《C++进阶之C++11》【列表初始化 + 右值引用】

《C++进阶之C++11》【列表初始化 + 右值引用】

序属秋秋秋
发布于 2025-12-18 16:13:22
发布于 2025-12-18 16:13:22
往期《C++初阶》回顾:《C++初阶》目录导航
往期《C++进阶》回顾:
/------------ 继承多态 ------------/
【普通类/模板类的继承 + 父类&子类的转换 + 继承的作用域 + 子类的默认成员函数】
【final + 继承与友元 + 继承与静态成员 + 继承模型 + 继承和组合】
【多态:概念 + 实现 + 拓展 + 原理】
/------------ STL ------------/
【二叉搜索树】
【AVL树】
【红黑树】
【set/map 使用介绍】
【set/map 模拟实现】
【哈希表】
【unordered_set/unordered_map 使用介绍】
【unordered_set/unordered_map 模拟实现】
前言:
hi ~ 小伙伴们大家好啊!♪(´▽`) 今天是 2025 年 9 月 22 日,不知道大家有没有留意到,明天就是秋分节气了 (ノ>ω<)ノ☆ 秋分是二十四节气中的第十六个,通常在每年 9 月 22 日至 24 日到来。 这一天,太阳直射赤道,全球昼夜几乎等长;而从秋分过后,北半球便会进入昼渐短、夜渐长的阶段,气温下降的速度也会明显加快,真正的秋天就此拉开序幕 ʕ•̀ω•́ʔ♪ (≧ڡ≦*)ゞ
恰逢秋分将至 —— 这个昼夜均分、秋意正式登场的节点,我们也即将开启 C++ 学习主线中的最后一座 “高山”——《C++11》 今天先给大家端上两道开胃小菜:【列表初始化 + 右值引用】,大家先趁热 “尝尝鲜”,后续更多硬核内容,咱们慢慢解锁! ٩(ˊᗜˋ*)و ✧(≖‿‿≖✿)
------------列表初始化------------
1. 什么是列表初始化?
列表初始化(List Initialization):是C++11引入的一种新的初始化方式,它使用花括号 {} 来提供一组值,用于初始化变量、对象或容器。
- 它能在初始化时明确指定初始值,增强代码的可读性和可维护性
- 它以花括号
{}的形式出现,为初始化操作带来了统一的语法风格
列表初始化的基本语法:
//基本语法一:
Type variable{arg1, arg2, ...};
//基本语法二:
Type variable = {arg1, arg2, ...};2. 列表初始化的使用场景有哪些?
1. 基本数据类型:
可以使用列表初始化来初始化基本数据类型,例如:int、double 等
//内置数据类型的初始化
int num = {5};
double d = {3.14};
//数组的初始化
int arr[]{1, 2, 3, 4, 5};2. 自定义类类型:
- 对于自定义类,只要类定义了合适的构造函数,就可以使用列表初始化
- 如果类定义了
默认构造函数和多个参数的构造函数,C++11 引入了聚合类的概念,聚合类可以直接使用列表初始化
聚合类需满足以下条件:
- 没有
用户提供的构造函数 - 没有
私有或保护的非静态数据成员 - 没有
虚函数 - 没有
虚基类
#include <iostream>
#include <vector>
#include <string>
/*--------------------------- 自定义类类型 ---------------------------*/
class Person
{
public:
// 构造函数可以使用初始化列表
Person(std::string n, int a, double h)
: name{ n },
age{ a },
height{ h }
{ }
void display() const
{
std::cout << "Name: " << name
<< ", Age: " << age
<< ", Height: " << height
<< "m" << std::endl;
}
private:
std::string name;
int age;
double height;
};
/*--------------------------- 聚合类 ---------------------------*/
class Point
{
public:
int x;
int y;
int z;
};
int main()
{
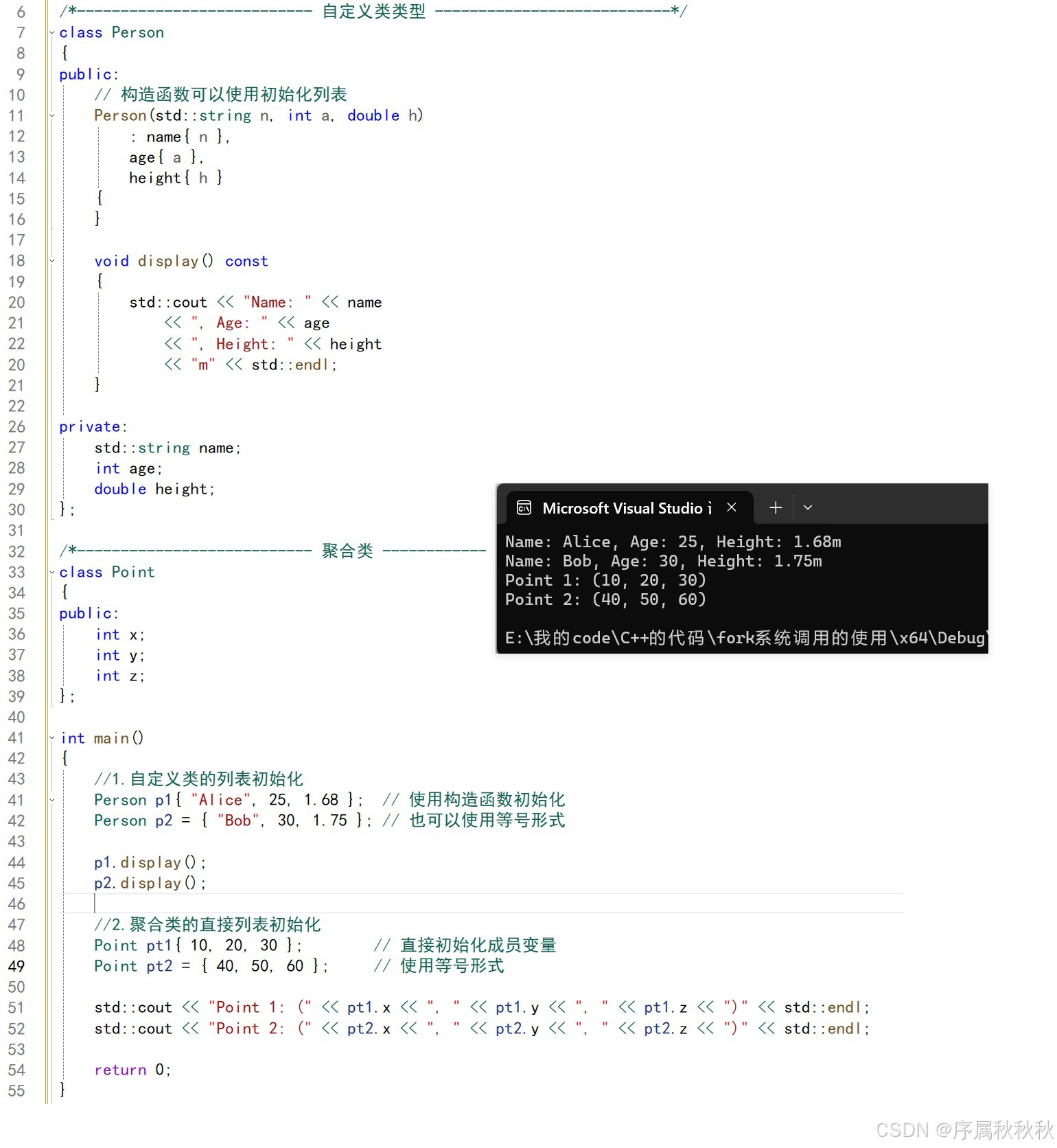
//1.自定义类的列表初始化
Person p1{ "Alice", 25, 1.68 }; // 使用构造函数初始化
Person p2 = { "Bob", 30, 1.75 }; // 也可以使用等号形式
p1.display();
p2.display();
//2.聚合类的直接列表初始化
Point pt1{ 10, 20, 30 }; // 直接初始化成员变量
Point pt2 = { 40, 50, 60 }; // 使用等号形式
std::cout << "Point 1: (" << pt1.x << ", " << pt1.y << ", " << pt1.z << ")" << std::endl;
std::cout << "Point 2: (" << pt2.x << ", " << pt2.y << ", " << pt2.z << ")" << std::endl;
return 0;
}
在这里插入图片描述
3. 标准容器:
在初始化标准容器(如:vector、list、map 等)时,列表初始化也非常常用
#include <vector>
#include <map>
//使用语法一进行初始化
std::vector<int> v = { 1, 2, 3, 4, 5 };
std::map<std::string, int> m = { {"apple", 1}, {"banana", 2} };
/* 列表初始化对 STL 容器特别友好
* - 调用 push_back、insert 等接口时:
* - 用 {} 可直接构造 “多参数对象”,无需手动创建临时对象
*
*/
//使用语法二进行初始化
std::vector<int> v{ 1, 2, 3, 4, 5 };
std::map<std::string, int> m{ {"one", 1}, {"two", 2} };3. C++11引入列表初始化的历程是什么?
在 C++98 标准里:
- 普通
数组和结构体(或类,满足聚合类型条件时 )能够借助{}这种初始化列表的形式来完成初始化操作
// 定义一个结构体 Point,用于表示二维坐标点
struct Point
{
int _x;
int _y;
};
int main()
{
//1.初始化一个整型数组 array1,花括号内依次是数组元素的初始值
int array1[] = { 1, 2, 3, 4, 5 }; //注意:编译器会根据初始值的数量自动推导数组长度为 5
//2.初始化一个长度为 5 的整型数组 array2
int array2[5] = { 0 }; //注意:花括号内只有一个初始值 0,此时数组的第一个元素被初始化为 0,剩余未显式初始化的元素会被默认初始化为 0(对于内置整型类型)
//3.初始化结构体 Point 的对象 p
Point p = { 1, 2 }; //注意:按照结构体成员的声明顺序,用花括号内的值依次初始化 _x 和 _y
return 0;
}C++98中传统的{}的总结: 结构体初始化要点:
- 这里的
Point结构体属于聚合类型(简单来说,就是没有自定义构造函数、没有 私有/保护 非静态成员、没有基类和虚函数等情况 ),所以可以直接用{}按照成员声明顺序进行初始化 - 如果结构体定义了自定义构造函数等,可能就需要用对应的构造函数语法来初始化了,不能直接这样简单用
{}按成员顺序初始化
与 C++11 及后续列表初始化的关联:
- C++98 这种
{}初始化是列表初始化的早期形态,C++11 在此基础上进行了大幅扩展和统一,让更多类型(比如:标准库容器、复杂自定义类等 )都能使用类似简洁的{}语法初始化 - 并且优化了很多初始化逻辑和特性 ,后续 C++ 标准不断完善,让初始化操作变得更灵活、易用和规范
在 C++11 标准里:
设计目标:统一初始化方式
- C++11 引入列表初始化(也叫
{}初始化 ),核心目标是让所有对象都能用统一的{}语法初始化 - 不管是内置类型(如:
int、double),还是自定义类,都能通过花括号完成初始化,简化语法、减少学习成本
支持范围:内置类型 + 自定义类型
内置类型:直接用 {} 赋值。
- 比如:
int a{5};、double b{3.14};
自定义类型:本质是通过类型转换 + 构造函数实现。
- 初始化时可能先产生临时对象,再经编译器优化后,直接调用构造函数完成初始化(减少不必要的临时对象开销 )
class Point
{
public:
int x, y;
Point(int a, int b) : x(a), y(b) {}
};
// 列表初始化:先匹配构造函数,编译器优化后直接构造
Point p{1, 2}; 4. 列表初始化有什么优势?
列表初始化与其他初始化方式的区别:
统一的初始化语法:传统的初始化方式,如使用 () 进行直接初始化,在某些情况下可能存在歧义,而列表初始化语法更清晰
- 例如:对于只有一个参数的构造函数,
int a(5);和int a = 5;都能完成初始化,但当遇到更复杂的情况,列表初始化能明确表达意图
防止窄化转换:
列表初始化会进行类型检查,防止窄化转换(即:把一个较大范围的数据类型转换为较小范围的数据类型,可能会丢失数据 )
如果出现窄化转换,编译器会报错
int a = {3.14}; // 编译错误,窄化转换5. 什么是initializer_list?
std::initializer_list:它允许函数或构造函数接受花括号初始化列表作为参数,是实现列表初始化的关键机制。
它是C++11引入的一个轻量级模板类
它表示一个轻量级的、可以持有相同类型对象的列表
它提供了一种统一的方式来处理在花括号初始化列表{}中指定的多个值
std::initializer_list定义在<initializer_list>头文件中,是一个模板类
template<class T> class initializer_list;T:是列表中元素的类型
initializer_list的工作原理:
- 当使用花括号初始化列表初始化一个对象时,如果该对象的构造函数是std::initializer_list类型的参数
- 编译器会自动将花括号中的值打包成一个std::initializer_list对象传递给构造函数
std::initializer_list内部通常包含三个关键部分:
- 指向列表首元素的指针:用于定位列表的起始位置
- 指向列表尾元素下一个位置的指针:用于确定列表的结束位置,类似
vector的end()迭代器 - 记录列表中元素个数的大小信息:方便在遍历或操作时知晓元素数量
例如:下面是一段简单示例代码,展示了std::initializer_list的基本使用:
#include <iostream>
#include <initializer_list>
void print(std::initializer_list<int> list)
{
for (auto it = list.begin(); it != list.end(); ++it)
{
std::cout << *it << " ";
}
std::cout << std::endl;
}
int main()
{
print({1, 2, 3, 4, 5});
return 0;
}在上述代码中:
print函数接受std::initializer_list<int>类型的参数- 在
main函数中调用print时,使用花括号初始化列表{1, 2, 3, 4, 5},编译器会自动将其转换为std::initializer_list<int>对象传递给print函数 - 然后通过迭代器遍历并输出列表中的元素
initializer_list使用场景: 1. 标准容器的初始化:
- C++11 之后,许多标准容器(如:
vector、list、set、map等)都增加了接受std::initializer_list参数的构造函数,这使得容器的初始化变得更加简洁直观
#include <iostream>
#include <vector>
#include <map>
std::vector<int> v = {1, 2, 3, 4, 5};
std::map<std::string, int> m = {{"apple", 1}, {"banana", 2}};
int main()
{
for (auto num : v)
{
std::cout << num << " ";
}
std::cout << std::endl;
for (auto it = m.begin(); it != m.end(); ++it)
{
std::cout << it->first << ": " << it->second << std::endl;
}
return 0;
}2. 自定义类的初始化:
- 自定义类也可以通过定义接受std::initializer_list参数的构造函数,来支持使用花括号初始化列表进行初始化
#include <iostream>
#include <vector>
#include <initializer_list> // 提供 initializer_list 类型支持花括号初始化
// 自定义数组类,封装 std::vector 并支持列表初始化
class MyArray
{
private:
std::vector<int> data; // 底层存储容器
public:
// 支持 initializer_list 的构造函数,允许使用花括号初始化 ---> 例如: MyArray arr = {1, 2, 3};
MyArray(std::initializer_list<int> list)
{
// 遍历 initializer_list 中的元素并添加到 vector
for (auto value : list)
{
data.push_back(value);
}
}
void print()
{
for (auto num : data)
{
std::cout << num << " ";
}
std::cout << std::endl;
}
};
int main()
{
// 使用列表初始化语法创建 MyArray 对象
MyArray arr = { 10, 20, 30 }; // 等价于调用 MyArray({10, 20, 30})
arr.print();
return 0;
}
在这里插入图片描述
6. 为什么要引入initializer_list?
C++11 initializer_list:容器批量初始化的解决方案
问题背景:容器初始化的痛点
虽然 C++ 列表初始化({})让语法更简洁,但早期直接用 {} 初始化容器(如:vector )仍有不便
如果想让容器支持 “任意数量值的初始化”,需要为容器写大量构造函数适配不同元素个数,比如:
vector<int> v1 = {1,2,3}; // 需支持 3 个元素的构造
vector<int> v2 = {1,2,3,4}; // 又需支持 4 个元素的构造这种方式显然不灵活,也无法适配动态数量的初始化需求。
解决方案:std::initializer_list
为统一容器的批量初始化,C++11 引入 std::initializer_list 类。它的本质是:
- 底层自动创建一个临时数组,存储
{}中的数据 - 内部通过两个指针(或迭代器)标记数组的 “起始” 和 “结束” 位置,方便遍历
代码示例
#include<iostream>
#include<string>
#include<vector>
#include<map>
using namespace std;
int main()
{
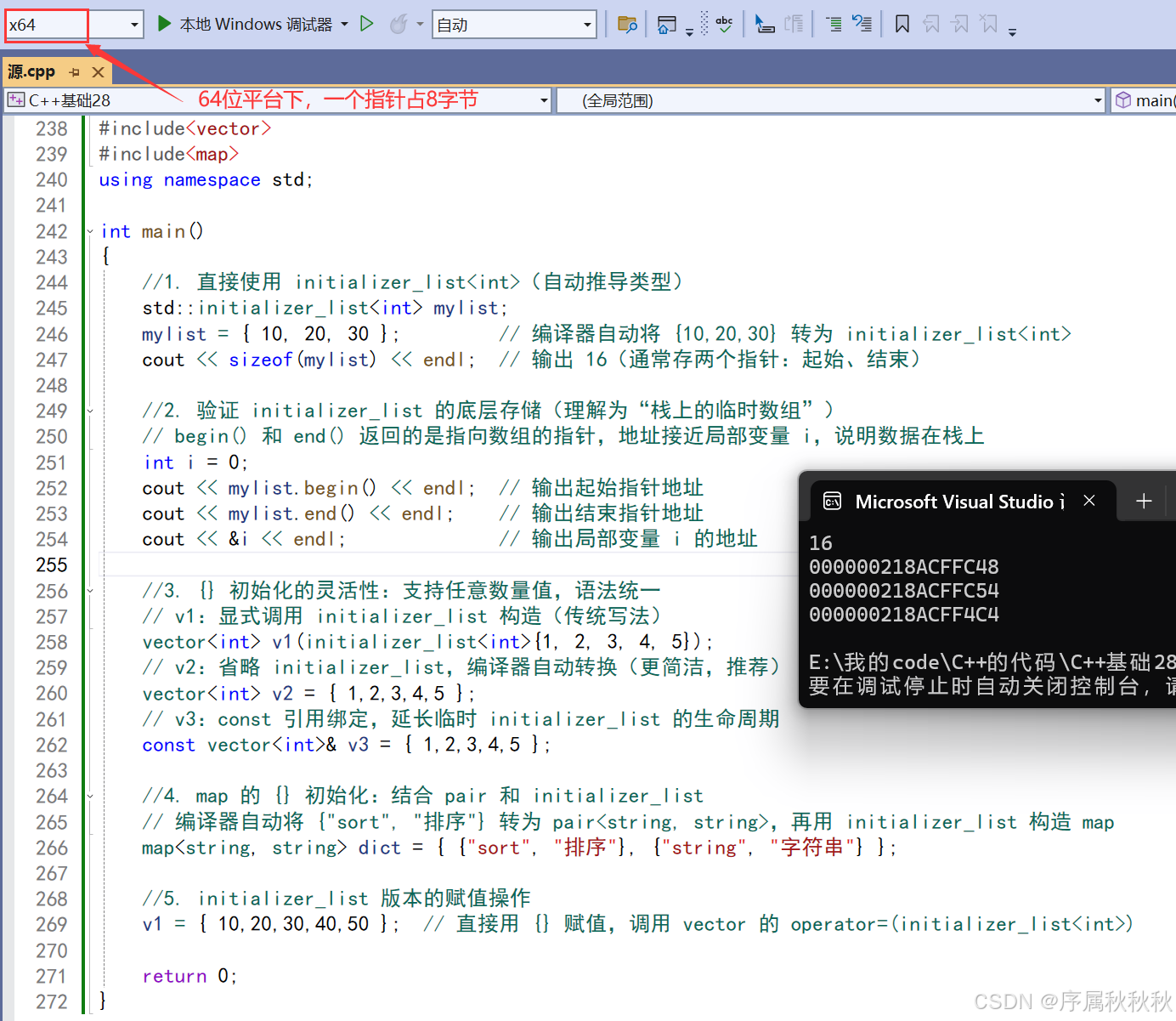
//1. 直接使用 initializer_list<int>(自动推导类型)
std::initializer_list<int> mylist;
mylist = { 10, 20, 30 }; // 编译器自动将 {10,20,30} 转为 initializer_list<int>
cout << sizeof(mylist) << endl; // 输出 16(通常存两个指针:起始、结束)
//2. 验证 initializer_list 的底层存储(理解为“栈上的临时数组”)
// begin() 和 end() 返回的是指向数组的指针,地址接近局部变量 i,说明数据在栈上
int i = 0;
cout << mylist.begin() << endl; // 输出起始指针地址
cout << mylist.end() << endl; // 输出结束指针地址
cout << &i << endl; // 输出局部变量 i 的地址
//3. {} 初始化的灵活性:支持任意数量值,语法统一
// v1:显式调用 initializer_list 构造(传统写法)
vector<int> v1(initializer_list<int>{1, 2, 3, 4, 5});
// v2:省略 initializer_list,编译器自动转换(更简洁,推荐)
vector<int> v2 = { 1,2,3,4,5 };
// v3:const 引用绑定,延长临时 initializer_list 的生命周期
const vector<int>& v3 = { 1,2,3,4,5 };
//4. map 的 {} 初始化:结合 pair 和 initializer_list
// 编译器自动将 {"sort", "排序"} 转为 pair<string, string>,再用 initializer_list 构造 map
map<string, string> dict = { {"sort", "排序"}, {"string", "字符串"} };
//5. initializer_list 版本的赋值操作
v1 = { 10,20,30,40,50 }; // 直接用 {} 赋值,调用 vector 的 operator=(initializer_list<int>)
return 0;
}
在这里插入图片描述
7. 列表初始化的底层原理是什么?
列表初始化的底层原理: 列表初始化本质上是通过调用构造函数来完成对象的初始化。
STL 容器(如 vector、list、map 等 )通过新增 initializer_list 构造函数,实现了 “用 {x1,x2,x3...} 直接初始化”,当写 vector<int> v = {1,2,3}; 时:
- 编译器自动将
{1,2,3}转换为initializer_list<int>对象 - 调用
vector的initializer_list构造函数,批量初始化容器元素
这样,无论 {} 里有多少个值,容器都能通过同一个构造函数处理,无需为不同元素数量写多个构造函数。
简单总结:
-
std::initializer_list是 C++11 为解决 “容器批量初始化” 设计的语法糖 - 通过自动转换
{}为临时数组,让容器只需一个构造函数,就能适配任意数量值的初始化需求,极大简化了 STL 容器的使用,也让代码更简洁统一
#include <initializer_list>
class MyClass
{
public:
MyClass(std::initializer_list<int> list)
{
for (auto it = list.begin(); it != list.end(); ++it)
{
// 处理列表中的元素
}
}
};
MyClass obj = {1, 2, 3}; // 调用MyClass(std::initializer_list<int>)构造函数总之: C++ 中的列表初始化提供了一种
简洁、安全且统一的初始化方式,在日常编程中合理使用它,可以让代码更加清晰、易读和健壮。
8. 列表初始化的使用大总结
#include<iostream>
#include<vector>
using namespace std;
// 定义一个结构体 Point,用于表示简单的二维点坐标
struct Point
{
int _x;
int _y;
};
// 定义一个类 Date,用于表示日期
class Date
{
public:
// 日期类的构造函数,带默认参数,若创建对象时不传入参数,将使用默认值(年、月、日都为 1)
Date(int year = 1, int month = 1, int day = 1)
// 使用成员初始化列表初始化类的成员变量
: _year(year)
, _month(month)
, _day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
// 日期类的拷贝构造函数,用于根据已有的 Date 对象创建新的 Date 对象
Date(const Date& d)
// 使用成员初始化列表,用传入的对象 d 的成员变量来初始化当前对象的成员变量
: _year(d._year)
, _month(d._month)
, _day(d._day)
{
cout << "Date(const Date& d)" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
// ------ C++98 支持的初始化方式 ------
int a1[] = { 1, 2, 3, 4, 5 };
int a2[5] = { 0 };
Point p = { 1, 2 };
// ------ C++11 支持的初始化方式 ------
// 内置类型支持 C++11 的列表初始化(可省略等号)
int x1 = { 2 };
// 自定义类型支持 C++11 的列表初始化
cout << "\n-----------Date d1 = { 2025, 1, 1 };-----------" << endl;
Date d1 = { 2025, 7, 25 };
/* 注意事项:
* 这里本质是用 { 2025, 1, 1 } 构造一个 Date 临时对象,
* 临时对象再去拷贝构造 d1,不过编译器通常会优化,直接用 { 2025, 1, 1 } 直接构造初始化 d1
*/
cout << "-----------const Date& d2 = { 2025, 7, 25 };-----------" << endl;
const Date& d2 = { 2025, 7, 25 };
/* 注意事项:
* 这里 d2 引用的是用 { 2025, 7, 25 } 构造的临时对象
* 因为是 const 引用,延长了临时对象的生命周期
*/
// C++98 支持单参数构造函数的类型转换(隐式转换)
cout << "\n-----------Date d3 = { 2025 };-----------" << endl;
Date d3 = { 2025 }; //这里用 {2025} 构造 Date 对象 d3,调用的是带默认参数的构造函数(month 和 day 用默认值 1)
cout << "-----------Date d4 = 2025;-----------" << endl;
Date d4 = 2025; //直接用整数 2025 创建 Date 对象 d4,同样 month 和 day 用默认值 1
// 可以省略等号的列表初始化方式(C++11 特性)
Point p1{ 1, 2 };
int x2{ 2 };
cout << "\n-----------Date d5{ 2025, 7, 25 };-----------" << endl;
Date d5{ 2025, 7, 25 };
cout << "-----------const Date& d6{ 2025, 7, 25 };-----------" << endl;
const Date& d6{ 2025, 7, 25 };
// 不支持的情况,只有列表初始化(用 {} )时,才能省略等号,这种直接赋值的方式不符合列表初始化规则,会编译报错
// Date d7 2025;
/*------------创建一个存储 Date 对象的 vector 容器 v------------*/
//1.创建vector容器
vector<Date> v;
//2.预先预留足够空间(比如:要插入 3 个元素,就预留 3)
v.reserve(3);
/*------------将Date类型的对象添加到 vector 容器 v------------*/
//1.将有名Date对象 d8 拷贝后添加到 vector 中
cout << "\n将有名Date对象 d1 拷贝后添加到 vector 中" << endl;
const Date& d8{ 2025, 1, 1 };
v.push_back(d8);
//2.将匿名Date对象(2025, 1, 1)添加到 vector 中
cout << "\n将匿名Date对象(2025, 1, 1)添加到 vector 中" << endl;
v.push_back(Date(2025, 1, 1));
/* 注意事项:
* vector::push_back 的本质是 “把对象拷贝(或移动)到容器内部”
* 即使传入的是临时对象,也会先构造临时对象,再拷贝到容器里(编译器可能优化,但基础逻辑要理解)
*/
//3.比起有名对象和匿名对象传参,用列表初始化直接构造临时对象添加到 vector 中,写法更简洁,更有性价比
cout << "\n用列表初始化直接构造临时对象添加到 vector 中" << endl;
v.push_back({ 2025, 1, 1 });
return 0;
}
在这里插入图片描述
------------右值引用------------
1. 什么是左值和右值?
在 C++ 中,左值(lvalue)和右值(rvalue)是对表达式的一种分类,它们描述了表达式的值特性、生命周期及可操作性
左值:是指表达式结束后依然存在的持久对象, 可以理解为有内存空间、有明确存储地址的对象。
左值可以出现在赋值运算符的左边(这也是 “左值” 名称的由来,但不是绝对的,比如 const 左值就不能被赋值 )
具有标识性,即有一个确定的存储位置,可以通过地址访问(可通过 & 取地址)
在程序执行过程中,其生命周期相对较长,直到超出作用域或者被显式销毁
常见的左值包括变量、数组元素、结构体成员等
int num = 10; // num 是左值,它在内存中有固定的存储位置
int arr[5];
arr[2] = 3; // arr[2] 是左值,代表数组中特定位置的元素
struct Point
{
int x;
int y;
};
Point p;
p.x = 5; // p.x 是左值,是结构体成员右值:是指表达式结束后就不再存在的临时对象。
右值只能出现在赋值语句的右侧
通常无名字,没有持久的内存地址(不可用 & 取地址)
生命周期短暂仅限于当前表达式,在表达式结束后就会被销毁
右值可以是字面常量(例如:10、"hello" 等)、函数的临时返回值、表达式的中间结果等
int a = 5 + 3; // 5 + 3 是右值,计算出结果后,这个临时的加法结果在表达式结束后就不再存在
int func()
{
return 20; // 返回值 20 是右值,函数返回后,这个临时值不再独立存在
}
int b = func(); 代码案例:左值和右值的种类有哪些?
#include<iostream>
using namespace std;
int main()
{
// ================ 左值(lvalue):可寻址、持久存在 ================
// 以下的 p、b、c、*p、s、s[0] 都是左值示例
//1. 指针 p 是左值(存储在栈上,有地址)
int* p = new int(0); // p 指向堆上的 int(值为 0)
//2. 普通变量 b 是左值(存储在栈上,可修改)
int b = 1;
//3. const 修饰的变量 c 是左值(虽不可修改,但仍可寻址)
const int c = b;
//4. 解引用指针 *p 是左值(可修改堆上的值)
*p = 10; // 修改堆上 int 的值为 10
//5. 字符串 s 是左值(std::string 对象,存储在栈上,内容在堆)
string s("111111");
//6. 数组元素 s[0] 是左值(可修改字符串的第一个字符)
s[0] = 'x'; // 字符串变为 "x11111"
// 验证左值可寻址:输出地址
cout << &c << endl; // 输出 const 左值 c 的地址
cout << (void*)&s[0] << endl;// 输出字符串首字符的地址(s[0] 是左值)
// ================ 右值(rvalue):不可寻址、临时存在 ================
// 以下的 10、x+y、fmin(x,y)、string("11111") 都是右值示例
// 1. 字面量 10 是右值(临时值,无地址)
10;
// 2. 表达式 x + y 是右值(临时结果,无地址)
x + y;
// 3. 函数返回值 fmin(x,y) 是右值(临时结果,无地址)
fmin(x, y);
// 4. 临时对象 string("11111") 是右值(表达式结束后销毁)
string("11111");
// 尝试取右值地址(编译报错或行为未定义)
cout << &10 << endl; // 非法:字面量右值不可寻址
cout << &(x+y) << endl; // 非法:表达式右值不可寻址
cout << &fmin(x, y) << endl; // 非法:函数返回值右值不可寻址
cout << &string("11111") << endl; // 非法:临时对象右值不可寻址
return 0;
}
在这里插入图片描述
2. 左值与右值的核心区别与本质是什么?
左值/右值名称的起源与现代解释:
- 传统含义:
- lvalue 是
“left value”缩写(左值) - rvalue 是
“right value”缩写(右值),对应赋值符号左右的位置
- lvalue 是
- 现代解释:
- lvalue 被重新解释为
“locator value”(可定位值 ):强调“可寻址、有持久存储” - rvalue 被重新解释为
“read value”(可读值 ):强调“仅提供数据值,不可寻址”
- lvalue 被重新解释为
核心区别:能否取地址(左值可寻址,右值不可寻址 )
-
左值(lvalue):可寻址的 “持久对象” -
右值(rvalue):不可寻址的 “临时数据”
左值与右值的关键对比:
特征 | 左值(lvalue) | 右值(rvalue) |
|---|---|---|
存储位置 | 内存中(有明确地址) | 临时存储(如:寄存器、栈上临时空间) |
可寻址性 | 是(& 合法) | 否(& 非法) |
生命周期 | 持久(作用域内有效) | 短暂(表达式结束后销毁) |
赋值位置 | 可在赋值符号左 / 右边 | 仅可在赋值符号右边 |
典型例子 | 变量名、*p(解引用指针) | 字面量、表达式临时结果 |
总结: 理解左值 “可寻址、持久” 和右值 “不可寻址、临时” 的核心区别,就能清晰区分两者 —— 这是后续学习移动语义、完美转发的基础!
3. 什么是左值引用/右值引用?
在 C++ 中,左值引用和右值引用是两种不同类型的引用,它们的核心区别在于绑定对象的类型(左值或右值)
理解这两种引用是掌握 C++11 移动语义、完美转发等高级特性的基础。
左值引用(Lvalue Reference):左值引用是对左值的引用,使用 & 声明。
核心规则:
只能绑定左值(如:变量、数组元素等可寻址 的对象)不能直接绑定右值(但const左值引用可以绑定右值)
代码示例:
int x = 10; // x 是左值
int& ref = x; // 左值引用 ref 绑定到左值 x
ref = 20; // 修改 ref 会影响 x(x 变为 20)
// int& invalid_ref = 10; // 错误:左值引用不能直接绑定右值(字面量 10 是右值)
const int& const_ref = 10; // 合法:const 左值引用可以绑定右值(延长右值生命周期)const 左值引用的特殊之处:
const左值引用可以绑定右值,常用于函数参数中接收临时对象(避免拷贝)
void func(const int& value) { /* ... */ }
func(10); // 合法:右值 10 被 const 左值引用接收右值引用(Rvalue Reference):是对右值的引用,使用 && 声明。
核心规则:
只能绑定右值(如:字面量、临时对象、表达式结果等)不能直接绑定左值(但可通过 std::move 将左值转为右值引用)
代码示例:
int&& rref = 10; // 右值引用 rref 绑定到右值 10
rref = 20; // 可修改右值引用(10 变为 20)
int x = 10;
// int&& invalid_rref = x; // 错误:右值引用不能直接绑定左值 x
int&& valid_rref = std::move(x); // 合法:通过 std::move 将左值转为右值引用std::move 的作用:
std::move 是标准库的函数模板,定义简化如下:
template <class T>
typename remove_reference<T>::type&& move (T&& arg)
{
// 强制类型转换:将 arg 转为右值引用返回
return static_cast<typename remove_reference<T>::type&&>(arg);
}std::move 的本质是强制类型转换,将左值转为右值引用,允许右值引用绑定左值
注意:move 本身不移动数据,只是 “允许右值引用绑定”,真正的移动语义由移动构造 / 赋值函数实现
4. 左值引用与右值引用的区别是什么?
左值引用和右值引用核心区别对比:
特征 | 左值引用 (&) | 右值引用 (&&) |
|---|---|---|
绑定对象 | 左值(如:变量、数组元素) | 右值(如:字面量、临时对象) |
能否修改 | 可修改(非 const 时) | 可修改 |
生命周期 | 延长绑定对象的生命周期 | 延长右值的生命周期 |
典型用途 | 函数参数(避免拷贝) | 移动语义、完美转发 |
特殊语法 | const & 可绑定右值 | std::move 转换左值为右值 |
5. 关于右值引用需要注意什么?
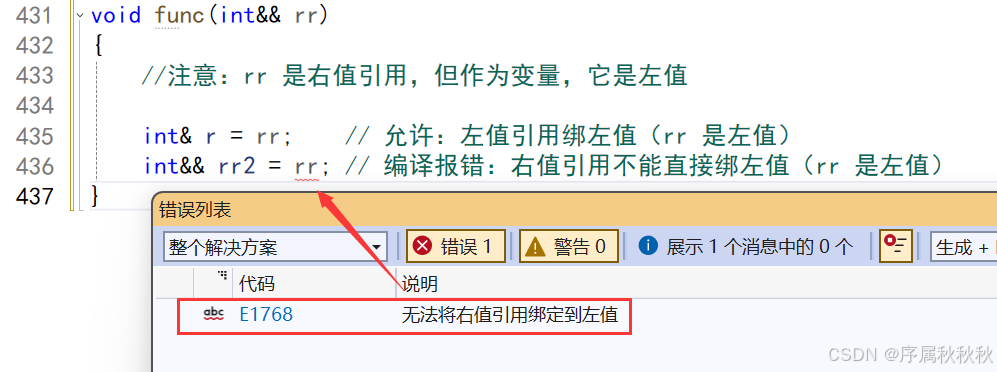
右值引用的 “左值属性” 陷阱:右值引用变量本身是左值!
void func(int&& rr)
{
//注意:rr 是右值引用,但作为变量,它是左值
int& r = rr; // 允许:左值引用绑左值(rr 是左值)
int&& rr2 = rr; // 编译报错:右值引用不能直接绑左值(rr 是左值)
//注意:变量有 “存储地址”(左值特征),即使它是右值引用类型。
}
在这里插入图片描述
代码案例:左引用和右值引用的使用
#include<iostream>
using namespace std;
int main()
{
// ================ 左值:可寻址的持久对象 ================
int* p = new int(0); // p 是左值(指针变量,存储在栈)
int b = 1; // b 是左值(普通变量,存储在栈)
const int c = b; // c 是左值(const 变量,虽不可修改,但可寻址)
*p = 10; // *p 是左值(解引用指针,修改堆内存)
string s("111111"); // s 是左值(std::string 对象,存储在栈)
s[0] = 'x'; // s[0] 是左值(数组元素,可修改字符串内容)
double x = 1.1, y = 2.2; // x、y 是左值
// ================ 左值引用:给左值取别名 ================
// 左值引用特征:只能绑定左值(非 const 时),修改引用会影响原对象
int& r1 = b; // r1 是左值引用,绑定左值 b
int*& r2 = p; // r2 是左值引用(指针的引用),绑定左值 p
int& r3 = *p; // r3 是左值引用,绑定左值 *p
string& r4 = s; // r4 是左值引用,绑定左值 s
// char& r5 = s[0]; // 注意:s[0] 是 char(值类型),这里会编译报错!
// 正确写法:若要绑定 s[0],需用 const 或值拷贝
char r5 = s[0]; // 改为值拷贝(s[0] 是 char,不是左值引用的合法目标)
// ================ 右值引用:给右值取别名 ================
int&& rr1 = 10; // rr1 是右值引用,绑定右值 10(字面量)
double&& rr2 = x + y; // rr2 是右值引用,绑定右值 x+y(表达式结果)
double&& rr3 = fmin(x, y); // rr3 是右值引用,绑定右值 fmin 返回值
string&& rr4 = string("11111"); // rr4 是右值引用,绑定右值临时对象
// ================ 左值引用的特殊规则 ================
// const 左值引用可以绑定右值(延长右值生命周期)
const int& rx1 = 10; // 合法:const 左值引用绑定右值 10
const double& rx2 = x + y; // 合法:const 左值引用绑定右值 x+y
const double& rx3 = fmin(x, y); // 合法:const 左值引用绑定右值 fmin 返回值
const string& rx4 = string("11111"); // 合法:const 左值引用绑定右值临时对象
// ================ 右值引用的特殊规则 ================
// 右值引用不能直接绑定左值,但可通过 std::move 转换左值为右值引用
int&& rrx1 = std::move(b); // 合法:std::move(b) 将左值 b 转为右值引用
int*&& rrx2 = std::move(p); // 合法:std::move(p) 将左值 p 转为右值引用
int&& rrx3 = std::move(*p); // 合法:std::move(*p) 将左值 *p 转为右值引用
string&& rrx4 = std::move(s); // 合法:std::move(s) 将左值 s 转为右值引用
// 以下写法等价于 std::move(s)(C++11 支持直接强转右值引用)
string&& rrx5 = (string&&)s;
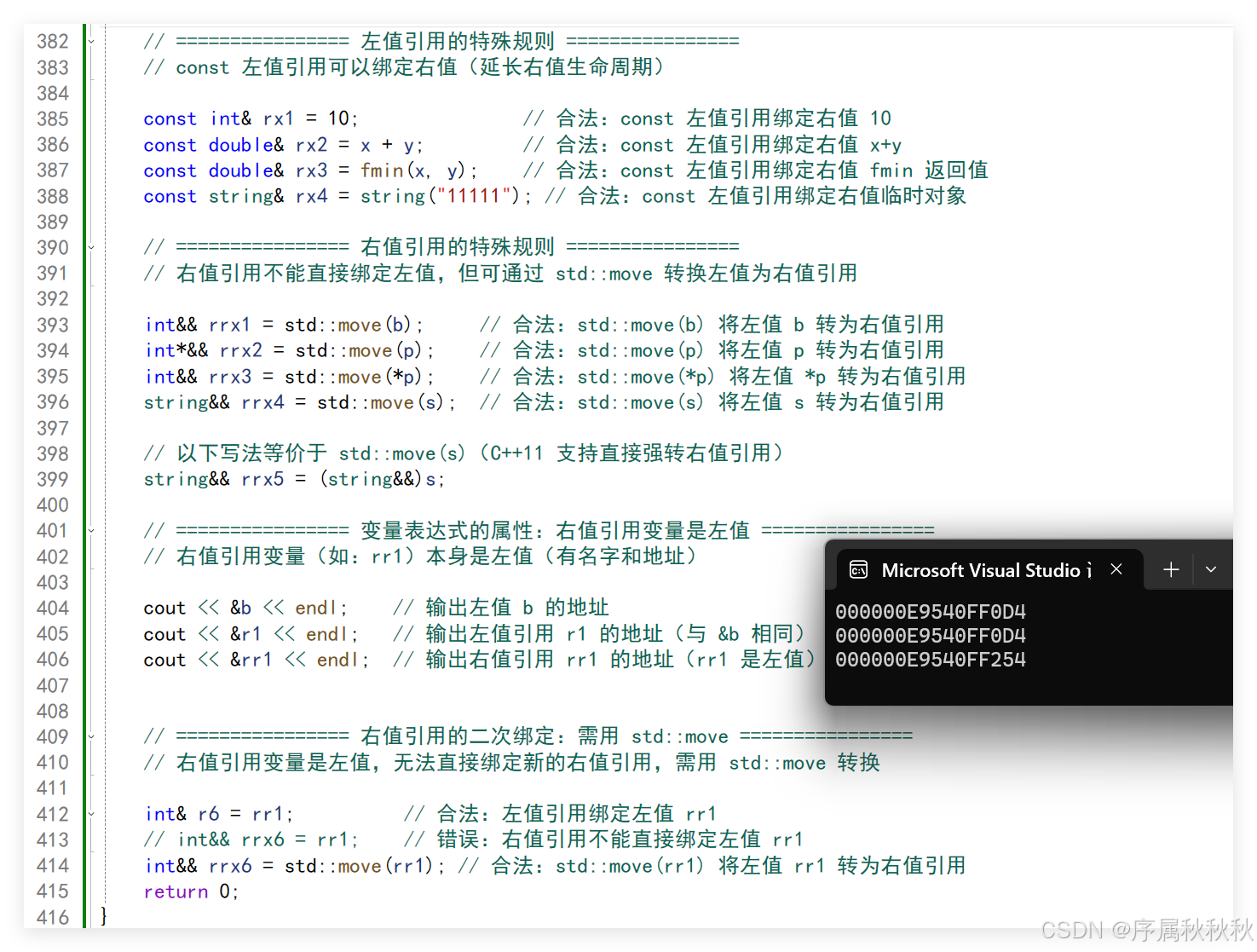
// ================ 变量表达式的属性:右值引用变量是左值 ================
// 右值引用变量(如:rr1)本身是左值(有名字和地址)
cout << &b << endl; // 输出左值 b 的地址
cout << &r1 << endl; // 输出左值引用 r1 的地址(与 &b 相同)
cout << &rr1 << endl; // 输出右值引用 rr1 的地址(rr1 是左值)
// ================ 右值引用的二次绑定:需用 std::move ================
// 右值引用变量是左值,无法直接绑定新的右值引用,需用 std::move 转换
int& r6 = rr1; // 合法:左值引用绑定左值 rr1
// int&& rrx6 = rr1; // 错误:右值引用不能直接绑定左值 rr1
int&& rrx6 = std::move(rr1); // 合法:std::move(rr1) 将左值 rr1 转为右值引用
return 0;
}
在这里插入图片描述
简单总结:
- 左值引用、右值引用是 C++ 为 “区分对象属性(左值 / 右值)” 设计的语法,核心规则是 “谁能绑谁”
std::move是 “打破绑定限制” 的工具- 同时要注意右值引用变量本身是左值的陷阱
6. 怎么使用引用延长对象的生命周期?
const左值引用和右值引用对临时对象生命周期的影响:
const左值引用能延长临时对象生存期;右值引用也可用于为临时对象延长生命周期- 但
const左值引用场景下的这些对象无法被修改;而右值引用绑定的临时对象,若引用本身非const,则可修改其值
#include <iostream>
#include <string>
using namespace std;
int main()
{
// 1. 定义左值对象 s1
std::string s1 = "Test";
// 2. 右值引用直接绑定左值(错误演示)
// std::string&& r1 = s1;
/* 注意事项:
* 错误原因:右值引用(&&)的设计初衷是绑定右值(临时对象)
* 直接绑定左值 s1 会编译报错,需用 std::move 转换左值为右值引用
*/
/*--------------------“const左值引用”绑定临时对象(延长生命周期)--------------------*/
const std::string& r2 = s1 + s1;
/* 注意事项:
* 原理:s1 + s1 是表达式产生的临时对象(右值)
* const左值引用可以绑定右值,并且会延长该临时对象的生命周期
* 使其在 r2 的作用域内持续存在
*/
// r2 += "Test";
// 错误原因:r2 是 const 左值引用,被 const 修饰的引用无法修改绑定对象的值。
/*--------------------“右值引用”绑定临时对象(延长生命周期)--------------------*/
std::string&& r3 = s1 + s1;
/* 注意事项:
* 原理:右值引用(&&)直接绑定临时对象(s1 + s1 的结果)
* 同样会延长临时对象的生命周期,且右值引用本身未被 const 修饰时
* 可以修改绑定对象的值
*/
r3 += "Test"; //通过右值引用修改临时对象
// 合法操作:r3 是非 const 的右值引用,可修改绑定的临时对象内容,这里会将 "Test" 追加到临时对象中。
std::cout << r3 << '\n'; //输出修改后的结果(s1 + s1 是 "TestTest",再追加 "Test" 后变为 "TestTestTest")
return 0;
}
在这里插入图片描述
关键逻辑总结:
- 临时对象的产生:
s1 + s1会生成一个临时的std::string对象(右值),表达式结束后,若未被引用绑定,临时对象会立即销毁 - const 左值引用的作用:
const std::string& r2绑定临时对象后,延长了临时对象的生命周期(与r2作用域一致),但因const限制,无法修改对象内容 - 右值引用的作用:
std::string&& r3绑定临时对象后,同样延长生命周期,且由于引用本身非const,可通过引用修改临时对象的值 - 右值引用的核心价值:既保留了 “延长临时对象生命周期” 的能力,又突破了const限制,支持修改操作,这对实现移动语义(避免深拷贝、转移资源)非常关键
通过这种方式,C++ 允许开发者灵活控制临时对象的生命周期,平衡 “资源高效利用” 和 “语法安全性” 的需求~
7. 左值和右值的参数怎么进行匹配?
在 C++ 中,左值引用和右值引用的函数重载规则,会直接影响实参(左值 / 右值)与形参的匹配逻辑。
C++98 的兼容设计:
在 C++98 中,const左值引用 是一种 “万能引用”:
- 它既可以接收左值(如:变量、对象),也可以接收右值(如:字面量、临时对象)
- 本质是为了兼容旧代码,让
const T&成为一种通用的参数类型
C++11 的精确匹配(左值 / 右值区分) C++11 引入右值引用后,函数重载可以更精确地区分实参类型:
- 实参是
普通左值→ 匹配非const 左值引用(T&) - 实参是
const左值→ 匹配const左值引用(const T&) - 实参是
右值(或被std::move转换的左值) → 匹配右值引用(T&&)
注意:右值引用的 “左值属性” 陷阱 —> 右值引用变量本身是左值!
- 当右值引用变量参与表达式时,它的属性是左值,会匹配左值引用重载
- 这个设计看似 “反直觉”,但在移动语义、完美转发中能发挥关键作用
#include<iostream>
using namespace std;
// 1. “非const左值引用”重载
// 匹配规则:接收普通左值(可修改的左值)
void f(int& x)
{
std::cout << "左值引用重载 f(" << x << ")\n";
}
// 2. “const左值引用”重载
// 匹配规则:接收 const左值(只读的左值)
void f(const int& x)
{
std::cout << "const左值引用重载 f(" << x << ")\n";
}
// 3. “右值引用”重载
// 匹配规则:接收右值(临时对象、字面量,或被 std::move 转换的左值)
void f(int&& x)
{
std::cout << "右值引用重载 f(" << x << ")\n";
}
int main()
{
// 定义普通左值和 const左值
int i = 1; // 普通左值(可修改)
const int ci = 2; // const 左值(只读)
// ================ 实参匹配测试 ================
f(i); // 实参是【普通左值】→ 匹配 f(int&)
f(ci); // 实参是【const左值】→ 匹配 f(const int&)
f(3); // 实参是【右值】→ 匹配 f(int&&)
// 若没有 f(int&&),则会匹配 f(const int&)(C++98 兼容逻辑)
f(std::move(i)); // 实参是【被 move 转换的左值(逻辑上变为右值)】→ 匹配 f(int&&)
// ================ 右值引用的“左值属性”测试 ================
int&& x = 1; // x 是【右值引用变量】,但本身是左值(有名字、可寻址)
f(x); // 实参是【左值(右值引用变量)】→ 匹配 f(int&)
f(std::move(x)); // 实参是【被 move 转换的右值引用变量(逻辑上变为右值)】→ 匹配 f(int&&)
return 0;
}
在这里插入图片描述
核心结论:
- 精确匹配规则:
-
普通左值→T& -
const左值→const T& -
右值(或std::move 转换的左值) →T&&
-
- 右值引用的 “左值属性”:
右值引用变量是左值,需通过
std::move再次转换为右值 - C++98 兼容逻辑:
若没有
T&&重载,右值会匹配const T&,保证旧代码可运行
理解这些规则,才能正确使用移动语义和完美转发,写出高效且符合预期的 C++ 代码~
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-09-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号