Whisper v0.2 免费开源语音转文字软件工具下载安装使用全指南(附安装教程)
原创
Whisper v0.2 免费开源语音转文字软件工具下载安装使用全指南(附安装教程)
原创
小姚姚
修改于 2025-09-23 13:41:24
修改于 2025-09-23 13:41:24
一、Whisper软件核心介绍
Whisper v0.2 是一款免费开源的本地语音转文字工具,基于通用语音识别模型开发,在海量音频数据集上训练完成,具备多任务处理能力 —— 支持多语言语音识别、语音翻译及语言识别,能轻松满足录音转文字需求。
该工具基于 Faster Whisper 模型优化,即便在普通 CPU 设备上,也能实现高效、精准的语音转文字效果,无需高性能硬件即可流畅使用。
Whisper语音转文字软件安装包下载:https://pan.quark.cn/s/3da25fd67c91
二、Whisper v0.2 详细安装步骤
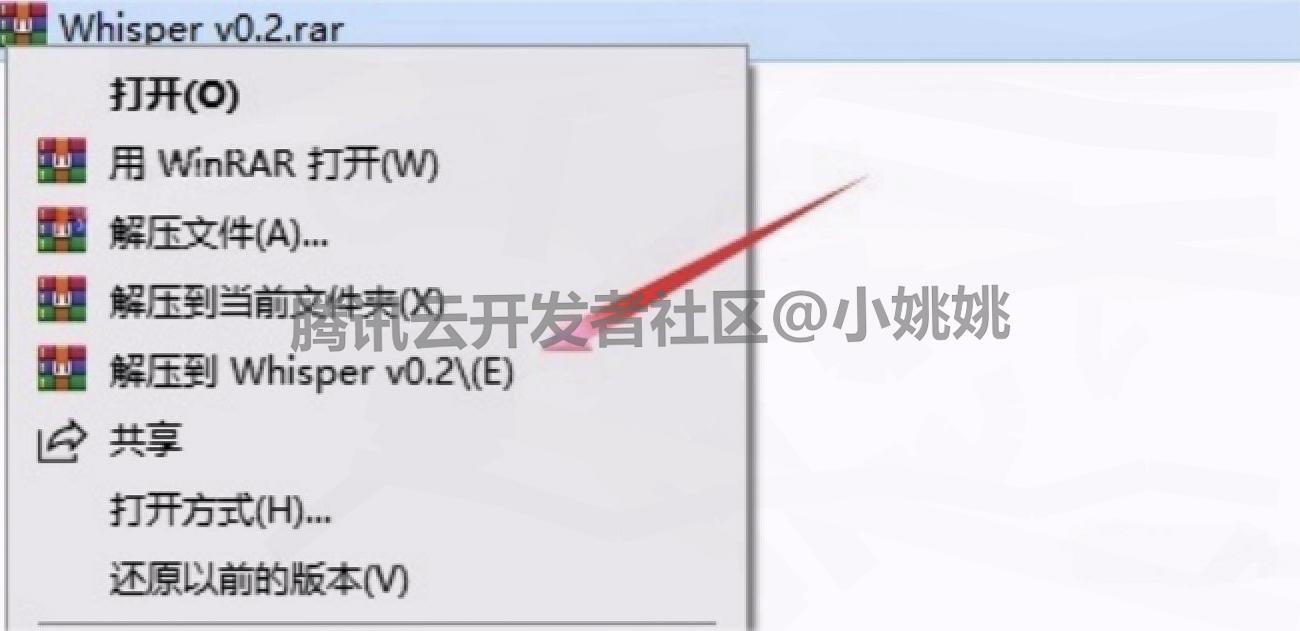
1. 解压Whisper安装包
找到下载好的 Whisper v0.2 安装包,右键点击选择 “解压到当前文件夹”(或自定义解压路径),等待解压完成。
Whisper v0.2 免费开源语音转文字软件工具下载安装使用全指南
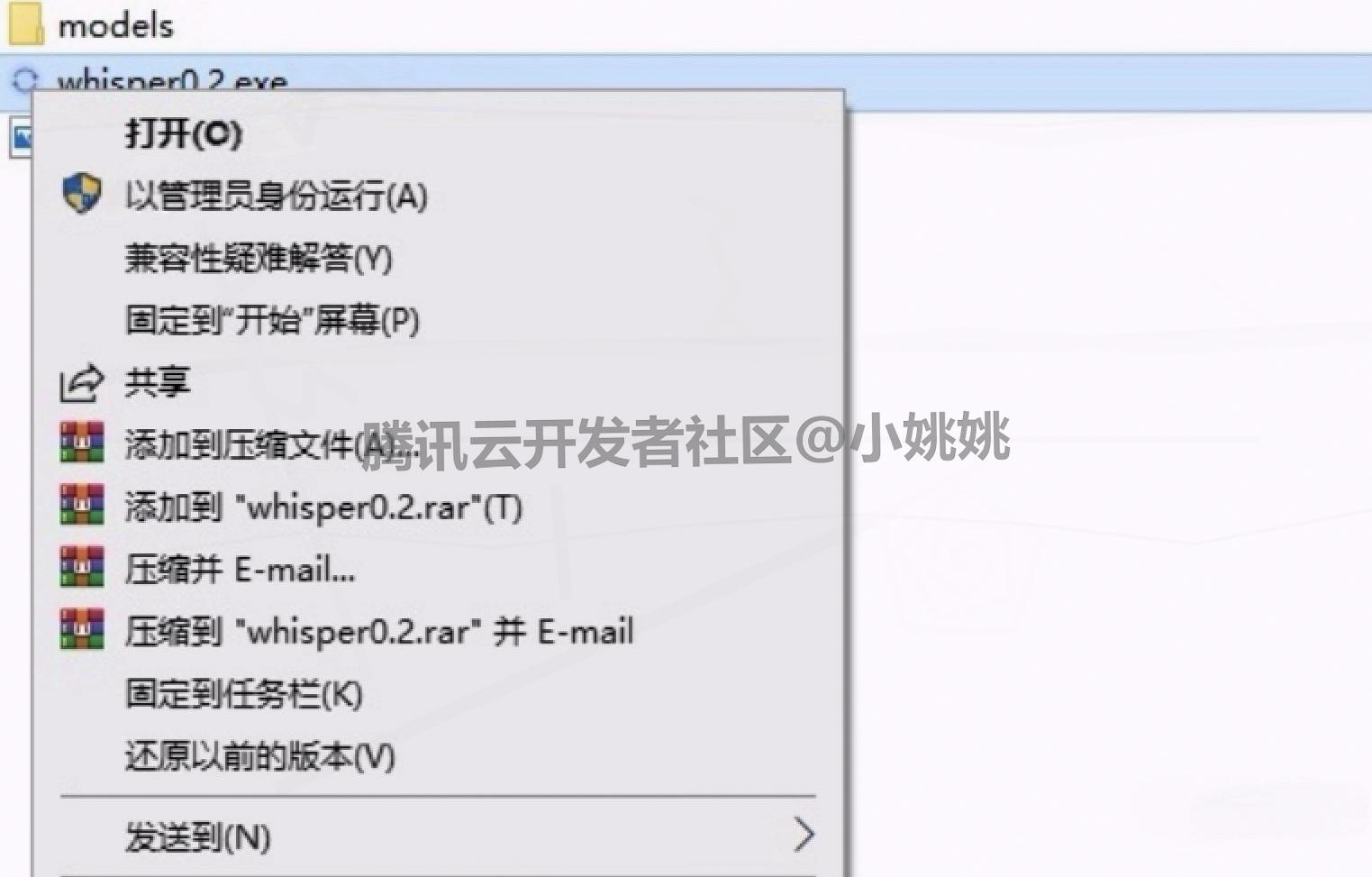
2. Whisper启动软件(附快捷方式设置)
- 进入解压后的文件夹,找到软件主程序(通常以.exe 结尾),右键点击选择 “以管理员身份运行”,确保软件正常启动。
- 若需后续快速打开,可右键点击主程序,选择 “发送到”→“桌面快捷方式”,之后直接双击桌面快捷方式即可启动。
进入解压后的文件夹,找到软件主程序(通常以.exe 结尾),右键点击选择 “以管理员身份运行”,确保软件正常启动。
若需后续快速打开,可右键点击主程序,选择 “发送到”→“桌面快捷方式”,之后直接双击桌面快捷方式即可启动。
Whisper v0.2 免费开源语音转文字软件工具下载安装使用全指南
三、Whisper软件功能设置与使用教程
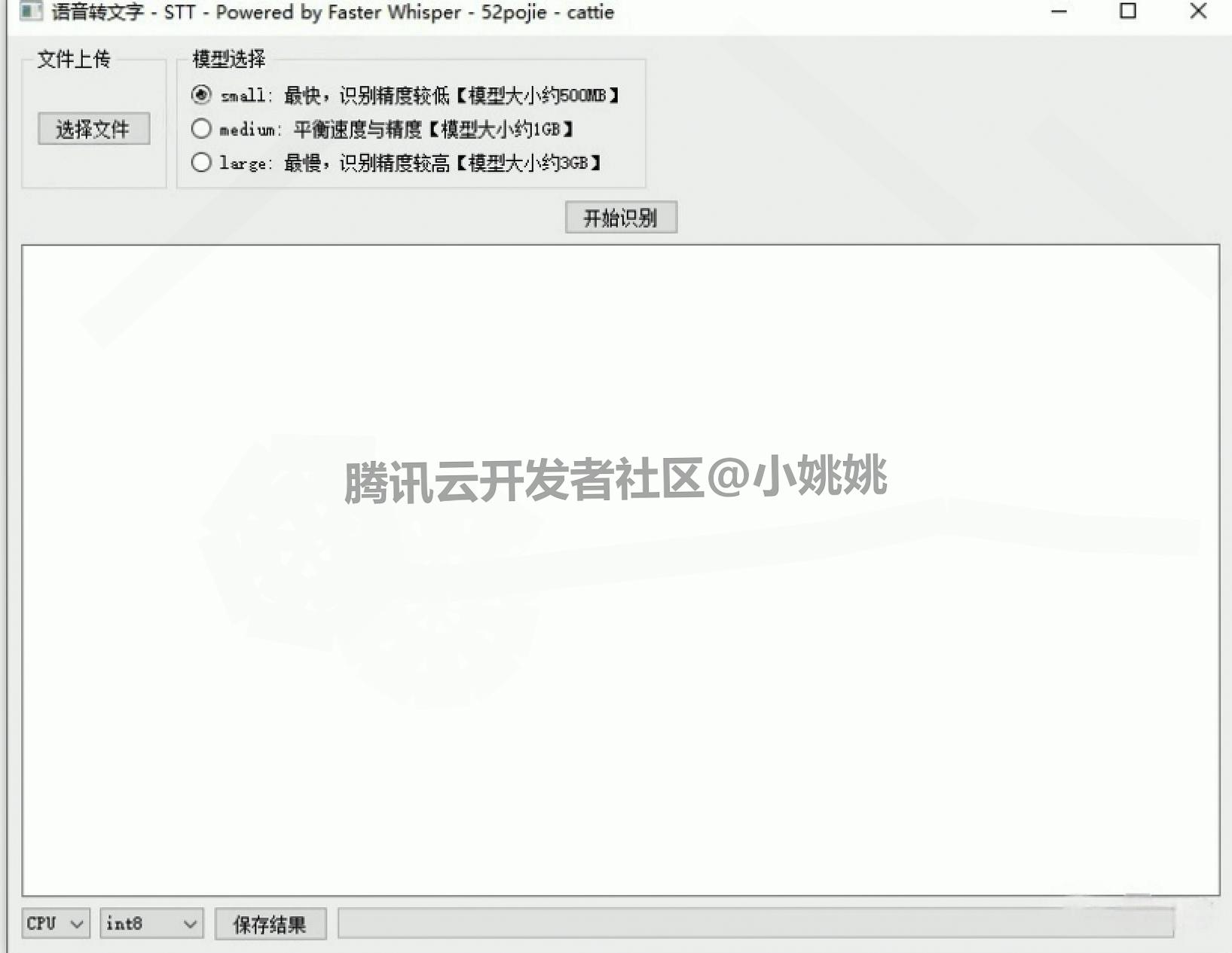
1. Whisper核心功能参数说明(新手必看)
Whisper v0.2 免费开源语音转文字软件工具下载安装使用全指南
(1)模型选择
- 软件默认集成 “medium 模型”,无需额外下载,直接选择即可满足日常语音转文字需求。
- 若需更高精度(如 large 模型)或更快速识别(如 small 模型),需手动选择对应模型,下载进度会在软件控制台中实时显示,等待下载完成后即可使用。
软件默认集成 “medium 模型”,无需额外下载,直接选择即可满足日常语音转文字需求。
若需更高精度(如 large 模型)或更快速识别(如 small 模型),需手动选择对应模型,下载进度会在软件控制台中实时显示,等待下载完成后即可使用。
(2)GPU 选项设置(避免程序崩溃)
- 若电脑配备支持 CUDA 的独立显卡,可选择 “GPU” 模式提升识别速度;
- 若电脑无独立显卡或显卡不支持 CUDA,务必不要选择 GPU 选项,否则可能导致程序崩溃,建议默认使用 CPU 模式。
若电脑配备支持 CUDA 的独立显卡,可选择 “GPU” 模式提升识别速度;
若电脑无独立显卡或显卡不支持 CUDA,务必不要选择 GPU 选项,否则可能导致程序崩溃,建议默认使用 CPU 模式。
(3)推理方式与精度选择(优化识别效率)
- 普通 CPU 用户:推荐选择 “int8” 精度模式,能大幅提升识别速度,同时保证识别准确率;
- 使用 “large 模型” 时:建议将精度设置为 “float32”,避免因精度不足导致识别误差。
普通 CPU 用户:推荐选择 “int8” 精度模式,能大幅提升识别速度,同时保证识别准确率;
使用 “large 模型” 时:建议将精度设置为 “float32”,避免因精度不足导致识别误差。
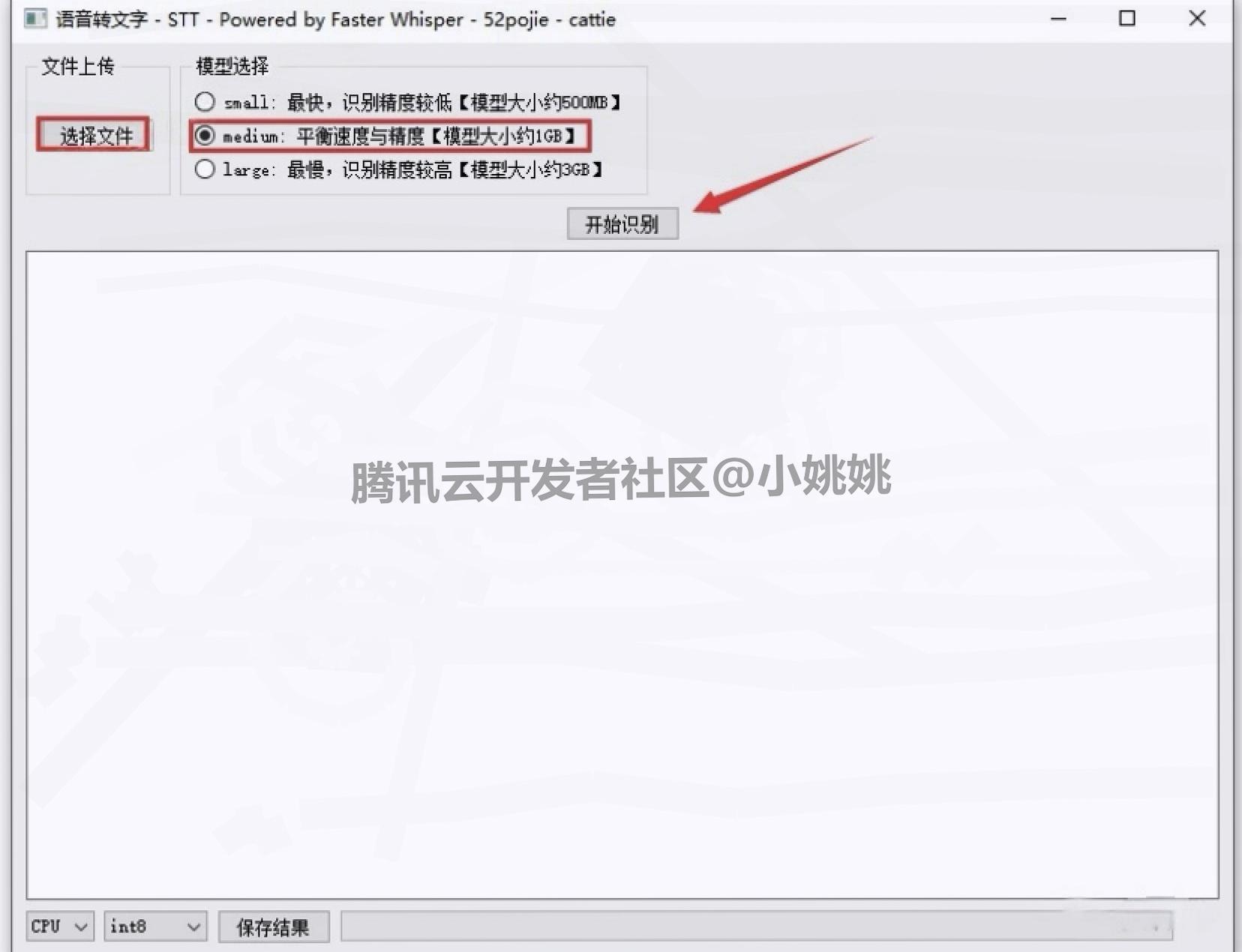
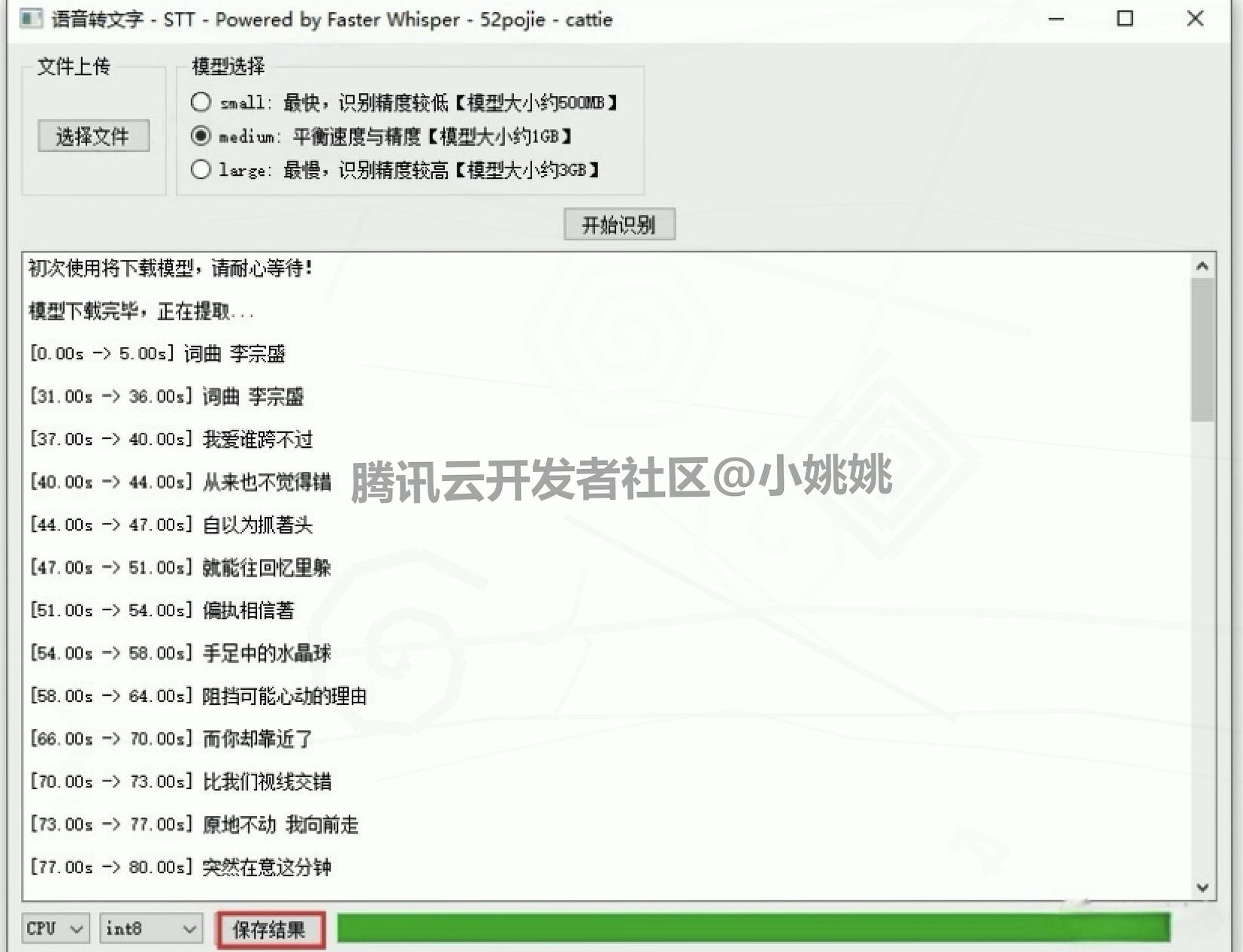
2. Whisper语音转文字操作步骤(全程 3 步)
- 添加音频文件:点击软件界面中的 “选择文件” 按钮,支持导入 wav、mp3 两种常见音频格式,选择需要转换的文件并确认。
Whisper v0.2 免费开源语音转文字软件工具下载安装使用全指南
- 设置参数并启动识别:模型选择 “medium”(无需下载),根据电脑配置设置 GPU/CPU 模式及精度,确认无误后点击 “开始识别”。
- 保存识别结果:等待识别完成后,点击界面中的 “保存结果” 按钮,选择保存路径(如桌面、文档文件夹),即可将文字结果保存为本地文件(通常为 txt 格式)。
设置参数并启动识别:模型选择 “medium”(无需下载),根据电脑配置设置 GPU/CPU 模式及精度,确认无误后点击 “开始识别”。
保存识别结果:等待识别完成后,点击界面中的 “保存结果” 按钮,选择保存路径(如桌面、文档文件夹),即可将文字结果保存为本地文件(通常为 txt 格式)。
Whisper v0.2 免费开源语音转文字软件工具下载安装使用全指南
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号