放弃强一致性:弱化事务模型在高性能系统中的应用实战与思考
原创
放弃强一致性:弱化事务模型在高性能系统中的应用实战与思考
原创
不做虫子
发布于 2025-09-24 15:36:42
发布于 2025-09-24 15:36:42
在构建后台服务系统时,我们经常被灌输一个原则:数据一致性是神圣不可侵犯的。事务及其ACID特性(原子性、一致性、隔离性、持久性)是守护这一信条的利剑。然而,随着系统负载攀升、架构分布式演进,这把利剑变得越来越重,越来越拿不动,甚至可能成为性能的瓶颈。强一致性虽好,但其实现复杂,性能代价高昂,尤其是在分布式环境中。
那么,是否存在一种“退一步海阔天空”的智慧?答案是肯定的。本文将结合项目实战,探讨如何通过有意识地弱化事务模型(即放弃强一致性),在性能、复杂度和数据一致性之间做出权衡,从而构建更高性能、更易实现的系统。
一、为什么敢“放弃”?理解弱化事务的本质
弱化事务模型并非一种技术,而是一种设计思想。其核心在于承认:并非所有业务场景都要求瞬间的、100%的强一致性。
它通过对ACID特性中的一个或多个进行有目的的弱化,来换取其他方面的收益:
- 弱化持久性(D):不立即持久化状态,如使用内存状态。
- 弱化原子性(A):允许中间状态存在,通过补偿机制修复。
- 弱化隔离性(I):接受短暂的数据不一致,追求更高的并发性能。
- 弱化一致性(C):将“强一致性”降级为“最终一致性”。
这种思想完美契合了BASE理论,为高并发、高性能系统的设计打开了新世界的大门。
二、弱化事务的三种典型场景
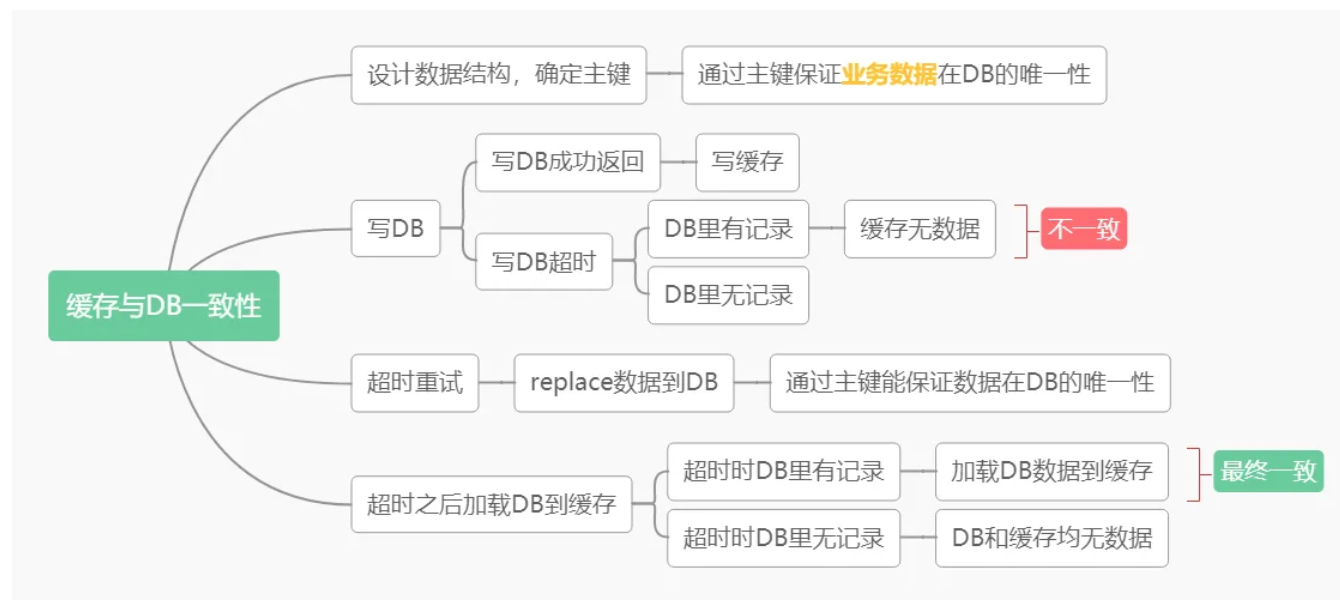
场景一:DB与缓存一致性 —— 用“最终一致”取代“强一致”
为了提升性能,引入缓存是常规操作,但这立刻带来了缓存与数据库(DB)的数据一致性问题。
传统困境:
- 先写DB再写缓存:若写缓存失败,则数据不一致。
- 先写缓存再写DB:若写DB失败,则数据不一致。
- 采用分布式事务(如两阶段提交2PC)?复杂度陡增,性能损耗大,且异常情况下仍可能不一致。
弱化实践: 在一个游戏地图项目中,处理玩家城数据时,我们放弃了复杂的分布式事务,采用了更轻量的方案:
- 保证DB唯一性:在玩家城表中,以玩家ID(xid)为主键,确保一个玩家在DB中只有一条记录。
- 写入时使用
REPLACE操作:当创建玩家城出现超时(不确定DB是否写入成功)时,客户端重试会直接执行REPLACE INTO语句。利用主键唯一性,DB内部会自动处理为插入或更新,保证最终只有一条正确记录。 - 缓存以DB为准:超时后,缓存中不保留不确定的数据。下次读取时,若缓存缺失,则从DB加载,此时加载到的就是最终一致的正确数据。
思考: 这个方案弱化了操作的原子性(两个写操作不是一个原子单元)和隔离性(中间状态可见)。但我们通过业务逻辑设计(主键唯一性)和重试机制,巧妙地实现了最终一致性,复杂度大大降低,性能显著提升。
场景二:基于共享内存 —— 牺牲持久性换取极致速度
在某些需要维护多步操作状态的流程中(如支付),如果每一步都读写数据库,性能开销巨大。
弱化实践: 在支付系统中,我们将一个支付请求的事务状态数据(如当前步骤、上下文信息)直接保存在共享内存中。
- 优势:进程内访问速度极快,即使进程重启,共享内存数据通常也可恢复,流程能继续执行。
- 风险:一旦服务器宕机,共享内存中的数据将丢失,导致流程中断,可能产生数据不一致。
思考: 这是对持久性(D) 的彻底弱化。它赌的是宕机是小概率事件。对于支付这类敏感业务,这听起来很冒险,但通常系统会在此基础上结合其他补偿机制(如下文的对账)。这种方案在实现上比完整的事务简单得多,在性能和实现效率上收益极高。
场景三:通过对账补偿 —— 主动修复的“安全网”
当我们已经弱化了事务模型,如何保证数据的长期正确性?对账就是那道最终的安全网。
弱化实践: 在同一个支付系统中,更新“支付账户表”和“支付发货回应表”时可能发生超时,导致两表数据不一致。
- 建立映射关系:支付账户表中的
last_order_id字段与支付发货回应表中的order_id字段对应。 - 触发对账:当重试请求到来时,系统会检查:根据
last_order_id去查询回应表,是否存在对应记录? - 执行补偿:如果查询结果为空,说明发货回应记录缺失,系统就在回应表中补插一条记录,从而修复不一致。
思考: 对账机制坦然接受了弱化事务模型可能带来的临时不一致,它不试图在过程中预防所有问题,而是事后异步地发现和修复问题。它将一致性保证从“实时强一致”弱化为“最终一致”,但通过自动化对账补偿,确保了结果的正确性,是实现最终一致性的核心手段。
三、总结与思考:学会权衡是架构师的必修课
通过以上三个实战场景,我们可以看到弱化事务模型不是简单的“偷懒”,而是一种充满智慧的权衡艺术。
方案 | 弱化的ACID特性 | 优势 | 风险 | 适用场景 |
|---|---|---|---|---|
DB缓存最终一致 | 原子性、隔离性 | 实现简单,性能高 | 短暂不一致 | 读多写少,可接受短暂旧数据 |
共享内存状态 | 持久性、原子性 | 性能极致,实现简单 | 宕机导致数据丢失 | 宕机概率低,或有其他补偿机制 |
对账补偿 | 强一致性(变为最终一致) | 保证长期正确,鲁棒性强 | 修复有延迟 | 所有重要且允许短暂不一致的流程 |
如何选择? 核心在于回答三个问题:
- 业务上能否接受短暂的不一致?能接受多久?
- 系统的瓶颈是性能还是数据绝对正确?
- 如果发生异常,是否有成本可接受的补救措施?
结论: 在追求高性能、高可用的现代系统架构中,盲目追求强一致性往往是过度设计。
敢于放弃强一致性,合理地运用弱化事务模型的思想,是架构师走向成熟的重要标志。 它要求我们深入理解业务,做出精准的权衡,用更灵活、更经济的方式解决实际问题。
记住,没有最好的方案,只有最适合业务场景的权衡。
毕竟架构就是权衡的艺术[手动狗头]。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号