使用Dify构建智能业务查询助手:从零到一的实践指南
原创

使用Dify构建智能业务查询助手:从零到一的实践指南
在企业数字化转型的浪潮中,如何让业务人员快速获取所需的数据信息,一直是个令人头疼的问题。传统的做法是让业务人员提交需求,技术人员编写SQL查询,再将结果反馈回去——这个过程往往耗时数小时甚至数天。而今天,借助Dify这样的AI工作流平台,我们可以构建一个智能业务查询助手,让业务人员用自然语言直接获取想要的数据,整个过程只需几秒钟。
本文将详细介绍如何使用Dify的工作流功能,结合数据库查询、条件分支、代码块等核心能力,构建一个真正实用的智能业务查询系统。
一、适用场景:谁需要这样的智能助手?
在深入技术细节之前,我们先来看看这套方案适合哪些场景。
1.1 项目管理场景
对于项目经理来说,每天都需要了解项目的最新进展:
- "帮我查一下新昌县天姥大桥项目的合同情况"
- "我负责的所有在建项目有哪些?"
- "XX项目的开票和回款进度怎么样了?"
传统方式需要登录多个系统,查看不同的报表,再手动汇总信息。而智能助手可以一次性整合所有相关数据,以对话的形式自然呈现。
1.2 日报周报生成场景
对于团队管理者,每周需要汇总团队成员的工作日报,生成周报:
- 自动抓取本周所有团队成员的日报
- 智能提取工作重点和需要协调的事项
- 按照固定格式生成周报,节省大量人工整理时间
1.3 权限敏感的数据查询
在企业环境中,不同员工拥有不同的数据权限:
- 普通员工只能查看自己负责的项目
- 部门经理可以查看本部门所有项目
- 公司高管可以查看全公司数据
智能助手需要能够根据用户身份,自动过滤数据,确保信息安全。
1.4 多维度数据整合
业务信息往往分散在多个数据表中:
- 项目基本信息在项目表
- 合同信息在合同表
- 开票记录在财务表
- 回款记录在收款表
智能助手需要能够自动关联这些表,将完整的信息整合后呈现给用户。
二、核心技术架构:Dify工作流的三大法宝
要构建这样一个智能助手,我们需要用到Dify工作流中的三个核心组件:
2.1 数据库查询工具:连接业务数据的桥梁
Dify提供了强大的数据库查询能力,支持MySQL、PostgreSQL等主流数据库。通过配置API Key,我们可以在工作流中直接执行SQL查询。
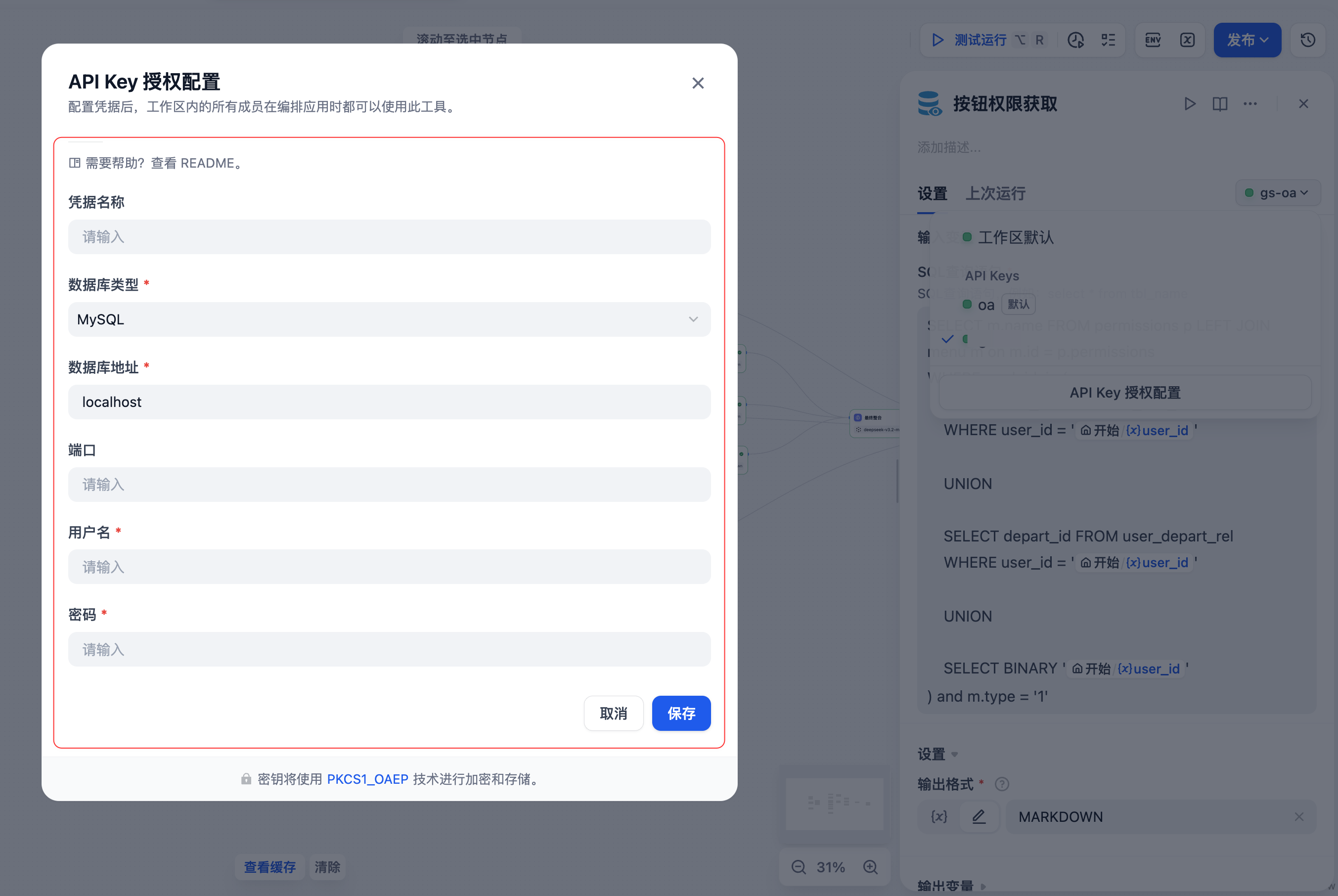
数据库预查询工具配置
如上图所示,配置数据库连接非常简单:
- 数据库类型:选择MySQL(或其他数据库)
- 数据库地址:填写数据库的host地址(如localhost或远程IP)
- 端口:默认3306
- 用户名/密码:数据库访问凭证
配置完成后,工作流中的SQL节点就可以直接查询数据库了。在右侧的SQL编辑器中,我们可以看到一个复杂的权限查询示例:
SELECT project_id FROM user_project_rel
WHERE user_id = '{{sys.user_id}}'
UNION
SELECT depart_id FROM user_depart_rel
WHERE user_id = '{{sys.user_id}}'
UNION
SELECT BINARY '全开权' FROM user_menu_rel
WHERE (user_id = '{{sys.user_id}}') and m.type = '1'这段SQL的巧妙之处在于:
- 通过UNION将多个查询结果合并
- 使用
{{sys.user_id}}动态引用当前用户ID - 分别查询用户的项目权限、部门权限和全局权限
适用场景提示:当你的业务数据存储在关系型数据库中,且需要根据用户身份进行动态查询时,数据库查询工具是不可或缺的基础设施。
2.2 工具市场:丰富的功能扩展
Dify的工具市场提供了大量开箱即用的工具,可以显著加速开发效率。
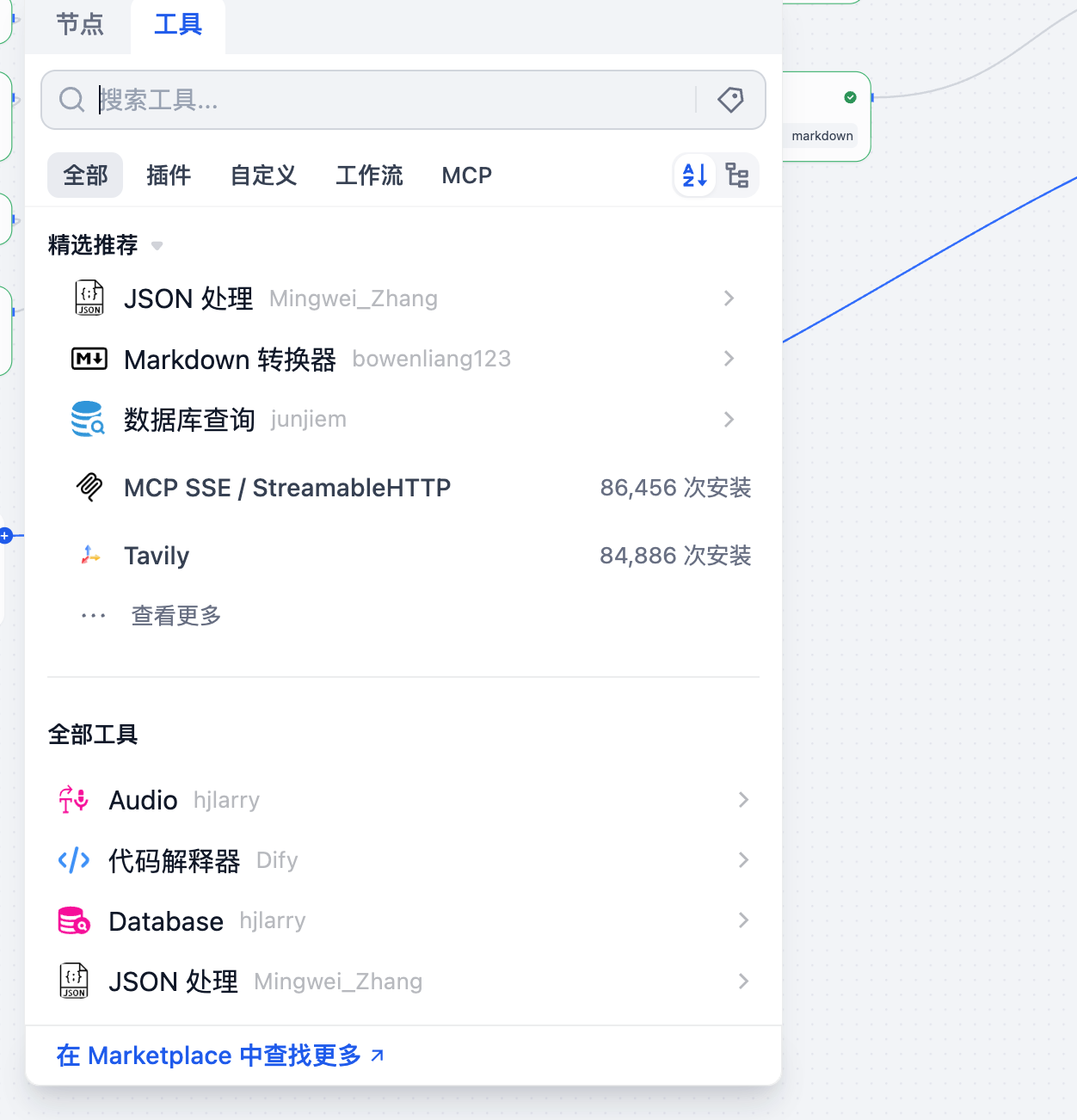
Dify工具市场
在精选推荐中,有几个特别实用的工具:
JSON处理工具:当数据库返回JSON格式数据时,这个工具可以帮助我们解析、提取、转换JSON结构。在我们的项目查询场景中,SQL查询结果通常是JSON格式,需要用这个工具处理。
Markdown转换器:将查询结果格式化为美观的Markdown表格,提升用户体验。业务人员看到的不再是冰冷的JSON数据,而是清晰易读的表格。
数据库查询工具:如前文所述,这是连接业务数据的核心工具。
MCP SSE / StreamableHTTP:如果需要实现流式输出(像ChatGPT那样逐字显示),这个工具可以帮助你。
Tavily:一个强大的网络搜索工具,如果你的助手需要结合外部信息(比如查询项目相关的行业政策),可以用这个工具。
适用场景提示:在开发初期,先浏览工具市场,看看有没有现成的工具能解决你的需求,避免重复造轮子。
2.3 条件分支:智能流程控制的关键
一个智能助手需要能够理解用户的不同意图,并根据意图执行不同的处理流程。这就需要用到条件分支节点。
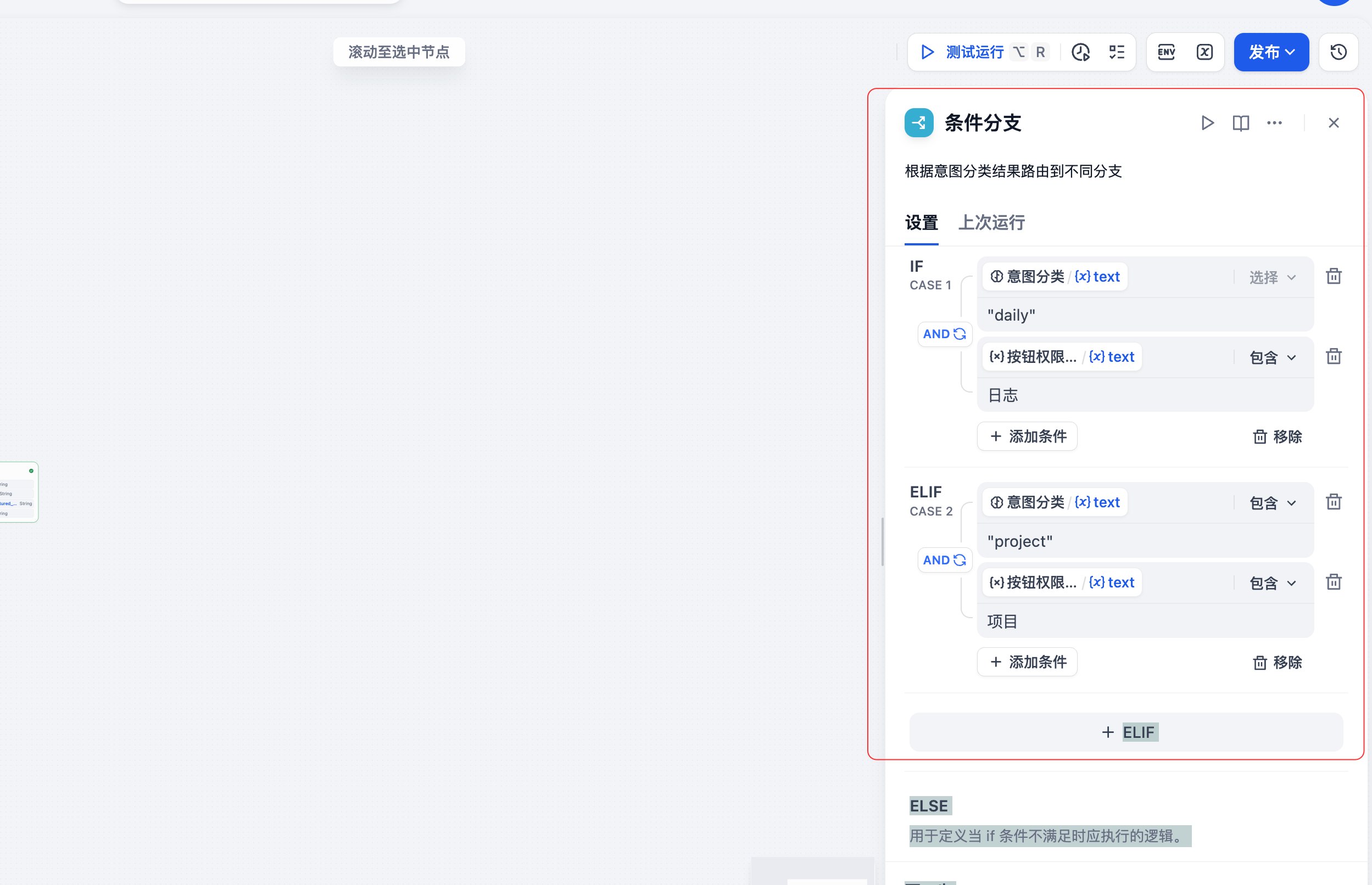
条件分支配置
上图展示了一个经典的意图分类条件分支:
IF (CASE 1):当意图分类为"daily"(日报查询)时
- 检查变量:
{{意图分类.text}} - 条件:包含 "daily"
- 匹配后执行日报查询分支
ELIF (CASE 2):当意图分类为"project"(项目查询)时
- 检查变量:
{{按钮权限.text}}(这里可能是配置有误,应该也检查意图分类) - 条件:包含 "project"
- 匹配后执行项目查询分支
ELSE:如果都不满足
- 执行兜底逻辑(比如提示用户重新输入)
这种分支结构使得一个工作流可以处理多种不同的业务场景,大大提高了系统的复用性。
适用场景提示:当你的助手需要处理多种不同类型的查询请求时(如日报、周报、项目查询、财务查询等),条件分支是必不可少的。建议先用LLM做意图识别,将用户的自然语言查询分类为固定的几种意图,再用条件分支分流到不同的处理逻辑。
2.4 代码块:数据处理的瑞士军刀
虽然LLM很强大,但在数据处理、统计计算等任务上,传统的代码往往更可靠、更高效。Dify的代码块节点支持Python3,可以编写自定义逻辑。
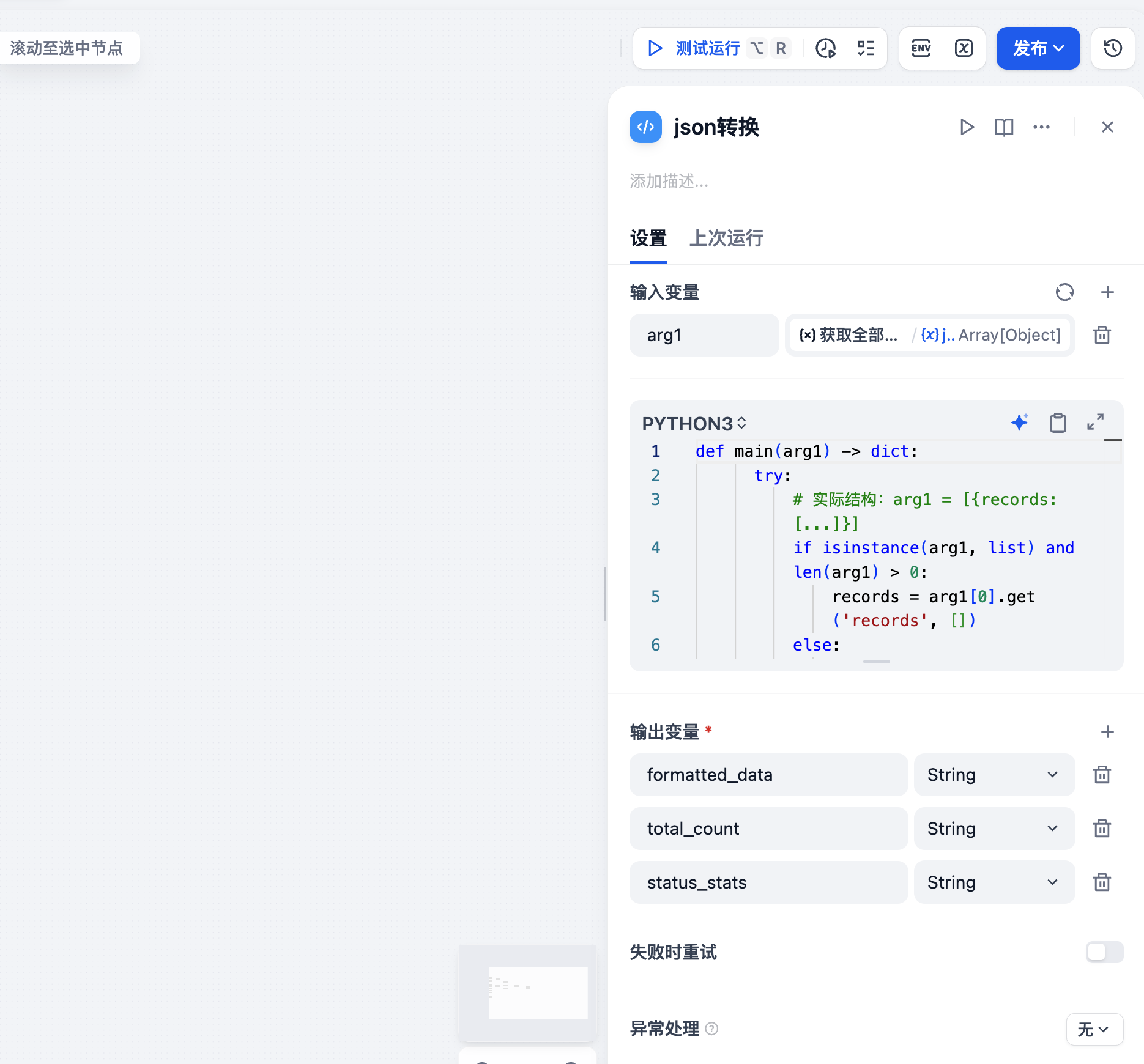
代码块实现
上图展示了一个"json转换"代码块的典型用法:
输入变量:
arg1:类型为Array[Object],这是SQL查询返回的数据
代码逻辑(从截图中可以看到):
def main(arg1) -> dict:
try:
# 实际结构:arg1 = [{records: [...]}]
if isinstance(arg1, list) and len(arg1) > 0:
records = arg1[0].get('records', [])
else:
records = []这段代码的作用是:
- 解析SQL返回的数据结构(Dify的SQL工具返回格式为
[{records: [...]}]) - 提取其中的
records数组 - 对数据进行统计、格式化等处理
- 输出为Markdown格式,便于展示
输出变量:
formatted_data(String):格式化后的Markdown文本total_count(String):项目总数status_stats(String):各状态项目的统计信息
适用场景提示:
- 数据统计:LLM在计数、求和等任务上不可靠,用代码块保证准确性
- 格式转换:将JSON数据转换为Markdown表格
- 复杂逻辑:比如根据权限过滤数据、提取特定字段、数据去重等
- 性能优化:代码执行速度远快于LLM,且不消耗Token
三、实战案例:构建项目信息查询助手
下面我们通过一个完整的案例,演示如何组合这些工具,构建一个实用的项目查询助手。
3.1 业务需求分析
我们的目标是构建一个助手,能够回答以下类型的问题:
- "帮我查一下新昌县天姥大桥项目的合同情况"
- "我负责的所有在建项目有多少个?"
- "XX项目的开票和回款进度"
关键技术挑战:
- 权限控制:不同用户看到的项目列表不同
- 信息整合:需要关联项目表、合同表、开票表、回款表
- 自然语言交互:用户用自然语言提问,系统需要理解意图并提取关键信息(如项目名称)
- 结果呈现:以对话式、易读的格式返回信息
3.2 工作流设计
整体流程如下:
用户输入
↓
意图识别(LLM)
↓
条件分支:是否为项目查询?
↓ 是
权限查询(SQL)→ 提取权限ID(代码块)
↓
查询所有项目(SQL)
↓
JSON转换(代码块)→ 格式化为Markdown,统计项目数
↓
项目ID提取(LLM)→ 从用户问题中识别具体项目
↓
条件分支:是查询具体项目还是列出所有项目?
↓ 查询具体项目
并行查询:合同信息(SQL)| 开票信息(SQL)| 回款信息(SQL)
↓
整合输出(LLM)→ 以对话形式呈现结果3.3 关键实现细节
3.3.1 权限控制的实现
首先查询用户权限:
SELECT permission_id, purview, type
FROM user_permission
WHERE user_id = '{{sys.user_id}}'然后用代码块处理权限数据:
def main(arg1) -> dict:
if isinstance(arg1, list) and len(arg1) > 0:
records = arg1[0].get('records', [])
else:
records = []
project_ids = []
depart_ids = []
is_permission = 'part' # 默认为部分权限
for record in records:
permission_id = record.get('permission_id', '')
purview = record.get('purview', '')
rec_type = record.get('type', '')
# 如果purview为1,表示有全部权限
if str(purview) == '1':
is_permission = 'all'
# 解析permission_id(可能是逗号分隔的多个ID)
if permission_id:
id_list = [id.strip() for id in permission_id.split(',')]
if rec_type == 'project':
project_ids.extend(id_list)
elif rec_type == 'depart':
depart_ids.extend(id_list)
# 去重并格式化为SQL IN子句格式
project_ids = list(set(project_ids))
project_ids_sql = ','.join([f"'{id}'" for id in project_ids])
return {
"project_ids": project_ids_sql,
"is_permission": is_permission
}这段代码的精妙之处:
- 判断用户是全部权限(
purview=1)还是部分权限 - 提取用户有权限的项目ID列表
- 将ID格式化为SQL的IN子句格式:
'id1','id2','id3'
然后在查询项目时,根据权限过滤:
SELECT * FROM projects
WHERE
({{#code.is_permission#}} = 'all') -- 如果是全部权限,不过滤
OR
(id IN ({{#code.project_ids#}})) -- 否则只查询有权限的项目3.3.2 数据统计与格式化
SQL查询返回的原始JSON数据不易阅读,我们用代码块进行格式化:
def main(arg1) -> dict:
try:
if isinstance(arg1, list) and len(arg1) > 0:
records = arg1[0].get('records', [])
else:
records = []
# 统计总数
total = len(records)
# 按项目状态分类统计
status_count = {}
for record in records:
status = record.get('project_status', '未知状态')
status_count[status] = status_count.get(status, 0) + 1
# 格式化输出为Markdown
output = f"## 项目查询结果\n\n"
output += f"### 统计概览\n"
output += f"- **项目总数**:{total} 个\n"
for status, count in status_count.items():
output += f"- **{status}**:{count} 个项目\n"
output += f"\n### 详细列表\n\n"
for i, record in enumerate(records, 1):
project_name = record.get('project_name', '未知项目')
owner_unit = record.get('owner_unit', '未知单位')
project_status = record.get('project_status', '未知状态')
output += f"**{i}. {project_name}**\n"
output += f"- 甲方单位:{owner_unit}\n"
output += f"- 项目状态:{project_status}\n\n"
return {
"formatted_data": output,
"total_count": str(total),
"status_stats": str(status_count)
}
except Exception as e:
return {
"formatted_data": f"数据解析失败:{str(e)}",
"total_count": "0"
}这个代码块的价值:
- 准确统计:LLM在计数上容易出错,代码保证准确性
- 结构化输出:生成美观的Markdown格式
- 异常处理:捕获错误,避免工作流崩溃
3.3.3 项目ID提取
当用户问"新昌县天姥大桥项目的合同情况"时,我们需要从项目列表中找到匹配的项目ID。这个任务适合用LLM:
系统提示词:
你是一个智能项目ID提取助手。
用户会提问关于项目的问题,你需要从项目列表中找到匹配的项目。
## 输出规则
情况1:匹配到 1-5 个项目
{
"type": "id",
"ids": "'id1','id2','id3'",
"content": ""
}
情况2:匹配到超过 5 个项目
{
"type": "info",
"ids": "",
"content": "找到 X 个相关项目,请明确您要查询的具体项目:[列出项目名称]"
}
情况3:未匹配到项目
{
"type": "info",
"ids": "",
"content": "未找到相关项目信息,请确认项目名称"
}用户提示词:
用户问题:{{#start.query#}}
项目列表:
{{#json_convert.formatted_data#}}
请提取项目ID或给出提示。通过LLM的语义理解能力,即使用户说的是"天姥大桥"而不是完整的"新昌县天姥大桥项目",也能准确匹配。
3.3.4 对话式结果呈现
最后,我们不希望输出僵硬的结构化报告,而是用对话的方式自然呈现信息:
系统提示词:
你是一个友好、专业的项目信息助手。以自然对话的方式整合项目信息。
## 核心原则
1. 像和朋友聊天一样自然地介绍信息
2. 自然融合合同、开票、回款等信息,不要分块罗列
3. 只展示用户有权限的内容
4. 如果信息较多,可以在最后用表格补充
## 可用数据
- 合同信息:{{#contract_query.text#}}
- 开票信息:{{#invoice_query.text#}}
- 回款信息:{{#payment_query.text#}}
## 输出示例
"关于新昌县天姥大桥项目,目前我们已经签订了两份合同,总金额约450万元。开票方面进展不错,已经开出了3期发票,累计金额320万。回款情况也比较顺利,目前已收到280万,还有170万在跟进中..."这种对话式的输出,比冰冷的表格更有温度,也更符合用户的使用习惯。
四、常见问题与解决方案
4.1 LLM统计不准确怎么办?
问题:让LLM统计"有多少个项目",每次答案都不一样。
解决方案:不要让LLM做统计!用代码块处理数据,进行精确计数。LLM只负责:
- 理解用户意图
- 提取关键信息(如项目名称)
- 格式化展示结果
数学计算和统计任务交给代码。
4.2 SQL查询返回的数据格式怎么解析?
问题:SQL节点返回的数据是[{records: [...]}]格式,如何解析?
解决方案:在代码块中:
if isinstance(arg1, list) and len(arg1) > 0:
records = arg1[0].get('records', [])注意:Dify的SQL工具返回的已经是Python对象,不需要json.loads()。
4.3 如何处理权限控制?
问题:不同用户看到的数据不同,怎么实现?
解决方案:
- 先查询用户权限,提取可访问的ID列表
- 用代码块格式化为SQL的IN子句:
'id1','id2','id3' - 在业务查询SQL中加上权限过滤条件
关键点:用变量{{sys.user_id}}获取当前用户ID。
4.4 如何避免输出过于冗长?
问题:LLM总是输出很多用户没问的信息。
解决方案:在提示词中明确强调:
只回答用户问的问题,不要主动展示额外信息。
代码块中的统计数据(total_count、status_stats)仅供参考,
除非用户明确询问统计信息,否则不要主动输出。4.5 如何让输出更美观?
问题:输出的数据太丑,不易阅读。
解决方案:
- 用代码块将数据格式化为Markdown(加粗、列表、表格)
- 在LLM提示词中给出格式示例
- 对于对话式输出,在最后补充表格作为详细数据的补充
五、最佳实践总结
经过实践,我们总结出以下最佳实践:
5.1 合理分工:LLM vs 代码
LLM擅长:
- 自然语言理解(意图识别、实体提取)
- 语义匹配(从项目列表中找到用户想要的项目)
- 自然语言生成(将结构化数据转换为对话式描述)
代码擅长:
- 数据统计与计算
- 格式转换
- 复杂的条件判断和循环
- 性能敏感的任务
记住:不要让LLM做数学题!
5.2 提示词设计技巧
- 明确输出格式:用JSON Schema约束LLM输出,避免格式混乱
- 给出示例:在提示词中给出好的输出示例和不好的反例
- 分步思考:对于复杂任务,引导LLM逐步分析
- 控制输出长度:明确告诉LLM"只回答问题,不要画蛇添足"
5.3 工作流设计原则
- 单一职责:每个节点只做一件事,便于调试和维护
- 容错处理:在代码块中加上try-except,避免因数据异常导致整个流程崩溃
- 权限前置:在流程开始就查询权限,后续节点自动过滤数据
- 并行优化:当多个查询没有依赖关系时(如同时查询合同、开票、回款),用并行节点提升性能
5.4 数据安全注意事项
- SQL注入防护:虽然Dify有一定的防护,但仍需注意不要直接拼接用户输入到SQL中
- 权限验证:所有数据查询都必须基于当前用户身份进行过滤
- 敏感信息脱敏:如果涉及手机号、身份证等敏感信息,在展示时进行脱敏处理
- 日志记录:记录每次查询的用户、时间、查询内容,便于审计
六、扩展思考:从查询助手到智能运营平台
当你成功构建了一个智能查询助手后,可以进一步思考:
6.1 多模态交互
结合Dify的语音识别和语音合成能力,让用户可以语音提问、语音接收结果,进一步降低使用门槛。
6.2 主动推送
不仅是被动回答问题,还可以:
- 每周一自动生成团队周报
- 项目进度延期时主动预警
- 重要节点(如合同到期)提前提醒
6.3 数据分析
在查询的基础上,增加分析能力:
- "分析一下我们公司最近三个月的项目成功率趋势"
- "对比不同地区的回款速度"
- "预测下个月的开票金额"
这需要结合统计分析、可视化等更多能力。
6.4 移动端支持
将Dify工作流封装为API,接入企业微信、钉钉等移动办公平台,让员工随时随地查询信息。
七、总结
通过本文的详细讲解,相信你已经掌握了使用Dify构建智能业务查询助手的完整方法。核心要点回顾:
- 明确适用场景:项目管理、日报周报、权限敏感查询、多维度数据整合
- 掌握三大工具:数据库查询、条件分支、代码块
- 合理分工:LLM负责理解和生成,代码负责计算和处理
- 权限控制:从查询开始就考虑权限,确保数据安全
- 用户体验:用对话式输出代替僵硬的结构化报告
Dify提供的低代码平台,让我们无需编写大量后端代码,就能快速搭建出一个实用的AI应用。但要做好,仍需深入理解业务逻辑、数据结构和用户需求。
希望本文能帮助你在企业数字化的道路上,用AI技术真正解决实际问题,让业务人员从繁琐的数据查询中解放出来,专注于更有价值的工作。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号