Java AI 开发全攻略:Spring AI、LangChain4J、Dify、百炼与微调一站式掌握

Java AI 开发全攻略:Spring AI、LangChain4J、Dify、百炼与微调一站式掌握

javpower
发布于 2025-11-17 19:26:27
发布于 2025-11-17 19:26:27
Java AI 开发全攻略:Spring AI、LangChain4J、Dify、百炼与微调一站式掌握
第 1 部分:Spring AI基础设施实战
Spring AI 作为 Spring 官方推出的 AI 应用开发框架,其核心设计哲学是将 AI 能力无缝集成到 Spring 生态系统中,为 Java 开发者提供熟悉、一致的编程模型。Spring AI 不是要重新发明轮子,而是基于 Spring 的核心原则——依赖注入、面向切面编程和模板模式,为各种 AI 服务提供统一的抽象层。
核心架构组件
Spring AI 的架构设计遵循典型的三层架构模式,但在每一层都针对 AI 特性进行了专门优化:
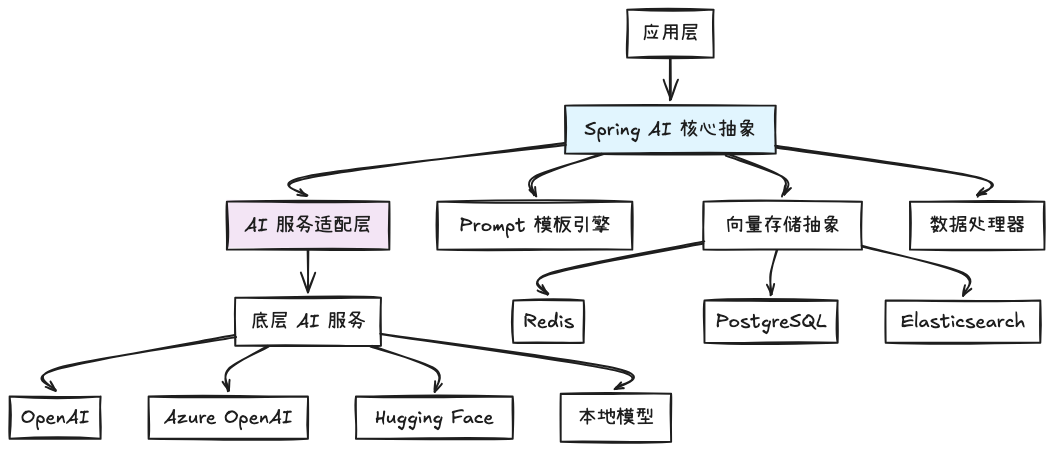
核心抽象层提供了统一的 API 接口,主要包括:
ChatClient- 对话服务抽象EmbeddingClient- 向量嵌入服务抽象VectorStore- 向量存储抽象PromptTemplate- 提示词模板引擎
统一配置与依赖注入
Spring AI 充分利用 Spring Boot 的自动配置特性,通过简单的配置即可接入不同的 AI 服务:
@Configuration
@EnableAi
publicclass AiConfig {
@Bean
public ChatClient openAiChatClient(
@Value("${spring.ai.openai.api-key}") String apiKey) {
returnnew OpenAiChatClient(apiKey);
}
@Bean
public EmbeddingClient embeddingClient(
@Value("${spring.ai.openai.api-key}") String apiKey) {
returnnew OpenAiEmbeddingClient(apiKey);
}
}
对应的 application.yml 配置:
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
chat:
options:
model: gpt-4
temperature: 0.7
Prompt 模板引擎详解
Spring AI 的 Prompt 模板引擎是其最强大的特性之一,支持动态变量替换和结构化提示词构建:
@Service
publicclass CustomerServiceAiAssistant {
privatefinal ChatClient chatClient;
public CustomerServiceAiAssistant(ChatClient chatClient) {
this.chatClient = chatClient;
}
public String generateResponse(String customerQuery, String context) {
PromptTemplate promptTemplate = new PromptTemplate("""
你是一名专业的客户服务代表。请基于以下上下文信息回答用户问题。
上下文:{context}
用户问题:{question}
请用专业、友好的语气回复,如果信息不足请明确说明。
""");
Prompt prompt = promptTemplate.create(
Map.of("context", context, "question", customerQuery));
return chatClient.call(prompt).getResult().getOutput().getContent();
}
}
向量存储与检索增强生成(RAG)
Spring AI 对 RAG 模式提供了原生支持,通过统一的 VectorStore 接口实现:
@Component
publicclass DocumentSearchService {
privatefinal VectorStore vectorStore;
privatefinal EmbeddingClient embeddingClient;
public DocumentSearchService(VectorStore vectorStore,
EmbeddingClient embeddingClient) {
this.vectorStore = vectorStore;
this.embeddingClient = embeddingClient;
}
public void addDocument(String documentId, String content) {
// 生成文档向量
List<Double> embedding = embeddingClient.embed(content);
// 构建文档向量对象
Document document = new Document(documentId, content, embedding);
// 存储到向量数据库
vectorStore.add(List.of(document));
}
public List<Document> similaritySearch(String query, int topK) {
// 生成查询向量
List<Double> queryEmbedding = embeddingClient.embed(query);
// 执行相似度搜索
return vectorStore.similaritySearch(
SearchRequest.query(query)
.withTopK(topK)
.withSimilarityThreshold(0.7)
);
}
}
流式响应处理
对于需要实时响应的场景,Spring AI 支持流式 API:
@RestController
public class StreamingChatController {
@PostMapping("/chat/stream")
public Flux<String> streamChat(@RequestBody ChatRequest request) {
return chatClient.stream(request.getPrompt())
.map(chatResponse -> chatResponse.getResult().getOutput().getContent());
}
}
Spring AI 通过这种设计,使得 Java 开发者能够以熟悉的方式构建 AI 应用,同时享受 Spring 生态系统的全部优势——强大的依赖注入、声明式事务管理等。这种"约定优于配置"的理念大幅降低了 AI 应用的学习曲线和开发成本。
第 2 部分:LangChain4J:大模型应用框架深度拆解
LangChain4J 作为 Java 生态中功能最丰富的大模型应用框架,其设计哲学是提供一套完整的工具链来构建复杂的 AI 应用。与 Spring AI 的轻量级集成不同,LangChain4J 提供了更加细粒度的组件化和模块化设计,支持从简单的对话应用到复杂的多步推理工作流。
核心架构层次
LangChain4J 采用分层的架构设计,每一层都提供特定的抽象和能力:
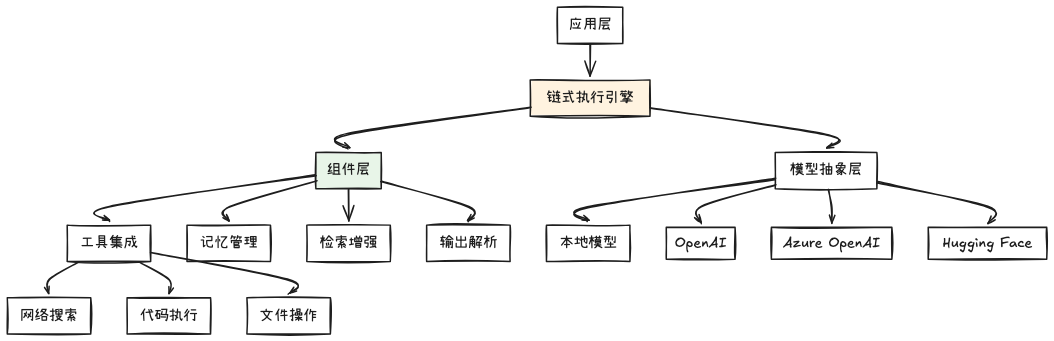
链式执行引擎是 LangChain4J 的核心,负责协调各个组件的执行顺序和数据流转。与 Spring AI 的模板式调用不同,LangChain4J 支持复杂的多步骤工作流。
链式编程模型详解
LangChain4J 的链式模型允许开发者构建复杂的工作流:
public class CustomerSupportChain {
privatefinal ChatLanguageModel chatModel;
privatefinal EmbeddingModel embeddingModel;
privatefinal EmbeddingStore<TextSegment> embeddingStore;
public CustomerSupportChain(ChatLanguageModel chatModel,
EmbeddingModel embeddingModel,
EmbeddingStore<TextSegment> embeddingStore) {
this.chatModel = chatModel;
this.embeddingModel = embeddingModel;
this.embeddingStore = embeddingStore;
}
public String processCustomerQuery(String query, String customerId) {
// 构建复杂的处理链
return AiServices.builder(CustomerSupportService.class)
.chatLanguageModel(chatModel)
.tools(new CustomerDatabaseTool(), new ProductCatalogTool())
.build()
.handleCustomerQuery(query, customerId);
}
// 定义 AI 服务接口
interface CustomerSupportService {
@SystemMessage("你是一名专业的客户支持专家,拥有访问客户数据和产品目录的权限。")
@UserMessage("处理客户查询:{{it}}")
String handleCustomerQuery(@V("it") String query,
@V("customerId") String customerId);
}
}
工具集成与函数调用
LangChain4J 的工具系统是其最强大的特性之一,允许模型调用外部函数:
public class AdvancedToolsIntegration {
// 定义工具接口
@Tool("根据客户ID获取客户信息")
public CustomerInfo getCustomerInfo(@P("客户ID") String customerId) {
// 模拟数据库查询
return customerRepository.findById(customerId)
.orElseThrow(() -> new CustomerNotFoundException(customerId));
}
@Tool("根据产品ID查询产品详情和库存")
public ProductInfo getProductInfo(@P("产品ID") String productId) {
return productService.getProductDetails(productId);
}
@Tool("计算两个地点之间的距离")
public DistanceInfo calculateDistance(@P("起点") String origin,
@P("终点") String destination) {
return distanceCalculator.calculate(origin, destination);
}
// 构建支持工具调用的AI服务
public void buildToolEnabledService() {
CustomerServiceAI service = AiServices.builder(CustomerServiceAI.class)
.chatLanguageModel(OpenAiChatModel.withApiKey(apiKey))
.tools(getCustomerInfo, getProductInfo, calculateDistance)
.build();
String response = service.answerCustomerQuestion(
"客户12345想了解产品P-1001的库存情况,并计算从北京到上海的配送时间");
System.out.println(response);
}
interface CustomerServiceAI {
String answerCustomerQuestion(String question);
}
}
记忆管理与会话状态
LangChain4J 提供了强大的记忆管理机制,支持长期和短期记忆:
public class MemoryManagementExample {
privatefinal ChatMemoryProvider memoryProvider;
privatefinal ChatLanguageModel chatModel;
public MemoryManagementExample() {
this.memoryProvider = memoryId -> MessageWindowChatMemory.withMaxMessages(10);
this.chatModel = OpenAiChatModel.withApiKey(apiKey);
}
public String continueConversation(String message, String conversationId) {
CustomerService service = AiServices.builder(CustomerService.class)
.chatLanguageModel(chatModel)
.chatMemoryProvider(memoryProvider)
.build();
return service.chat(message, conversationId);
}
// 使用 TokenWindow 控制记忆长度
public void setupTokenBasedMemory() {
ChatMemoryProvider tokenMemoryProvider = memoryId ->
TokenWindowChatMemory.builder()
.maxTokens(1000)
.build();
// 构建支持 token 限制的记忆系统
AiServiceWithMemory service = AiServices.builder(AiServiceWithMemory.class)
.chatLanguageModel(chatModel)
.chatMemoryProvider(tokenMemoryProvider)
.build();
}
interface CustomerService {
String chat(@UserMessage String message, @MemoryId String conversationId);
}
interface AiServiceWithMemory {
String process(@UserMessage String input, @MemoryId String sessionId);
}
}
高级检索增强生成(RAG)
LangChain4J 的 RAG 实现比 Spring AI 更加灵活和强大:
public class AdvancedRAGImplementation {
privatefinal EmbeddingModel embeddingModel;
privatefinal EmbeddingStore<TextSegment> embeddingStore;
privatefinal ChatLanguageModel chatModel;
public AdvancedRAGImplementation(EmbeddingModel embeddingModel,
EmbeddingStore<TextSegment> embeddingStore,
ChatLanguageModel chatModel) {
this.embeddingModel = embeddingModel;
this.embeddingStore = embeddingStore;
this.chatModel = chatModel;
}
// 文档处理流水线
public void processDocumentPipeline(Path documentPath) {
// 文档加载
Document document = DocumentLoader.load(documentPath);
// 文档分割
List<TextSegment> segments = DocumentSplitter.split(document, 500);
// 生成嵌入向量
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
// 存储到向量数据库
for (int i = 0; i < segments.size(); i++) {
embeddingStore.add(embeddings.get(i), segments.get(i));
}
}
// 高级检索策略
public String advancedRetrieval(String query) {
// 生成查询向量
Embedding queryEmbedding = embeddingModel.embed(query).content();
// 多策略检索
List<EmbeddingMatch<TextSegment>> relevantMatches = embeddingStore.findRelevant(
queryEmbedding,
5,
0.7
);
// 重排序
List<TextSegment> rerankedSegments = rerankSegments(query, relevantMatches);
// 构建上下文
String context = buildContext(rerankedSegments);
// 生成回答
return chatModel.generate(
"基于以下上下文回答问题:\n\n" + context + "\n\n问题:" + query
);
}
private List<TextSegment> rerankSegments(String query,
List<EmbeddingMatch<TextSegment>> matches) {
// 实现基于相关性的重排序逻辑
return matches.stream()
.sorted((a, b) -> Double.compare(b.score(), a.score()))
.map(EmbeddingMatch::embedded)
.collect(ToList.toList());
}
}
输出解析与结构化响应
LangChain4J 提供了强大的输出解析机制,确保模型返回结构化的数据:
public class OutputParsingExamples {
// 自定义输出解析器
publicstaticclass ProductRecommendationParser implements OutputParser<ProductRecommendation> {
@Override
public ProductRecommendation parse(String text) {
// 解析模型返回的文本为结构化对象
try {
ObjectMapper mapper = new ObjectMapper();
return mapper.readValue(text, ProductRecommendation.class);
} catch (Exception e) {
thrownew OutputParseException("Failed to parse product recommendation", e);
}
}
@Override
public String formatInstructions() {
return"请以 JSON 格式返回产品推荐,包含 productId、productName、reason 字段";
}
}
// 使用输出解析器的服务
public ProductRecommendation getStructuredRecommendation(String userPreference) {
StructuredChatService service = AiServices.builder(StructuredChatService.class)
.chatLanguageModel(chatModel)
.outputParser(new ProductRecommendationParser())
.build();
return service.recommendProducts(userPreference);
}
interface StructuredChatService {
@UserMessage("根据用户偏好推荐产品:{{it}}")
ProductRecommendation recommendProducts(@V("it") String userPreference);
}
// 支持多个输出解析器
public void multipleParsersExample() {
ComplexService service = AiServices.builder(ComplexService.class)
.chatLanguageModel(chatModel)
.outputParsers(
Map.of(
"json", new JsonOutputParser(),
"xml", new XmlOutputParser(),
"custom", new ProductRecommendationParser()
)
)
.build();
}
}
流式处理与实时响应
LangChain4J 支持复杂的流式处理场景:
public class StreamingImplementation {
privatefinal StreamingChatLanguageModel streamingModel;
public StreamingImplementation(StreamingChatLanguageModel streamingModel) {
this.streamingModel = streamingModel;
}
// 基础流式响应
public Flux<String> streamChatResponse(String message) {
return Flux.create(sink -> {
streamingModel.generate(message, new StreamingResponseHandler() {
@Override
public void onNext(String token) {
sink.next(token);
}
@Override
public void onComplete() {
sink.complete();
}
@Override
public void onError(Throwable error) {
sink.error(error);
}
});
});
}
// 带工具调用的流式处理
public Flux<StreamingResponse> streamWithTools(String query) {
StreamingAiService<StreamingService> service =
AiServices.create(StreamingService.class, streamingModel);
return service.streamingChat(query)
.map(response -> new StreamingResponse(response.content(), response.finishReason()));
}
interface StreamingService {
@UserMessage("{{it}}")
Flux<String> streamingChat(@V("it") String message);
}
}
LangChain4J 通过这些丰富的特性和细粒度的控制能力,为构建复杂的企业级 AI 应用提供了完整的解决方案。其模块化设计和强大的工具集成能力,使得开发者能够构建从简单对话到复杂多步工作流的各种 AI 应用场景。
第 3 部分:Dify:零代码可视化AI工作流编排
在前两部分中,我们深入探讨了 Spring AI 和 LangChain4J 这两种基于代码的 AI 应用开发框架。现在让我们转向一个完全不同的范式——Dify,一个面向非技术用户的零代码可视化 AI 工作流编排平台。Dify 的核心设计哲学是将复杂的 AI 应用开发过程抽象为可视化的拖拽操作,让产品经理、业务专家等非技术角色也能快速构建和部署 AI 应用。
可视化工作流引擎架构
Dify 的架构围绕可视化工作流引擎构建,将传统需要编码的 AI 处理流程转化为图形化节点:

工作流节点类型包括:
- 输入节点:定义数据入口和格式验证
- 处理节点:文本清洗、格式转换、数据增强
- AI 节点:模型调用、参数配置、提示词管理
- 逻辑节点:条件分支、循环控制、并行处理
- 工具节点:API 调用、数据库查询、文件操作
- 输出节点:结果格式化、响应模板
工作流设计模式
客户服务自动化工作流
通过 Dify 可视化界面构建的客户服务自动化流程:

关键配置参数:
- 意图识别准确率阈值:0.85
- RAG 检索 top_k:5
- 情感分析敏感度:中
- 满意度预测阈值:0.7
多模态内容生成流水线
Dify 支持复杂的多模态处理流程,如图文内容协同生成:
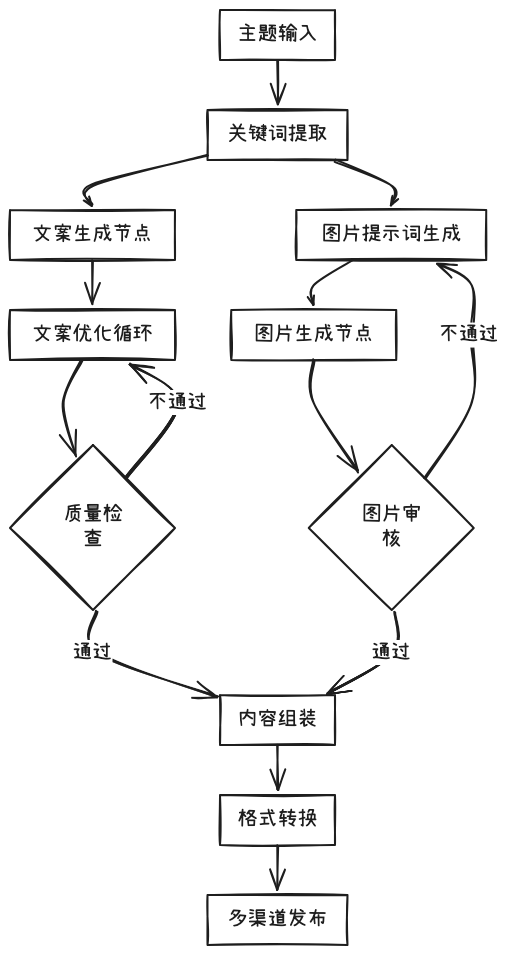
高级提示词工程与管理
动态提示词模板系统
Dify 提供了企业级的提示词管理系统,支持变量替换和条件逻辑:
name: "客户服务专业回复"
version:"1.2"
description:"针对不同客户类型和问题的动态提示词"
variables:
-name:"customer_type"
type:"enum"
values:["新客户","老客户","VIP客户"]
default:"新客户"
-name:"question_category"
type:"enum"
values:["产品咨询","技术支持","价格问题","投诉建议"]
required:true
-name:"customer_tone"
type:"string"
default:"友好专业"
template:|
你是一名{customer_type}服务专家。
{%ifcustomer_type=="VIP客户"%}
请提供优先服务和专属解决方案。
{%endif%}
用户的问题属于:{question_category}
{%ifquestion_category=="投诉建议"%}
请首先表达歉意,然后认真解决问题。
{%elsifquestion_category=="价格问题"%}
请详细解释价格构成和价值体现。
{%endif%}
使用{customer_tone}的语气回复,确保回复专业且易于理解。
上下文信息:{{context}}
用户问题:{{question}}
提示词版本控制与 A/B 测试
Dify 内置的提示词版本管理系统支持迭代优化和效果对比:
prompt_experiment:
name:"销售话术优化实验"
base_version:"v1.2"
variants:
-id:"variant_a"
version:"v1.3-aggressive"
changes:
-"增加紧迫感表达"
-"强化价值主张"
metrics:
-"转化率"
-"响应时间"
-id:"variant_b"
version:"v1.3-conservative"
changes:
-"增强信任建立"
-"减少促销语言"
metrics:
-"客户满意度"
-"长期留存率"
traffic_allocation:
variant_a:40%
variant_b:40%
base_version:20%
evaluation_period:"7d"
primary_metric:"转化率"
集成与扩展能力
API 网关与微服务集成
Dify 作为 AI 能力中台,提供统一的 API 网关:
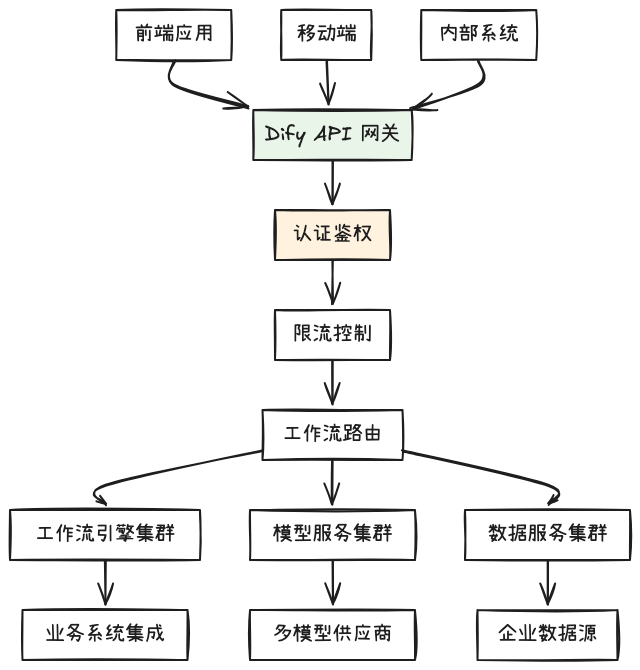
网关配置示例:
api_gateway:
rate_limiting:
default:"1000/小时"
premium:"10000/小时"
authentication:
methods:["API_KEY","JWT","OAUTH2"]
default_ttl:"24h"
endpoints:
-path:"/v1/chat/completions"
workflow:"customer_service_v2"
timeout:"30s"
-path:"/v1/images/generate"
workflow:"content_creation_v1"
timeout:"60s"
monitoring:
metrics:["latency","error_rate","throughput"]
alerts:
-condition:"error_rate > 5%"
action:"slack_alert"
自定义工具开发框架
对于需要特定业务逻辑的场景,Dify 支持自定义工具开发:
# 自定义客户数据查询工具
@tool
class CustomerDataTool:
name = "customer_data_lookup"
description = "根据客户ID查询客户基本信息和历史记录"
parameters:
customer_id:
type: "string"
required: true
description: "客户唯一标识符"
data_fields:
type: "array"
items: "string"
enum: ["basic_info", "order_history", "preferences"]
default: ["basic_info"]
def execute(self, customer_id, data_fields):
# 连接企业 CRM 系统
customer_data = crm_client.get_customer_data(
customer_id,
fields=data_fields
)
# 数据清洗和格式化
formatted_data = self.format_customer_data(customer_data)
return {
"success": True,
"data": formatted_data,
"source": "crm_system_v2"
}
def format_customer_data(self, raw_data):
# 实现特定的数据格式化逻辑
return {
"customer_id": raw_data["id"],
"name": f"{raw_data['first_name']} {raw_data['last_name']}",
"segment": raw_data.get("segment", "standard"),
"lifetime_value": raw_data.get("ltv", 0),
"last_interaction": raw_data.get("last_contact")
}
实际应用案例:电商智能客服系统
端到端工作流实现
一个完整的电商客服工作流在 Dify 中的配置:
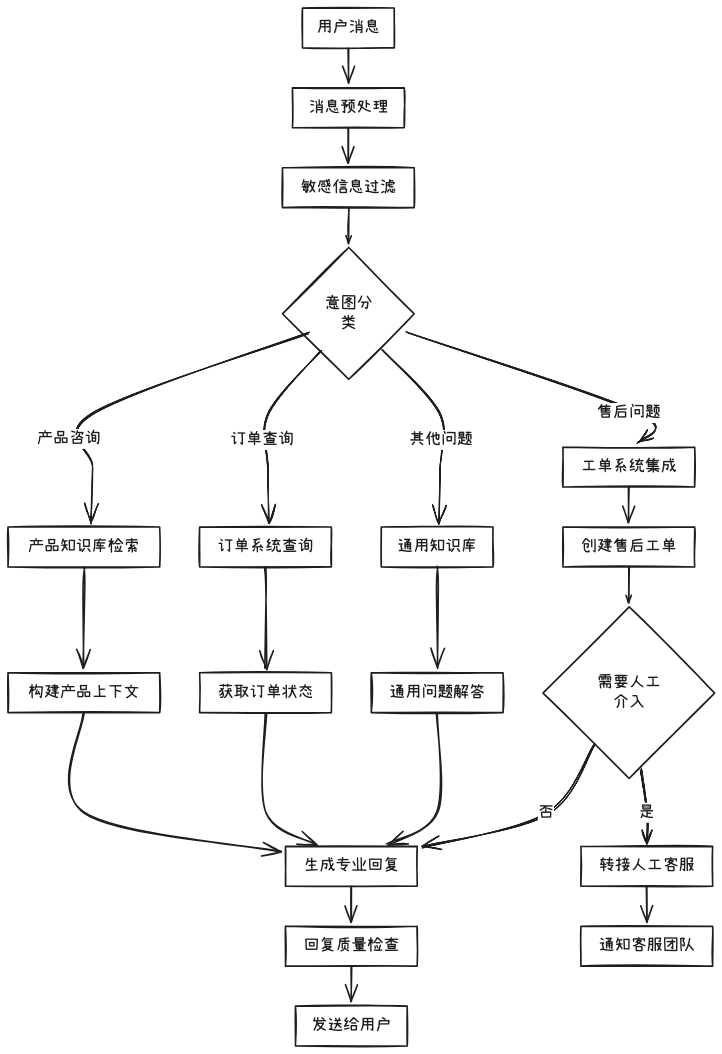
业务效果指标:
- 自动化处理率:85%
- 平均响应时间:2.3秒
- 客户满意度:4.6/5.0
- 人工客服负载减少:65%
Dify 通过这种可视化的方式,让企业能够快速构建、测试和部署复杂的 AI 应用,大幅降低了 AI 技术的使用门槛,同时保证了企业级应用所需的性能、安全和可维护性要求。
第 4 部分:百炼:私域大模型训练
在深入探讨了 Spring AI、LangChain4J 和 Dify 三大开发框架后,我们转向企业 AI 应用的另一个关键环节——私域大模型的训练与推理加速。百炼作为阿里云推出的一站式大模型平台,专门针对企业私有化部署和定制化训练场景进行了深度优化。其核心设计哲学是在保证模型效果的前提下,最大化训练和推理的性能效率,为企业提供成本可控、性能卓越的私有化 AI 解决方案。
百炼平台整体架构
百炼采用分层架构设计,每一层都针对性能进行了专门优化:
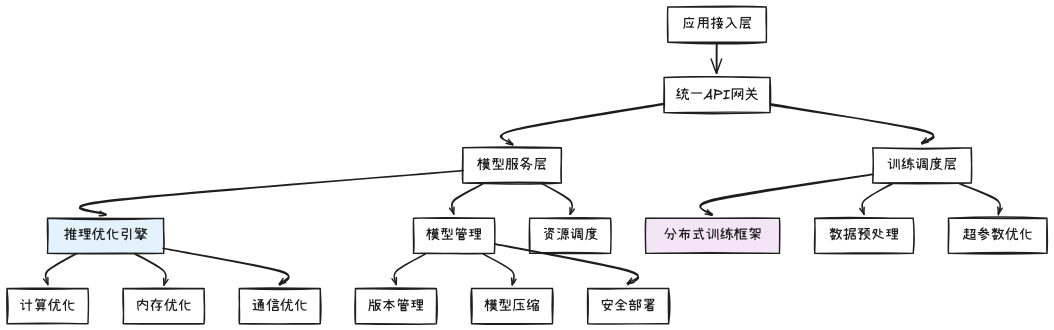
核心优化层包括:
- 推理优化引擎:集成多种推理加速技术
- 分布式训练框架:支持大规模并行训练
- 资源调度系统:动态分配计算资源
模型训练性能优化
分布式训练策略
百炼支持多种分布式训练模式,根据模型规模和硬件配置自动选择最优策略:
public class DistributedTrainingConfig {
// 数据并行配置
@Bean
public DataParallelConfig dataParallelConfig() {
return DataParallelConfig.builder()
.gradient_accumulation_steps(4)
.pipeline_parallel_size(1)
.tensor_parallel_size(2)
.data_parallel_size(4)
.build();
}
// 混合并行训练
@Bean
public HybridParallelTraining hybridParallelTraining() {
return HybridParallelTraining.builder()
.model_sharding_strategy("auto")
.optimizer_state_sharding(true)
.activation_checkpointing(true)
.zero_optimization(3) // ZeRO-3 优化
.build();
}
// 梯度累积配置
@Bean
public GradientAccumulationConfig gradientConfig() {
return GradientAccumulationConfig.builder()
.steps(8)
.sync_gradients(true)
.scale_loss(true)
.build();
}
}
训练数据流水线优化
高效的数据预处理和加载是训练性能的关键:
public class TrainingDataPipeline {
privatefinal DatasetProcessor datasetProcessor;
privatefinal FeatureEngineer featureEngineer;
public TrainingDataPipeline() {
this.datasetProcessor = new ParallelDatasetProcessor();
this.featureEngineer = new CachedFeatureEngineer();
}
// 并行数据预处理
public Dataset createOptimizedDataset(String dataPath, int batchSize) {
return Dataset.builder()
.dataPath(dataPath)
.batchSize(batchSize)
.prefetchBufferSize(1024) // 预取缓冲
.numParallelWorkers(8) // 并行工作线程
.shuffleBufferSize(10000) // 洗牌缓冲大小
.cacheInMemory(true) // 内存缓存
.build();
}
// 动态批处理优化
public DynamicBatchingConfig dynamicBatchingConfig() {
return DynamicBatchingConfig.builder()
.maxBatchSize(64)
.timeoutMs(100)
.paddingStrategy("longest")
.bucketBoundaries(List.of(32, 64, 128, 256))
.build();
}
// 数据增强流水线
public DataAugmentationPipeline augmentationPipeline() {
return DataAugmentationPipeline.builder()
.textAugmentations(List.of(
new SynonymReplacement(0.1),
new RandomInsertion(0.05),
new RandomSwap(0.05),
new BackTranslation("en", "zh")
))
.imageAugmentations(List.of(
new RandomRotation(5),
new ColorJitter(0.1, 0.1, 0.1, 0.1),
new RandomHorizontalFlip(0.5)
))
.parallelAugmentation(true)
.cacheAugmentedData(true)
.build();
}
}
推理性能优化
模型压缩与量化
百炼提供多种模型压缩技术,在保持精度的同时大幅提升推理速度:
public class ModelCompressionService {
// 动态量化配置
public DynamicQuantizationConfig dynamicQuantization() {
return DynamicQuantizationConfig.builder()
.quantization_bits(8)
.per_channel_quantization(true)
.symmetric_quantization(true)
.quantized_modules(List.of("Linear", "Conv2d"))
.excluded_modules(List.of("LayerNorm", "Embedding"))
.calibration_dataset("validation_set")
.calibration_samples(1000)
.build();
}
// 知识蒸馏配置
public KnowledgeDistillationConfig distillationConfig() {
return KnowledgeDistillationConfig.builder()
.teacher_model("qwen-72b")
.student_model("qwen-7b")
.temperature(4.0)
.alpha(0.7)
.distillation_loss("kl_divergence")
.attention_transfer(true)
.hidden_state_transfer(true)
.build();
}
// 模型剪枝策略
public ModelPruningConfig pruningConfig() {
return ModelPruningConfig.builder()
.pruning_method("magnitude")
.pruning_ratio(0.3)
.pruning_frequency(1000)
.global_pruning(true)
.structured_pruning(false)
.importance_criteria("l1_norm")
.build();
}
}
推理引擎优化
百炼集成多种推理引擎,根据硬件自动选择最优后端:
public class InferenceEngineOptimization {
// TensorRT 优化配置
public TensorRTConfig tensorRTConfig() {
return TensorRTConfig.builder()
.precision_mode("FP16")
.max_workspace_size(2L * 1024 * 1024 * 1024) // 2GB
.min_timing_iterations(10)
.avg_timing_iterations(100)
.optimization_level(3)
.calibration_cache("calibration.cache")
.build();
}
// ONNX Runtime 优化
public ONNXRuntimeConfig onnxRuntimeConfig() {
return ONNXRuntimeConfig.builder()
.execution_providers(List.of(
"CUDAExecutionProvider",
"CPUExecutionProvider"
))
.graph_optimization_level(99)
.enable_profiling(true)
.memory_pattern_optimization(true)
.enable_cpu_mem_arena(true)
.build();
}
// 自研推理引擎配置
public BailianInferenceConfig bailianConfig() {
return BailianInferenceConfig.builder()
.kernel_fusion(true)
.memory_optimization(true)
.operator_optimization(true)
.dynamic_batching(true)
.continuous_batching(true) // 连续批处理
.paged_attention(true) // 分页注意力
.build();
}
}
内存优化策略
显存管理优化
针对大模型显存占用的深度优化:
public class MemoryOptimization {
// 激活检查点配置
public ActivationCheckpointingConfig activationCheckpointing() {
return ActivationCheckpointingConfig.builder()
.checkpoint_every_n_layers(2)
.offload_activations(true)
.cpu_offload_buffer_size(4L * 1024 * 1024 * 1024) // 4GB
.partition_activations(true)
.contiguous_memory_optimization(true)
.build();
}
// 梯度检查点配置
public GradientCheckpointingConfig gradientCheckpointing() {
return GradientCheckpointingConfig.builder()
.checkpoint_ratio(0.5)
.offload_to_cpu(true)
.recompute_strategy("balanced")
.build();
}
// 显存碎片整理
public MemoryDefragmentationConfig defragmentationConfig() {
return MemoryDefragmentationConfig.builder()
.defragmentation_interval(1000)
.max_defragmentation_time_ms(500)
.defragmentation_threshold(0.1) // 10% 碎片率触发
.build();
}
}
动态显存分配
智能的显存分配策略,最大化利用可用资源:
public class DynamicMemoryAllocator {
privatefinal MemoryPool memoryPool;
privatefinal AllocationStrategy strategy;
public DynamicMemoryAllocator() {
this.memoryPool = new HierarchicalMemoryPool();
this.strategy = new BestFitAllocationStrategy();
}
// 分层内存池配置
public MemoryPoolConfig memoryPoolConfig() {
return MemoryPoolConfig.builder()
.max_gpu_memory(0.9) // 最大使用 90% 显存
.reserved_memory(512 * 1024 * 1024) // 保留 512MB
.allocation_strategy("best_fit")
.defragmentation_enabled(true)
.build();
}
// 张量重用时序优化
public TensorReuseOptimizer tensorReuseOptimizer() {
return TensorReuseOptimizer.builder()
.reuse_distance_threshold(100)
.lifetime_analysis(true)
.preallocation_strategy("statistical")
.build();
}
}
计算图优化
图编译与优化
百炼的计算图优化引擎在模型加载时进行深度优化:
public class ComputationalGraphOptimization {
// 图融合策略
public GraphFusionConfig graphFusionConfig() {
return GraphFusionConfig.builder()
.enable_vertical_fusion(true) // 垂直融合
.enable_horizontal_fusion(true) // 水平融合
.fusion_patterns(List.of(
"Conv-BatchNorm-ReLU",
"Linear-GELU",
"LayerNorm-Silu"
))
.max_fusion_group_size(10)
.build();
}
// 算子优化配置
public OperatorOptimizationConfig operatorOptimization() {
return OperatorOptimizationConfig.builder()
.kernel_auto_tuning(true)
.winograd_optimization(true)
.depthwise_separable_optimization(true)
.attention_optimization("flash_attention")
.build();
}
// 常量折叠与代数简化
public ConstantFoldingConfig constantFolding() {
return ConstantFoldingConfig.builder()
.fold_constants(true)
.algebraic_simplification(true)
.arithmetic_optimization(true)
.build();
}
}
通信优化
分布式训练通信优化
针对多机多卡训练的通信瓶颈优化:
public class CommunicationOptimization {
// 梯度通信优化
public GradientCommunicationConfig gradientCommunication() {
return GradientCommunicationConfig.builder()
.all_reduce_algorithm("nccl")
.gradient_compression("fp16")
.bucket_cap_mb(25) // 25MB 桶大小
.overlap_communication(true) // 通信计算重叠
.build();
}
// 模型并行通信优化
public ModelParallelConfig modelParallelConfig() {
return ModelParallelConfig.builder()
.pipeline_parallel_communication("1f1b")
.tensor_parallel_communication("all_reduce")
.sequence_parallel_enabled(true)
.build();
}
// 混合精度通信
public MixedPrecisionCommunication mixedPrecisionComm() {
return MixedPrecisionCommunication.builder()
.master_weights_fp32(true)
.loss_scaling(true)
.gradient_scaling_algorithm("dynamic")
.communication_dtype("fp16")
.build();
}
}
百炼平台通过这些深度优化技术,为企业提供了从模型训练到推理部署的全链路性能优化解决方案,使得在有限的计算资源下也能高效运行大规模 AI 模型,真正实现了"小资源办大事"的目标。
第 5 部分:微调:Java场景化模型调优
在前四部分中,我们系统性地掌握了 Java AI 开发的四大核心框架——Spring AI 的基础设施集成、LangChain4J 的复杂应用构建、Dify 的可视化编排以及百炼的私有化训练推理。现在,我们进入 AI 应用落地的最终环节:场景化模型微调与上线闭环。微调的核心价值在于将通用大模型转化为贴合具体业务场景的专属智能体,在保持基础能力的同时显著提升特定任务的准确性和可靠性。
微调与提示词工程的对比优势
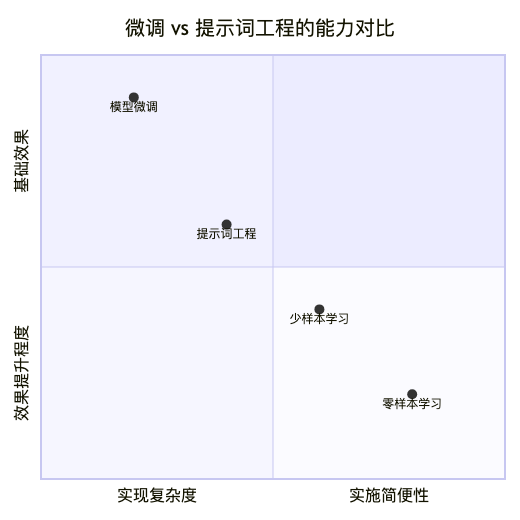
从技术实现维度分析,微调相比提示词工程具有显著优势:
提示词工程的局限性:
- 上下文长度受限,无法注入大量领域知识
- 每次推理都需要重复传递领域上下文,成本高昂
- 对复杂逻辑和专业知识理解深度有限
- 存在"遗忘"现象,难以保持长期一致性
微调的核心优势:
- 将领域知识内化到模型参数中,实现永久记忆
- 显著降低推理阶段的 token 消耗和成本
- 能够学习复杂的领域特定模式和逻辑
- 支持风格迁移和术语统一
微调数据工程最佳实践
高质量训练数据构建
数据质量是微调成功的关键,需要系统化的数据工程流程:
public class FineTuningDataEngineering {
privatefinal DataValidator dataValidator;
privatefinal DataAugmentor dataAugmentor;
privatefinal QualityScorer qualityScorer;
public FineTuningDataEngineering() {
this.dataValidator = new MultiStageDataValidator();
this.dataAugmentor = new SmartDataAugmentor();
this.qualityScorer = new LLMBasedScorer();
}
// 数据收集与清洗流水线
public Dataset buildHighQualityDataset(DataSources sources) {
return DataPipeline.builder()
.sources(sources)
.addStage(new DataCollectionStage()
.fromDatabase("business_db")
.fromLogs("user_interactions")
.fromDocuments("knowledge_base")
)
.addStage(new DataCleaningStage()
.removeDuplicates(true)
.fixEncodingIssues(true)
.normalizeText(true)
.filterByLength(10, 2000)
)
.addStage(new DataValidationStage()
.validator(new FormatValidator())
.validator(new ContentValidator())
.validator(new SafetyValidator())
)
.addStage(new DataAugmentationStage()
.paraphraseAugmentation(0.3) // 30% 数据 paraphrasing
.backTranslationAugmentation(0.2) // 20% 回译增强
.entityReplacementAugmentation(0.1) // 10% 实体替换
)
.addStage(new QualityScoringStage()
.scorer(qualityScorer)
.minQualityScore(0.8) // 最低质量分数
.autoRejectLowQuality(true)
)
.build()
.execute();
}
// 对话数据格式标准化
public List<Conversation> formatConversationData(List<RawDialog> rawDialogs) {
return rawDialogs.stream()
.map(this::convertToStandardFormat)
.filter(conv -> validateConversationStructure(conv))
.map(conv -> enrichWithMetadata(conv))
.collect(Collectors.toList());
}
private Conversation convertToStandardFormat(RawDialog rawDialog) {
return Conversation.builder()
.messages(rawDialog.getTurns().stream()
.map(turn -> Message.builder()
.role(turn.getSpeakerType())
.content(turn.getText())
.timestamp(turn.getTimestamp())
.build())
.collect(Collectors.toList()))
.metadata(Map.of(
"domain", extractDomain(rawDialog),
"complexity", assessComplexity(rawDialog),
"success", evaluateSuccess(rawDialog)
))
.build();
}
}
数据质量评估体系
建立多维度的数据质量评估标准:
public class DataQualityAssessment {
// 多维度质量指标
public QualityReport assessDatasetQuality(Dataset dataset) {
return QualityReport.builder()
.linguisticQuality(assessLinguisticQuality(dataset))
.domainRelevance(assessDomainRelevance(dataset))
.diversityMetrics(calculateDiversity(dataset))
.difficultyDistribution(analyzeDifficulty(dataset))
.biasDetection(detectBiases(dataset))
.build();
}
private LinguisticQuality assessLinguisticQuality(Dataset dataset) {
return LinguisticQuality.builder()
.grammarScore(calculateGrammarScore(dataset))
.fluencyScore(calculateFluencyScore(dataset))
.coherenceScore(calculateCoherenceScore(dataset))
.styleConsistency(assessStyleConsistency(dataset))
.build();
}
private DiversityMetrics calculateDiversity(Dataset dataset) {
return DiversityMetrics.builder()
.vocabularyRichness(calculateVocabRichness(dataset))
.syntacticDiversity(calculateSyntacticDiversity(dataset))
.semanticDiversity(calculateSemanticDiversity(dataset))
.topicCoverage(analyzeTopicCoverage(dataset))
.build();
}
// 基于 LLM 的自动质量评分
public double llmBasedQualityScore(String text, String context) {
String prompt = """
请从以下维度评估文本质量,给出0-1的分数:
文本:{text}
领域上下文:{context}
评估标准:
1. 语言流畅性(0.25分)
2. 内容准确性(0.25分)
3. 领域相关性(0.25分)
4. 信息完整性(0.25分)
请直接返回分数,不要解释。
""";
String scoreStr = llmClient.call(prompt
.replace("{text}", text)
.replace("{context}", context));
return Double.parseDouble(scoreStr.trim());
}
}
微调策略与技术选型
参数高效微调(PEFT)技术
针对不同资源约束选择合适的微调方法:
public class PEFTStrategySelector {
// LoRA 配置 - 适合大多数场景
public LoRAConfig loraConfigForDomainAdaptation() {
return LoRAConfig.builder()
.lora_rank(16)
.lora_alpha(32)
.target_modules(List.of(
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
))
.lora_dropout(0.1)
.bias("none")
.build();
}
// QLoRA 配置 - 资源受限环境
public QLoRAConfig qloraConfigForLowResource() {
return QLoRAConfig.builder()
.lora_rank(64)
.lora_alpha(16)
.quantization_config(NF4Config.builder()
.double_quant(true)
.quant_type("nf4")
.build())
.target_modules(List.of("all-linear"))
.build();
}
// Adapter-based 方法 - 多任务学习
public AdapterConfig adapterConfigForMultiTask() {
return AdapterConfig.builder()
.adapter_dim(512)
.adapter_activation("gelu")
.adapter_dropout(0.1)
.add_layer_norm(true)
.build();
}
// 根据场景选择最优策略
public PEFTConfig selectOptimalStrategy(FinetuningScenario scenario) {
switch (scenario.getType()) {
case DOMAIN_ADAPTATION:
return loraConfigForDomainAdaptation();
case STYLE_TRANSFER:
return StyleTransferConfig.builder()
.lora_rank(8)
.target_modules(List.of("attn", "mlp"))
.build();
case MULTI_TASK:
return adapterConfigForMultiTask();
case LOW_RESOURCE:
return qloraConfigForLowResource();
default:
return loraConfigForDomainAdaptation();
}
}
}
多阶段渐进式微调
采用渐进式策略避免灾难性遗忘:
public class ProgressiveFineTuning {
privatefinal ModelLoader modelLoader;
privatefinal TrainingScheduler scheduler;
public ProgressiveFineTuning() {
this.modelLoader = new CheckpointManager();
this.scheduler = new AdaptiveScheduler();
}
// 三阶段渐进微调流程
public TrainingPlan createProgressivePlan(TrainingData data) {
return TrainingPlan.builder()
.stage1(createWarmupStage(data.getGeneralData()))
.stage2(createDomainAdaptationStage(data.getDomainData()))
.stage3(createSpecializationStage(data.getTaskData()))
.validationStrategy(new IncrementalValidation())
.build();
}
private TrainingStage createWarmupStage(Dataset generalData) {
return TrainingStage.builder()
.name("通用能力保持")
.dataset(generalData)
.learningRate(1e-5)
.epochs(1)
.batchSize(32)
.peftConfig(loraConfigForDomainAdaptation())
.objective("保持基础语言理解能力")
.earlyStopping(patience=3)
.build();
}
private TrainingStage createDomainAdaptationStage(Dataset domainData) {
return TrainingStage.builder()
.name("领域知识注入")
.dataset(domainData)
.learningRate(5e-5)
.epochs(3)
.batchSize(16)
.peftConfig(loraConfigForDomainAdaptation())
.objective("学习领域术语和知识")
.metrics(List.of("domain_accuracy", "terminology_usage"))
.build();
}
private TrainingStage createSpecializationStage(Dataset taskData) {
return TrainingStage.builder()
.name("任务专项优化")
.dataset(taskData)
.learningRate(2e-5)
.epochs(5)
.batchSize(8)
.peftConfig(qloraConfigForLowResource())
.objective("优化特定任务表现")
.metrics(List.of("task_accuracy", "response_quality"))
.build();
}
}
评估体系与迭代优化
多维度评估框架
建立全面的模型评估体系:
public class ComprehensiveEvaluation {
privatefinal List<Evaluator> evaluators;
privatefinal BenchmarkSuite benchmarkSuite;
public ComprehensiveEvaluation() {
this.evaluators = Arrays.asList(
new AccuracyEvaluator(),
new FluencyEvaluator(),
new SafetyEvaluator(),
new BiasDetector(),
new EfficiencyEvaluator()
);
this.benchmarkSuite = new DomainBenchmarkSuite();
}
// 自动化评估流水线
public EvaluationReport evaluateModel(FineTunedModel model, TestData testData) {
EvaluationReport.Builder reportBuilder = EvaluationReport.builder();
// 基础能力评估
reportBuilder.baseCapabilities(evaluateBaseCapabilities(model));
// 领域专项评估
reportBuilder.domainPerformance(evaluateDomainPerformance(model, testData));
// 安全性评估
reportBuilder.safetyMetrics(evaluateSafety(model));
// 效率评估
reportBuilder.efficiencyMetrics(evaluateEfficiency(model));
return reportBuilder.build();
}
private BaseCapabilities evaluateBaseCapabilities(FineTunedModel model) {
return BaseCapabilities.builder()
.languageUnderstanding(testMMLU(model))
.reasoningAbility(testReasoning(model))
.knowledgeRetention(testKnowledge(model))
.build();
}
private DomainPerformance evaluateDomainPerformance(FineTunedModel model, TestData testData) {
return DomainPerformance.builder()
.accuracy(calculateAccuracy(model, testData))
.precision(calculatePrecision(model, testData))
.recall(calculateRecall(model, testData))
.f1Score(calculateF1(model, testData))
.domainSpecificMetrics(calculateDomainMetrics(model, testData))
.build();
}
// A/B 测试框架
public ABTestResult runABTest(FineTunedModel modelA, FineTunedModel modelB,
UserTraffic traffic) {
return ABTestFramework.builder()
.models(Map.of("A", modelA, "B", modelB))
.trafficAllocation(Map.of("A", 0.5, "B", 0.5))
.metrics(List.of(
"conversion_rate",
"user_satisfaction",
"task_success_rate",
"response_quality"
))
.duration(Duration.ofDays(7))
.minSampleSize(1000)
.build()
.run();
}
}
持续学习与模型迭代
建立模型持续改进机制:
public class ContinuousLearningPipeline {
privatefinal FeedbackCollector feedbackCollector;
privatefinal DataCurator dataCurator;
privatefinal RetrainingScheduler retrainingScheduler;
public ContinuousLearningPipeline() {
this.feedbackCollector = new RealTimeFeedbackCollector();
this.dataCurator = new SmartDataCurator();
this.retrainingScheduler = new AdaptiveRetrainingScheduler();
}
// 持续学习闭环
public void setupContinuousLearning(FineTunedModel model) {
ContinuousLearningConfig config = ContinuousLearningConfig.builder()
.feedbackCollection(feedbackCollector)
.dataCuration(dataCurator)
.retrainingTrigger(new PerformanceDropTrigger(0.05)) // 性能下降5%触发
.retrainingStrategy(new IncrementalRetraining())
.versionManagement(new SemanticVersioning())
.rollbackStrategy(new AutomaticRollback())
.build();
ContinuousLearningEngine engine = new ContinuousLearningEngine(config);
engine.start(model);
}
// 基于用户反馈的数据收集
public Dataset collectFeedbackData() {
return feedbackCollector.collectRecentFeedback(Duration.ofDays(30))
.stream()
.filter(feedback -> feedback.getQualityScore() < 0.7) // 收集低质量反馈
.map(this::convertToTrainingExample)
.collect(Collectors.toCollection(Dataset::new));
}
// 智能数据筛选策略
public Dataset curateTrainingData(Dataset rawData) {
return dataCurator.curate(rawData,
CuratorStrategy.builder()
.diversitySampling(true)
.difficultyBalancing(true)
.qualityFiltering(true)
.outlierDetection(true)
.build());
}
}
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号