C语言基础之【函数】

C语言基础之【函数】

序属秋秋秋
发布于 2025-12-18 15:12:00
发布于 2025-12-18 15:12:00
往期《C语言基础系列》回顾:链接: C语言基础之【C语言概述】 C语言基础之【数据类型】(上) C语言基础之【数据类型】(下) C语言基础之【运算符与表达式】 C语言基础之【程序流程结构】 C语言基础之【数组和字符串】(上) C语言基础之【数组和字符串】(下)
概述
函数分类
根据函数的来源分类,函数可分为 库函数 和 用户自定义函数 两种:
1.库函数(标准函数)
- 由C标准库提供的函数,可以在包含了相应的头文件后直接调用。
- 输入输出函数:
printf、scanf、puts、gets(位于<stdio.h>) - 字符串处理函数:
strlen、strcpy、strcat(位于<string.h>) - 数学函数:
sqrt、sin、cos(位于<math.h>) - 内存管理函数:
malloc、free(位于<stdlib.h>)
- 输入输出函数:
2.用户自定义函数
由程序员根据需求编写的函数。
int add(int a, int b)
{
return a + b;
}函数的作用
1.提高代码复用性
将常用的代码逻辑封装成函数,可以在程序中多次调用,避免重复编写相同的代码。
int add(int a, int b)
{
return a + b;
}
int main()
{
int sum1 = add(3, 5); // 调用 add 函数
int sum2 = add(10, 20); // 再次调用 add 函数
return 0;
}2.实现模块化编程
将程序分解为多个功能独立的模块(函数),每个模块完成特定的任务,便于理解和维护。
void printMenu()
{
printf("1. Add\n");
printf("2. Subtract\n");
printf("3. Exit\n");
}
int main()
{
printMenu(); // 调用打印菜单的函数
return 0;
}3.隐藏实现细节
通过函数封装具体的实现细节,调用者只需关注函数的功能,而不需要了解内部实现。
int factorial(int n)
{
if (n == 0) return 1;
return n * factorial(n - 1);
}
int main()
{
int result = factorial(5); // 调用计算阶乘的函数
printf("Factorial: %d\n", result);
return 0;
}4.支持递归
函数可以调用自身,用于解决分治、回溯等问题。
int fibonacci(int n)
{
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
int main()
{
int result = fibonacci(6); // 调用递归函数
printf("Fibonacci: %d\n", result);
return 0;
}5.提高代码的可读性
- 通过将复杂的逻辑拆分为多个函数,使代码结构更清晰,易于阅读和理解。
6.提高代码的可维护性
- 将功能独立的代码封装成函数后,修改或优化某个功能时只需修改对应的函数,而不影响其他部分。
7.提高代码的可测试性
- 将功能封装成函数后,可以单独测试每个函数,确保其正确性。
函数的调用:产生随机数
代码示例:生成一个1到100之间的随机数并输出。
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
int main()
{
// 获取当前时间
time_t tm = time(NULL);
// 使用当前时间作为随机数种子
srand((unsigned int)tm);
// 生成一个1到100之间的随机数
int r = rand() % 100 + 1;
// 输出随机数
printf("r = %d\n", r);
return 0;
}分析:
1.头文件
#include <stdio.h>
#include <time.h>
#include <stdlib.h>stdio.h:是标准输入输出库。- 用于使用
printf函数。
- 用于使用
time.h:是时间库。- 用于获取当前时间。
stdlib.h:是标准库。- 包含
srand()和rand()函数,用于生成随机数。
- 包含
2.main函数
获取当前时间:
time_t tm = time(NULL);time(NULL):返回当前的时间(从1970年1月1日至今的秒数)- 并将返回当前的时间赋值给
tm变量。
- 并将返回当前的时间赋值给
设置随机数种子:
srand((unsigned int)tm);srand():用于设置随机数生成器的种子。- 种子决定了
rand()函数生成的随机数序列。 - 这里使用当前时间
tm作为种子,确保每次运行程序时生成的随机数序列不同。
- 种子决定了
生成随机数:
int r = rand() % 100 + 1;rand():用于生成一个伪随机数,范围是0到RAND_MAX(通常是32767)rand() % 100 + 1将随机数限制在1到100之间。
time()
函数的介绍:time():用于获取当前的系统时间(通常是从 1970 年 1 月 1 日 00:00:00 UTC 至今的秒数)
- 它在
<time.h>头文件中定义,常用于时间相关的操作。- 例如:生成随机数种子、记录时间戳等。
- 该函数的精度只能精确到秒级。
函数的原型:
time_t time(time_t *timer);timer:是一个指向time_t类型变量的指针。- 如果传递
NULL,函数会直接返回当前时间。 - 如果传递一个
有效的指针,函数会将当前时间存储到该指针指向的变量中,并同时返回该值。
- 如果传递
time_t:是一个表示时间的算术类型,通常是整数类型(如:long或long long)
函数的返回值:
- 成功时:返回当前时间的
time_t类型值 - 失败时:返回
(time_t)-1
函数的使用:
time 函数的简单使用:
直接获取当前时间
time_t now = time(NULL);
printf("当前时间: %ld\n", now);- 调用
time(NULL)会直接返回当前时间的秒数。- 输出结果是一个整数,表示从 1970 年 1 月 1 日至今的秒数。
将当前时间存储到变量中
time_t now;
time(&now); // 将当前时间存储到 now 变量中
printf("当前时间: %ld\n", now);- 调用
time(&now)会将当前时间存储到now变量中,并同时返回该值。
time 函数的典型应用场景:
生成随机数种子
srand((unsigned int)time(NULL));
int r = rand();-
time(NULL)返回当前时间的秒数,作为随机数种子传递给srand函数。 - 这样可以确保每次运行程序时生成的随机数序列不同。
计算时间差
time_t start = time(NULL);
// 模拟一段耗时操作
for (int i = 0; i < 100000000; i++) {}
time_t end = time(NULL);
printf("已过去的时间:%ld 秒\n", end - start);- 使用
time函数记录开始和结束时间,计算程序执行的时间差。
获取当前时间的字符串表示
time_t now = time(NULL);
char *time_str = ctime(&now);
printf("当前时间: %s", time_str);ctime函数将time_t类型的时间转换为可读的字符串格式- 如:
"现在的时间为: Mon Jan 27 15:26:26 2025"
- 如:
srand()
函数的介绍:srand():用于设置随机数生成器的种子。
- 它在
<time.h>头文件中定义,常用于时间相关的操作。 - 它通常与
rand函数一起使用,以确保每次运行程序时生成的随机数序列不同。 - 因为系统时间是不断变化的,这样能保证每次程序运行时使用不同的种子,从而生成不同的随机数序列。
函数的原型:
void srand(unsigned int seed);seed:是一个无符号类型的整数,作为随机数生成器的种子。
函数的使用:
使用当前时间作为种子:
如果需要生成可随机的随机数序列,可以使用当前时间作为种子。
srand((unsigned int)time(NULL));使用固定值作为种子:
如果需要生成可重复的随机数序列,可以使用固定值作为种子。
srand(123); // 使用固定种子代码示例:使用 srand 和 rand 函数生成随机数
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main()
{
// 设置随机数种子
srand((unsigned int)time(NULL));
// 生成 5 个随机数
for (int i = 0; i < 5; i++)
{
int num = rand(); // 生成随机数
printf("随机数 %d: %d\n", i + 1, num);
}
return 0;
}输出:
随机数 1: 12345
随机数 2: 67890
随机数 3: 54321
随机数 4: 98765
随机数 5: 43210注意事项:种子只需设置一次
- 在程序中只需调用一次
srand,通常放在main函数的开头。 - 如果多次调用
srand,可能会导致随机数序列不够随机。
rand()
函数的介绍:rand():用于生成伪随机数的函数。
- 它在
<stdlib.h>头文件中定义。 - 这里的 “伪随机” 意味着生成的随机数序列是基于一个确定性的算法产生的,只要给定相同的初始条件(即随机数种子),就会生成相同的随机数序列。
函数的原型:
int rand(void);
函数的返回值:rand():返回一个范围在0到RAND_MAX之间的整数。
RAND_MAX是一个在<stdlib.h>中定义的宏,它表示rand函数所能返回的最大随机数。- 不同的系统中
RAND_MAX的值可能不同,但通常至少为32767
函数的使用:
- 生成
[0, n)范围内的随机数
可以使用取模运算符%
int random_num = rand() % n;- 生成
[a, b]范围内的随机数
可以先使用rand() % (b - a + 1)生成[0, b - a]范围内的随机数,再加上a
int random_num = rand() % (b - a + 1) + a;rand函数是基于一个内部的状态(随机数种子)来生成随机数的。
- 如果不通过srand函数设置种子,rand函数默认使用固定的种子(通常是
1),这就导致每次程序运行时,rand函数都会生成相同的随机数序列。 - 为了使每次运行程序时生成不同的随机数序列,通常会使用srand函数结合当前系统时间来设置种子,因为系统时间是不断变化的。
代码示例:生成5个范围在 [10, 20] 的随机数。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main()
{
srand((unsigned int)time(NULL));
int a = 10, b = 20;
for (int i = 0; i < 5; i++)
{
int random_num = a + rand() % (b - a + 1);
printf("第 %d 个范围在 [%d, %d] 的随机数是: %d\n", i + 1, a, b, random_num);
}
return 0;
}输出:
第 1 个范围在 [10, 20] 的随机数是: 13
第 2 个范围在 [10, 20] 的随机数是: 17
第 3 个范围在 [10, 20] 的随机数是: 12
第 4 个范围在 [10, 20] 的随机数是: 20
第 5 个范围在 [10, 20] 的随机数是: 19注意事项:
- rand() 生成的是
伪随机数,每次程序运行时,相同的种子会生成相同的随机数序列,其序列是确定的,只是看起来随机。 - 如果需要更高质量的随机数,可以使用其他库(如:
<random>库)
函数的定义
函数定义格式
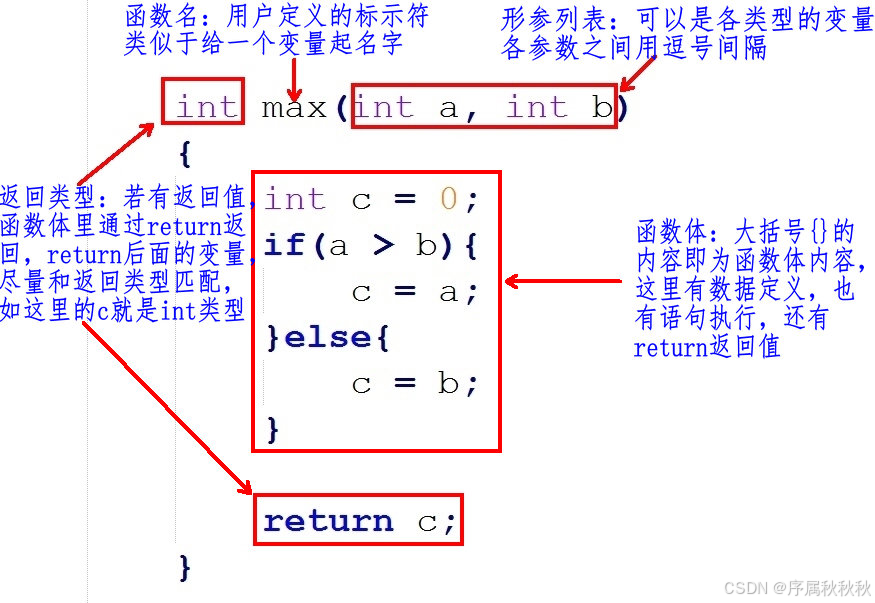
在这里插入图片描述
C语言函数定义的基本格式:
返回值类型 函数名(参数列表)
{
// 函数体
语句序列;
return 返回值; // 可选
}-
返回类型:是函数执行后返回的数据类型。 - 可以是基本数据类型(如:
int、float、char等),也可以是自定义类型(如:结构体、指针等) - 如果函数不需要返回值,返回类型应为
void -
函数名:是函数的标识符,用于在程序中调用该函数。- 函数名必须是一个有效的标识符(由字母、数字和下划线组成,且不能以数字开头)
-
参数列表:是函数接受的输入参数,多个参数之间用逗号分隔。- 每个参数由参数类型和参数名组成,用于向函数传递数据。
- 例如:
int a, float b
- 例如:
- 如果函数不需要参数,可以写
void或留空。
- 每个参数由参数类型和参数名组成,用于向函数传递数据。
-
函数体:是函数的主体部分,包含了实现函数功能的语句序列。- 函数体中可以包含变量声明、控制语句、表达式等。
-
返回值:用于从函数中返回一个值给调用者。- 返回值的类型必须与函数定义的返回值类型一致。
- 如果返回类型是
void,则可以省略return语句。 - 可以使用
return;来提前结束函数的执行。
无参数+无返回值的函数
#include <stdio.h>
// 定义一个无参数、无返回值的函数
void sayHello()
{
printf("Hello, World!\n");
}
int main()
{
sayHello(); // 调用函数
return 0;
}输出: Hello, World!
带参数+有返回值的函数
#include <stdio.h>
// 定义一个带参数、有返回值的函数
int add(int a, int b)
{
return a + b;
}
int main()
{
int result = add(3, 5); // 调用函数
printf("结果为: %d\n", result);
return 0;
}输出: 结果为: 8
无参数+有返回值的函数
#include <stdio.h>
#include <stdlib.h>
// 定义一个无参数、有返回值的函数
int getRandomNumber()
{
return rand(); // 返回一个随机数
}
int main()
{
int num = getRandomNumber(); // 调用函数
printf("随机数字为: %d\n", num);
return 0;
}输出: 随机数字为: 41
带参数+无返回值的函数
#include <stdio.h>
// 定义一个带参数、无返回值的函数
void printSum(int a, int b)
{
printf("和为: %d\n", a + b);
}
int main()
{
printSum(10, 20); // 调用函数
return 0;
}输出: 和为: 30
函数名、形参列表、函数体、返回类型
函数名
在C语言中,函数名是函数的标识符。函数名需要遵循C语言的标识符命名规则:
- 由字母、数字和下划线组成:函数名可以包含字母(大小写均可)、数字和下划线(
_),但不能以数字开头。 - 区分大小写:C语言是区分大小写的,因此
myFunction和myfunction是两个不同的函数名。 - 不能使用关键字:函数名不能与C语言的关键字(如:
int、return、if等)冲突。
常见命名风格:
- 驼峰命名法:
myFunctionName - 下划线命名法:
my_function_name - 全大写命名法:
MY_FUNCTION(通常用于宏或常量)
形参列表
参数列表:位于函数名之后的圆括号内,定义了函数调用时需要传递的参数的个数、类型和顺序
在定义函数时指定的形参,在未出现函数调用时,它们并不占内存中的存储单元,因此称它们是形式参数或虚拟参数,简称 形参
参数列表的特点:
1.参数类型和数量固定
- C语言是静态类型语言,参数的
类型和数量在函数定义时就已经确定。- 调用函数时,必须传递与参数列表匹配的实际参数。
2.参数名的作用域
- 参数名的作用域仅限于函数体内,不能在函数外部使用。
3.参数传递方式
C语言默认使用 值传递(pass by value),即:函数接收的是实际参数的副本,修改参数不会影响原始数据。
如果需要修改原始数据,可以使用 指针传递(pass by reference)
void increment(int *x)
{
(*x)++; // 通过指针修改原始数据
}
int main()
{
int num = 10;
increment(&num); // 传递变量的地址
printf("Num: %d\n", num); // 输出 11
return 0;
}参数列表的注意事项:
在函数定义时 指定的形参,必须是类型+变量的形式:
//1: right, 类型+变量
void max(int a, int b)
{
}
//2: error, 只有类型,没有变量
void max(int, int)
{
}
//3: error, 只有变量,没有类型
int a, int b;
void max(a, b)
{
}在函数声明时 参数列表中的参数名可以省略(仅保留类型),但通常不建议这样做,因为会降低代码的可读性。
函数体
函数体:是函数定义的核心部分,包含了函数的具体实现代码。
- 函数体位于函数头的后面,用一对花括号
{}括起来。 - 函数体内可以包含:变量声明、表达式、控制语句、函数调用等,用于实现函数的功能。
函数体的组成部分:
声明部分:用于存储和处理数据。
在函数体中,可以声明变量、指针、数组等,这些声明的变量作用域通常仅限于该函数内部。
int add(int a, int b)
{
int sum; // 声明一个变量sum,用于存储两数之和
sum = a + b;
return sum;
}执行部分:用于实现函数的具体功能。
这是函数体的主要部分,包含了一系列的语句,这些语句可以是赋值语句、算术运算语句、逻辑判断语句、循环语句、函数调用语句等。
void printNumbers(int n)
{
int i;
for(i = 1; i <= n; i++)
{
printf("%d ", i); // 执行部分,输出数字
}
printf("\n");
}3.返回部分:用于返回函数的执行结果。
对于有返回值的函数,函数体中必须包含return语句,
return语句后面的值必须与函数定义的返回值类型一致。
double square(double x)
{
return x * x; // 返回部分,返回x的平方
}如果函数没有返回值(返回值类型为void),则可以不使用return语句,或者使用return;来提前结束函数的执行。
返回值
返回值的注意事项:
尽量保证return语句中表达式的值和函数返回类型是同一类型。
int max() // 函数的返回值为int类型
{
int a = 10;
return a;// 返回值a为int类型,函数返回类型也是int,匹配
}如果函数返回的类型和return语句中表达式的值不一致,则以函数返回类型为准,即:函数返回类型决定返回值的类型
- 对数值型数据,可以自动进行类型转换。
double max() // 函数的返回值为double类型
{
int a = 10;
return a;// 返回值a为int类型,它会转为double类型再返回
}- 注意:如果函数返回的类型和return语句中表达式的值不一致,而它又无法自动进行类型转换,程序则会报错。
return语句的另一个作用为中断return所在的执行函数。
- 类似于break中断循环、switch语句一样。
int max()
{
return 1;// 执行到,函数已经被中断,所以下面的return 2无法被执行到
return 2;// 没有执行
}函数的调用
定义函数后,我们需要调用此函数才能执行到这个函数里的代码段。
这和main函数不一样,main是编译器设定好自动调用的主函数,无需人为调用,我们都是在main函数里调用别的函数。
一个 C 程序里有且只有一个main函数。
函数调用:是程序执行过程中调用已定义函数的过程。
函数调用是C语言中实现代码复用和模块化编程的核心机制。
函数调用的基本语法:返回值类型 变量名 = 函数名(实际参数);
函数调用的示例:
无返回值函数调用
#include <stdio.h>
void greet()
{
printf("Hello, World!\n");
}
int main()
{
greet(); // 调用函数
return 0;
}有返回值函数调用
#include <stdio.h>
int add(int a, int b)
{
return a + b;
}
int main()
{
int result = add(3, 5); // 调用函数并接收返回值
printf("和为: %d\n", result); // 输出 8
return 0;
}嵌套函数调用
#include <stdio.h>
int square(int x)
{
return x * x;
}
int sumOfSquares(int a, int b)
{
return square(a) + square(b); // 嵌套调用square函数
}
int main()
{
int result = sumOfSquares(3, 4); // 调用函数
printf("结果为: %d\n", result); // 输出 25
return 0;
}递归函数调用
#include <stdio.h>
int factorial(int n)
{
if (n <= 1) return 1; // 终止条件
return n * factorial(n - 1); // 递归调用
}
int main()
{
int result = factorial(5); // 调用递归函数
printf("阶乘结果: %d\n", result); // 输出 120
return 0;
}函数调用的参数传递
1.值传递
实参的值会被复制到形参中,函数内部对形参的修改不会影响实参。
实参和形参之间数据的值传递,也称为单向传递
- 即:只由实参传给形参,而不能由形参传回来给实参。
#include <stdio.h>
void increment(int x) // x是形参
{
x++;
printf("函数内部的值: %d\n", x); // 输出 11
}
int main()
{
int num = 10;
increment(num); // num是实参
printf("函数外部的值: %d\n", num); // 输出 10(未改变)
return 0;
}输出:
函数内部的值: 11 函数外部的值: 10
2.地址传递
通过传递指针,函数可以修改实参的值。
#include <stdio.h>
void increment(int* x) // x是指针形参
{
(*x)++;
printf("函数内部的值: %d\n", *x); // 输出 11
}
int main()
{
int num = 10;
increment(&num); // 传递num的地址
printf("函数外部的值: %d\n", num); // 输出 11(已修改)
return 0;
}输出:
函数内部的值: 11 函数外部的值: 11
函数调用的执行流程
函数调用执行流程:描述了从函数调用开始到函数执行结束的整个过程。
函数调用的步骤: 1.参数传递:
- 调用函数时,实际参数的值会被传递给函数的形式参数。
- C语言默认使用
值传递(pass by value),即:传递的是实际参数的副本,函数内部对参数的修改不会影响原始数据。
- C语言默认使用
2.控制权转移:
- 程序的控制权从调用点转移到被调用的函数,开始执行函数体中的代码。
3.返回值:
- 如果函数有返回值,函数执行完毕后会将返回值传递回调用点。
4.继续执行:
- 函数执行完毕后,控制权返回到调用点,程序继续执行后续代码。
#include <stdio.h>
void print_test()
{
printf("this is for test\n");
}
int main()
{
print_test(); // print_test函数的调用
return 0;
}- 进入main()函数
- 调用print_test()函数
- 它会在main()函数的前面寻找有没有一个名字叫“print_test”的函数定义
- 如果找到,接着检查函数的参数,这里调用函数时没有传参,函数定义也没有形参,参数类型匹配
- 开始执行print_test()函数,这时候,main()函数里面的执行会阻塞在print_test()这一行代码,等待print_test()函数执行完毕
- print_test()函数执行完( 打印 this is for test ),main()函数继续往下执行,执行到
return 0;整个程序执行完毕
函数的形参和实参
形参(形式参数):用于在调用函数时接收传递的具体值。
实参(实际参数):用于在调用函数时传递具体值。
形参:是函数定义中声明的参数,位于函数名后的括号内。
int add(int a, int b) // a和b是形参
{
return a + b;
}形参的特点:
- 形参是局部变量,其作用域仅限于函数体内。
- 形参的类型和数量在
函数定义时确定。 - 形参在
函数调用时被初始化,函数执行结束后被销毁。
实参:是函数调用时传递给函数的具体值或变量。
int result = add(3, 5); // 3和5是实参实参的特点:
实参出现在主调函数中,进入被调函数后,实参不能再使用。
实参的类型和数量必须与形参匹配。
实参可以是常量、变量、表达式或函数调用的返回值,无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值,以便把这些值传送给形参。
// 函数的定义
void test(int a, int b)
{
}
int main()
{
// 函数的调用
int p = 10, q = 20;
test(p, q); // right
test(11, 30 - 10); // right
test(int a, int b); // error, 不应该在圆括号里定义变量
return 0;
}函数的声明
如果使用用户自己定义的函数,但是
- 该函数与调用它的函数
(即主调函数)不在同一文件中 - 或该函数定义的位置在
主调函数之后
则必须在调用此函数之前对被调用的函数作函数声明
注意:一个函数只能被定义一次,但可以声明多次
函数声明:是在函数尚在未定义的情况下,事先将该函数的有关信息通知编译系统,相当于告诉编译器,函数的定义在后面,以便使编译能正常进行。
函数声明的作用:
- 提供函数信息:
- 告诉编译器函数的名称、返回类型和参数列表。
- 使编译器能够检查函数调用的正确性(如:参数类型和数量是否匹配)
- 支持分离编译:
- 在大型程序中,通常会将函数的定义和调用放在不同的源文件中。
- 函数声明可以放在头文件中,供其他源文件包含。
- 避免隐式声明:
- 如果函数在调用之前没有声明,C语言会假设函数返回
int类型,这可能导致未定义行为。
- 如果函数在调用之前没有声明,C语言会假设函数返回
函数声明的语法:返回类型 函数名(参数类型1 参数名1, 参数类型2 参数名2, ...);
返回类型:函数返回值的类型(如:int、float、void等)函数名:函数的标识符参数类型:每个参数的数据类型(如:int、char、float等)参数名:可选,可以省略参数名,只保留参数类型
正常函数声明
#include <stdio.h>
int add(int a, int b); // 函数声明
int main()
{
int result = add(3, 5); // 调用函数
printf("结果: %d\n", result); // 输出 8
return 0;
}
// 函数定义
int add(int a, int b)
{
return a + b;
}省略参数名声明
#include <stdio.h>
int add(int, int); // 函数声明(省略参数名)
int main()
{
int result = add(3, 5); // 调用函数
printf("结果: %d\n", result); // 输出 8
return 0;
}
// 函数定义
int add(int a, int b)
{
return a + b;
}函数声明的注意事项:
头文件中的声明:
在大型项目中,函数声明通常放在头文件(.h文件)中,以便多个源文件共享。
// myfunctions.h
#ifndef MYFUNCTIONS_H
#define MYFUNCTIONS_H
int add(int a, int b);
void printHello();
#endif避免隐式声明:
如果函数在调用之前没有声明,C语言会假设函数返回int类型,这可能导致未定义行为。
#include <stdio.h>
int main()
{
// 隐式声明(不推荐)
int result = add(3, 5); // 假设add返回int类型
printf("结果: %d\n", result);
return 0;
}
// 函数定义
int add(int a, int b)
{
return a + b;
}函数声明与函数定义的区别:
特性 | 函数声明 | 函数定义 |
|---|---|---|
作用 | 告知编译器函数接口 | 提供函数具体实现 |
函数体 | 无函数体(以分号 ; 结尾) | 必须包含函数体(代码块 {}) |
内存分配 | 不分配内存 | 分配内存存储代码 |
出现次数 | 可多次声明 | 只能定义一次 |
参数名 | 参数名可省略(只需类型) | 必须指定参数名 |
exit函数
函数的介绍:exit():用于终止当前正在运行的程序,并将控制权返回给操作系统或调用者。
- 它定义在
<stdlib.h>头文件中。
函数的原型:
void exit(int status);status:程序的退出状态码。0:表示程序正常结束。非零值:表示程序异常结束。
在C语言中,
return和exit虽然都涉及程序控制流的终止,但它们的用途和行为有显著区别。
return:是 C 语言关键字,用于函数中结束当前函数执行。exit:是一个函数,用于结束整个进程。
return与exit的区别:
特性 | return | exit |
|---|---|---|
作用域 | 退出当前函数 | 终止整个程序 |
清理行为 | 仅在main中触发全局清理 | 始终执行全局清理 |
参数类型 | 与函数返回值类型一致 | int状态码 |
头文件 | 无需头文件 | 需<stdlib.h> |
典型用途 | 函数正常退出 | 立即终止程序(如:严重错误) |
1. 作用范围
return:仅在函数内部使用,退出当前函数并将返回值传递给调用者。- 在
main函数中,return会结束程序,返回状态码给操作系统。 - 在
非main函数中,return仅退出当前函数,程序继续执行调用者的后续代码。
- 在
exit:立即终止整个程序,无论调用位置在何处。- 在任意函数中调用exit都会直接结束整个进程,返回状态码给操作系统。
2. 使用场景
-
return- 函数需返回结果或错误码,且程序需继续执行后续逻辑(如:递归返回、多层错误处理)
-
exit- 遇到不可恢复错误,或程序已达成目标需立即终止(如:命令行工具完成操作后退出)
3. 清理行为
return- 在
main函数中,return会触发与exit相同的清理操作(如:刷新I/O缓冲区、执行atexit注册的函数) - 在
非main函数中,return仅退出当前函数,不会直接触发全局清理。
- 在
exit- 始终执行标准库的清理操作:刷新所有
stdio缓冲区、关闭文件流、执行atexit注册的函数。
- 始终执行标准库的清理操作:刷新所有
代码示例:
#include <stdio.h>
#include <stdlib.h>
void func_return()
{
printf("func_return执行\n");
return; // 仅退出当前函数
}
void func_exit()
{
printf("func_exit执行\n");
exit(0); // 终止整个程序
}
int main()
{
func_return();
printf("main继续执行\n"); // 会输出
func_exit();
printf("这行不会执行\n"); // 不会输出
return 0;
}输出: func_return执行 main继续执行 func_exit执行
分文件编程
分文件编程
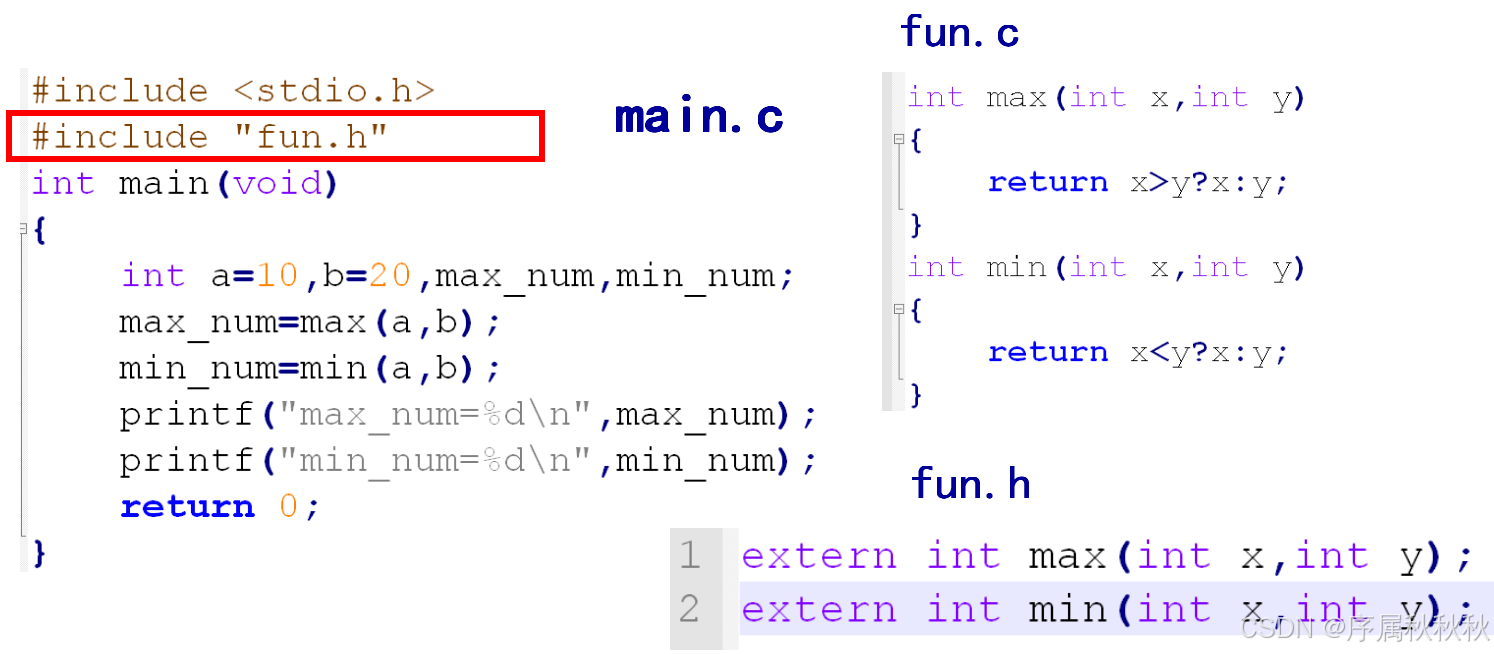
在这里插入图片描述
分文件编程:是一种常见的开发方式,它将程序代码分散到多个文件中,每个文件负责程序的一部分功能,以提高代码的可读性、可维护性和可复用性。
文件类型划分
- 头文件(.h)
声明函数原型:告诉编译器函数的名称、参数类型和返回类型。声明全局变量:用于在多个源文件之间共享变量。定义宏:用于常量定义或简单的代码替换。定义数据结构:如结构体、联合体和枚举类型。
- 源文件(.c)
定义函数:实现函数的具体逻辑。定义全局变量:为全局变量分配存储空间。包含头文件:通过#include指令引入头文件,以使用头文件中声明的内容。
标准分文件流程示例:
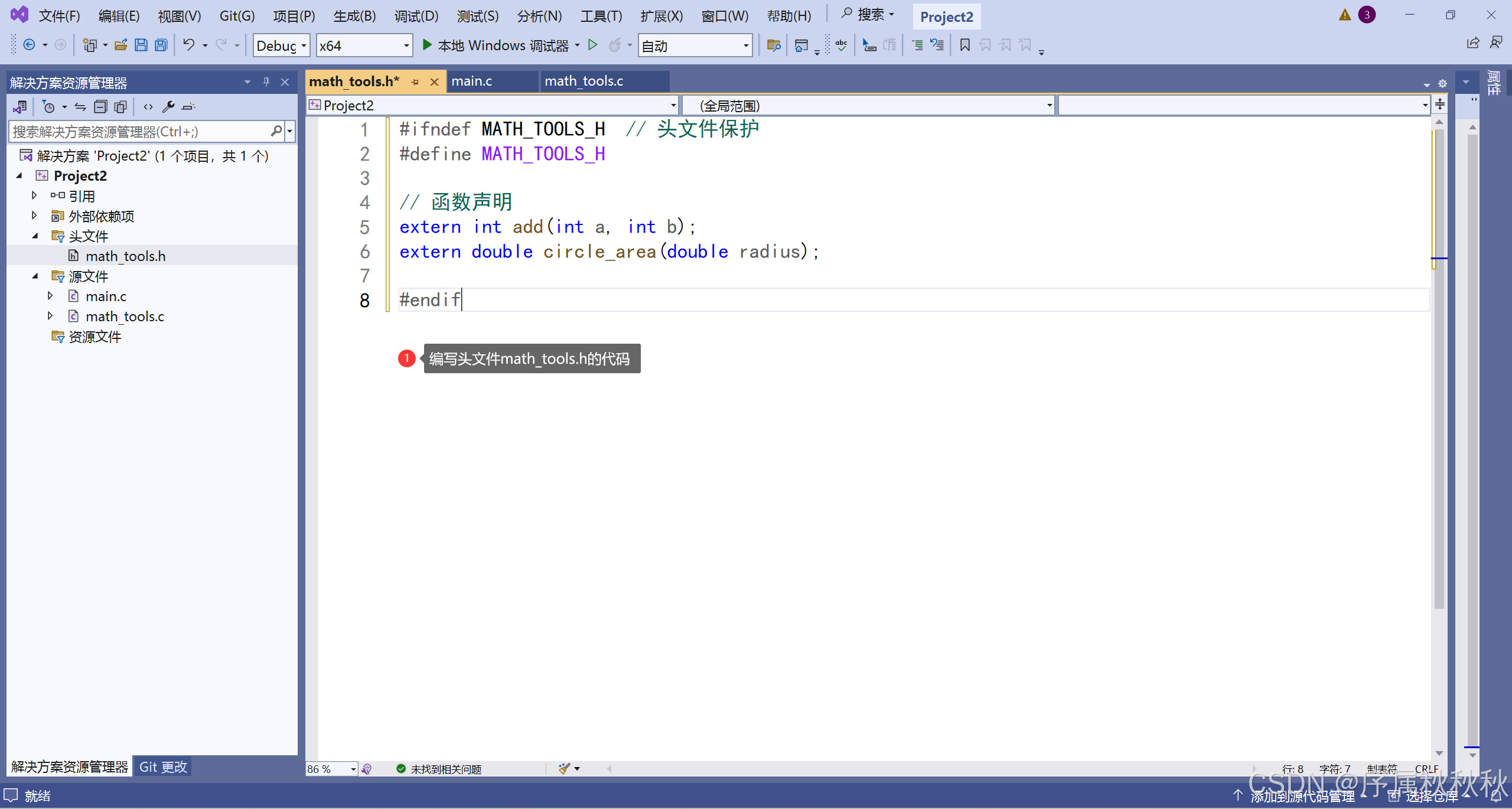
创建头文件 math_tools.h
//math_tools.h
#ifndef MATH_TOOLS_H // 头文件保护
#define MATH_TOOLS_H
// 函数声明
extern int add(int a, int b);
extern double circle_area(double radius);
#endif
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
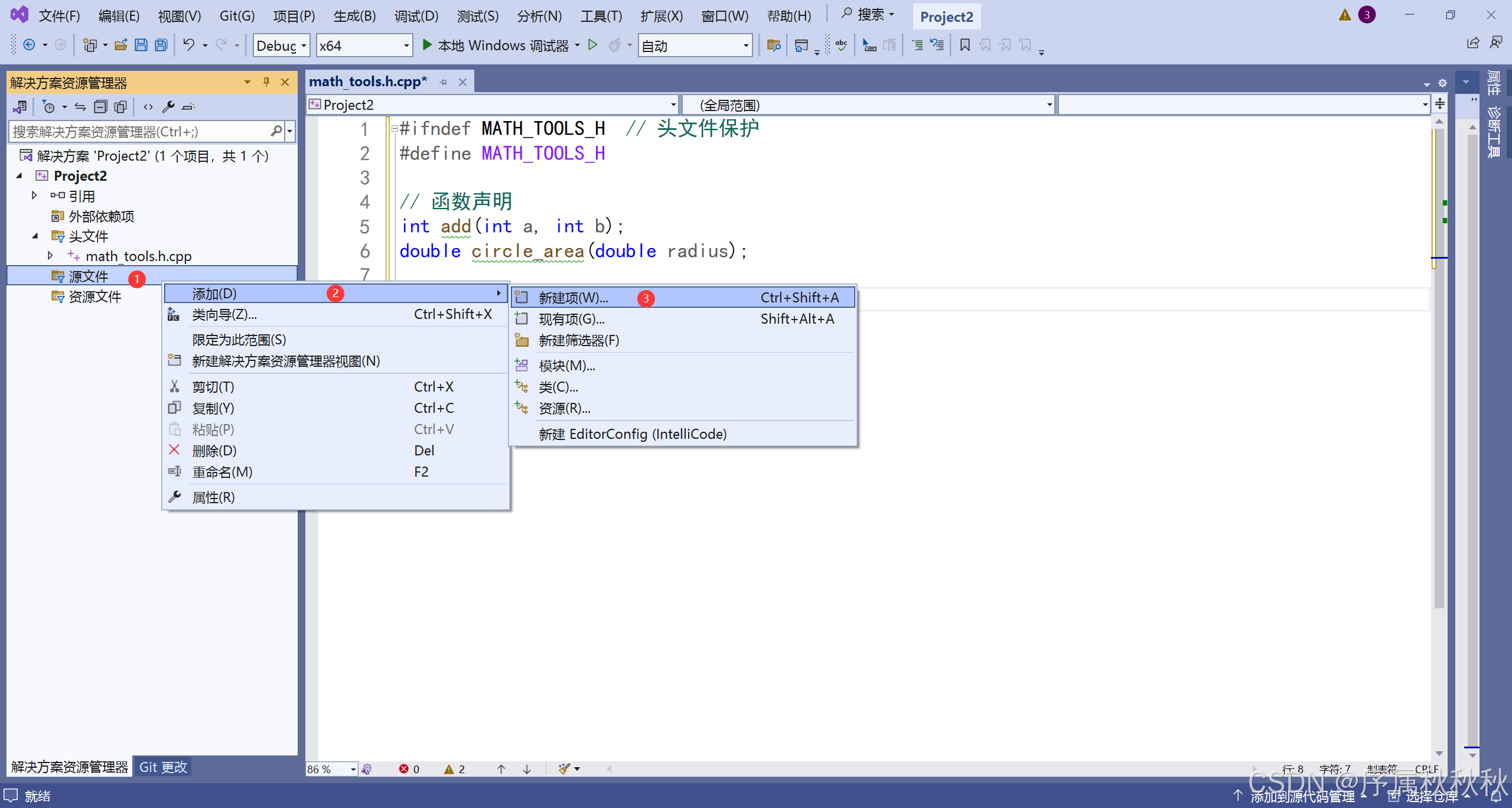
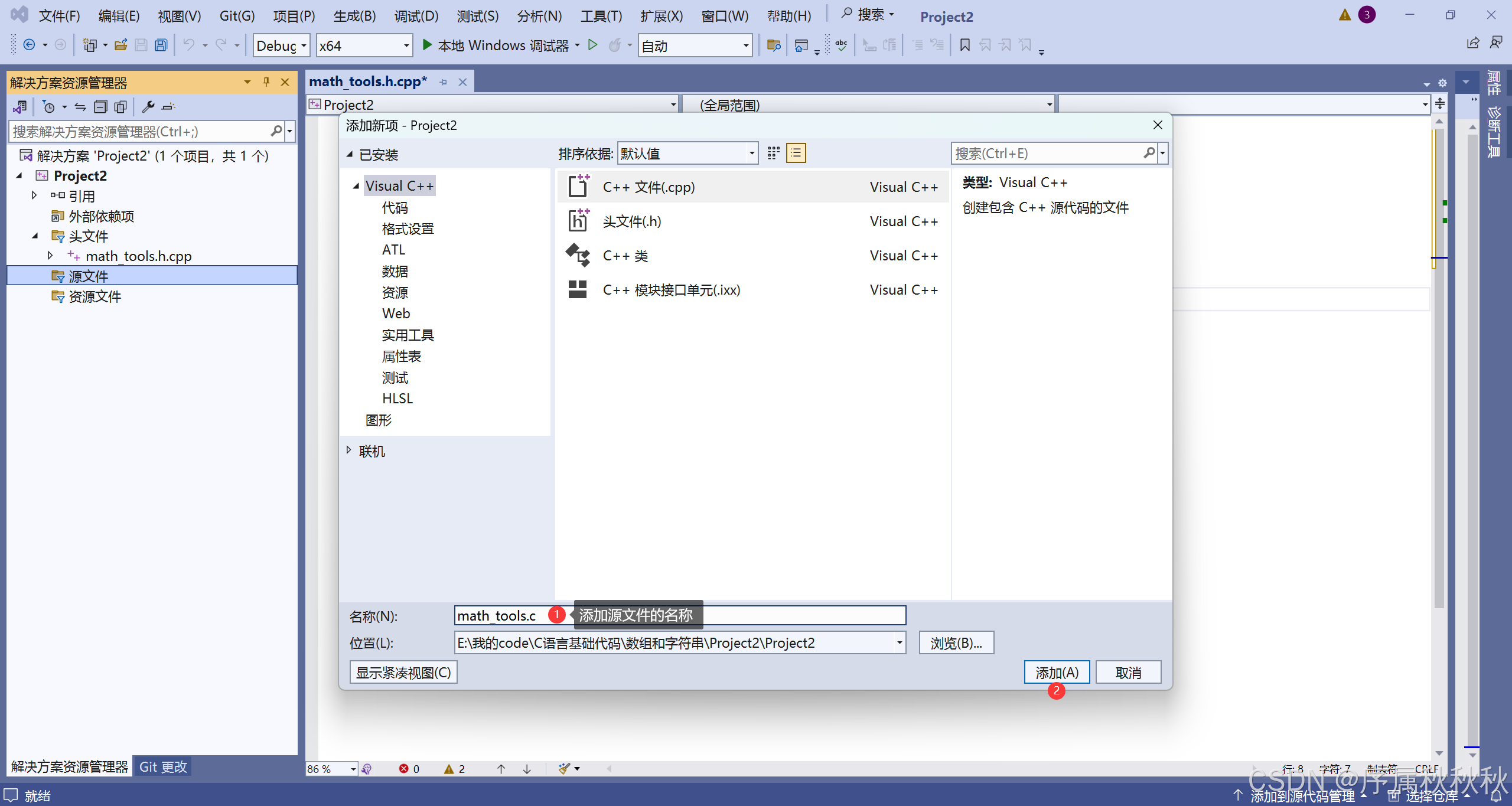
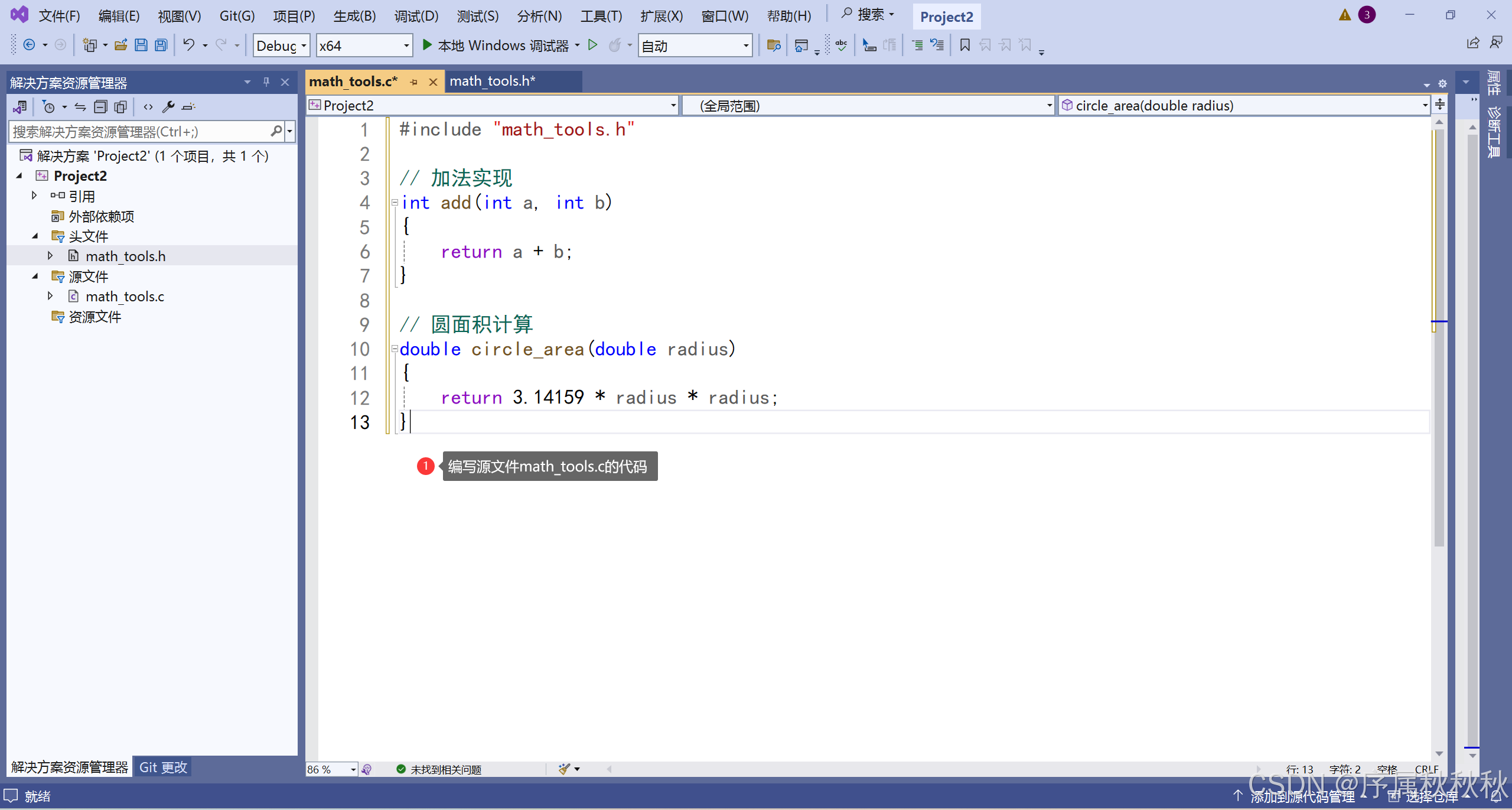
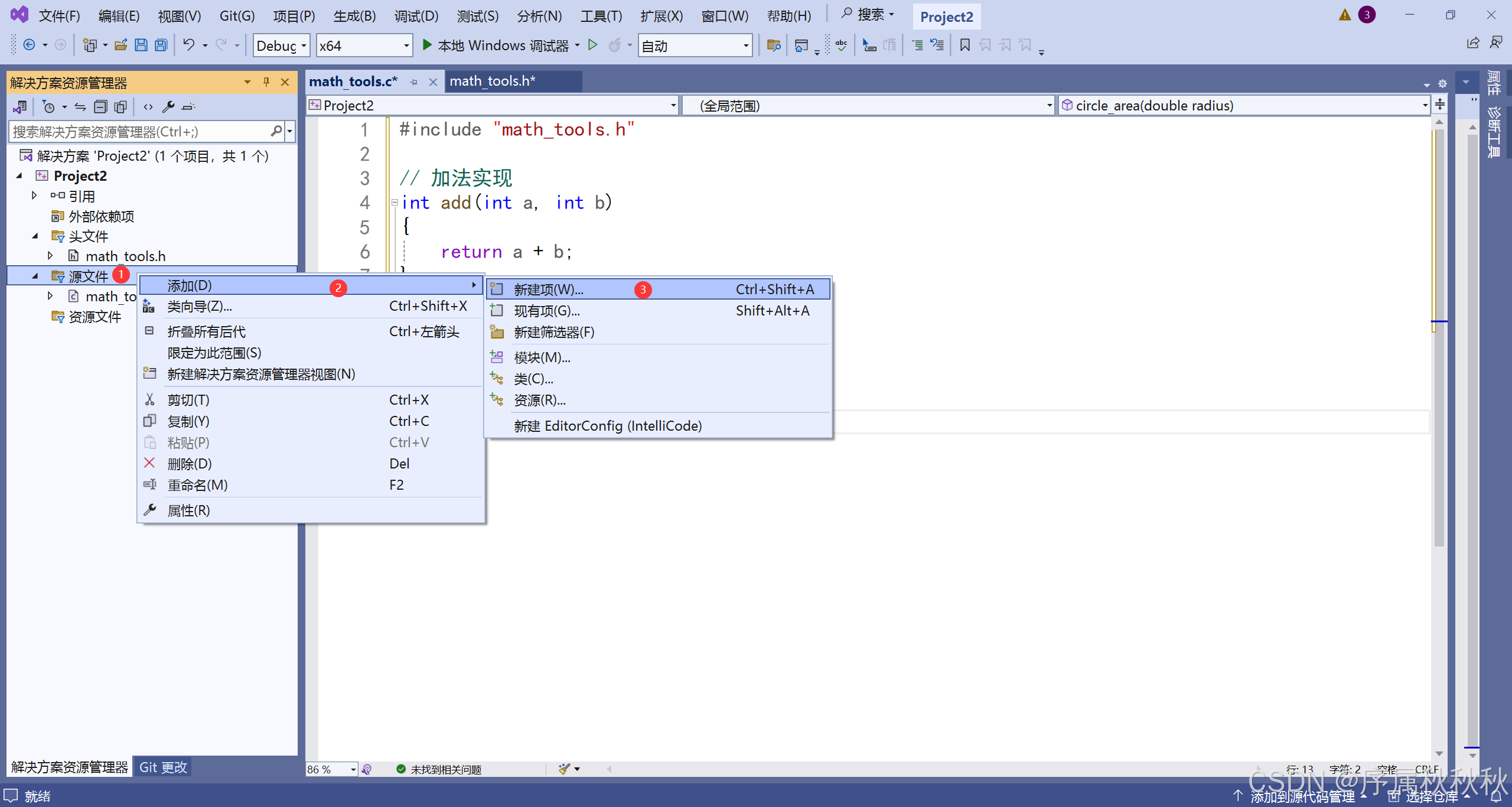
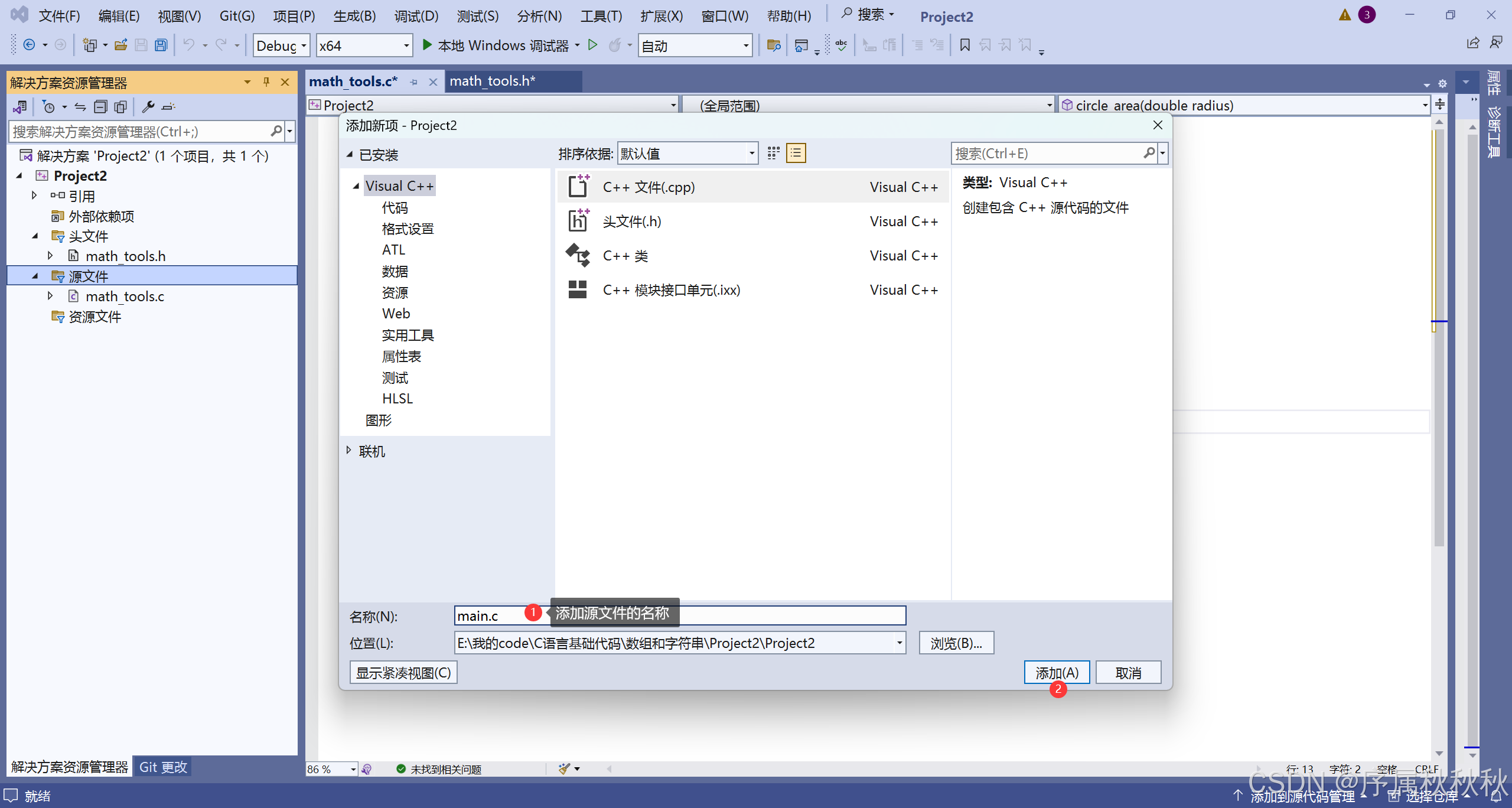
创建源文件 math_tools.c
//math_tools.c
#include "math_tools.h"
// 加法实现
int add(int a, int b)
{
return a + b;
}
// 圆面积计算
double circle_area(double radius)
{
return 3.14159 * radius * radius;
}
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
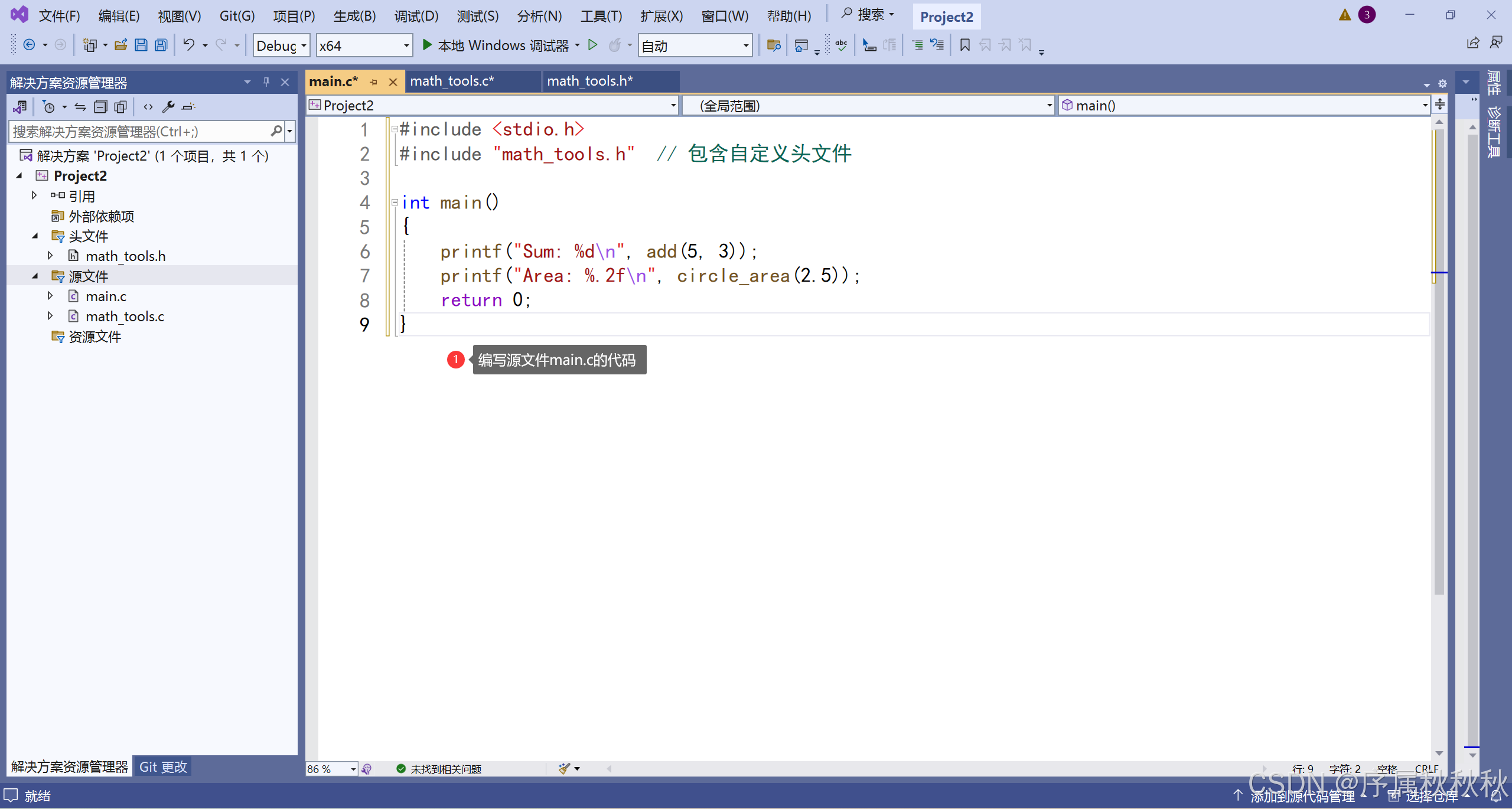
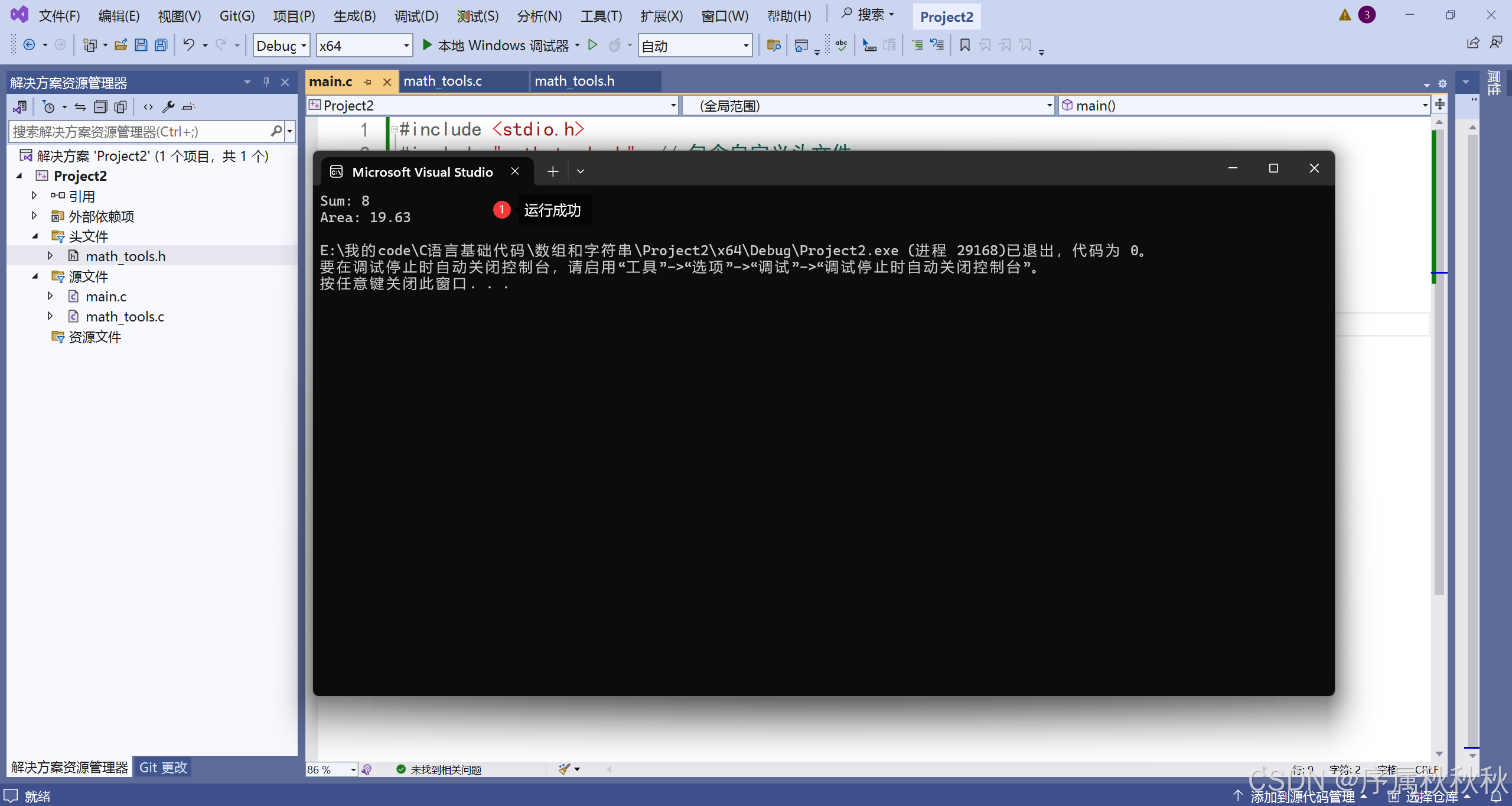
主程序 main.c
//main.c
#include <stdio.h> /// 包含系统库头文件
#include "math_tools.h" // 包含自定义头文件
int main()
{
printf("Sum: %d\n", add(5, 3));
printf("Area: %.2f\n", circle_area(2.5));
return 0;
}
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
防止头文件重复包含
在 C/C++ 开发中,头文件重复包含是一个常见的问题,可能导致编译错误、重复定义等问题。
为了避免这些问题,通常使用 头文件保护机制(Header Guard) 来防止头文件被重复包含。
头文件保护机制有两种常见的实现方式:#pragma once 和 包含卫士(Include Guards)
包含卫士:使用 #ifndef、#define、#endif 预处理指令来防止头文件重复包含的方法。
包含卫士的基本格式:
#ifndef 唯一标识符
#define 唯一标识符
// 头文件内容
#endif // 唯一标识符#ifndef:检查某个标识符是否未定义。- 标识符必须是唯一的,通常使用头文件名的大写形式,并用下划线替换点号。
- 例如:
myheader.h的标识符可以是MYHEADER_H
- 例如:
- 标识符必须是唯一的,通常使用头文件名的大写形式,并用下划线替换点号。
#define:定义一个标识符。#endif:结束条件编译。
代码示例:假设有一个头文件 myheader.h
#ifndef MYHEADER_H // 如果 MYHEADER_H 未定义
#define MYHEADER_H // 定义 MYHEADER_H
// 头文件内容
#define PI 3.14159 // 宏定义
extern int add(int a, int b); // 函数声明
#endif // MYHEADER_H // 结束条件编译包含卫士的工作原理:
- 当第一次包含
myheader.h时:#ifndef MYHEADER_H为真(因为MYHEADER_H未定义)- 执行
#define MYHEADER_H,定义MYHEADER_H - 头文件内容被包含
- 当第二次包含
myheader.h时:#ifndef MYHEADER_H为假(因为MYHEADER_H已经定义)- 头文件内容被跳过
避免与其他头文件冲突:确保不同头文件的标识符不会重复
#pragma once: 是一种更简洁的用于防止头文件重复包含的方法。
#pragma once
// 头文件内容
#define PI 3.14159 // 宏定义
int add(int a, int b); // 函数声明#pragma once与包含卫士的比较:
特性 | #pragma once | 包含卫士 |
|---|---|---|
标准性 | 非标准,但被大多数现代编译器支持 | 标准,所有编译器都支持 |
代码简洁性 | 一行指令 | 需三行宏定义 |
编译性能 | 高,编译器优化处理 | 稍微低,需要检查宏定义 |
可移植性 | 低,依赖于编译器的支持 | 高,标准C语言特性 |
唯一性保证 | 依赖编译器路径解析 | 依赖用户定义的宏名 |
👨💻 博主正在持续更新C语言基础系列中。 ❤️ 如果你觉得内容还不错,请多多点赞。 ⭐️ 如果你觉得对你有帮助,请多多收藏。(防止以后找不到了) 👨👩👧👦
C语言基础系列持续更新中~,后续分享内容主要涉及C++全栈开发的知识,如果你感兴趣请多多关注博主。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-02-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号