基于YOLO11的鹿群检测系统(Python源码+数据集+Pyside6界面)
原创
基于YOLO11的鹿群检测系统(Python源码+数据集+Pyside6界面)
原创
AI小怪兽
发布于 2025-12-04 13:00:03
发布于 2025-12-04 13:00:03
💡💡💡本文摘要:基于YOLO11的鹿群检测系统,阐述了整个数据制作和训练可视化过程

博主简介

AI小怪兽 | 计算机视觉算法专家 | 目标检测领域创新者
深耕计算机视觉与深度学习领域,专注于目标检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
- YOLO算法结构性创新:于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
- 技术生态建设与知识传播:独立运营 “计算机视觉大作战” 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
- 荣获腾讯云年度影响力作者与创作之星奖项,内容质量与专业性获行业权威平台认证。
- 全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
- 具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 “让每一行代码都有温度” 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。
1.YOLO11介绍
Ultralytics YOLO11是一款尖端的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。
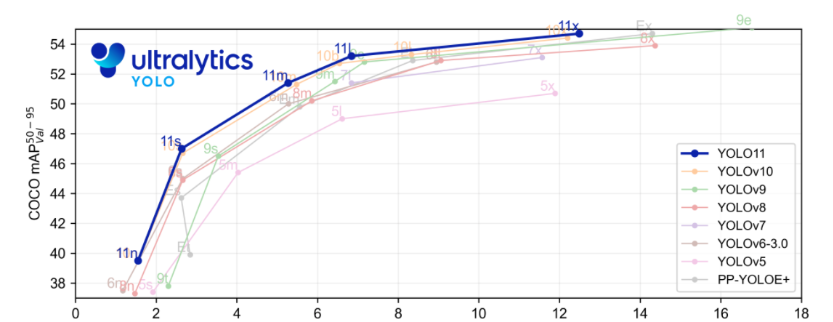

结构图如下:
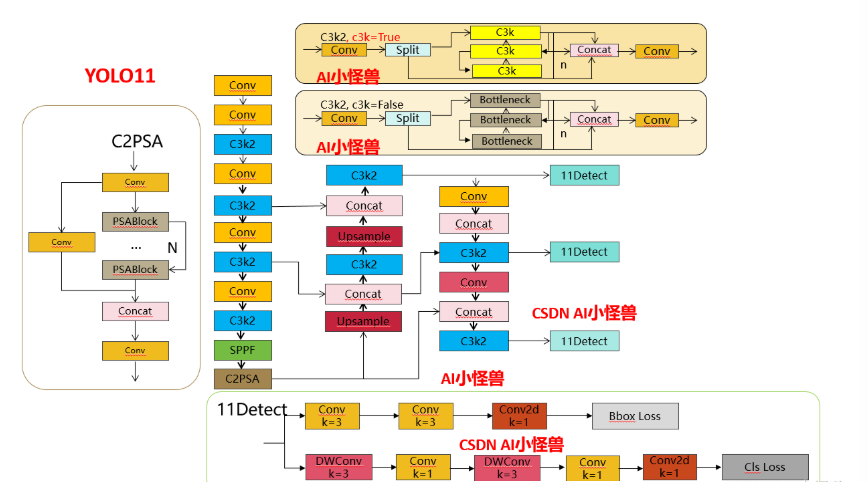
1.1 C3k2
C3k2,结构图如下
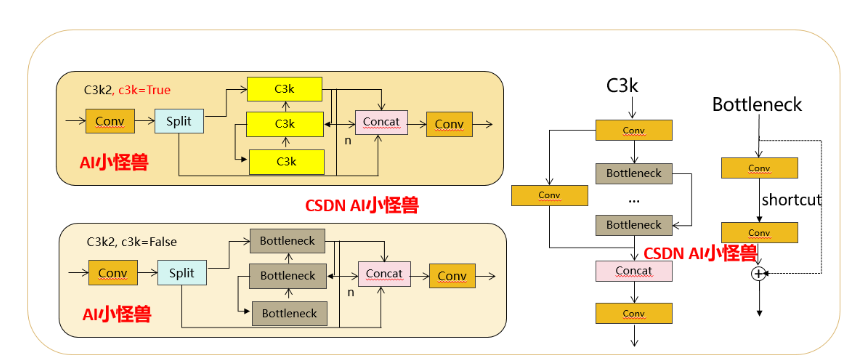
C3k2,继承自类C2f,其中通过c3k设置False或者Ture来决定选择使用C3k还是Bottleneck
实现代码ultralytics/nn/modules/block.py
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
class C3k(C3):
"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
"""Initializes the C3k module with specified channels, number of layers, and configurations."""
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))1.2 C2PSA介绍
借鉴V10 PSA结构,实现了C2PSA和C2fPSA,最终选择了基于C2的C2PSA(可能涨点更好?)
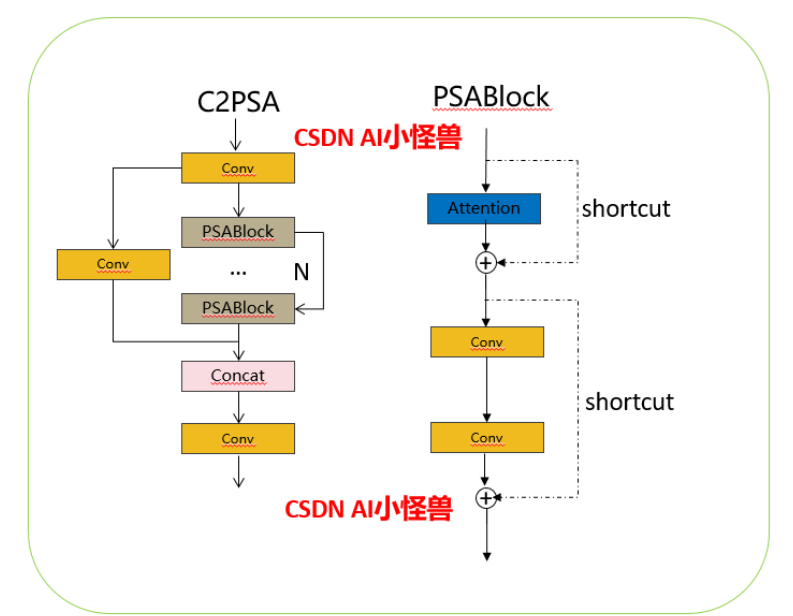
实现代码ultralytics/nn/modules/block.py
class PSABlock(nn.Module):
"""
PSABlock class implementing a Position-Sensitive Attention block for neural networks.
This class encapsulates the functionality for applying multi-head attention and feed-forward neural network layers
with optional shortcut connections.
Attributes:
attn (Attention): Multi-head attention module.
ffn (nn.Sequential): Feed-forward neural network module.
add (bool): Flag indicating whether to add shortcut connections.
Methods:
forward: Performs a forward pass through the PSABlock, applying attention and feed-forward layers.
Examples:
Create a PSABlock and perform a forward pass
>>> psablock = PSABlock(c=128, attn_ratio=0.5, num_heads=4, shortcut=True)
>>> input_tensor = torch.randn(1, 128, 32, 32)
>>> output_tensor = psablock(input_tensor)
"""
def __init__(self, c, attn_ratio=0.5, num_heads=4, shortcut=True) -> None:
"""Initializes the PSABlock with attention and feed-forward layers for enhanced feature extraction."""
super().__init__()
self.attn = Attention(c, attn_ratio=attn_ratio, num_heads=num_heads)
self.ffn = nn.Sequential(Conv(c, c * 2, 1), Conv(c * 2, c, 1, act=False))
self.add = shortcut
def forward(self, x):
"""Executes a forward pass through PSABlock, applying attention and feed-forward layers to the input tensor."""
x = x + self.attn(x) if self.add else self.attn(x)
x = x + self.ffn(x) if self.add else self.ffn(x)
return x
class C2PSA(nn.Module):
"""
C2PSA module with attention mechanism for enhanced feature extraction and processing.
This module implements a convolutional block with attention mechanisms to enhance feature extraction and processing
capabilities. It includes a series of PSABlock modules for self-attention and feed-forward operations.
Attributes:
c (int): Number of hidden channels.
cv1 (Conv): 1x1 convolution layer to reduce the number of input channels to 2*c.
cv2 (Conv): 1x1 convolution layer to reduce the number of output channels to c.
m (nn.Sequential): Sequential container of PSABlock modules for attention and feed-forward operations.
Methods:
forward: Performs a forward pass through the C2PSA module, applying attention and feed-forward operations.
Notes:
This module essentially is the same as PSA module, but refactored to allow stacking more PSABlock modules.
Examples:
>>> c2psa = C2PSA(c1=256, c2=256, n=3, e=0.5)
>>> input_tensor = torch.randn(1, 256, 64, 64)
>>> output_tensor = c2psa(input_tensor)
"""
def __init__(self, c1, c2, n=1, e=0.5):
"""Initializes the C2PSA module with specified input/output channels, number of layers, and expansion ratio."""
super().__init__()
assert c1 == c2
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.m = nn.Sequential(*(PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64) for _ in range(n)))
def forward(self, x):
"""Processes the input tensor 'x' through a series of PSA blocks and returns the transformed tensor."""
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = self.m(b)
return self.cv2(torch.cat((a, b), 1))
class C2fPSA(C2f):
"""
C2fPSA module with enhanced feature extraction using PSA blocks.
This class extends the C2f module by incorporating PSA blocks for improved attention mechanisms and feature extraction.
Attributes:
c (int): Number of hidden channels.
cv1 (Conv): 1x1 convolution layer to reduce the number of input channels to 2*c.
cv2 (Conv): 1x1 convolution layer to reduce the number of output channels to c.
m (nn.ModuleList): List of PSA blocks for feature extraction.
Methods:
forward: Performs a forward pass through the C2fPSA module.
forward_split: Performs a forward pass using split() instead of chunk().
Examples:
>>> import torch
>>> from ultralytics.models.common import C2fPSA
>>> model = C2fPSA(c1=64, c2=64, n=3, e=0.5)
>>> x = torch.randn(1, 64, 128, 128)
>>> output = model(x)
>>> print(output.shape)
"""
def __init__(self, c1, c2, n=1, e=0.5):
"""Initializes the C2fPSA module, a variant of C2f with PSA blocks for enhanced feature extraction."""
assert c1 == c2
super().__init__(c1, c2, n=n, e=e)
self.m = nn.ModuleList(PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64) for _ in range(n))1.3 11 Detect介绍
分类检测头引入了DWConv(更加轻量级,为后续二次创新提供了改进点),结构图如下(和V8的区别):
实现代码ultralytics/nn/modules/head.py
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch
)
self.cv3 = nn.ModuleList(
nn.Sequential(
nn.Sequential(DWConv(x, x, 3), Conv(x, c3, 1)),
nn.Sequential(DWConv(c3, c3, 3), Conv(c3, c3, 1)),
nn.Conv2d(c3, self.nc, 1),
)
for x in ch
)2. 背景
美国各地日益增长的鹿群数量给农民带来了严峻挑战,由于鹿侵入种植玉米、大豆、棉花和小麦等作物的农田,他们不得不承担由此产生的巨大经济损失。例如,密西西比州拥有全国最高的鹿群密度,一项对行栽作物生产者的调查显示,共有17,830英亩农田遭受鹿害,导致每年高达460万美元的经济损失(Mills and Croft, 2025)。研究表明,该问题遍及整个美国,野生动物对玉米、大豆、小麦和棉花造成的损失总计估计达5.926亿美元(McKee et al., 2021);另一项研究确认,在全美造成最广泛和最严重作物损害的野生生物主要物种是白尾鹿(Boyer et al., 2024)。
人们已探索了多种控制方法来减少野生动物相关的作物损失,例如围栏、狩猎、诱捕和驱避剂。然而,这些方法中的每一种在成本、可扩展性和长期可持续性方面都存在显著局限性。围栏是使用最广泛的威慑方法之一,高强度或带电围栏能有效减少鹿的侵入。但是,对于大规模农业经营而言,其成本高昂得令人望而却步,平均每英里高达13,000美元,并且需要持续维护以修复因风暴、倒下的树木或执意闯入的动物造成的损坏(Landguth et al., 2020)。此外,顽固的鹿常常学会破坏或绕过障碍物,随着时间推移降低了有效性。狩猎和扑杀计划代表了另一种策略。受监管的狩猎季节可以在局部地区提供一些缓解,但它们通常是季节性的,因此无法实现全年度的作物损失防控。更密集的扑杀计划可能会更显著地减少种群数量,但它们常常面临公众反对、动物福利关切以及关于改变野生动物种群的生态争论。这些计划还需要相关野生动物管理机构的许可,限制了农民的自主权和灵活性(Warren, 2011)。诱捕法经常用于野猪,并且如果策略性地使用大型围栏式陷阱可能会有效。然而,这种方法高度密集劳力,需要持续监控、投放诱饵和维护。诱捕还带有捕获非目标野生动物的风险,引发了生态和伦理方面的关切(Conover, 2001)。此外,尽管诱捕可能暂时抑制局部地区的种群数量,但野猪繁殖迅速并会重新侵入已处理过的土地,使得单靠诱捕不足以成为长期解决方案。
驱避剂也得到了广泛研究,特别是针对鹿(el Hani and Conover, 1995)。虽然化学或气味驱避剂可以暂时减少啃食压力,但它们通常在雨、风或阳光照射后迅速降解,因此需要频繁重新施用。总体而言,这些方法在很大程度上是反应性的,而非主动性的,只能在损害发生后解决问题。它们从长期来看通常是不可持续的,并可能给野生动物带来不必要的压力、伤害或死亡,从而引发伦理和生态方面的关切(Dubois et al., 2017)。
可持续的野生动物管理,在不采取致命措施的情况下主动防止鹿进入农田,代表了应对这些挑战的根本性解决方案(Abed et al., 2025; Kovacs and Hajnal, 2024)。未来的系统可以利用先进的计算机视觉和深度学习技术,尤其是YOLO模型(Terven et al., 2023),来实现对鹿出现和移动的高精度实时识别(Sharma et al., 2024)。随后,详细的输出结果(例如鹿在图像中的位置或增强的分割掩码)可以触发定制化的、动态的威慑手段,包括物种特异性的声音或光发射,或者由无人机和无人地面车辆执行的自主机动(Roca et al., 2024)。新兴研究中的一个常见设计模式涉及一个分层过程:初始的运动检测(通常通过被动红外传感器)会激活更复杂的基于视觉的模型进行动物识别。例如,S等人(2025)集成了一个卷积神经网络来识别动物,随后激活非致命威慑手段,如超声波、闪光或喷水装置。类似地,Mishra和Yadav(2024)采用PIR传感器来触发循环卷积神经网络,进而启动物种特异性的超声波频率以减轻动物的习惯化效应。针对其他物种,也开发了更先进的系统。例如,R等人(2025)设计了一套野猪威慑系统,该系统使用YOLOv5n(Jocher et al., 2020)来确认目标存在,然后将威慑手段从超声波升级到捕食者气味(狼尿)和叫声。
机器视觉是这些新兴威慑系统的基础,充当实时鹿检测的"眼睛"。在现有的方法中,YOLO模型因其在准确性和速度之间的平衡而优于两阶段检测器(如Faster R-CNN或EfficientDet),使其非常适合现场部署(I et al., 2025; Li et al., 2023)。例如,I等人(2025)在NVIDIA Jetson-Nano上证明了YOLOv10在野生动物检测上优于YOLOv5,实现了0.934的mAP@0.5。同样,Nishanth等人(2024)在树莓派上实现了一个基于YOLOv8m的监控系统,展示了其在低功耗边缘设备上的可行性。在最近的一个应用中,Temesgen等人(2025)将经过TensorRT优化的YOLOv5模型部署在NVIDIA Jetson Orion Nano上,用于基于无人机的威慑系统,实现了每帧仅0.025秒的推理时间。总的来说,这些研究证实了YOLO系列模型已成为在边缘硬件上实现实用、高性能野生动物检测系统的实际标准。
尽管近期取得了进展,但大多数鹿及野生动物检测研究仍然依赖私有数据集或通用目标检测数据集。例如,Abood等人(2023)将YOLOv5应用于PASCAL VOC数据集,而其他研究则使用了来自Roboflow Universe的包含多个动物类别的聚合数据集(I et al., 2025; Nishanth et al., 2024)。在针对鹿的研究中,定制数据集已被用于通过YOLOv8n从相机陷阱图像中检测梅花鹿(Sharma et al., 2024),以及通过YOLOv8-seg从无人机图像中识别不同鹿种(Roca et al., 2025)。然而,这些数据集通常局限于针对特定鹿群的简化场景,并且通常不公开,使得重现性和广泛的基准测试变得困难。表1总结了代表性研究,突显出亟需能够反映真实农场和田野复杂多变条件的、公开可用的、高质量的、领域特定的数据集。
另一方面,现有研究主要集中于单个YOLO模型,未能提供跨架构的全面基准测试或系统评估。此外,大多数研究仅评估了模型在高端GPU设备上的性能,很少有工作从效率和有效性方面检验其在边缘设备上的性能,而这对于实际现场部署至关重要。为了弥补这些空白,我们提出了一个公开可用的数据集,包含3,095张带有边界框标注的鹿图像,源自爱达荷相机陷阱项目,代表了具有挑战性的真实场景。利用该数据集,我们为YOLOv8至YOLOv11模型建立了全面的基准,不仅在高端的NVIDIA RTX 5090 GPU上评估性能,还在资源受限的平台(包括基于CPU的树莓派5和GPU加速的NVIDIA Jetson AGX Xavier)上进行了评估。这项研究预期将为推进用于野生动物检测与控制的机器视觉系统,以及在农业和其他领域的相关应用,提供宝贵的资源。本研究的主要贡献如下:
- 一个包含3,095张带边界框标注的鹿图像的开源数据集,涵盖了多样的环境条件和光照场景。
- 对四种YOLO架构(v8至v11)共12个模型变种在鹿检测任务上进行了全面评估和基准测试。
- 在边缘设备(包括基于CPU的树莓派5和GPU加速的NVIDIA Jetson AGX Xavier)上对12个YOLO模型变种进行了推理基准测试。
1.1. 数据获取
为进行全面比较,我们整理了两个鹿图像数据集。我们首先从 Roboflow Universe 中选择了一个包含带标注鹿图像的数据集,在后续讨论中称其为"Roboflow 数据集"。如图1所示,Roboflow 数据集 (Dyer, 2022) 包含 2,339 张在不同环境中拍摄的不同鹿种图像,这些图像大多光照条件良好,运动模糊极少,这在手动拍摄的图像中很常见。该数据集被划分为 2,043 张训练图像和 296 张验证图像。然而,正如图1所示,此类数据集未能完全体现真实野外条件下的挑战,例如低光环境、运动模糊、部分遮挡以及多变的相机陷阱设置。
为了更好地呈现这些场景,我们从爱达荷相机陷阱项目中整理了第二个数据集,该项目由爱达荷渔猎局通过 LILA BC 在线存储库 (Morris, 2022) 共享。该相机陷阱项目包含来自多个地区视频序列的超过 150 万张相机陷阱图像。虽然原始数据集仅提供序列级标签而没有边界框标注,但我们筛选了约 7,000 张包含鹿的图像(置信度分数 > 0.9),并使用计算机视觉标注工具 (CVAT) (Corporation, 2024) 手动为其中的 3,095 张图像添加了边界框标注。这个"相机陷阱数据集"随后被划分为 2,578 张训练图像和 517 张验证图像。一些代表性样本如图1所示。
这两个数据集在复杂性和真实性上存在显著差异。Roboflow 数据集由清晰、手动拍摄的鹿图像组成,大多光照良好,运动或遮挡有限,使其更适用于基线模型训练。相比之下,相机陷阱数据集捕捉的是具有挑战性的真实世界条件下的鹿,包括多变的背景、夜间/低光照设置、遮挡和伪装。因此,如图1所示,相机陷阱数据集为评估模型在野外部署中的鲁棒性提供了一个更真实的基准。

3.如何训练鹿群检测数据集
3.1 数据集介绍
常见的八类元器件图片共计2581张
数据集大小:
2064 images for training
517 images for validation类别1类:
nc: 1
names: ['Deer']
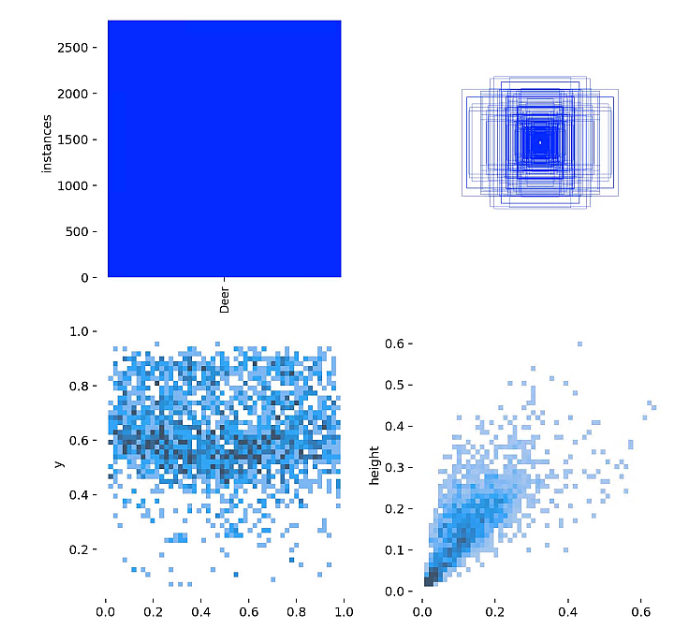
标签可视化分析
2.2 超参数修改
位置如下default.yaml
2.3 配置deer.yaml
ps:建议填写绝对路径
path: D:/YOLOv11/data/deer/
train: ./train/images
val: ./valid/images
nc: 1
names: ['Deer']
2.4 如何训练
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/11/yolo11.yaml')
#model.load('yolo11n.pt') # loading pretrain weights
model.train(data='data/deer.yaml',
cache=False,
imgsz=640,
epochs=200,
batch=8,
close_mosaic=10,
device='0',
optimizer='SGD', # using SGD
project='runs/train',
name='exp',
)
2.5 训练结果可视化结果
YOLO11 summary (fused): 341 layers, 3,265,489 parameters, 0 gradients, 7.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 17/17 [00:08<00:00, 2.07it/s]
all 517 736 0.966 0.849 0.934 0.729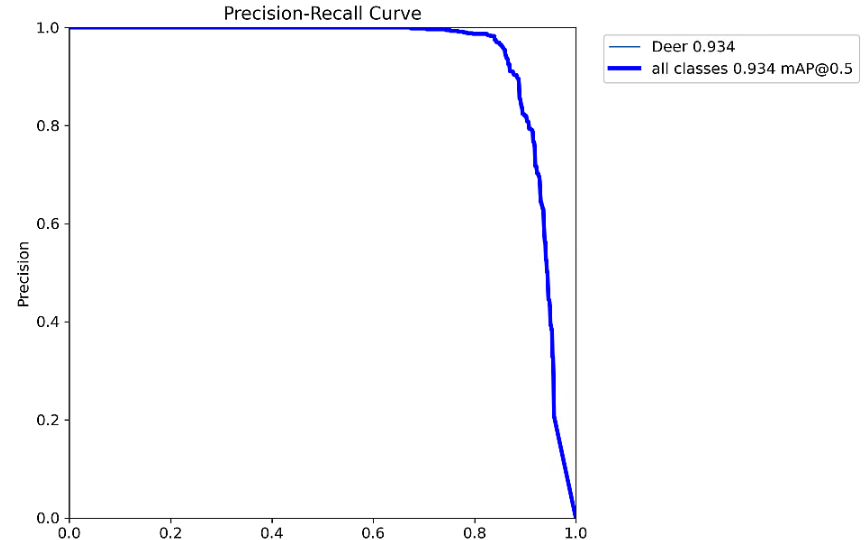
预测结果:

3.鹿群检测系统设计
3.1 PySide6介绍
受益于人工智能的崛起,Python语言几乎以压倒性优势在众多编程语言中异军突起,成为AI时代的首选语言。在很多情况下,我们想要以图形化方式将我们的人工智能算法打包提供给用户使用,这时候选择以python为主的GUI框架就非常合适了。
PySide是Qt公司的产品,PyQt是第三方公司的产品,二者用法基本相同,不过在使用协议上却有很大差别。PySide可以在LGPL协议下使用,PyQt则在GPL协议下使用。
PySide目前常见的有两个版本:PySide2和PySide6。PySide2由C++版的Qt5开发而来.,而PySide6对应的则是C++版的Qt6。从PySide6开始,PySide的命名也会与Qt的大版本号保持一致,不会再出现类似PySide2对应Qt5这种容易混淆的情况。
3.2 安装PySide6
pip install --upgrade pip
pip install pyside6 -i https://mirror.baidu.com/pypi/simple
基于PySide6开发GUI程序包含下面三个基本步骤:
- 设计GUI,图形化拖拽或手撸;
- 响应UI的操作(如点击按钮、输入数据、服务器更新),使用信号与Slot连接界面和业务;
- 打包发布;
3.3 鹿群检测系统设计

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号