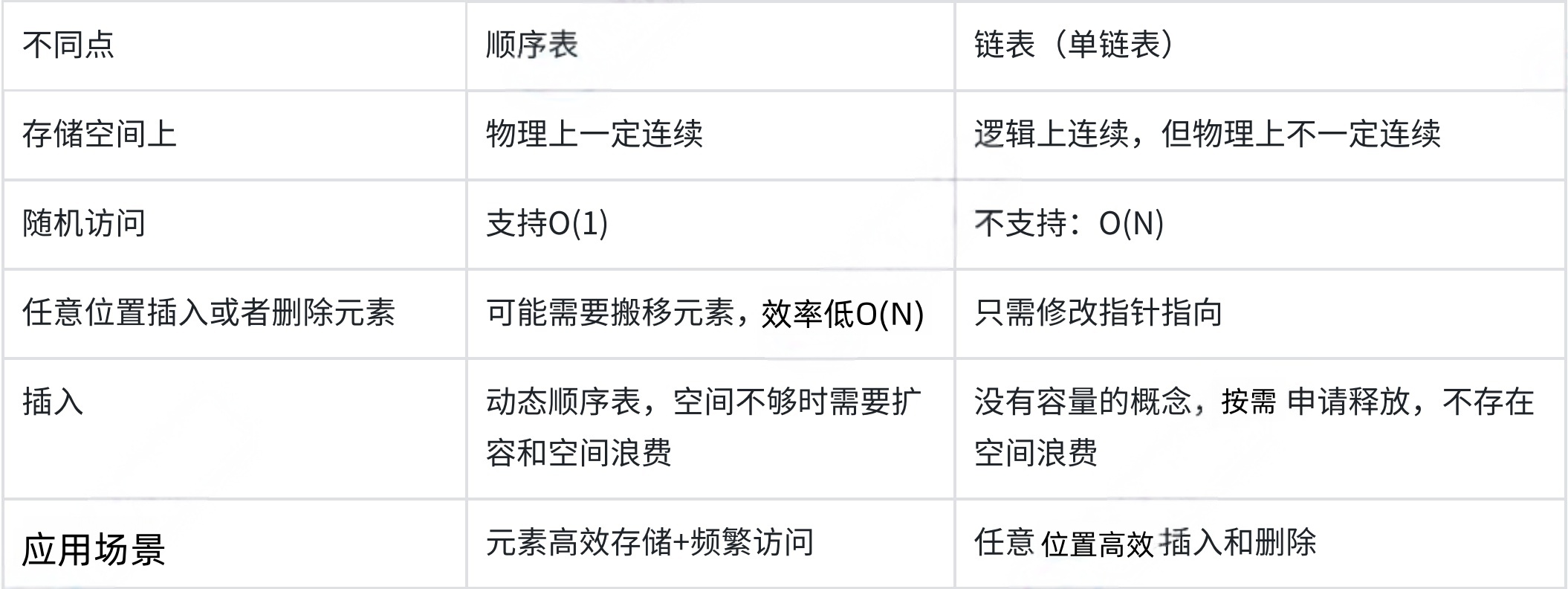
总结:通过上面的介绍,我们来回想一下前言的内容:链表头部插入和删除时间复杂度降为了:O(1);链表无需增容;链表不存在空间浪费.那这样子通过与顺序表的对比是不是说链表比顺序表要好呢?其实不是的,两者各有各的优势,存在即合理! 我们来看一下顺序表和链表之间的差异
4.单链表的完整代码实现
SList.c
#include"SList.h"
//链表的打印
void SLTPrint(SLTNode* phead)
{
SLTNode* pcur = phead;
while (pcur)
{
printf("%d -> ", pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}
SLTNode* SLTbuyNode(SLTDataType x)
{
//根据x创建节点
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail!");
exit(1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = SLTbuyNode(x);
//链表为空
if (*pphead == NULL)
{
*pphead = newnode;
}
else {
//找尾
SLTNode* ptail = *pphead;
while (ptail->next)
{
ptail = ptail->next;
}
//ptail newnode
ptail->next = newnode;
}
}
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = SLTbuyNode(x);
//newnode *pphead
newnode->next = *pphead;
*pphead = newnode;
}
//尾删
void SLTPopBack(SLTNode** pphead)
{
assert(pphead && *pphead);
//只有一个结点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else {
SLTNode* prev = NULL;
SLTNode* ptail = *pphead;
while (ptail->next)
{
prev = ptail;
ptail = ptail->next;
}
//prev ptail
prev->next = NULL;
free(ptail);
ptail = NULL;
}
}
//头删
void SLTPopFront(SLTNode** pphead)
{
assert(pphead && *pphead);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* pcur = phead;
while (pcur)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
//在指定位置之前插⼊数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead && pos);
//当pos指向第一个结点,是头插
if (pos == *pphead)
{
SLTPushFront(pphead, x);
}
else {
SLTNode* newnode = SLTbuyNode(x);
//找pos的前一个结点
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//prev--> newnode--> pos
prev->next = newnode;
newnode->next = pos;
}
}
//在指定位置之后插⼊数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = SLTbuyNode(x);
//pos newnode pos->next
newnode->next = pos->next;
pos->next = newnode;
}
//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead && pos);
//pos就是头结点
if (pos == *pphead)
{
SLTPopFront(pphead);
}
else {
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//prev pos pos->next
prev->next = pos->next;
free(pos);
pos = NULL;
}
}
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos)
{
assert(pos && pos->next);
//pos del del->next
SLTNode* del = pos->next;
pos->next = del->next;
free(del);
del = NULL;
}
//销毁链表
void SListDestroy(SLTNode** pphead)
{
SLTNode* pcur = *pphead;
while (pcur)
{
SLTNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;
}SList.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
//定义链表的结构---结点的结构
typedef int SLTDataType;
typedef struct SListNode {
SLTDataType data;//存储的数据
struct SListNode* next; //指向下一个结点
}SLTNode;
//typedef struct SListNode SLTNode;
//链表的打印
void SLTPrint(SLTNode* phead);
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
//尾删
void SLTPopBack(SLTNode** pphead);
//头删
void SLTPopFront(SLTNode** pphead);
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//在指定位置之前插⼊数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//在指定位置之后插⼊数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos);
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos);
//销毁链表
void SListDestroy(SLTNode** pphead);test.c
#include"SList.h"
void test01()
{
SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node2 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node3 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node4 = (SLTNode*)malloc(sizeof(SLTNode));
node1->data = 1;
node2->data = 2;
node3->data = 3;
node4->data = 4;
node1->next = node2;
node2->next = node3;
node3->next = node4;
node4->next = NULL;
SLTNode* plist = node1;
SLTPrint(plist);
}
void test02()
{
//创建空链表
SLTNode* plist = NULL;
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
SLTPushBack(&plist, 4);
SLTPrint(plist);
SLTPushFront(&plist, 1);
SLTPushFront(&plist, 2);
SLTPushFront(&plist, 3);
SLTPushFront(&plist, 4);
SLTPrint(plist);
SLTPushFront(NULL, 4);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPopFront(&plist);
SLTPrint(plist);
SLTPopFront(&plist);
SLTPrint(plist);
SLTPopFront(&plist);
SLTPrint(plist);
SLTPopFront(&plist);
SLTPrint(plist);
SLTPopFront(&plist);
SLTNode* find = SLTFind(plist, 4);
if (find)
{
printf("找到了!\n");
}
else {
printf("未找到!\n");
}
SLTInsert(&plist, find, 100);//1 2 3 100 4
SLTInsertAfter(find, 100);//1 100 2 3 4
SLTErase(&plist, find);
SLTEraseAfter(find);//1 3 4
SLTPrint(plist);
SListDestroy(&plist);
}
struct ListNode {
int val;//保存的数据 data
struct ListNode* next;
};
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val) {
//创建空链表
ListNode* newHead, * newTail;
newHead = newTail = NULL;
ListNode* pcur = head;
while (pcur)
{
//把值不为val的结点尾插到新链表中
if (pcur->val != val)
{
//尾插
//链表为空
if (newHead == NULL)
{
newHead = newTail = pcur;
}
else {
//链表非空
newTail->next = pcur;
newTail = newTail->next;
}
}
pcur = pcur->next;
}
//pcur为空
return newHead;
}
ListNode* buynode(int val)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
newnode->val = val;
newnode->next = NULL;
return newnode;
}
void testOJ()
{
//构造链表
SLTNode* node1 = buynode(1);
SLTNode* node2 = buynode(2);
SLTNode* node3 = buynode(6);
SLTNode* node4 = buynode(3);
SLTNode* node5 = buynode(4);
SLTNode* node6 = buynode(5);
SLTNode* node7 = buynode(6);
node1->next = node2;
node2->next = node3;
node3->next = node4;
node4->next = node5;
node5->next = node6;
node6->next = node7;
ListNode* ret = removeElements(node1,6);
}
int main()
{
//test01();
//test02();
testOJ();
return 0;
}5.链表的分类
链表的结构⾮常多样,以下情况组合起来就有8种(2 x 2 x 2)链表结构:
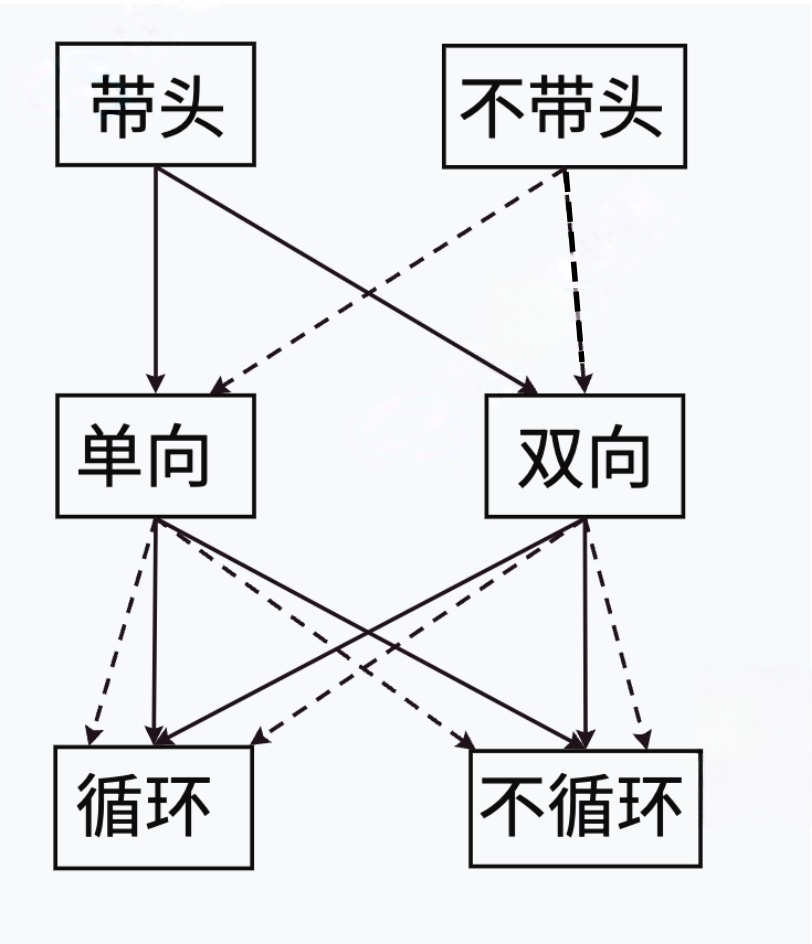
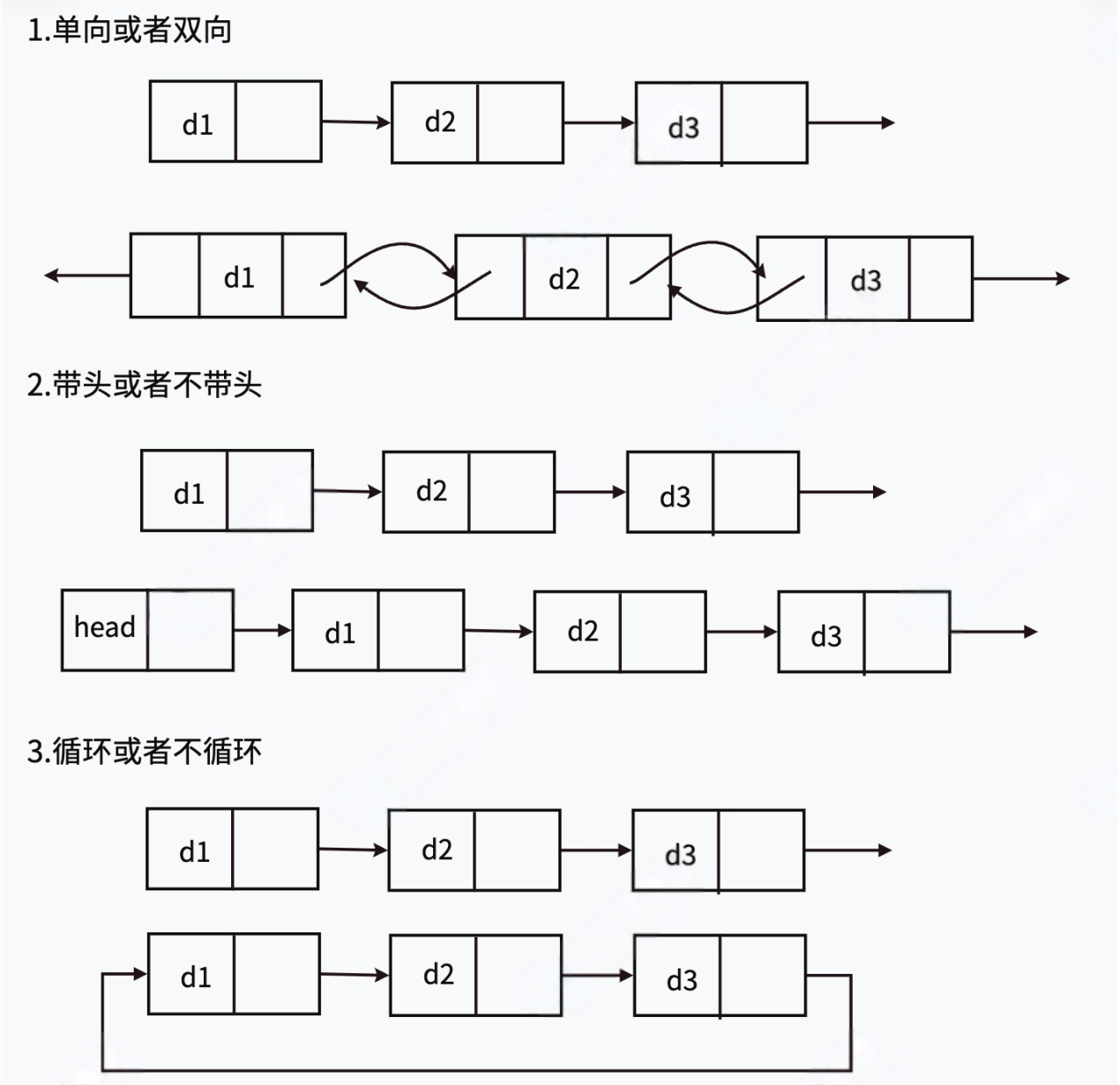
虽然有这么多的链表的结构,但是我们实际中最常⽤还是两种结构:单链表和双向带头循环链表 1️⃣⽆头单向⾮循环链表:结构简单,⼀般不会单独⽤来存数据.实际中更多是作为其他数据结构的⼦ 结构,如哈希桶、图的邻接表等等.另外这种结构在笔试⾯试中出现很多. 2️⃣带头双向循环链表:结构最复杂,⼀般⽤在单独存储数据.实际中使⽤的链表数据结构,都是带头 双向循环链表.另外这个结构虽然结构复杂,但是使⽤代码实现以后会发现结构会带来很多优势,实现反⽽简单了,后⾯我们代码实现了就知道了.
敬请期待下一篇文章内容:数据结构之单链表算法题和双向链表实现!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-11-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号