深入解析网络 I/O 阻塞,从成因到高并发解决方案
原创

作为开发者,我们都知道,无论是日常使用的即时通讯软件,还是支撑海量用户访问的电商平台,背后都离不开网络 I/O(输入 / 输出)的高效运作。然而,网络 I/O 阻塞却像一颗隐藏的 “定时炸弹”,随时可能导致程序响应缓慢、系统资源浪费,甚至引发服务崩溃。这里我将从网络 I/O 阻塞的本质入手,深入剖析其成因与危害,系统梳理主流 I/O 模型与高并发解决方案。希望可以帮助到大家。ok,下面正文开始
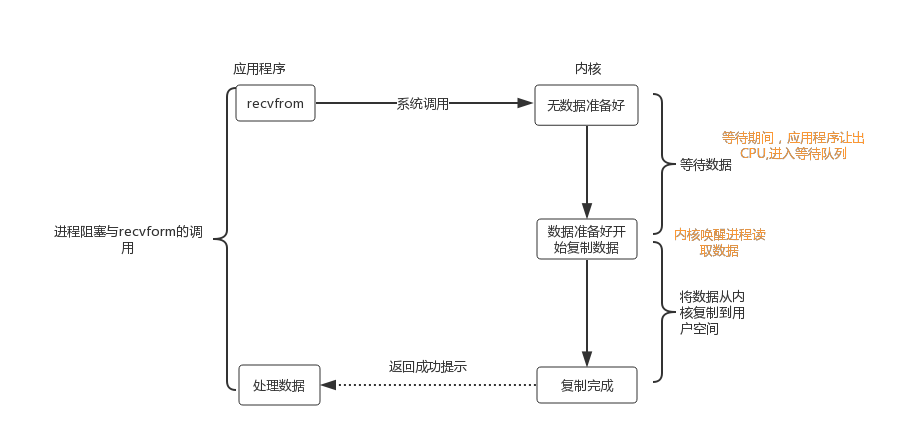
一、网络 I/O 阻塞
网络 I/O 阻塞,本质上是程序在发起网络请求后,因等待数据传输完成而陷入 “停滞” 状态的现象。就像现实生活中的交通拥堵,车辆(数据)无法顺畅通行,导致整条道路(程序执行流程)效率低下。要解决这一问题,首先需要明确其背后的核心成因。
1. 四大核心成因:从物理层到协议层的制约
- 网络延迟:距离与协议的双重考验
网络延迟是导致 I/O 阻塞的基础因素,主要受传输距离、路由器处理效率、网络拥塞程度及协议开销影响。例如,本地局域网内的延迟通常仅 1-10ms,而跨洲际的卫星通信延迟可高达 500ms 以上。更关键的是,TCP 协议的 “三次握手” 流程 —— 客户端发送 SYN 报文、服务端返回 SYN-ACK 报文、客户端再发送 ACK 报文 —— 仅建立连接就需消耗多个 RTT(往返时间),进一步加剧了等待时间。
- 带宽限制:理论与现实的差距
尽管 5G 网络的理论带宽可达 10Gbps,但实际应用中,受限于运营商网络规划、终端设备性能及网络拥堵,用户能体验到的带宽往往只有理论值的 10%-30%。例如,4G 移动网络理论下载速度为 100Mbps,实际使用中可能仅 20Mbps 左右,当传输大文件时,有限的带宽会直接导致数据传输停滞,引发 I/O 阻塞。
- 流量与拥塞控制:“削峰填谷” 的副作用
TCP 协议为保证数据可靠性,设计了流量控制与拥塞控制机制。当接收方缓冲区已满时,会通过 TCP 头部的 “窗口大小” 字段告知发送方降低发送速率;若网络出现丢包(通常意味着拥塞),发送方会触发 “慢启动” 算法,大幅减少发送窗口。这些机制虽能避免网络崩溃,但会导致数据传输间歇性停滞,成为 I/O 阻塞的重要诱因。
- 应用层设计缺陷:程序自身的 “短板”
除了底层因素,应用程序的设计问题也可能导致 I/O 阻塞。例如,使用阻塞式 I/O 模型时,程序调用recv()或read()接口后,会一直等待数据到达,期间无法执行其他任务;若未合理设置超时时间,甚至可能陷入无限等待,直接导致线程 “僵死”。
2. 阻塞式 I/O 的代价:资源浪费与性能瓶颈
阻塞式 I/O 的工作流程看似简单 —— 应用程序发起 I/O 请求→操作系统检查数据是否就绪→若未就绪,应用程序被挂起→数据到达后,操作系统通知应用程序继续执行 —— 但在高并发场景下,其弊端会被无限放大。
以处理 1000 个并发连接为例:采用阻塞式 I/O 时,每个连接需分配一个独立线程(或进程),而每个线程仅栈空间就需 1-8MB(取决于操作系统),1000 个线程的内存消耗可达 1200MB 以上。更严重的是,线程上下文切换的开销会随着线程数量增加而急剧上升 ——Linux 系统中,一次线程切换需消耗约 1-5μs,若每秒发生 10 万次切换,仅切换开销就会占用 CPU 5%-25% 的资源。最终,大量 CPU 时间被浪费在 “等待数据” 上,资源利用率极低,成为系统性能的瓶颈。
二、主流 I/O 模型与高并发解决方案
为解决网络 I/O 阻塞问题,行业内逐渐发展出多种 I/O 模型与解决方案。从早期的多进程模型到现代的异步 I/O 与协程,每一次技术演进都旨在平衡 “性能” 与 “开发效率”。
1. 四大 I/O 模型对比:从阻塞到异步
不同 I/O 模型的核心差异在于 “应用程序等待数据的方式”,以下是四种主流模型的对比分析:
模型 | 核心特点 | 适用场景 | 优缺点 |
|---|---|---|---|
阻塞 I/O | 应用程序调用后阻塞,直到数据传输完成 | 并发量低、对性能要求不高的场景(如简单 TCP 客户端) | 优点:实现简单;缺点:资源利用率低,无法高并发 |
非阻塞 I/O | 调用后立即返回,无数据时返回错误码,需应用程序轮询检查 | 需同时处理多个连接,且可穿插执行其他任务的场景 | 优点:避免阻塞;缺点:轮询消耗 CPU,效率低 |
I/O 多路复用 | 通过 select/poll/epoll 等接口监控多个 socket,仅当事件发生时才处理 | 高并发连接场景(如 Nginx、Redis、MySQL) | 优点:单线程处理大量连接,资源利用率高;缺点:实现复杂 |
异步 I/O | 调用异步接口后立即返回,操作系统完成 I/O 后通过信号或回调通知应用程序 | 需最大化 CPU 利用率,避免任何等待的场景(如高性能服务器) | 优点:完全非阻塞,性能最优;缺点:实现难度大,跨平台支持差 |
其中,I/O 多路复用是当前高并发场景的主流选择,而其核心在于不同的 “事件通知机制”。以下是几种常见多路复用技术的细节对比:
技术 | 最大连接数 | 时间复杂度 | 触发方式 | 适用平台 | 典型应用 |
|---|---|---|---|---|---|
select | 1024(默认) | O(n) | 轮询 | 跨平台(Linux/Windows/macOS) | 早期服务器程序 |
poll | 无限制 | O(n) | 轮询 | Linux/macOS | 替代 select 的场景 |
epoll | 无限制 | O(1) | 事件通知 | Linux | Nginx、Redis、Node.js |
kqueue | 无限制 | O(1) | 事件通知 | BSD/macOS | macOS 下的高性能应用 |
IOCP | 无限制 | O(1) | 事件通知 | Windows | Windows 服务器程序 |
可以看到,epoll 凭借 “O (1) 时间复杂度” 和 “事件通知” 机制,成为 Linux 系统下处理高并发的 “利器”。例如,Nginx 通过 epoll 实现单进程处理数万并发连接,而 Redis 则通过 epoll 支撑每秒数十万的请求量。
2. 高并发解决方案的演进:从进程到用户态协议栈
随着业务对并发量的需求不断提升,高并发解决方案也经历了多代演进,每一代都针对前一代的痛点进行优化:
- 1990s:多进程 / 多线程模型
代表应用为 Apache 的 prefork 模式,每个连接对应一个独立进程(或线程)。这种模型的优点是实现简单、稳定性高(进程隔离),但缺点是资源消耗大 —— 当并发量达到数千时,内存与 CPU 开销会急剧上升,无法支撑更高并发。
- 2000s:I/O 多路复用模型
以 Nginx、Lighttpd 为代表,采用 “单进程(或多进程)+ I/O 多路复用” 架构,单进程即可处理数万并发连接。这种模型大幅降低了资源消耗,但开发难度较高,需要手动管理事件循环与状态机。
- 2010s:协程模型
随着 Go 语言的兴起,协程(Coroutine)成为平衡 “性能” 与 “开发效率” 的新选择。协程是轻量级线程,由用户态调度,单个进程可创建数十万甚至数百万个协程,且上下文切换开销仅为线程的 1/1000 左右。例如,Go 的 goroutine 通过 “M:N 调度”(M 个协程映射到 N 个操作系统线程),既避免了阻塞 I/O 的资源浪费,又简化了开发 —— 开发者可像编写同步代码一样处理异步逻辑。
- 2020s:异步 I/O 与用户态协议栈
为进一步突破性能瓶颈,行业开始探索异步 I/O 与用户态协议栈。例如,Linux 的 io_uring 接口支持批量提交 I/O 请求、零拷贝传输,且兼容网络、磁盘等所有 I/O 类型,性能比 epoll 提升 30% 以上;DPDK(Data Plane Development Kit)则绕过操作系统内核,直接在用户态实现 TCP/IP 协议栈,将网络数据包处理性能提升 10 倍以上,适用于高频交易、CDN 等超高性能场景。
三、现代技术实战
掌握了 I/O 模型与解决方案后,如何在实际开发中应用?以下将通过 Python 与 Go 语言的示例,展示异步 I/O 与协程的实现方式。
1. Python 异步 HTTP 服务器(基于 aiohttp)
aiohttp 是 Python 的异步 HTTP 框架,基于 asyncio 实现,支持非阻塞 I/O。以下示例实现一个简单的 HTTP 服务器,模拟非阻塞数据库查询:
import aiohttp
from aiohttp import web
import asyncio
# 模拟非阻塞数据库查询(实际场景中可能是MySQL/Redis的异步客户端)
async def query_database(user_id):
# 模拟I/O等待(替代数据库查询的耗时)
await asyncio.sleep(0.1) # 非阻塞等待,期间可处理其他请求
return {"user_id": user_id, "name": "Alice", "age": 25}
# 处理HTTP请求
async def handle_request(request):
user_id = request.match_info.get("user_id", "1")
# 调用非阻塞数据库查询
user_data = await query_database(user_id)
return web.json_response(user_data)
# 启动服务器
async def main():
app = web.Application()
app.add_routes([web.get("/user/{user_id}", handle_request)])
runner = web.AppRunner(app)
await runner.setup()
site = web.TCPSite(runner, "0.0.0.0", 8080)
await site.start()
print("Async HTTP server started on http://0.0.0.0:8080")
# 保持服务器运行
await asyncio.Event().wait()
if __name__ == "__main__":
asyncio.run(main())在上述代码中,query_database函数通过await asyncio.sleep(0.1)模拟非阻塞 I/O 等待,期间事件循环会切换到其他就绪的任务,从而实现 “同时处理多个请求”。即使有 1000 个并发请求,服务器也无需创建 1000 个线程,仅通过少量线程(默认等于 CPU 核心数)即可高效处理。
2. Go 协程服务端(基于 net/http)
Go 语言天然支持协程(goroutine),其标准库的net/http包默认使用协程处理每个请求,开发效率极高。以下示例实现一个简单的 HTTP 服务,模拟 I/O 操作:
package main
import (
"fmt"
"net/http"
"time"
)
// 模拟I/O操作(如数据库查询、文件读取)
func simulateIO(userID string) map[string]interface{} {
// 模拟I/O等待(Go的time.Sleep不会阻塞线程,仅阻塞当前协程)
time.Sleep(100 * time.Millisecond)
return map[string]interface{}{
"user_id": userID,
"name": "Bob",
"age": 30,
}
}
// 处理HTTP请求
func handleRequest(w http.ResponseWriter, r *http.Request) {
userID := r.PathValue("userID")
// 调用模拟I/O函数(即使耗时,也仅阻塞当前协程)
userData := simulateIO(userID)
// 返回JSON响应
w.Header().Set("Content-Type", "application/json")
fmt.Fprintf(w, `{"user_id":"%s","name":"%s","age":%d}`,
userData["user_id"], userData["name"], userData["age"])
}
func main() {
// 注册路由
http.HandleFunc("/user/{userID}", handleRequest)
// 启动服务器(默认使用协程池处理请求)
fmt.Println("Goroutine HTTP server started on http://0.0.0.0:8080")
err := http.ListenAndServe(":8080", nil)
if err != nil {
fmt.Printf("Server error: %v\n", err)
}
}在 Go 的实现中,即使simulateIO函数有 100ms 的 I/O 等待,也不会阻塞操作系统线程 ——Go 的调度器会将阻塞的协程挂起,切换到其他就绪的协程执行。因此,该服务器可轻松处理数万并发请求,且开发难度远低于 I/O 多路复用模型。
四、优化法则与未来趋势
要打造高性能网络应用,不仅需要选择合适的 I/O 模型,还需遵循一定的优化法则,并关注技术发展趋势。
1. 网络 I/O 优化黄金法则
不同场景下,最优的 I/O 方案存在差异,以下是基于场景的优化建议:
应用场景 | 推荐方案 | 核心技术 / 工具 | 优化目标 |
|---|---|---|---|
高并发连接(如 API 网关) | I/O 多路复用 + 非阻塞 I/O | epoll(Linux)、kqueue(macOS)、Nginx | 单进程处理数万连接,低资源消耗 |
计算密集型(如数据分析) | 线程池 + 阻塞 I/O | Java ThreadPool、Go sync.Pool | 充分利用多核 CPU,避免 I/O 等待影响计算 |
混合型应用(如 Web 后端) | 协程 + 异步 I/O 客户端 | Go goroutine、Python asyncio + aiohttp | 兼顾开发效率与性能 |
超高性能场景(如高频交易) | 用户态协议栈 + 异步 I/O | DPDK、io_uring、XDP | 减少内核开销,降低延迟 |
分布式系统(如微服务) | 异步 RPC + 连接池 | gRPC(HTTP/2)、RSocket、Redis 连接池 | 减少连接建立开销,提升吞吐量 |
2. 未来技术趋势:突破内核瓶颈,拥抱可编程硬件
随着网络速率从 10Gbps 向 100Gbps 甚至 400Gbps 演进,操作系统内核成为新的性能瓶颈。未来,网络 I/O 技术将朝着 “内核旁路” 与 “可编程硬件” 方向发展:
- 内核旁路(Kernel Bypass)
传统网络 I/O 需经过 “网卡→内核→用户态” 的数据路径,内核处理占比可达 30%-50%。内核旁路技术(如 DPDK、Netmap)直接将网卡数据映射到用户态,绕过内核协议栈,使数据处理延迟从毫秒级降至微秒级。例如,DPDK 可实现每秒处理数百万个网络数据包,适用于高频交易、DDoS 防护等场景。
- QUIC 协议:TCP 的 “替代品”
QUIC(Quick UDP Internet Connections)是基于 UDP 的新型传输协议,由 Google 主导开发,已成为 HTTP/3 的底层协议。其核心优势包括:0-RTT 快速建立连接(首次连接 1-RTT,后续连接 0-RTT)、多路复用无队头阻塞(避免 TCP 的 “一个流阻塞所有流” 问题)、前向纠错(FEC)减少重传。未来,QUIC 有望逐步替代 TCP,成为主流网络传输协议。
- 可编程网络硬件
随着 SmartNIC(智能网卡)、FPGA(现场可编程门阵列)的普及,网络处理任务可直接在硬件中完成,无需 CPU 参与。例如,SmartNIC 可实现 TCP/IP 协议栈、数据加密 / 解密、流量过滤等功能,将 CPU 从繁重的网络处理中解放出来。此外,P4(Programming Protocol-independent Packet Processors)语言的出现,使开发者可通过代码定义数据包处理逻辑,进一步提升网络硬件的灵活性。
五、总结
最后简单总结一下,网络 I/O 阻塞的本质是 “等待数据到达”,而解决这一问题的核心在于 “如何高效利用等待时间”。从阻塞 I/O 到 I/O 多路复用,再到协程与异步 I/O,每一次技术演进都旨在平衡 “性能” 与 “开发效率”。对于开发者而言,我们要学会根据并发量、延迟要求、计算密集程度,选择合适的 I/O 模型。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号