《C++进阶之STL》【unordered_set/unordered_map 使用介绍】

《C++进阶之STL》【unordered_set/unordered_map 使用介绍】

序属秋秋秋
发布于 2025-12-18 16:12:48
发布于 2025-12-18 16:12:48
【unordered_set/unordered_map 使用介绍】目
往期《C++初阶》回顾:《C++初阶》目录导航
往期《C++进阶》回顾:
/------------ 继承多态 ------------/
【普通类/模板类的继承 + 父类&子类的转换 + 继承的作用域 + 子类的默认成员函数】
【final + 继承与友元 + 继承与静态成员 + 继承模型 + 继承和组合】
【多态:概念 + 实现 + 拓展 + 原理】
/------------ STL ------------/
【二叉搜索树】
【AVL树】
【红黑树】
【set/map 使用介绍】
【set/map 模拟实现】
【哈希表】
前言
hi~,小伙伴们大家好啊!昨天下午有事没写博客,今天中午之前鼠鼠一定要将这篇博客发出去,还愣着干嘛,快上车啊!!🚗💨(╯°□°)╯︵ ┻━┻
今天我们学习的内容是(☞゚ヮ゚)☞ 【unordered_set/unordered_map 使用介绍】,内容相对要简单一点——简单到就像点外卖:不用排队、不用排序,直接“哈希”一下,嗖地就把数据送到你面前!(≧ڡ≦*)ゞ 还记得我们之前手撕红黑树、旋转到头晕的悲壮历史吗?现在终于可以扔掉“平衡”这根拐杖,投奔 O(1) 的怀抱啦~(╯✧∇✧)╯ unordered 家族主打一个“佛系无序”,只要键值对得上,立刻给你安排座位,绝不拖泥带水!Let’s go !♪(´▽`)
------------unordered_set------------
一、介绍
cplusplus网站上关于C++的
unordered_set容器的介绍:unordered_set - C++ 参考资料
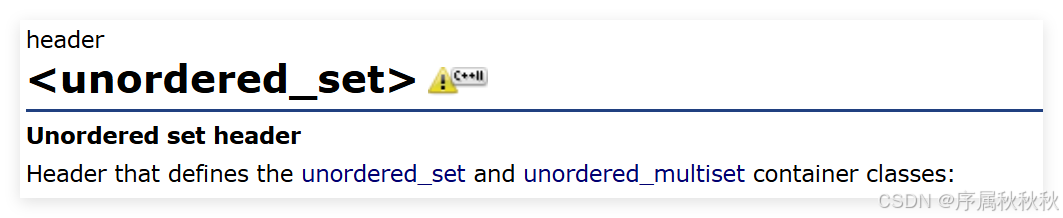
在这里插入图片描述

在这里插入图片描述

在这里插入图片描述
template <
class Key, // unordered_set::key_type/value_type
class Hash = hash<Key>, // unordered_set::hasher
class Pred = equal_to<Key>, // unordered_set::key_equal
class Alloc = allocator<Key> // unordered_set::allocator_type
> class unordered_set;
template<
class Key, // 关键字类型(底层存储的关键值类型)
class Hash = hash<Key>, // 哈希函数(默认用标准库 hash<Key> )
class Pred = equal_to<Key>, // 相等比较规则(默认用 == 比较)
class Alloc = allocator<Key> // 内存分配器(默认用标准分配器)
> class unordered_set;关于 C++ STL 中 unordered_set 容器的模板参数说明:
键类型(Key):unordered_set 中存储的键的类型。
哈希函数(Hash,默认 hash<Key>):用于计算键的哈希值。
相等比较器(Pred,默认 equal_to<Key>):用于判断两个键是否相等。
内存分配器(Alloc,默认 allocator<Key>):负责管理unordered_set的内存分配与释放。
若需针对特定内存管理需求(如:自定义内存分配策略),可自定义分配器。
unordered_set<Key, MyHash<Key>, MyEqual<Key>, MyAllocator<Key>> myUnorderedSet; // 使用自定义哈希、比较器和分配器C++ 标准模板库(STL)中的
unordered_set容器相关内容,主要可以分为以下两个部分:
- 成员函数:提供了 unordered_set 容器的 各类操作接口
- 涵盖
对象构造与销毁、容量查询、迭代器获取、元素查找、元素修改、桶操作、哈希策略控制、分配器获取等功能。
- 涵盖
- 非成员函数重载:对一些操作符和通用函数进行了重载
- 用于支持 unordered_set 容器间的
关系比较、内容交换等操作。
- 用于支持 unordered_set 容器间的
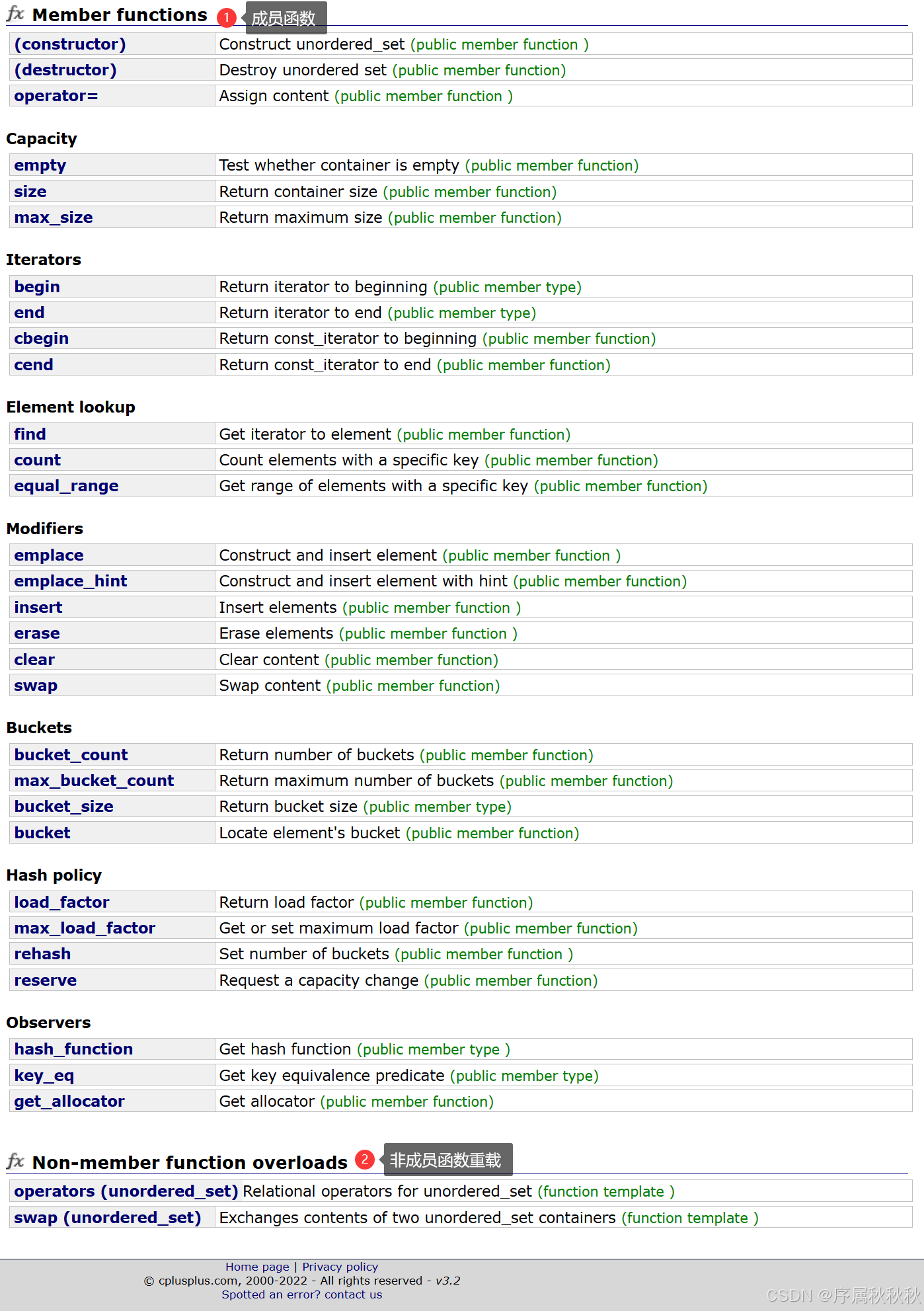
在这里插入图片描述
二、接口
1. 常见的构造
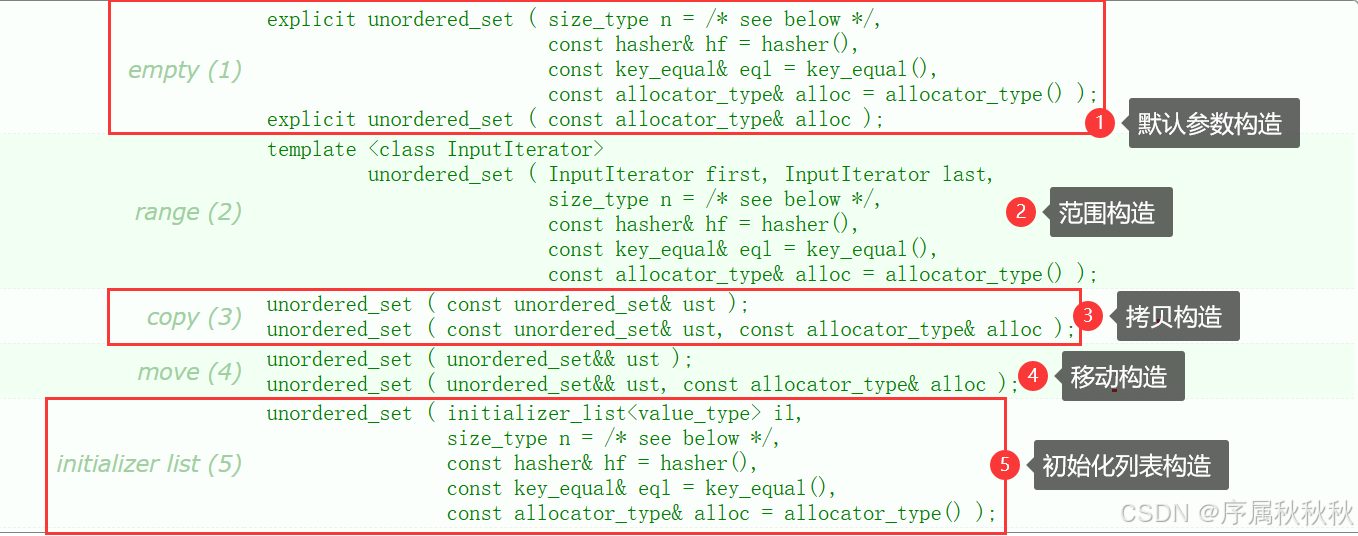
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
//定义一个模板函数cmerge,用于合并两个同类型的容器
template<class T> //模板参数T代表容器类型,需支持插入操作和迭代器
T cmerge(T a, T b)
{
//1.用容器a的内容初始化新容器t(拷贝构造)
T t(a);
//2.将容器b的所有元素插入到t中
t.insert(b.begin(), b.end());
//3.返回合并后的容器t
return t;
}
int main()
{
/*------------------------ 默认构造函数 ------------------------*/
//1.默认构造函数:创建一个空的unordered_set,存储string类型
std::unordered_set<std::string> first;
/*------------------------ 初始化列表构造 ------------------------*/
//2.初始化列表构造:使用初始化列表中的元素创建unordered_set
std::unordered_set<std::string> second({ "red","green","blue" });
//3.初始化列表构造:创建另一个包含不同颜色的unordered_set
std::unordered_set<std::string> third({ "orange","pink","yellow" });
/*------------------------ 拷贝构造函数 ------------------------*/
//4.拷贝构造函数:通过拷贝second的内容创建fourth
std::unordered_set<std::string> fourth(second);
/*------------------------ 移动构造函数 ------------------------*/
//5.移动构造函数:通过移动cmerge的返回值创建fifth
std::unordered_set<std::string> fifth(cmerge(third, fourth)); //
/* 注意:
* 1. cmerge函数合并了third和fourth的内容,返回一个临时容器
* 2. 这里使用移动构造而非拷贝构造,提高效率
*/
/*------------------------ 范围构造函数 ------------------------*/
//6.范围构造函数:通过迭代器范围[fifth.begin(), fifth.end())中的元素创建sixth
std::unordered_set<std::string> sixth(fifth.begin(), fifth.end());
// 输出sixth容器中的所有元素
std::cout << "sixth contains:";
for (const std::string& x : sixth) //范围for循环遍历sixth中的每个元素(注意:unordered_set中的元素无序)
{
std::cout << " " << x;
}
std::cout << std::endl;
return 0;
}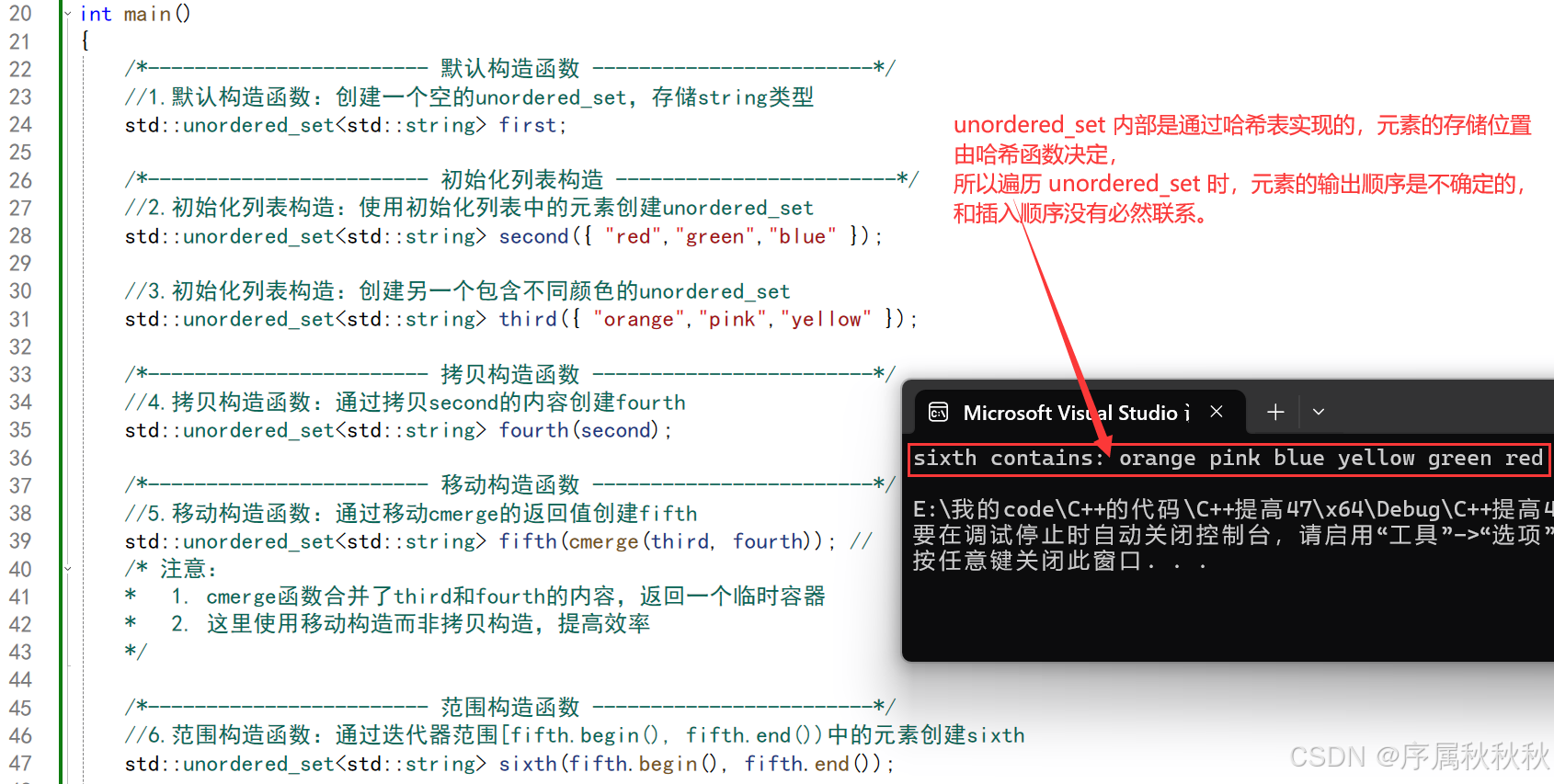
在这里插入图片描述
2. 容量的操作
std::unordered_set::size

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
//1.创建一个存储string类型的空unordered_set容器
std::unordered_set<std::string> myset;
//2.调用size()函数:返回容器中当前元素的数量
std::cout << "0. size: " << myset.size() << std::endl;
//3.用初始化列表给容器赋值,包含3个元素:"milk","potatoes","eggs"
myset = { "milk","potatoes","eggs" };
std::cout << "向容器中插入3个元素:size: " << myset.size() << std::endl;
//4.向容器中插入一个新元素"pineapple"
myset.insert("pineapple");
std::cout << "再插入1个元素到容器:size: " << myset.size() << std::endl;
//5.从容器中删除元素"milk"
myset.erase("milk");
std::cout << "从容器中删除1个元素:size: " << myset.size() << std::endl;
return 0;
}
在这里插入图片描述
std::unordered_set::empty
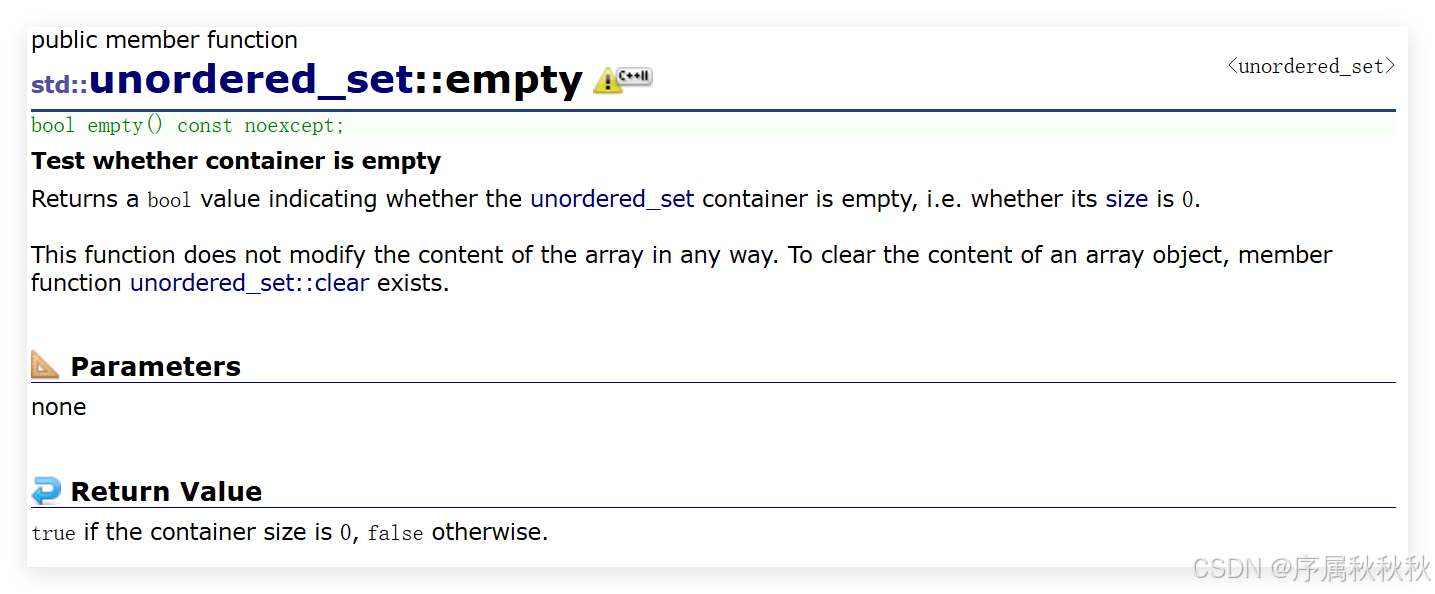
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
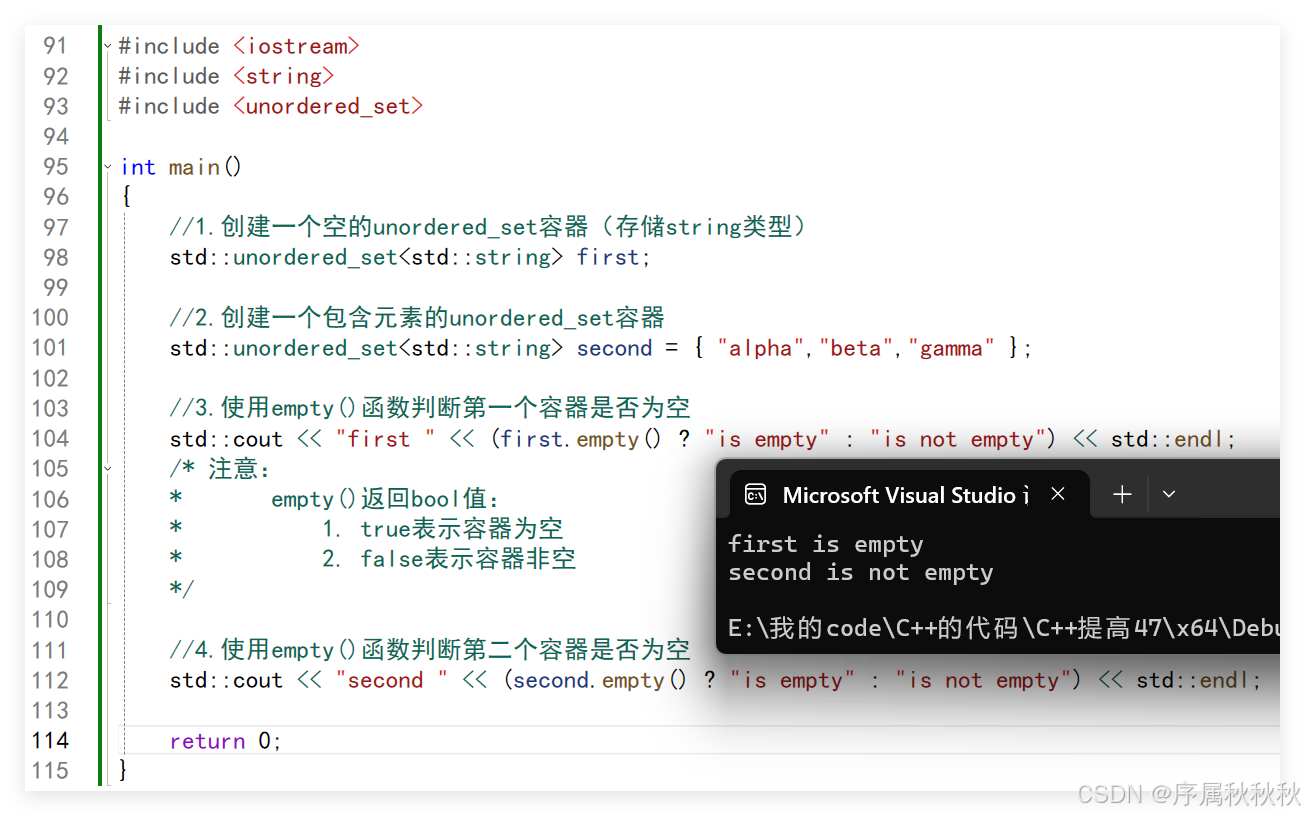
int main()
{
//1.创建一个空的unordered_set容器(存储string类型)
std::unordered_set<std::string> first;
//2.创建一个包含元素的unordered_set容器
std::unordered_set<std::string> second = { "alpha","beta","gamma" };
//3.使用empty()函数判断第一个容器是否为空
std::cout << "first " << (first.empty() ? "is empty" : "is not empty") << std::endl;
/* 注意:
* empty()返回bool值:
* 1. true表示容器为空
* 2. false表示容器非空
*/
//4.使用empty()函数判断第二个容器是否为空
std::cout << "second " << (second.empty() ? "is empty" : "is not empty") << std::endl;
return 0;
}
在这里插入图片描述
3. 访问的操作
std::unordered_set::find
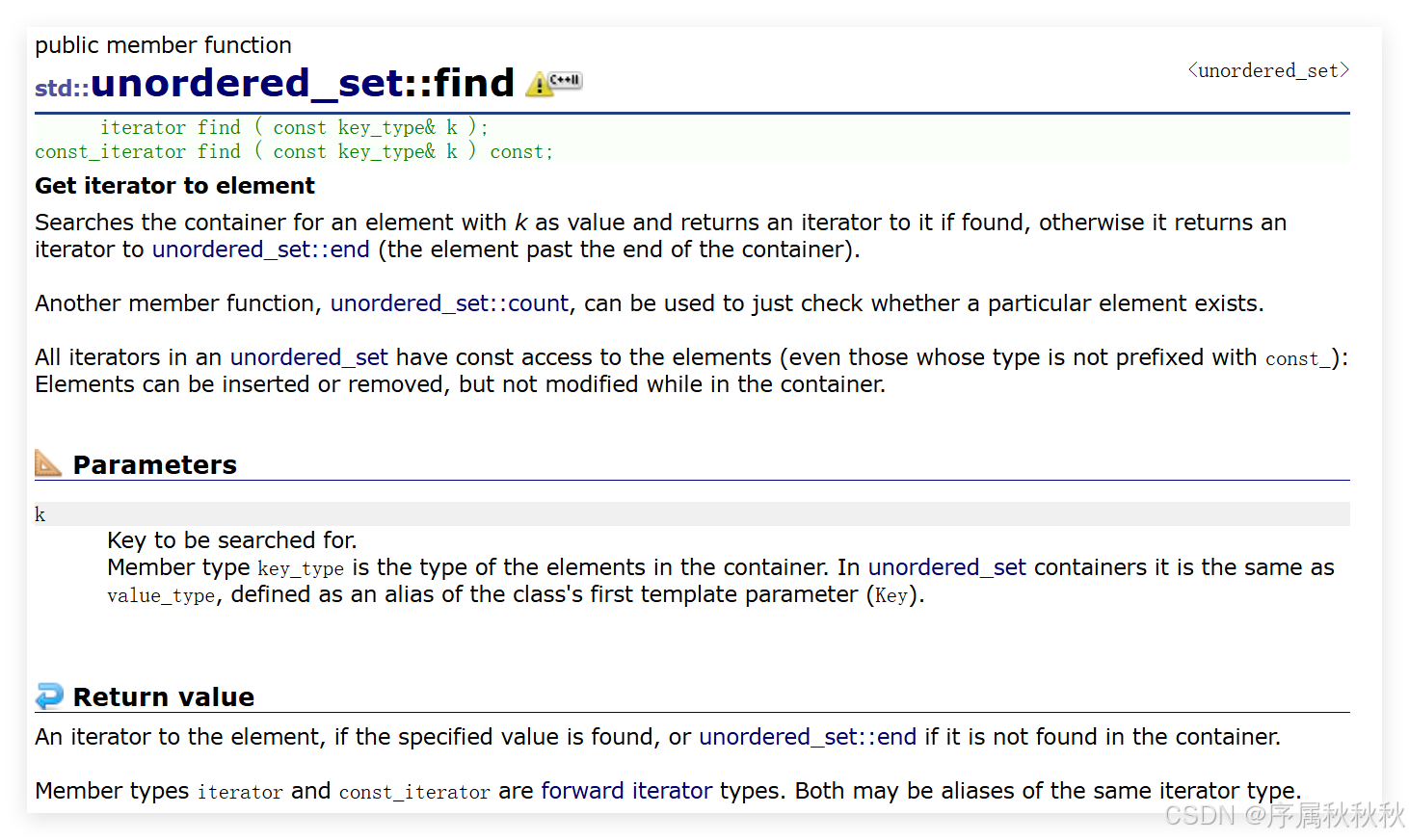
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
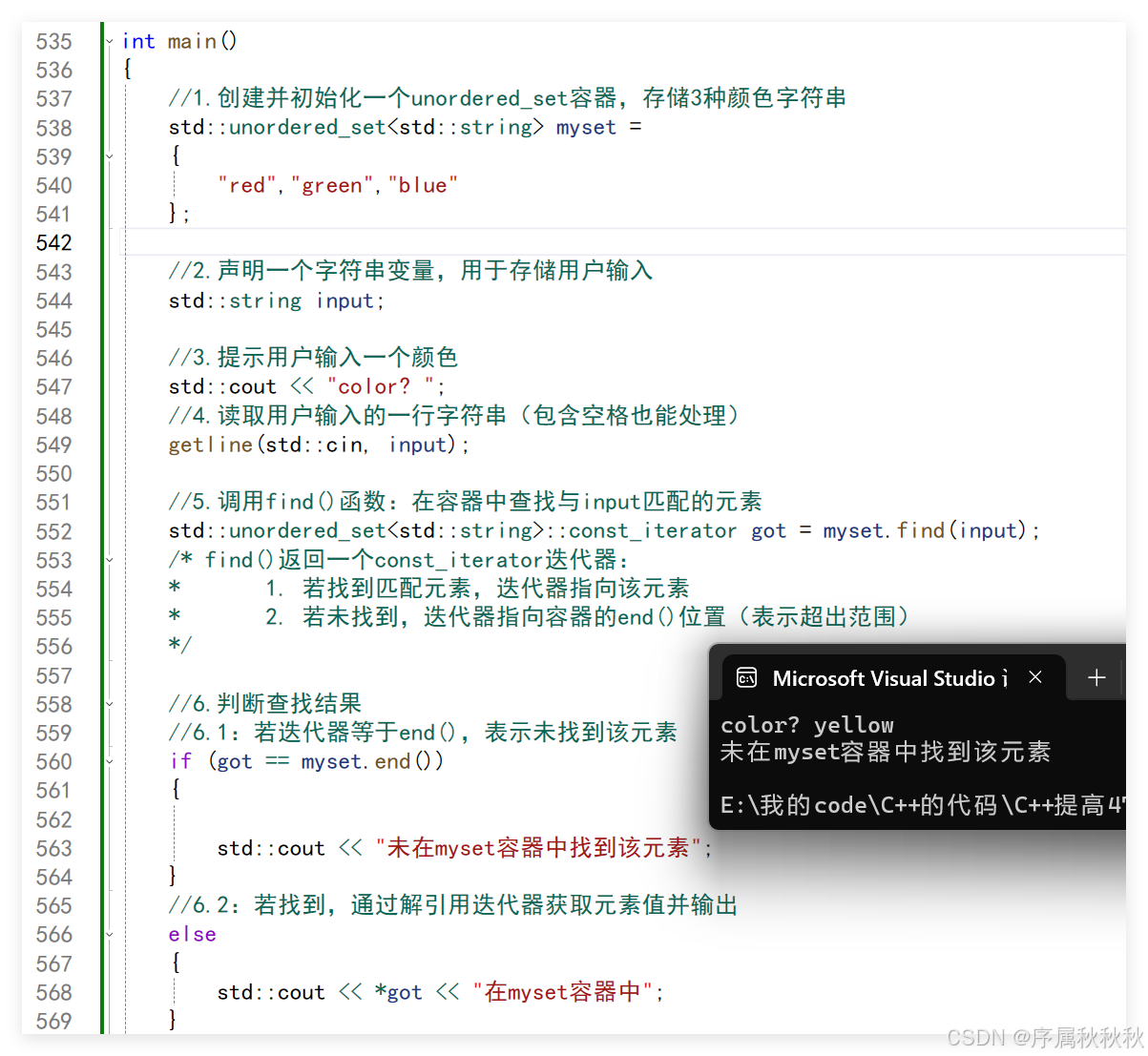
int main()
{
//1.创建并初始化一个unordered_set容器,存储3种颜色字符串
std::unordered_set<std::string> myset =
{
"red","green","blue"
};
//2.声明一个字符串变量,用于存储用户输入
std::string input;
//3.提示用户输入一个颜色
std::cout << "color? ";
//4.读取用户输入的一行字符串(包含空格也能处理)
getline(std::cin, input);
//5.调用find()函数:在容器中查找与input匹配的元素
std::unordered_set<std::string>::const_iterator got = myset.find(input);
/* find()返回一个const_iterator迭代器:
* 1. 若找到匹配元素,迭代器指向该元素
* 2. 若未找到,迭代器指向容器的end()位置(表示超出范围)
*/
//6.判断查找结果
//6.1:若迭代器等于end(),表示未找到该元素
if (got == myset.end())
{
std::cout << "未在myset容器中找到该元素";
}
//6.2:若找到,通过解引用迭代器获取元素值并输出
else
{
std::cout << *got << "在myset容器中";
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
std::unordered_set::count
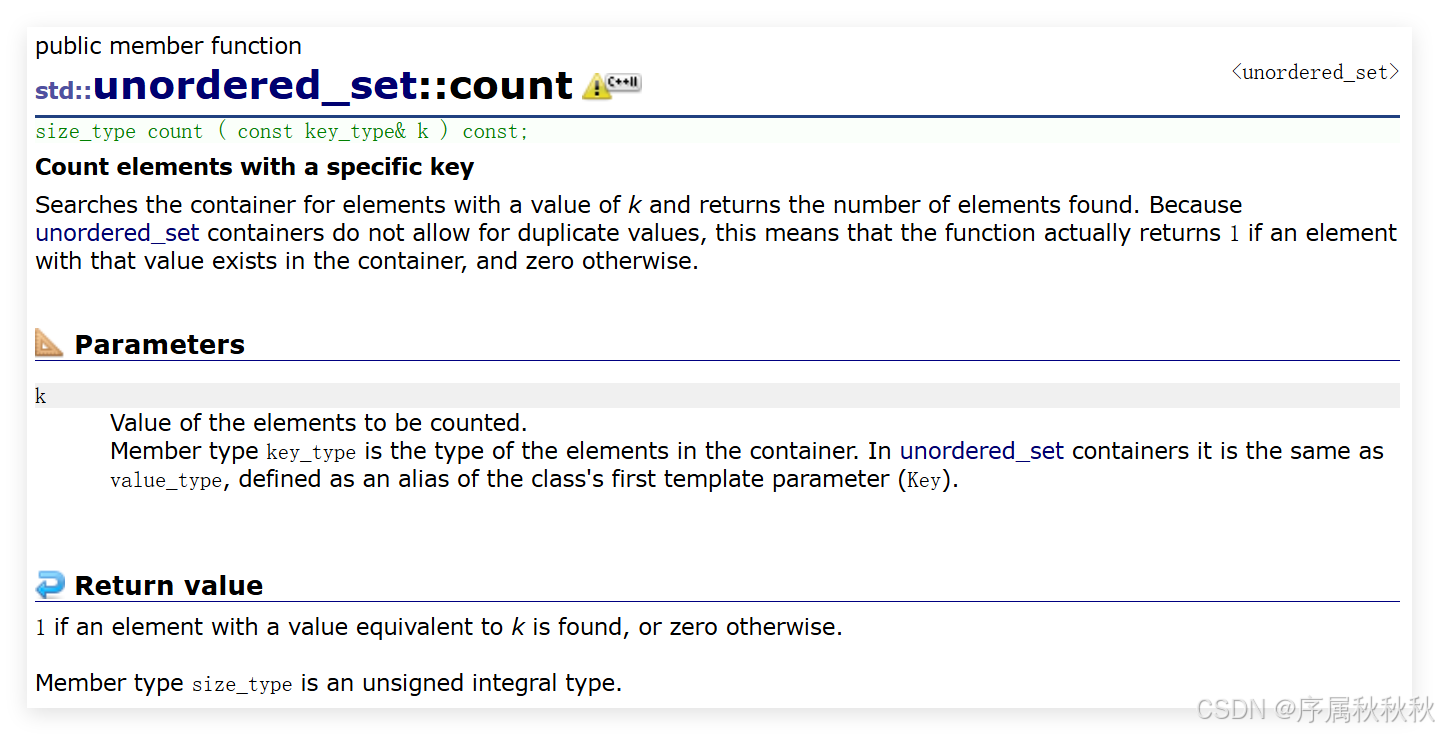
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
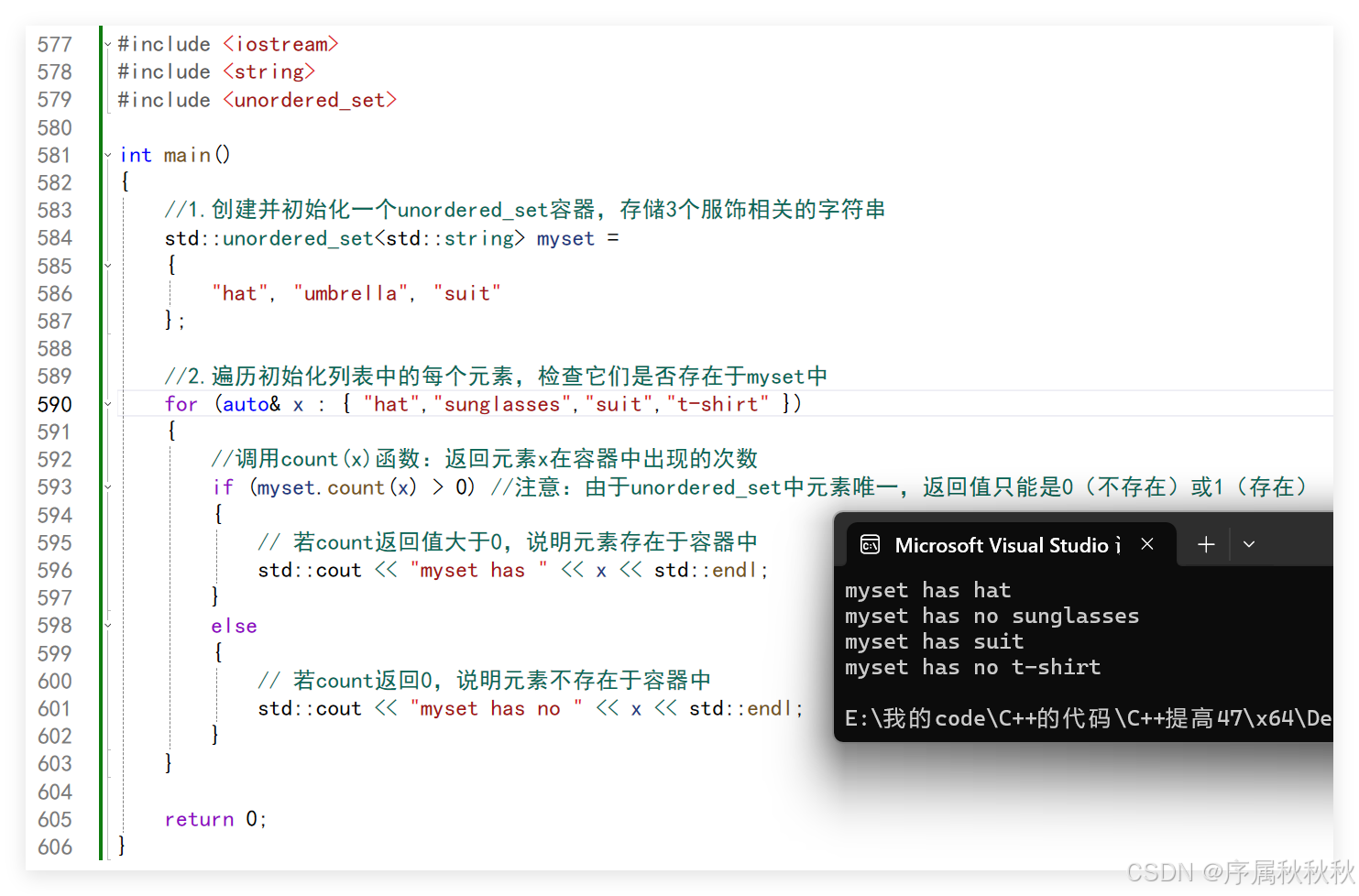
//1.创建并初始化一个unordered_set容器,存储3个服饰相关的字符串
std::unordered_set<std::string> myset =
{
"hat", "umbrella", "suit"
};
//2.遍历初始化列表中的每个元素,检查它们是否存在于myset中
for (auto& x : { "hat","sunglasses","suit","t-shirt" })
{
//调用count(x)函数:返回元素x在容器中出现的次数
if (myset.count(x) > 0) //注意:由于unordered_set中元素唯一,返回值只能是0(不存在)或1(存在)
{
// 若count返回值大于0,说明元素存在于容器中
std::cout << "myset has " << x << std::endl;
}
else
{
// 若count返回0,说明元素不存在于容器中
std::cout << "myset has no " << x << std::endl;
}
}
return 0;
}
在这里插入图片描述
4. 修改的操作
std::unordered_set::clear

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
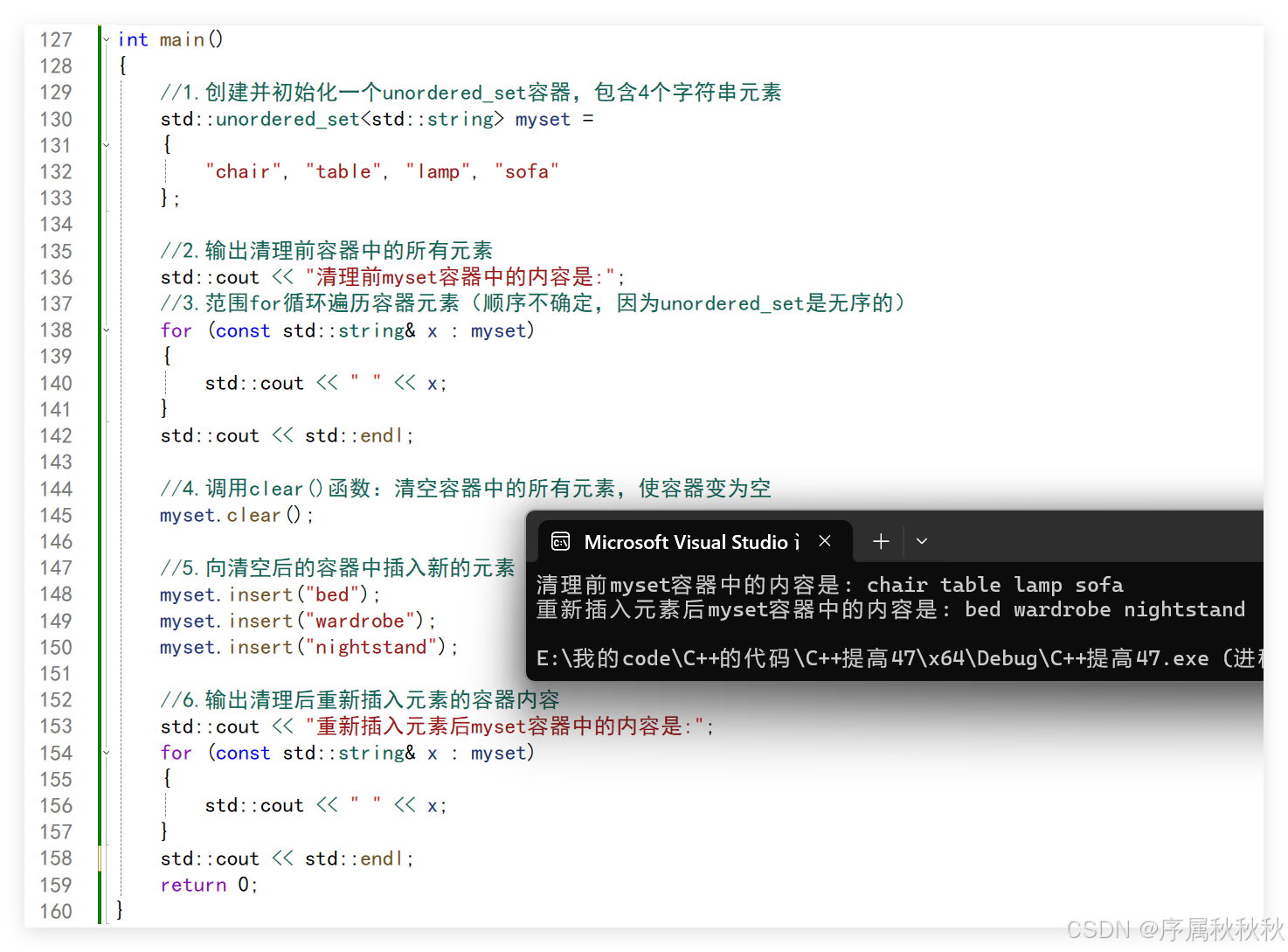
//1.创建并初始化一个unordered_set容器,包含4个字符串元素
std::unordered_set<std::string> myset =
{
"chair", "table", "lamp", "sofa"
};
//2.输出清理前容器中的所有元素
std::cout << "清理前myset容器中的内容是:";
//3.范围for循环遍历容器元素(顺序不确定,因为unordered_set是无序的)
for (const std::string& x : myset)
{
std::cout << " " << x;
}
std::cout << std::endl;
//4.调用clear()函数:清空容器中的所有元素,使容器变为空
myset.clear();
//5.向清空后的容器中插入新的元素
myset.insert("bed");
myset.insert("wardrobe");
myset.insert("nightstand");
//6.输出清理后重新插入元素的容器内容
std::cout << "重新插入元素后myset容器中的内容是:";
for (const std::string& x : myset)
{
std::cout << " " << x;
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
std::unordered_set::swap

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
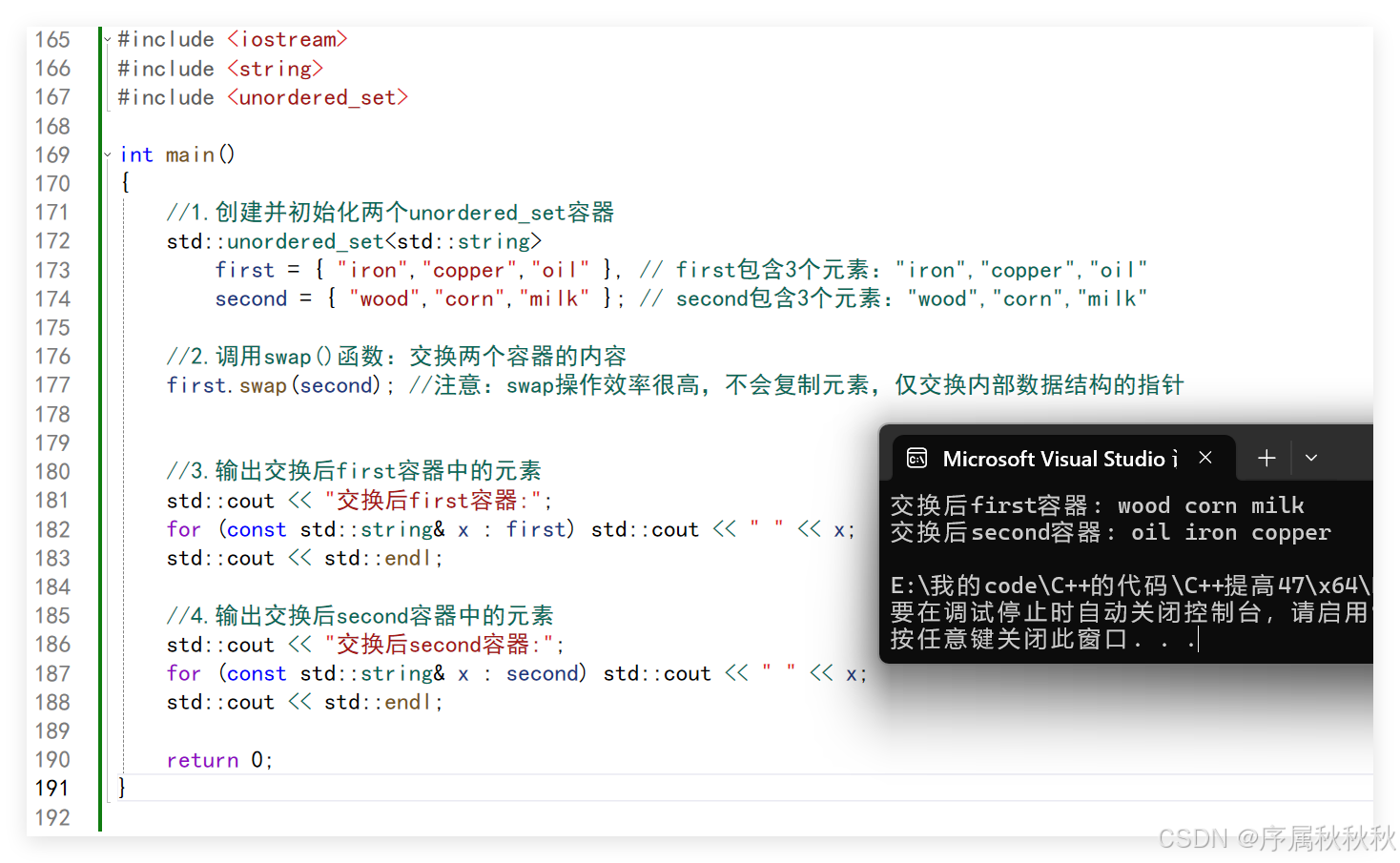
//1.创建并初始化两个unordered_set容器
std::unordered_set<std::string>
first = { "iron","copper","oil" }, // first包含3个元素:"iron","copper","oil"
second = { "wood","corn","milk" }; // second包含3个元素:"wood","corn","milk"
//2.调用swap()函数:交换两个容器的内容
first.swap(second); //注意:swap操作效率很高,不会复制元素,仅交换内部数据结构的指针
//3.输出交换后first容器中的元素
std::cout << "交换后first容器:";
for (const std::string& x : first) std::cout << " " << x;
std::cout << std::endl;
//4.输出交换后second容器中的元素
std::cout << "交换后second容器:";
for (const std::string& x : second) std::cout << " " << x;
std::cout << std::endl;
return 0;
}
在这里插入图片描述
std::unordered_set::insert

在这里插入图片描述
#include <iostream>
#include <string>
#include <array>
#include <unordered_set>
int main()
{
//1.创建并初始化一个unordered_set容器,包含3个初始元素
std::unordered_set<std::string> myset = { "yellow","green","blue" };
//2.创建一个包含2个字符串元素的array容器
std::array<std::string, 2> myarray = { "black","white" };
//3.创建一个单独的字符串变量
std::string mystring = "red";
/*----------------------- 拷贝插入 -----------------------*/
//拷贝插入:插入已有字符串变量的副本
myset.insert(mystring); //将mystring的值("red")复制一份插入到myset中
/*----------------------- 移动插入 -----------------------*/
//移动插入:插入临时字符串对象(会触发移动语义)
myset.insert(mystring + "dish"); //mystring+"dish"生成临时字符串"reddish",直接移动到容器中
/*----------------------- 范围插入 -----------------------*/
//范围插入:插入另一个容器指定范围内的所有元素
myset.insert(myarray.begin(), myarray.end()); //将myarray中从begin()到end()的所有元素("black","white")插入
/*----------------------- 初始化列表插入 -----------------------*/
//初始化列表插入:插入初始化列表中的所有元素
myset.insert({ "purple","orange" }); //将{"purple","orange"}两个元素插入到myset中
//4.输出容器中所有元素(注意:unordered_set元素无序)
std::cout << "myset容器中的内容是:";
for (const std::string& x : myset)
{
std::cout << " " << x;
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
std::unordered_set::erase

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
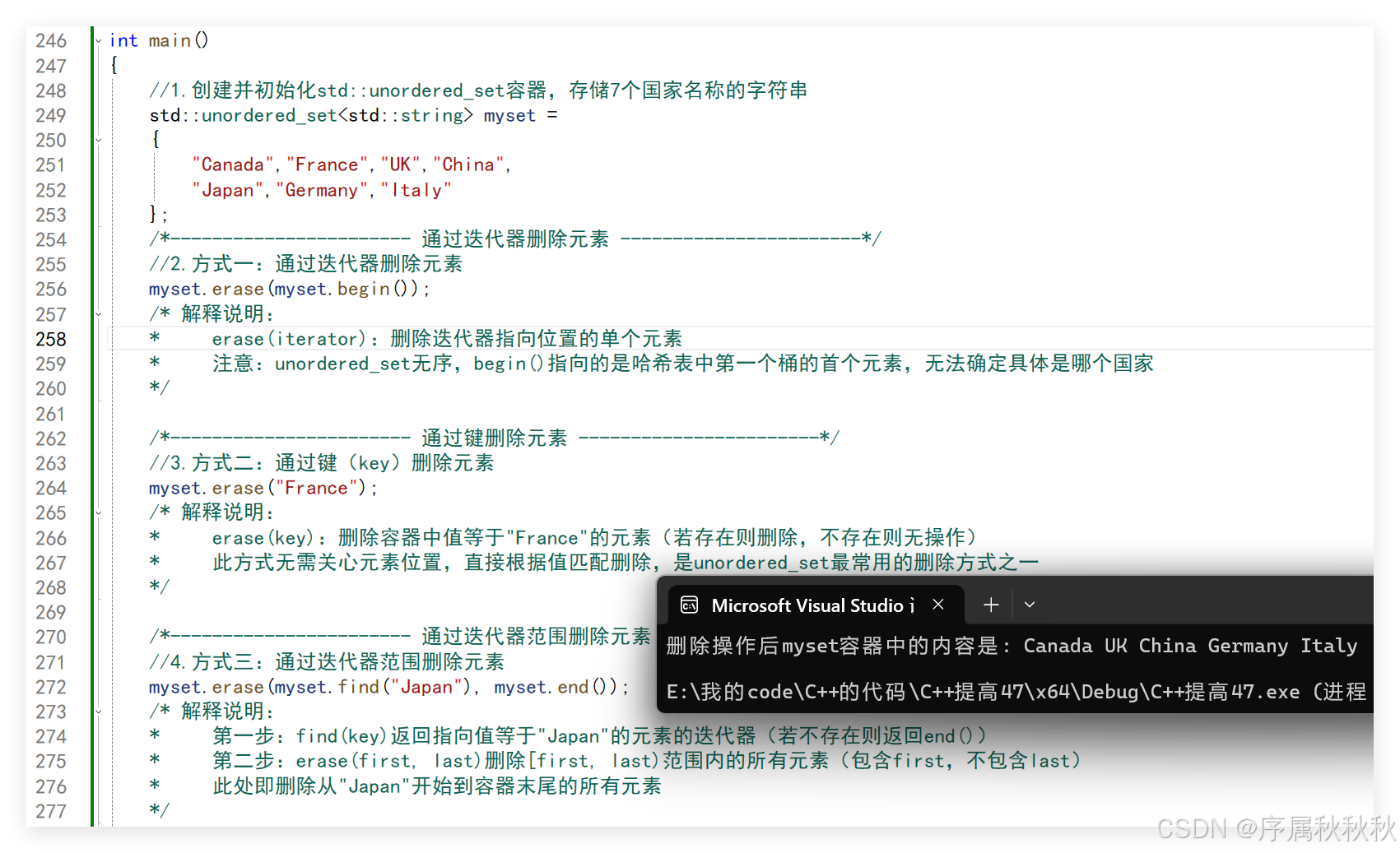
//1.创建并初始化std::unordered_set容器,存储7个国家名称的字符串
std::unordered_set<std::string> myset =
{
"Canada","France","UK","China",
"Japan","Germany","Italy"
};
/*----------------------- 通过迭代器删除元素 -----------------------*/
//2.方式一:通过迭代器删除元素
myset.erase(myset.begin());
/* 解释说明:
* erase(iterator):删除迭代器指向位置的单个元素
* 注意:unordered_set无序,begin()指向的是哈希表中第一个桶的首个元素,无法确定具体是哪个国家
*/
/*----------------------- 通过键删除元素 -----------------------*/
//3.方式二:通过键(key)删除元素
myset.erase("France");
/* 解释说明:
* erase(key):删除容器中值等于"France"的元素(若存在则删除,不存在则无操作)
* 此方式无需关心元素位置,直接根据值匹配删除,是unordered_set最常用的删除方式之一
*/
/*----------------------- 通过迭代器范围删除元素 -----------------------*/
//4.方式三:通过迭代器范围删除元素
myset.erase(myset.find("Japan"), myset.end());
/* 解释说明:
* 第一步:find(key)返回指向值等于"Japan"的元素的迭代器(若不存在则返回end())
* 第二步:erase(first, last)删除[first, last)范围内的所有元素(包含first,不包含last)
* 此处即删除从"Japan"开始到容器末尾的所有元素
*/
//5.输出删除操作后容器中剩余的元素
std::cout << "删除操作后myset容器中的内容是:";
for (const std::string& x : myset)
{
std::cout << " " << x;
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
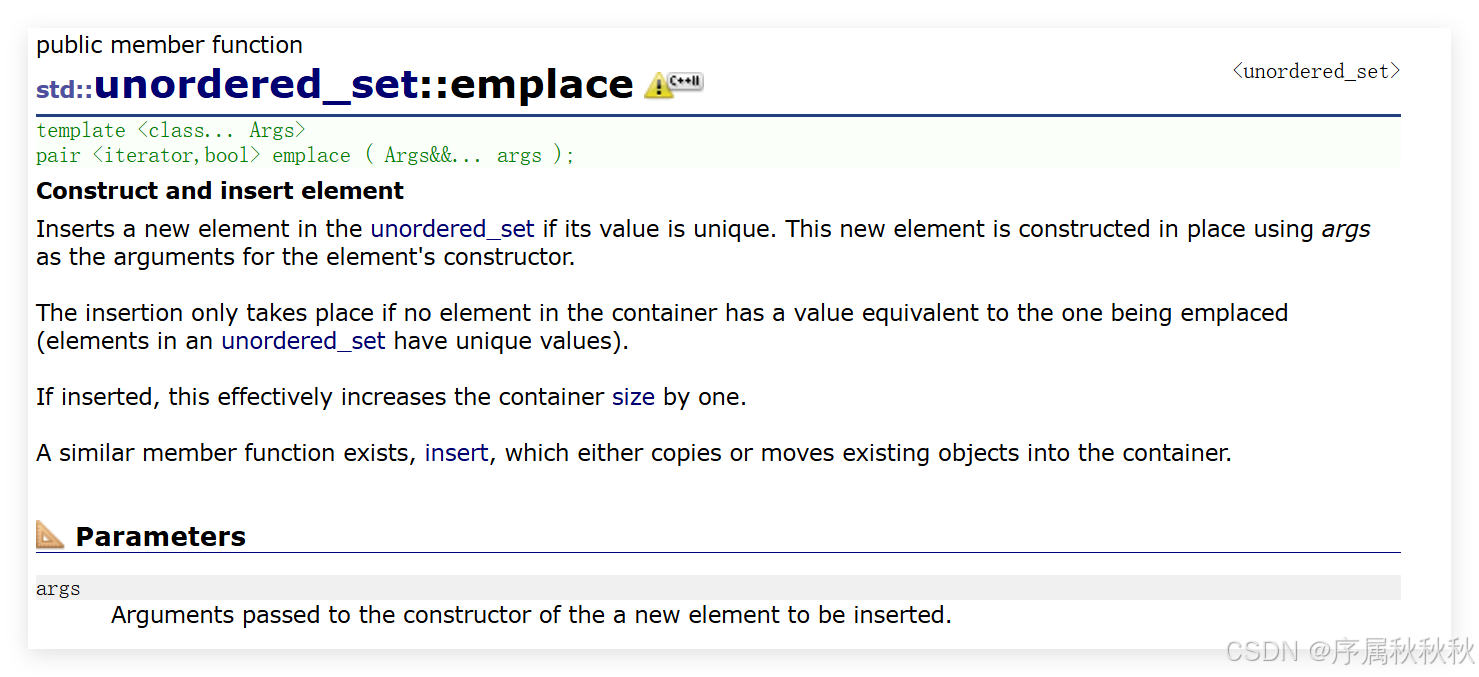
std::unordered_set::emplace
在这里插入图片描述
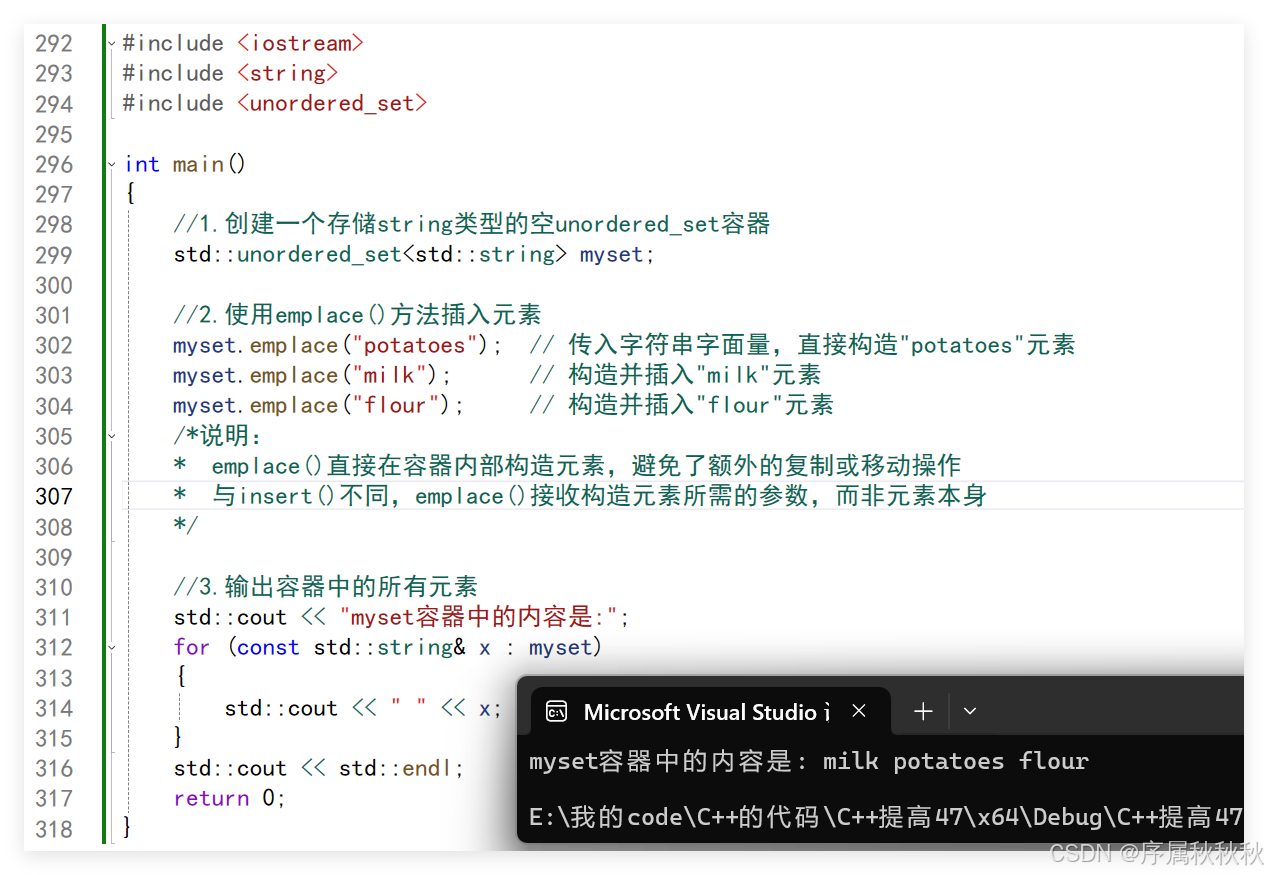
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
//1.创建一个存储string类型的空unordered_set容器
std::unordered_set<std::string> myset;
//2.使用emplace()方法插入元素
myset.emplace("potatoes"); // 传入字符串字面量,直接构造"potatoes"元素
myset.emplace("milk"); // 构造并插入"milk"元素
myset.emplace("flour"); // 构造并插入"flour"元素
/*说明:
* emplace()直接在容器内部构造元素,避免了额外的复制或移动操作
* 与insert()不同,emplace()接收构造元素所需的参数,而非元素本身
*/
//3.输出容器中的所有元素
std::cout << "myset容器中的内容是:";
for (const std::string& x : myset)
{
std::cout << " " << x;
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
5. 哈希桶操作
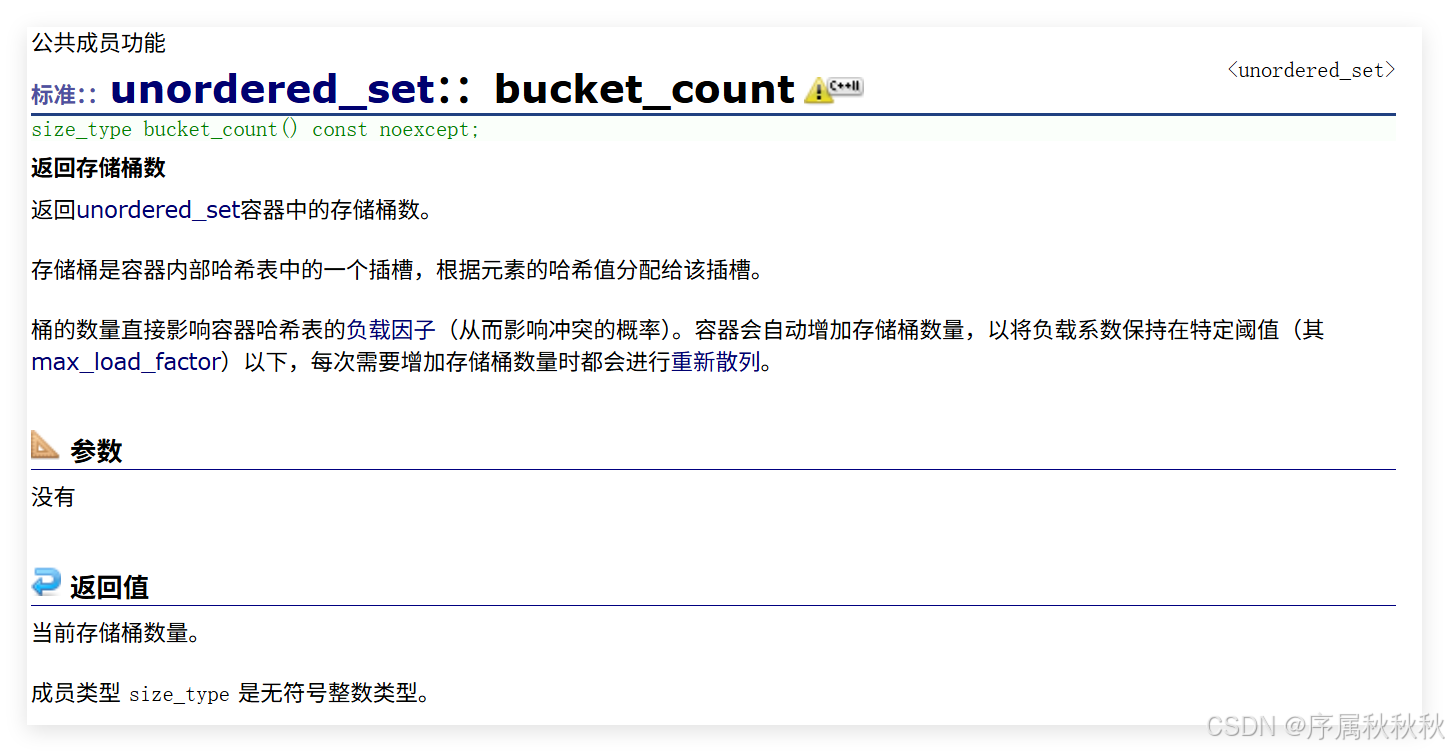
std::unordered_set::bucket_count
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
//1.创建并初始化一个unordered_set容器,存储8个行星名称
std::unordered_set<std::string> myset =
{
"Mercury","Venus","Earth","Mars",
"Jupiter","Saturn","Uranus","Neptune"
};
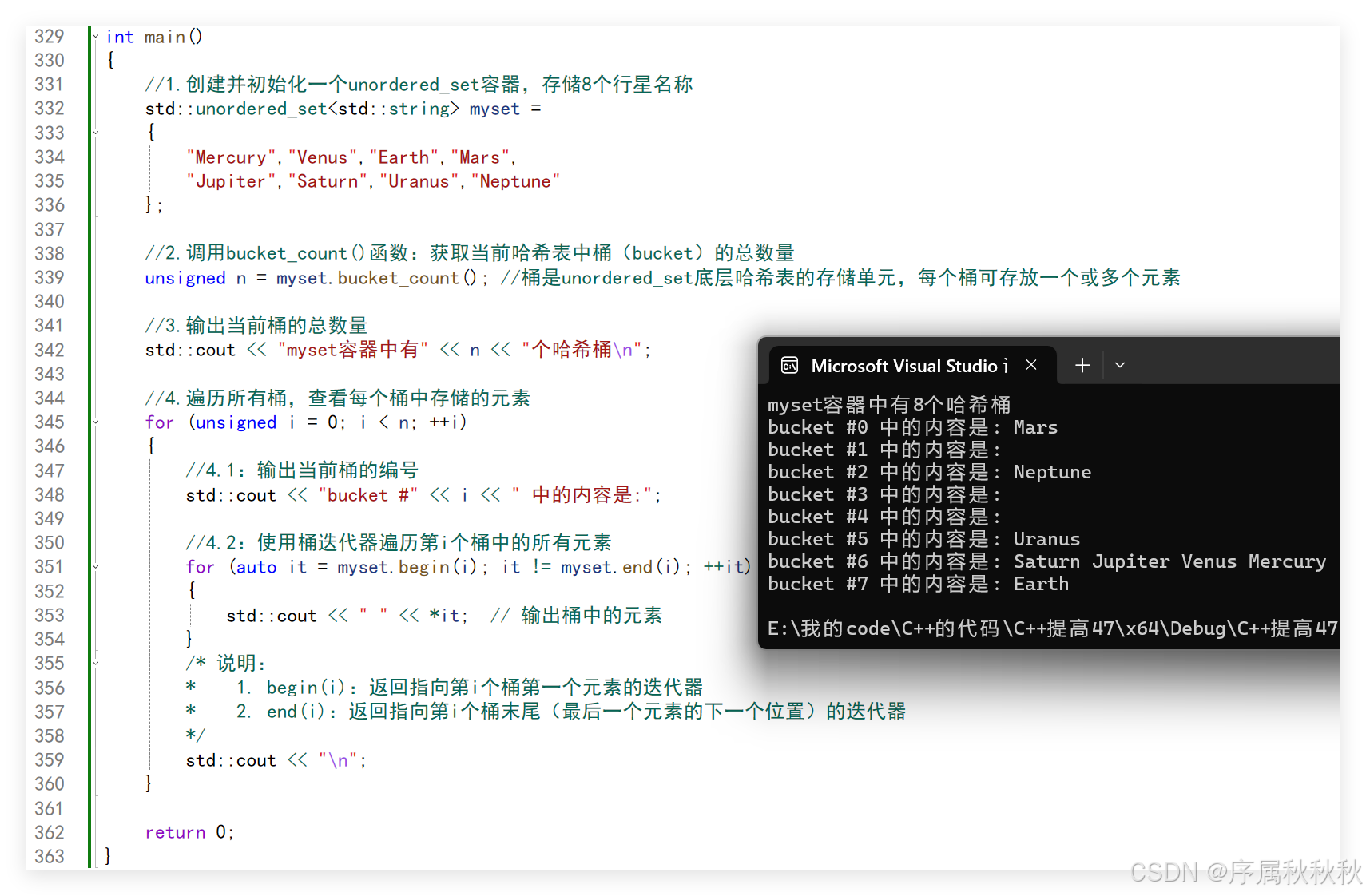
//2.调用bucket_count()函数:获取当前哈希表中桶(bucket)的总数量
unsigned n = myset.bucket_count(); //桶是unordered_set底层哈希表的存储单元,每个桶可存放一个或多个元素
//3.输出当前桶的总数量
std::cout << "myset容器中有" << n << "个哈希桶\n";
//4.遍历所有桶,查看每个桶中存储的元素
for (unsigned i = 0; i < n; ++i)
{
//4.1:输出当前桶的编号
std::cout << "bucket #" << i << " 中的内容是:";
//4.2:使用桶迭代器遍历第i个桶中的所有元素
for (auto it = myset.begin(i); it != myset.end(i); ++it)
{
std::cout << " " << *it; // 输出桶中的元素
}
/* 说明:
* 1. begin(i):返回指向第i个桶第一个元素的迭代器
* 2. end(i):返回指向第i个桶末尾(最后一个元素的下一个位置)的迭代器
*/
std::cout << "\n";
}
return 0;
}
在这里插入图片描述
std::unordered_set::bucket_size

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
//1.创建并初始化一个unordered_set容器,存储6个颜色名称字符串
std::unordered_set<std::string> myset =
{
"red", "green", "blue",
"yellow", "purple", "pink"
};
//2.调用bucket_count()函数:获取当前哈希表中桶(bucket)的总数量
unsigned nbuckets = myset.bucket_count(); //桶是unordered_set底层哈希表的存储单元,所有元素分散存储在这些桶中
//3.输出当前哈希表中桶的总数量
std::cout << "myset容器中有" << nbuckets << "个哈希桶\n";
//4.遍历所有桶,查询并输出每个桶中包含的元素数量
for (unsigned i = 0; i < nbuckets; ++i)
{
// 调用bucket_size(i)函数:获取第i个桶中存储的元素个数
std::cout << "bucket #" << i << " 有 " << myset.bucket_size(i) << " 个元素\n";
//注意:该函数用于分析哈希表的负载均衡情况,元素分布越均匀,哈希表性能越好
}
return 0;
}
在这里插入图片描述
std::unordered_set::bucket
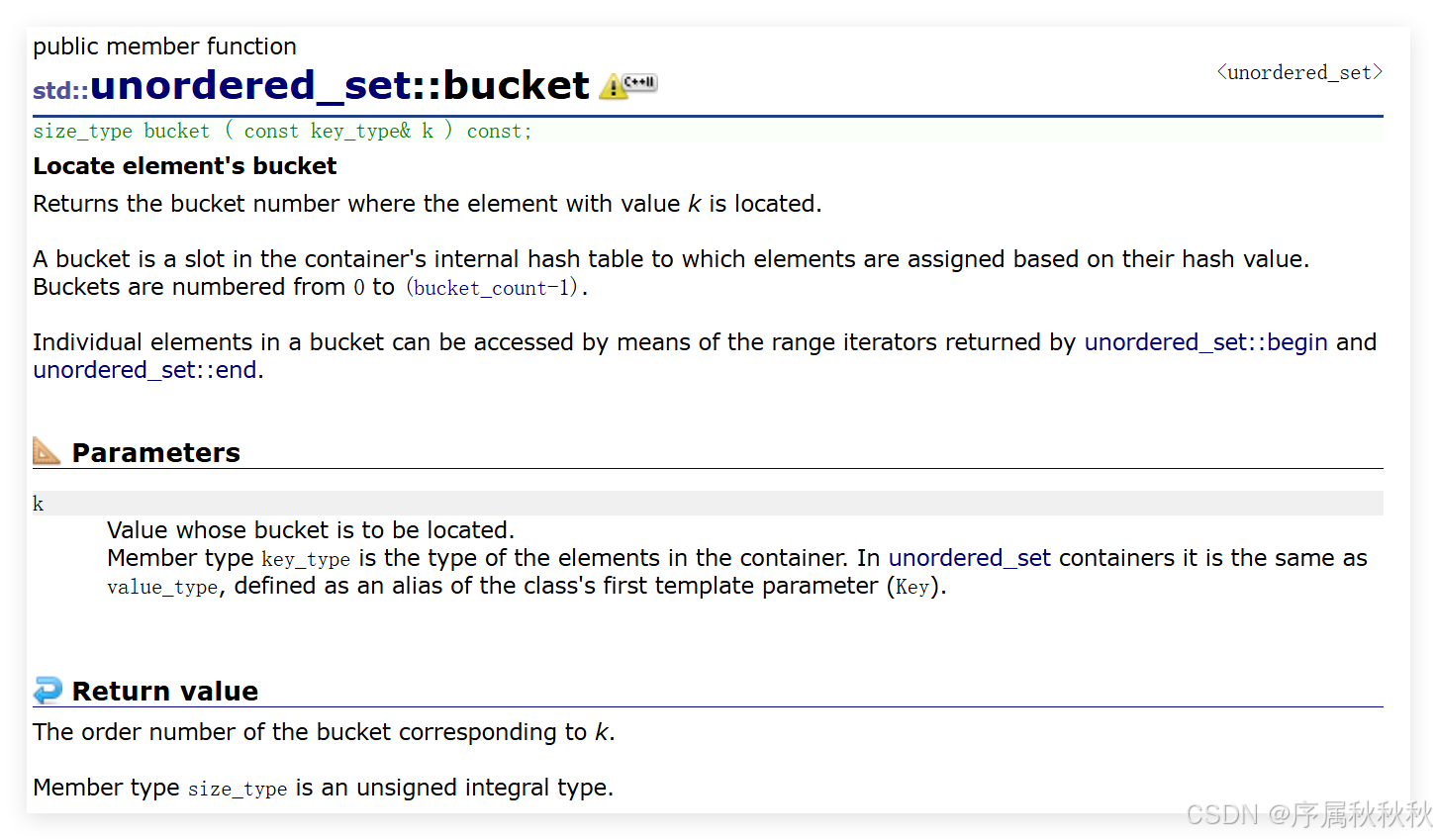
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
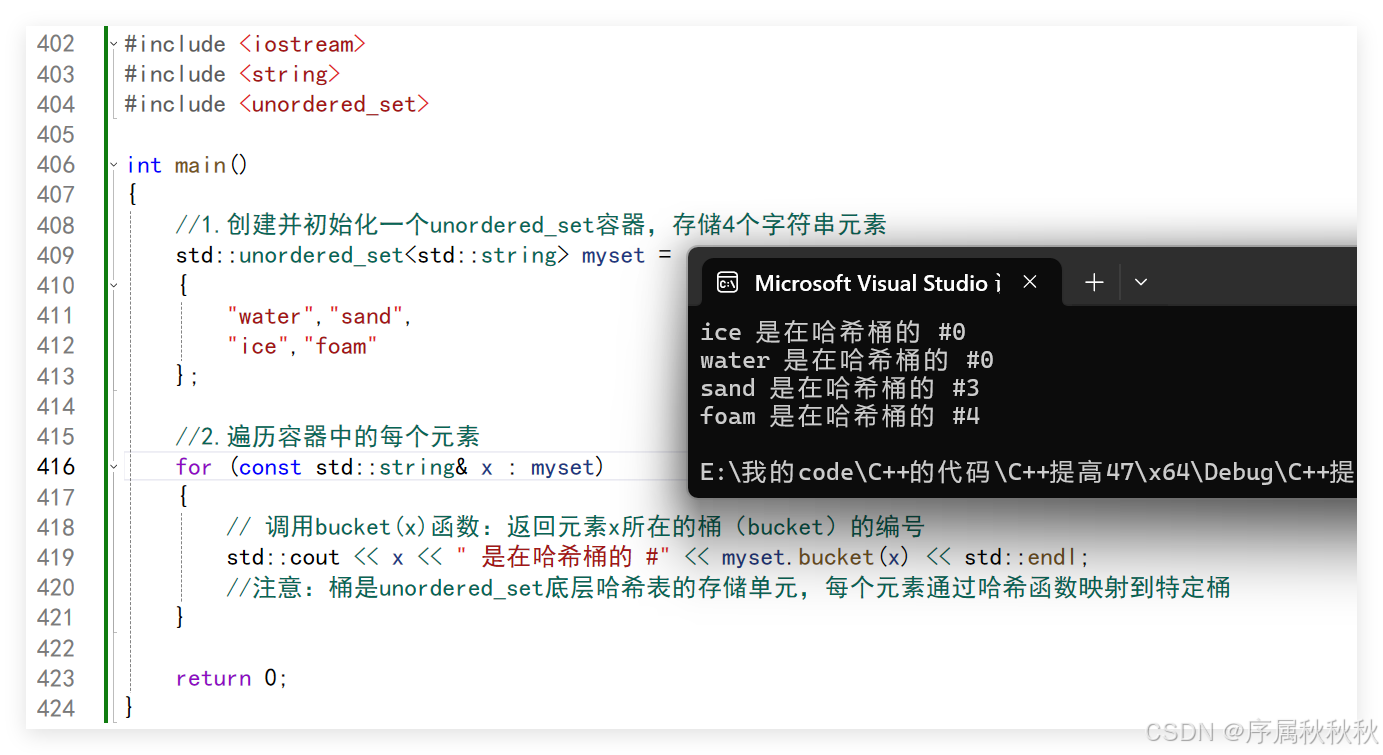
//1.创建并初始化一个unordered_set容器,存储4个字符串元素
std::unordered_set<std::string> myset =
{
"water","sand",
"ice","foam"
};
//2.遍历容器中的每个元素
for (const std::string& x : myset)
{
// 调用bucket(x)函数:返回元素x所在的桶(bucket)的编号
std::cout << x << " 是在哈希桶的 #" << myset.bucket(x) << std::endl;
//注意:桶是unordered_set底层哈希表的存储单元,每个元素通过哈希函数映射到特定桶
}
return 0;
}
在这里插入图片描述
6. 哈希的策略
std::unordered_set::load_factor
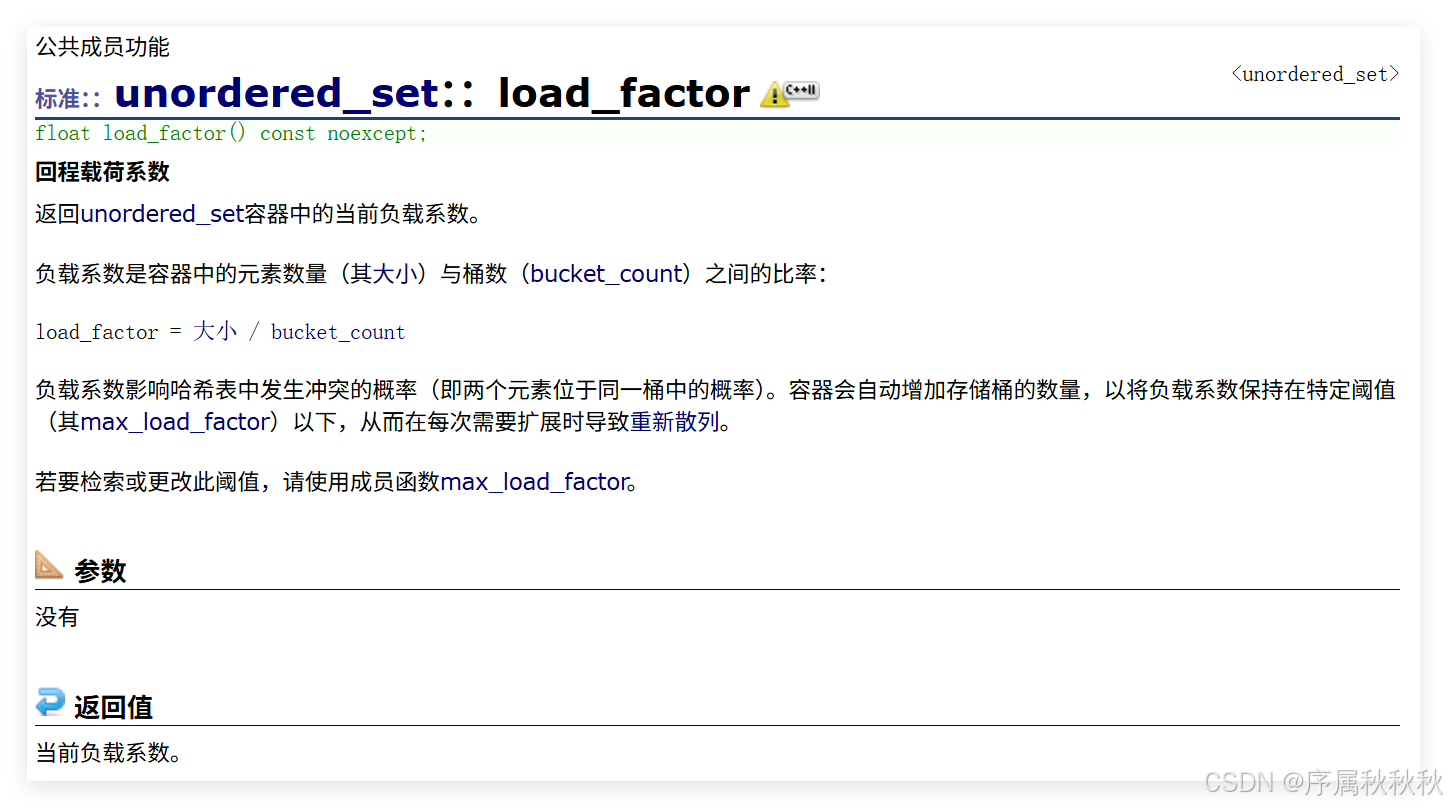
在这里插入图片描述
#include <iostream>
#include <unordered_set>
int main()
{
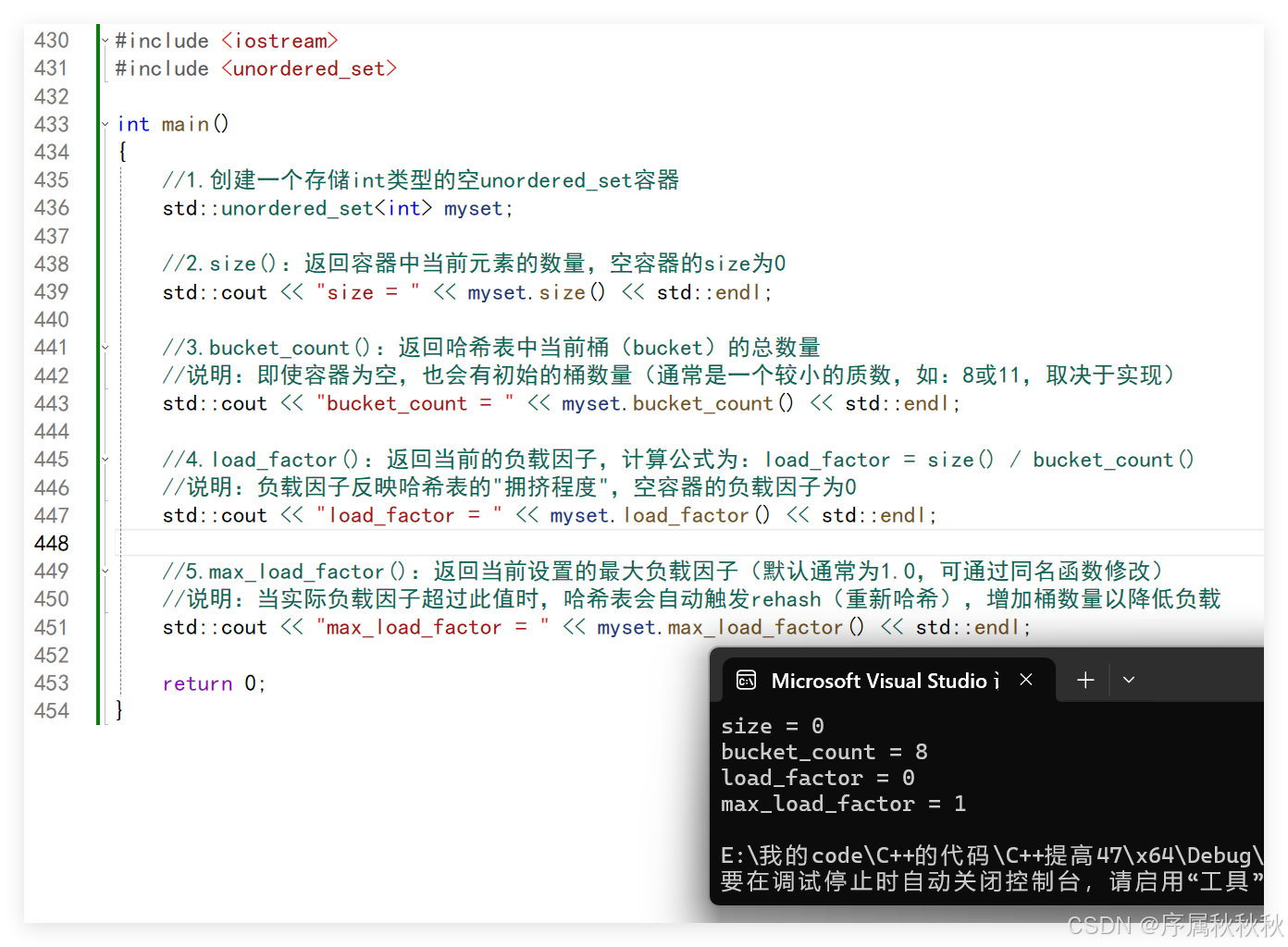
//1.创建一个存储int类型的空unordered_set容器
std::unordered_set<int> myset;
//2.size():返回容器中当前元素的数量,空容器的size为0
std::cout << "size = " << myset.size() << std::endl;
//3.bucket_count():返回哈希表中当前桶(bucket)的总数量
//说明:即使容器为空,也会有初始的桶数量(通常是一个较小的质数,如:8或11,取决于实现)
std::cout << "bucket_count = " << myset.bucket_count() << std::endl;
//4.load_factor():返回当前的负载因子,计算公式为:load_factor = size() / bucket_count()
//说明:负载因子反映哈希表的"拥挤程度",空容器的负载因子为0
std::cout << "load_factor = " << myset.load_factor() << std::endl;
//5.max_load_factor():返回当前设置的最大负载因子(默认通常为1.0,可通过同名函数修改)
//说明:当实际负载因子超过此值时,哈希表会自动触发rehash(重新哈希),增加桶数量以降低负载
std::cout << "max_load_factor = " << myset.max_load_factor() << std::endl;
return 0;
}
在这里插入图片描述
std::unordered_set::rehash

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
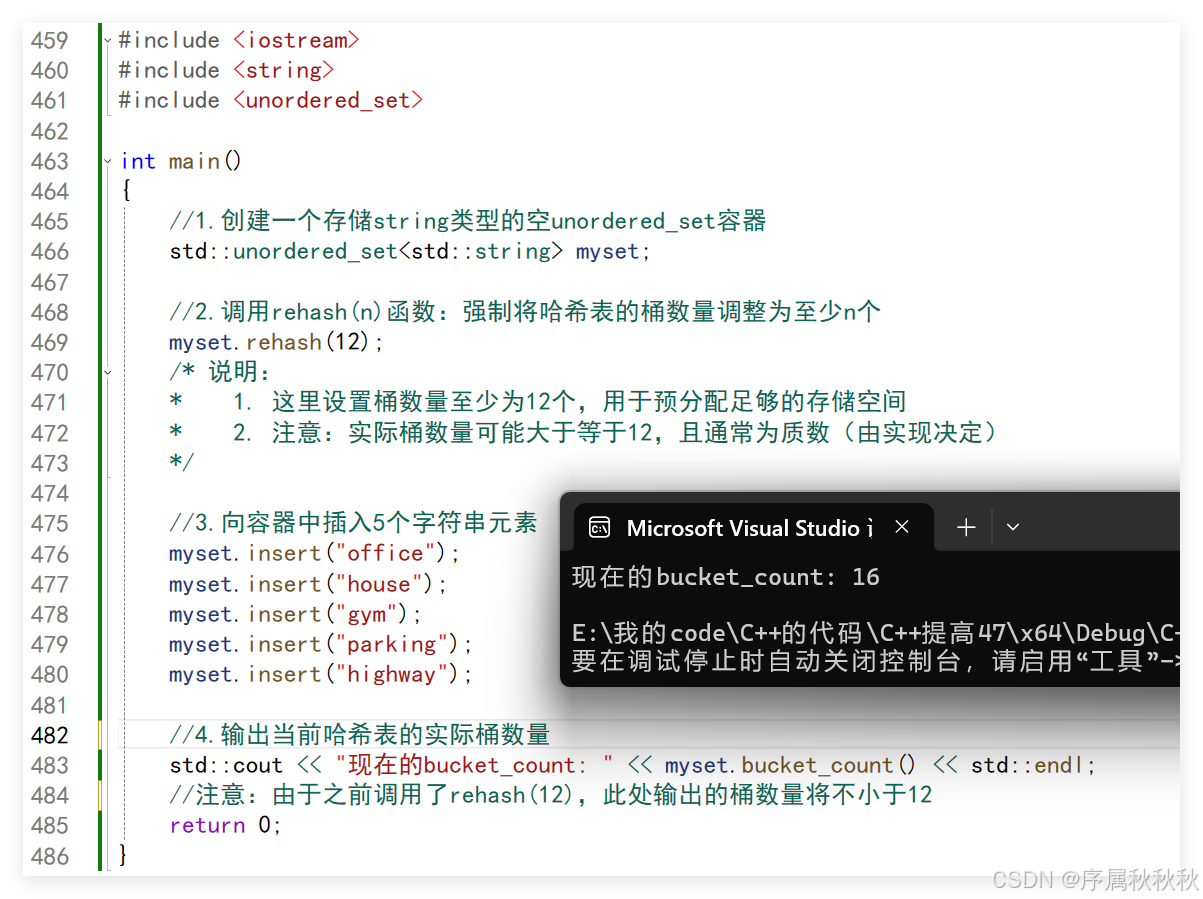
//1.创建一个存储string类型的空unordered_set容器
std::unordered_set<std::string> myset;
//2.调用rehash(n)函数:强制将哈希表的桶数量调整为至少n个
myset.rehash(12);
/* 说明:
* 1. 这里设置桶数量至少为12个,用于预分配足够的存储空间
* 2. 注意:实际桶数量可能大于等于12,且通常为质数(由实现决定)
*/
//3.向容器中插入5个字符串元素
myset.insert("office");
myset.insert("house");
myset.insert("gym");
myset.insert("parking");
myset.insert("highway");
//4.输出当前哈希表的实际桶数量
std::cout << "现在的bucket_count: " << myset.bucket_count() << std::endl;
//注意:由于之前调用了rehash(12),此处输出的桶数量将不小于12
return 0;
}
在这里插入图片描述
std::unordered_set::reserve
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
//1.创建一个存储string类型的空unordered_set容器
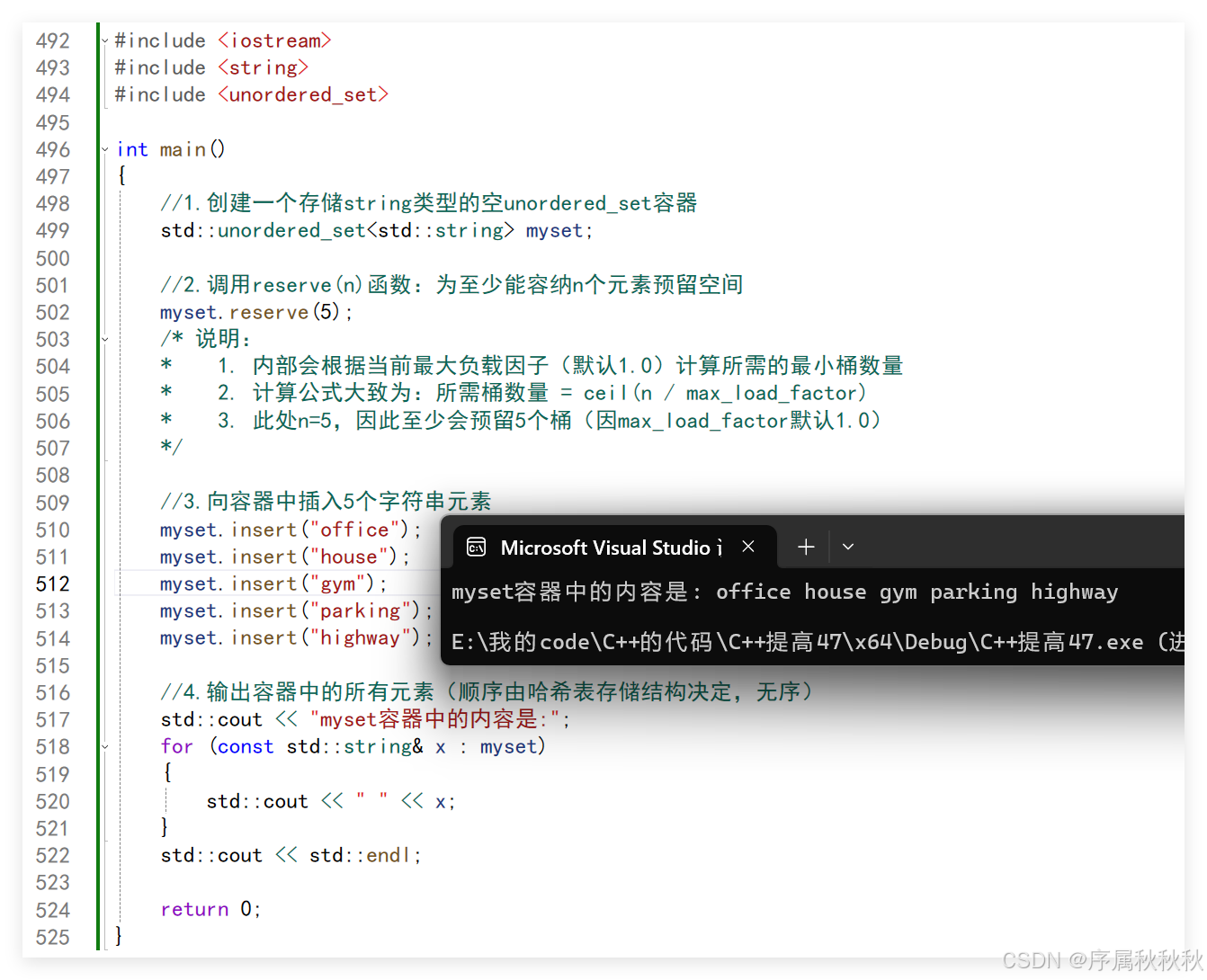
std::unordered_set<std::string> myset;
//2.调用reserve(n)函数:为至少能容纳n个元素预留空间
myset.reserve(5);
/* 说明:
* 1. 内部会根据当前最大负载因子(默认1.0)计算所需的最小桶数量
* 2. 计算公式大致为:所需桶数量 = ceil(n / max_load_factor)
* 3. 此处n=5,因此至少会预留5个桶(因max_load_factor默认1.0)
*/
//3.向容器中插入5个字符串元素
myset.insert("office");
myset.insert("house");
myset.insert("gym");
myset.insert("parking");
myset.insert("highway");
//4.输出容器中的所有元素(顺序由哈希表存储结构决定,无序)
std::cout << "myset容器中的内容是:";
for (const std::string& x : myset)
{
std::cout << " " << x;
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
------------unordered_map------------
一、介绍
cplusplus网站上关于C++的
unordered_map容器的介绍:unordered_map - C++ 参考

在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
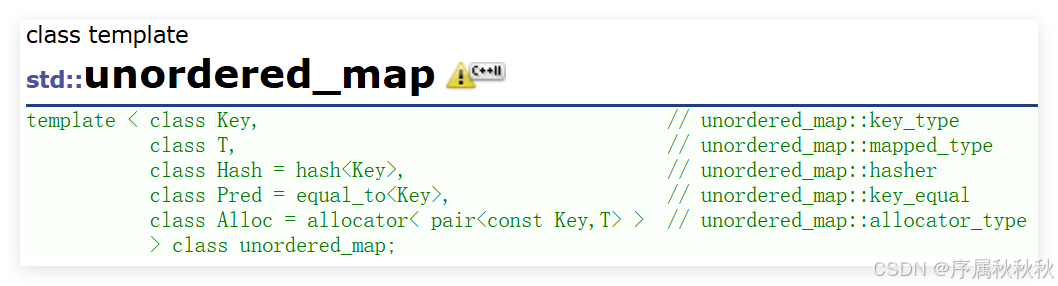
template <
class Key, // unordered_map::key_type
class T, // unordered_map::mapped_type
class Hash = hash<Key>, // unordered_map::hasher
class Pred = equal_to<Key>, // unordered_map::key_equal
class Alloc = allocator< pair<const Key, T> > // unordered_map::allocator_type
> class unordered_map;
template <
class Key, // 键的类型(key_type)
class T, // 值的类型(mapped_type)
class Hash = hash<Key>, // 哈希函数(默认用标准库 hash<Key>)
class Pred = equal_to<Key>,// 键相等比较规则(默认用 == 比较)
class Alloc = allocator< pair<const Key, T> > // 内存分配器(默认用标准分配器)
> class unordered_map;关于 C++ STL 中 unordered_map 容器的模板参数说明:
键类型(Key):unordered_map 中存储的键的类型,即键值对里 “键” 的类型。
映射值类型(T):unordered_map 中存储的映射值的类型,即键值对里 “值” 的类型。
哈希函数(Hash,默认 hash<Key>):用于计算键的哈希值,决定键在哈希表中对应的桶位置。
相等比较器(Pred,默认 equal_to<Key>):用于判断两个键是否相等,以处理哈希冲突等场景下的键匹配。
内存分配器(Alloc,默认 allocator<pair<const Key, T>>):负责管理 unordered_map 的内存分配与释放,用于分配存储键值对 pair<const Key, T> 的内存。
若需针对特定内存管理需求(如:自定义内存分配策略),可自定义分配器。
unordered_map<Key, T, MyHash<Key>, MyEqual<Key>, MyAllocator<pair<const Key, T>>> myUnorderedMap; // 使用自定义哈希、比较器和分配器C++ 标准模板库(STL)中的
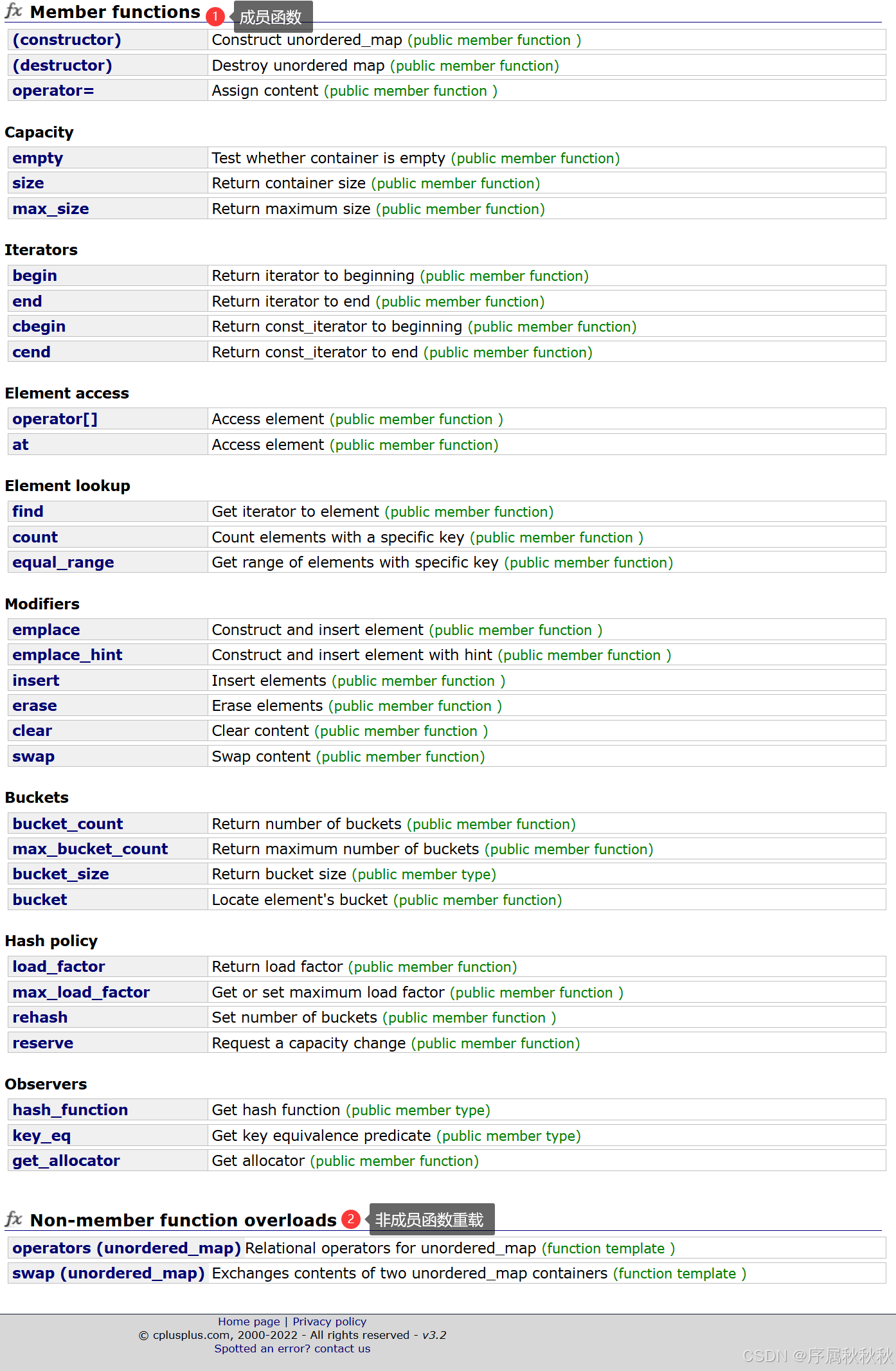
unordered_map容器 相关内容,主要可以分为以下两个部分:
- 成员函数:提供了 unordered_map 容器的 各类操作接口
- 涵盖
对象构造与销毁、容量查询、迭代器获取、元素访问、元素查找、元素修改、桶操作、哈希策略控制、观察器(获取哈希、键比较、分配器等)等功能。
- 涵盖
- 非成员函数重载:对一些操作符和通用函数进行了重载
- 用于支持 unordered_map 容器间的
关系比较、内容交换等操作。
- 用于支持 unordered_map 容器间的
在这里插入图片描述
二、接口
1. 常用的构造
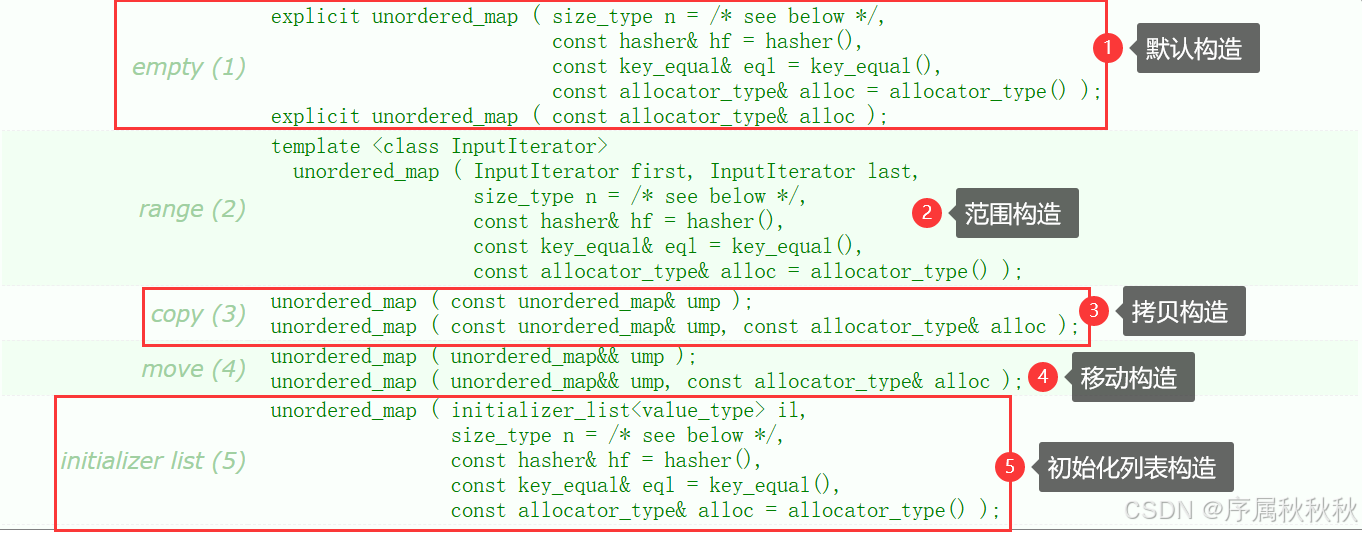
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
//1.定义类型别名stringmap,简化unordered_map<std::string, std::string>的使用
//注意:该容器存储string到string的键值对(key-value pairs)
typedef std::unordered_map<std::string, std::string> stringmap;
//2.定义一个合并两个stringmap的函数
//功能:将两个unordered_map合并为一个,返回合并后的新容器
stringmap merge(stringmap a, stringmap b)
{
//2.1:先用a初始化临时容器temp(拷贝构造)
stringmap temp(a);
//2.2:将b中的所有元素插入到temp中(范围插入)
temp.insert(b.begin(), b.end());
//2.3:返回合并后的容器(此处会触发移动语义)
return temp;
}
int main()
{
/*----------------------- 默认构造 -----------------------*/
//1.构造一个空的unordered_map
stringmap first;
/*----------------------- 初始化列表构造 -----------------------*/
//2.使用初始化列表构造unordered_map,包含两个键值对
stringmap second({ {"apple", "red"}, {"lemon", "yellow"} });
stringmap third({ {"orange", "orange"}, {"strawberry", "red"} });
/*----------------------- 拷贝构造函数 -----------------------*/
//3.使用拷贝构造函数,用second初始化fourth(复制second的所有元素)
stringmap fourth(second);
/*----------------------- 移动构造函数 -----------------------*/
//4.使用移动构造函数,用merge函数的返回值初始化fifth
stringmap fifth(merge(third, fourth)); //注意:merge返回的临时对象会被移动到fifth,而非拷贝(更高效)
/*----------------------- 范围构造函数 -----------------------*/
//5.使用范围构造函数,用fifth的所有元素(从begin到end)初始化sixth
stringmap sixth(fifth.begin(), fifth.end());
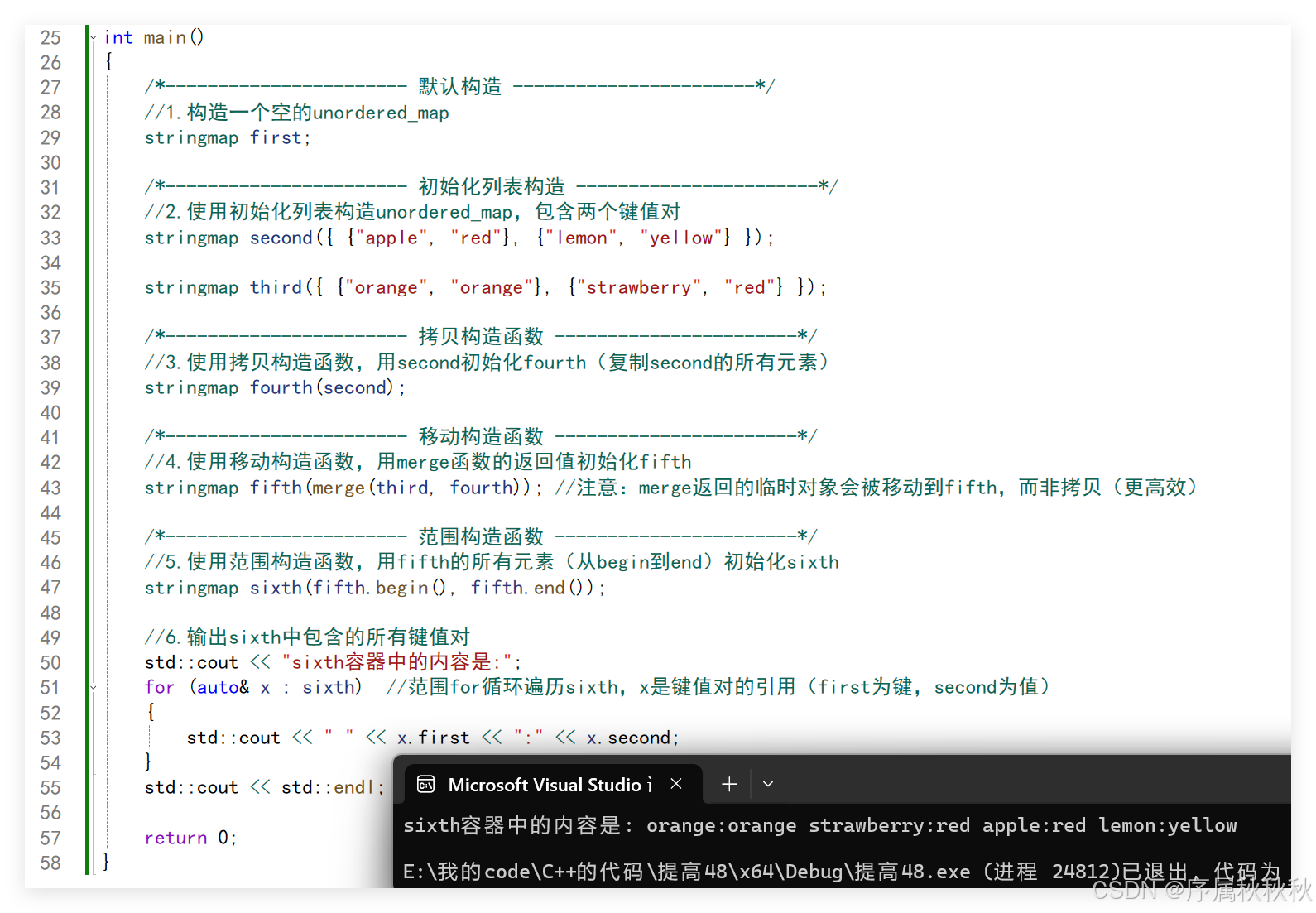
//6.输出sixth中包含的所有键值对
std::cout << "sixth容器中的内容是:";
for (auto& x : sixth) //范围for循环遍历sixth,x是键值对的引用(first为键,second为值)
{
std::cout << " " << x.first << ":" << x.second;
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
2. 容量的操作
std::unordered_map::size
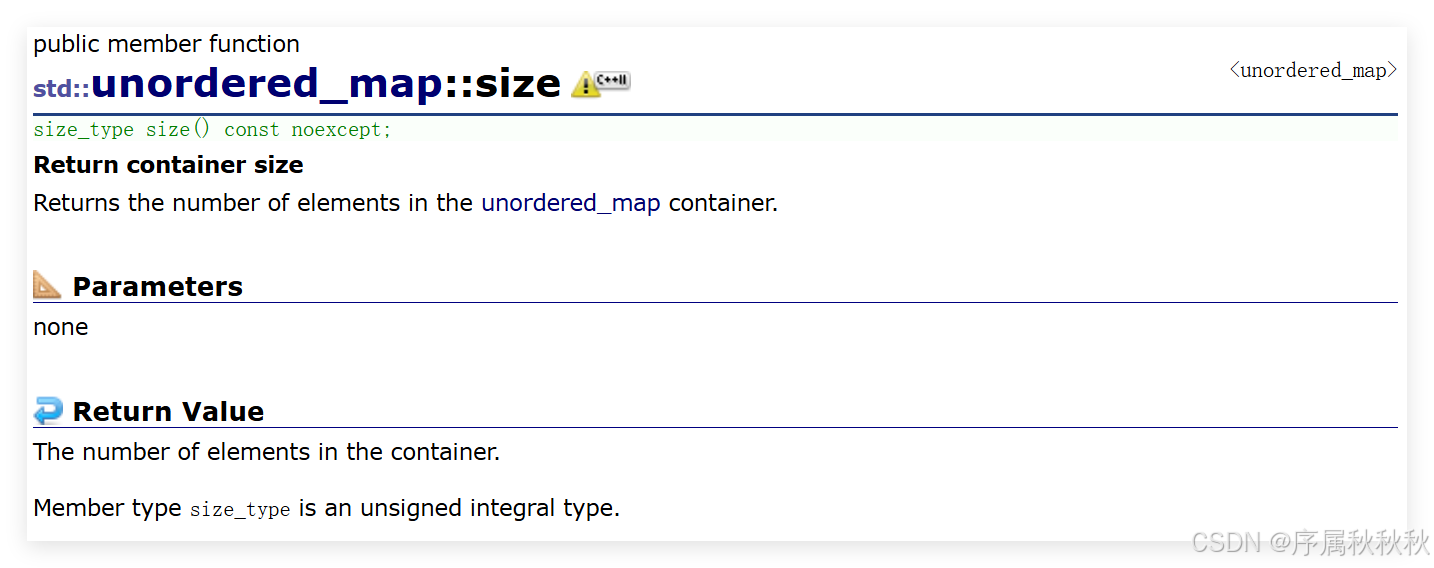
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
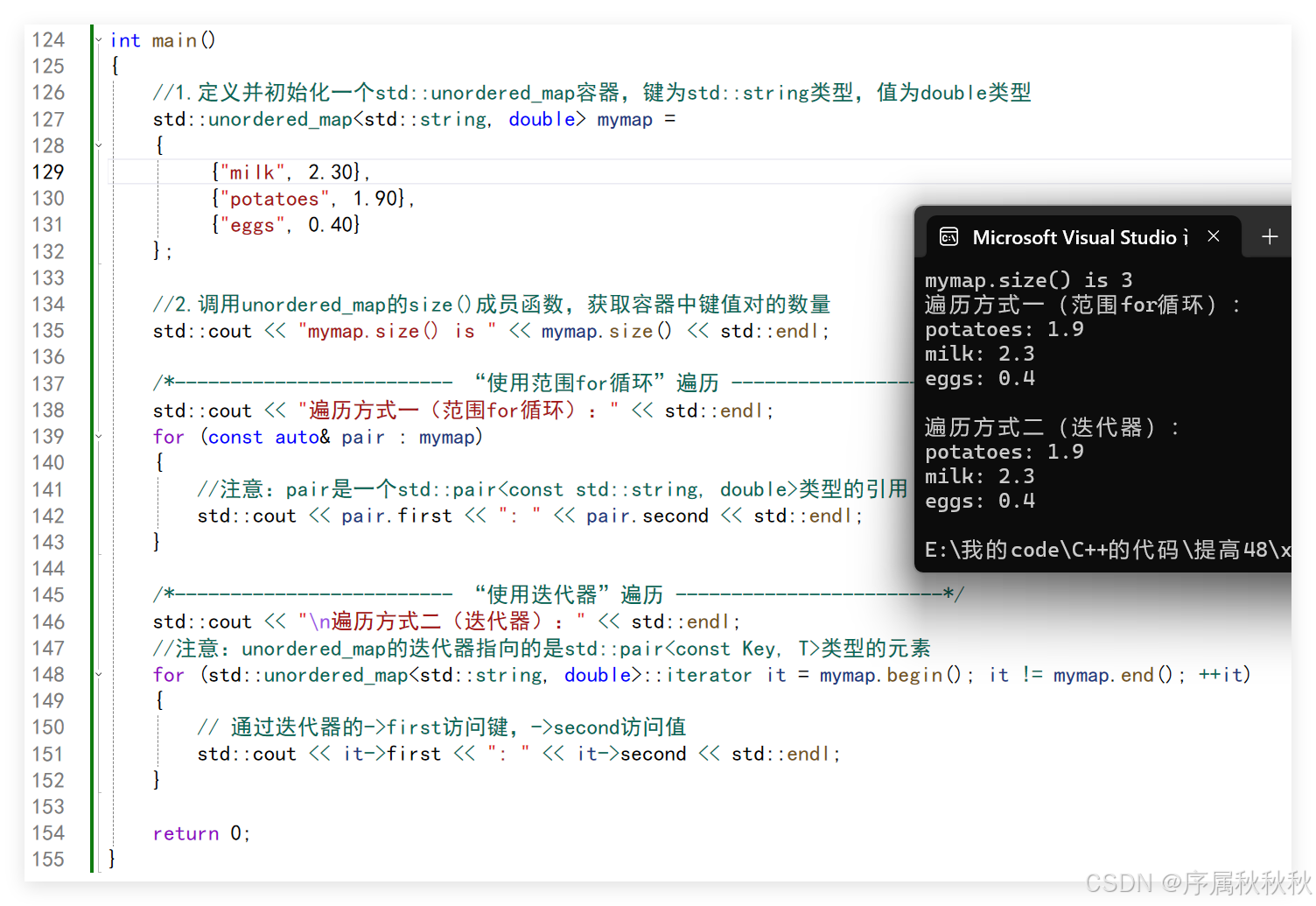
//1.定义并初始化一个std::unordered_map容器,键为std::string类型,值为double类型
std::unordered_map<std::string, double> mymap =
{
{"milk", 2.30},
{"potatoes", 1.90},
{"eggs", 0.40}
};
//2.调用unordered_map的size()成员函数,获取容器中键值对的数量
std::cout << "mymap.size() is " << mymap.size() << std::endl;
/*------------------------- “使用范围for循环”遍历 ------------------------*/
std::cout << "遍历方式一(范围for循环):" << std::endl;
for (const auto& pair : mymap)
{
//注意:pair是一个std::pair<const std::string, double>类型的引用
std::cout << pair.first << ": " << pair.second << std::endl;
}
/*------------------------- “使用迭代器”遍历 ------------------------*/
std::cout << "\n遍历方式二(迭代器):" << std::endl;
//注意:unordered_map的迭代器指向的是std::pair<const Key, T>类型的元素
for (std::unordered_map<std::string, double>::iterator it = mymap.begin(); it != mymap.end(); ++it)
{
// 通过迭代器的->first访问键,->second访问值
std::cout << it->first << ": " << it->second << std::endl;
}
return 0;
}
在这里插入图片描述
std::unordered_map::empty
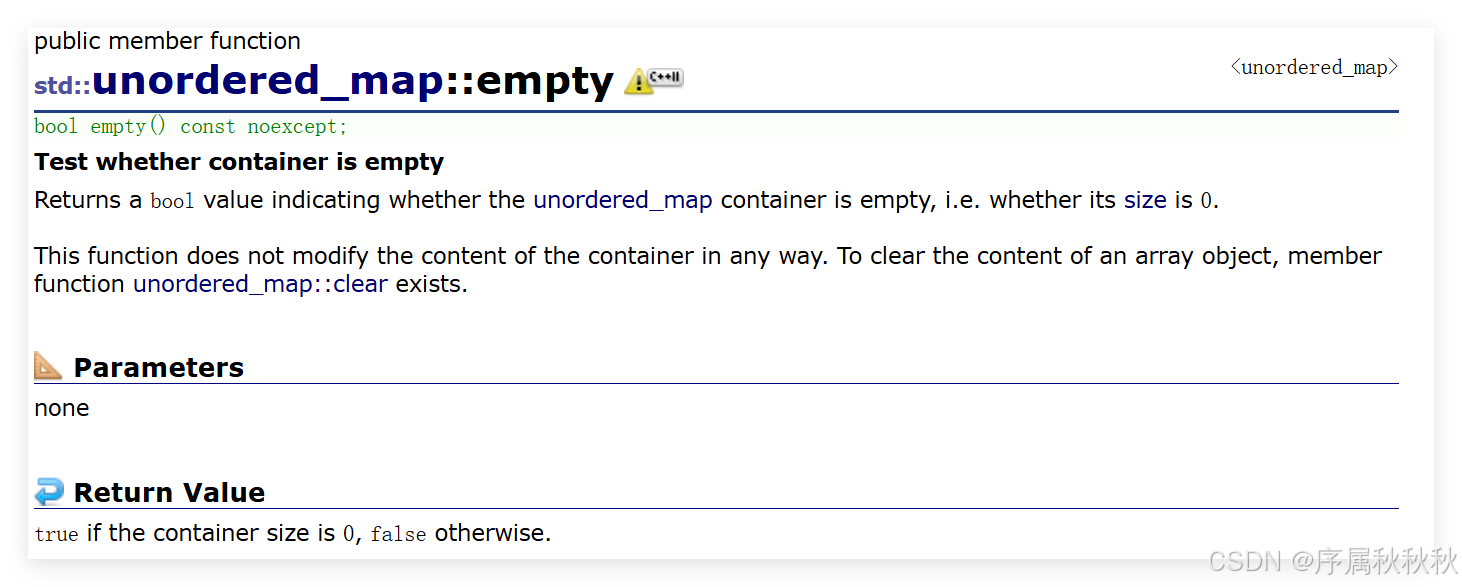
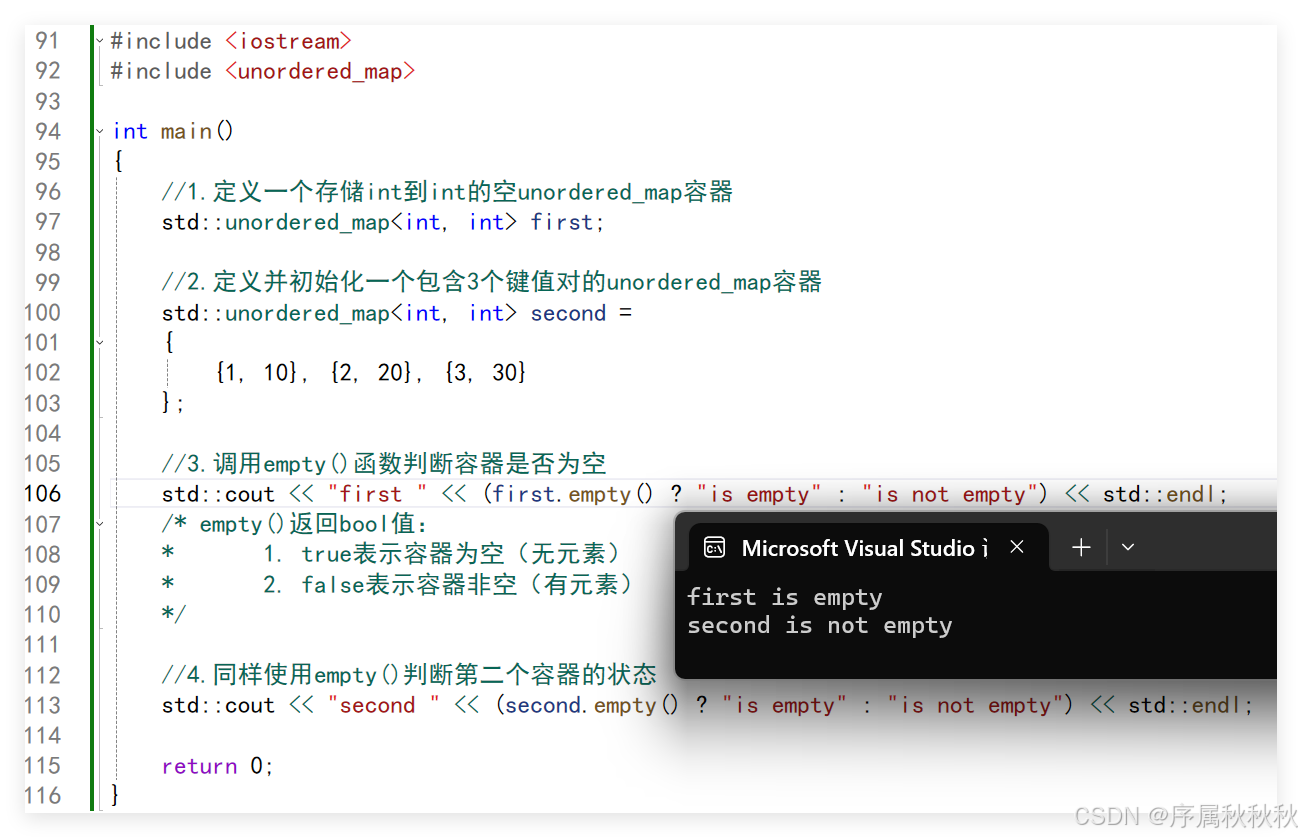
在这里插入图片描述
#include <iostream>
#include <unordered_map>
int main()
{
//1.定义一个存储int到int的空unordered_map容器
std::unordered_map<int, int> first;
//2.定义并初始化一个包含3个键值对的unordered_map容器
std::unordered_map<int, int> second =
{
{1, 10}, {2, 20}, {3, 30}
};
//3.调用empty()函数判断容器是否为空
std::cout << "first " << (first.empty() ? "is empty" : "is not empty") << std::endl;
/* empty()返回bool值:
* 1. true表示容器为空(无元素)
* 2. false表示容器非空(有元素)
*/
//4.同样使用empty()判断第二个容器的状态
std::cout << "second " << (second.empty() ? "is empty" : "is not empty") << std::endl;
return 0;
}
在这里插入图片描述
3. 访问的操作
std::unordered_map::operator[]

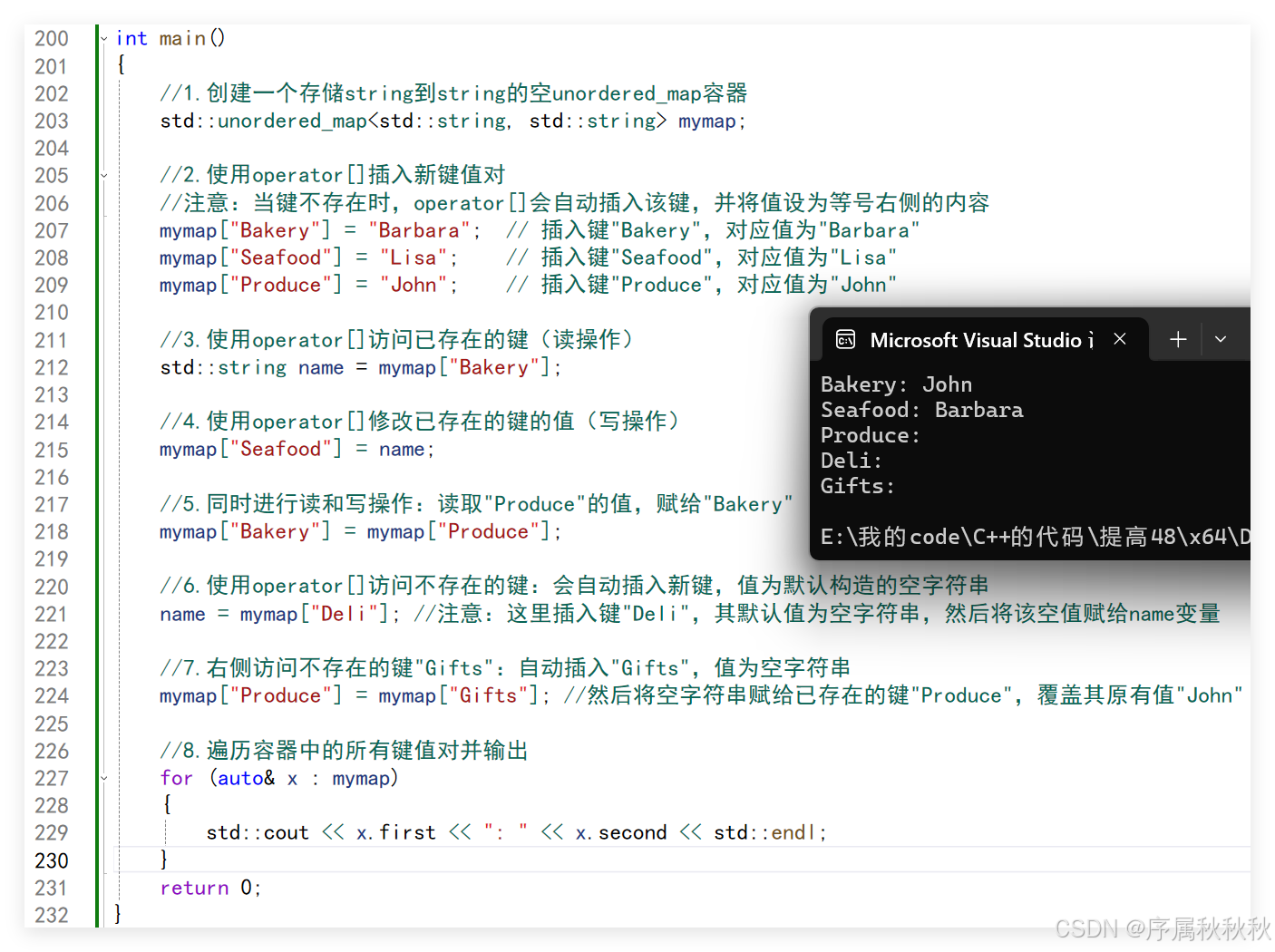
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
//1.创建一个存储string到string的空unordered_map容器
std::unordered_map<std::string, std::string> mymap;
//2.使用operator[]插入新键值对
//注意:当键不存在时,operator[]会自动插入该键,并将值设为等号右侧的内容
mymap["Bakery"] = "Barbara"; // 插入键"Bakery",对应值为"Barbara"
mymap["Seafood"] = "Lisa"; // 插入键"Seafood",对应值为"Lisa"
mymap["Produce"] = "John"; // 插入键"Produce",对应值为"John"
//3.使用operator[]访问已存在的键(读操作)
std::string name = mymap["Bakery"];
//4.使用operator[]修改已存在的键的值(写操作)
mymap["Seafood"] = name;
//5.同时进行读和写操作:读取"Produce"的值,赋给"Bakery"
mymap["Bakery"] = mymap["Produce"];
//6.使用operator[]访问不存在的键:会自动插入新键,值为默认构造的空字符串
name = mymap["Deli"]; //注意:这里插入键"Deli",其默认值为空字符串,然后将该空值赋给name变量
//7.右侧访问不存在的键"Gifts":自动插入"Gifts",值为空字符串
mymap["Produce"] = mymap["Gifts"]; //然后将空字符串赋给已存在的键"Produce",覆盖其原有值"John"
//8.遍历容器中的所有键值对并输出
for (auto& x : mymap)
{
std::cout << x.first << ": " << x.second << std::endl;
}
return 0;
}
在这里插入图片描述
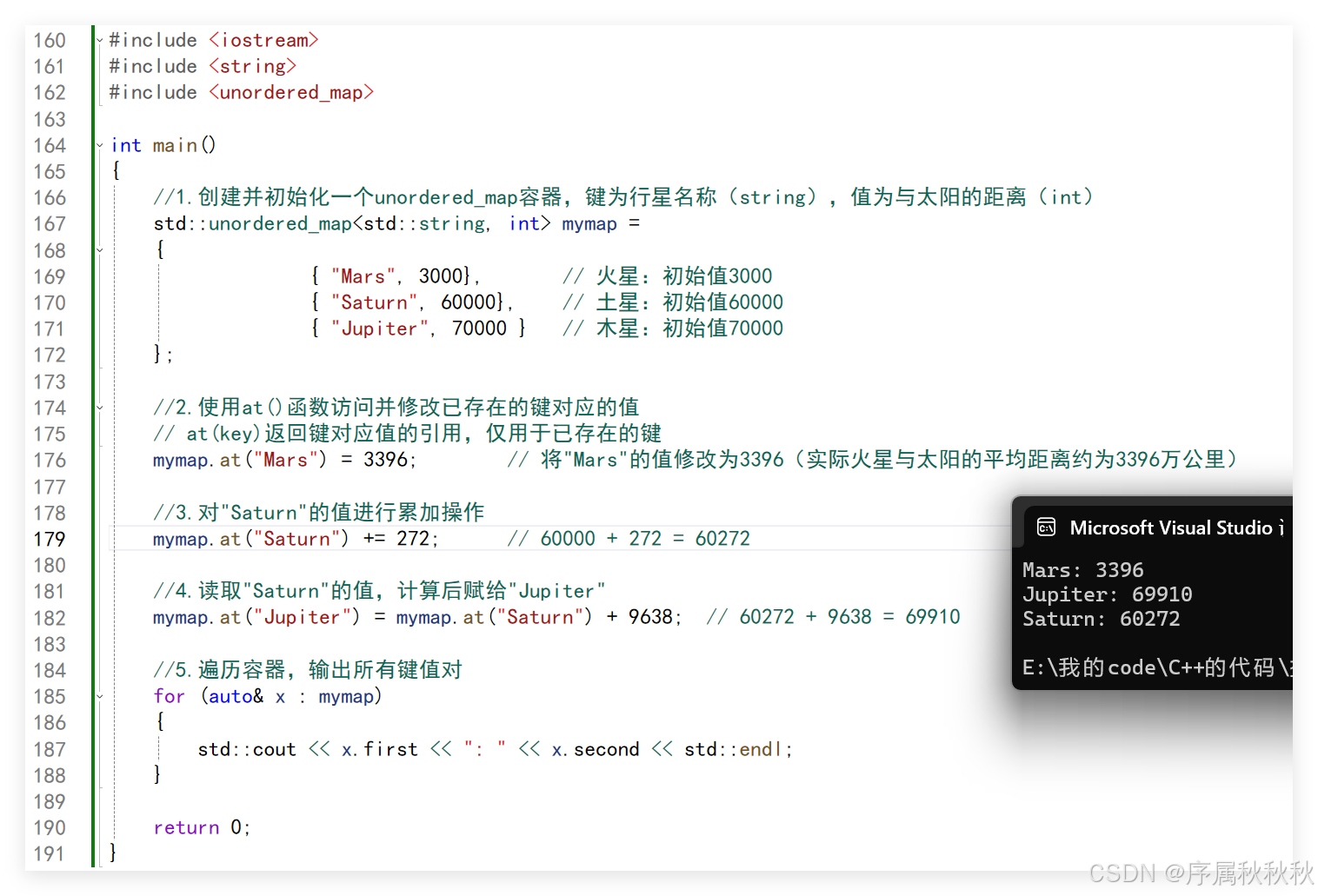
std::unordered_map::at

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
//1.创建并初始化一个unordered_map容器,键为行星名称(string),值为与太阳的距离(int)
std::unordered_map<std::string, int> mymap =
{
{ "Mars", 3000}, // 火星:初始值3000
{ "Saturn", 60000}, // 土星:初始值60000
{ "Jupiter", 70000 } // 木星:初始值70000
};
//2.使用at()函数访问并修改已存在的键对应的值
// at(key)返回键对应值的引用,仅用于已存在的键
mymap.at("Mars") = 3396; // 将"Mars"的值修改为3396(实际火星与太阳的平均距离约为3396万公里)
//3.对"Saturn"的值进行累加操作
mymap.at("Saturn") += 272; // 60000 + 272 = 60272
//4.读取"Saturn"的值,计算后赋给"Jupiter"
mymap.at("Jupiter") = mymap.at("Saturn") + 9638; // 60272 + 9638 = 69910
//5.遍历容器,输出所有键值对
for (auto& x : mymap)
{
std::cout << x.first << ": " << x.second << std::endl;
}
return 0;
}
在这里插入图片描述
std::unordered_map::find
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
//1.创建并初始化一个unordered_map容器
std::unordered_map<std::string, double> mymap =
{
{"mom", 5.4}, // 妈妈的身高:5.4
{"dad", 6.1}, // 爸爸的身高:6.1
{"bro", 5.9} // 兄弟的身高:5.9
};
//2.声明一个字符串变量,用于存储用户的输入
std::string input;
//3.提示用户输入一个家庭成员称呼
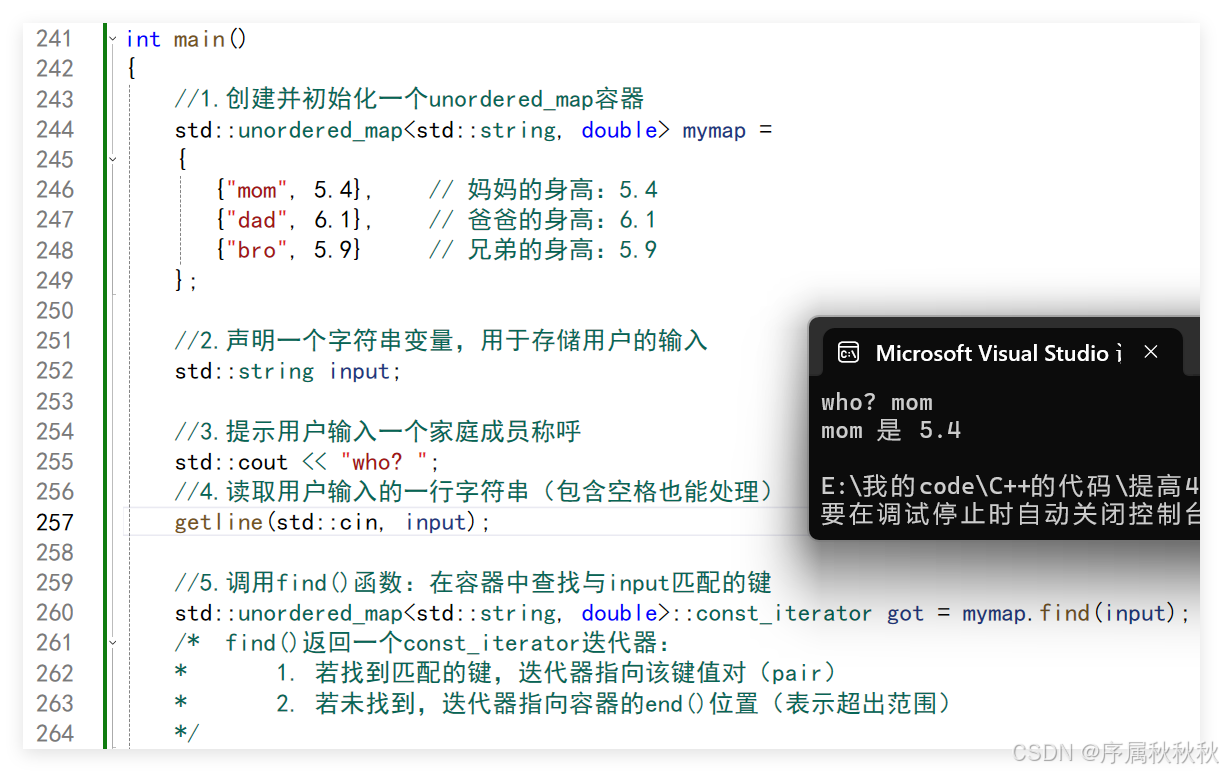
std::cout << "who? ";
//4.读取用户输入的一行字符串(包含空格也能处理)
getline(std::cin, input);
//5.调用find()函数:在容器中查找与input匹配的键
std::unordered_map<std::string, double>::const_iterator got = mymap.find(input);
/* find()返回一个const_iterator迭代器:
* 1. 若找到匹配的键,迭代器指向该键值对(pair)
* 2. 若未找到,迭代器指向容器的end()位置(表示超出范围)
*/
//6.判断查找结果
//6.1: 若迭代器等于end(),表示未找到该键
if (got == mymap.end())
{
std::cout << "没有找到";
}
//6.2:若找到,通过迭代器访问键值对:
else
{
std::cout << got->first << " 是 " << got->second;
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
std::unordered_map::count

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
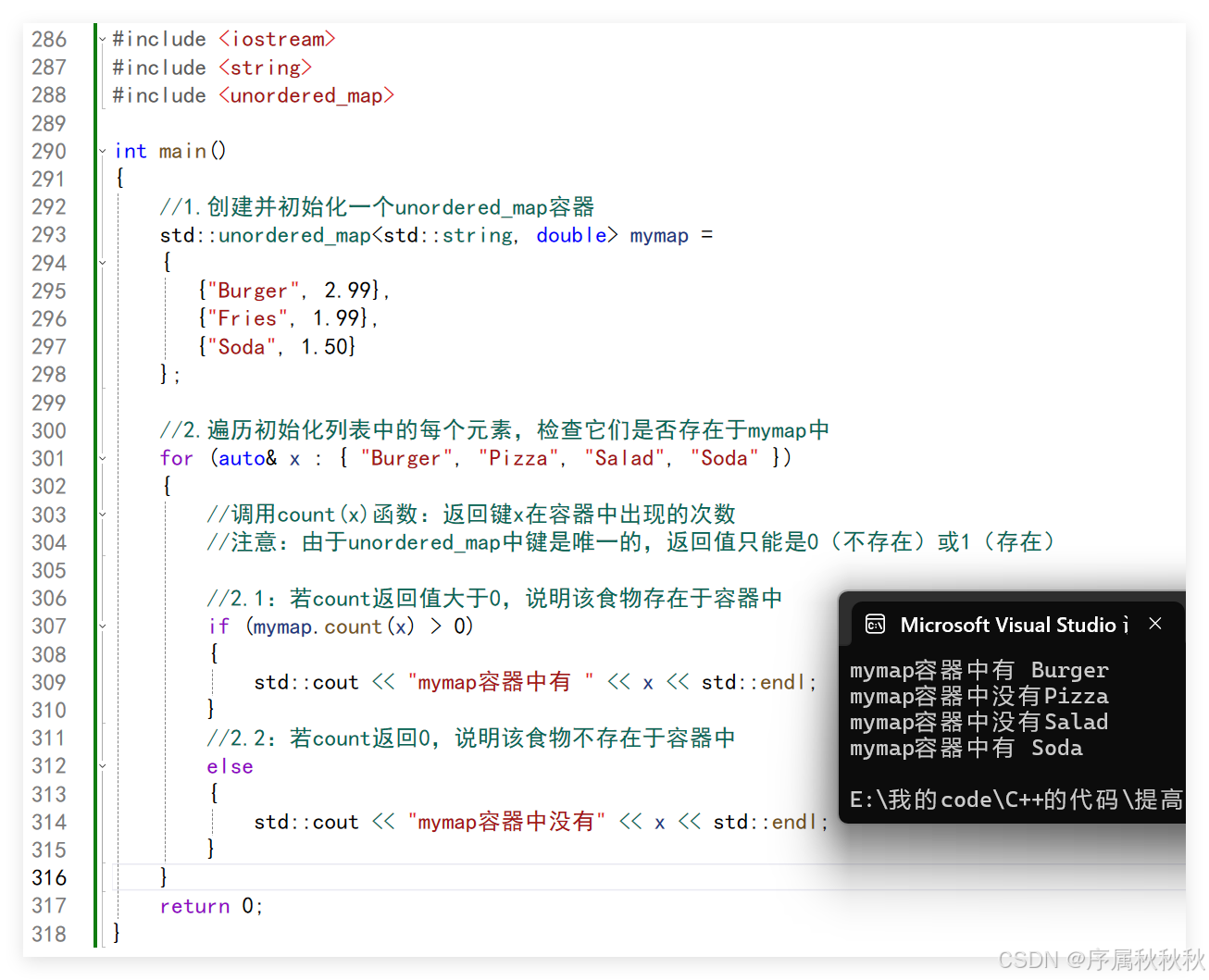
//1.创建并初始化一个unordered_map容器
std::unordered_map<std::string, double> mymap =
{
{"Burger", 2.99},
{"Fries", 1.99},
{"Soda", 1.50}
};
//2.遍历初始化列表中的每个元素,检查它们是否存在于mymap中
for (auto& x : { "Burger", "Pizza", "Salad", "Soda" })
{
//调用count(x)函数:返回键x在容器中出现的次数
//注意:由于unordered_map中键是唯一的,返回值只能是0(不存在)或1(存在)
//2.1:若count返回值大于0,说明该食物存在于容器中
if (mymap.count(x) > 0)
{
std::cout << "mymap容器中有 " << x << std::endl;
}
//2.2:若count返回0,说明该食物不存在于容器中
else
{
std::cout << "mymap容器中没有" << x << std::endl;
}
}
return 0;
}
在这里插入图片描述
4. 修改的操作
std::unordered_map::clear
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
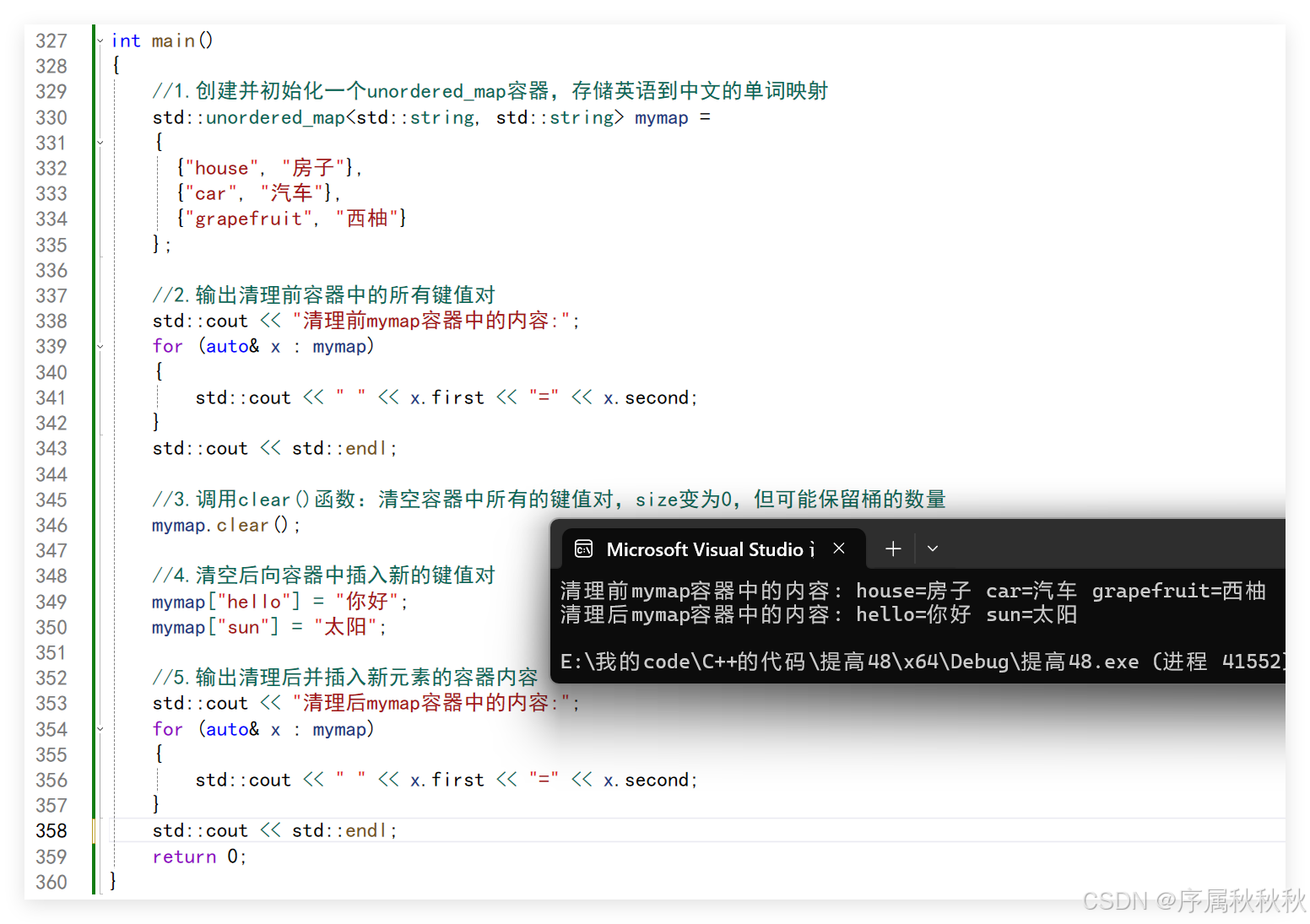
//1.创建并初始化一个unordered_map容器,存储英语到中文的单词映射
std::unordered_map<std::string, std::string> mymap =
{
{"house", "房子"},
{"car", "汽车"},
{"grapefruit", "西柚"}
};
//2.输出清理前容器中的所有键值对
std::cout << "清理前mymap容器中的内容:";
for (auto& x : mymap)
{
std::cout << " " << x.first << "=" << x.second;
}
std::cout << std::endl;
//3.调用clear()函数:清空容器中所有的键值对,size变为0,但可能保留桶的数量
mymap.clear();
//4.清空后向容器中插入新的键值对
mymap["hello"] = "你好";
mymap["sun"] = "太阳";
//5.输出清理后并插入新元素的容器内容
std::cout << "清理后mymap容器中的内容:";
for (auto& x : mymap)
{
std::cout << " " << x.first << "=" << x.second;
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
std::unordered_map::swap
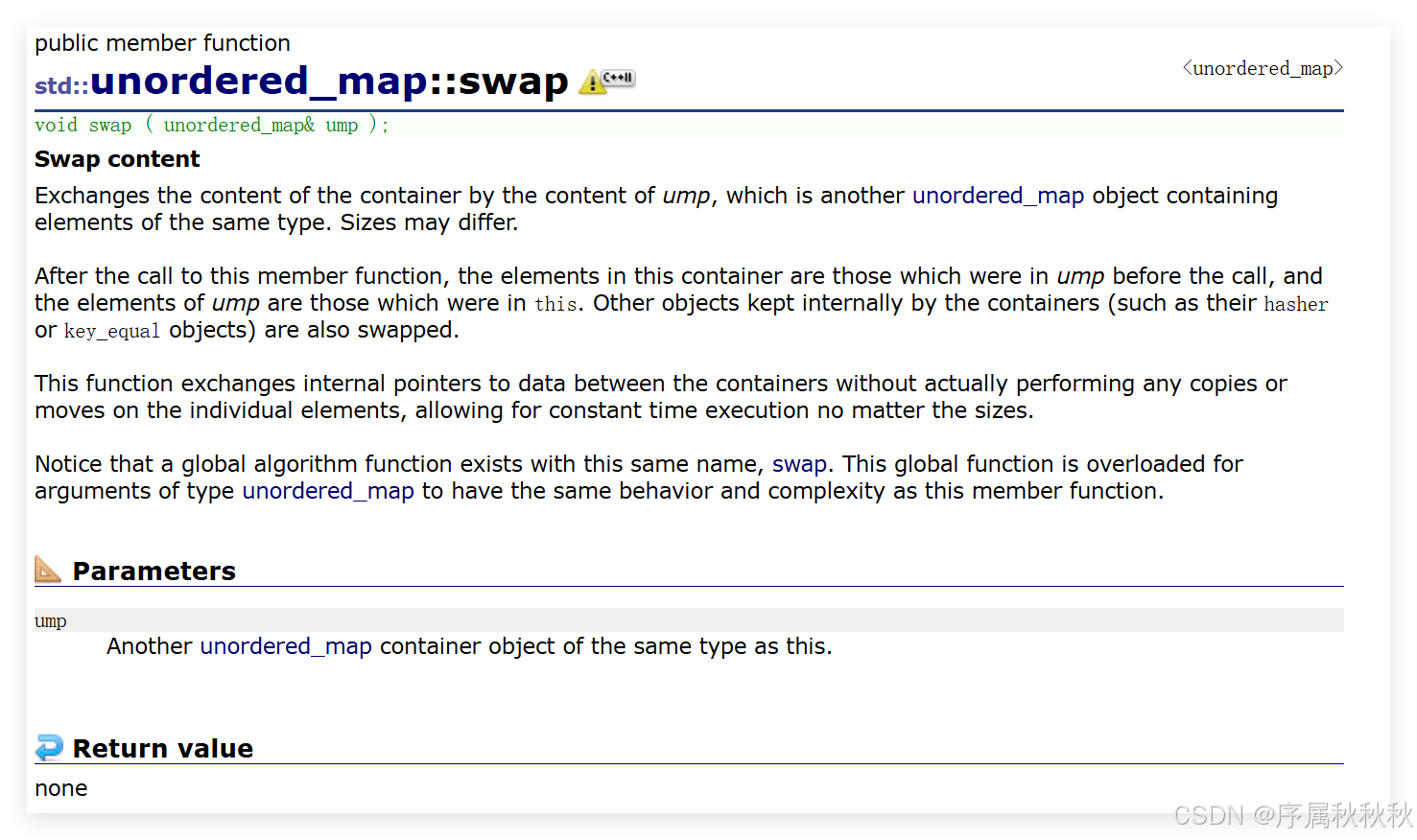
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
//1.创建并初始化两个unordered_map容器,存储电影名称到导演姓名的映射
std::unordered_map<std::string, std::string>
first =
{
{"Star Wars", "G. Lucas"}, // 《星球大战》导演:G. Lucas
{"Alien", "R. Scott"}, // 《异形》导演:R. Scott
{"Terminator", "J. Cameron"} // 《终结者》导演:J. Cameron
},
second =
{
{"Inception", "C. Nolan"}, // 《盗梦空间》导演:C. Nolan
{"Donnie Darko", "R. Kelly"} // 《死亡幻觉》导演:R. Kelly
};
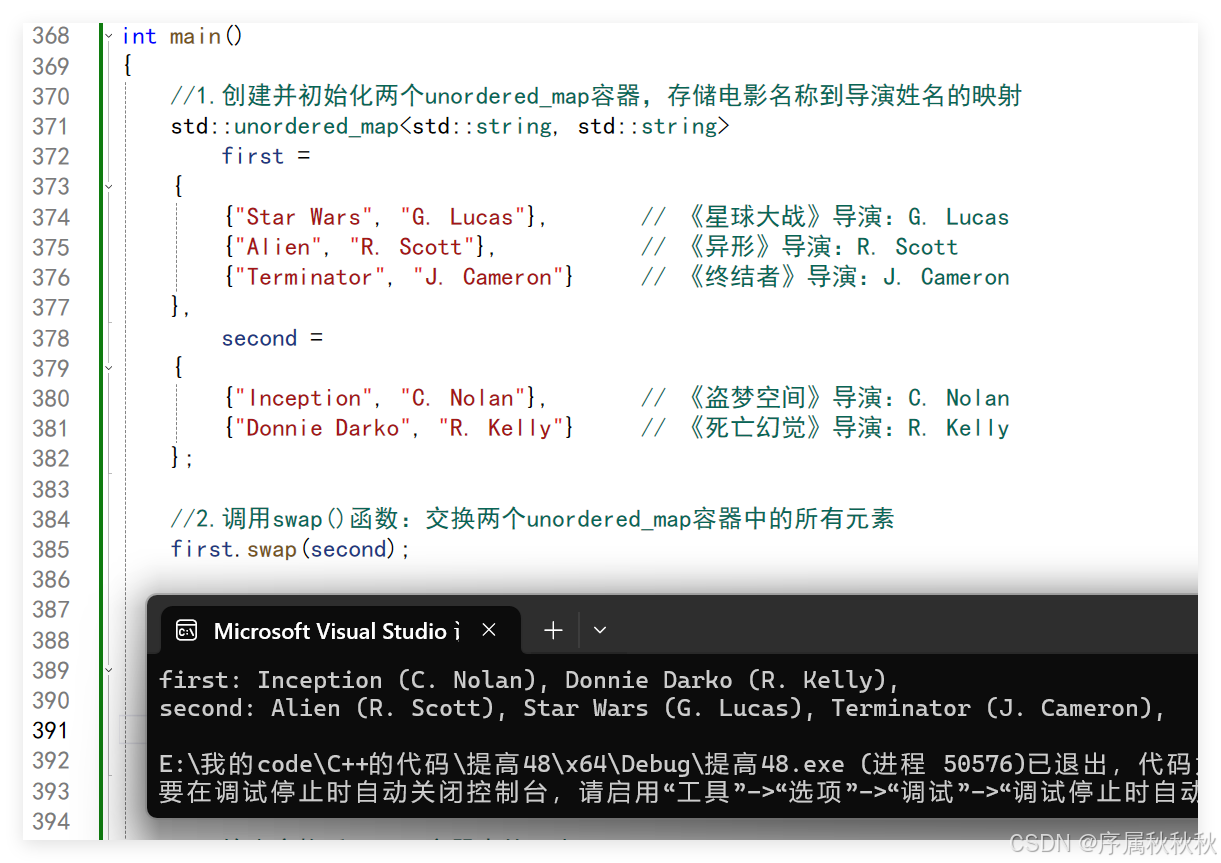
//2.调用swap()函数:交换两个unordered_map容器中的所有元素
first.swap(second);
//3.输出交换后first容器中的元素
std::cout << "first: ";
for (auto& x : first)
{
std::cout << x.first << " (" << x.second << "), ";
}
std::cout << std::endl;
//4.输出交换后second容器中的元素
std::cout << "second: ";
for (auto& x : second)
{
std::cout << x.first << " (" << x.second << "), ";
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
std::unordered_map::insert
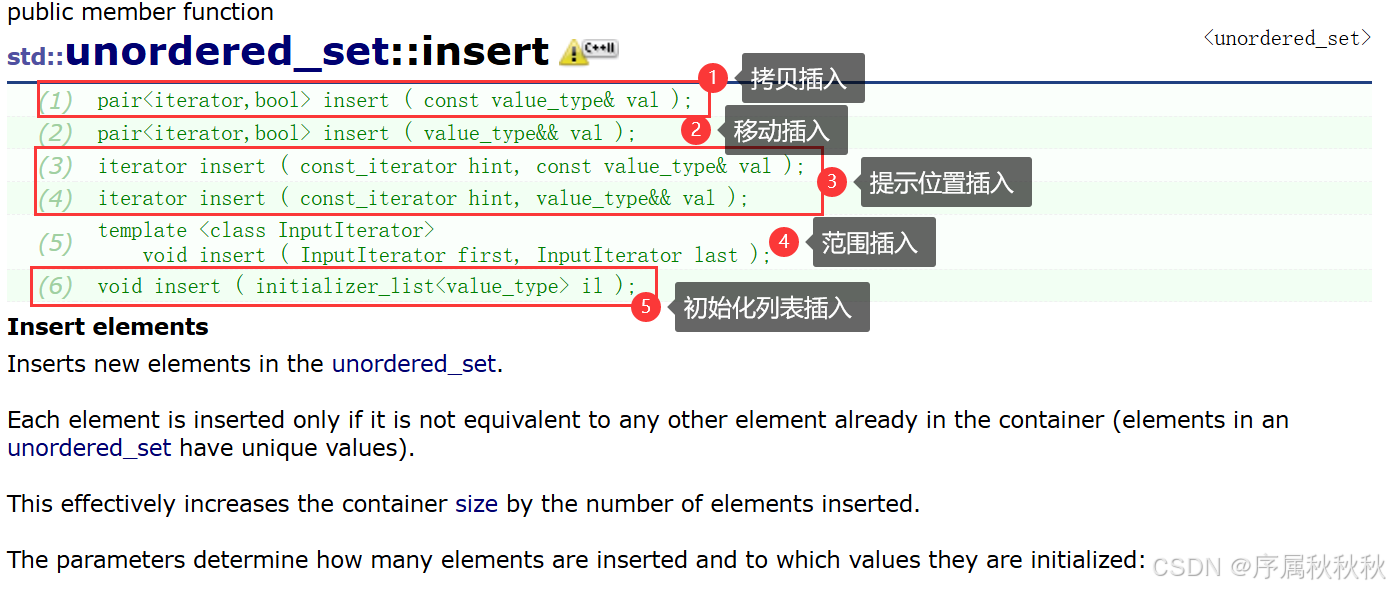
在这里插入图片描述
#include <iostream>
#include <string>
#include <array>
#include <unordered_set>
int main()
{
//1.创建并初始化一个unordered_set容器,存储3种颜色字符串
std::unordered_set<std::string> myset = { "yellow", "green", "blue" };
//2.创建一个包含两个字符串元素的array容器,存储另外两种颜色
std::array<std::string, 2> myarray = { "black", "white" };
//3.定义一个字符串变量,存储一种颜色
std::string mystring = "red";
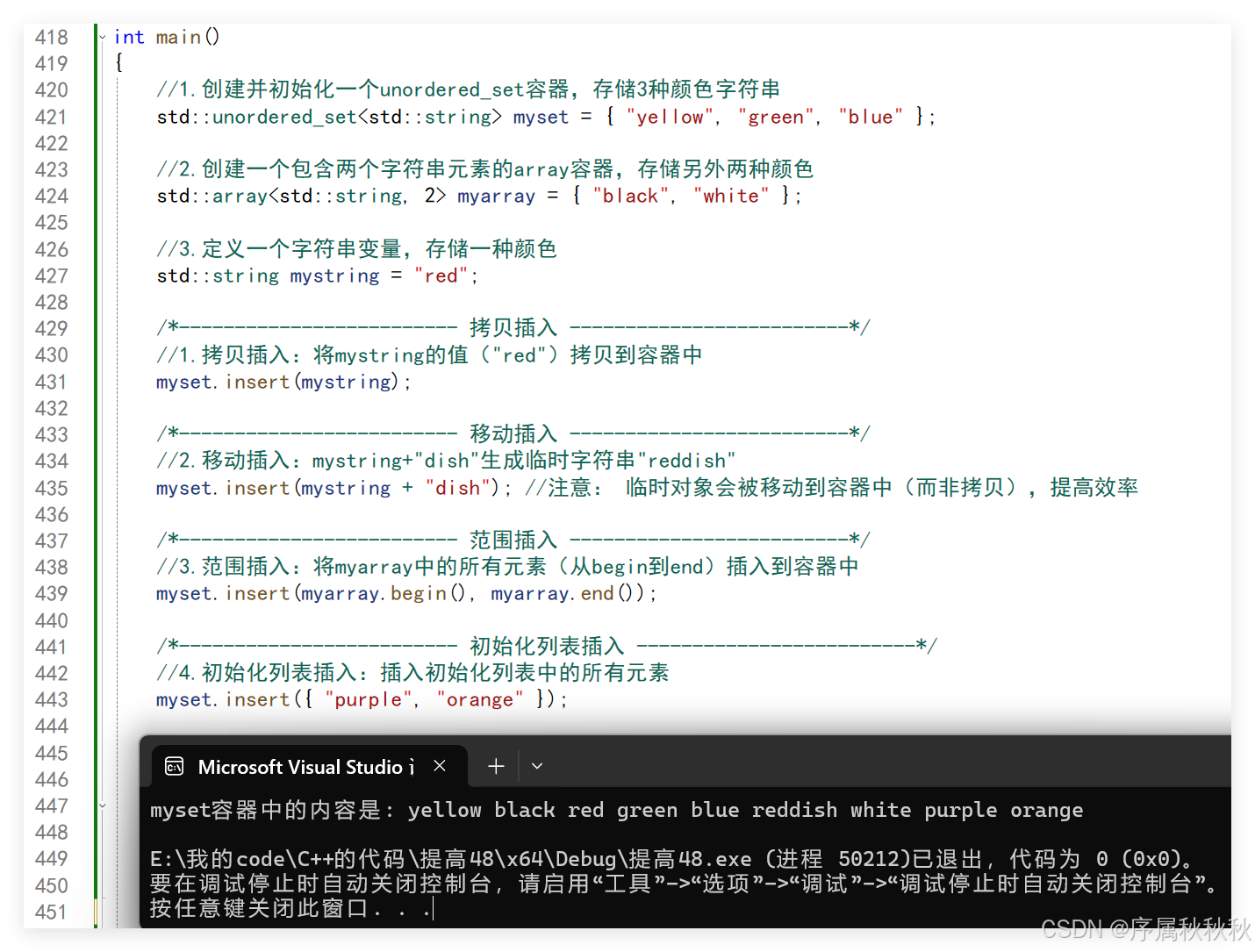
/*------------------------- 拷贝插入 -------------------------*/
//1.拷贝插入:将mystring的值("red")拷贝到容器中
myset.insert(mystring);
/*------------------------- 移动插入 -------------------------*/
//2.移动插入:mystring+"dish"生成临时字符串"reddish"
myset.insert(mystring + "dish"); //注意: 临时对象会被移动到容器中(而非拷贝),提高效率
/*------------------------- 范围插入 -------------------------*/
//3.范围插入:将myarray中的所有元素(从begin到end)插入到容器中
myset.insert(myarray.begin(), myarray.end());
/*------------------------- 初始化列表插入 -------------------------*/
//4.初始化列表插入:插入初始化列表中的所有元素
myset.insert({ "purple", "orange" });
//4.输出容器中所有的元素
std::cout << "myset容器中的内容是:";
for (const std::string& x : myset)
{
std::cout << " " << x;
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
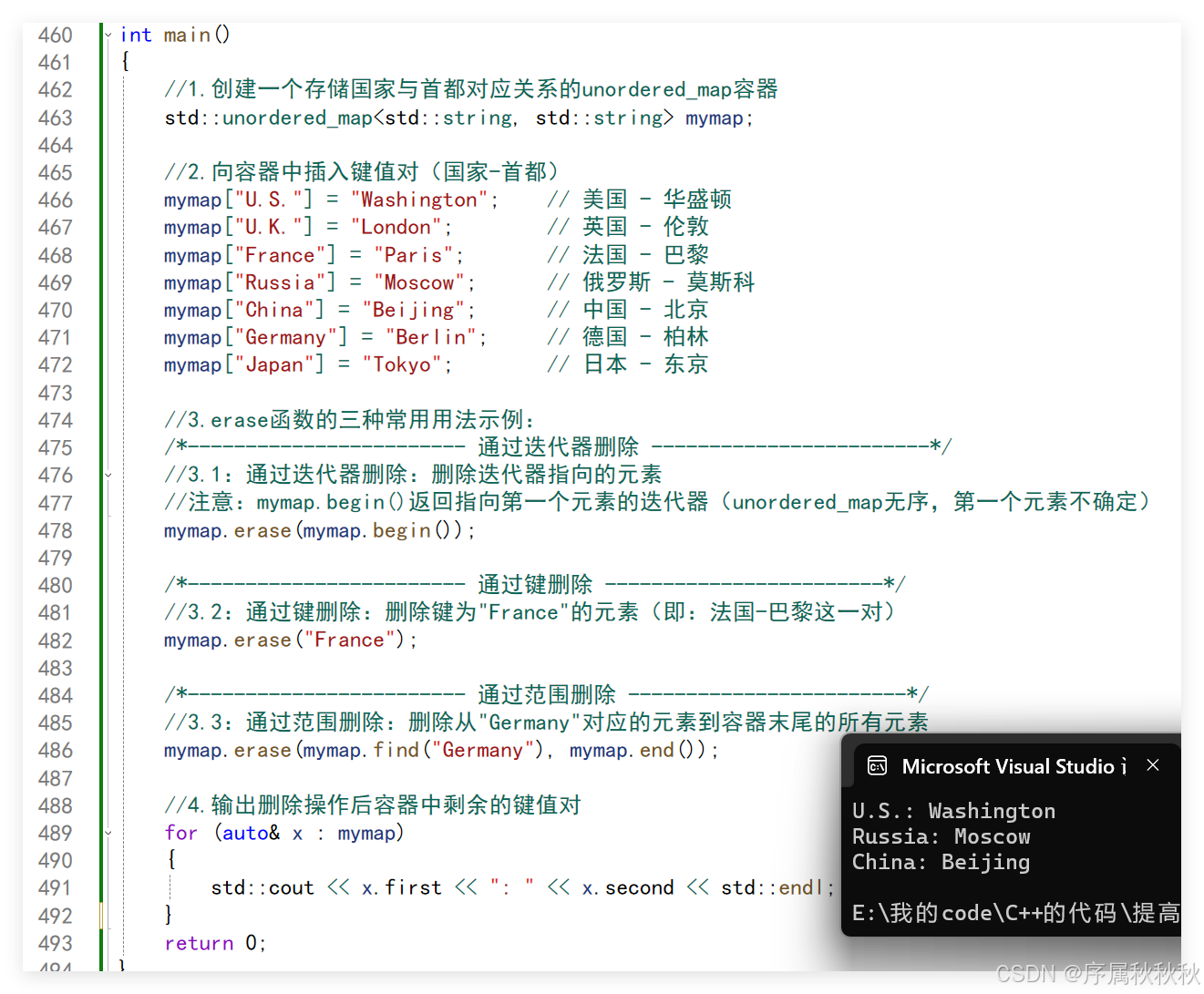
std::unordered_map::erase

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
//1.创建一个存储国家与首都对应关系的unordered_map容器
std::unordered_map<std::string, std::string> mymap;
//2.向容器中插入键值对(国家-首都)
mymap["U.S."] = "Washington"; // 美国 - 华盛顿
mymap["U.K."] = "London"; // 英国 - 伦敦
mymap["France"] = "Paris"; // 法国 - 巴黎
mymap["Russia"] = "Moscow"; // 俄罗斯 - 莫斯科
mymap["China"] = "Beijing"; // 中国 - 北京
mymap["Germany"] = "Berlin"; // 德国 - 柏林
mymap["Japan"] = "Tokyo"; // 日本 - 东京
//3.erase函数的三种常用用法示例:
/*------------------------ 通过迭代器删除 ------------------------*/
//3.1:通过迭代器删除:删除迭代器指向的元素
//注意:mymap.begin()返回指向第一个元素的迭代器(unordered_map无序,第一个元素不确定)
mymap.erase(mymap.begin());
/*------------------------ 通过键删除 ------------------------*/
//3.2:通过键删除:删除键为"France"的元素(即:法国-巴黎这一对)
mymap.erase("France");
/*------------------------ 通过范围删除 ------------------------*/
//3.3:通过范围删除:删除从"Germany"对应的元素到容器末尾的所有元素
mymap.erase(mymap.find("Germany"), mymap.end());
//4.输出删除操作后容器中剩余的键值对
for (auto& x : mymap)
{
std::cout << x.first << ": " << x.second << std::endl;
}
return 0;
}
在这里插入图片描述
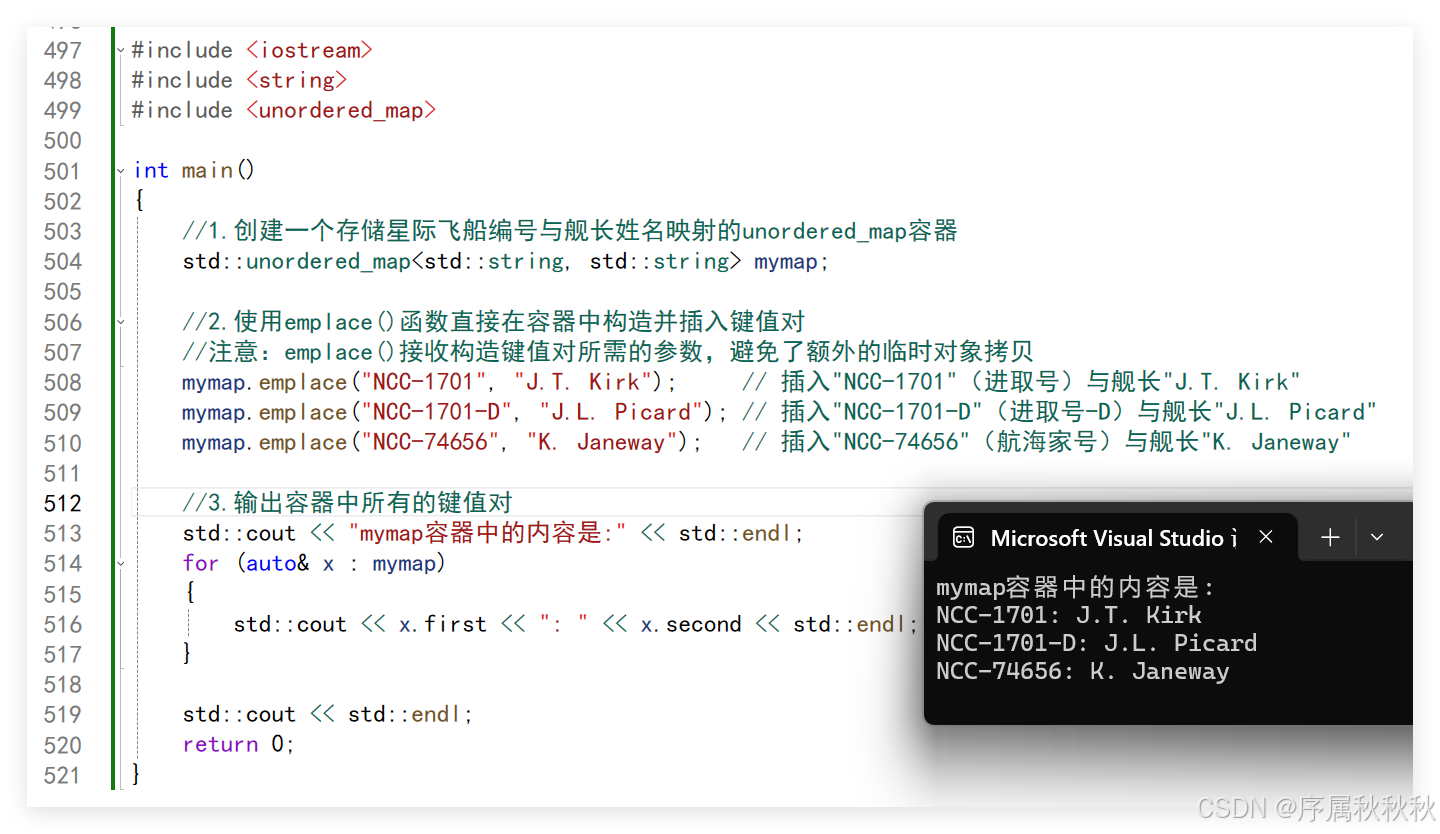
std::unordered_map::emplace
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
//1.创建一个存储星际飞船编号与舰长姓名映射的unordered_map容器
std::unordered_map<std::string, std::string> mymap;
//2.使用emplace()函数直接在容器中构造并插入键值对
//注意:emplace()接收构造键值对所需的参数,避免了额外的临时对象拷贝
mymap.emplace("NCC-1701", "J.T. Kirk"); // 插入"NCC-1701"(进取号)与舰长"J.T. Kirk"
mymap.emplace("NCC-1701-D", "J.L. Picard"); // 插入"NCC-1701-D"(进取号-D)与舰长"J.L. Picard"
mymap.emplace("NCC-74656", "K. Janeway"); // 插入"NCC-74656"(航海家号)与舰长"K. Janeway"
//3.输出容器中所有的键值对
std::cout << "mymap容器中的内容是:" << std::endl;
for (auto& x : mymap)
{
std::cout << x.first << ": " << x.second << std::endl;
}
std::cout << std::endl;
return 0;
}
在这里插入图片描述
5. 哈希桶操作
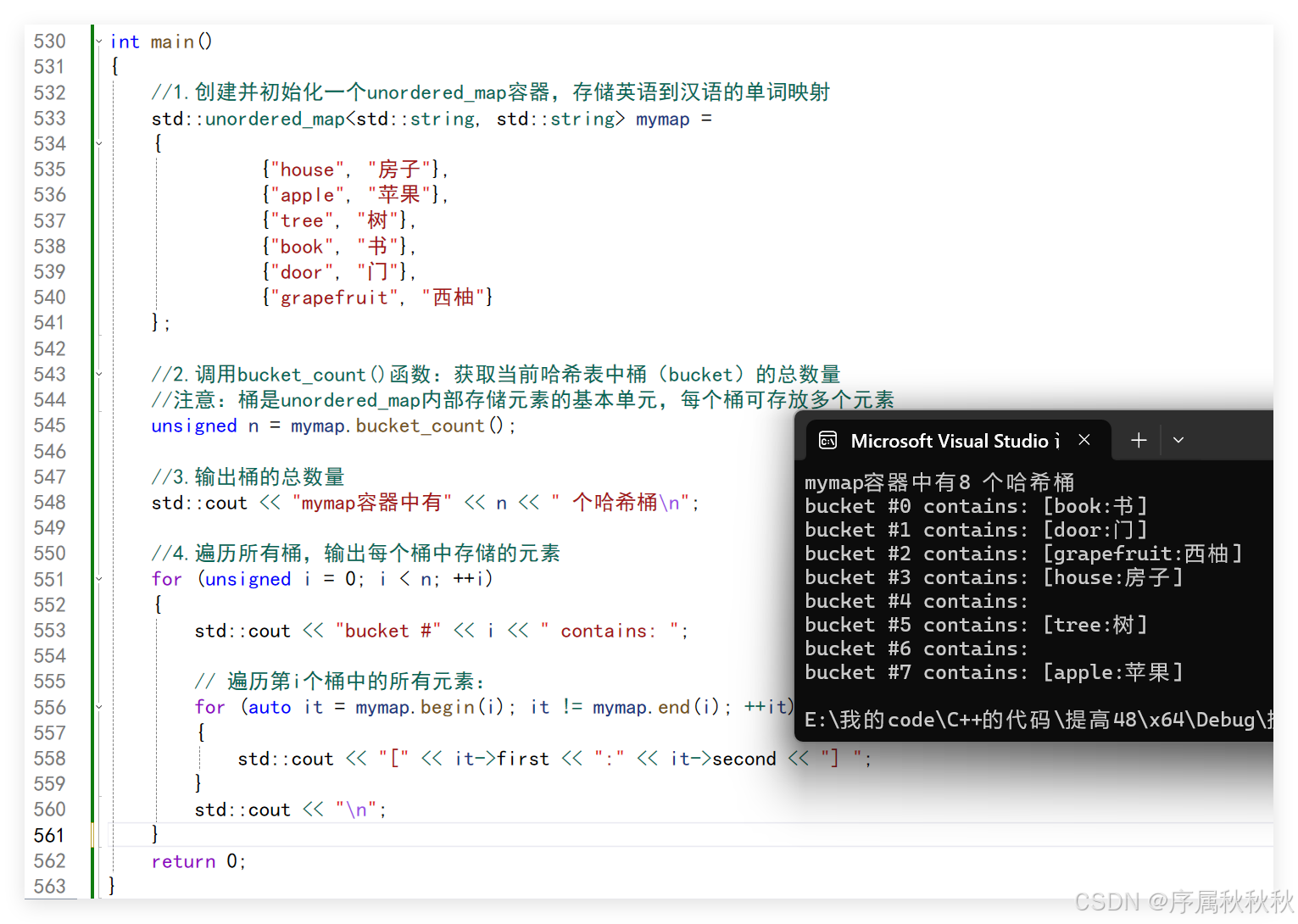
std::unordered_map::bucket_count

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
//1.创建并初始化一个unordered_map容器,存储英语到汉语的单词映射
std::unordered_map<std::string, std::string> mymap =
{
{"house", "房子"},
{"apple", "苹果"},
{"tree", "树"},
{"book", "书"},
{"door", "门"},
{"grapefruit", "西柚"}
};
//2.调用bucket_count()函数:获取当前哈希表中桶(bucket)的总数量
//注意:桶是unordered_map内部存储元素的基本单元,每个桶可存放多个元素
unsigned n = mymap.bucket_count();
//3.输出桶的总数量
std::cout << "mymap容器中有" << n << " 个哈希桶\n";
//4.遍历所有桶,输出每个桶中存储的元素
for (unsigned i = 0; i < n; ++i)
{
std::cout << "bucket #" << i << " contains: ";
// 遍历第i个桶中的所有元素:
for (auto it = mymap.begin(i); it != mymap.end(i); ++it)
{
std::cout << "[" << it->first << ":" << it->second << "] ";
}
std::cout << "\n";
}
return 0;
}
在这里插入图片描述
std::unordered_map::bucket_size
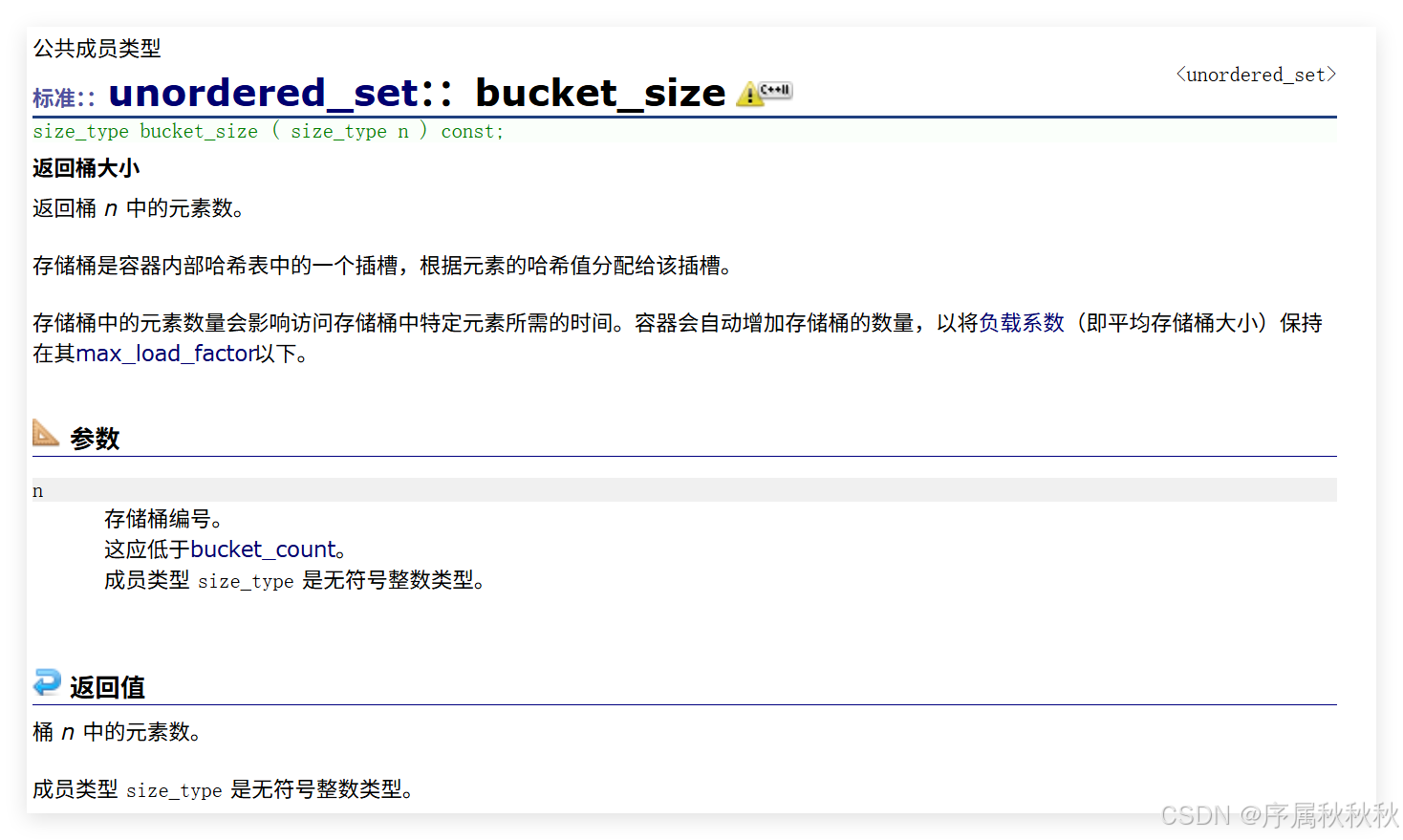
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
//1.创建并初始化一个unordered_set容器,存储多种颜色字符串
std::unordered_set<std::string> myset =
{
"red", "green", "blue",
"yellow", "purple", "pink"
};
//2.调用bucket_count()函数:获取当前哈希表中桶(bucket)的总数量
unsigned nbuckets = myset.bucket_count();
//3.输出桶的总数量
std::cout << "myset容器中有 " << nbuckets << "个哈希桶\n";
//4.遍历所有桶,输出每个桶中包含的元素数量
for (unsigned i = 0; i < nbuckets; ++i)
{
// 调用bucket_size(i)函数:获取第i个桶中存储的元素数量
std::cout << "bucket #" << i << " 有 " << myset.bucket_size(i) << "个元素\n";
}
return 0;
}
在这里插入图片描述
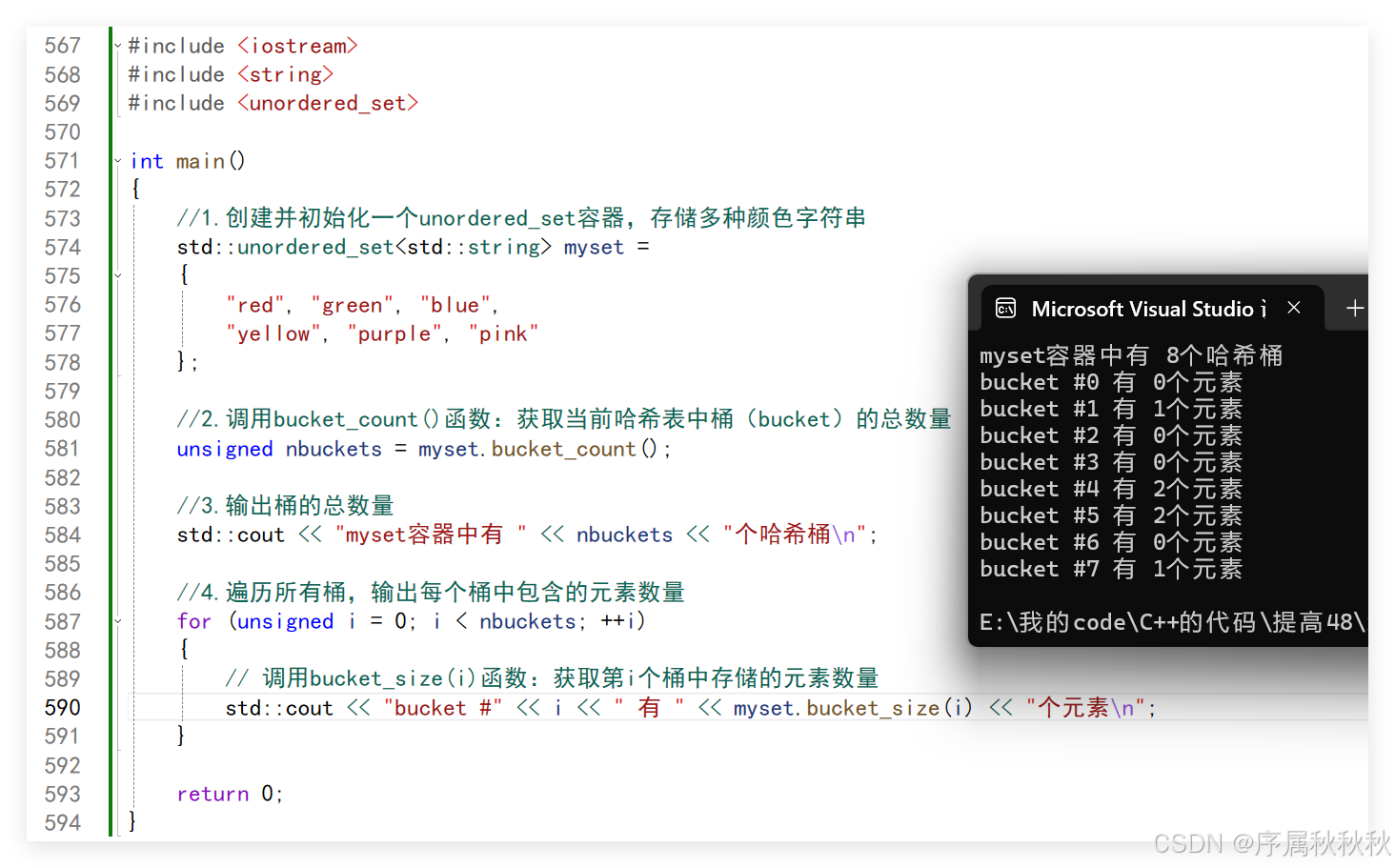
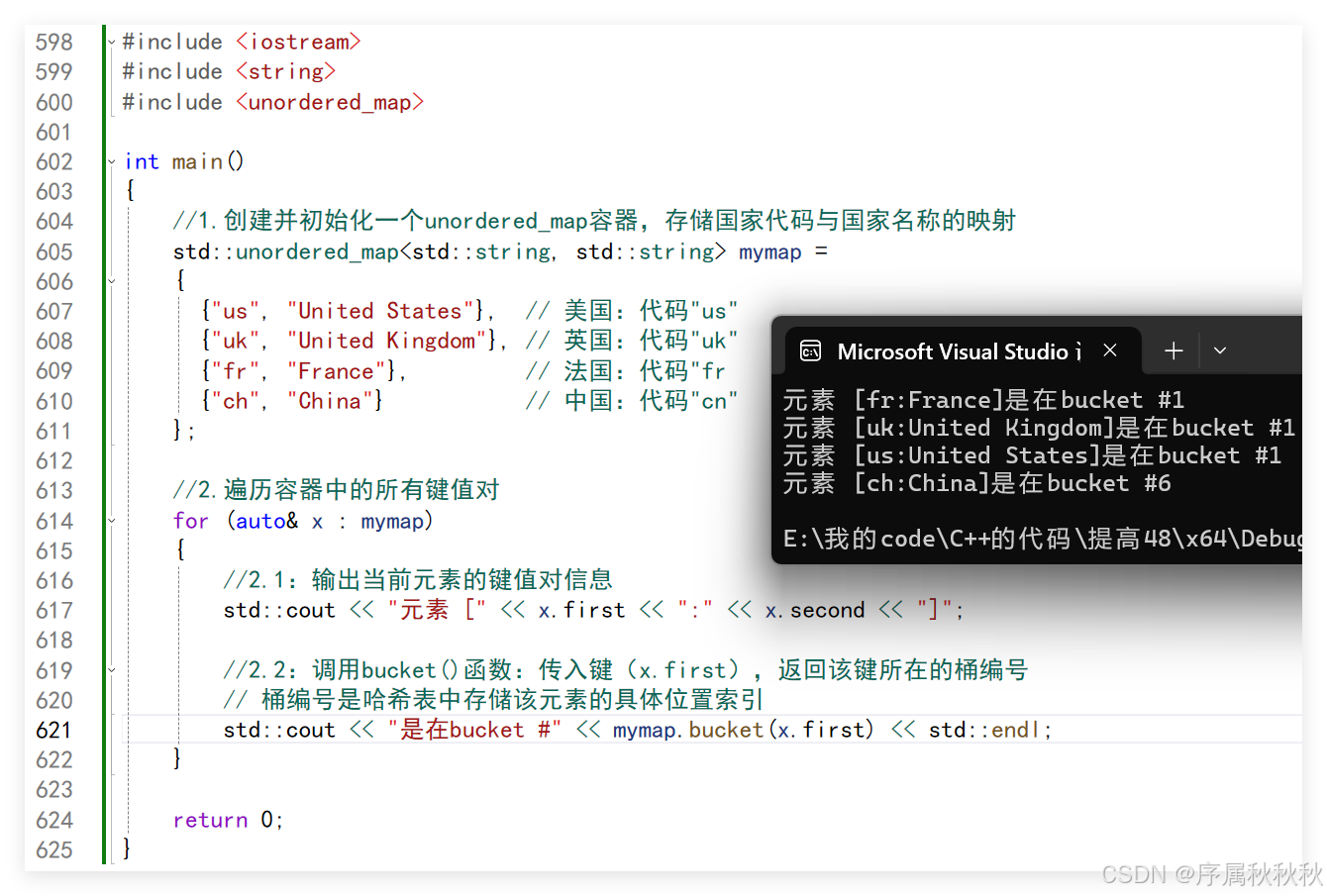
std::unordered_map::bucket

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
//1.创建并初始化一个unordered_map容器,存储国家代码与国家名称的映射
std::unordered_map<std::string, std::string> mymap =
{
{"us", "United States"}, // 美国:代码"us"
{"uk", "United Kingdom"}, // 英国:代码"uk"
{"fr", "France"}, // 法国:代码"fr
{"ch", "China"} // 中国:代码"cn"
};
//2.遍历容器中的所有键值对
for (auto& x : mymap)
{
//2.1:输出当前元素的键值对信息
std::cout << "元素 [" << x.first << ":" << x.second << "]";
//2.2:调用bucket()函数:传入键(x.first),返回该键所在的桶编号
// 桶编号是哈希表中存储该元素的具体位置索引
std::cout << "是在bucket #" << mymap.bucket(x.first) << std::endl;
}
return 0;
}
在这里插入图片描述
6. 哈希的策略
std::unordered_map::load_factor
在这里插入图片描述
#include <iostream>
#include <unordered_map>
int main()
{
//1.创建一个存储int到int映射的空unordered_map容器
std::unordered_map<int, int> mymap;
//2.size():返回容器中当前存储的键值对数量
std::cout << "size = " << mymap.size() << std::endl;
//3.bucket_count():返回哈希表中当前的桶(bucket)总数量
//注意:桶是哈希表存储元素的基本单元,即使容器为空,也会预分配一定数量的桶
std::cout << "bucket_count = " << mymap.bucket_count() << std::endl;
//4.load_factor():返回当前哈希表的负载因子
std::cout << "load_factor = " << mymap.load_factor() << std::endl;
/* 说明:
* 1. 负载因子 = 元素数量(size) / 桶数量(bucket_count)
* 2. 用于衡量哈希表的拥挤程度,空容器的负载因子为0.0
*/
//5.max_load_factor():返回哈希表的最大负载因子(阈值)
// 当实际负载因子超过该阈值时,哈希表会自动扩容(增加桶数量)并重建,以减少哈希冲突
std::cout << "max_load_factor = " << mymap.max_load_factor() << std::endl;
return 0;
}
在这里插入图片描述
std::unordered_map::rehash

在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_set>
int main()
{
//1.创建一个存储字符串的空unordered_set容器
std::unordered_set<std::string> myset;
//2.调用rehash(12)函数:强制将哈希表的桶数量调整为至少12个
myset.rehash(12);
/* 说明:
* 1. 若当前桶数量小于12,则扩容到12;若已大于等于12,则可能保持不变(取决于实现)
* 2. 该操作会触发哈希表重建,重新分配元素到新的桶中
*/
//3.向容器中插入多个字符串元素(表示不同的场所)
myset.insert("office"); // 办公室
myset.insert("house"); // 房子
myset.insert("gym"); // 健身房
myset.insert("parking"); // 停车场
myset.insert("highway"); // 高速公路
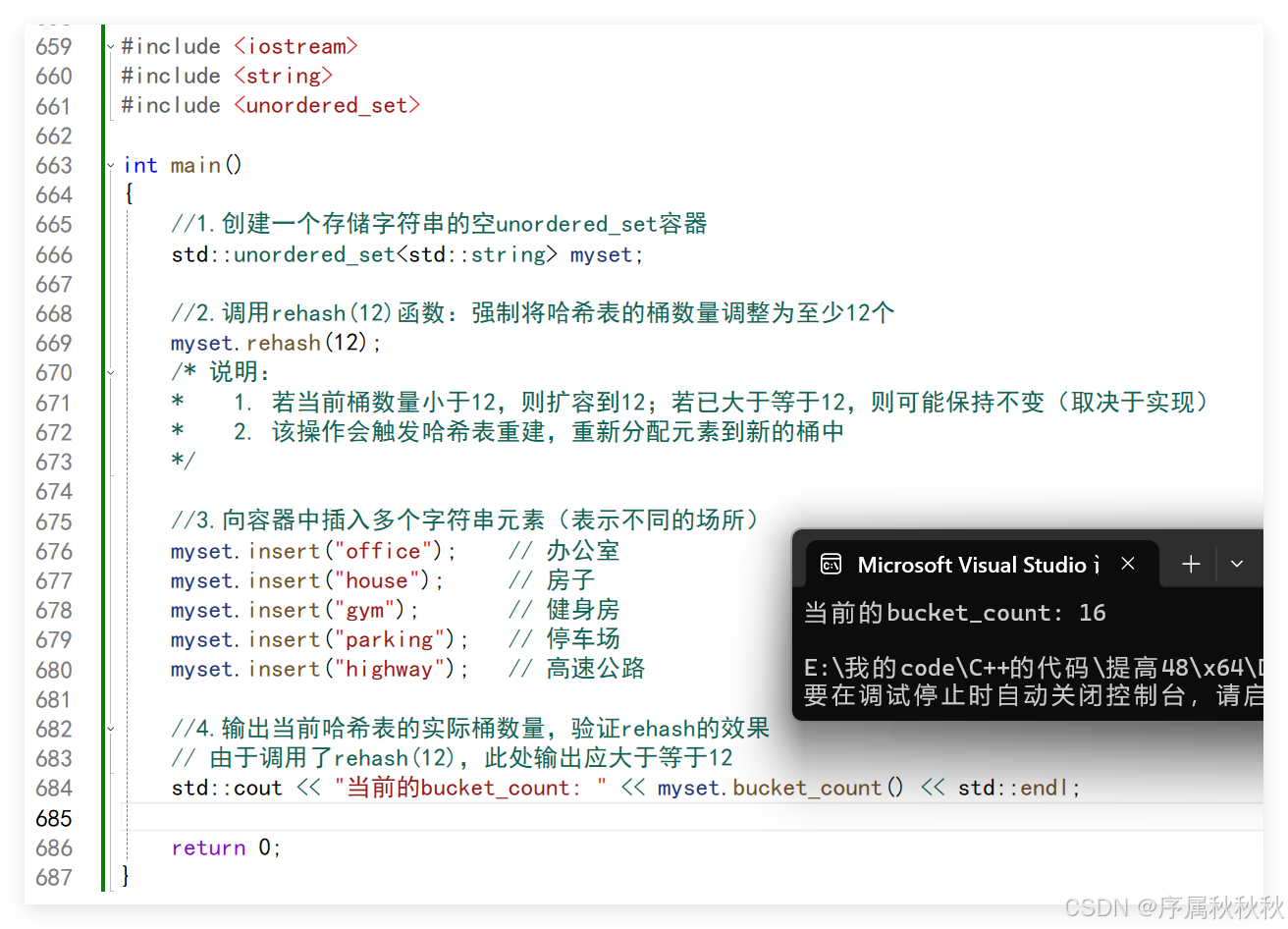
//4.输出当前哈希表的实际桶数量,验证rehash的效果
// 由于调用了rehash(12),此处输出应大于等于12
std::cout << "当前的bucket_count: " << myset.bucket_count() << std::endl;
return 0;
}
在这里插入图片描述
std::unordered_map::reserve
在这里插入图片描述
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
//1.创建一个存储英语到法语单词映射的unordered_map容器
std::unordered_map<std::string, std::string> mymap;
//2.调用reserve(6)函数:为至少能容纳6个元素预留空间
mymap.reserve(6);
/* 说明:
* 1. 内部会计算所需的最小桶数量(基于max_load_factor),确保插入6个元素时无需扩容
* 2. 这是一种性能优化手段,避免插入过程中多次自动扩容的开销
*/
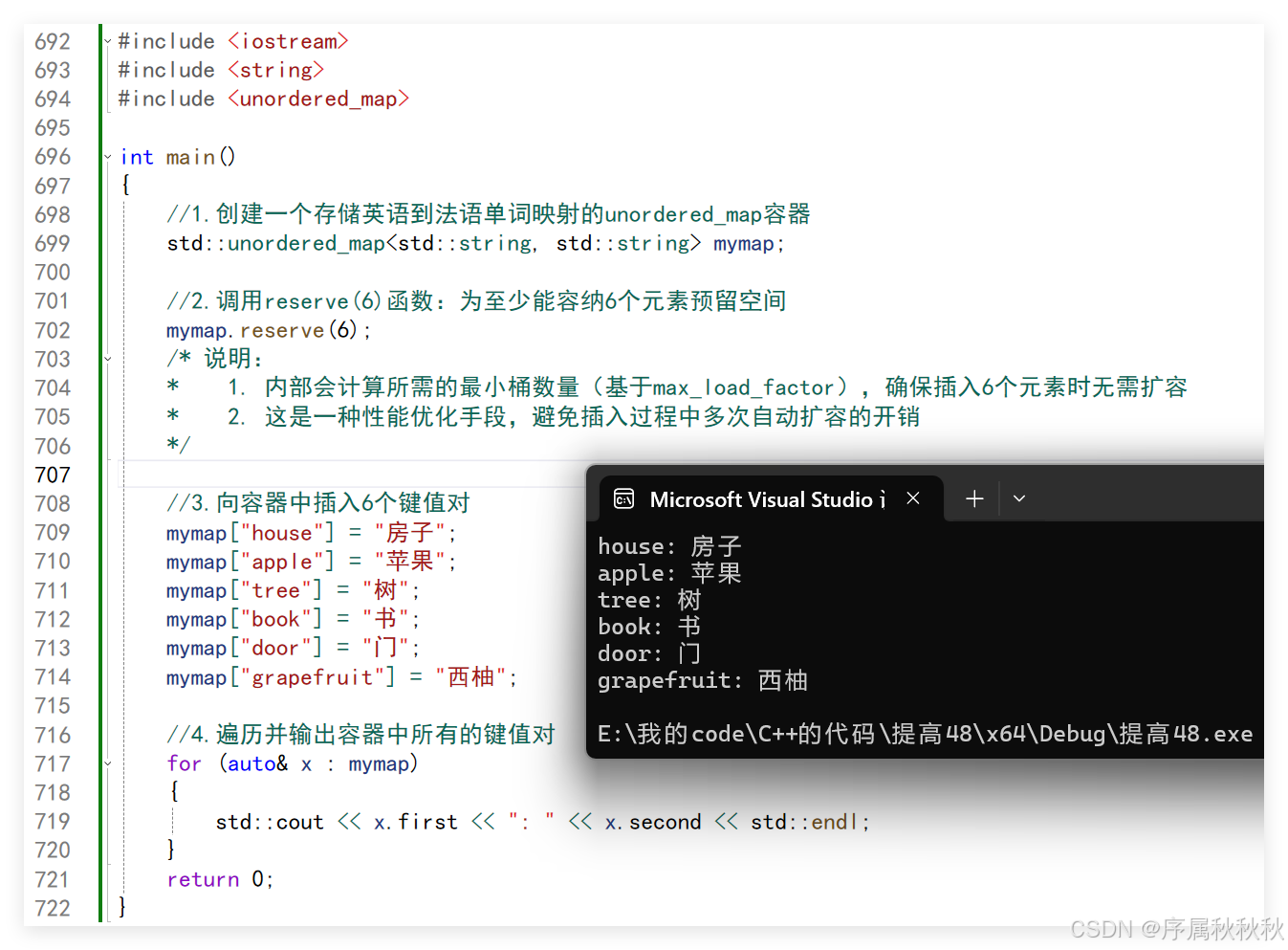
//3.向容器中插入6个键值对
mymap["house"] = "房子";
mymap["apple"] = "苹果";
mymap["tree"] = "树";
mymap["book"] = "书";
mymap["door"] = "门";
mymap["grapefruit"] = "西柚";
//4.遍历并输出容器中所有的键值对
for (auto& x : mymap)
{
std::cout << x.first << ": " << x.second << std::endl;
}
return 0;
}
在这里插入图片描述
-----------功能差异------------
cplusplus网站上关于C++的关于:
unordered_set容器的介绍:unordered_set - C++ 参考资料unordered_multiset容器的介绍:unordered_multiset - C++ 参考资料unordered_map容器的介绍:unordered_map - C++ 参考unordered_multimap容器的介绍:unordered_multimap - C++ 参考资料
一、unordered_set
template <
class Key, // unordered_set::key_type/value_type
class Hash = hash<Key>, // unordered_set::hasher
class Pred = equal_to<Key>, // unordered_set::key_equal
class Alloc = allocator<Key> // unordered_set::allocator_type
> class unordered_set;
template<
class Key, // 关键字类型(底层存储的关键值类型)
class Hash = hash<Key>, // 哈希函数(默认用标准库 hash<Key> )
class Pred = equal_to<Key>, // 相等比较规则(默认用 == 比较)
class Alloc = allocator<Key> // 内存分配器(默认用标准分配器)
> class unordered_set;1. unordered_set模板参数的解析
unordered_set 对 Key 有三类核心需求,默认通过标准库实现,也支持自定义:
1. 哈希转换需求(Hash 参数)
默认逻辑:要求 Key 能通过 hash<Key> 转换为整数哈希值(如:int/double 可直接哈希,string 有特化实现 )
自定义场景:若 Key 不支持默认哈希(如:自定义类),或需特殊哈希规则(如:调整哈希种子 ),可自定义哈希仿函数传给第二个模板参数
// 自定义哈希
struct MyHash
{
size_t operator()(const Key& key) const
{
// 自定义哈希计算逻辑(如结合多个字段、加盐)
return ...;
}
};
unordered_set<Key, MyHash> us; // 替换默认哈希2. 相等比较需求(Pred 参数)
默认逻辑:要求 Key 支持 == 比较(判断两个关键字是否相等 )
自定义场景:若 Key 无默认 ==(如:未重载运算符 ),或需特殊相等规则(如:忽略大小写比较字符串 ),可自定义相等仿函数传给第三个模板参数
// 自定义相等比较
struct MyPred
{
bool operator()(const Key& a, const Key& b) const
{
// 自定义相等逻辑(如字符串忽略大小写)
return ...;
}
};
unordered_set<Key, hash<Key>, MyPred> us; // 替换默认相等规则3. 内存分配需求(Alloc 参数)
- 默认逻辑:通过
allocator<Key>从堆上申请内存 - 自定义场景:若需优化内存管理(如:使用内存池减少分配开销 ),可自定义分配器传给第四个模板参数
2. unordered_set与set的功能差异是什么?
unordered_set与set的核心差异梳理: 查阅文档可知,unordered_set支持增、删、查操作,且使用方式与set完全一致(如:insert/erase/find等接口用法相同 ),因此关于基础使用,此处不再重复赘述和演示。
1. 对 Key 的约束差异
unordered_set 与 set 最核心的差异,体现在对关键字 Key 的约束要求:
- set 的约束:
- 要求
Key支持小于比较(通常通过operator<或自定义比较仿函数实现 ) - 这是因为
set底层基于红黑树(二叉搜索树),需通过大小比较维护有序性
- 要求
- unordered_set 的约束:要求Key满足两点:
- 能转换为整数哈希值(通过哈希函数,如:
hash<Key>) - 支持相等比较(通常通过
operator==或自定义相等仿函数实现 )
- 能转换为整数哈希值(通过哈希函数,如:
这些约束本质是哈希表的底层需求(哈希表需通过哈希值定位桶,通过相等比较判断键是否重复 )
2. 迭代器的差异 二者的迭代器特性也有明显区别:
- set 的迭代器:
- 是双向迭代器(支持
++/--操作 ) - 由于 set 底层是红黑树(二叉搜索树),中序遍历可输出有序序列,因此 set 的迭代器遍历时,结果是有序且去重的
- 是双向迭代器(支持
- unordered_set 的迭代器:
- 是单向迭代器(仅支持
++操作 ) - 由于 unordered_set 底层是哈希表,桶与桶之间无全局顺序,因此迭代器遍历时,结果是无序但去重的
- 是单向迭代器(仅支持
3. 性能差异
set 和 unordered_set 功能高度重合(均支持去重、增删查 ),核心差异在底层:
set:基于红黑树,遍历有序,增删查时间复杂度
unordered_set:基于哈希表,遍历无序,增删查平均
实际使用中,需根据 “是否需要有序遍历” 和 “性能需求” 选择:
- 需有序场景(如:字典序遍历 )→ 选
set - 追求极致增删查效率 → 选
unordered_set(注意哈希冲突风险 )
二、unordered_map
template <
class Key, // unordered_map::key_type
class T, // unordered_map::mapped_type
class Hash = hash<Key>, // unordered_map::hasher
class Pred = equal_to<Key>, // unordered_map::key_equal
class Alloc = allocator< pair<const Key, T> > // unordered_map::allocator_type
> class unordered_map;
template <
class Key, // 键的类型(key_type)
class T, // 值的类型(mapped_type)
class Hash = hash<Key>, // 哈希函数(默认用标准库 hash<Key>)
class Pred = equal_to<Key>,// 键相等比较规则(默认用 == 比较)
class Alloc = allocator< pair<const Key, T> > // 内存分配器(默认用标准分配器)
> class unordered_map;1. unordered_map模板参数的解析
unordered_map 的模板参数解析
unordered_map 存储的是 pair<const Key, T>(键值对,键不可修改 ),模板参数设计围绕 键的哈希、相等比较 和 内存管理 展开。
以下解析各参数的作用与自定义方式:
1. 哈希转换需求(Hash 参数)
默认逻辑:要求 Key 能通过 hash<Key> 转换为整数哈希值,用于定位哈希桶
自定义场景:若 Key 不满足默认哈希(如:自定义类 / 结构体),或需特殊哈希规则(如:调整哈希算法、加盐防冲突 ),可自定义哈希仿函数并传给第三个模板参数
// 自定义键类型(无默认 hash 支持)
struct Point
{
int x, y;
Point(int a = 0, int b = 0)
: x(a)
, y(b)
{}
};
// 自定义哈希仿函数
struct PointHash
{
size_t operator()(const Point& p) const
{
// 结合 x/y 计算哈希(示例:BKDR 算法)
size_t hash = 0;
hash += p.x;
hash *= 131; // 质数减少冲突
hash += p.y;
return hash;
}
};
// 使用自定义哈希的 unordered_map
unordered_map<Point, string, PointHash> umap;2. 相等比较需求(Pred 参数)
默认逻辑:要求 Key 支持 == 比较,用于判断键是否重复(unordered_map 的键具有唯一性,需通过 == 识别重复键 )
自定义场景:若 Key 无默认 ==(如:未重载 operator== ),或需特殊相等规则(如:字符串忽略大小写比较 ),可自定义相等仿函数并传给第四个模板参数。
// 自定义相等比较:忽略字符串大小写
struct IgnoreCaseEqual
{
bool operator()(const string& a, const string& b) const
{
if (a.size() != b.size()) return false;
for (size_t i = 0; i < a.size(); ++i)
{
// 转小写后比较
if (tolower(a[i]) != tolower(b[i])) return false;
}
return true;
}
};
// 使用自定义相等规则的 unordered_map
unordered_map<string, int, hash<string>, IgnoreCaseEqual> umap;
// 插入测试:视为相同键
umap["Apple"] = 5;
umap["apple"] = 10; // 因忽略大小写,判定为重复键,覆盖值3. 内存分配需求(Alloc 参数)
- 默认逻辑:通过
allocator< pair<const Key, T> >从堆内存中申请空间,用于创建哈希桶、存储键值对节点。 - 自定义场景:若需优化内存管理(如:使用内存池减少分配开销、自定义内存对齐策略 ),可自定义内存分配器并传给第五个模板参数。
unordered_map模板参数的总结:
unordered_map 的模板参数设计,本质是为了适配哈希表的三大需求:
哈希定位:通过Hash将Key映射到整数,确定存储桶键唯一性:通过Pred识别重复键(保证键的唯一性)内存管理:通过Alloc灵活控制内存分配策略
2. unordered_map与map的功能差异是什么?
unordered_map与map的核心差异梳理: 查阅文档可知,unordered_map支持增、删、查、改操作,且使用方式与map完全一致(如:insert/erase/find/[]等接口用法相同 )。因此关于基础使用,此处不再重复赘述和演示。
1. 对 Key 的约束差异
unordered_map 与 map 最核心的差异,体现在对关键字 Key 的约束要求:
- map 的约束:
- 要求
Key支持小于比较(通常通过operator<或自定义比较仿函数实现 ) - 这是因为
map底层基于红黑树(二叉搜索树),需通过大小比较维护有序性
- 要求
- unordered_map 的约束:要求Key满足两点:
- 能转换为整数哈希值(通过哈希函数,如:
hash<Key>) - 支持相等比较(通常通过
operator==或自定义相等仿函数实现 )
- 能转换为整数哈希值(通过哈希函数,如:
这些约束本质是哈希表的底层需求(哈希表需通过哈希值定位桶,通过相等比较判断键是否重复 )
2. 迭代器的差异 二者的迭代器特性也有明显区别:
- map 的迭代器:
- 是双向迭代器(支持
++/--操作 ) - 由于 map 底层是红黑树(二叉搜索树),中序遍历可输出有序序列,因此 map 的迭代器遍历时,结果是键有序且去重的
- 是双向迭代器(支持
- unordered_map 的迭代器:
- 是单向迭代器(仅支持
++操作 ) - 由于 unordered_map 底层是哈希表,桶与桶之间无全局顺序,因此迭代器遍历时,结果是键无序但去重的
- 是单向迭代器(仅支持
3. 性能差异
从性能角度,unordered_map 与 map 各有侧重:
map:底层红黑树的增、删、查、改操作复杂度是O(log N)(N是元素数量 ),优势是遍历有序,且最坏情况下性能稳定unordered_map:底层哈希表的增、删、查、改操作平均复杂度是O(1)(极端哈希冲突时退化到O(N),但概率极低 )
因此多数场景下,unordered_map 的增删查改效率更高
------------性能对决------------
测试文件:Test.h
//任务1:包含需要使用的头文件
#include <iostream>
#include <set>
//#include <map>
#include <unordered_set>
//#include <unordered_map>
using namespace std;
int test_set()
{
/*---------------------------第一阶段:准备阶段---------------------------*/
//1.指定测试数据的规模为百万级
const size_t N = 1000000;
//2.初始化随机数种子(基于当前时间)
srand(unsigned int(time(0)));
//3.定义set容器
//3.1:定义“红黑树”实现的set容器
set<int> rb_s;
//3.2:定义“哈希表”实现的set容器
unordered_set<int> ht_s;
//4.定义预存测试数据的容器
vector<int> v;
v.reserve(N); // 预先开辟空间,避免多次扩容
//5.将生成的N个随机数据添加到预存数据的容器中
for (size_t i = 0; i < N; ++i)
{
// 三种数据生成方式(可根据需求注释/取消注释)
//5.1:纯随机(重复值多,适合测哈希冲突)
//v.push_back(rand());
//5.2:随机+递增(重复值少,接近真实场景)
v.push_back(rand() + i);
//5.3:完全有序(无重复,极端场景)
//v.push_back(i);
}
/*---------------------------第二阶段:插入性能对比---------------------------*/
cout << "------------插入性能对比------------" << endl;
//1.测试:“红黑树”实现的“set容器”插入的性能
size_t begin1 = clock();
for (auto it : v)
{
rb_s.insert(it); // 红黑树插入:自动排序+去重
}
size_t end1 = clock();
cout << "set insert:" << end1 - begin1 << "ms" << endl;
//2.测试:“哈希表”实现的“unordered_set容器”插入的性能
size_t begin2 = clock();
ht_s.reserve(N); // 预先扩容,减少插入时的扩容次数
for (auto it : v)
{
ht_s.insert(it); // 哈希表插入:先哈希映射,再处理冲突
}
size_t end2 = clock();
cout << "unordered_set insert:" << end2 - begin2 << "ms" << endl;
//3.验证插入后两种容器的数据量(set 和 unordered_set 都会去重)
cout << "插入数据个数:" << rb_s.size() << endl;
cout << "插入数据个数:" << ht_s.size() << endl << endl;
/*---------------------------第二阶段:查找性能对比---------------------------*/
cout << "------------查找性能对比------------" << endl;
//1.测试:“红黑树”实现的“set容器”查找的性能
int m1 = 0; // 记录 set 找到的次数
size_t begin3 = clock();
for (auto it : v)
{
auto ret = rb_s.find(it); // 红黑树查找:O(logN)
if (ret != rb_s.end())
{
++m1;
}
}
size_t end3 = clock();
cout << "set find:" << end3 - begin3 << "ms--->" << "查找的节点的数量是" << m1 << endl;
//2.测试:“哈希表”实现的“unordered_set容器”查找的性能
int m2 = 0; // 记录 unordered_set 找到的次数
size_t begin4 = clock();
for (auto e : v)
{
auto ret = ht_s.find(e); // 哈希表查找:平均 O(1)
if (ret != ht_s.end())
{
++m2;
}
}
size_t end4 = clock();
cout << "unordered_set find:" << end4 - begin4 << "ms--->" << "查找的节点的数量是" << m2 << endl << endl;
/*---------------------------第二阶段:删除性能对比---------------------------*/
cout << "------------删除性能对比------------" << endl;
//1.测试:“红黑树”实现的“set容器”删除的性能
size_t begin5 = clock();
for (auto it : v)
{
rb_s.erase(it); // 红黑树删除:O(logN)
}
size_t end5 = clock();
cout << "set erase:" << end5 - begin5 << "ms" << endl;
//1.测试:“红黑树”实现的“set容器”删除的性能
size_t begin6 = clock();
for (auto it : v)
{
ht_s.erase(it); // 哈希表删除:平均 O(1)
}
size_t end6 = clock();
cout << "unordered_set erase:" << end6 - begin6 << "ms" << endl << endl;
return 0;
}
int main()
{
test_set();
return 0;
}
在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号