由DeepSeek-OCR对图像文本模态对齐的思考


deepseek这篇论文得到广泛关注,主要是提出的视觉编码文字相比token编码文字具有更高的效率,论文introduction部分提到核心思路:leveraging visual modality as an efficient compression medium for textual information,这句话概括了技术实现思路,通过视觉模态压缩文本信息是一种有效的文本信息表征方式。刚好想到多模态对齐,就结合目前的多模态背景来谈一下自己的观点。
我们看到现在大部分的VLM现在都是以text 模态为中心,图像信息得到的representation最终会对齐到text空间上,基于对齐合并后的text representation再去进行推理完成任务,这背后的一个原因是现在缺乏一个有效的表征图像的方法,或者是视觉基础模型还没有到达llm的chatgpt时刻,veo3那篇论文[1]分析视觉基础模型应该通过视频模型来实现通用泛化生成理解,这个后面也会聊到。另外目前很多视觉文本融合的方法是基于划分patch的视觉信息编码对图像进行离散化处理得到图像表征,加上llm在training,test上scaling的进展,很自然的将图像模态对齐到文本模态,由llm来处理统一模态表征完成各类任务,这个范式也叫mllm(multimodal large language model ),现在vlm和mllm两个领域其实存在很大重叠。近期推出的工作有qwen3-vl[2],llava-onevison-1.5[3],都是先提取视觉patch特征进行编码,然后与文本表示进行对齐合并,统一经过一个lm来产生输出。
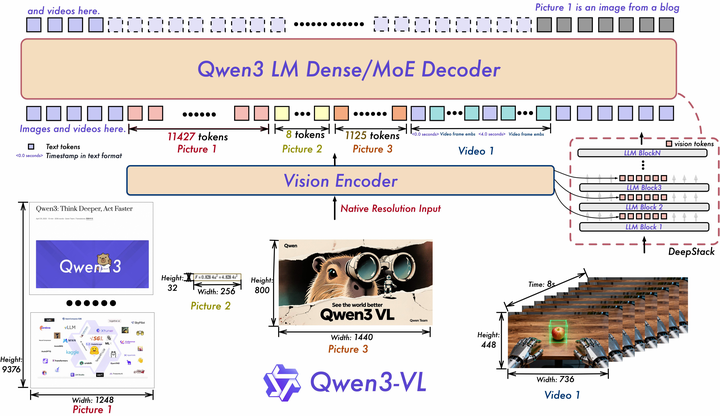
添加图片注释,不超过 140 字(可选)
但也看到一些以视觉为中心的多模态对齐方法(vision-centric),比如最近发的几篇文章由上交和蚂蚁合作的Vaco[4],引入了多个视觉基础模型,整合从多个视觉基础模型(VFMs)提取的任务感知特征,通过将视觉token与文本token进行联合优化。
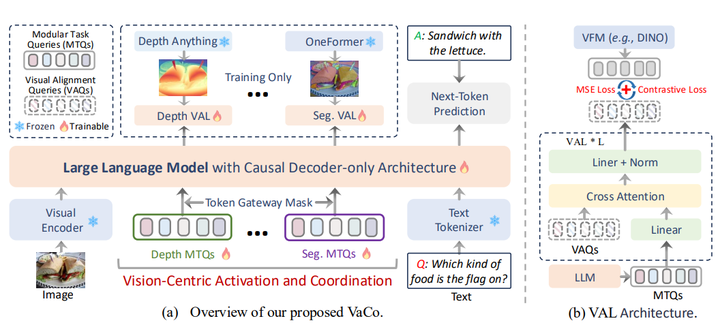
添加图片注释,不超过 140 字(可选)
但是不管是否以视觉为中心,语言空间和图像空间的对齐是一个核心问题。而ocr恰好是图像如何对齐语言的一种特定任务,与最近发布的paddleocr-vl对比,PaddleOCR-VL[]使用传统VLM架构,以视觉为主导,通过原生分辨率和动态处理来保留视觉细节。
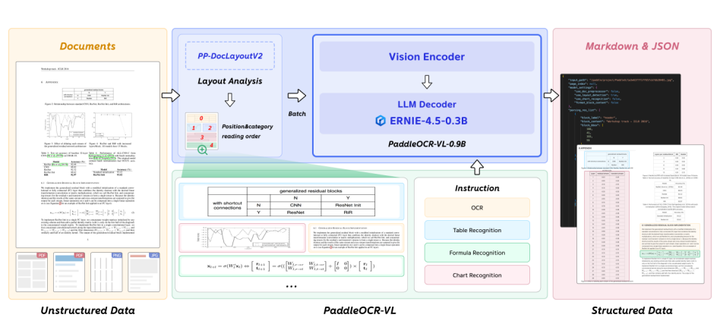
添加图片注释,不超过 140 字(可选)
而Deepseek-ocr[5]本质上是"语言为中心"的设计。将文本转换为图像并通过视觉编码器处理,目的是为LLM记忆提供有损压缩方案。所以从视觉->语言表征的设计,deepseek-ocr[6]确实提出了比较创新并且具备落地性的方案,在对文字表征上确实有不小作用。
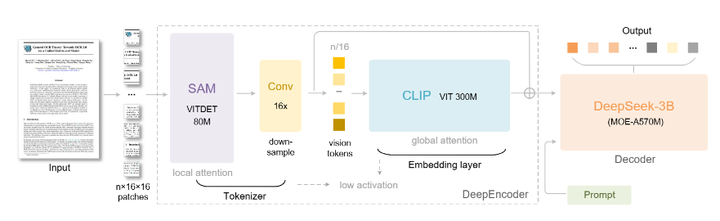
添加图片注释,不超过 140 字(可选)
但现在视觉文本对齐的问题,我觉得更难的不是单向图像到文字的对齐,而是文字到图像的对齐,图像到文字上的对齐是"压缩",文字到图像的对齐是"扩展",扩展的难度在于更大的空间要求可控还原。比如文生图现在的效果确实也越来越好,但一旦需要严谨核对,就会出现各种违背事实的问题。但关键还是在于两个模态的隔阂,比如六个手指的图片,现在的模型都基本会回答五个,这可能是先验知识过强导致了视觉理解偏差,更有可能是在common sense层面,两个模态的信息就完全没对齐。
所以两个模态的单向的打通和双向打通难度是不一样的。另外现在模态对齐更难的是时间维度上的对齐,前面也提到veo3的视频多模态模型为视觉迈向通用化的训练基础,这个参考llm也好理解,因为LLM本身是时序模型,已经具备在文本世界的时序推理能力,而目前的视频生成模型还没有突破对物理规律的基础理解,虽然有genie3,sora2,还有李飞飞团队最近发布的RTFM[7],但是这些工作都没有非常solid的理论和证据表明实现对现实世界的理解。
deepseek-ocr确实是很有价值的通过图像压缩文本编码的方法,是图像对齐文本的一种有效编码方式,但不是文本图像模态对齐的通解。
参考文献:
1https://arxiv.org/pdf/2509.20328
2.https://github.com/QwenLM/Qwen3-VL
3.https://arxiv.org/pdf/2509.23661
4.https://arxiv.org/pdf/2510.14349
5.https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
6.https://arxiv.org/pdf/2510.14528
7.https://www.worldlabs.ai/blog/rtfm
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号