Dolphinscheduler海豚调度器实现离线任务提交安装实录
原创
Dolphinscheduler海豚调度器实现离线任务提交安装实录
原创
大王叫我来巡山、
发布于 2025-11-17 10:57:45
发布于 2025-11-17 10:57:45
简介: 学习一个东西,个人认为最好的方式是:官网+源码+实践。
安装步骤
1、前置要求
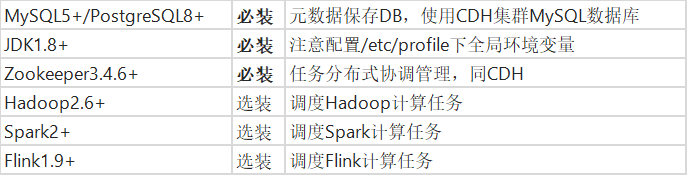
添加描述
2、软件包下载安装
注意:需要在集群中所有节点传输安装包并解压,完成集群分布式协调管理。
- 解压
tar -zxvf apache-dolphinscheduler-incubating-1.3.4-dolphinscheduler-bin.tar.gz -C /opt/dolphinscheduler;复制
- 改名
mv apache-dolphinscheduler-incubating-1.3.4-dolphinscheduler-bin dolphinscheduler-bin复制
3、创建部署用户并确保hosts映射完备,以及其他配置
# 创建用户需使用root登录,设置部署用户名
useradd dolphinscheduler;
# 设置用户密码
echo "dolphinscheduler123" | passwd --stdin dolphinscheduler
# 配置sudo免密
echo 'dolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' >> /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
# 安装sshpass,需先安装epel
yum install -y epel-release
yum repolist
# 安装完成epel之后,就可以按照sshpass了
yum install -y sshpass
# 修改目录权限
dolphinscheduler-bin复制
4、数据库DB初始化
注意:因为使用的是CDH集群MySQL保存元数据,所以需要提供mysql-connector-java驱动包到dolphinscheduler的lib目录下:
mv mysql-connector-java-5.1.39.jar /opt/dolphinscheduler/dolphinscheduler-bin/lib复制
然后需要对数据库用户进行添加和权限修改:
# 添加dolphinscheduler用户
create user 'dolphinscheduler'@'%' identified by '123456';
# 创建dolphinscheduler数据库
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
# 为dolphinescheduler赋予全IP权限
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%' IDENTIFIED BY '123456';
# 刷新权限
flush privileges;
最后要对dolphinscheduler导入基础数据,首先需要对conf/datasource.properties文件进行以下内容的修改:
# postgresql
#spring.datasource.driver-class-name=com.mysql.jdbc.Driver
#spring.datasource.url=jdbc:mysql://10.0.2.138:3306/dolphinscheduler?characterEncoding=UTF-8&allowMultiQueries=true
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://10.0.2.138:3306/dolphinscheduler?characterEncoding=UTF-8&allowMultiQueries=true
spring.datasource.username=dolphinscheduler
spring.datasource.password=123456复制
修改并保存后退出,然后执行script目录下的数据导入脚本:
sh script/create-dolphinscheduler.sh复制
至此,完成基础安装和数据导入。
5、修改运行参数
1】选装技术组件
当选装了技术组件如Hadoop、Spark、Flink、Hive等的时候,此时需要对conf/env/dolphinschedule_env.sh进行配置:
export HADOOP_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop
export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/etc/hadoop
#export SPARK_HOME1=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark1
#export SPARK_HOME2=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark2
export SPARK_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark
#export PYTHON_HOME=/
export JAVA_HOME=/usr/java/jdk1.8.0_181
export HIVE_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive
export FLINK_HOME=/opt/cloudera/parcels/FLINK-1.12.4-BIN-SCALA_2.11/lib/flink
#export DATAX_HOME=/opt/soft/datax/bin/datax.py
#export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH:$FLINK_HOME/bin:$DATAX_HOME:$PATH
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin::$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH:$FLINK_HOME/bin::$PATH复制
另外,安装了Hadoop和Hive,还需要将
HADOOPHOME/etc/hadoop下的core−site.xml和hdfs−site.xml,
HIVE_HOME/conf/hive-site.xml移动到目录/opt/dolphinscheduler下的新建conf目录中:
cp /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/etc/hadoop/core-site.xml conf/
cp /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/etc/hadoop/hdfs-site.xml conf/
cp /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/conf/hive-site.xml conf复制
2】一键部署文件的修改
在conf/config/install_config.conf中有很多参数需要进行修改:
# NOTICE : If the following config has special characters in the variable `.*[]^${}\+?|()@#&`, Please escape, for example, `[` escape to `\[`
# postgresql or mysql
dbtype="mysql"
# db config
# db address and port
dbhost="10.0.2.138:3306"
# db username
username="dolphinscheduler"
# database name
dbname="dolphinscheduler"
# db passwprd
# NOTICE: if there are special characters, please use the \ to escape, for example, `[` escape to `\[`
password="123456"
# zk cluster
zkQuorum="data-dev01:2181,data-dev02:2181,data-dev02:2181"
# Note: the target installation path for dolphinscheduler, please not config as the same as the current path (pwd)
installPath="/opt/dolphinscheduler"
# deployment user
# Note: the deployment user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled, the root directory needs to be created by itself
deployUser="dolphinscheduler"
# alert config
# mail server host
mailServerHost="smtp.163.com"
# mail server port
# note: Different protocols and encryption methods correspond to different ports, when SSL/TLS is enabled, make sure the port is correct.
mailServerPort="25"
# sender
mailSender="bigdata_hjt@163.com"
# user
mailUser="bigdata_hjt@163.com"
# sender password
# note: The mail.passwd is email service authorization code, not the email login password.
mailPassword="bigdata2021"
# TLS mail protocol support
starttlsEnable="true"
# SSL mail protocol support
# only one of TLS and SSL can be in the true state.
sslEnable="false"
#note: sslTrust is the same as mailServerHost
sslTrust="smtp.163.com"
# resource storage type:HDFS,S3,NONE
resourceStorageType="HDFS"
# if resourceStorageType is HDFS,defaultFS write namenode address,HA you need to put core-site.xml and hdfs-site.xml in the conf directory.
# if S3,write S3 address,HA,for example :s3a://dolphinscheduler,
# Note,s3 be sure to create the root directory /dolphinscheduler
defaultFS="hdfs://nameservice1" # 注意,因为这里配置了HDFS的HA
# if resourcemanager HA enable, please type the HA ips ; if resourcemanager is single, make this value empty
yarnHaIps=""
# if resourcemanager HA enable or not use resourcemanager, please skip this value setting; If resourcemanager is single, you only need to replace yarnIp1 to actual resourcemanager hostname.
singleYarnIp="data-dev01"
# resource store on HDFS/S3 path, resource file will store to this hadoop hdfs path, self configuration, please make sure the directory exists on hdfs and have read write permissions。/dolphinscheduler is recommended
resourceUploadPath="/opt/dolphinscheduler"
# who have permissions to create directory under HDFS/S3 root path
# Note: if kerberos is enabled, please config hdfsRootUser=
hdfsRootUser="root"
# kerberos config
# whether kerberos starts, if kerberos starts, following four items need to config, otherwise please ignore
kerberosStartUp="false"
# kdc krb5 config file path
krb5ConfPath="$installPath/conf/krb5.conf"
# keytab username
keytabUserName="hdfs-mycluster@ESZ.COM"
# username keytab path
keytabPath="$installPath/conf/hdfs.headless.keytab"
# api server port
apiServerPort="12345" # 登录WebUI的初始密码
# install hosts
# Note: install the scheduled hostname list. If it is pseudo-distributed, just write a pseudo-distributed hostname
ips="10.0.2.138,10.0.2.139,10.0.2.140"
# ssh port, default 22
# Note: if ssh port is not default, modify here
sshPort="22"
# run master machine
# Note: list of hosts hostname for deploying master
masters="data-dev01"
# run worker machine
# note: need to write the worker group name of each worker, the default value is "default"
workers="data-dev01:default,data-dev02:default,data-dev03:default"
# run alert machine
# note: list of machine hostnames for deploying alert server
alertServer="data-dev03"
# run api machine
# note: list of machine hostnames for deploying api server
apiServers="data-dev01"复制
6、初始化
完成了上述步骤之后,确认完毕就可以进行dolphinscheduler的初始化。
sh install.sh复制
之后在主节点和从节点进行jps查看java进程可以看到新增的进程服务:
(主)

添加描述
(从)

添加描述
通过运维增加ds的映射路径:
staging-ds.***.com复制
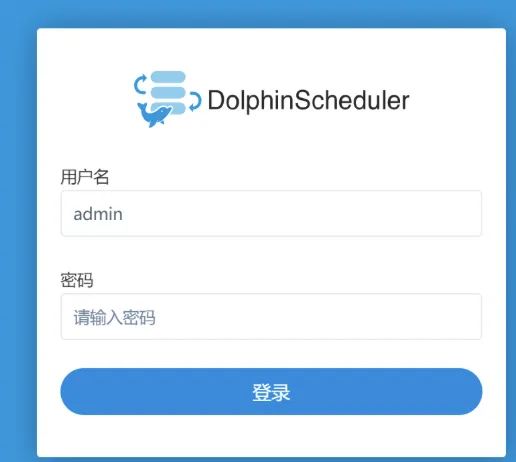
添加描述
通过admin账户和初始密码,可以进入到以下Web UI管理界面:

添加描述
7、各目录和文件用途解释

添加描述
bin:包含各种集群脚本目录
conf:配置目录
dolphinscheduler-bin:原始安装和配置目录
gc.log:记录垃圾回收日志
install.sh:初始化脚本
lib:相关jar包目录
logs:日志文件目录
pid:启动进程pid目录
script:包含各种使用脚本目录
sql:sql配置和任务记录相关目录
ui:WebUI相关目录复制
8、服务启停
服务的启停,都可以在./bin目录下找到对应脚本:
# 一键停止集群所有服务
sh ./bin/stop-all.sh
# 一键开启集群所有服务
sh ./bin/start-all.sh
# 启停Master
sh ./bin/dolphinscheduler-daemon.sh start master-server
sh ./bin/dolphinscheduler-daemon.sh stop master-server
# 启停Worker
sh ./bin/dolphinscheduler-daemon.sh start worker-server
sh ./bin/dolphinscheduler-daemon.sh stop worker-server
# 启停Api
sh ./bin/dolphinscheduler-daemon.sh start api-server
sh ./bin/dolphinscheduler-daemon.sh stop api-server
# 启停Logger
sh ./bin/dolphinscheduler-daemon.sh start logger-server
sh ./bin/dolphinscheduler-daemon.sh stop logger-server
# 启停Alert
sh ./bin/dolphinscheduler-daemon.sh start alert-server
sh ./bin/dolphinscheduler-daemon.sh stop alert-server复制
9、遇到的问题和解决
1】导入基础数据失败,并报错【bin/java: No such file or directory】
解决:检查JAVA_HOME在全局环境变量下的配置正确性。
2】直接用admin在资源中心创建文件夹会提示创建资源错误NullPointerException,报空指针

添加描述
解决:默认的admin租户为空首先应该创建一个租户 把admin的租户改为刚才创建的,再次创建文件夹。

添加描述
#10、关于dolphinscheduler的思考
查看start-all.sh脚本可以看到,内部其实包含了很多的ssh命令,从而实现跨越节点的服务启动,所以再一次证明上面的免密ssh的必要性。
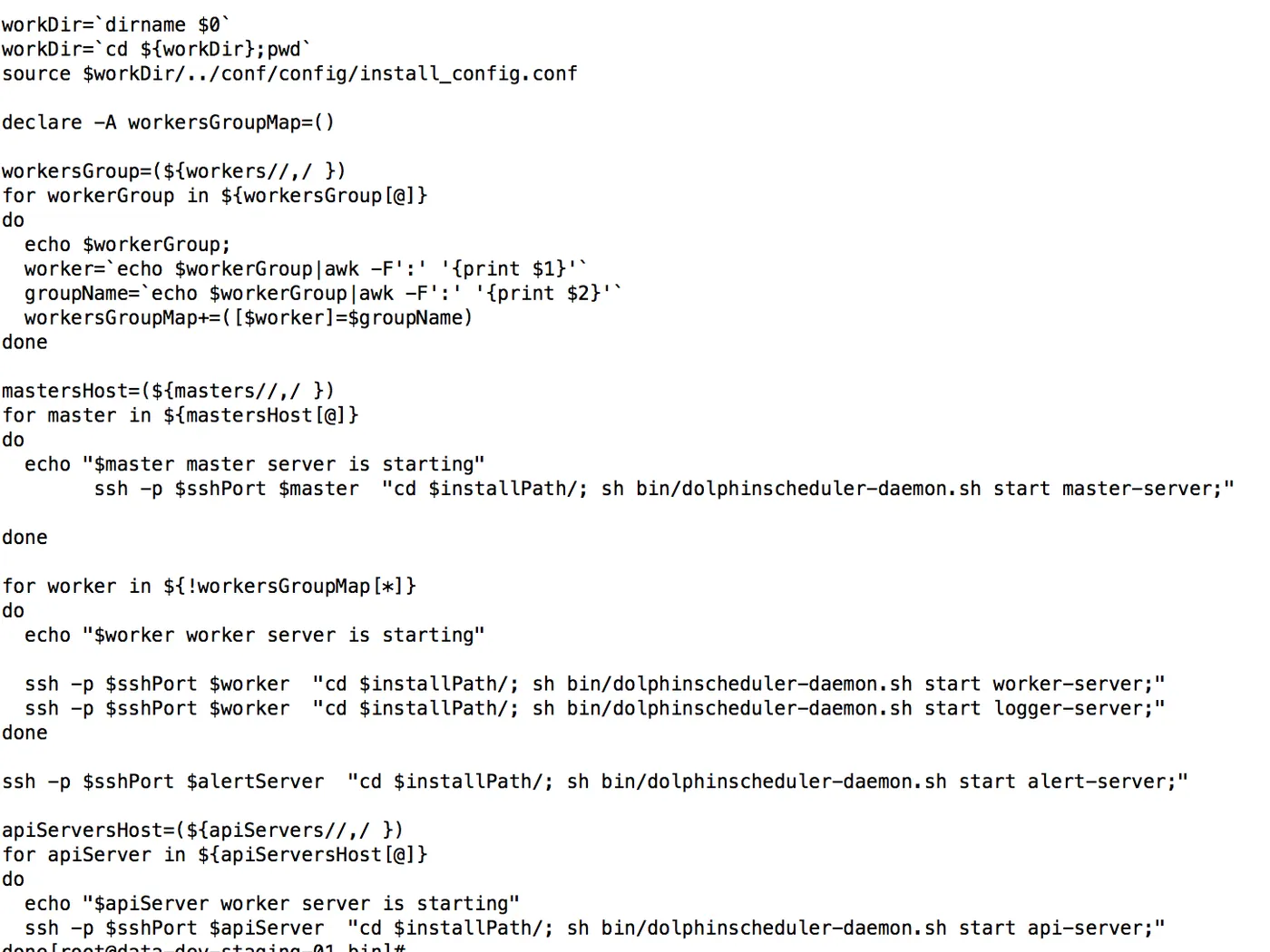
添加描述
另外,切换视角到dolphinscheduler-daemon.sh脚本,它里面有这样一段关于JVM配置相关的内容:
export DOLPHINSCHEDULER_OPTS="-server -Xms$HEAP_INITIAL_SIZE -Xmx$HEAP_MAX_SIZE -Xmn$HEAP_NEW_GENERATION__SIZE -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+PrintGCDetails -Xloggc:gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dump.hprof"复制
设置的MaxMetaspaceSize=128m,这里在后续的元数据增加场景可以增大,-XX:+UseConcMarkSweepGC使用的CMS垃圾回收器,其实可以修改为G1垃圾回收器,但是它里面增加一些关于CMS的配置,修改为G1对应的配置即可。
另外-XX+UseCMSInitiatingOccupancyOnly标志来命令JVM不基于运行时收集的数据来启动CMS垃圾收集周期,和CMSInitiatingOccupancyFraction=70,说明在对CMS GC频率上,是做了一定优化的。这个参数的意思是:设定CMS在对内存占用率达到70%的时候开始GC(因为CMS会有浮动垃圾,所以一般都较早启动GC)。
关于这一点,确实能发现对比Oozie的优化做的还是不错的,因为一般来说,JVM自己就能做非常好的垃圾回收策略,在apache基金会下面的孵化项目中,dolphinscheduler敢于这样做出设置,都是在application产生的对象的生命周期有深刻的认知之后才会使用这个标志。并且因为涉及到Haoop、Spark、Hive等多个组件,能兼容管理,确实也说明了这个组件的可取之处的。
以上,为海豚调度器本次的安装实录,如有疑问,欢迎评论区留言!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号