[数据分析]中断时间序列分析:当无法设置对照组的解决方案
原创

I. 引言
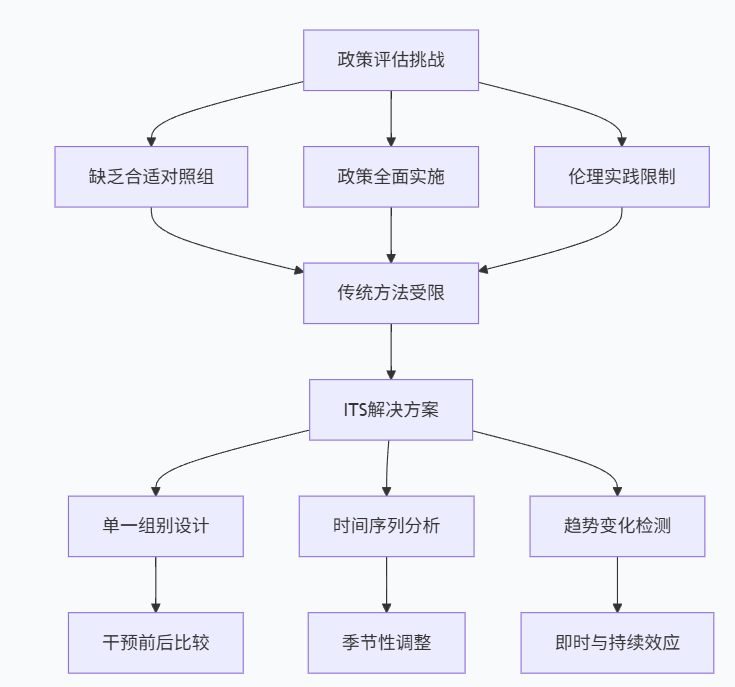
在政策评估和干预效果分析中,研究人员常常面临一个根本性挑战:当无法设置合适的对照组时,我们如何评估政策或干预的因果效应? 这一难题在公共卫生、教育政策、环境规制等领域尤为突出,因为在这些领域中,政策往往是全国性或地区性统一实施,难以找到不受影响的对照组。
中断时间序列分析(Interrupted Time Series, ITS)正是为解决这一难题而生的强大工具。作为一种准实验研究方法,ITS通过分析干预前后结果变量时间序列趋势的变化,来识别干预的因果效应。当随机对照试验不可行或不符合伦理要求时,ITS提供了严谨的替代方案。
现实中的评估困境
考虑以下真实场景:
- 全国性烟草控制立法实施后,如何评估其对吸烟率的影响?
- 新冠疫情封锁政策对经济活动的因果效应如何识别?
- 新药品上市后,如何监测其长期安全性和有效性?
在这些情境中,传统的随机对照试验或双重差分法往往不适用。ITS方法通过利用干预前后时间序列数据的内在结构,为因果推断提供了可行路径。
ITS方法的核心优势
ITS方法具有几个显著优势:
- 不需要对照组:仅依靠干预组的时间序列数据
- 利用历史数据:将干预前的趋势作为反事实的基准
- 检测多种效应:不仅能识别即时效应,还能分析趋势变化
- 适用性广泛:可用于评估各种类型的干预措施
II. 中断时间序列分析的理论基础
ITS方法的基本原理
中断时间序列分析的核心思想是通过比较干预前后时间序列的趋势变化来识别因果效应。其基本逻辑是:如果没有干预,时间序列将继续遵循干预前的趋势模式。因此,观察到的与这一预期模式的偏离可以被归因于干预效应。
ITS分析通常检测两种类型的干预效应:
- 水平变化(Level Change):干预导致的即时效应,表现为时间序列在干预点处的跳跃
- 斜率变化(Slope Change):干预导致的持续效应,表现为时间序列趋势的变化
统计模型设定
标准的ITS模型可以表示为:
Yₜ = β₀ + β₁Tₜ + β₂Xₜ + β₃XₜTₜ + εₜ
其中:
- Yₜ是时间点t的结果变量
- Tₜ是时间变量(如月份、季度等)
- Xₜ是干预虚拟变量(干预后=1,干预前=0)
- XₜTₜ是时间与干预的交互项
- εₜ是误差项
模型中关键系数的解释:
- β₁:干预前的趋势(斜率)
- β₂:干预导致的即时效应(水平变化)
- β₃:干预导致的趋势变化(斜率变化)
方法假设与有效性条件
ITS方法的有效性依赖于几个关键假设:
假设类型 | 具体内容 | 检验方法 |
|---|---|---|
趋势连续性 | 干预前趋势在没有干预时会继续 | 干预前趋势稳定性检验 |
无同时期干扰 | 没有其他事件与干预同时发生 | 历史数据分析、敏感性分析 |
数据完整性 | 时间序列完整且测量一致 | 数据质量评估 |
模型设定正确 | 函数形式能准确捕捉趋势 | 模型诊断检验 |
ITS与相关方法的比较
ITS方法在因果推断方法谱系中占有独特位置:
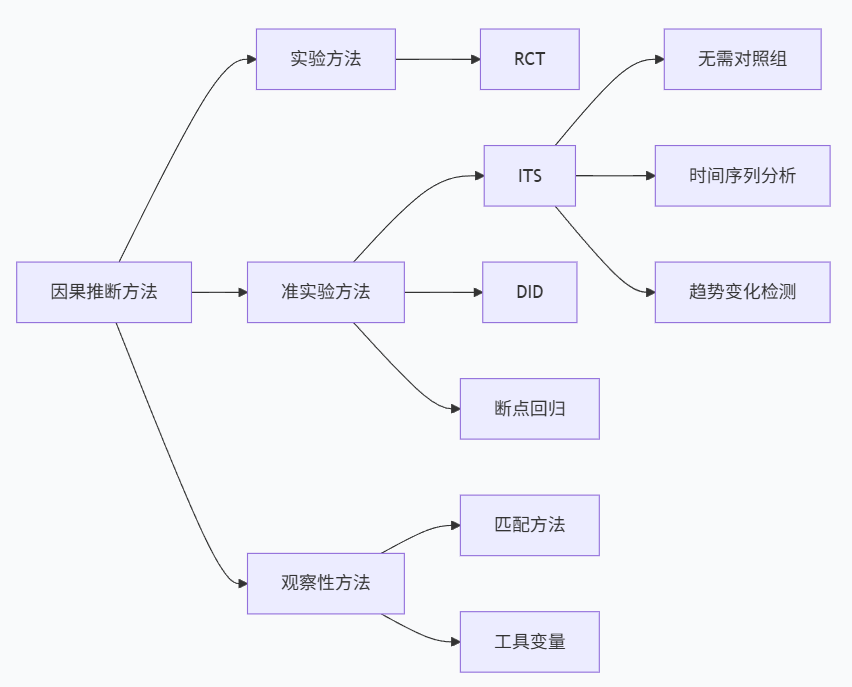
与双重差分法(DID)相比,ITS具有独特的优势和局限:
- 优势:不依赖对照组,适用于全面实施的干预
- 局限:更易受同时期其他事件的影响,需要更强的假设
III. 实例背景与数据生成
研究背景:公共卫生政策评估
假设我们要评估一项于2020年3月实施的全国性公共卫生政策(如口罩强制令)对呼吸道传染病发病率的影响。由于政策是全国性实施,我们无法找到合适的对照组,因此ITS成为理想的评估方法。
我们将模拟一个包含72个月(6年)的月度传染病发病率时间序列,其中前36个月为干预前期,后36个月为干预后期。
数据生成过程
以下Python代码生成符合ITS分析要求的模拟数据:
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.stattools import acf, adfuller
import warnings
warnings.filterwarnings('ignore')
# 设置随机种子确保结果可重现
np.random.seed(2023)
def generate_its_data(n_months=72, intervention_month=36,
base_rate=100, trend_pre=0.1, trend_post=0.05,
level_change=-8, seasonal_amplitude=5,
noise_sd=2):
"""
生成ITS分析所需的模拟时间序列数据
参数:
n_months: 总月数
intervention_month: 干预开始月份
base_rate: 基础发病率
trend_pre: 干预前趋势(每月变化)
trend_post: 干预后趋势(每月变化)
level_change: 干预导致的水平变化
seasonal_amplitude: 季节性振幅
noise_sd: 随机噪声标准差
"""
# 创建时间索引
dates = pd.date_range(start='2015-01-01', periods=n_months, freq='M')
# 初始化结果数组
infection_rate = np.zeros(n_months)
for t in range(n_months):
# 基础水平
rate = base_rate
# 时间趋势
if t < intervention_month:
rate += trend_pre * t # 干预前趋势
else:
rate += trend_pre * intervention_month # 干预前累积趋势
rate += trend_post * (t - intervention_month) # 干预后趋势
# 干预效应
if t >= intervention_month:
rate += level_change # 水平变化
# 季节性成分(12个月周期)
seasonal = seasonal_amplitude * np.sin(2 * np.pi * t / 12)
rate += seasonal
# 随机噪声
noise = np.random.normal(0, noise_sd)
rate += noise
# 确保非负
infection_rate[t] = max(rate, 0)
# 创建数据框
df = pd.DataFrame({
'date': dates,
'month': range(1, n_months + 1),
'time': range(n_months),
'intervention': [1 if t >= intervention_month else 0 for t in range(n_months)],
'infection_rate': infection_rate,
'post_intervention_time': [max(0, t - intervention_month) for t in range(n_months)]
})
return df
# 生成数据
its_data = generate_its_data(n_months=72, intervention_month=36,
base_rate=100, trend_pre=0.1, trend_post=0.05,
level_change=-8, seasonal_amplitude=5, noise_sd=2)
print("生成的数据集前10行:")
print(its_data.head(10))
print(f"\n数据集形状: {its_data.shape}")数据探索与可视化
在建立正式模型前,我们需要对时间序列数据进行初步探索,了解其基本特征:
# 数据基本描述
print("描述性统计:")
print(its_data['infection_rate'].describe())
# 干预前后对比
pre_intervention = its_data[its_data['intervention'] == 0]
post_intervention = its_data[its_data['intervention'] == 1]
print(f"\n干预前平均发病率: {pre_intervention['infection_rate'].mean():.2f}")
print(f"干预后平均发病率: {post_intervention['infection_rate'].mean():.2f}")
print(f"变化幅度: {post_intervention['infection_rate'].mean() - pre_intervention['infection_rate'].mean():.2f}")
# 时间序列图
def plot_its_data(df, intervention_month):
"""绘制ITS数据时间序列图"""
plt.figure(figsize=(14, 8))
# 绘制时间序列
plt.plot(df['date'], df['infection_rate'], 'o-', linewidth=1, markersize=4,
label='月度发病率')
# 标记干预点
intervention_date = df[df['time'] == intervention_month]['date'].iloc[0]
plt.axvline(x=intervention_date, color='red', linestyle='--',
linewidth=2, label='政策实施', alpha=0.7)
# 添加趋势线
# 干预前趋势线
pre_trend = sm.OLS(df[df['time'] < intervention_month]['infection_rate'],
sm.add_constant(df[df['time'] < intervention_month]['time'])).fit()
pre_times = df[df['time'] < intervention_month]['time']
plt.plot(df[df['time'] < intervention_month]['date'],
pre_trend.predict(sm.add_constant(pre_times)),
'b--', alpha=0.7, label='干预前趋势')
# 干预后趋势线(如果有足够数据)
if len(df[df['time'] >= intervention_month]) > 1:
post_trend = sm.OLS(df[df['time'] >= intervention_month]['infection_rate'],
sm.add_constant(df[df['time'] >= intervention_month]['time'])).fit()
post_times = df[df['time'] >= intervention_month]['time']
plt.plot(df[df['time'] >= intervention_month]['date'],
post_trend.predict(sm.add_constant(post_times)),
'g--', alpha=0.7, label='干预后趋势')
plt.xlabel('时间', fontsize=12)
plt.ylabel('发病率(每10万人)', fontsize=12)
plt.title('传染病发病率时间序列与政策干预', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(True, alpha=0.3)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 绘制时间序列图
plot_its_data(its_data, 36)季节性分解
时间序列数据通常包含趋势、季节性和随机成分,分解这些成分有助于我们理解数据的内在结构:
# 季节性分解
def seasonal_decomposition(df, variable='infection_rate', period=12):
"""进行季节性分解"""
# 确保数据按时间排序
df_sorted = df.sort_values('date').reset_index(drop=True)
# 创建时间序列
ts = df_sorted[variable]
# 季节性分解
decomposition = seasonal_decompose(ts, model='additive', period=period)
# 绘制分解结果
fig, axes = plt.subplots(4, 1, figsize=(14, 10))
decomposition.observed.plot(ax=axes[0], title='原始序列', legend=False)
decomposition.trend.plot(ax=axes[1], title='趋势成分', legend=False)
decomposition.seasonal.plot(ax=axes[2], title='季节性成分', legend=False)
decomposition.resid.plot(ax=axes[3], title='残差成分', legend=False)
# 标记干预点
for ax in axes:
ax.axvline(x=36, color='red', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
return decomposition
# 执行季节性分解
decomposition = seasonal_decomposition(its_data)
IV. 基础中断时间序列模型
模型设定与估计
现在我们将建立正式的中断时间序列模型。基础ITS模型包含时间趋势、干预虚拟变量及其交互项:
# 基础ITS模型
def basic_its_model(df, outcome_var='infection_rate'):
"""估计基础ITS模型"""
# 准备变量
X = df[['time', 'intervention', 'post_intervention_time']].copy()
X['intervention_time'] = X['intervention'] * X['time']
X = sm.add_constant(X)
y = df[outcome_var]
# 估计模型
model = sm.OLS(y, X).fit()
return model, X, y
# 估计基础ITS模型
basic_model, X_basic, y_basic = basic_its_model(its_data)
print("="*60)
print("基础ITS模型结果")
print("="*60)
print(basic_model.summary())
# 更灵活的模型设定
def flexible_its_model(df, outcome_var='infection_rate'):
"""更灵活的ITS模型设定"""
# 创建模型矩阵
df_model = df.copy()
# 基础项
df_model['const'] = 1
df_model['time_since_intervention'] = df_model['post_intervention_time']
# 分段线性趋势
df_model['trend_pre'] = df_model['time']
df_model['trend_post'] = np.where(df_model['intervention'] == 1,
df_model['time'] - 36, 0)
# 模型公式
X_flex = df_model[['const', 'trend_pre', 'intervention', 'trend_post']]
y_flex = df_model[outcome_var]
# 估计模型
flex_model = sm.OLS(y_flex, X_flex).fit()
return flex_model, X_flex, y_flex
# 估计灵活ITS模型
flex_model, X_flex, y_flex = flexible_its_model(its_data)
print("\n" + "="*60)
print("灵活ITS模型结果")
print("="*60)
print(flex_model.summary())模型结果解释
ITS模型系数的解释需要特别关注其因果含义:
模型系数 | 解释 | 在我们的例子中的含义 |
|---|---|---|
时间趋势 | 干预前的自然趋势 | 每月发病率变化幅度 |
干预虚拟变量 | 干预的即时效应 | 政策实施后发病率的立即变化 |
时间×干预交互项 | 干预对趋势的影响 | 政策改变发病率趋势的程度 |
# 模型结果提取与解释
def interpret_its_model(model, model_type='basic'):
"""解释ITS模型结果"""
params = model.params
conf_int = model.conf_int()
print(f"\n{model_type.upper()} ITS模型结果解释:")
print("-" * 40)
if model_type == 'basic':
# 基础模型解释
print(f"干预前趋势: {params['time']:.3f} (每月变化)")
print(f" 95%置信区间: [{conf_int.loc['time', 0]:.3f}, {conf_int.loc['time', 1]:.3f}]")
print(f"即时水平变化: {params['intervention']:.3f}")
print(f" 95%置信区间: [{conf_int.loc['intervention', 0]:.3f}, {conf_int.loc['intervention', 1]:.3f}]")
if 'intervention_time' in params:
print(f"趋势变化: {params['intervention_time']:.3f}")
print(f" 95%置信区间: [{conf_int.loc['intervention_time', 0]:.3f}, {conf_int.loc['intervention_time', 1]:.3f}]")
elif model_type == 'flexible':
# 灵活模型解释
print(f"干预前趋势: {params['trend_pre']:.3f} (每月变化)")
print(f" 95%置信区间: [{conf_int.loc['trend_pre', 0]:.3f}, {conf_int.loc['trend_pre', 1]:.3f}]")
print(f"即时水平变化: {params['intervention']:.3f}")
print(f" 95%置信区间: [{conf_int.loc['intervention', 0]:.3f}, {conf_int.loc['intervention', 1]:.3f}]")
print(f"干预后趋势变化: {params['trend_post']:.3f} (相对于干预前趋势的变化)")
print(f" 95%置信区间: [{conf_int.loc['trend_post', 0]:.3f}, {conf_int.loc['trend_post', 1]:.3f}]")
# 统计显著性判断
pvalues = model.pvalues
significance = {0.01: '***', 0.05: '**', 0.1: '*', 1: ''}
print("\n统计显著性:")
for param in params.index:
if param != 'const':
sig_level = next(level for level in sorted(significance.keys()) if pvalues[param] <= level)
print(f"{param}: {significance[sig_level]} (p = {pvalues[param]:.4f})")
# 解释模型结果
interpret_its_model(basic_model, 'basic')
interpret_its_model(flex_model, 'flexible')模型预测与反事实分析
ITS分析的核心是构建反事实场景:如果没有干预,结果变量会如何变化?
# 反事实预测
def counterfactual_analysis(model, df, model_type='basic'):
"""进行反事实分析"""
df_cf = df.copy()
# 创建反事实场景(无干预)
df_cf['intervention_cf'] = 0
df_cf['post_intervention_time_cf'] = 0
if model_type == 'basic':
df_cf['intervention_time_cf'] = 0
X_cf = df_cf[['time', 'intervention_cf', 'post_intervention_time']]
X_cf['intervention_time'] = df_cf['intervention_cf'] * df_cf['time']
X_cf = sm.add_constant(X_cf)
else:
df_cf['trend_post_cf'] = 0
X_cf = df_cf[['const', 'trend_pre', 'intervention_cf', 'trend_post_cf']]
# 预测反事实值
counterfactual = model.predict(X_cf)
return counterfactual
# 进行反事实分析
counterfactual_basic = counterfactual_analysis(basic_model, its_data, 'basic')
counterfactual_flex = counterfactual_analysis(flex_model, its_data, 'flexible')
# 可视化实际值与反事实值
def plot_counterfactual(df, actual, counterfactual, model_name):
"""绘制实际值与反事实值对比图"""
plt.figure(figsize=(14, 6))
# 实际值
plt.plot(df['date'], actual, 'o-', linewidth=1.5, markersize=4,
label='实际观测值', color='blue')
# 反事实值
plt.plot(df['date'], counterfactual, '--', linewidth=1.5,
label='反事实(无干预)', color='red', alpha=0.7)
# 标记干预点
intervention_date = df[df['time'] == 36]['date'].iloc[0]
plt.axvline(x=intervention_date, color='green', linestyle='--',
linewidth=2, label='政策实施', alpha=0.7)
# 填充干预效应区域
post_intervention = df['time'] >= 36
plt.fill_between(df['date'], actual, counterfactual, where=post_intervention,
alpha=0.3, color='gray', label='干预效应')
plt.xlabel('时间', fontsize=12)
plt.ylabel('发病率(每10万人)', fontsize=12)
plt.title(f'ITS分析: 实际值与反事实对比 ({model_name})', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(True, alpha=0.3)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 绘制对比图
plot_counterfactual(its_data, its_data['infection_rate'], counterfactual_basic, '基础模型')
plot_counterfactual(its_data, its_data['infection_rate'], counterfactual_flex, '灵活模型')
# 计算干预效应大小
def calculate_intervention_effect(actual, counterfactual, intervention_point):
"""计算干预效应大小"""
post_actual = actual[intervention_point:]
post_counterfactual = counterfactual[intervention_point:]
# 平均效应
mean_effect = np.mean(post_actual - post_counterfactual)
# 累积效应
cumulative_effect = np.sum(post_actual - post_counterfactual)
# 效应大小(标准化)
pre_std = np.std(actual[:intervention_point])
standardized_effect = mean_effect / pre_std
effect_measures = {
'平均效应': mean_effect,
'累积效应': cumulative_effect,
'标准化效应': standardized_effect,
'相对变化(%)': (mean_effect / np.mean(counterfactual[intervention_point:])) * 100
}
return effect_measures
# 计算干预效应
effect_basic = calculate_intervention_effect(its_data['infection_rate'].values,
counterfactual_basic, 36)
effect_flex = calculate_intervention_effect(its_data['infection_rate'].values,
counterfactual_flex, 36)
print("干预效应评估:")
print("基础模型:")
for measure, value in effect_basic.items():
print(f" {measure}: {value:.2f}")
print("\n灵活模型:")
for measure, value in effect_flex.items():
print(f" {measure}: {value:.2f}")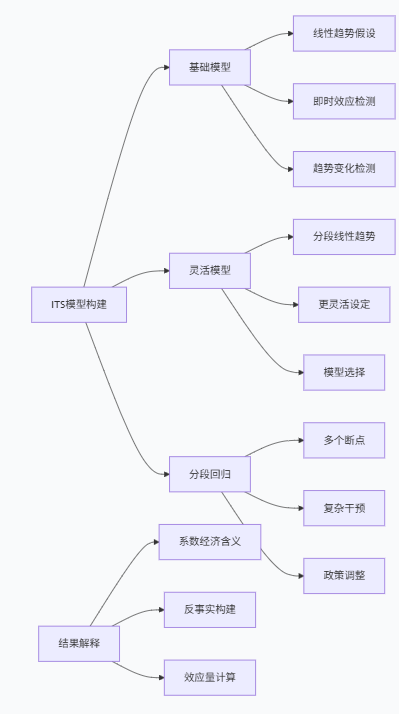
V. 模型诊断与假设检验
自相关检验与处理
时间序列数据常常存在自相关问题,这会影响标准误的估计和统计推断的有效性:
# 自相关检验
def autocorrelation_test(model, lags=12):
"""检验模型残差的自相关"""
residuals = model.resid
# Durbin-Watson检验
dw_stat = sm.stats.durbin_watson(residuals)
print(f"Durbin-Watson统计量: {dw_stat:.3f}")
if dw_stat < 1.5:
print(" 存在正自相关")
elif dw_stat > 2.5:
print(" 存在负自相关")
else:
print(" 无明显自相关")
# Ljung-Box检验
lb_test = sm.stats.acorr_ljungbox(residuals, lags=[lags], return_df=True)
print(f"Ljung-Box检验 (滞后{lags}期):")
print(f" 统计量: {lb_test['lb_stat'].iloc[0]:.3f}, p值: {lb_test['lb_pvalue'].iloc[0]:.4f}")
# 自相关函数图
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# ACF图
sm.graphics.tsa.plot_acf(residuals, lags=lags, ax=axes[0], alpha=0.05)
axes[0].set_title('残差自相关函数(ACF)')
# PACF图
sm.graphics.tsa.plot_pacf(residuals, lags=lags, ax=axes[1], alpha=0.05)
axes[1].set_title('残差偏自相关函数(PACF)')
plt.tight_layout()
plt.show()
return dw_stat, lb_test
# 自相关检验
print("基础模型自相关检验:")
dw_basic, lb_basic = autocorrelation_test(basic_model)
print("\n灵活模型自相关检验:")
dw_flex, lb_flex = autocorrelation_test(flex_model)自相关校正模型
当存在自相关时,我们需要使用能够处理自相关的估计方法:
# 自相关校正模型
def autocorrelation_corrected_model(df, outcome_var='infection_rate', method='newey'):
"""估计自相关校正的ITS模型"""
# 准备数据
df_model = df.copy()
df_model['const'] = 1
df_model['trend_pre'] = df_model['time']
df_model['trend_post'] = np.where(df_model['intervention'] == 1,
df_model['time'] - 36, 0)
X = df_model[['const', 'trend_pre', 'intervention', 'trend_post']]
y = df_model[outcome_var]
if method == 'newey':
# Newey-West标准误(异方差和自相关稳健)
model = sm.OLS(y, X).fit(cov_type='HAC', cov_kwds={'maxlags': 4})
elif method == 'cochrane-orcutt':
# Cochrane-Orcutt校正
try:
from statsmodels.regression.linear_model import GLS
# 简化的自相关校正(实际应用可能需要更复杂的迭代过程)
rho = np.corrcoef(model.resid[1:], model.resid[:-1])[0, 1]
# 这里使用简化版本,实际应用应使用完整的Cochrane-Orcutt程序
model = sm.OLS(y, X).fit()
except:
model = sm.OLS(y, X).fit()
else:
# 普通OLS
model = sm.OLS(y, X).fit()
return model
# 估计自相关校正模型
newey_model = autocorrelation_corrected_model(its_data, method='newey')
print("="*60)
print("Newey-West标准误校正模型")
print("="*60)
print(newey_model.summary())
# 比较不同标准误
def compare_standard_errors(models, model_names):
"""比较不同标准误下的结果"""
comparison = pd.DataFrame()
for i, model in enumerate(models):
params = model.params
se_regular = model.bse
pvalues = model.pvalues
# 尝试获取HAC标准误(如果可用)
try:
se_hac = model.HC0_se
except:
se_hac = se_regular
for param in params.index:
if param != 'const':
comparison.loc[param, f'{model_names[i]}_coef'] = params[param]
comparison.loc[param, f'{model_names[i]}_se'] = se_regular[param]
comparison.loc[param, f'{model_names[i]}_p'] = pvalues[param]
return comparison
# 比较标准误
models_to_compare = [flex_model, newey_model]
model_names = ['标准OLS', 'Newey-West']
se_comparison = compare_standard_errors(models_to_compare, model_names)
print("\n标准误比较:")
print(se_comparison)平稳性检验
时间序列的平稳性是许多时间序列模型的重要前提:
# 平稳性检验
def stationarity_tests(df, variable='infection_rate'):
"""进行平稳性检验"""
series = df[variable].values
# ADF检验(Augmented Dickey-Fuller)
adf_result = adfuller(series, autolag='AIC')
print("平稳性检验结果:")
print(f"ADF统计量: {adf_result[0]:.6f}")
print(f"p值: {adf_result[1]:.6f}")
print(f"滞后阶数: {adf_result[2]}")
print(f"观测值数量: {adf_result[3]}")
# 临界值
print("临界值:")
for key, value in adf_result[4].items():
print(f" {key}: {value:.3f}")
# 结果判断
if adf_result[1] <= 0.05:
print("结论: 序列是平稳的(拒绝单位根假设)")
else:
print("结论: 序列非平稳(不能拒绝单位根假设)")
return adf_result
# 平稳性检验
adf_result = stationarity_tests(its_data)异常值检测与处理
异常值可能对ITS分析结果产生重大影响,需要谨慎处理:
# 异常值检测
def outlier_detection(model, df, threshold=2.5):
"""检测和处理异常值"""
residuals = model.resid
standardized_residuals = (residuals - np.mean(residuals)) / np.std(residuals)
# 识别异常值
outliers = np.abs(standardized_residuals) > threshold
outlier_indices = np.where(outliers)[0]
print(f"检测到 {len(outlier_indices)} 个异常值(阈值: {threshold}标准差)")
if len(outlier_indices) > 0:
print("异常值位置:")
for idx in outlier_indices:
print(f" 时间点 {idx}: 标准化残差 = {standardized_residuals[idx]:.3f}")
# 创建异常值虚拟变量
df_outlier = df.copy()
for idx in outlier_indices:
df_outlier[f'outlier_{idx}'] = 0
df_outlier.loc[idx, f'outlier_{idx}'] = 1
# 重新估计包含异常值控制的模型
outlier_vars = [col for col in df_outlier.columns if 'outlier_' in col]
if len(outlier_vars) > 0:
# 准备模型矩阵
df_outlier['const'] = 1
df_outlier['trend_pre'] = df_outlier['time']
df_outlier['trend_post'] = np.where(df_outlier['intervention'] == 1,
df_outlier['time'] - 36, 0)
X_vars = ['const', 'trend_pre', 'intervention', 'trend_post'] + outlier_vars
X_outlier = df_outlier[X_vars]
y_outlier = df_outlier['infection_rate']
# 估计模型
outlier_model = sm.OLS(y_outlier, X_outlier).fit()
print("\n包含异常值控制的模型结果:")
print(outlier_model.summary())
return outlier_model, outlier_indices
else:
print("未检测到异常值,返回原模型")
return model, []
# 异常值检测与处理
outlier_model, outlier_indices = outlier_detection(flex_model, its_data)
VI. 高级ITS模型与扩展
季节性调整模型
对于具有明显季节性的时间序列,我们需要在ITS模型中明确控制季节性因素:
# 季节性调整ITS模型
def seasonal_its_model(df, outcome_var='infection_rate', period=12):
"""季节性调整的ITS模型"""
df_seasonal = df.copy()
# 创建月度虚拟变量(季节性控制)
months = pd.get_dummies(df_seasonal['date'].dt.month, prefix='month')
df_seasonal = pd.concat([df_seasonal, months], axis=1)
# 准备模型变量
df_seasonal['const'] = 1
df_seasonal['trend_pre'] = df_seasonal['time']
df_seasonal['trend_post'] = np.where(df_seasonal['intervention'] == 1,
df_seasonal['time'] - 36, 0)
# 模型矩阵(排除一个月份作为基准)
month_vars = [col for col in df_seasonal.columns if 'month_' in col]
if len(month_vars) > 0:
month_vars = month_vars[:-1] # 排除基准月份
X_vars = ['const', 'trend_pre', 'intervention', 'trend_post'] + month_vars
X_seasonal = df_seasonal[X_vars]
y_seasonal = df_seasonal[outcome_var]
# 估计模型
seasonal_model = sm.OLS(y_seasonal, X_seasonal).fit()
return seasonal_model, month_vars
# 估计季节性调整模型
seasonal_model, month_vars = seasonal_its_model(its_data)
print("="*60)
print("季节性调整ITS模型")
print("="*60)
print(seasonal_model.summary())
# 比较有无季节性控制的模型
def compare_seasonal_models(non_seasonal_model, seasonal_model):
"""比较有无季节性控制的模型"""
comparison = pd.DataFrame()
# 共同变量
common_vars = set(non_seasonal_model.params.index) & set(seasonal_model.params.index)
common_vars = [v for v in common_vars if v != 'const']
for var in common_vars:
comparison.loc[var, '无季节性控制'] = f"{non_seasonal_model.params[var]:.3f} ({non_seasonal_model.pvalues[var]:.3f})"
comparison.loc[var, '有季节性控制'] = f"{seasonal_model.params[var]:.3f} ({seasonal_model.pvalues[var]:.3f})"
# 模型拟合优度
comparison.loc['R-squared', '无季节性控制'] = f"{non_seasonal_model.rsquared:.3f}"
comparison.loc['R-squared', '有季节性控制'] = f"{seasonal_model.rsquared:.3f}"
comparison.loc['Adj R-squared', '无季节性控制'] = f"{non_seasonal_model.rsquared_adj:.3f}"
comparison.loc['Adj R-squared', '有季节性控制'] = f"{seasonal_model.rsquared_adj:.3f}"
print("模型比较: 有无季节性控制")
print(comparison)
# 比较模型
compare_seasonal_models(flex_model, seasonal_model)ARIMA ITS模型
对于复杂的时间序列模式,ARIMA模型可以提供更灵活的建模框架:
# ARIMA ITS模型
def arima_its_model(df, outcome_var='infection_rate'):
"""ARIMA ITS模型"""
try:
from statsmodels.tsa.arima.model import ARIMA
# 准备数据
y = df[outcome_var]
# 创建干预变量
intervention = df['intervention'].values
time_since_intervention = df['post_intervention_time'].values
# 简单ARIMA模型(实际应用中需要更复杂的选择过程)
# 这里使用自动选择方法(简化版)
best_aic = np.inf
best_order = None
best_model = None
# 简单的参数搜索(实际应用应使用更系统的方法)
for p in range(3):
for d in range(2):
for q in range(3):
try:
# 包含外生变量(干预)
exog = np.column_stack([intervention, time_since_intervention])
model = ARIMA(y, order=(p, d, q), exog=exog).fit()
if model.aic < best_aic:
best_aic = model.aic
best_order = (p, d, q)
best_model = model
except:
continue
if best_model is not None:
print(f"最佳ARIMA模型: ARIMA{best_order}")
print(f"AIC: {best_aic:.2f}")
return best_model, best_order
else:
print("ARIMA模型估计失败,返回None")
return None, None
except ImportError:
print("statsmodels版本可能不支持ARIMA,跳过ARIMA分析")
return None, None
# 估计ARIMA ITS模型
arima_model, arima_order = arima_its_model(its_data)
if arima_model is not None:
print("\nARIMA ITS模型结果:")
print(arima_model.summary())多变量ITS模型
当有其他协变量可能影响结果变量时,我们可以扩展ITS模型以包含这些控制变量:
# 多变量ITS模型
def multivariate_its_model(df, outcome_var='infection_rate'):
"""多变量ITS模型(包含控制变量)"""
# 模拟一些控制变量
np.random.seed(42)
df_multi = df.copy()
# 生成模拟控制变量(在实际应用中使用真实数据)
df_multi['temperature'] = np.random.normal(20, 5, len(df)) # 温度
df_multi['precipitation'] = np.random.exponential(10, len(df)) # 降水量
df_multi['population_density'] = np.random.normal(1000, 200, len(df)) # 人口密度
# 准备模型矩阵
df_multi['const'] = 1
df_multi['trend_pre'] = df_multi['time']
df_multi['trend_post'] = np.where(df_multi['intervention'] == 1,
df_multi['time'] - 36, 0)
# 模型变量
control_vars = ['temperature', 'precipitation', 'population_density']
X_vars = ['const', 'trend_pre', 'intervention', 'trend_post'] + control_vars
X_multi = df_multi[X_vars]
y_multi = df_multi[outcome_var]
# 估计模型
multi_model = sm.OLS(y_multi, X_multi).fit()
return multi_model, control_vars
# 估计多变量ITS模型
multi_model, control_vars = multivariate_its_model(its_data)
print("="*60)
print("多变量ITS模型")
print("="*60)
print(multi_model.summary())
# 模型比较
def model_comparison(models, model_names, criteria=['rsquared_adj', 'aic', 'bic']):
"""比较不同模型的拟合优度"""
comparison = pd.DataFrame(index=criteria, columns=model_names)
for i, model in enumerate(models):
for criterion in criteria:
if hasattr(model, criterion):
value = getattr(model, criterion)
comparison.loc[criterion, model_names[i]] = f"{value:.3f}"
else:
comparison.loc[criterion, model_names[i]] = "N/A"
print("模型比较:")
print(comparison)
# 比较所有模型
all_models = [basic_model, flex_model, seasonal_model, multi_model]
model_names = ['基础模型', '灵活模型', '季节性调整', '多变量模型']
if arima_model is not None:
all_models.append(arima_model)
model_names.append('ARIMA模型')
model_comparison(all_models, model_names)分段回归与多断点ITS
当干预有多个阶段或多个政策时间点时,我们需要更复杂的分段回归模型:
# 多断点ITS模型
def multiple_breakpoint_its(df, outcome_var='infection_rate'):
"""多断点ITS模型(模拟两个政策阶段)"""
df_multi_break = df.copy()
# 模拟第二个政策干预点(第54个月)
second_intervention = 54
df_multi_break['intervention2'] = [1 if t >= second_intervention else 0 for t in df_multi_break['time']]
df_multi_break['post_intervention_time2'] = [max(0, t - second_intervention) for t in df_multi_break['time']]
# 准备模型矩阵
df_multi_break['const'] = 1
df_multi_break['trend_pre'] = df_multi_break['time']
# 第一段干预后趋势
df_multi_break['trend_post1'] = np.where((df_multi_break['time'] >= 36) &
(df_multi_break['time'] < second_intervention),
df_multi_break['time'] - 36, 0)
# 第二段干预后趋势
df_multi_break['trend_post2'] = np.where(df_multi_break['time'] >= second_intervention,
df_multi_break['time'] - second_intervention, 0)
# 干预水平变化
df_multi_break['level_change1'] = df_multi_break['intervention']
df_multi_break['level_change2'] = df_multi_break['intervention2']
# 模型变量
X_vars = ['const', 'trend_pre', 'level_change1', 'trend_post1', 'level_change2', 'trend_post2']
X_multi_break = df_multi_break[X_vars]
y_multi_break = df_multi_break[outcome_var]
# 估计模型
multi_break_model = sm.OLS(y_multi_break, X_multi_break).fit()
return multi_break_model, second_intervention
# 估计多断点模型
multi_break_model, second_intervention = multiple_breakpoint_its(its_data)
print("="*60)
print("多断点ITS模型")
print("="*60)
print(multi_break_model.summary())
# 可视化多断点分析
def plot_multiple_breakpoints(df, model, first_break, second_break):
"""可视化多断点ITS分析"""
# 预测值
df_plot = df.copy()
df_plot['const'] = 1
df_plot['trend_pre'] = df_plot['time']
df_plot['level_change1'] = df_plot['intervention']
df_plot['trend_post1'] = np.where((df_plot['time'] >= first_break) &
(df_plot['time'] < second_break),
df_plot['time'] - first_break, 0)
df_plot['level_change2'] = df_plot['intervention2']
df_plot['trend_post2'] = np.where(df_plot['time'] >= second_break,
df_plot['time'] - second_break, 0)
X_plot = df_plot[['const', 'trend_pre', 'level_change1', 'trend_post1', 'level_change2', 'trend_post2']]
df_plot['predicted'] = model.predict(X_plot)
# 绘图
plt.figure(figsize=(14, 6))
plt.plot(df_plot['date'], df_plot['infection_rate'], 'o-', linewidth=1, markersize=3,
label='实际观测值', alpha=0.7)
plt.plot(df_plot['date'], df_plot['predicted'], '-', linewidth=2,
label='模型拟合值')
# 标记干预点
first_date = df_plot[df_plot['time'] == first_break]['date'].iloc[0]
second_date = df_plot[df_plot['time'] == second_break]['date'].iloc[0]
plt.axvline(x=first_date, color='red', linestyle='--', alpha=0.7, label='第一次干预')
plt.axvline(x=second_date, color='green', linestyle='--', alpha=0.7, label='第二次干预')
plt.xlabel('时间', fontsize=12)
plt.ylabel('发病率(每10万人)', fontsize=12)
plt.title('多断点ITS分析', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(True, alpha=0.3)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 绘制多断点分析图
plot_multiple_breakpoints(its_data, multi_break_model, 36, second_intervention)
VII. 稳健性检验与敏感性分析
安慰剂检验
安慰剂检验是评估ITS结果稳健性的重要方法,通过虚构干预时间点来检验是否会出现虚假的"干预效应":
# 安慰剂检验
def placebo_test(df, outcome_var='infection_rate', n_simulations=1000):
"""进行安慰剂检验"""
placebo_effects_level = []
placebo_effects_trend = []
# 可能的安慰剂干预点范围(避免边界效应)
min_time = 12 # 最早干预点
max_time = len(df) - 12 # 最晚干预点
for i in range(n_simulations):
# 随机选择安慰剂干预点
placebo_point = np.random.randint(min_time, max_time)
# 创建安慰剂干预变量
df_placebo = df.copy()
df_placebo['intervention_placebo'] = [1 if t >= placebo_point else 0
for t in df_placebo['time']]
df_placebo['post_intervention_time_placebo'] = [max(0, t - placebo_point)
for t in df_placebo['time']]
# 估计安慰剂模型
df_placebo['const'] = 1
df_placebo['trend_pre'] = df_placebo['time']
df_placebo['trend_post_placebo'] = np.where(df_placebo['intervention_placebo'] == 1,
df_placebo['time'] - placebo_point, 0)
X_vars = ['const', 'trend_pre', 'intervention_placebo', 'trend_post_placebo']
X_placebo = df_placebo[X_vars]
y_placebo = df_placebo[outcome_var]
try:
placebo_model = sm.OLS(y_placebo, X_placebo).fit()
# 记录安慰剂效应
if 'intervention_placebo' in placebo_model.params:
placebo_effects_level.append(placebo_model.params['intervention_placebo'])
if 'trend_post_placebo' in placebo_model.params:
placebo_effects_trend.append(placebo_model.params['trend_post_placebo'])
except:
continue
return placebo_effects_level, placebo_effects_trend
# 执行安慰剂检验
placebo_level, placebo_trend = placebo_test(its_data, n_simulations=500)
# 真实效应
real_level_effect = flex_model.params['intervention']
real_trend_effect = flex_model.params['trend_post']
print(f"真实水平效应: {real_level_effect:.3f}")
print(f"真实趋势效应: {real_trend_effect:.3f}")
# 可视化安慰剂检验结果
def plot_placebo_test(placebo_effects, real_effect, effect_type='水平'):
"""绘制安慰剂检验结果"""
plt.figure(figsize=(10, 6))
# 安慰剂效应分布
plt.hist(placebo_effects, bins=30, alpha=0.7, color='lightblue',
edgecolor='black', label='安慰剂效应分布')
# 真实效应
plt.axvline(x=real_effect, color='red', linestyle='--', linewidth=2,
label=f'真实{effect_type}效应')
# 零效应线
plt.axvline(x=0, color='black', linestyle='-', alpha=0.5)
plt.xlabel(f'{effect_type}效应大小', fontsize=12)
plt.ylabel('频数', fontsize=12)
plt.title(f'安慰剂检验: {effect_type}效应', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 计算p值
if real_effect > 0:
p_value = np.mean(np.array(placebo_effects) > real_effect)
else:
p_value = np.mean(np.array(placebo_effects) < real_effect)
print(f"{effect_type}效应安慰剂检验p值: {p_value:.4f}")
return p_value
# 绘制安慰剂检验图
p_level = plot_placebo_test(placebo_level, real_level_effect, '水平')
p_trend = plot_placebo_test(placebo_trend, real_trend_effect, '趋势')引导不确定性区间
使用引导法(Bootstrap)来估计模型参数的不确定性区间:
# 引导法估计
def bootstrap_its(df, outcome_var='infection_rate', n_bootstrap=1000):
"""使用引导法估计不确定性"""
bootstrap_level_effects = []
bootstrap_trend_effects = []
for i in range(n_bootstrap):
# 有放回抽样
bootstrap_indices = np.random.choice(len(df), size=len(df), replace=True)
df_bootstrap = df.iloc[bootstrap_indices].reset_index(drop=True)
# 估计模型
df_bootstrap['const'] = 1
df_bootstrap['trend_pre'] = df_bootstrap['time']
df_bootstrap['trend_post'] = np.where(df_bootstrap['intervention'] == 1,
df_bootstrap['time'] - 36, 0)
X_vars = ['const', 'trend_pre', 'intervention', 'trend_post']
X_bootstrap = df_bootstrap[X_vars]
y_bootstrap = df_bootstrap[outcome_var]
try:
bootstrap_model = sm.OLS(y_bootstrap, X_bootstrap).fit()
if 'intervention' in bootstrap_model.params:
bootstrap_level_effects.append(bootstrap_model.params['intervention'])
if 'trend_post' in bootstrap_model.params:
bootstrap_trend_effects.append(bootstrap_model.params['trend_post'])
except:
continue
return bootstrap_level_effects, bootstrap_trend_effects
# 执行引导法
bootstrap_level, bootstrap_trend = bootstrap_its(its_data, n_bootstrap=1000)
# 计算引导置信区间
def bootstrap_ci(bootstrap_effects, alpha=0.05):
"""计算引导置信区间"""
lower = np.percentile(bootstrap_effects, 100 * alpha / 2)
upper = np.percentile(bootstrap_effects, 100 * (1 - alpha / 2))
return lower, upper
ci_level = bootstrap_ci(bootstrap_level)
ci_trend = bootstrap_ci(bootstrap_trend)
print(f"水平效应的95%引导置信区间: [{ci_level[0]:.3f}, {ci_level[1]:.3f}]")
print(f"趋势效应的95%引导置信区间: [{ci_trend[0]:.3f}, {ci_trend[1]:.3f}]")
# 比较与标准置信区间
print(f"水平效应的标准95%置信区间: [{flex_model.conf_int().loc['intervention', 0]:.3f}, {flex_model.conf_int().loc['intervention', 1]:.3f}]")
print(f"趋势效应的标准95%置信区间: [{flex_model.conf_int().loc['trend_post', 0]:.3f}, {flex_model.conf_int().loc['trend_post', 1]:.3f}]")模型设定敏感性分析
通过改变模型设定来检验结果的稳健性:
# 模型设定敏感性分析
def sensitivity_analysis(df, outcome_var='infection_rate'):
"""模型设定敏感性分析"""
sensitivity_results = []
# 不同的模型设定
specifications = [
{'name': '基础线性', 'pre_trend': 'linear', 'post_trend': 'linear', 'seasonal': False},
{'name': '二次趋势', 'pre_trend': 'quadratic', 'post_trend': 'linear', 'seasonal': False},
{'name': '季节性控制', 'pre_trend': 'linear', 'post_trend': 'linear', 'seasonal': True},
{'name': '不同滞后结构', 'pre_trend': 'linear', 'post_trend': 'linear', 'seasonal': False, 'lags': 1},
]
for spec in specifications:
df_sens = df.copy()
# 准备模型矩阵
df_sens['const'] = 1
# 干预前趋势
if spec['pre_trend'] == 'linear':
df_sens['trend_pre'] = df_sens['time']
elif spec['pre_trend'] == 'quadratic':
df_sens['trend_pre'] = df_sens['time']
df_sens['trend_pre_sq'] = df_sens['time'] ** 2
# 干预后趋势
df_sens['trend_post'] = np.where(df_sens['intervention'] == 1,
df_sens['time'] - 36, 0)
# 季节性控制
if spec['seasonal']:
months = pd.get_dummies(df_sens['date'].dt.month, prefix='month')
df_sens = pd.concat([df_sens, months], axis=1)
month_vars = [col for col in df_sens.columns if 'month_' in col][:-1]
X_vars = ['const', 'trend_pre', 'intervention', 'trend_post'] + month_vars
else:
X_vars = ['const', 'trend_pre', 'intervention', 'trend_post']
# 二次趋势项
if spec['pre_trend'] == 'quadratic':
X_vars.append('trend_pre_sq')
X_sens = df_sens[X_vars]
y_sens = df_sens[outcome_var]
# 估计模型
sens_model = sm.OLS(y_sens, X_sens).fit()
# 提取关键系数
level_effect = sens_model.params['intervention'] if 'intervention' in sens_model.params else np.nan
trend_effect = sens_model.params['trend_post'] if 'trend_post' in sens_model.params else np.nan
sensitivity_results.append({
'specification': spec['name'],
'level_effect': level_effect,
'trend_effect': trend_effect,
'rsquared': sens_model.rsquared,
'n_params': len(sens_model.params)
})
return pd.DataFrame(sensitivity_results)
# 执行敏感性分析
sensitivity_df = sensitivity_analysis(its_data)
print("模型设定敏感性分析:")
print(sensitivity_df)干预时间敏感性分析
检验结果对干预时间点选择的敏感性:
# 干预时间敏感性分析
def intervention_time_sensitivity(df, outcome_var='infection_rate', window=6):
"""干预时间敏感性分析"""
sensitivity_times = []
# 测试不同的干预时间点(真实点前后)
true_intervention = 36
test_points = range(true_intervention - window, true_intervention + window + 1)
for point in test_points:
if point <= 12 or point >= len(df) - 12: # 避免边界点
continue
df_time = df.copy()
# 创建新的干预变量
df_time['intervention_test'] = [1 if t >= point else 0 for t in df_time['time']]
df_time['post_intervention_time_test'] = [max(0, t - point) for t in df_time['time']]
# 准备模型
df_time['const'] = 1
df_time['trend_pre'] = df_time['time']
df_time['trend_post_test'] = np.where(df_time['intervention_test'] == 1,
df_time['time'] - point, 0)
X_vars = ['const', 'trend_pre', 'intervention_test', 'trend_post_test']
X_time = df_time[X_vars]
y_time = df_time[outcome_var]
# 估计模型
time_model = sm.OLS(y_time, X_time).fit()
# 提取效应
level_effect = time_model.params['intervention_test'] if 'intervention_test' in time_model.params else np.nan
trend_effect = time_model.params['trend_post_test'] if 'trend_post_test' in time_model.params else np.nan
sensitivity_times.append({
'intervention_point': point,
'level_effect': level_effect,
'trend_effect': trend_effect,
'deviation_from_true': point - true_intervention
})
return pd.DataFrame(sensitivity_times)
# 执行干预时间敏感性分析
time_sensitivity_df = intervention_time_sensitivity(its_data)
print("干预时间敏感性分析:")
print(time_sensitivity_df)
# 可视化干预时间敏感性
plt.figure(figsize=(10, 6))
plt.plot(time_sensitivity_df['intervention_point'], time_sensitivity_df['level_effect'],
'o-', label='水平效应', linewidth=2)
plt.axvline(x=36, color='red', linestyle='--', label='真实干预点', alpha=0.7)
plt.xlabel('假设干预时间点', fontsize=12)
plt.ylabel('水平效应估计值', fontsize=12)
plt.title('干预时间敏感性分析', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
VIII. 实践指南与常见陷阱
ITS分析的最佳实践
基于理论分析和实证经验,我们总结出ITS分析的最佳实践指南:
# ITS分析检查清单
def its_checklist():
"""ITS分析检查清单"""
checklist = {
'研究设计': [
'明确干预时间点和性质',
'确保干预外生性或论证其合理性',
'确定合适的结果变量和测量频率',
'选择足够长的时间序列(干预前后各有多点)'
],
'数据准备': [
'检查数据完整性和一致性',
'处理缺失值问题',
'验证时间序列的平稳性',
'识别和处理异常值'
],
'模型设定': [
'进行充分的探索性数据分析',
'检验并处理自相关问题',
'控制季节性因素',
'考虑函数形式(线性/非线性)'
],
'稳健性检验': [
'进行安慰剂检验',
'改变模型设定检验敏感性',
'使用引导法估计不确定性',
'检验干预时间敏感性'
],
'结果解释': [
'区分统计学显著和实际意义',
'考虑同时期其他事件的干扰',
'讨论效应的可能机制',
'明确分析局限性'
]
}
return checklist
# 显示检查清单
checklist = its_checklist()
print("="*60)
print("ITS分析检查清单")
print("="*60)
for category, items in checklist.items():
print(f"\n{category}:")
for i, item in enumerate(items, 1):
print(f" {i}. {item}")
# 常见陷阱检测
def common_pitfalls_detection(df, model):
"""检测常见ITS陷阱"""
pitfalls = {}
# 1. 自相关问题
dw_stat = sm.stats.durbin_watson(model.resid)
pitfalls['自相关'] = {
'DW统计量': f"{dw_stat:.3f}",
'问题': '存在自相关' if dw_stat < 1.5 or dw_stat > 2.5 else '无严重自相关'
}
# 2. 异常值影响
standardized_residuals = (model.resid - np.mean(model.resid)) / np.std(model.resid)
n_outliers = np.sum(np.abs(standardized_residuals) > 2.5)
pitfalls['异常值'] = {
'异常值数量': n_outliers,
'占比': f"{n_outliers/len(df)*100:.1f}%"
}
# 3. 模型设定错误
# 检查二次项是否显著(线性假设)
df_test = df.copy()
df_test['time_sq'] = df_test['time'] ** 2
X_test = sm.add_constant(df_test[['time', 'time_sq']])
y_test = df_test['infection_rate']
test_model = sm.OLS(y_test, X_test).fit()
if 'time_sq' in test_model.params:
sq_pvalue = test_model.pvalues['time_sq']
pitfalls['函数形式'] = {
'二次项p值': f"{sq_pvalue:.4f}",
'建议': '考虑非线性趋势' if sq_pvalue < 0.05 else '线性趋势可能合适'
}
# 4. 季节性未控制
# 简单的季节性检验(月份间方差)
monthly_means = df.groupby(df['date'].dt.month)['infection_rate'].mean()
seasonal_variation = np.std(monthly_means) / np.mean(monthly_means)
pitfalls['季节性'] = {
'季节变异系数': f"{seasonal_variation:.3f}",
'建议': '控制季节性' if seasonal_variation > 0.1 else '季节性可能不显著'
}
return pitfalls
# 检测常见陷阱
pitfalls = common_pitfalls_detection(its_data, flex_model)
print("\n" + "="*60)
print("常见陷阱检测结果")
print("="*60)
for pitfall, results in pitfalls.items():
print(f"{pitfall}:")
for key, value in results.items():
print(f" {key}: {value}")样本量要求与统计功效
ITS分析对样本量有特定要求,特别是干预前后的时间点数量:
# 统计功效分析
def power_analysis_its(effect_sizes=[0.2, 0.5, 0.8], alpha=0.05, n_pre=36, n_post=36):
"""ITS分析的统计功效分析"""
from statsmodels.stats.power import TTestIndPower
power_analyzer = TTestIndPower()
# 简化功效分析(基于两样本t检验近似)
results = []
for effect_size in effect_sizes:
# 总样本量(前后期观察值)
total_n = n_pre + n_post
# 功效计算
power = power_analyzer.solve_power(
effect_size=effect_size,
nobs1=total_n/2, # 简化假设
alpha=alpha,
power=None
)
results.append({
'效应大小': effect_size,
'干预前观测值': n_pre,
'干预后观测值': n_post,
'统计功效': f"{power:.3f}",
'建议': '充足' if power >= 0.8 else '不足'
})
return pd.DataFrame(results)
# 执行功效分析
power_df = power_analysis_its()
print("\n统计功效分析:")
print(power_df)
# 样本量建议
def sample_size_recommendation():
"""ITS分析样本量建议"""
recommendations = {
'时间点数量': [
'干预前后至少各12个时间点(基本要求)',
'干预前后各24-36个时间点(推荐)',
'干预前后各50+个时间点(理想情况)'
],
'数据频率': [
'高频数据(如每日)需要更复杂的模型',
'月度数据是最常见的选择',
'低频数据(如年度)需要更长时间跨度'
],
'特殊情况': [
'强季节性数据需要更多整周期观测',
'多断点分析需要每个阶段有足够观测值',
'小效应检测需要更大样本量'
]
}
return recommendations
# 显示样本量建议
recommendations = sample_size_recommendation()
print("\n样本量建议:")
for category, items in recommendations.items():
print(f"\n{category}:")
for i, item in enumerate(items, 1):
print(f" {i}. {item}")结果报告标准
为了确保ITS分析的可重复性和透明度,我们建议遵循以下报告标准:
报告项目 | 必要内容 | 示例 |
|---|---|---|
研究设计 | 干预描述、时间点、研究背景 | "评估2020年3月实施的口罩政策对发病率的影响" |
数据来源 | 数据来源、时间范围、测量方式 | "2015年1月至2020年12月全国月度发病率数据" |
模型设定 | 模型公式、假设检验、控制变量 | "分段线性模型控制季节性固定效应" |
主要结果 | 效应大小、置信区间、统计显著性 | "水平变化-8.2单位(95%CI: -10.1至-6.3)" |
稳健性检验 | 安慰剂检验、敏感性分析结果 | "安慰剂检验p=0.012,结果稳健" |
局限性 | 研究局限性、潜在偏倚来源 | "无法完全排除同时期其他事件的影响" |

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号