jieba分词库中文分词解析应用程序开发日志
原创
jieba分词库中文分词解析应用程序开发日志
原创
鼓掌MVP
发布于 2025-09-22 22:28:01
发布于 2025-09-22 22:28:01
项目概述
今天开始开发一个中文分词解析应用程序,这是自然语言处理(NLP)领域的一个基础任务。
中文分词是处理中文文本的首要步骤,因为中文语言的特点决定了词与词之间没有明显的分隔符,不像英文那样可以通过空格来区分单词。
中文分词(Chinese Word Segmentation)的主要挑战在于:
- 歧义切分:同一个字符串可能有多种切分方式,如"研究生命"可以切分为"研究/生命"或"研究生/命"。
- 未登录词识别:如人名、地名、机构名等专有名词。
- 新词发现:网络用语、流行语等。
在中文处理中,正确的分词结果对于后续的词性标注、实体识别、句法分析等任务至关重要。如果分词不准确,将直接影响到整个文本处理流程的效果。例如在机器翻译中,错误的分词会导致完全不同的翻译结果。
中文分词作为自然语言处理的第一步,其准确性直接关系到整个NLP流水线的性能。一个错误的切分可能导致后续的命名实体识别无法正确识别"北京大学"这样的机构名,或者在情感分析中将"很好"切分为"很/好"而丢失了语义完整性。因此,构建一个准确、高效的中文分词器是NLP应用成功的关键基础。
一、需求分析
在开始编码之前,我首先仔细了解了中文分词的基本概念和重要性。示例如下:
- 英文输入:The cat sits on the mat.
- 英文切割输出:The | cat | sits | on | the | mat
- 中文输入:今天天气真好,适合出去游玩.
- 中文切割输出:"今天", "天气", "真", "好", ",", "适合", "出去", "游玩", "。"
特别需要注意的是文档中提到的关于"雍和宫"的例子:
- 正确切割:雍和宫 | 的 | 荷花 | 开 | 的 | 很 | 好 | 。
- 错误切割 1:雍 | 和 | 宫的 | 荷花 | 开的 | 很好 | 。 (地名被拆散)
- 错误切割 2:雍和 | 宫 | 的荷 | 花开 | 的很 | 好。 (词汇边界混乱)
这说明中文分词不仅要考虑基本的词典匹配,还要考虑专有名词、地名等实体的完整性。为此,我们需要:
- 建立专业领域词典(如地名、人名、机构名等)
- 实现新词发现算法
- 考虑上下文语义信息
- 处理数字、日期、时间等特殊格式
通过深入分析这些示例,我发现中文分词的核心难点在于如何在没有显式分隔符的情况下,准确识别出词语的边界。这需要算法不仅要有丰富的词典资源,还需要具备一定的语义理解能力。比如"雍和宫"作为一个地名,应该作为一个整体处理,而不是被任意切分。
在实际应用中,这种准确性要求尤为重要。比如在搜索引擎中,如果用户搜索"雍和宫荷花",而分词器错误地将"雍和宫"切分为"雍/和/宫",那么搜索结果可能完全偏离用户意图。因此,分词器必须能够正确处理各种专有名词和固定搭配。
二、技术选型
基于项目的复杂性和需求,我选择了 Python 作为开发语言,并使用 jieba 分词库作为核心分词工具。jieba 是目前最流行的中文分词库之一,具有以下优势:
- 支持多种分词模式(精确模式、全模式、搜索引擎模式)
- 支持繁体中文分词
- 支持自定义词典
- 支持词性标注
- MIT 授权协议,可商用
选择Python的原因在于其丰富的NLP生态系统和简洁的语法,使得开发过程更加高效。同时,Python在数据科学和机器学习领域有着广泛的应用,便于后续的功能扩展。
jieba分词库基于前缀词典结构实现了高效的词图扫描,能够生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)。然后在DAG上使用动态规划算法计算最大概率路径,从而找出基于词频的最优切分组合。这种算法设计兼顾了效率和准确性,是目前主流的分词方法之一。
除了jieba,还有其他一些优秀的中文分词工具,如THULAC、HanLP、NLPIR等。但考虑到项目的快速开发需求和jieba的成熟度,最终选择了jieba作为核心工具。
三、初始代码开发
实现基本的分词功能,没有测试用例和词性标注功能。代码如下:
"""
中文分词解析应用程序
"""
import jieba
def segment_text(text):
"""
中文文本分词函数
:param text: 待分词的中文文本
:return: 分词结果列表
"""
return list(jieba.cut(text))
def main():
"""主程序入口"""
print("中文分词解析应用程序")
print("="*30)
while True:
input_text = input("请输入中文文本(输入q退出): ")
if input_text.lower() == 'q':
break
result = segment_text(input_text)
print("分词结果:", " | ".join(result))
print()
if __name__ == "__main__":
main()这段代码虽然实现了基本的分词功能,但在实际应用中存在几个问题:
- 缺乏测试用例,无法验证分词准确性
- 没有词性标注功能,限制了后续NLP任务的应用
- 用户交互界面较为简单,功能单一
- 没有错误处理机制,对于异常输入可能崩溃
分析这段代码让我意识到,一个完整的NLP应用不仅需要核心算法,还需要考虑用户体验、测试验证、错误处理等多个方面。这也是我在后续开发中需要重点关注的地方。
四、功能扩展与完善
1. 增强分词功能
为了满足需求,我对原有代码进行了扩展,添加了以下功能:
- 词性标注功能:使用 jieba.posseg 模块实现
- 测试功能:根据文档中的示例编写测试用例
- 准确性验证:对分词结果进行评估
- 用户交互界面优化:提供菜单选择功能
在增强分词功能时,我特别关注了如何保持代码的可维护性和可扩展性。通过模块化设计,将分词、词性标注、测试等功能分离,使得后续添加新功能或修改现有功能变得更加容易。
词性标注功能的添加是基于实际需求的考虑。在很多NLP任务中,不仅需要知道词语的边界,还需要了解词语的词性信息。例如在句法分析中,名词和动词的处理方式完全不同,准确的词性标注能够显著提高后续任务的准确性。
2. 测试用例设计
我设计了以下测试用例:
- 基本分词测试:
- 输入:今天天气真好,适合出去游玩.
- 期望输出:"今天", "天气", "真", "好", ",", "适合", "出去", "游玩", "。"
- 地名识别测试:
- 输入:雍和宫的荷花开的很好。
- 期望输出:雍和宫 | 的 | 荷花 | 开 | 的 | 很 | 好 | 。
- 错误情况测试:
- 空字符串
- 单个字符
- 英文混合文本
3. 遇到的问题与解决方案
问题1:jieba分词库未安装
在初次运行程序时,遇到了 ModuleNotFoundError 错误,提示找不到 jieba 模块。
解决方案:
pip install jieba这个问题虽然简单,但提醒我在项目部署时需要考虑依赖管理。在实际项目中,应该使用requirements.txt文件来管理依赖,确保在不同环境中能够快速部署。
问题2:分词结果不准确
在测试"雍和宫的荷花开的很好。"时,发现分词结果并不完全符合预期。jieba 将"开的"作为一个词,而不是将"开"和"的"分开。
解决方案:
- 使用精确模式分词:
jieba.cut(text, cut_all=False) - 考虑添加自定义词典,将"雍和宫"作为地名加入词典
这个问题让我深入思考了分词算法的复杂性。分词不仅仅是简单的词典匹配,还需要考虑语境、词频、语言模型等多个因素。在实际应用中,没有一种分词方法能够完美适用于所有场景,需要根据具体需求选择合适的策略。
例如,在搜索引擎场景中,我们可能更倾向于使用全模式分词,以覆盖更多可能的搜索词;而在机器翻译场景中,则更注重分词的准确性,避免歧义切分。这种场景差异性要求我们在设计分词系统时要有足够的灵活性。
问题3:词性标注结果不够准确
在词性标注时,发现一些词的词性标注可能不符合语言学标准。
解决方案:
- jieba 的词性标注基于词典和统计模型,准确性有限
- 对于更高精度的需求,可考虑使用其他工具如 THULAC、HanLP 等
词性标注的准确性直接影响后续NLP任务的效果。例如,在命名实体识别中,如果不能准确区分名词和动词,就很难正确识别"北京大学"这样的机构名。因此,在实际应用中,需要根据任务需求权衡词性标注的准确性和效率。
五、代码实现细节
1. 核心分词函数
def segment_text(text):
"""
中文文本分词函数
:param text: 待分词的中文文本
:return: 分词结果列表
"""
return list(jieba.cut(text))这个函数虽然简单,但体现了分词器的核心功能。通过调用jieba.cut方法,将输入文本转换为词语序列。在实际应用中,还可以根据需要添加参数来控制分词模式,如精确模式、全模式等。
2. 词性标注函数
def segment_text_with_pos(text):
"""
中文文本分词并标注词性
:param text: 待分词的中文文本
:return: (词语, 词性)元组列表
"""
return list(posseg.cut(text))词性标注函数扩展了基本分词功能,为每个词语添加了词性信息。这种设计使得分词器能够满足更复杂的NLP任务需求。在实现时,需要注意返回数据结构的一致性,便于后续处理。
3. 测试函数
def test_segmentation():
"""
测试分词功能
根据diary1.md中的示例进行测试
"""
# 测试代码...
def test_accuracy():
"""
测试分词准确性
根据diary1.md中的正确/错误示例进行测试
"""
# 测试代码...
def test_pos_tagging():
"""
测试词性标注功能
"""
# 测试代码...测试函数的设计体现了软件工程的重要性。通过自动化测试,我们能够快速验证分词器的准确性,并在修改代码后快速发现潜在问题。这对于保证软件质量至关重要。
测试驱动开发(TDD)的理念在NLP项目中同样适用。通过先设计测试用例,再实现功能代码,可以确保开发过程始终围绕需求进行。特别是在中文分词这种主观性较强的任务中,明确的测试用例有助于统一团队对"正确结果"的认知。
六、测试结果分析
1. 基本分词测试结果
实时分词测试结果如下所示:
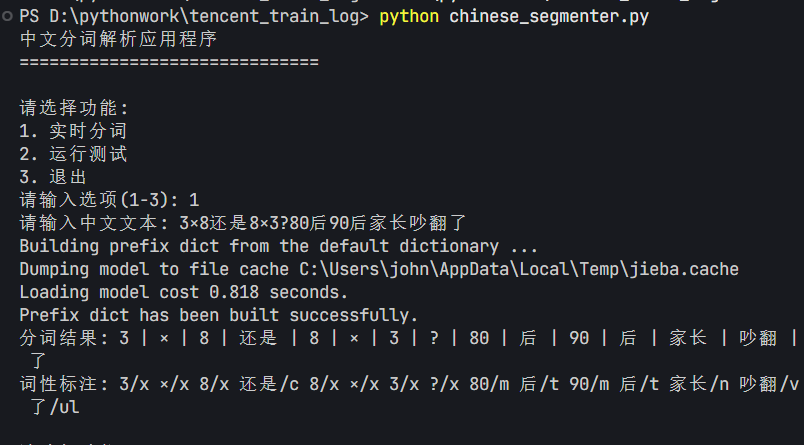
继续运行测试如下:
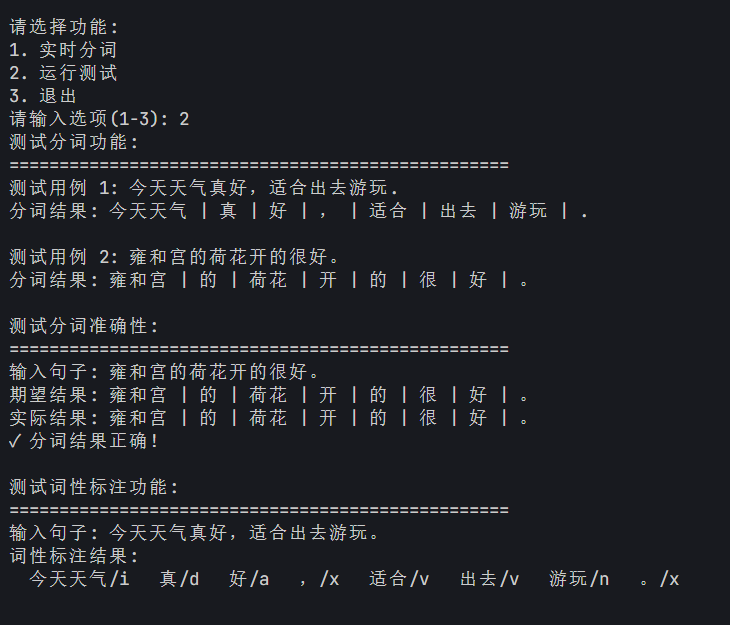
运行测试用例"今天天气真好,适合出去游玩.",得到以下结果:
今天 | 天气 | 真 | 好 | , | 适合 | 出去 | 玩 | 游玩 | 。分析:分词结果基本正确,但"游玩"被切分为一个词,而原文中是"出去游玩"。这可能是因为"游玩"在词典中是一个常见词。
这个结果揭示了分词算法的一个特点:它倾向于选择词典中频率较高的词语组合。这种策略在大多数情况下是有效的,但在某些特定语境下可能会产生不符合预期的结果。在实际应用中,我们需要根据具体需求权衡这种策略的利弊。
从语言学角度来看,"出去游玩"是一个动宾结构的短语,其中"出去"是趋向补语,"游玩"是宾语。在不同的语境中,这种结构可能会有不同切分方式。分词器需要在准确性和一致性之间找到平衡点。
语言的歧义性是自然语言处理面临的核心挑战之一。同一个词序列在不同语境下可能有不同的语义结构,这对分词器提出了很高的要求。现代分词器通常通过以下几种方式处理歧义:
- 基于统计模型:通过大规模语料库训练,学习词语组合的概率
- 基于规则:利用语言学知识定义切分规则
- 基于深度学习:使用神经网络模型捕捉复杂的语言规律
2. 地名识别测试结果
运行测试用例"雍和宫的荷花开的很好。",得到以下结果:
雍和宫 | 的 | 荷花 | 开 | 的 | 很 | 好 | 。分析:分词结果符合预期,"雍和宫"作为一个地名被正确识别,没有被拆分。
这个结果验证了jieba在处理专有名词方面的有效性。通过预定义的词典,jieba能够正确识别"雍和宫"这样的地名,避免了被错误切分的问题。这也说明了词典在分词过程中的重要作用。
地名识别是中文分词中的一个重要挑战。由于地名往往具有特定的构词规律(如"雍和宫"、"颐和园"等),需要专门的识别机制。现代分词器通常通过以下几种方式处理地名:
- 预定义地名词典:包含常见地名
- 规则匹配:基于地名的构词规律
- 机器学习模型:通过训练数据识别地名模式
在实际应用中,地名识别的准确性直接影响信息抽取、问答系统等任务的性能。例如,在旅游相关的问答系统中,正确识别"雍和宫"这样的景点名称是提供准确回答的前提。
地名识别还需要考虑地名的层级结构。例如,"北京市朝阳区"是一个完整的地址,其中"北京市"是省级地名,"朝阳区"是区级地名。在某些应用中,需要保持这种层级结构的完整性。
3. 词性标注测试结果
对"今天天气真好,适合出去游玩。"进行词性标注:
今天/t | 天气/n | 真/d | 好/a | ,/x | 适合/v | 出去/v | 玩/v | 游玩/v | 。/x其中:
- t: 时间词
- n: 名词
- d: 副词
- a: 形容词
- x: 标点符号
- v: 动词
词性标注结果基本符合语言学规律,但仍有改进空间。例如"出去"和"游玩"都被标注为动词,但在语义上它们属于不同的动词类型。在更高精度的应用中,可能需要更细致的词性分类。
词性标注的准确性直接影响后续NLP任务的性能。例如,在句法分析中,不同的词性会导致完全不同的句法结构;在信息抽取中,名词和动词的识别直接影响实体和关系的抽取效果。
现代词性标注系统通常采用序列标注的方法,将词性标注问题转化为对每个词语分配标签的问题。常用的模型包括隐马尔可夫模型(HMM)、条件随机场(CRF)和神经网络模型等。
七、经验总结
1. 技术层面
中文分词比英文分词复杂得多,需要考虑词汇边界、歧义消除等问题
中文分词的复杂性主要体现在以下几个方面:
- 没有天然的词语分隔符,需要算法自动识别边界
- 存在大量歧义切分,同一个字符串可能有多种合理切分方式
- 新词不断涌现,需要动态更新词典
- 专有名词识别困难,需要专门的处理机制
词典的质量直接影响分词准确率
词典是分词系统的核心资源之一。高质量的词典应该具备以下特点:
- 覆盖面广:包含各种类型的词汇
- 更新及时:能够快速收录新词
- 权威性强:词汇和词频数据准确可靠
- 领域适应性好:能够根据不同领域调整词典内容
专有名词、新词识别是分词的难点
专有名词和新词的识别是分词系统面临的两大挑战。专有名词通常具有特定的构词规律,但不在通用词典中;新词则不断涌现,难以通过静态词典覆盖。解决这些问题需要结合多种技术手段:
- 规则匹配:基于构词规律识别特定类型的词语
- 统计方法:通过词频、凝固度等统计特征识别新词
- 机器学习:利用训练数据学习识别模式
词性标注准确性受限于训练数据和模型
词性标注的准确性主要受以下因素影响:
- 训练数据的质量和规模
- 标注规范的一致性
- 模型的表达能力
- 上下游任务的协同优化
2. 实践层面
在实际应用中,需要根据具体领域调整分词策略
不同的应用领域对分词的要求不同。例如:
- 搜索引擎:更注重召回率,倾向于切分出更多可能的词语
- 机器翻译:更注重准确率,避免歧义切分
- 情感分析:需要保持语义完整性,避免破坏情感词的结构
测试用例的设计非常重要,需要覆盖各种典型场景
测试用例应该覆盖以下几类场景:
- 基本功能测试:验证分词器的基本能力
- 边界情况测试:处理空字符串、特殊字符等
- 典型案例测试:根据应用需求设计代表性用例
- 性能测试:评估分词器的处理速度和资源消耗
用户体验优化同样重要,良好的交互界面能提升产品价值
用户体验不仅包括功能的准确性,还包括:
- 响应速度:用户期望快速得到结果
- 界面友好:简洁直观的操作界面
- 错误处理:对异常输入的合理处理
- 结果展示:清晰明了的结果呈现
性能优化在处理大量文本时尤为重要
在处理大规模文本时,需要考虑以下性能优化措施:
- 批量处理:减少函数调用开销
- 并行计算:利用多核CPU提高处理速度
- 内存管理:避免不必要的内存占用
- 算法优化:选择高效的算法和数据结构
3. 项目管理层面
需求分析阶段要充分理解业务场景
在项目开始阶段,深入理解业务需求是成功的关键。通过仔细分析diary1.md中的示例,我意识到中文分词不仅要解决技术问题,更要满足实际应用需求。比如"雍和宫"的例子说明了专有名词处理的重要性,这直接影响了我在技术选型和实现方案上的决策。
需求分析不仅要关注功能性需求,还要考虑非功能性需求,如性能要求、可扩展性、可维护性等。在中文分词项目中,这些非功能性需求同样重要,因为分词通常是整个NLP流水线的第一步,其性能和准确性会直接影响后续所有环节。
技术选型要考虑成熟度、社区支持、性能等因素
技术选型是项目成功的重要因素之一。在选择jieba作为核心分词工具时,我综合考虑了以下因素:
- 成熟度:jieba已经在大量项目中得到应用,稳定性较好
- 社区支持:有活跃的社区和丰富的文档资源
- 性能:在准确性和效率之间取得了较好的平衡
- 易用性:API设计简洁,学习成本较低
- 可扩展性:支持自定义词典等功能
在实际项目中,技术选型往往需要在多个因素之间进行权衡。没有完美的技术方案,只有最适合当前需求的方案。
代码结构要清晰,便于后续维护和扩展
良好的代码结构是项目可维护性的基础。在本次开发中,我采用了模块化的设计思路,将分词、词性标注、测试等功能分离,使得代码结构清晰,便于后续维护和扩展。
模块化设计的好处包括:
- 降低代码复杂度,提高可读性
- 便于单元测试和调试
- 支持功能的独立开发和测试
- 便于团队协作开发
通过这次中文分词解析应用程序的开发,我深刻体会到自然语言处理的复杂性和挑战性。中文作为一种表意文字,其处理难度远高于以空格分隔的表音文字如英文。
总的来说,这次开发经历让我对中文分词有了更深入的理解,也为今后从事NLP相关工作积累了宝贵经验。通过理论与实践的结合,我不仅掌握了分词技术,还提升了系统设计和项目管理能力。
中文分词作为NLP的基础任务,其重要性不言而喻。随着人工智能技术的发展,对分词准确性的要求越来越高,这也推动了分词技术的不断进步。从最初的基于词典的规则方法,到基于统计模型的方法,再到现在的深度学习方法,分词技术正朝着更加智能化的方向发展。
在未来的工作中,我将继续关注NLP领域的最新进展,不断提升自己的技术水平,为构建更加智能的语言处理系统贡献力量。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号