Agentic AI 时代的内存(1)-从HBM谈起

Agentic AI 时代的内存(1)-从HBM谈起

数据存储前沿技术
发布于 2025-11-20 13:37:02
发布于 2025-11-20 13:37:02
阅读收获
- 掌握智能体AI记忆系统的分层架构:深入了解工作记忆与长期记忆的技术差异及其在AI推理中的具体作用
- 理解HBM技术的关键价值:认识高带宽内存在解决AI"内存墙"问题中的决定性作用
- 获得工程实践指导:学习如何平衡模型参数量与硬件性能,优化LLM生产部署方案
- 把握技术发展趋势:了解从HBM3E到HBM4E的技术演进路线,为未来AI基础设施建设做好准备
全文概览
在人工智能飞速发展的今天,智能体AI(Agentic AI)正面临着前所未有的内存挑战。您是否曾思考过,一个能够进行复杂推理和决策的AI系统,其"记忆"系统是如何构建的?
传统AI模型的内存需求相对简单,但智能体AI的记忆系统被划分为工作记忆和长期记忆两大体系,每种记忆都有不同的技术要求和存储特性。工作记忆负责实时任务处理,而长期记忆则包含程序性记忆、语义记忆和情景记忆三个维度。这种复杂的记忆架构对存储系统提出了TB级甚至数十TB级的容量需求,同时还需要满足极高的带宽要求。本文将带您深入理解智能体AI内存系统的技术挑战和解决方案。
👉 划线高亮 观点批注
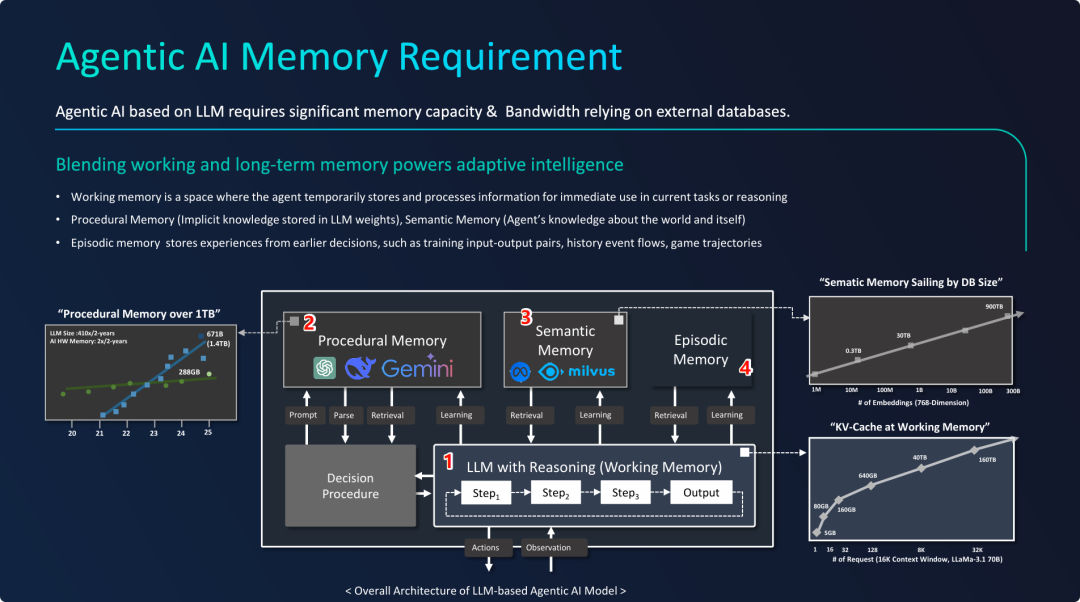
智能体AI的内存需求
智能体AI的内存需求
核心概念: 图片首先提出了一个核心概念:“Blending working and long-term memory powers adaptive intelligence”(融合工作记忆和长期记忆,驱动自适应智能)。它将AI的记忆系统分为两大类:
- 工作记忆 (Working Memory): AI用于处理当前任务或进行推理时,临时存储和处理信息的空间。
- 长期记忆 (Long-term Memory):
- 程序性记忆 (Procedural Memory): 隐性知识,存储在LLM的权重中。代表了AI“如何做”的技能和知识。
- 语义记忆 (Semantic Memory): 关于世界和其自身的知识。代表了AI“知道什么”。
- 情景记忆 (Episodic Memory): 存储来自早期决策的经验,例如训练的输入输出对、历史事件流、游戏轨迹等。代表了AI的“经历”。
===
PPT的核心观点是,构建一个强大的智能体AI(Agentic AI)对内存和存储系统提出了前所未有的、多层次的巨大需求。
- AI记忆系统是分层的: 智能体AI的记忆系统被划分为工作记忆(处理当前任务)和长期记忆(知识、技能、经验),这两种记忆需要不同的技术和存储介质来承载。
- 需求是多维度的,且均达到TB级以上:
- 程序性记忆 (模型本身): 随着LLM模型参数量的增长,其自身大小已达到 TB 级别。
- 语义记忆 (外部知识库): 存储外部知识的向量数据库,其容量需求可达 数十TB。
- 工作记忆 (运行时缓存): 在高并发推理时,仅KV缓存一项就能消耗 上百TB 的内存。
- 架构复杂性: 整个系统不是单一的内存池,而是一个复杂的架构,融合了LLM(如Gemini)、外部数据库(如Milvus)和高速缓存机制,并通过检索、学习等方式进行交互,这对数据流动的带宽和延迟提出了极高要求。
PPT通过架构图和量化数据,清晰地揭示了Agentic AI对存储和内存系统的挑战:容量巨大、类型多样、架构复杂,预示着未来的AI基础设施必须具备能够同时满足这三种不同记忆需求的高性能、大容量、分层式的存储解决方案。
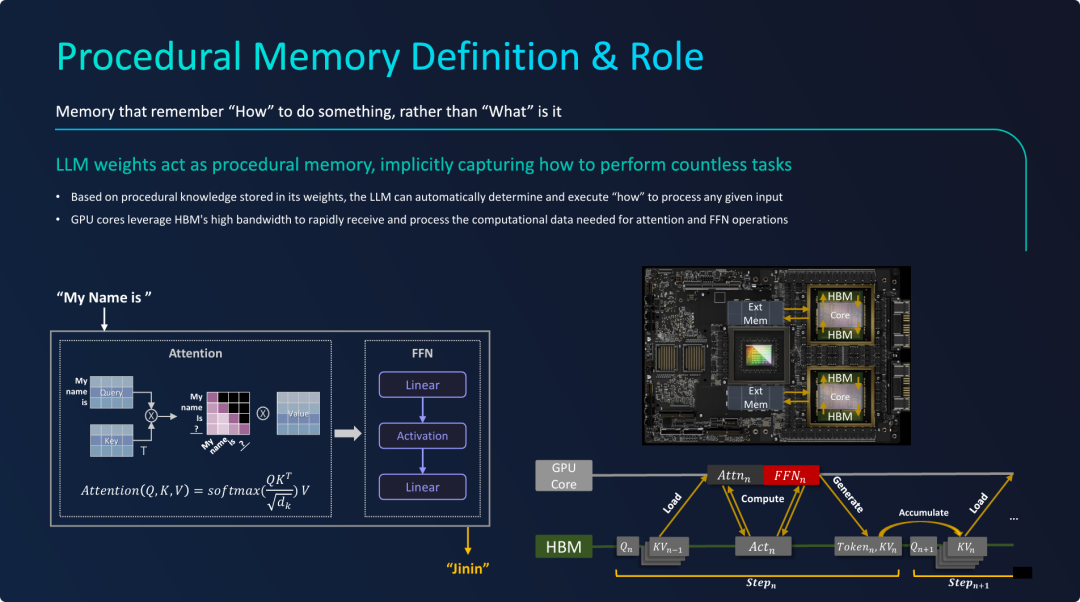
程序性记忆的定义与作用
程序性记忆的定义与作用
- 核心定义:
- 第一句就点明了程序性记忆的本质:“Memory that remember 'How' to do something, rather than 'What' is it”(一种记得“如何做”某事的记忆,而不是“是什么”的记忆)。
- 紧接着解释道:“LLM weights act as procedural memory, implicitly capturing how to perform countless tasks”(大语言模型的权重扮演了程序性记忆的角色,它隐式地捕获了如何执行无数任务的方法)。
- 作用阐述:
- 基于存储在权重中的程序性知识,LLM能够自动决定并执行“如何”处理任何给定的输入。
- 特别指出了硬件层面的实现:“GPU cores leverage HBM's high bandwidth to rapidly receive and process the computational data needed for attention and FFN operations”(GPU核心利用HBM的高带宽来快速接收和处理注意力机制及前馈网络运算所需的计算数据)
可以说:HBM 是 程序性记忆的最佳载体,因此需要满足GPU计算/LLM工作 过程中对数据高带宽的处理诉求,且这一部分记忆的容量是极其昂贵且相对有限。
===
PPT的核心观点是,LLM的权重就是其程序性记忆,它编码了模型执行任务的“方法论”,而这种记忆的有效运作高度依赖于GPU和HBM等高性能硬件。
- 定义了程序性记忆: 在AI领域,程序性记忆不是传统数据库里的事实,而是LLM模型参数中蕴含的、用于解决问题的隐式知识和计算流程。
- 揭示了实现机制: 通过拆解Transformer模型的核心部件——Attention机制和FFN网络,具体展示了LLM“如何”一步步处理输入并生成输出,将抽象的“程序性记忆”概念具象化。
- 强调了硬件依赖性: 明确指出程序性记忆(LLM权重)物理上存储在GPU的HBM中。并通过计算流程图强调,HBM的高带宽是保证GPU能够快速读取模型参数和中间计算结果(如KV Cache),从而高效执行这些复杂“程序”的关键。没有高带宽内存,GPU的强大算力将无法得到充分发挥。
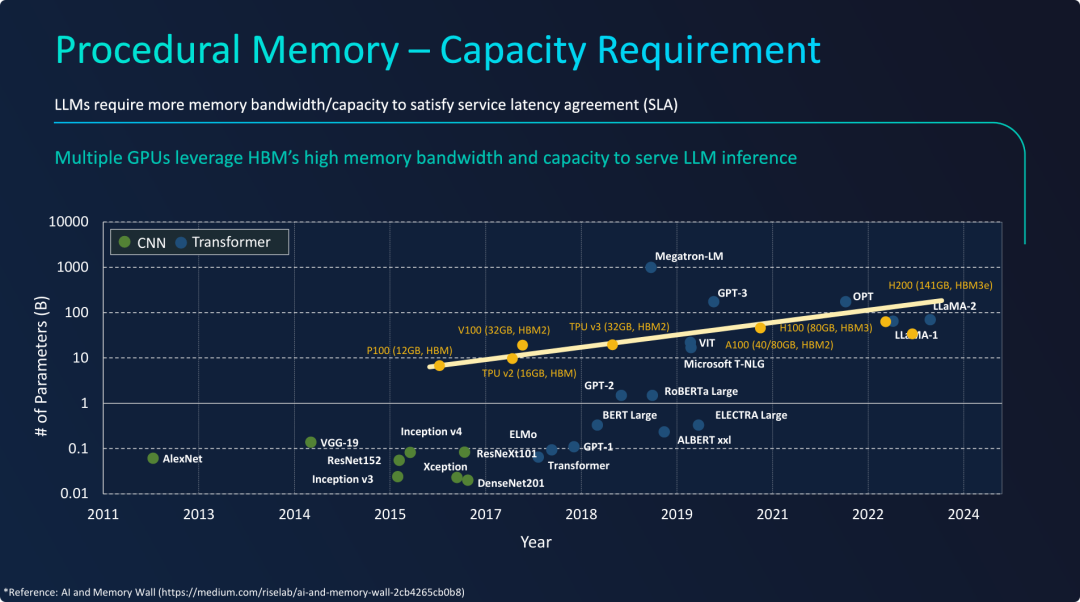
不同模型参数量及同时期GPU加速卡HBM容量
不同模型参数量及同时期GPU加速卡HBM容量
PPT的核心观点是,Transformer架构的兴起导致AI模型的程序性记忆(即模型权重)容量需求呈指数级增长,其速度远远超过了单个GPU上高带宽内存(HBM)的增长速度,从而形成了一道“内存墙”。
- 需求与供给的失衡: AI模型(特别是LLM)对内存容量的需求增长是指数级的,而硬件(单个GPU)的内存容量供给增长是相对线性和缓慢的。
- “内存墙”问题凸显: 这个日益扩大的差距意味着单个GPU已经远不足以容纳一个完整的大型语言模型。例如,一个需要350GB内存的GPT-3模型无法直接加载到只有80GB HBM的A100 GPU中。
- 解决方案的必然性: 为了解决“内存墙”问题,唯一的办法就是使用多个GPU协同工作。其首要目的就是将所有GPU的HBM容量汇集起来,形成一个足够大的内存池来“装下”整个模型。这解释了为什么现代LLM推理和训练集群通常由数十甚至数百个GPU组成,这不仅是为了算力,更是为了内存容量。
与 Transformer 架构相比,CNN 架构的特点是什么?为什么 Transformer 能成为深度学习的新宠?
CNN 架构的核心特点 (与 Transformer 对比)
卷积神经网络(CNN)的设计灵感来源于生物的视觉皮层,它为处理网格状数据(如图像)引入了非常有效的归纳偏置 (Inductive Bias)。归纳偏置可以理解为模型在学习之前做出的一些“先验假设”。CNN的成功很大程度上归功于它的两个核心假设:
- 局部性 (Locality): 假设相邻的区域存在关联。一个像素和它周围的像素关系更密切,而和很远的像素关系较弱。这是通过卷积核 (Kernel) 实现的,卷积核只在输入数据的一个小邻域(感受野)内进行计算。
- 平移不变性 (Translation Invariance): 假设一个物体出现在图像的任何位置,它仍然是同一个物体。这是通过权重共享 (Weight Sharing) 实现的,即用同一个卷积核去滑过整张图片,以及通过池化 (Pooling) 操作来实现。
基于以上特点,我们可以将 CNN 和 Transformer 进行一个清晰的对比:
特性 | 卷积神经网络 (CNN) | Transformer |
|---|---|---|
核心思想 | 局部关联和空间层级 通过小范围的卷积核逐层提取从低级(边缘、纹理)到高级(物体部件、整体)的特征。 | 全局依赖和上下文感知 使用自注意力机制(Self-Attention)直接计算输入序列中任意两个位置之间的相互依赖关系。 |
数据处理方式 | 卷积运算 在局部感受野内滑动卷积核进行加权求和。天然地处理空间局部信息。 | 自注意力机制 为序列中的每个元素(Token)计算一个加权平均值,权重来自于该元素与其他所有元素的相似度。 |
归纳偏置 | 强偏置 内置了强大的“局部性”和“平移不变性”假设,使其在图像任务上非常高效,学习速度快。 | 弱偏置 除了序列元素的顺序(通过位置编码注入)外,几乎没有对数据结构做任何假设。它必须从数据中学习所有关系。 |
计算复杂度 | 对输入尺寸呈线性关系 O(N),其中N是像素点总数。处理高分辨率图像非常高效。 | 对序列长度呈平方关系 O(L²),其中L是序列长度。当序列很长时(如将高分率图像像素展平),计算量会爆炸式增长。 |
适用领域 | 天然适用于网格状数据,如图像、视频、光谱图等,在计算机视觉领域长期占据主导地位。 | 最初为序列数据(自然语言)设计,但其通用性使其可以被改造用于视觉(ViT)、语音、蛋白质折叠等多种领域。 |
为什么 Transformer 能成为深度学习的新宠?
Transformer之所以能超越CNN和RNN(循环神经网络),成为当前AI领域(尤其是大模型时代)的主宰,主要有以下几个革命性优势:
- 完美解决了长距离依赖问题 这是Transformer最核心的优势。
- CNN的局限: 由于卷积核的感受野有限,一个CNN层只能捕获局部信息。要想捕获全局信息,必须堆叠非常多的层,让感受野逐渐扩大,这使得信息在层层传递中容易丢失或失真。
- RNN的局限: RNN按顺序处理数据,理论上可以记忆长序列信息,但存在梯度消失/爆炸问题,导致其很难真正记住几百个时间步之前的信息。
- Transformer的突破: 自注意力机制允许序列中的任意一个词元(Token)直接与序列中所有其他词元进行交互和信息加权。这两个词元无论在序列中相隔多远,其信息交互的路径长度都是1。这从根本上解决了长距离依赖的难题,使得模型能够理解更复杂的全局上下文。
- 强大的并行计算能力,为大数据时代而生 训练大模型需要巨大的计算资源,而并行计算能力是关键。
- RNN的瓶颈: RNN的计算是串行的,必须计算完上一个时间步(t−1)的结果,才能计算当前时间步(t),这严重限制了其在现代GPU上的训练速度。
- Transformer的优势: Transformer的自注意力计算没有这种串行依赖。对于一层内的所有词元,其注意力得分可以完全并行计算,这完美契合了GPU的架构,极大地提升了训练效率,使得训练拥有数千亿甚至万亿参数的超大规模模型成为可能。
- 惊人的模型可扩展性 (Scaling Law) 研究发现,Transformer架构具有非常好的“缩放法则”(Scaling Law)。这意味着,当你增加模型参数量、增加训练数据量、投入更多计算资源时,模型的性能会可预测地持续提升。这种“大力出奇迹”的特性,给了研究机构和企业巨大的信心去投入资源构建史无前例的超大模型(如GPT系列),因为他们知道投入很大概率会换来性能的回报。
- 架构的通用性和灵活性 由于Transformer的归纳偏置很弱,它不对数据做过多假设,这反而使它成为一种极其通用的“积木”。通过将不同类型的数据“Token化”(例如,将图像切分成小块 Patch),就可以将同一个Transformer架构应用到自然语言、计算机视觉、语音识别、生物信息等多个领域,并取得顶尖效果。这种“一个架构统一多个领域”的潜力是CNN等专用架构无法比拟的。
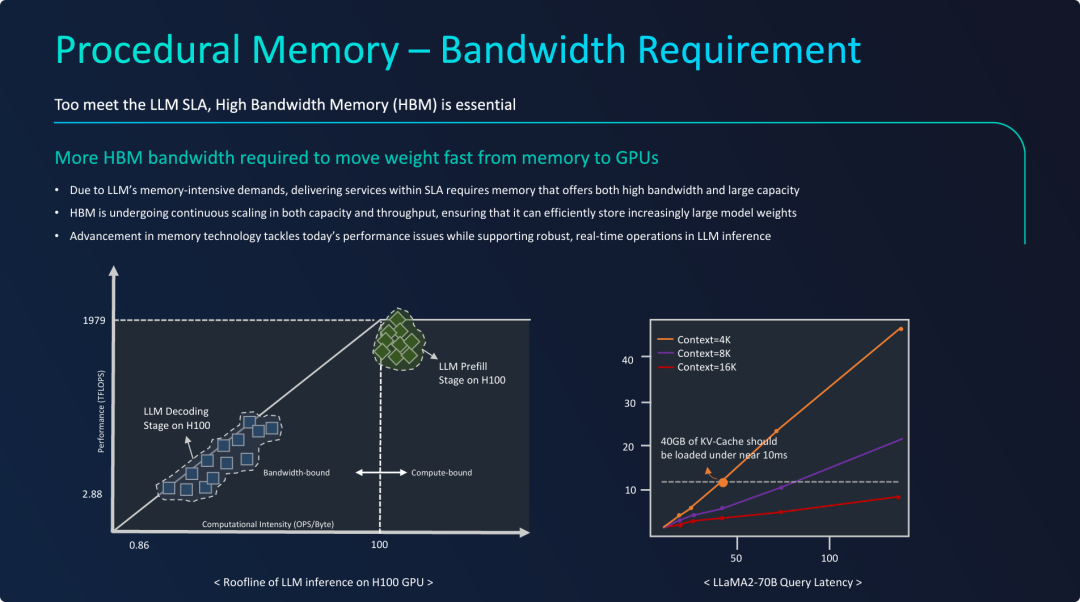
程序性记忆对内存带宽的诉求
程序性记忆对内存带宽的诉求
PPT的核心观点是,对于LLM推理,尤其是要满足实时交互的低延迟要求,内存带宽是与内存容量同等重要、甚至更为关键的性能瓶颈。
- LLM推理分为两个阶段,瓶颈不同:
- 处理用户输入的Prefill阶段是计算密集型的,瓶颈在GPU的算力。
- 逐字生成回答的Decoding阶段是带宽密集型的,瓶颈在于从HBM中读取模型权重的速度。对于聊天等实时应用,用户感受到的延迟主要由Decoding阶段决定。
- Decoding阶段是延迟关键,且受限于带宽: 屋顶线模型清晰地证明,在生成回复的每一步,GPU的强大算力都无法完全发挥,因为它在“等待”数据从内存中送达。因此,提升内存带宽是降低Decoding阶段延迟的最直接手段。
- KV缓存的读写加剧了带宽压力: 除了模型权重,不断增长的KV缓存(属于工作记忆)也需要在每个token生成步骤中被高速读写。图表中标注的“10毫秒内加载40GB”具体说明了这种需求已经达到了4 TB/s级别,只有HBM这样的技术才能满足。
PPT有力地论证了高带宽内存(HBM)是现代LLM推理加速器的“生命线”。没有HBM提供的超高带宽,即使GPU拥有再强的算力,也无法快速地将庞大的程序性记忆(模型权重)和工作记忆(KV缓存)喂给计算单元,从而无法满足实时应用苛刻的SLA延迟要求。
这两张图对于理解现阶段的LLM工程应用有帮助: - 左图,直观诠释了 PD 分离为什么成为现阶段LLM生产应用的最佳实践,因其workload的资源禀赋有显著差异,做好分离优化能进一步提升工程效率,另一方面来看,GPU硬件的计算能力和HBM带宽不可能无限制地增长,对模型参数量的工程优化,以平衡计算、高带宽两者的解耦损失,可能是端侧大模型应用关键。 - 右图,模型上下文是时延敏感型参数,尽管上下文长度能一定程度增强模型的专用性,但盲目追求上下文长度,将带来硬件瓶颈,具体场景优化模型上下文长度能避免对硬件性能的过度追求。
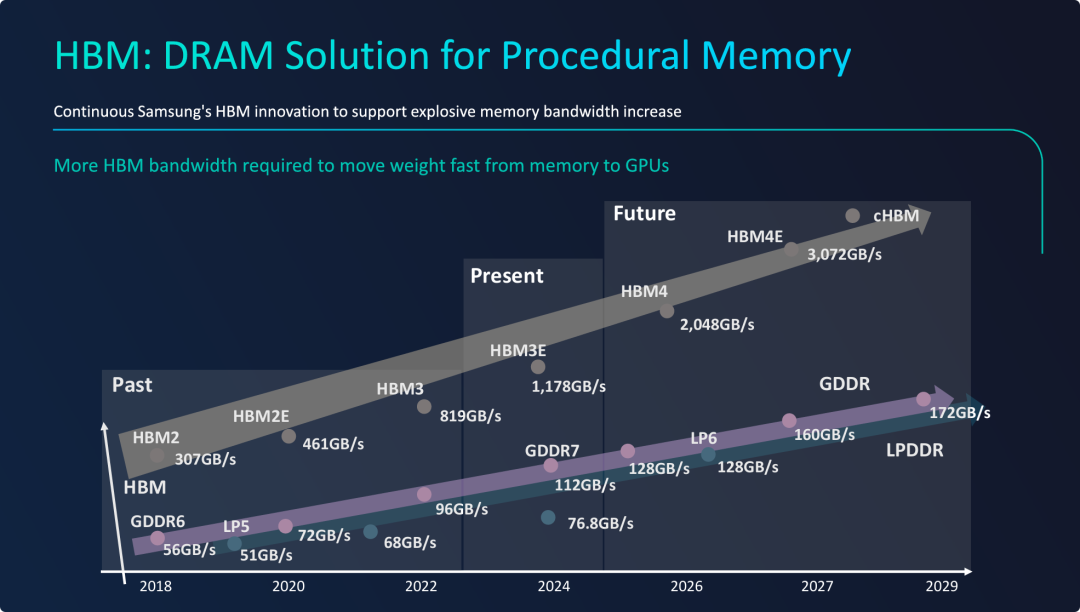
HBM:程序性记忆的DRAM解决方案
HBM:程序性记忆的DRAM解决方案
PPT的核心观点是,HBM是唯一能够满足现代及未来AI大模型(程序性记忆)极端带宽需求的内存技术解决方案,其发展速度和性能水平已经与传统内存拉开了决定性的差距。
- 明确技术选型: PPT明确指出,为了解决前几页所提出的“带宽墙”问题,行业的技术选择已经聚焦于HBM。
- 展示性能优势: 通过与GDDR/LPDDR的直接对比,图表极具说服力地展示了HBM在带宽上的绝对领先地位。这种领先优势并非微不足道,而是存在一个数量级的差异。
- 描绘未来蓝图: 图表不仅说明了现状,更重要的是描绘了HBM技术的未来发展路线图。从HBM3E的 1.2 TB/s到HBM4E的 3 TB/s,这个清晰的、指数级增长的蓝图,向业界传递了一个明确的信号:内存技术正在努力跟上AI算力的发展步伐,为下一代更强大的AI模型铺平道路。
- 强化核心问题: 整张PPT是对前面所有问题的一个总结性回答。既然程序性记忆(LLM权重)的访问是带宽密集型的,那么解决方案就必须是一种拥有超高带宽的内存技术,而HBM正是为此而生的。
有同学可能会比较好奇:HBM 带宽何以能超越同时期 GDDR/DDR/LPDDR 数十倍,这样从其片上集成方式和通信原理入手,建议阅读:HBM,先进封装和能效的集大成者
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- 随着AI模型参数量的持续增长,除了HBM技术外,还有哪些创新的内存架构可能突破当前的"内存墙"限制?
- 在实际工程部署中,如何在不同类型的记忆需求(程序性、语义性、情景性)之间实现最优的资源分配和性能平衡?
- 考虑到Transformer架构的平方复杂度问题,未来是否会出现新的AI架构能够在保持强大性能的同时,显著降低对内存带宽的依赖?
原文标题:Heterogeneous Memory Opportunity [1] with Agentic AI and Memory Centric Computing
Notice:Human's prompt, Datasets by Gemini-2.5-Pro
#FMS25 #HBM
---【本文完】---
公众号:王知鱼,专注数据存储、云计算趋势&产品方案。
PPT取自 Samsung 资深系统架构师 Jinin So,在FMS 2025 闪存峰会上的汇报材料。
👇阅读原文,查看历史文章,推荐PC端打开 💻。
- https://files.futurememorystorage.com/proceedings/2025/20250807_DRAM-304-1_SO.pdf ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号