【C/C++】初识C++(一):C++历史的简单回顾+命名空间、流插入、命名空间的指定访问、展开问题等概念整理

【C/C++】初识C++(一):C++历史的简单回顾+命名空间、流插入、命名空间的指定访问、展开问题等概念整理

艾莉丝努力练剑
发布于 2025-11-13 10:19:15
发布于 2025-11-13 10:19:15
🔥个人主页:艾莉丝努力练剑 ❄专栏传送门:《C语言》、《数据结构与算法》、C语言刷题12天IO强训、LeetCode代码强化刷题、C/C++干货分享&学习过程记录 🍉学习方向:C/C++方向 ⭐️人生格言:为天地立心,为生民立命,为往圣继绝学,为万世开太平
前言:本专栏记录了博主C++从初阶到高阶完整的学习历程,会发布一些博主学习的感悟、碰到的问题、重要的知识点,和大家一起探索C++这门程序语言的奥秘。本文即本专栏的第一篇文章,这个专栏将记录博主C++语法、高阶数据结构、STL的学习过程,正所谓“万丈高楼平地起”,我们话不多说,正式进入C++阶段的学习。
C++的一些参考文档
我们的老朋友:cplusplus——C++
我们之前介绍C语言的时候曾经挂过这个链接:C Library
虽然是我们的老熟人了,但是我们还是要注意一下:这个CPlusPlus不是C++官方文档,而且标准也只更新到C++11,但是以头文件形式呈现,排版看起来很舒服,内容也更加好懂。
官方文档(同步更新):cppreference
这个其实博主之前也挂过链接,是C++官方的文档。
之前其实是有中文版的,但是很不幸的是,中文版在暑假之前就挂了,现在只有英文版了,大家不用担心,对英语其实要求没那么高,再说,我们程序员看英文文档也是家常便饭了,大家也要习惯,毕竟这么多东西是人家老外搞出来的,如果是我们先搞出来的,不就是中文版了嘛。计算机软硬件这些技术都起源于人家欧美,前沿一点的我们在用的一些东西,可能也有我们的一些拓展,比方说你在公司用一个东西,可能国内的资料不是那么多,只有英文的资料,那没招啊,我们只能硬着头皮看。这些英文的文档、资料,大家慢慢习惯就好了。主要它对于英文的要求也没那么高,咱们都是学过十几年英语的人啦,无非就是单词认识的多少、对一些东西的认识,实在不行咱们装个软件也可以查一下嘛。翻译软件博主建议还是少用,用是可以用的,主要问题是我们有很多名词、术语的翻译它翻译软件翻译的味儿就不对,我们尽可能还是去了解第一手的资料。比如,我们复制一下,看看在CSDN里面有没有介绍这块内容的博客,办法有很多。
这个也截个图给大家看看:
大家也能感受到,这个文档的排版确实是不如前者,但是这个的优点就是“全”“官方同步更新”,不仅信息很全,而且更新到了最新的C++标准,就是内容不如cplusplus好懂。
两个文档各有千秋,各有各的优点,我们就结合起来使用。
C++学习难度的知名梗图:“21天自学C++”
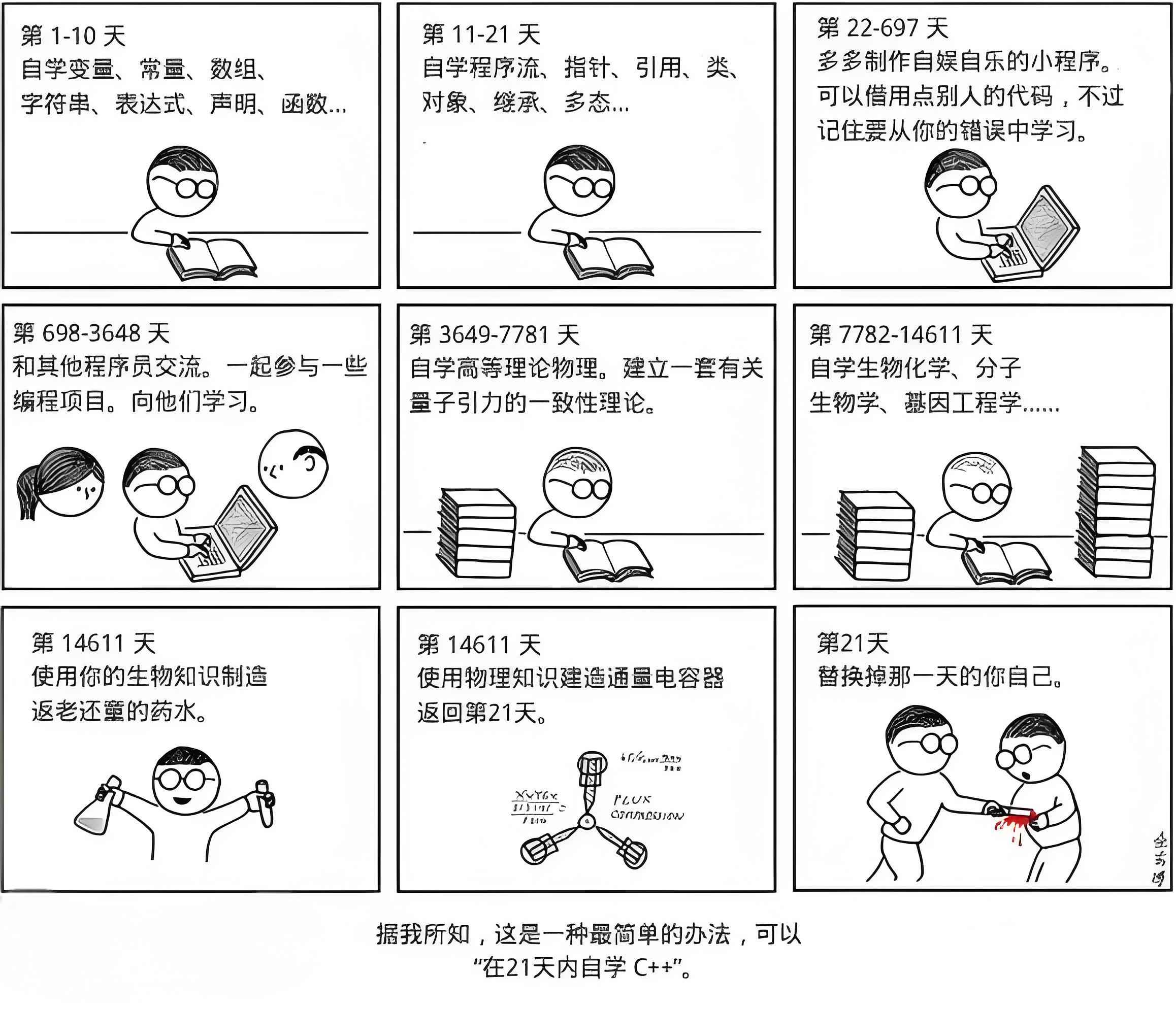
一、C++历史回顾(了解即可)
下面这位看起来十分散漫的大佬就是大名鼎鼎的“C++之父”Bjarne博士:

是不是长得就很程序员,往那儿一坐跟个BOSS似的。。。哈哈哈,开个玩笑。
起源与早期发展(1979-1983) C++的起源可以追溯到1979年,当时Bjarne Stroustrup(本贾尼·斯特劳斯特卢普,因为是音译名,可能会有所差异)在贝尔实验室从事计算机科学和软件工程的研究工作。面对项目中复杂的软件开 发任务,特别是模拟和操作系统的开发工作,他感受到了现有语言(如C语言,C语言就是贝尔实验室搞出来的)在表达能力、可维护性和可扩展性方面的不足。 1983年,Bjarne Stroustrup在C语言的基础上添加了面向对象编程的特性,设计出了C++语言的雏形, 此时的C++已经有了类、封装、继承等核心概念,为后来的面向对象编程奠定了基础。这一年该语言被正式命名为C++。 初期特性: 支持封装、运算符重载、函数默认参数等基础功能,为后续发展奠定框架。 标准化阶段(1989-1998) 在随后的几年中,C++在学术界和工业界的应用逐渐增多。一些大学和研究所开始将C++作为教学和研究的首选语言,而一些公司也开始在产品开发中尝试使用C++。这一时期,C++的标准库和模板等特性也得到了进一步的完善和发展。 C++的标准化工作于1989年开始,并成立了一个ANSI和ISO(International Standards Organization)国际标准化组织的联合标准化委员会。1994年标准化委员会提出了第一个标准化草案。在该草案中,委员会在保持斯特劳斯特卢普最初定义的所有特征的同时,还增加了部分新特征。 在完成C++标准化的第一个草案后不久,STL(Standard Template Library)是惠普实验室开发的一系列软件的统称。它是由Alexander Stepanov、Meng Lee和David R Musser在惠普实验室工作时所开发出来的。在通过了标准化第一个草案之后,联合标准化委员会投票并通过了将STL包含到C++标准中的提议。STL对C++的扩展超出C++的最初定义范围。虽然在标准中增加STL是个很重要的决定,但也因此延缓了C++标准化的进程。 1997年11月14日,联合标准化委员会通过了该标准的最终草案。1998年,C++的ANSI/IS0标准被投入使用。 1998年发布C++98标准,纳入模板、命名空间、异常处理等关键特性。 技术突破: 标准模板库(STL)的加入彻底改变了泛型编程范式。 现代化演进(2011-2026) C++11(2011): 引入智能指针、lambda表达式、多线程库等现代化特性,被称为"新纪元"。 C++20(2020): 新增协程、概念约束、模块化编程等革命性功能。 C++23(2023): 优化标准库使用体验,C++26(规划中)拟加入反射和异步执行框架。
下面几张图就是C++的几个版本啦,就像有些友友可能玩过二游,有3.0版本、几点几版本,一样的道理。中间其实C++的委员会还有一个从“五年计划” 到“三年计划”这样的有趣的小插曲,大家感兴趣可以去了解了解。
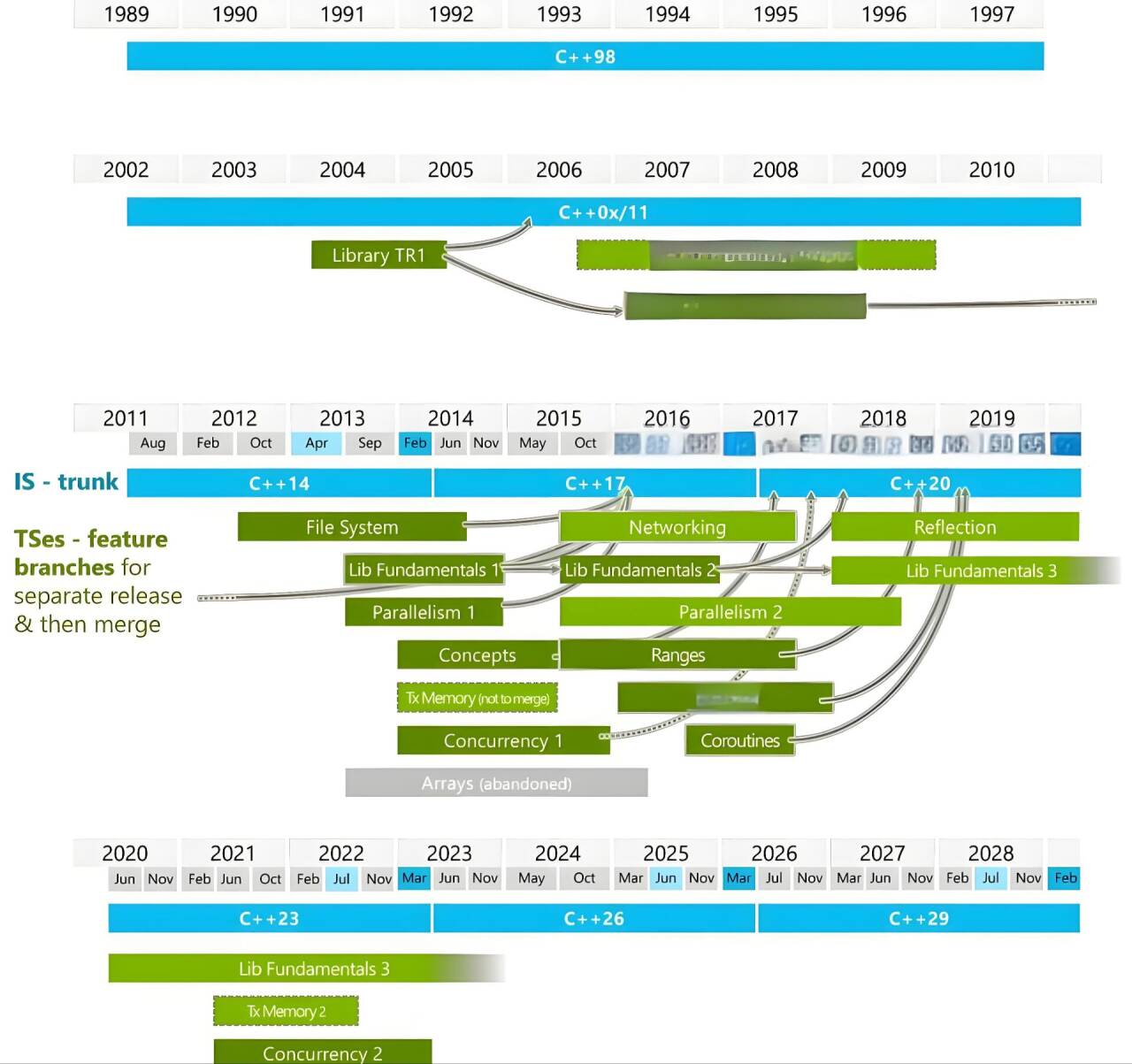
如下图就是C++发展历程,包含了各个版本主要的特性:
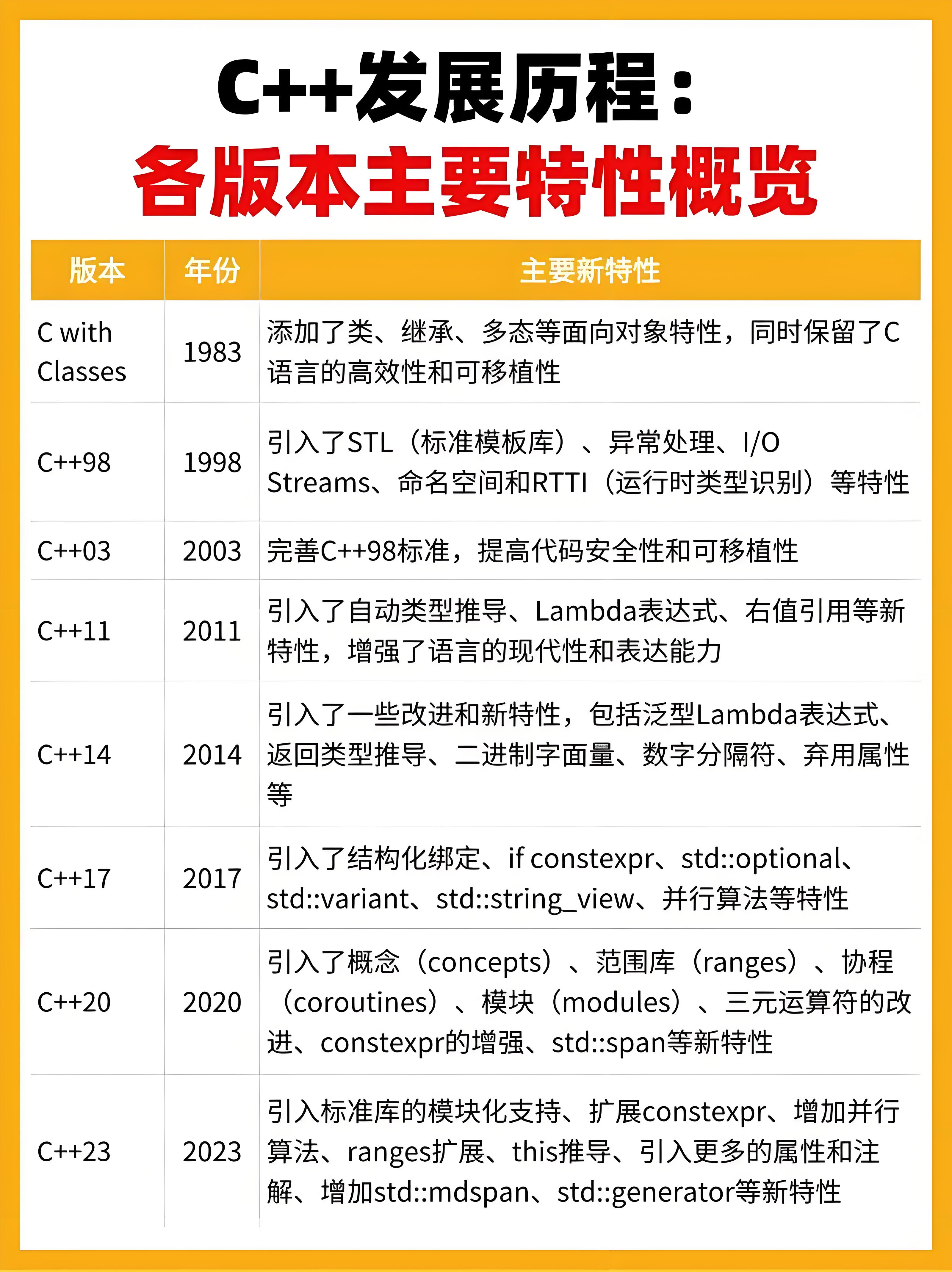
我们学的时候C++98、C+11这两个就够用了:
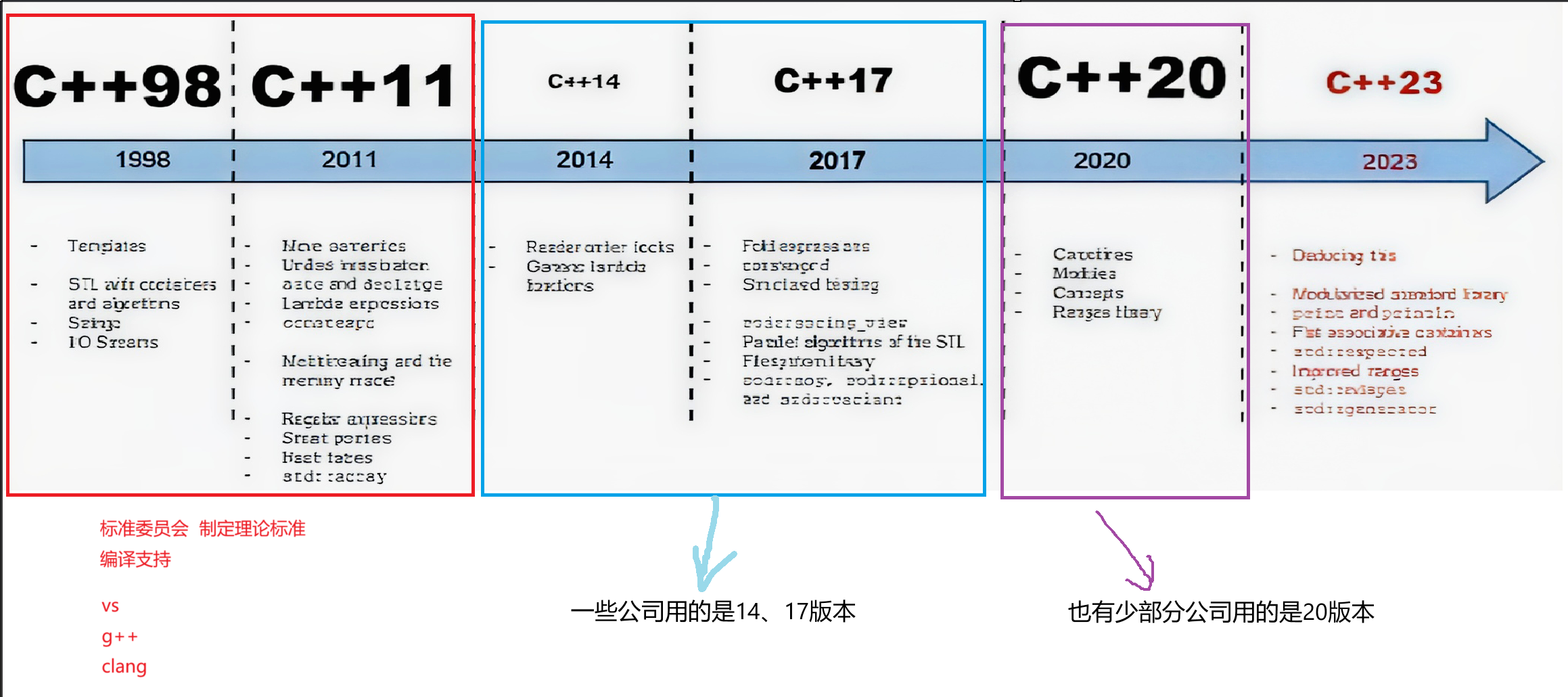
C++23和C++26,23是虽然有编译器支持也都支持的不太好,26则是还没有发布。
二、C++的认识
(一)C++的生态
1、C++23的小趣闻
有一件C++23的趣事:
C++一直以来被诟病的一个地方就是一直没出网络库(networking),networking之前是在委员会的C++23的计划中的,现在C++23虽然早就已经发布了,但是依然没有networking,由此引发了IT领域一众吃瓜群众的吃瓜和吐槽,非常有趣。看看大家的群情激奋:

这个是关于C++23的网络库的一些投票:C++23网络库投票

翻译的网页内容并不准确,大家看看就行:
大家也可以去看看知乎上这位大佬的文章:C++23的目标
2、和Java相比,C++的生态
在IT领域,大家经常会听到生态这个词,生态到底是啥意思?

Java的生态很好,这个生态说的就是它的框架、库搞得好,更新快。因为Java是公司搞出来的,盈利性的,而C++是个人搞的,C++的委员会纯纯为爱发电,比较偏公益性,没有啥利益。
C++没有网络库这一点一直都是被诟病的点(口罩也是一大原因)。
(二)C++的重要性以及在工作领域的应用
1、C++的重要性
大致成这个趋势:
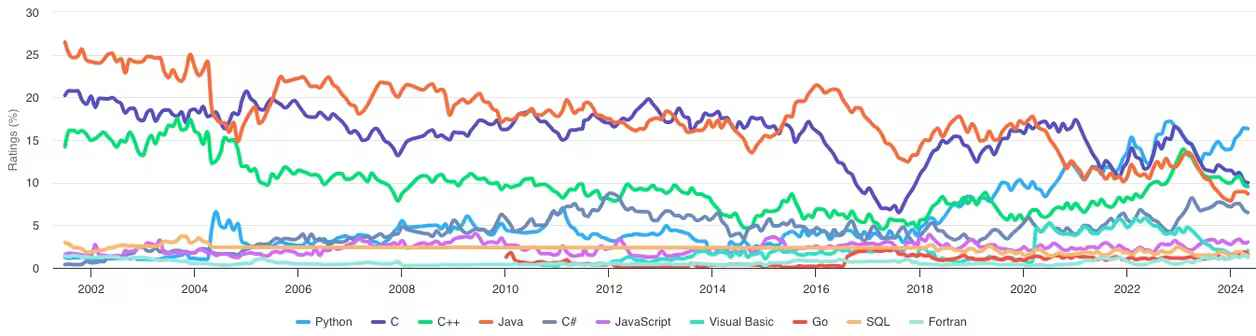
观察TIOBE发布的编程语言排行榜这两年的变动,其实C++的变化不大。
这是去年6月TIOBE发布的编程语言排行榜:
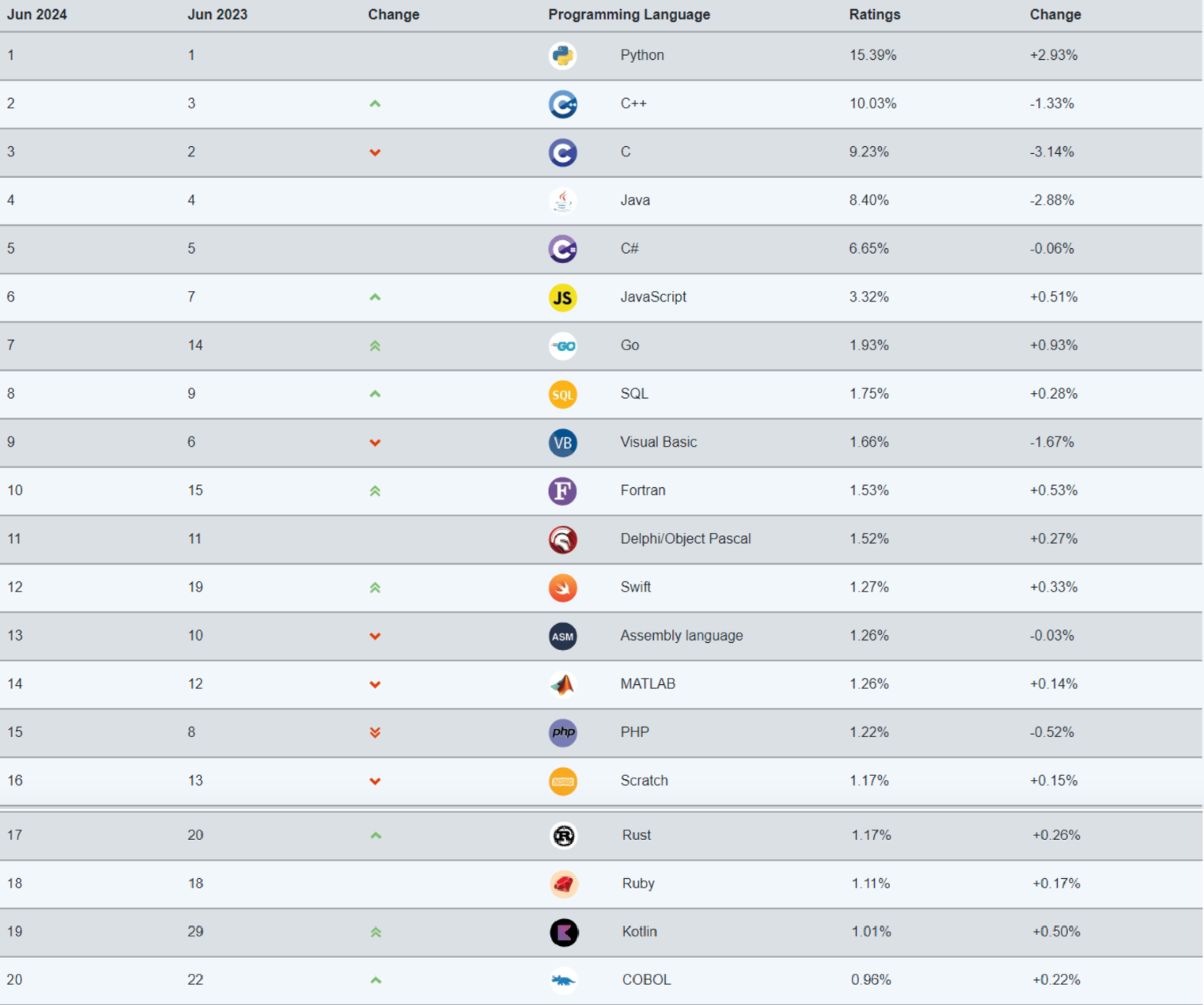
这是今年6月TIOBE发布的编程语言排行榜:
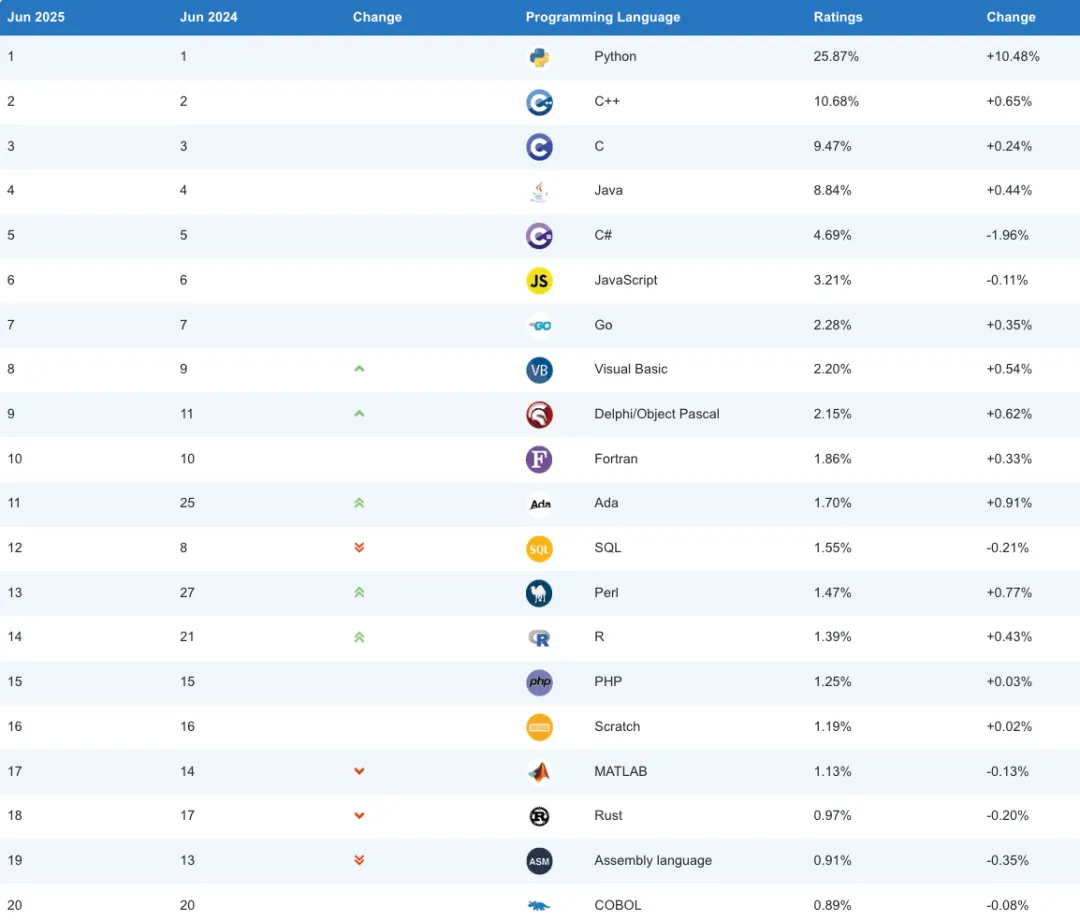
C++虽然变化不大,但随着AI的爆火,Python在一年内涨幅就超过了10%,因为AI的上层很多都是用Python写的,简直可以说是暴发户了。 Python是门解释性的语言,它没有编译的过程,只能在运行时报错,所以很慢。C++是指令性的,因而胜在性能。
2、在工作领域的应用
虽说如此,C++作为一辆1979年诞生、1998年标准化的老牌性能跑车,连以前曾经如日中天的PHP(一种用于Web开发的服务器端脚本语言)语言都衰落了,C++这辆老牌跑车竟然还能“老当益壮”,甚至历久弥新,由此可见C++的重要性。
C++的应用领域服务器端、游戏(引擎)、机器学习引擎、音视频处理、嵌入式软件、电信设备、金融应用、基础库、操作系统、编译器、基础架构、基础工具、硬件交互等很多方面都有。比如下面这些:


后端开发就是用C++、Java。
前端通常指的是用户直接交互的部分,包括网页、移动应用或桌面应用的用户界面,前端是网络申请数据,所以网一断,就全都丸辣,后端也称服务端,也就是服务器,或者说后台,是负责处理数据存储、业务逻辑和与前端交互的部分,而且后端是在后台工作的,控制着前端的内容,主要负责程序设计架构思想,管理数据库等。
后端性能要求会比前端高。
像客户端,分PC端、APP,APP又分安卓(Android)和苹果的IOS端,安卓是用Java写的。其中,PC端(PC即Personal Computer)的开发用到了C++的QT框架。
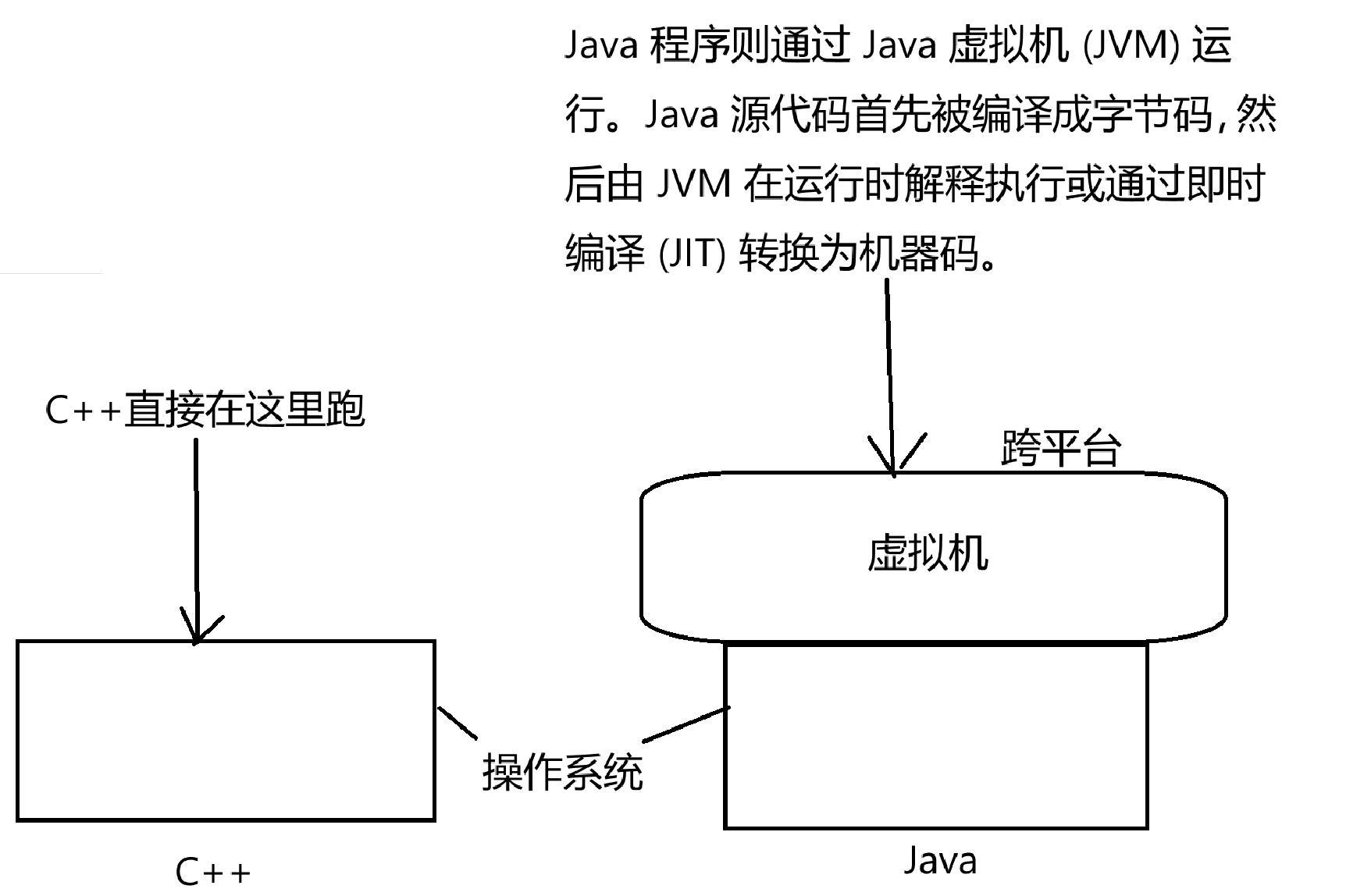
C++的特点就是一个字:快(比Java快)。
因为C++是直接编译指令,而Java做不到:
三、C++入门基础
(一)写第一个程序
C++我们还是用VS来编译,VS是按后缀识别文件的,我们创建文件时只需要从原来的.c变回默认的.cpp就可以了,可能需要适应一段时间。 现在C++还是在VS这样的IDE(集成开发环境)的界面,等到我们学到Linux(指令去编译)的时候就是在一个终端,或者说控制台——一个黑框框——里面去书写指令了——
我们在初学C语言的时候写过这个代码:
//C版本的hello world一样可以跑
#include<stdio.h>
int main()
{
printf("%s", "hello world!");
return 0;
}这个在C++依然是可以跑的,因为Bjarne博士是在C语言的基础上搞出来的,只是对一些小语法修修改改,祖宗之法还是不变的,一些变了的,博主会单独说明。
注意:C++兼容C语言绝大多数的语法,所以C语言实现的hello world依旧可以运行,C++中需要把定义文件代码后缀改为.cpp,vs编译器看到是.cpp就会调用C++编译器编译,linux下要用g++编译,不再是gcc。
C++有一套自己的输入输出,严格来讲C++版本的"hello world"应该是这样写的:
//C++第一个程序
#include<iostream>
using namespace std;
int main()
{
cout << "hello world" << endl;
return 0;
}这个<iostream>就是Input Output Stream的简称,即“输入输出流”,我们在C语言部分介绍过:
【掌握文件操作】(上):二进制文件和文本文件、文件的打开和关闭、文件的顺序读写
这里的几个新面孔像“<<” “cout”“endl”我们一会儿也会和其它新面孔一块儿介绍。
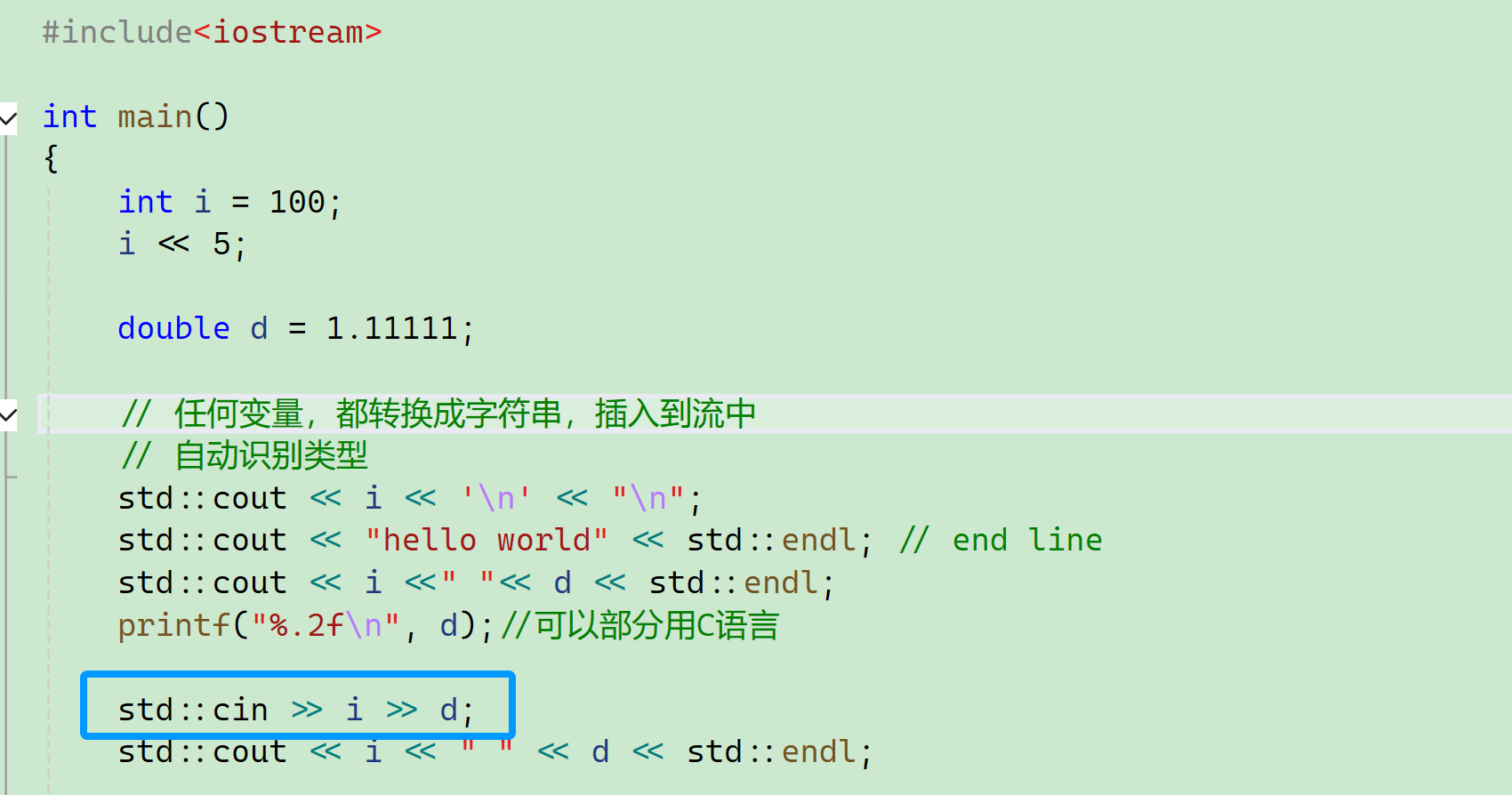
<<:在C语言里面它还作为位运算符,“流向”,在 C++ 的标准输入输出库中,<<被重载为输出操作符,用于将数据发送到输出流,就比如在std::cout << "Hello World";中,<<将字符串"Hello World"输出到控制台。这种用法是 C++ I/O 流的核心特性之一,允许将多种数据类型(如整数、浮点数、字符串等)以统一的方式输出到流中; cout:cin、cout分别是istream、cstream的变量; endl:即end line,前面要std::,std::endl,换行。
(二)命名空间
1、命名冲突
我们写这样一段代码:
#include<stdio.h>
#include<stdlib.h>
int rand = 10;
int main()
{
printf("%d\n", rand);
return 0;
}这个其实红色波浪线跳出的提示放在这里是不严谨的:
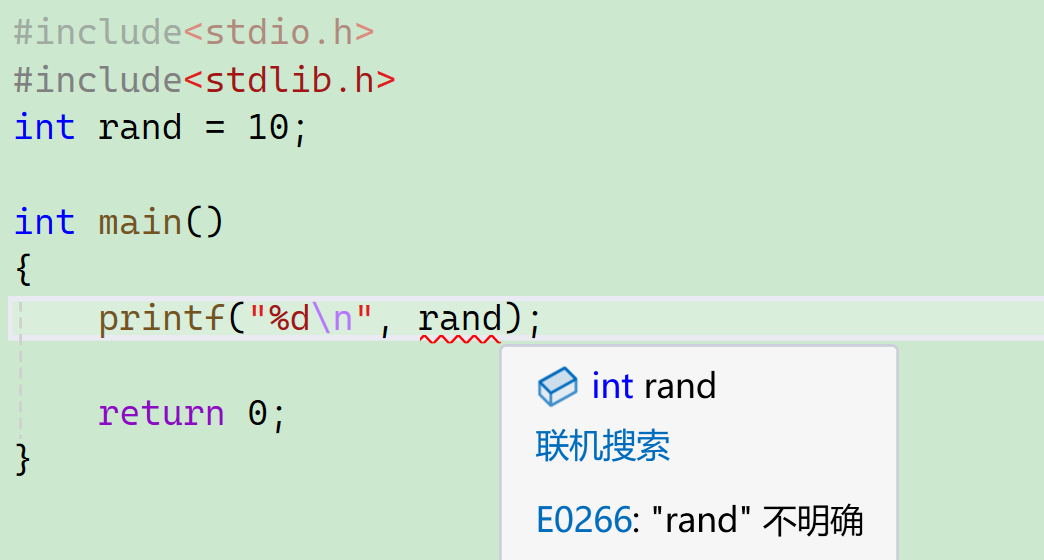
因为这里是博主没有把前面代码的头文件注释掉,但和博主想表达的意思殊途同归了: 没错,这里的rand不明确。
现在我把前面的头文件都注释掉:
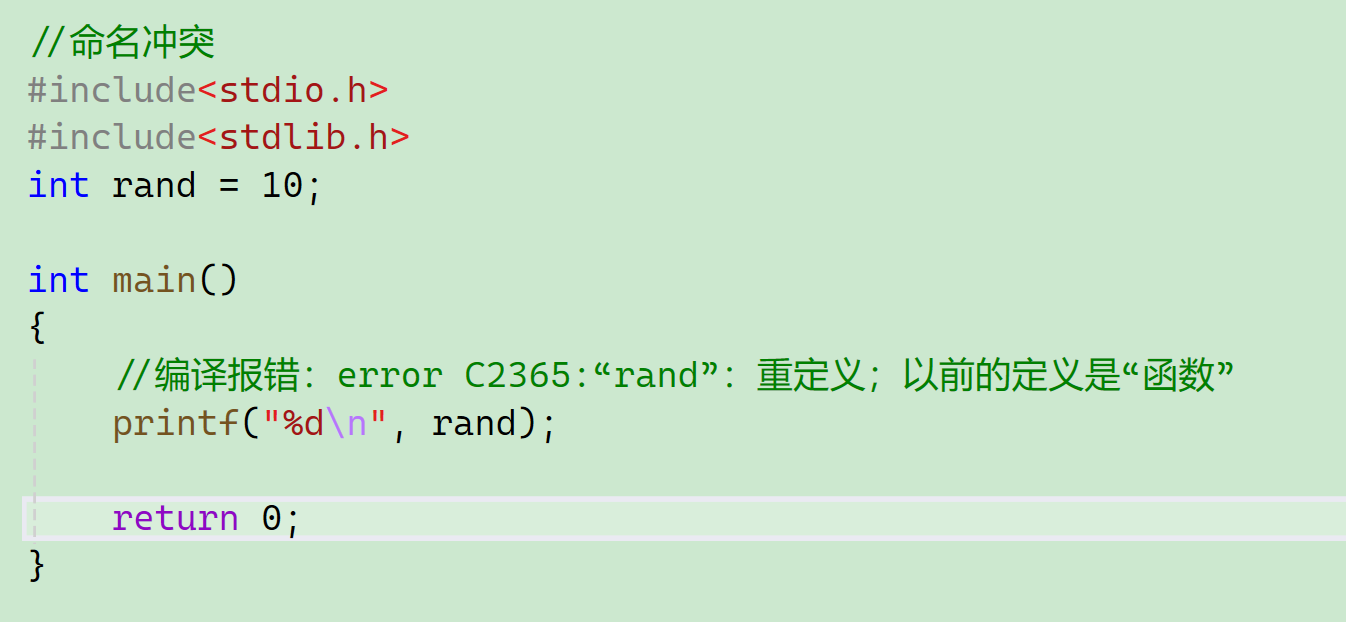
如果运行,会报这样一个错误:

我们在C++文档检索<stdlib.h>可以看到这样一条:
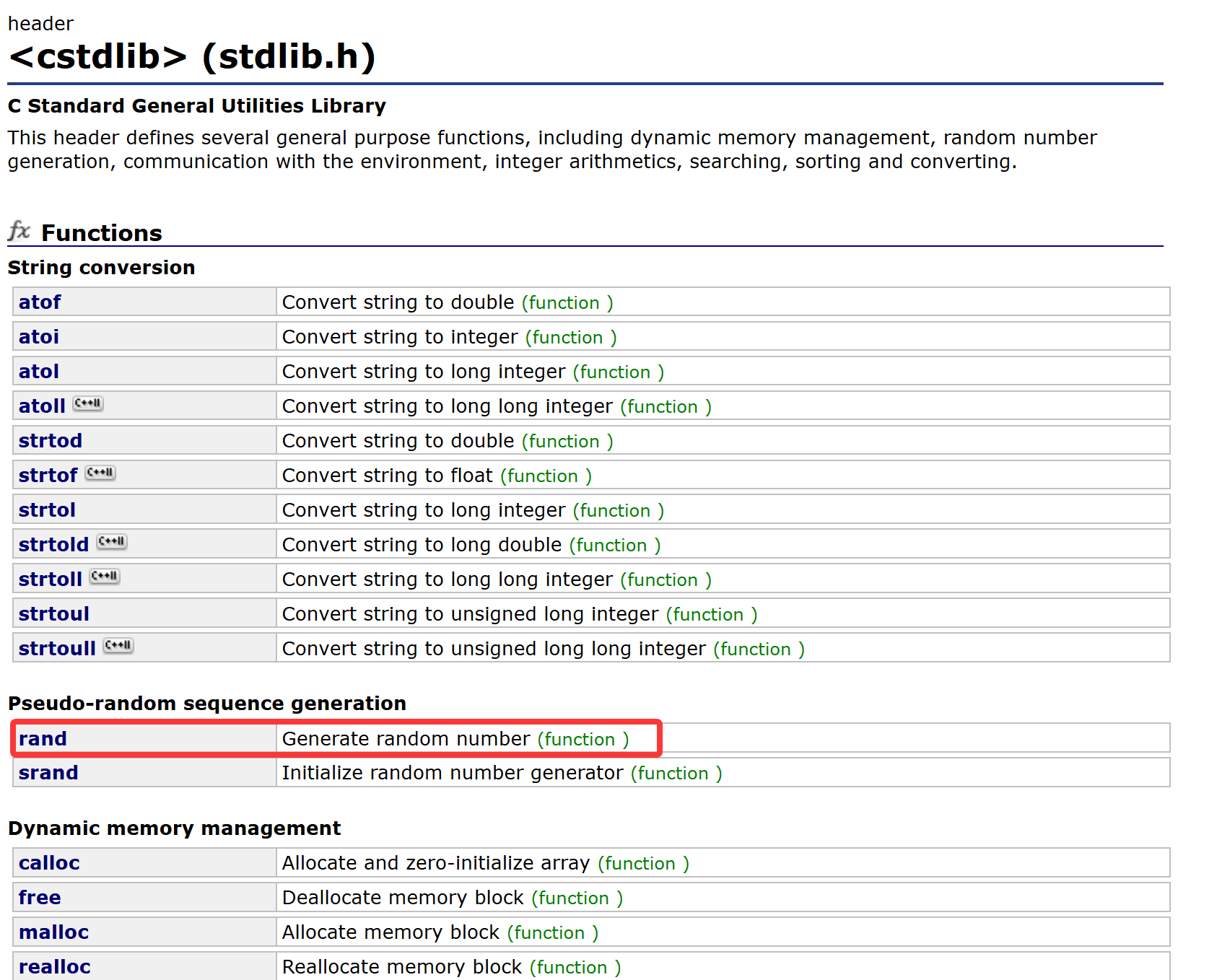
这就是命名冲突了,编译器不知道你指的是哪个rand,<stdlib.h>里面也有一个rand。

我们把#include<stdlib.h>注释掉,代码就顺利运行了:


这个命名冲突的问题怎么解决呢?Bjarne博士发明了命名空间(namespace)。

这也是C++中我们遇到的第一个关键字。
像上面这样的命名冲突是普遍存在的问题,C++引入namespace就是为了更好的解决这样的问题。
2、namespace

比如说我们写这样一个命名空间的代码:
#include<stdio.h>
#include<stdlib.h>
namespace ATM
{
//命名空间里面可以定义变量/函数/类型
int rand = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}
int a = 10;
int main()
{
int a = 0;
printf("%d\n", a);
return 0;
}这里还有一个要注意的点就是从代码可以看出,结构体后面是有“;”的,命名空间后面没有。
我们以前在C语言介绍过局部优先原则。
像这里这个顺序是什么呢?我们先在局部找,找到了就不会去全局找了。
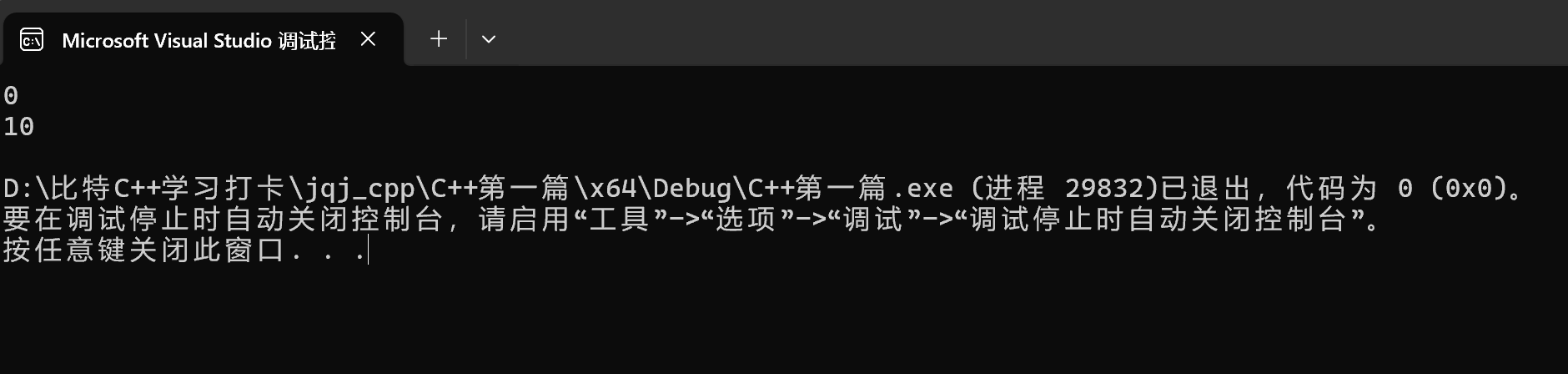
这里一运行,结果输出的是局部的a的值0:

如果没找到,我再去全局找,这里全局有a,找到了:

输出全局的a的值:

如果全局也没有找到,它就会报错,“未声明的标识” :

3、域作用限定符::
功能:指定访问作用域。
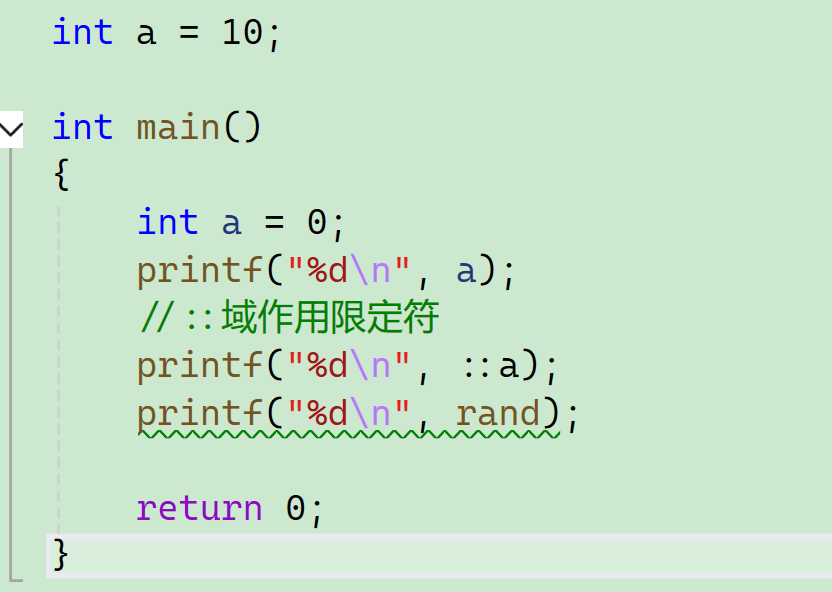
如果我们要访问全局的a怎么做呢?这时候就要用到域作用限定符:: 。

第二个输出的就是全局的a的值了:
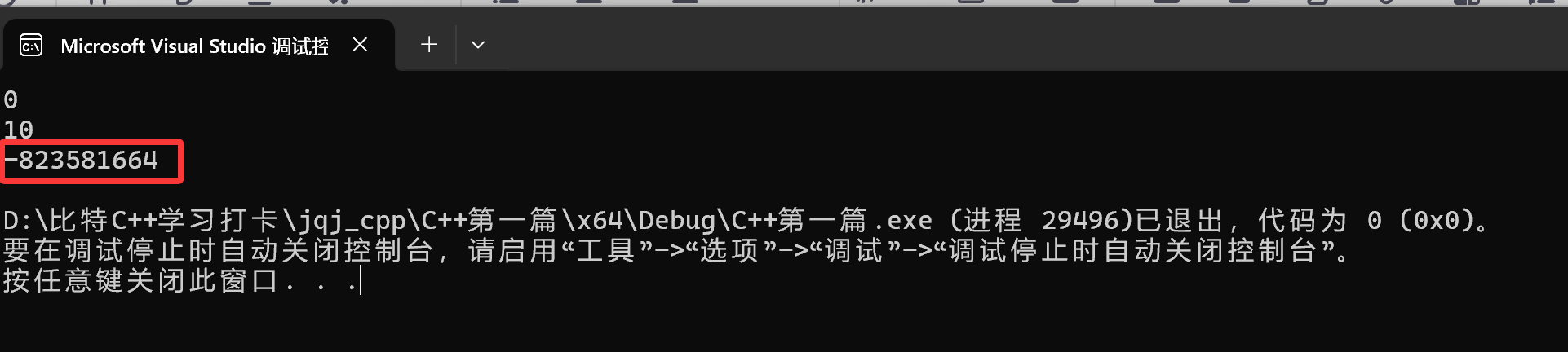
我们再来打印这个rand:
编译器没有报错,但是给我们报了一个警告:

因为这个<stdlib.h>里面的rand是个函数名,也就是个指针,我们就不能用%d这个占位符,打印指针我们之前专门介绍过,要用“%p”来打印,所以这里用%d会打印一个随机值:
我们改成用“%p”来打印(当然博主这里是x64环境):

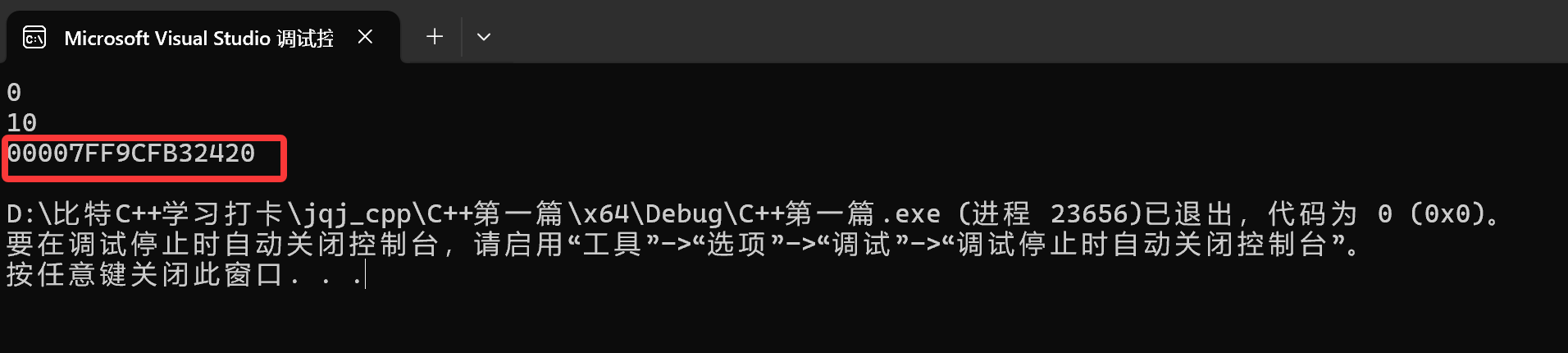
换成x86环境就是:
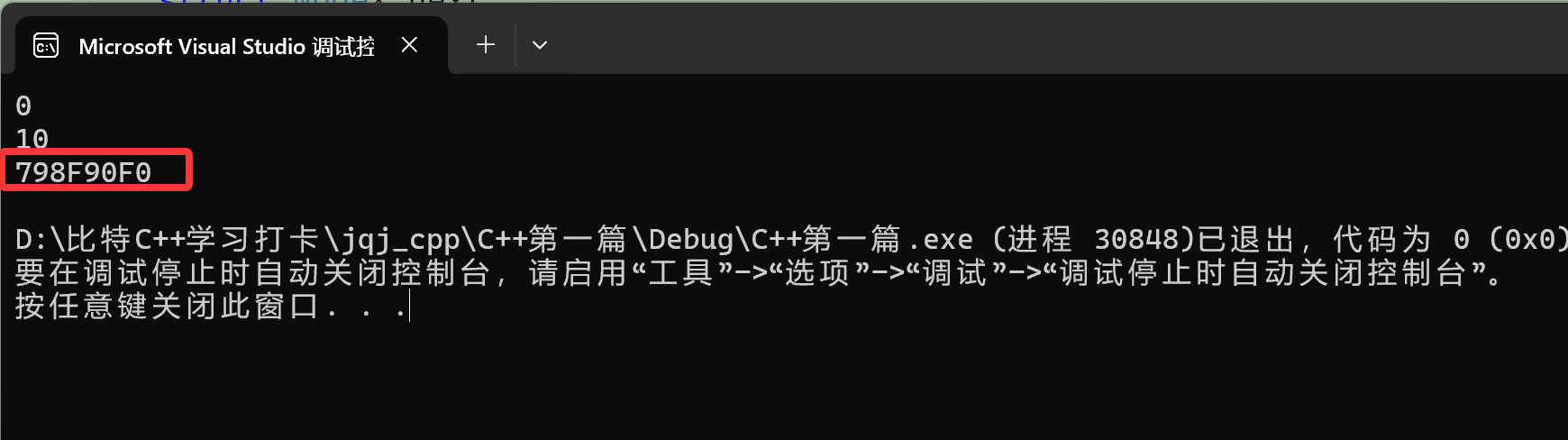
那如果我想访问命名空间里面的rand怎么办?我们前面知道了可以用域作用限定符::

但是注意,我们刚才命名空间是取了名字的,叫ATM,这可不是多此一举!
注意: 域作用操作符::前面要加上命名空间的名字,否则就默认是全局,默认不会到命名空间搜索。 找不到就是未声明的标识符。
因此如果我们不加这个名字,就算用了::,结果也还是指针:

我们把名字加上,记得把%p改成%d,命名空间里面rand不是函数名:

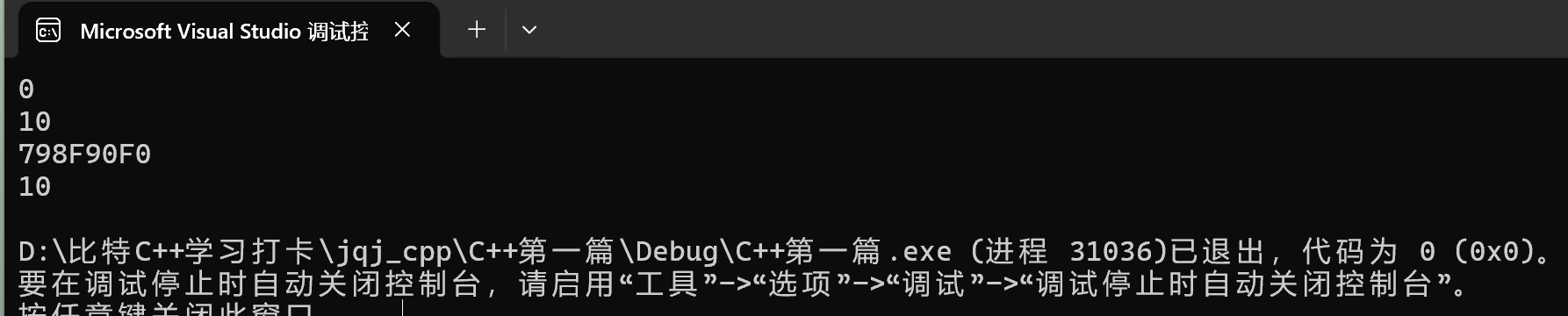
强调一下,如果没有什么指定域,它的搜索逻辑就很简单:先局部,再全局。
注:C++有局部域、全局域、命名空间域、类域。 其中,局部域、全局域会影响生命周期,命名空间域、类域不会影响生命周期。 定义的变量还是全局变量,main函数结束才会结束。


我们也可以指定一下:


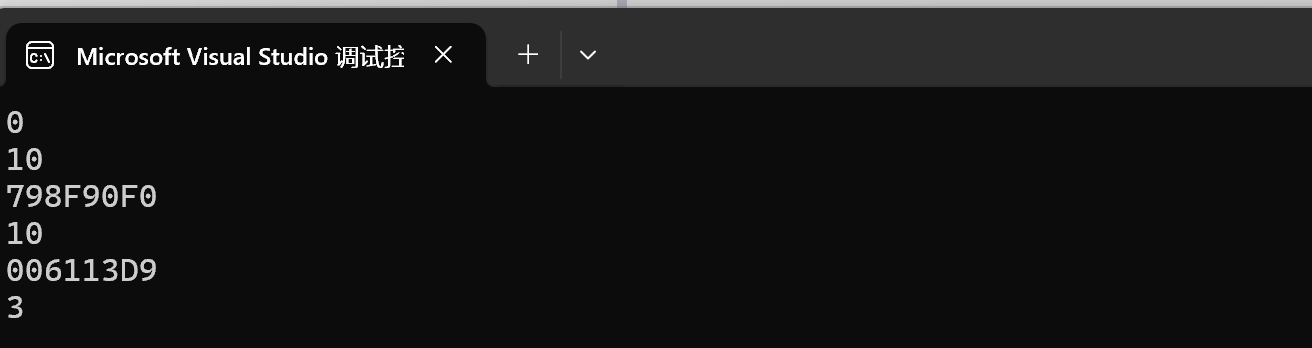
前一个Add是函数名,用%p打印,后一个Add是运算的结果,值用%d打印。
4、同一个文件用命名空间隔离相同命名不会冲突
全局域用命名空间隔离,相同命名不会冲突。
就像一个公司做项目,分成各种组,为了防止命名冲突,我们用命名空间隔离。
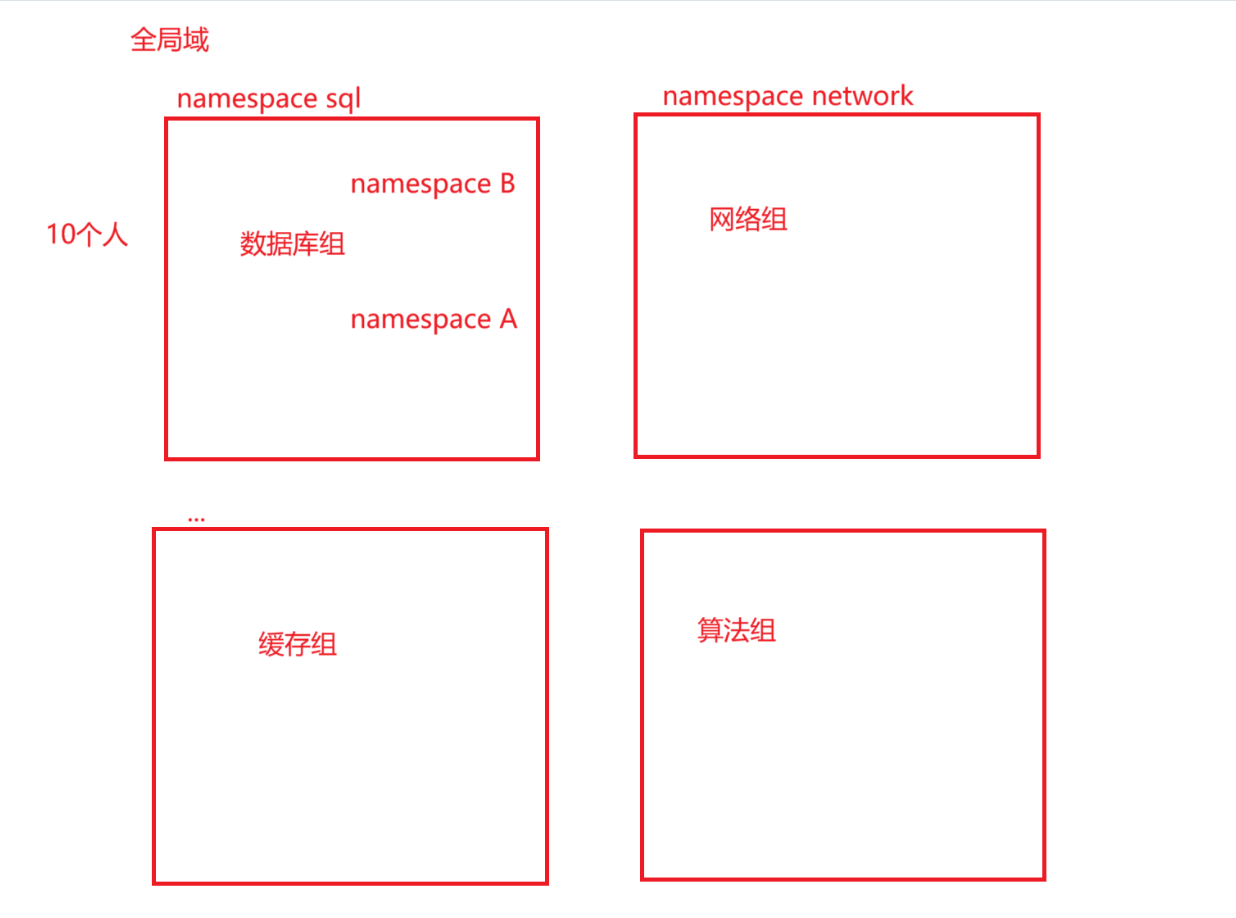
同一文件,如果命名空间名字相同,为了防止命名冲突,就只能改名字了。
公司里面同一个组不同的人也有可能用命名冲突,那怎么办?命名空间可以嵌套。
5、命名空间可以嵌套
#include<stdio.h>
namespace ATM
{
//张三
namespace zs
{
int rand = 1;
int Add(int left, int right)
{
return left + right;
}
}
//李四
namespace ls
{
int rand = 2;
int Add(int left, int right)
{
return left + right;
}
}
}
int main()
{
printf("%d\n", ATM::zs::rand);
printf("%d\n", ATM::ls::rand);
return 0;
}有了指定,编译器它就不会去走默认规则(局部优先原则)。

命名空间是可以嵌套很多很多的,但是从实践的角度我们还是不要嵌套很多,嵌套很多你用起来也会很不爽。
问:能不能用文件夹隔离?
文件夹是为了更好的项目管理。
我们刚才这些都是定义在同一个文件里面,但是稍微大一点的项目都会写到不同的文件,方便进行管理,定义到多个文件里面,不可能写到同一个文件里面。
6、多文件里面是什么样子的

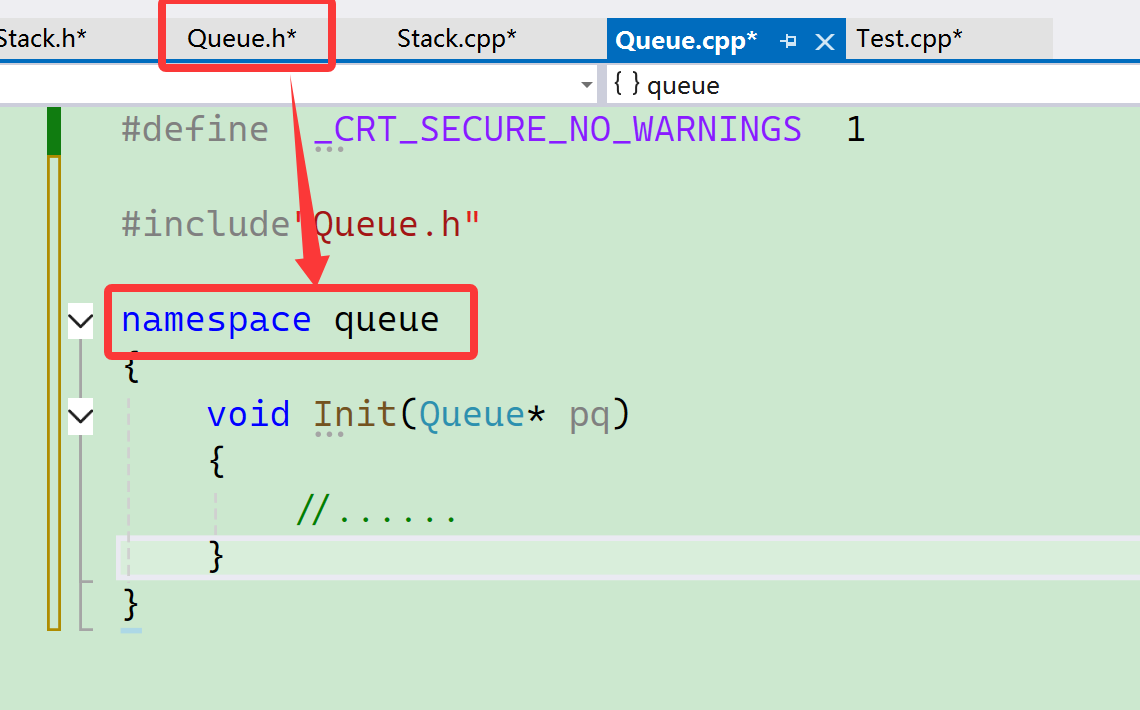
<Queue.h> 和<Queue.c>虽然定义在不同的文件里面,但是会把它们合成一个。
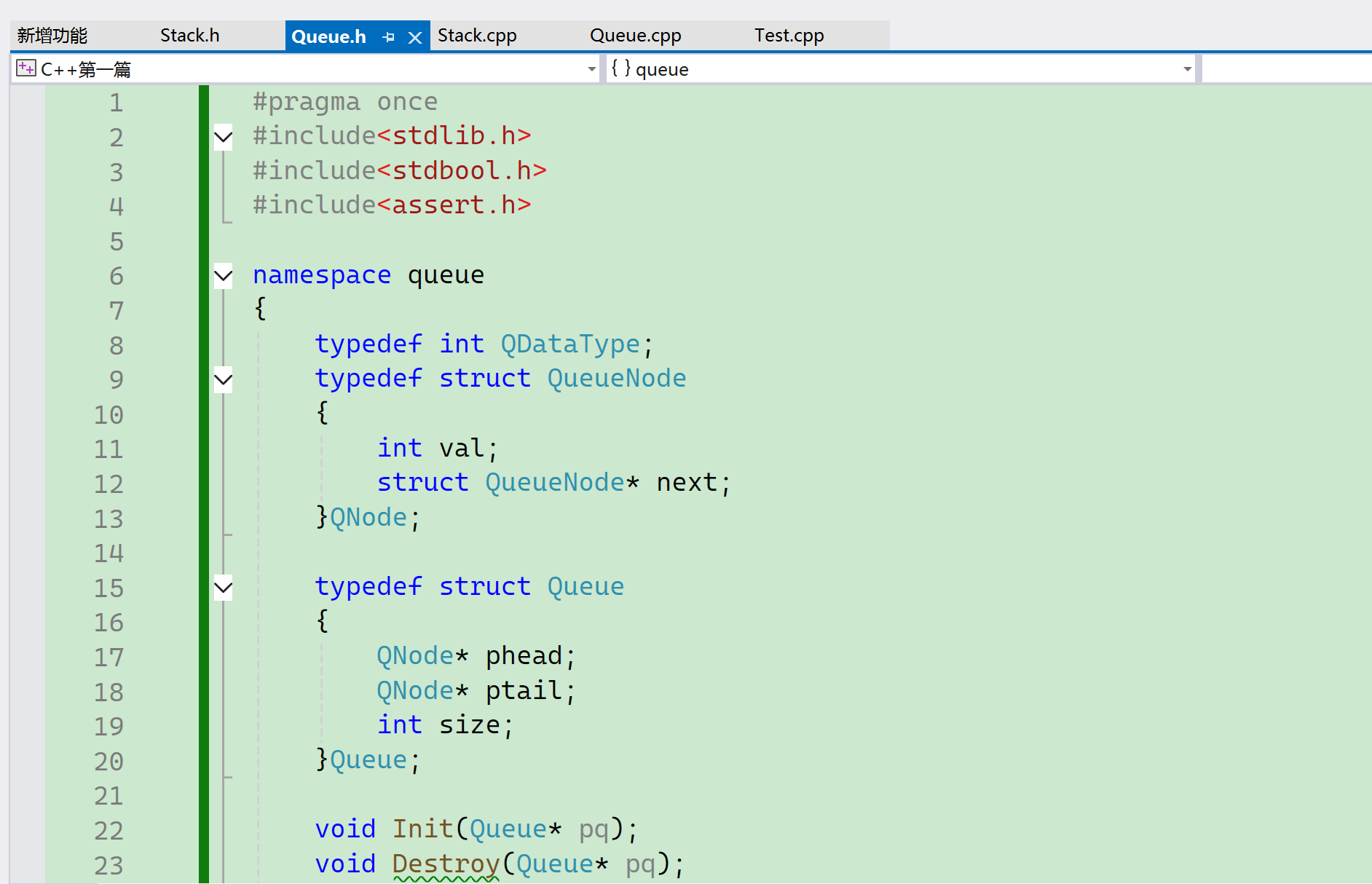
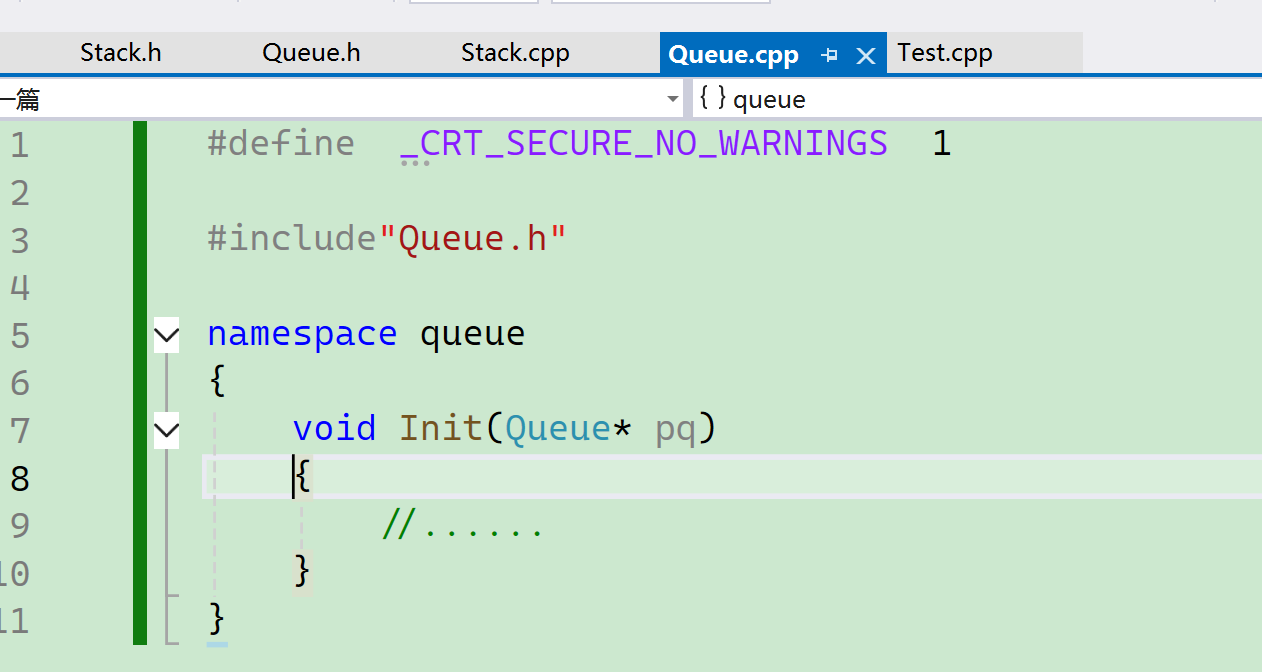
因此,不同的文件我们是可以定义同一个命名空间,无论几个,都会进行一个合并, 可以认为就像同一个文件一样。

多文件里面命名空间是可以随便定义的。
7、C++头文件通常都不带.h


C++发展的早期是带.h的,后来有了命名空间,为了跟没有命名空间的时候做区分,就不带了。
现在我们如果头文件包.h是包不通过的:

因为历史的一些原因,标准库std里面已经把.h给取消了。
注意:头文件也不是一定要包.h,只是说包了预处理会把它展开。
不要思维定势,脑袋固化啦。

微软在二十多年前开发的vc6.0里面,还是可以包.h的。
8、std库

std就是stardard标准库(里面有各种函数),这个sort是快排。
后面我们还会介绍这个std,这个sort怎么用我们后面会介绍,因为涉及到容器、迭代器等。
C++怕冲突,把标准库包在命名空间中:

9、流插入

比如说把i这个类型的对象转换成字符串插入到cout里面去,然后输出:
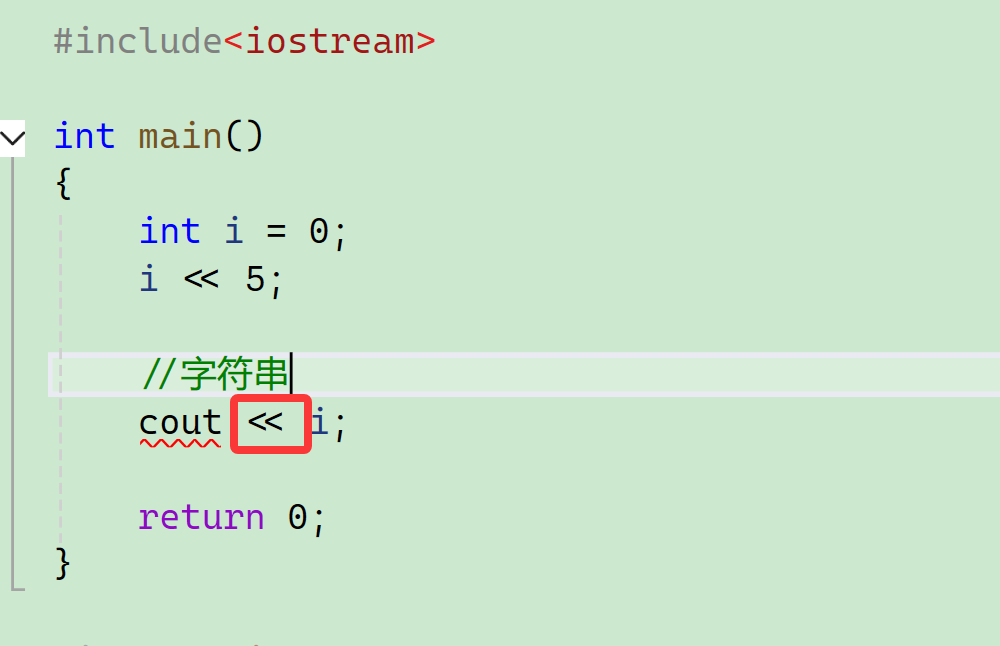
简单点我们也可以叫它输出运算符。
10、自动识别类型
大家可以看到,这里冒红色波浪线,编译能不能通过?通不过。
头文件<iostream>明明包了为什么还是通不过呢?
因为cout是头文件定义的一个全局对象,什么对象呢?

更具体一点有什么我们后面会介绍。
C++标准库的东西为了防止命名冲突,都是:

所以我们在这里得指定std:

这个就是我们对应的输出。
它的最大特点:自动识别类型。

比如这个就是一个空格的字符串。
11、换行
两种换行的方式:
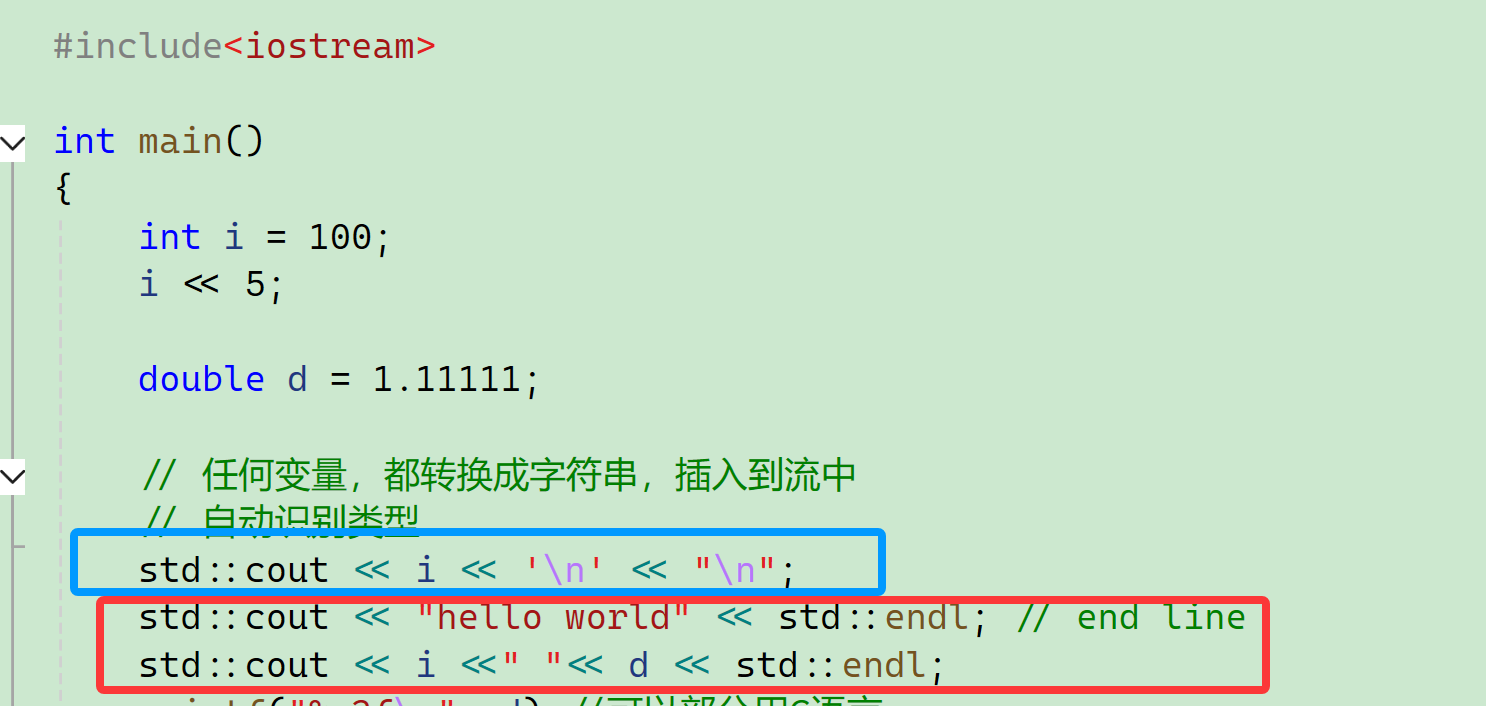
endl也是换行,即end line(结束一行)。
它是<iostream>定义的,也在std的命名空间,所以要指定。
大家经常看见的写法应该是这个:

现阶段我们可以认为这两个是一样的,我们介绍IO流的时候会介绍它们不一样的一些细节。
区别:会不会刷新缓冲区
频繁地刷新缓冲区会导致一定的效率上的问题。 这种不会频繁刷新缓冲区:
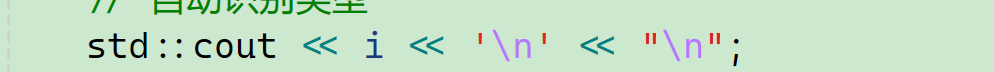
这个会频繁刷新缓冲区:
缓冲区的概念博主在C语言专栏的文件操作相关的博客中介绍过:
【掌握文件操作】(下):文件的顺序读写、文件的随机读写、文件读取结束的判定、文件缓冲区
下面是这篇博客【文件缓冲区】部分的截图:
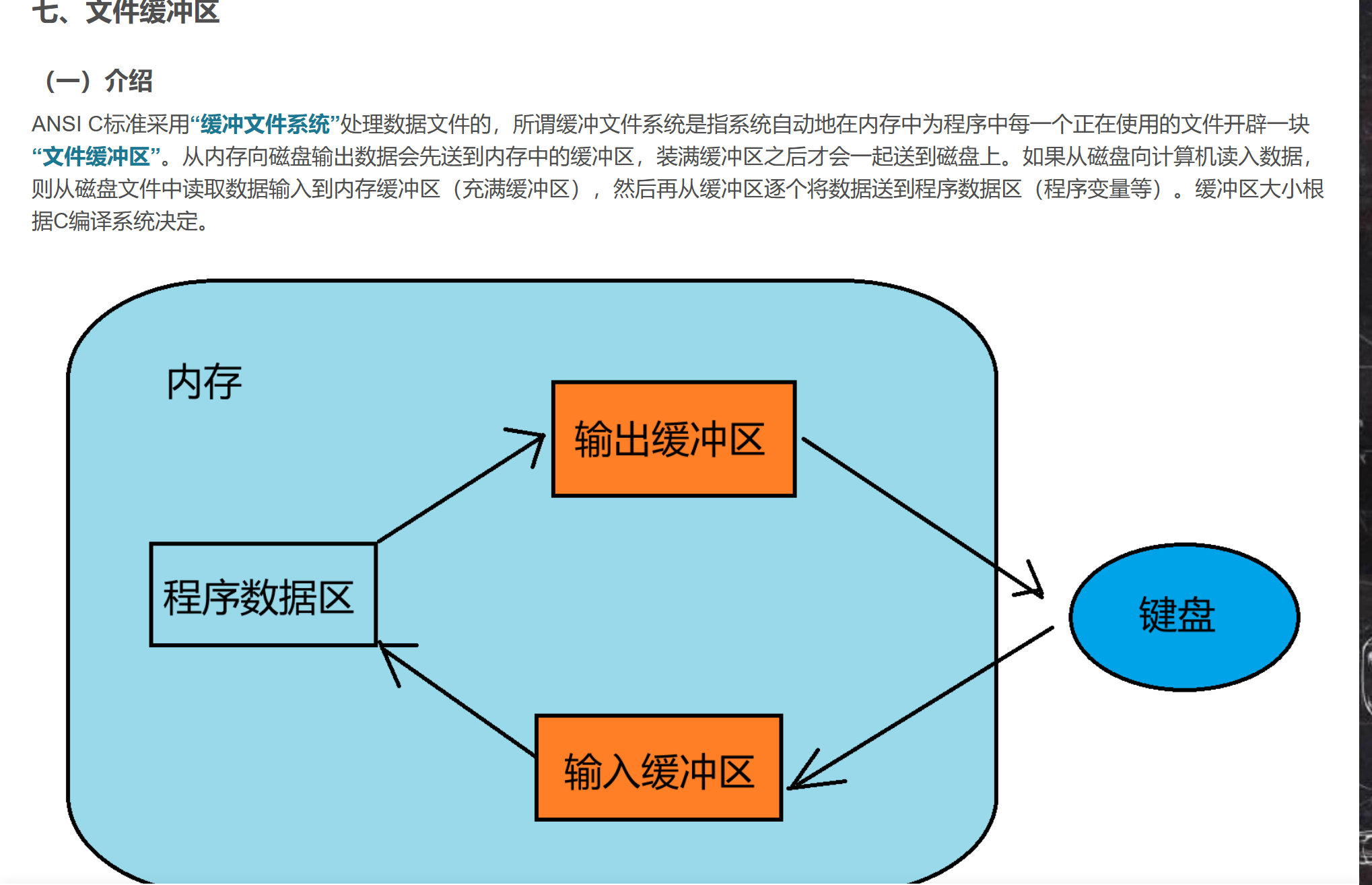
它会先到一个缓存里面去,累积到一个程度之后再出去。
因为这个IO输出的东西不会先到终端去,而是会先到一段缓存里面去,等累积多输入一些东西之后,再写到我们的终端可能效率会更高一些。
12、类型转换
因为本质上输入的都是字符串,cin是将其转换成对应的类型,当然这个类型得匹配上:
这个>>就是指定转换的类型,它叫流提取运算符:
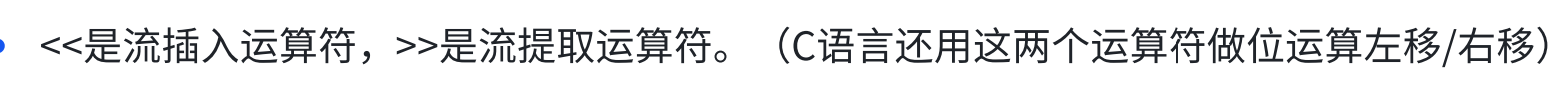
匹配不上它肯定就会报错,比如我们要转换成整型,但里面却包含字符串,那肯定匹配不上匹配不上它肯定就会报错,比如我们要转换成整型,但里面却包含字符串,那肯定匹配不上 。
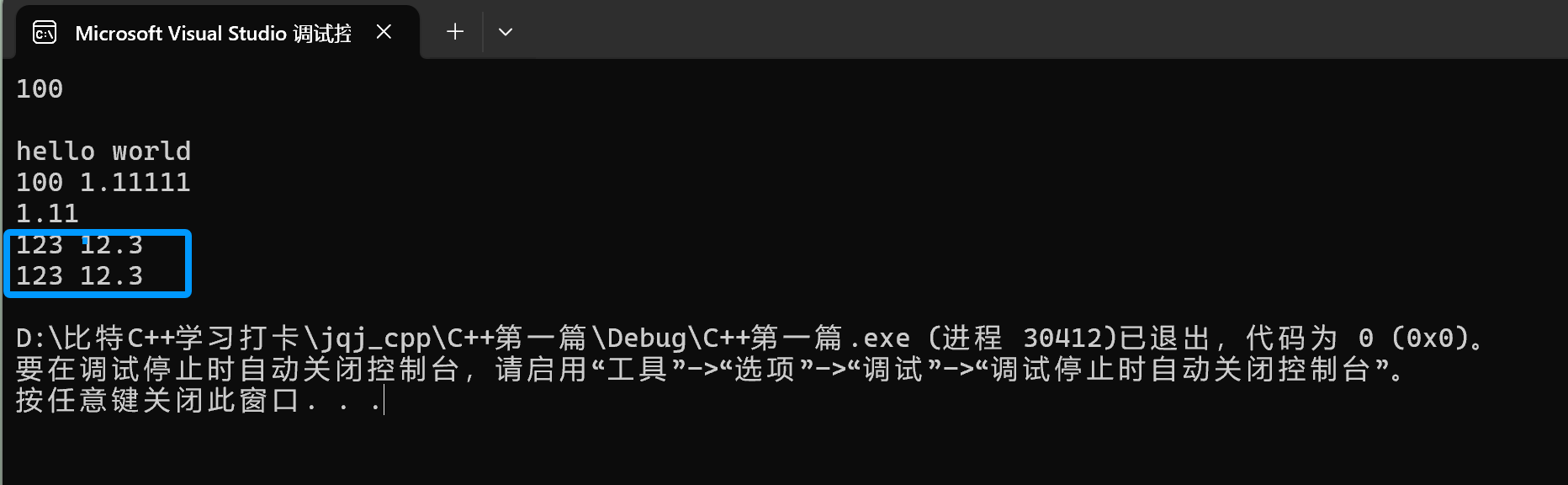
像下面这样:
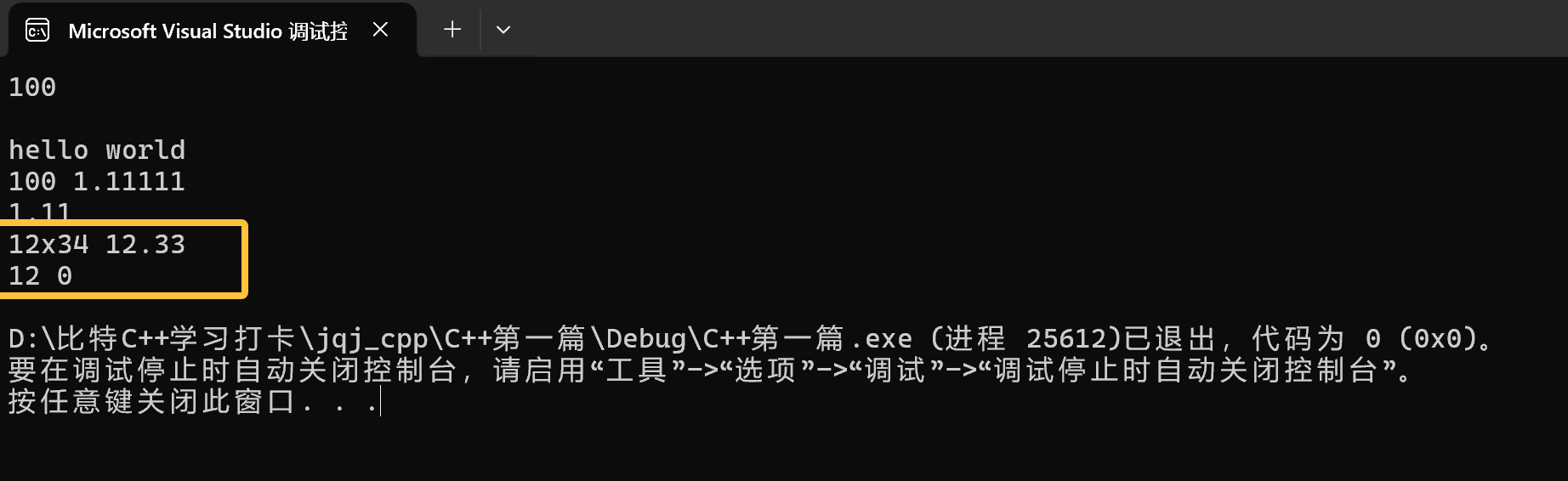
它识别到x之前的12,就输出12。
本质上就是报错了,没有读到正确的数值。
流出错这个是个比较复杂的问题,我们留到IO流再去详细介绍一下。
13、打印小数点后位数
具体我们等到类和对象中IO流的部分再介绍,但是C语言还是支持的:

14、只要是C++标准库的,都要指定std
我们现在学过的就是C语言的库和C++的库,C语言的改不了,但只要是C++库里面的都要指定std。C语言库的不需要,因为C++要兼容以前的用法,就比如这个:
因而C++不敢用命名空间封起来。
15、指定命名空间访问
每次都要加这个std,实在是太麻烦了:
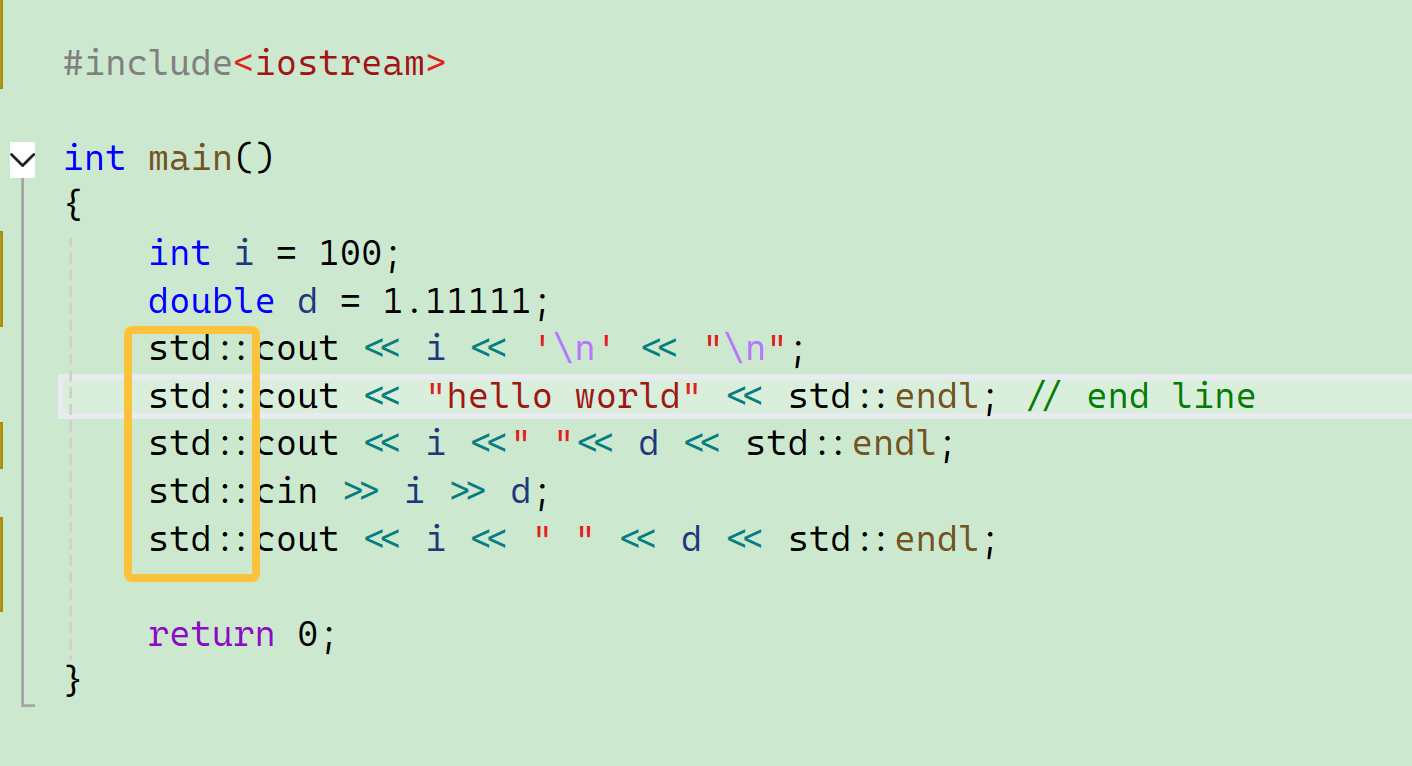
可不可以不加这个?可以。

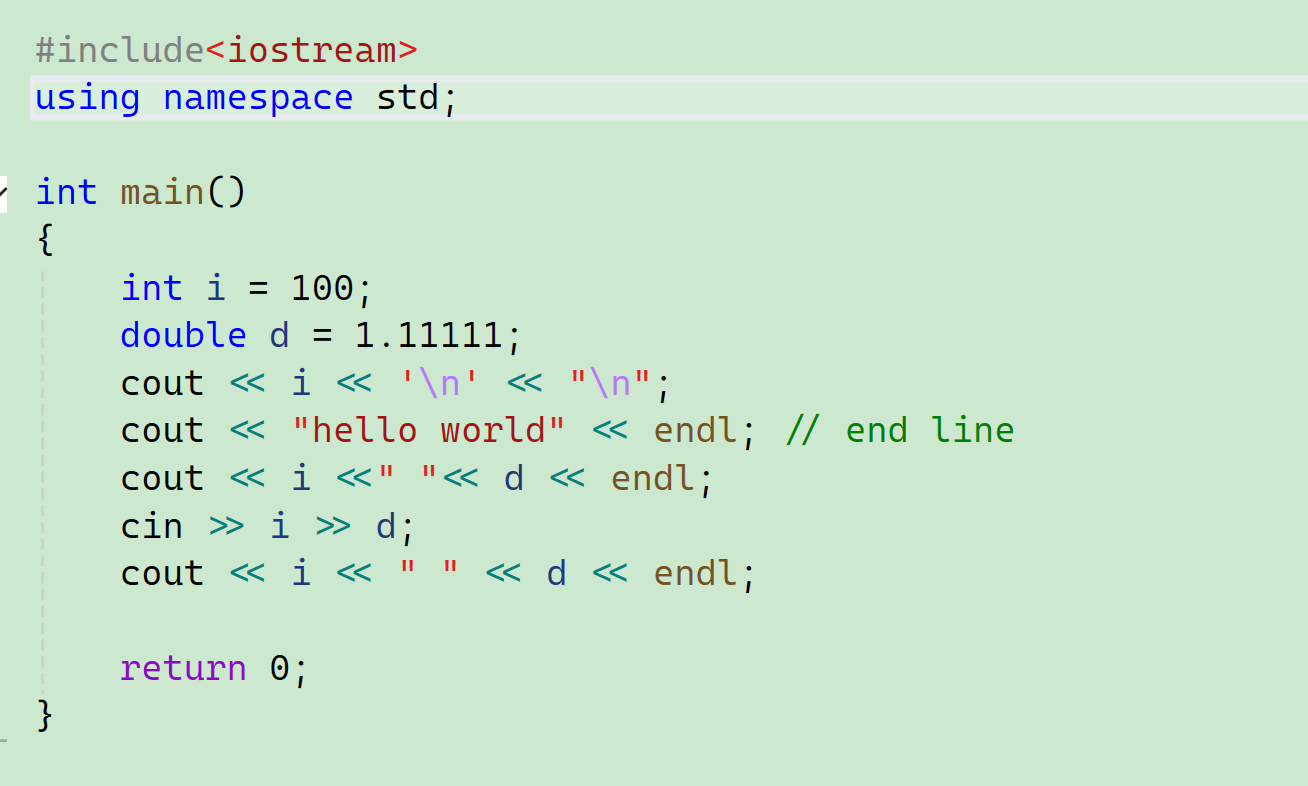
这是展开库里面的命名空间,那我们就不需要指定了。
某种程度上我们可以这样认为:
这样是把命名空间里面的东西暴露到全局去了,虽然它叫“展开命名空间”,但是这个展开的意思其实就是把标准库里面的比如说头文件(这个<iostream>就是拿namespace std包起来的),也就是说,这句话的意思就相当于暴露到全局了:

本质的意思是:
先在局部查找,再在全局查找,都没找到的话,它还会到std——展开的命名空间里面去查找。从底层实现的角度其实就是多了这样一个步骤。
弊端:
我们命名空间std展开,如果我们定义和库里面冲突的东西就会报错了。
总结:在大型的项目是不能这么干的,只能说在日常练习中使用比较方便。
折中的方式:
现在要不就是每个都要去指定,要不就是一次性全展开全冲突了,有没有折中的方式呢?

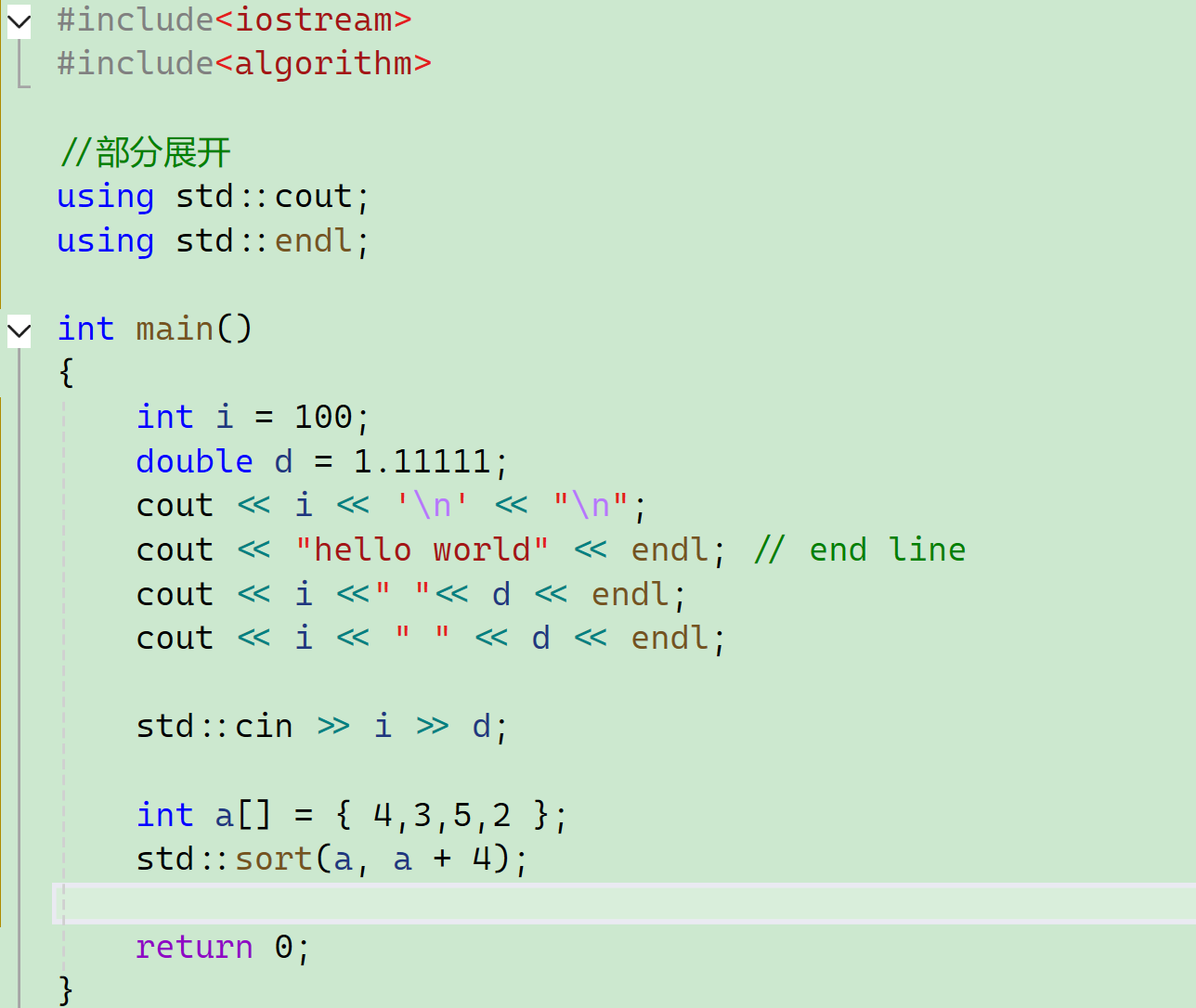
部分展开之后能不能定义和部分展开同名的东西?
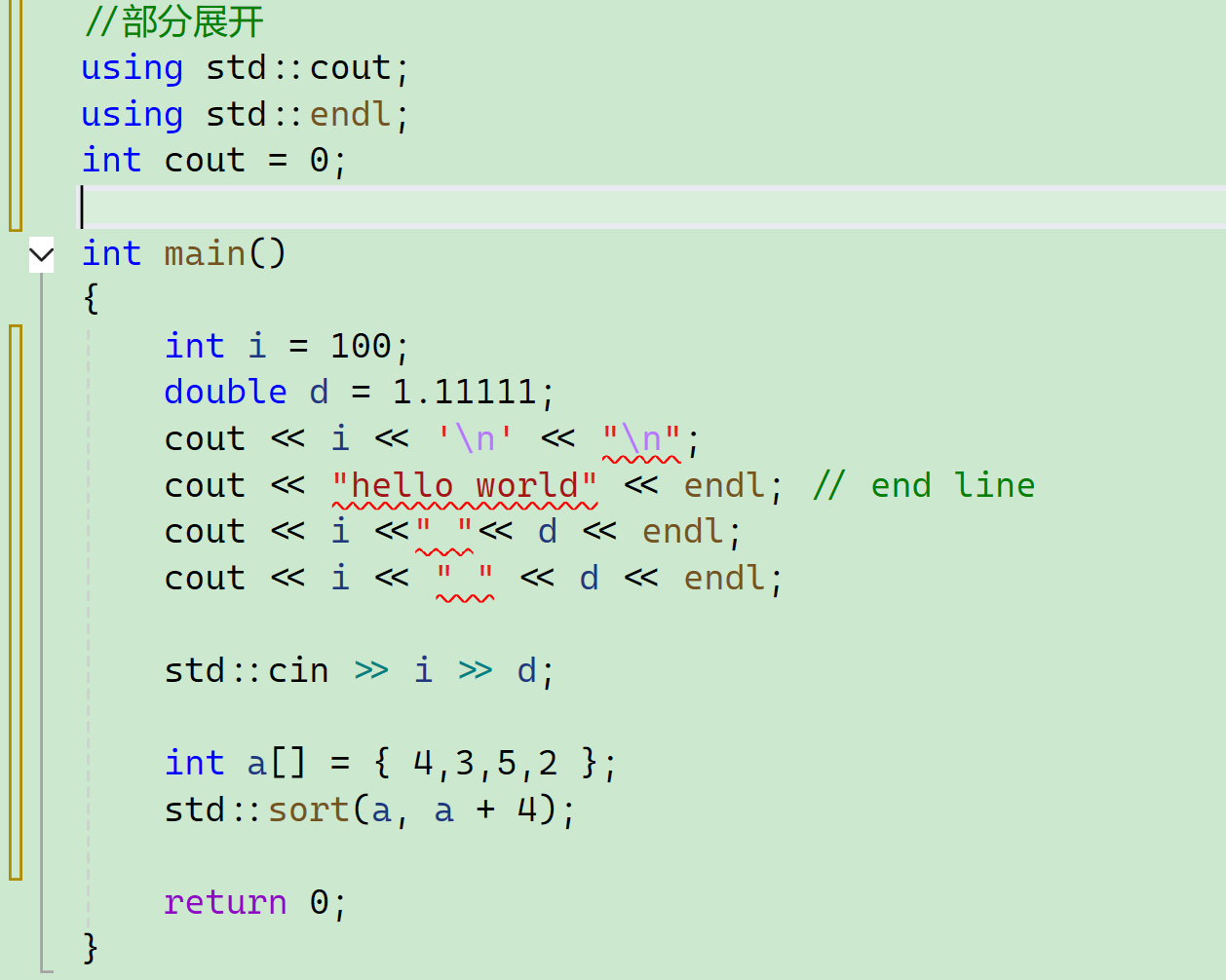
是不是不行呀。
因此,我们可以得出一个结论:
全部展开就是全部不能冲突,部分展开就是部分不能冲突,至少不跟它展开的冲突。 比如说using std :: endl——简而言之就是暴露到全局了: 相当于我们改变了查找规则。
这个还是可以做到的。那我们定义一个和部分展开不同名的会不会有问题?
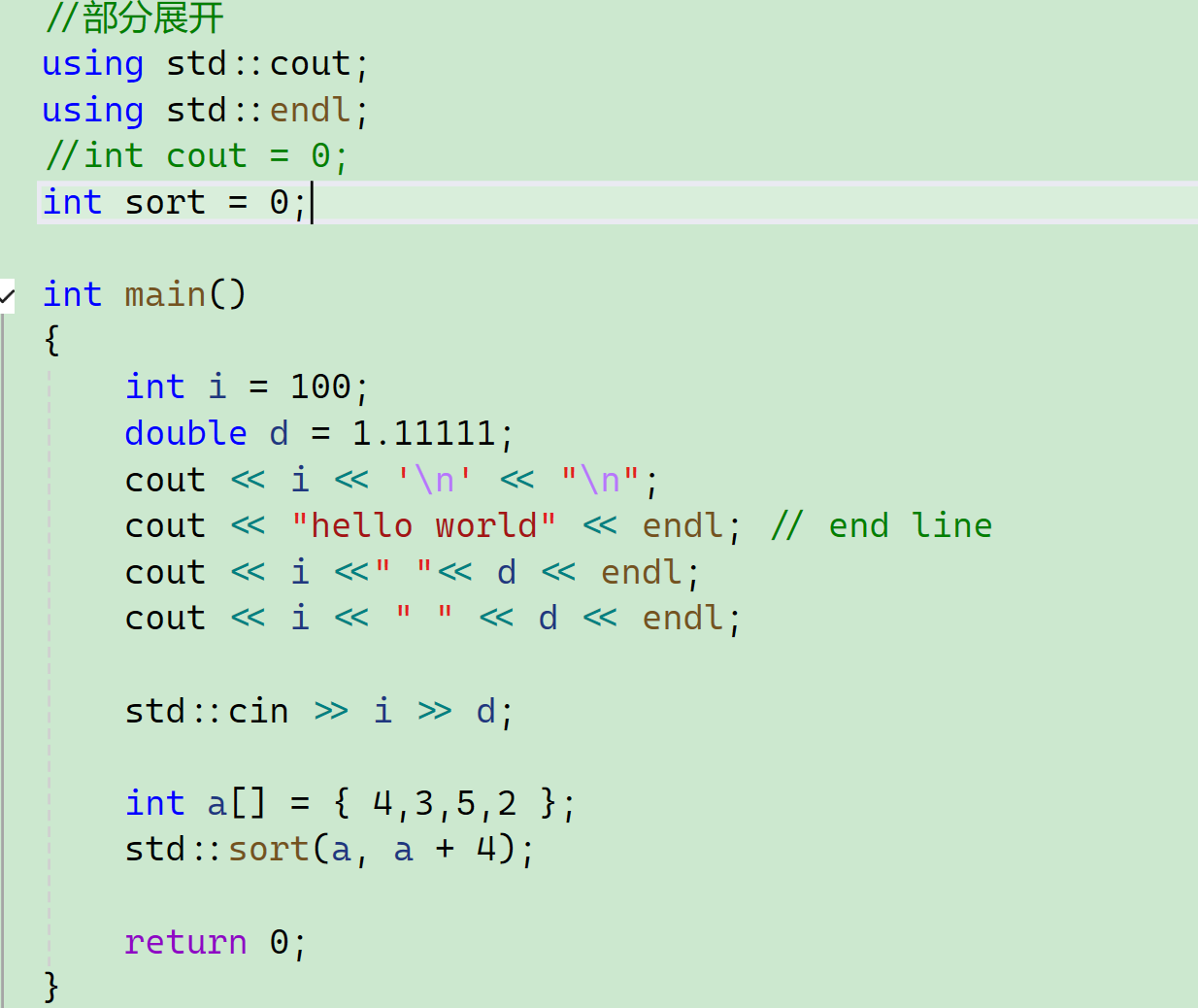
不会有问题。
std里面有sort,全局里面也有sort,但是这里访问sort是指定的,不存在冲突。
全部展开就是全部不能冲突,部分展开就是部分不能冲突,否则就会有认不清的问题。

16、C++的这些内容是要解决什么问题
总结一下,本质上是要解决什么问题? 是要解决C语言不足的问题。 1、命名空间是要解决名字冲突的问题; 2、IO流是要解决复杂类型的输入输出问题,printf、scanf只能支持简单类型的输入输出。
因此Bjarne博士不是说他感觉这个语法不爽那个语法不爽就改了,而是因为之前C语言的那些东西确实存在缺陷,所以他才来定义这些东西。
结尾
本文是C++的入门,大家不能马虎,要为接下来的【类和对象】打好基础。
本文作为本专栏的“长子”,暂时没有【往期回顾】这个环节。 结语:本文内容到这里就全部结束了, 本文我们简单了解了一下C++历史的,整理了命名空间、流插入、命名空间的指定访问、展开问题等概念,在我们学习到模版初阶之前,都是些晦涩的概念,还用不起来,到后面我们就能像之前那样,结合起来介绍。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-08-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号