AGI世界模拟迎来统一框架!首篇综述打通2D→视频→3D→4D生成全链路!

AGI世界模拟迎来统一框架!首篇综述打通2D→视频→3D→4D生成全链路!

AI生成未来
发布于 2025-08-27 15:05:35
发布于 2025-08-27 15:05:35
作者:Yuqi Hu等
解读:AI生成未来

文章链接: https://arxiv.org/pdf/2503.04641
亮点直击
- 首次统一2D、视频、3D和4D生成研究的综述,为该研究领域提供了结构化和全面的概述。
- 从数据维度增长的角度,通过多模态生成模型的视角,系统性地回顾了现实世界模拟的方法。
- 从多个角度调查了常用数据集、其特性以及相应的评估指标。
- 它指出了开放的研究挑战,旨在为该领域的进一步探索提供指导。
理解并复现现实世界是通用人工智能(AGI)研究中的一个关键挑战。为实现这一目标,许多现有方法(例如世界模型)旨在捕捉支配物理世界的基本原理,从而实现更精确的模拟和有意义的交互。然而,当前的方法通常将不同模态(包括2D(图像)、视频、3D和4D表示)视为独立领域,忽略了它们之间的相互依赖性。此外,这些方法通常专注于现实的孤立维度,而没有系统地整合它们之间的联系。本综述提出了一种多模态生成模型的统一综述,探讨了现实世界模拟中数据维度的演进。具体而言,本综述从2D生成(外观)开始,随后转向视频(外观+动态)和3D生成(外观+几何),最后以整合所有维度的4D生成为终点。据我们所知,这是首次尝试在单一框架内系统性地统一2D、视频、3D和4D生成的研究。为指导未来研究,全面回顾了数据集、评估指标和未来方向,并为新研究者提供了启发。本综述作为桥梁,推动了多模态生成模型和现实世界模拟在统一框架内的研究进展。
1 引言
几十年来,研究界一直致力于开发能够封装物理世界基本原理的系统,这是实现通用人工智能(AGI)的关键基石。这一努力的核心是通过机器模拟现实世界,旨在通过多模态生成模型的视角捕捉现实的复杂性。由此产生的世界模拟器有望推动对现实世界的理解,并解锁诸如虚拟现实 、游戏、机器人和自动驾驶等变革性应用。
“世界模拟器”一词最早由 Ha David提出,借鉴了认知科学中的心理模型概念。基于这一视角,现代研究将模拟器定义为一个抽象框架,使智能系统能够通过多模态生成模型模拟现实世界。这些模型将现实世界的视觉内容和时空动态编码为紧凑的表示形式。由于几何、外观和动态共同决定了生成内容的真实感,这三个方面得到了广泛研究。传统的现实世界模拟方法长期以来依赖于结合几何、纹理和动态的图形技术。具体而言,几何和纹理建模用于创建物体,而关键帧动画和基于物理的模拟等方法则用于模拟物体随时间的运动和行为。
尽管取得了巨大进展,但这些传统方法通常需要大量的手动设计、启发式规则定义和计算密集型处理,限制了其可扩展性和对多样化场景的适应性。近年来,基于学习的方法,特别是多模态生成模型,通过提供数据驱动的现实模拟方法,彻底改变了内容创作。这些方法减少了对人工努力的依赖,提高了跨任务的泛化能力,并实现了人与模型之间的直观交互。例如,Sora 因其逼真的模拟能力而备受关注,展示了早期对物理定律的理解。此类生成模型的出现引入了新的视角和方法,通过减少对大量手动设计和计算密集型建模的需求,同时增强多样化模拟场景中的适应性和可扩展性,解决了传统方法的局限性。
尽管现有的生成模型为合成不同数据维度中的逼真内容提供了强大的技术,但现实世界表现出固有的高维复杂性,目前仍缺乏一项系统整合这些跨维度进展的全面综述。本综述旨在通过从数据维度增长的角度统一现实世界模拟的研究,填补这一空白,如下图 1 所示。具体而言,从 2D 生成(仅外观)开始,然后通过分别引入动态和几何维度,扩展到视频和 3D 生成。最后,通过整合所有维度,以 4D 生成为终点。
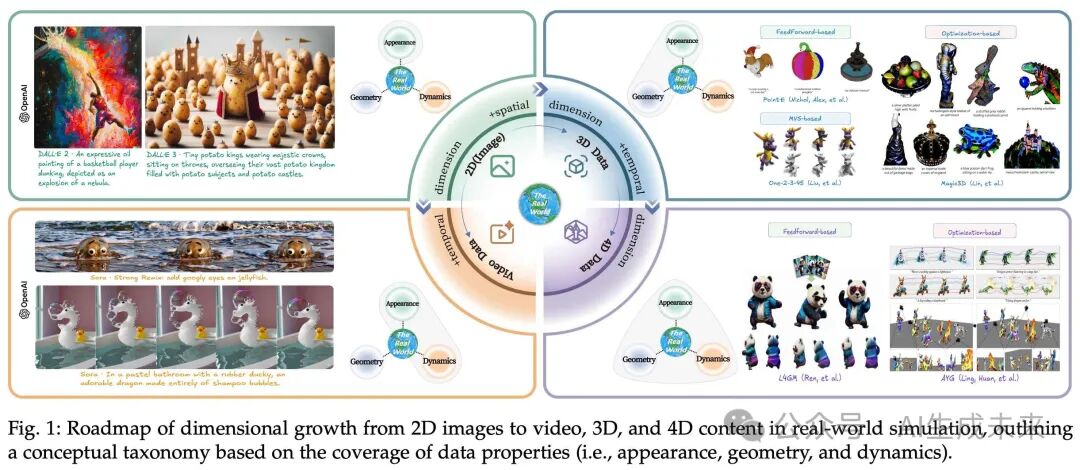
总结而言,本综述做出了三项关键贡献。首先,它从数据维度增长的角度,通过多模态生成模型的视角,系统性地回顾了现实世界模拟的方法。据我们所知,这是首次统一 2D、视频、3D 和 4D 生成研究的综述,为该研究领域提供了结构化和全面的概述。其次,它从多个角度调查了常用数据集、其特性以及相应的评估指标。第三,它指出了开放的研究挑战,旨在为该领域的进一步探索提供指导。
希望本综述能够为新研究者提供有价值的见解,并促进经验丰富的研究者进行批判性分析。本综述的组织结构如下:第 2 节介绍了深度生成模型的基础概念;第 3 节介绍了 2D、视频、3D 和 4D 生成四个关键范式;第 4 节回顾了这些范式的数据集和评估指标;第 5 节概述了未来方向;第 6 节总结了本综述。
2 预备知识
深度生成模型借助深度神经网络学习复杂且高维的数据分布。将数据样本表示为 ,其分布为 ,深度生成模型的目标是用 近似 ,其中 是模型的参数。本节简要回顾了几种主流的生成模型(下表 1),包括生成对抗网络(GANs)、变分自编码器(VAEs)、自回归模型(AR Models)、归一化流(NFs)和扩散模型。
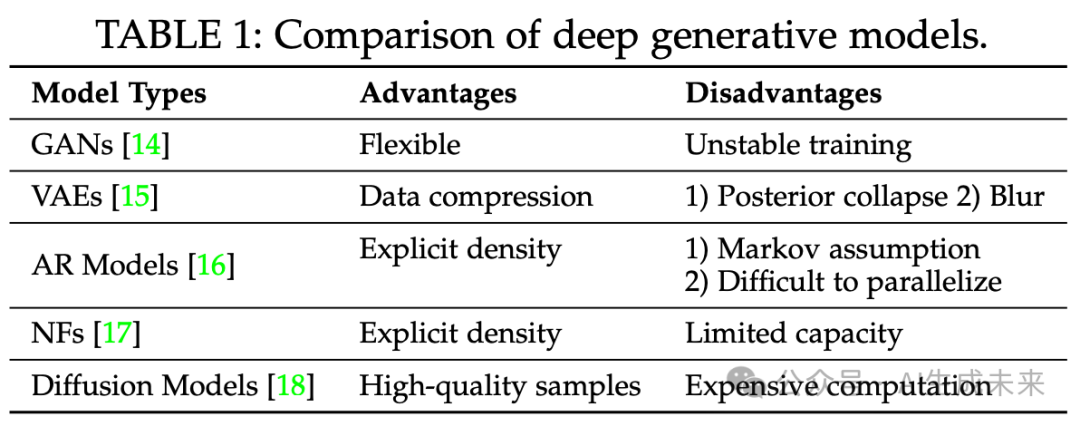
2.1 生成对抗网络(GANs)
GANs 避免了 的参数化形式,而是将 表示为生成器生成的样本的分布。研究表明,在一定条件下, 会收敛到 。
生成器以噪声向量 作为输入,合成数据样本 。 被定义为 的分布,其中 。与此同时,判别器 判断输入数据样本是真实的还是合成的。在训练过程中,判别器被训练以区分生成样本和真实数据,而生成器则被训练以欺骗判别器。该过程可以表示为:
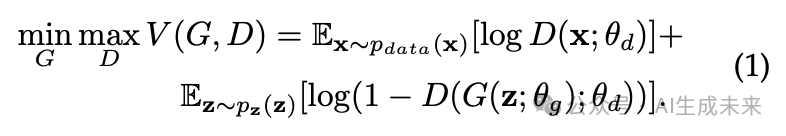
2.2 变分自编码器(VAEs)
变分自编码器(VAEs)将 表述为:
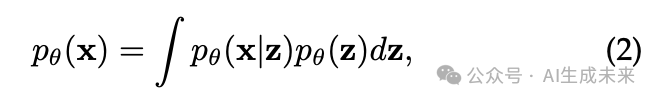
其中, 是 的先验分布, 是给定 下 的条件分布。然而,由于这个积分通常是难以计算的,VAEs 转而最大化 的下界:
其中, 是 和 之间的 KL 散度, 通过随机梯度变分贝叶斯估计器计算。
2.3 自回归模型(AR Models)
自回归模型(AR Models)将 分解为条件概率的乘积,以缓解建模多元联合概率的困难:
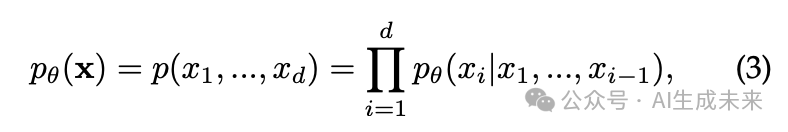
其中, 是序列长度。 最近,许多研究致力于使用自回归模型对图像中的像素进行顺序建模 [19]–[21]。
2.4 归一化流(Normalizing Flows, NFs)
归一化流(NFs)使用一个可逆的神经网络 将 从一个已知且易于处理的分布映射到真实数据分布。通过这种方式, 可以表示为:
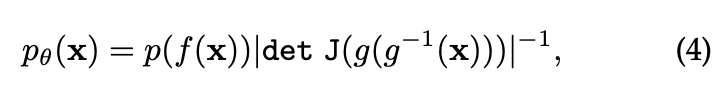
其中, 是 的逆函数, 是 的雅可比矩阵。归一化流通过组合一组 个双射函数来构建任意复杂的非线性可逆函数,并定义 。
2.5 扩散模型
扩散模型是一类概率生成模型,通过逐步引入噪声来破坏数据,随后学习逆转这一过程以生成样本。通过能量项 定义 :
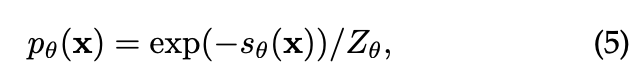
其中, 是归一化项。
由于 难以计算,扩散模型转而学习得分函数 。
将数据分布转换为标准高斯分布的前向过程定义为:
其中, 是漂移系数, 是扩散系数, 是标准维纳过程,。样本通过相应的反向过程生成,该过程描述为:
其中, 是时间从 1 流向 0 时的标准维纳过程。
3 范式
本节从数据维度增长的角度介绍了模拟现实世界的方法。首先从外观建模的 2D 生成(第 3.1 节)开始,然后通过引入动态和几何维度,扩展到视频生成(第 3.2 节)和 3D 生成(第 3.3 节)。最后,通过整合这三个维度,介绍了 4D 生成(第 3.4 节)的最新进展。
3.1 2D 生成
近年来,生成模型领域取得了显著进展,尤其是在文本到图像生成方面。文本到图像生成因其能够通过捕捉现实世界的外观从文本描述中生成逼真图像而备受关注。利用扩散模型、大语言模型(LLMs)和自编码器等技术,这些模型实现了高质量且语义准确的图像生成。
3.1.1 算法
Imagen 基于 GLIDE 的原则,但引入了显著的优化和改进。Imagen 没有从头开始训练任务特定的文本编码器,而是使用预训练并冻结的语言模型,从而减少了计算需求。Imagen 测试了在图像-文本数据集(如 CLIP)上训练的模型,以及在纯文本数据集(如 BERT 和 T5)上训练的模型。这一实践表明,扩大语言模型的规模比扩大图像扩散模型更有效地提高了图像保真度和文本一致性。
DALL-E(v1版本)使用了一种 Transformer 架构,将文本和图像作为单一数据流进行处理。
DALL-E 2 利用了 CLIP 的强大语义和风格能力,采用生成扩散解码器来逆转 CLIP 图像编码器的过程。
DALL-E 3 在 DALL-E 2 的基础上进一步改进,显著提升了图像保真度和文本对齐能力。它增强了文本理解能力,能够从复杂描述中生成更准确和细致的图像。DALL-E 3 与 ChatGPT集成,使用户可以直接在 ChatGPT 界面中构思和完善提示,从而简化生成详细和定制化提示的过程。该模型生成的图像具有更高的真实感,并与提供的文本更好地对齐,使其成为创意和专业应用的强大工具。
DeepFloyd IF DeepFloyd IF 以其卓越的 photorealism(超写实主义)和高级语言理解能力而闻名。该系统采用模块化设计,包括一个静态文本编码器和三个顺序的像素扩散模块。首先,基础模型从文本描述生成 64×64 像素的图像,然后通过两个超分辨率模型将其增强到 256×256 像素,最终达到 1024×1024 像素。每个阶段都使用基于 T5 Transformer 的静态文本编码器生成文本嵌入,随后通过集成了交叉注意力和注意力池化机制的 U-Net 架构进行处理。
Stable Diffusion (SD) Stable Diffusion(SD),也称为 Latent Diffusion Model(LDM),在有限的计算资源上提高了训练和推理效率,同时生成高质量和多样化的图像。去噪过程在预训练自编码器的隐空间中进行,这些自编码器将图像映射到空间隐空间。底层的 U-Net 架构通过交叉注意力机制增强,以建模条件分布,条件可以包括文本提示、分割掩码等。它使用 BERT 分词器进行文本编码,并在 LAION-400M数据集上训练,生成分辨率为 256×256 的图像(隐空间分辨率为 32×32)。
在 Stable Diffusion 的基础上,SDXL 采用了三倍大的 U-Net 骨干网络,并引入了额外的注意力块和更大的交叉注意力上下文,通过使用第二个文本编码器实现。此外,SDXL 还包含一个细化模型,通过后处理的图像到图像技术增强 SDXL 生成样本的视觉保真度。
FLUX.1 FLUX.1 采用了一种混合架构,集成了多模态和并行扩散 Transformer 块,达到了 120 亿参数的规模。通过使用流匹配(flow matching)这一简单而有效的生成模型训练技术,FLUX.1 超越了之前的最先进扩散模型。该套件还采用了旋转位置嵌入和并行注意力层,极大地提高了模型性能和效率。
3.2 视频生成
文本到视频生成模型通过扩展文本到图像框架来处理现实世界中的动态维度。根据不同的生成机器学习架构将这些模型分为三类。下图 2 总结了最近的文本到视频生成技术。如需更详细的综述,读者可以参考该子领域的更多详细综述 [62], [63]。

3.2.1 算法
(1) 基于 VAE 和 GAN 的方法 在扩散模型之前,视频生成研究主要通过两种方法推进:基于 VAE 和基于 GAN 的方法,每种方法都为视频合成的挑战提供了独特的解决方案。基于 VAE 的方法从 SV2P的随机动态发展到 VideoGPT 中 VQ-VAE与 Transformer 的结合,通过分层离散隐空间变量高效处理高分辨率视频。FitVid的参数高效架构和对抗训练的引入带来了显著改进。基于 GAN 的方法则从 MoCoGAN开始,通过分解内容和运动组件实现可控生成。StyleGAN-V 通过位置嵌入将视频视为时间连续信号,而 DIGAN引入了隐式神经表示以改进连续视频建模。StyleInV利用预训练的 StyleGAN生成器,结合时间风格调制反演网络,标志着高质量帧合成和时间一致性的又一里程碑。
(2) 基于扩散的方法 文本到视频生成最近取得了显著进展,主要分为两类:基于 U-Net 的架构和基于 Transformer 的架构。
- (i) 基于 U-Net 的架构 开创性的视频扩散模型(VDM) 通过扩展图像扩散架构并引入联合图像-视频训练以减少梯度方差,实现了高保真、时间一致的视频生成。Make-A-Video通过利用现有视觉表示和创新时空模块,在没有配对文本-视频数据的情况下推进了文本到视频生成。Imagen Video引入了结合基础生成和超分辨率的扩散模型级联,而 MagicVideo通过在低维空间中的隐空间扩散实现了高效生成。GEN-1专注于使用深度估计进行结构保留编辑,而 PYoCo通过精心设计的视频噪声先验展示了在有限数据下的高效微调。Align-your-Latents通过扩展 Stable Diffusion并结合时间对齐技术,实现了高分辨率生成(1280×2048)。Show-1结合了基于像素和基于隐空间的方法,以提高质量并减少计算量。VideoComposer通过时空条件编码器引入了一种新的可控合成范式,支持基于多种条件的灵活组合。AnimateDiff提出了一个即插即用的运动模块,具有可迁移的运动先验,并引入了 MotionLoRA 以实现高效适配。PixelDance通过结合首帧和末帧图像指令以及文本提示,增强了生成效果。
- (ii) 基于 Transformer 的架构 随着 Diffusion Transformer (DiT)的成功,基于 Transformer 的模型逐渐崭露头角。VDT引入了模块化的时间和空间注意力机制,支持预测、插值和补全等多样化任务。W.A.L.T通过统一的隐空间和因果编码器架构实现了照片级真实感生成,生成分辨率为 512×896 的高分辨率视频。Snap Video通过处理空间和时间冗余像素,将训练效率提高了 3.31 倍,而 GenTron通过无运动引导扩展到了超过 30 亿参数。Luminia-T2X通过零初始化注意力和标记化的隐时空空间集成了多种模态。CogVideoX通过专家 Transformer、3D VAE 和渐进训练在长视频生成中表现出色,通过多项指标验证了其最先进的性能。突破性的 Sora是一种先进的扩散 Transformer 模型,专注于生成不同分辨率、宽高比和时长的高质量图像和视频。Sora 通过对隐时空空间进行标记化,实现了灵活且可扩展的生成能力。
(3) 基于自回归的方法 与基于扩散的方法并行,受大语言模型(LLMs)启发的自回归框架也成为了视频生成的另一种方法。这些方法通常遵循两阶段过程:首先使用 VQ-GAN和 MAGVIT, [71]–[74] 等向量量化自编码器将视觉内容编码为离散的隐空间标记,然后在隐空间中建模标记分布。CogVideo 是一个基于预训练文本到图像模型 CogView 的 90 亿参数 Transformer 模型,代表了这一方向的重大进展。它采用多帧率分层训练策略来增强文本-视频对齐,并作为首批开源的大规模预训练文本到视频模型之一,在机器和人类评估中设立了新的基准。VideoPoet引入了一种仅解码器的 Transformer 架构,用于零样本视频生成,能够处理包括图像、视频、文本和音频在内的多种输入模态。遵循 LLM 训练范式,VideoPoet 在零样本视频生成中实现了最先进的性能,特别是在运动保真度方面表现出色。
3.2.2 应用
(1) 视频编辑 最近,扩散模型显著推动了视频编辑的发展,能够在保持时间一致性的同时实现复杂的修改。该领域通过多种创新方法不断发展,涵盖了视频操作的各个方面。早期的发展包括 Tune-A-Video,它通过时空注意力机制将文本到图像扩散模型扩展到视频生成。VidToMe引入了标记合并以对齐帧,而 EI开发了专门的注意力模块。Ground-A-Video通过接地引导框架处理多属性编辑,而 Video-P2P引入了交叉注意力控制以生成角色。UniEdit和 AnyV2V等最新框架提供了无需调优的方法和简化的编辑流程。CoDeF和 Pix2Video等专门应用引入了创新的时间一致性处理和渐进变化传播技术。这些方法成功平衡了内容编辑和结构保留,标志着视频操作技术的重大进展。
(2) 新视角合成 视频扩散模型彻底改变了新视角合成,通过学习真实世界几何的先验,从有限的输入图像生成高质量视角。ViewCrafter通过将视频扩散模型与基于点的 3D 表示相结合,开创了这一方向,引入了迭代合成策略和相机轨迹规划,从稀疏输入中生成高保真结果。CameraCtrl通过即插即用模块引入了精确的相机姿态控制。ViVid-1-to-3将新视角合成重新定义为相机运动的视频生成,而 NVSSolver引入了一种零样本范式,通过给定视图调制扩散采样。这一趋势表明,利用视频扩散先验的同时保持几何一致性和相机控制,正在推动越来越逼真的合成应用。
(3) 视频中的人类动画 人类动画在视频生成中具有重要意义,正如第 3.2.1 节所述,它在世界模拟器中扮演着关键角色。由于人类是现实世界中最主要的参与者,因此其逼真模拟尤为重要。得益于生成模型的早期成功,一些代表性工作 [37], [89], [90] 引入了生成对抗网络(GAN)来生成视频中的人类动画。尽管取得了这些进展,人类视频动画中最关键的问题仍然是生成视频的视觉保真度。ControlNet 和 HumanSD 是基于基础文本到图像模型(如 Stable Diffusion [31])的即插即用方法,用于参考姿势生成人类动画。此外,为了解决这些方法的泛化问题,animate-anyone 提出了 ReferenceNet 以保持参考视频的更多空间细节,并将野外生成质量推向了新的里程碑。一些后续工作 [94], [95] 尝试简化训练架构和成本。此外,随着计算机图形学中对几何和纹理的深入研究,一些工作将 3D 建模引入人类视频动画。Liquid Warping GAN、CustomHuman 和 LatentMan是早期尝试将 3D 人类先验引入生成循环的成果。最新进展 MIMO 明确分别建模角色、3D 运动和场景,以驱动野外人类动画。这些方法无论是否使用 3D 先验,都为将人类引入世界模拟器循环迈出了重要一步。
3.3 3D 生成
3D 生成关注几何结构和外观,以更好地模拟现实世界场景。在本节中,探讨各种 3D 表示和生成算法,并对最新进展进行系统概述。具体而言,根据输入模式对 3D 生成方法进行分类,包括 文本到 3D 生成(Text-to-3D Generation),该方法直接从文本描述合成 3D 内容;图像到 3D 生成(Image-to-3D Generation),该方法通过引入图像约束优化基于文本的输出;视频到 3D 生成(Video-to-3D Generation),该方法利用视频先验信息生成更一致的 3D 结果。图 4 按时间顺序总结了这些技术的进展,而表 2 则对最前沿的方法进行了全面比较。值得注意的是,一些方法跨多个类别,展示了现代 3D 生成技术的多功能性。
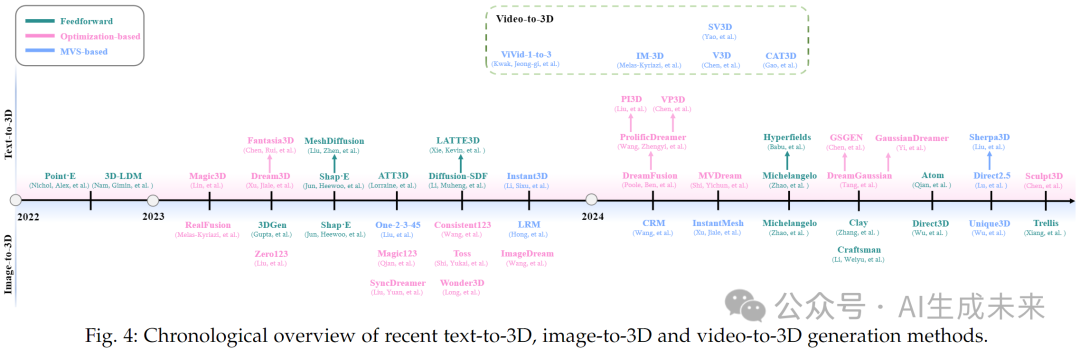
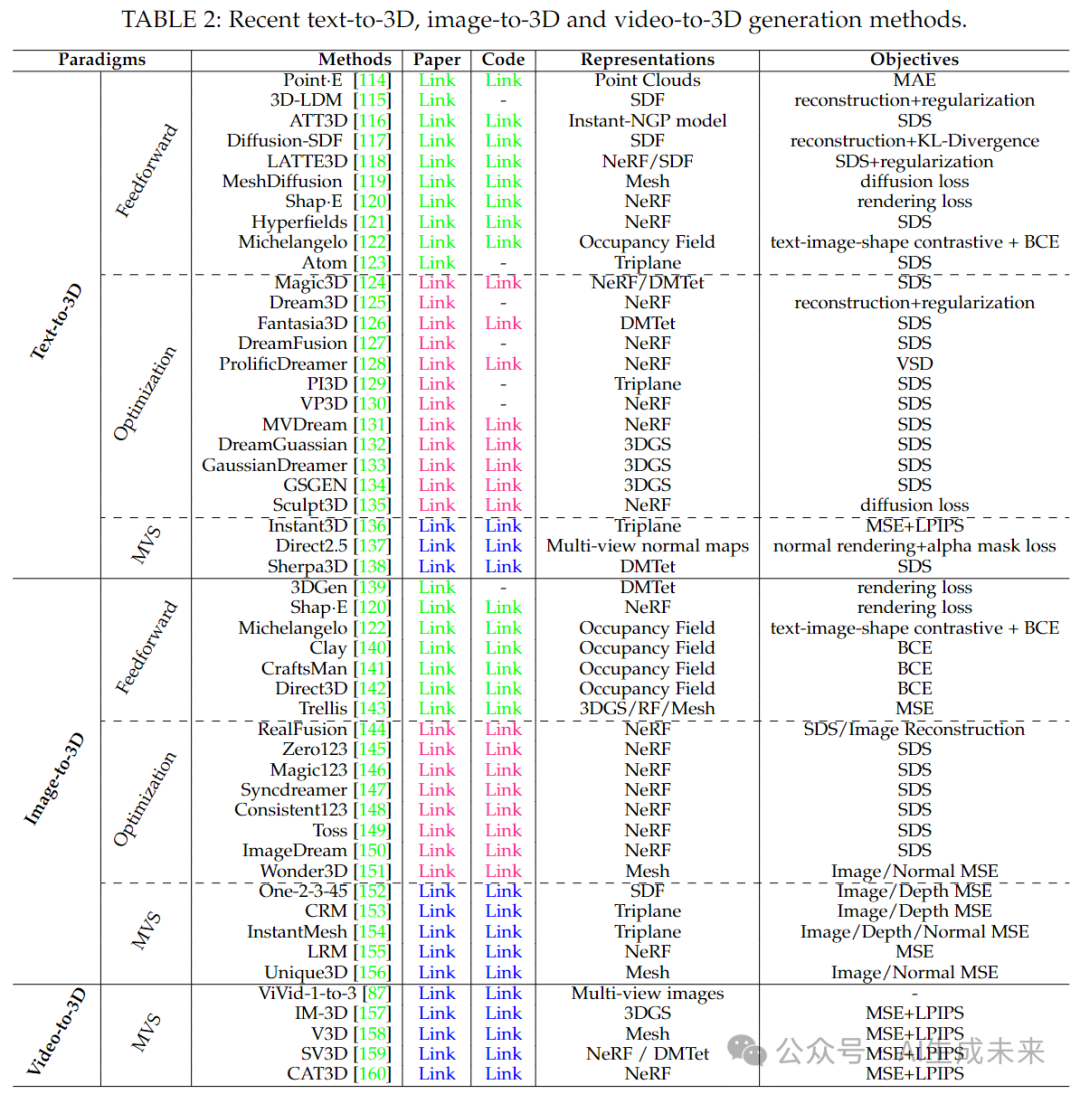
3.3.1 3D 表示
在 3D 生成领域,选择最优的 3D 表示至关重要。对于神经场景表示,3D 数据通常可分为三类:显式表示(explicit representations)、隐式表示(implicit representations)和 混合表示(hybrid representations),这些类别在图 3 中有所展示。
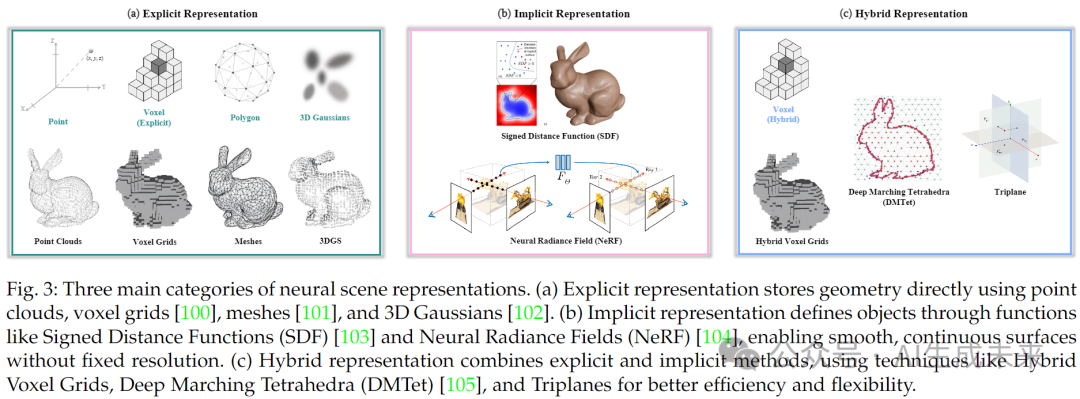
(1) 显式表示
显式表示通过一组元素清晰地可视化对象和场景。传统形式包括 点云(point clouds)、网格(meshes)和 体素(voxels),这些方法已广泛应用多年。
- 点云(Point Clouds)是 3D 点 的无序集合,通常附带颜色或法向量等属性。由于深度传感器的输出,其应用广泛。然而,它们的不规则结构 [106], [107] 使其难以适应 2D 领域的常规神经网络。
- 体素网格(Voxel Grids)由基本单元 体素 组成,体素是 3D 版的像素 [108],用于在 3D 网格上表示点。体素将边界框细分为更小的单元,每个单元包含一个占用值。虽然体素可以存储透明度或颜色等数据,但由于立方体的内存增长()及其稀疏占用率,它在高分辨率数据中存在内存效率低的问题。
- 网格(Meshes)由顶点和边组成多边形(面),用于定义3D空间中的二维表面。与体素网格相比,它们更节省内存,仅对对象的表面进行编码;同时,它们比点云更具显式连接性,可支持几何变换和高效的纹理编码。
- 3D Gaussian Splatting(3DGS)是一种用于加速训练和渲染的有效方法。该方法将对象建模为各向异性高斯分布的集合,每个高斯分布由位置(均值 )、协方差矩阵 、不透明度 和球谐系数 (其中 代表自由度)定义,从而能够建模视角相关的颜色变化,其表达式如下:
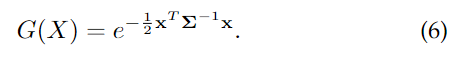
为了优化计算,协方差矩阵 通常被分解为一个缩放矩阵 和一个旋转矩阵 ,使得:
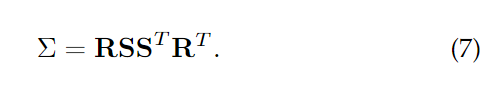
(2) 隐式表示
隐式表示使用连续函数(如数学模型或神经网络)来描述 3D 空间,捕捉体积特性,而非直接表示表面几何。隐式神经表示利用神经网络逼近这些函数,提高表现力,但带来了更高的训练和推理开销。主要方法包括 有向距离场(Signed Distance Field, SDF)和 神经辐射场(Neural Radiance Field, NeRF)。
- 有向距离场(SDF) 使用神经场来表示 3D 形状,其中表面由 SDF 的零水平集隐式定义。对于任意点 ,SDF 函数 返回该点到最近表面的最短距离,并以符号区分内外部( 表示点位于物体内部, 表示点位于物体外部)。表面由满足 的点集定义。
- 神经辐射场(NeRF)使用多层感知机(MLP)编码 3D 场景,将空间位置 和视角方向 映射到密度 和颜色 ,即:
在渲染时,NeRF 从相机沿着光线 采样多个点 ,最终像素颜色 由体积渲染计算如下:
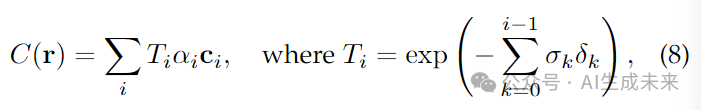
其中, 代表采样点的不透明度,而累积透射率 表示从 到 沿光线传播的透射概率, 为相邻采样点间的距离。
(3) 混合表示
目前,大多数隐式方法依赖于回归 NeRF 或 SDF 值,这可能限制它们利用目标视图或表面的显式监督能力。而显式表示提供了有益的训练约束并改善用户交互。混合表示结合了二者的优势,是显式和隐式表示之间的一种折中方案。
- 混合体素网格 在方法 [110]–[112] 中有所应用,例如 [111] 通过密度和特征网格重建辐射场,而 Instant-NGP [112] 利用哈希多层网格优化 GPU 性能,以加速训练和渲染。
- DMTet将四面体网格与implicit SDF相结合,用于灵活的3D表面表示。神经网络预测每个顶点的SDF值和位置偏移,从而可以对复杂的拓扑进行建模。网格通过可微的Marching Tetrahedra(MT)层转换为网格,实现了高效、高分辨率的渲染。通过基于网格的损失优化几何和拓扑,DMTet实现了更精细的细节、更少的伪影,并在复杂3D数据集上从粗体素进行条件形状合成方面优于以前的方法。
- 三平面表示(Tri-plane) 通过将 3D 体积分解为三个正交的 2D 特征平面(XY、XZ、YZ),提供了一种节省内存的替代方案。例如 EG3D采用此结构,并使用 MLP 聚合平面特征以预测 3D 点的颜色和密度:
该方法比基于体素的 NeRF 更节省内存,并能实现更快的渲染。
3.3.2 算法
(1) 文本到 3D 生成
为了通过模拟真实世界中的几何结构,从文本提示生成 3D 内容,已经进行了大量研究,并且可以分为三个分支。读者可以参考 [161]–[163] 以获取该领域更全面的综述。
- (i) 前馈方法
受文本到图像生成的启发,一类主要的方法扩展了现有成功的生成模型,以在一次前馈传播中直接从文本提示合成 3D 表示。成功的关键在于将 3D 几何编码为紧凑的表示,并使其与相应的文本提示对齐。
Michelangelo首先构建了一个 VAE 模型,将 3D 形状编码到一个隐空间嵌入中。然后,该嵌入使用 CLIP模型与从语言和图像中提取的嵌入进行对齐。通过使用对比损失进行优化,可以从文本提示推断出 3D 形状。
ATT3D使用Instant-NGP模型作为 3D 表示,并通过映射网络将其与文本嵌入连接起来。然后,从 Instant-NGP 模型渲染多视图图像,并使用 SDS 损失优化整个网络。
受 ATT3D 启发,Atom学习从文本嵌入预测三平面(triplane)表示,并采用两阶段优化策略。
Hyperfields训练一个动态超网络,以记录从不同场景学习到的 NeRF 参数。
最近,扩散模型(diffusion models)的出色表现促使研究人员将其扩展到 3D 生成。早期方法主要专注于学习从文本提示(text prompt)合成显式 3D 表示。具体来说,Point·E首先使用 GLIDE生成多个视角的图像,然后利用扩散模型将这些图像作为条件生成点云(point cloud)。随后,MeshDiffusion使用扩散模型建立从文本到网格(meshes)的映射。
后续方法尝试将扩散模型应用于隐式 3D 表示(implicit 3D representations)。Shap·E 首先将 3D 内容映射到辐射场(radiance field)的参数,并训练扩散模型生成这些参数,以文本嵌入(text embedding)作为条件。3D-LDM 使用 SDF(签名距离场)表示 3D 内容的几何信息,并训练扩散模型进行基于文本的生成。同样,Diffusion-SDF 通过体素化(voxelized)的扩散模型构建一个 SDF 自编码器(autoencoder),从文本提示生成体素化的 SDFs。LATTE3D 发展了一个纹理网络(texture network)和一个几何网络(geometry network),分别生成 NeRF 和 SDF,并以文本嵌入作为条件。然后,通过 SDS 损失优化一个 3D 感知的扩散模型。
讨论:与基于优化的方法相比,前馈方法(feedforward approaches)效率更高,并且能够在无需测试时优化(test-time optimization)的情况下生成 3D 内容。然而,这些方法依赖于大量数据,并且通常在结构和纹理细节方面表现较差。
- (ii) 基于优化的方法(Optimization-based Approaches)
在文本到图像生成的基础上,另一类方法通过利用强大的文本到图像生成模型提供丰富的监督信号,以优化 3D 表示。
DreamFusion首次引入得分蒸馏采样(Score Distillation Sampling, SDS)损失,以优化从文本提示合成的图像的 NeRF。MVDream通过微调一个多视角扩散模型(multi-view diffusion model),以生成跨视角一致的多视角图像,从而训练 NeRF 以捕捉 3D 内容。Magic3D采用带有纹理的网格(textured meshes)来表示 3D 物体,并使用 SDS 损失优化网格。Dream3D首先从文本提示生成图像,然后利用该图像生成 3D 形状,以初始化神经辐射场(NeRF),随后 NeRF 通过 CLIP 指导进行优化。Fantasia3D 进一步结合 DMTet 和 SDS 损失,从文本提示生成 3D 物体。
ProlificDreamer发展了一种变分得分蒸馏(VSD)方法,以建模 3D 表示的分布,并产生更高质量、细节丰富的结果。为了应对多面 Janus(multi-face Janus)问题,PI3D先微调文本到图像扩散模型,以生成伪图像(pseudo-images),然后利用这些图像通过 SDS 损失生成 3D 形状。VP3D首先使用文本到图像扩散模型从文本提示生成高质量图像,然后使用 SDS 损失,以该图像和文本提示为条件优化 3D 表示。
随着 3D 高斯(3D Gaussian)的显著进展,该技术被广泛应用于文本到 3D 生成领域。DreamGaussian首次使用扩散模型生成 3D 高斯,并采用 SDS 损失进行优化。然后,从 3D 高斯中提取网格,并优化纹理,以获得更高质量的内容。为促进收敛,GSGEN和 GaussianDreamer首先利用 Point·E 从文本提示生成点云,以初始化高斯的位置。随后,这些高斯通过 SDS 损失优化其几何和外观。Sculpt3D引入了 3D 先验(3D prior),通过检索数据库中的参考 3D 物体,与现有流水线无缝集成。
讨论:得益于文本到图像模型的丰富知识,基于优化的方法能够生成更精细的细节。然而,这些方法需要昂贵的逐提示优化(per-prompt optimization),并且计算开销较大。
- (iii) 基于多视角(MVS)的方法
相比于直接从文本提示生成 3D 表示,为了更好地利用文本到图像模型,许多方法尝试合成多视角图像以进行 3D 生成。
Instant3D首先微调文本到图像扩散模型,以生成四视角图像。然后,这些图像输入一个 Transformer,以预测三平面(triplane)表示。Direct2.5对2.5D渲染和自然图像上的多视图法线扩散模型进行了微调。给定一个文本提示,Direct2.5首先生成法线贴图,并通过可微分光栅化对其进行优化。然后,采用最优法线图作为合成多视图图像的条件。Sherpa3D首先采用3D扩散模型从文本提示生成粗略的3D先验。然后,生成法线图并用于合成具有3D相干性的多视图图像。
讨论:随着视觉语言模型(VLMs)的发展,通过注入 3D 先验提升 2D 生成模型的 3D 生成能力引起了越来越多的兴趣。然而,3D 一致性的建立以及有限 3D 数据的微调仍然是开放性问题。
(2) 图像到3D生成
图像到3D任务的目标是生成与给定图像身份一致的高质量3D资产。
(i) 前馈方法 此类方法首先通过压缩网络(如VAE)将3D资产编码为隐空间变量,随后训练生成模型对隐空间样本进行建模:
- 3DGen:引入三平面作为隐空间,提升压缩网络精度与效率。
- Direct3D:采用三平面表征并直接使用3D监督训练,保留隐空间中的细节3D信息。
- Michelangelo:受3Dshape2vecset启发,使用一维向量作为隐空间,并通过占据场监督输出。
- CraftsMan:引入多视角生成模型为扩散模型提供条件,结合法线优化生成网格。
- Clay:构建基于大规模3D数据集预训练的综合系统,包含一维向量VAE/扩散模型(几何生成)、PBR材质扩散与多模态条件设计。
讨论:原生方法在3D数据集上训练压缩网络和生成模型,与基于MVS和基于优化的方法相比,在几何生成方面表现出卓越的性能,能够生成更细粒度的几何细节。然而,由于制作和收集成本高昂,3D数据集的大小比图像或视频数据集要慢得多。因此,原生方法缺乏足够多样和广泛的数据用于预训练。因此,如何利用视频和图像中的先验信息来增强3D生成的多样性和通用性,特别是在纹理生成方面,仍然是一个有待进一步探索的领域。
(ii) 基于优化的方法 基于文本到3D模型的蒸馏方法发展,此类方法通过预训练图像-图像/文本-图像生成模型提供的SDS损失监督优化3D资产,同时通过额外损失约束保持图像身份:
- RealFusion:融合DreamFusion、Magic3D与SJC,结合图像重建损失(保持低层特征)与文本反转(保持语义身份)优化。
- Zero123:将文本-图像模型替换为新视角合成模型,引入相机位姿条件,在3D数据集上微调预训练模型。其新视角合成模型同时保留图像细节与3D数据集的多视角一致性,显著缓解多面Janus问题。
- Zero123-xl:在10倍规模3D数据集上预训练Zero123流程以提升泛化性。
- Magic123:联合利用2D/3D先验进行蒸馏,平衡泛化与一致性,采用粗-细流程提升质量。
- SyncDreamer:通过3D体积建模图像联合分布关系提升多视角一致性。
- Consistent123:利用跨视角注意力与共享自注意力机制增强一致性。
- Toss:引入文本描述作为3D数据高层语义,增强不可见视角的合理性与可控性。
- ImageDream:设计多级图像提示控制器并结合文本描述训练,解决多视角一致性与3D细节问题。
- Wonder3D:跨域注意力机制同步去噪图像与对齐法线图,并引入法线图优化流程。
讨论:继承图像生成模型的强大先验,优化方法展现出强泛化能力与高精度纹理建模。但由于新视角合成(NVS)模型预训练仅使用3D数据采样的2D数据而非直接3D监督,即使通过3D体积建模或跨视角注意力改进,多视角一致性问题仍无法根本解决,导致几何过平滑与训练耗时较长。
(iii) 基于MVS的方法 MVS方法将图像到3D生成拆分为两阶段:1)使用NVS模型从单图生成多视角图像;2)通过前馈重建网络直接生成3D资产:
- One-2-3-45:基于Zero123预测图像,提出高度估计模块与SDF通用神经表面重建模块(3D数据集预训练),实现360°网格重建(耗时45秒,远快于优化方法)。
- CRM:固定多视角生成图像为六种相机位姿以提升一致性,通过卷积U-Net生成深度/RGB监督的高分辨率三平面。
- InstantMesh:固定多视角相机位姿,采用基于LRM的Transformer多视角重建模型,以部分细节一致性为代价提升泛化性。
- Unique3D:多级上采样策略生成高分辨率多视角图像,法线扩散模型预测多视角法线图初始化粗网格,并基于多视角图像优化着色。
讨论:相比优化方法,基于MVS的方法在3D数据集上训练前馈重建模型,显著提升3D一致性与推理速度(秒级)。但受模型规模限制,几何细节质量仍有不足。
(3) 视频到3D生成
海量在线视频数据蕴含物体运动、视角变化与相机运动信息,为3D生成提供静态图像难以捕获的多视角先验。这些动态内容具有时序连贯性与空间一致性,对复杂3D场景理解与高保真结构生成至关重要。当前研究探索视频先验以实现跨帧连贯、视角自适应的3D表征,核心思想是将相机可控视频模型作为密集3D重建的连贯多视角生成器。
视频扩散模型的最新进展展现了其在生成逼真视频与隐式推理3D结构方面的卓越能力,但精确相机控制仍是关键挑战。传统模型通常局限于生成短轨迹平滑相机运动片段,难以有效构建动态3D场景或整合多变视角。为此,研究者提出多种创新技术增强视频扩散框架的相机控制:
- AnimateDiff:采用低秩自适应(LoRA)微调视频扩散模型,生成固定相机运动类型的结构化场景。
- MotionCtrl:引入条件机制支持任意相机路径跟踪,突破传统方法刚性限制。
- SVD-MV、SV3D、IM-3D:基于相机可控视频生成能力优化3D物体生成。例如SV3D训练可渲染任意视角的视频扩散模型,输出576×576高分辨率,保持跨帧空间一致性。
这些能力使得能够保持跨框架的空间一致性,同时适应各种观点,有效地应对密集重建中的关键挑战。虽然有效,这些方法往往限制摄像机的运动固定,轨道路径周围的中心对象,这限制了他们的适用性,复杂的场景与丰富的背景。然而,许多这些方法仍然不能产生令人信服的复杂环境的 3D 表示,其中不同的摄像机角度和与多个对象的交互是至关重要的。
随着视频模型中相机运动控制与新颖视角信息的互补,部分方法探索视频扩散模型在新视角合成(NVS)中的潜力:
- Vivid-1-to-3:融合视角条件扩散模型与视频扩散模型,生成时序一致视图。
- CAT3D:通过多视角扩散模型增强丰富多视角信息。
讨论:视频先验驱动多视角生成技术将推进高保真3D表征发展,尤其在需要强大多视角合成的复杂动态环境建模中潜力巨大。
3.3.3 应用
(1) 头像生成(Avatar Generation)
随着元宇宙(Metaverse)的兴起和 VR/AR 的普及,3D 头像生成受到了越来越多的关注。早期工作主要专注于生成头部头像,采用文本到图像扩散模型和神经辐射场生成面部资产。随后的方法更加关注逼真的全身头像生成,结合神经辐射场与统计模型。最近,头像生成的动画能力受到了广泛关注,并涌现出许多相关方法。
(2) 场景生成(Scene Generation)
除了头像生成,场景生成(Scene Generation)在元宇宙和具身智能(embodied intelligence)等应用中也至关重要。早期方法主要集中在基于物体的场景,并利用条件扩散模型合成多视角图像,以优化神经辐射场。后续研究扩展了这些方法至房间尺度(room-scale)场景,并引入渐进式策略。受其成功启发,最近的研究进一步探索了从街道尺度到城市尺度的室外场景生成。
(3) 3D 编辑(3D Editing)
3D 生成能力的强大,使得 3D 内容编辑成为了一个新的下游应用方向。一些方法专注于全局更改 3D 内容的外观或几何形状,例如场景风格化(scene stylization)方法,用于调整照明或气候变化。近年来,研究人员致力于实现更加灵活和精细化的 3D 内容编辑,包括外观修改、几何变形和基于物体级别的操作,并取得了令人瞩目的成果。
3.4 4D 生成
最终整合所有维度,探讨4D生成。作为计算机视觉的前沿领域,4D 生成专注于合成基于文本、图像或视频等多模态输入的动态 3D 场景。与传统的 2D 或 3D 生成不同,4D 合成引入了独特的挑战,要求在保持高保真度、计算效率和动态真实感的同时,实现空间连贯性和时间一致性。在本节中,首先介绍基于3D 表示扩展的 4D 表示,然后总结当前的 4D 生成方法。最近的研究探索了两种主要范式:利用评分蒸馏采样(SDS)的优化方法,以及避免每次提示优化的前馈方法。这些范式解决了不同的技术挑战,凸显了该领域的复杂性,以及在视觉质量、计算效率和场景灵活性之间寻找可行平衡的持续努力。表 3 总结了 4D 生成的代表性工作。
3.4.1 4D表示
4D 表示领域将时间维度融入 3D 建模,为理解动态场景提供了坚实基础。通过将静态 3D 空间表示 ((x, y, z)) 扩展到时间 ((t)),这些方法对场景动态和变换进行编码,对于非刚性人体运动捕捉和模拟物体轨迹等应用至关重要。
4D 表示面临的一个主要挑战是重建单个场景的高计算成本。为了解决这一问题,显式和混合方法在不牺牲质量的情况下提高了效率。例如:
- 平面分解 通过将 4D 时空网格拆分为更小的组件来优化计算。
- 基于哈希的表示 降低了内存和处理需求。
- 3DGS 通过变形网络将静态高斯调整为动态高斯,以平衡速度与质量。
最近的进展将静态和动态场景组件解耦,以高效渲染刚性和非刚性运动。例如:
- D-NeRF 先将场景编码到一个标准空间,然后再映射到随时间变化的变形状态。
- 3D Cinemagraphy 通过单张图像生成基于特征的点云,并使用 3D 场景流进行动画化。
- 4DGS 通过将尺度、位置、旋转等属性建模为时间函数来捕捉时间动态,同时保持静态场景不变。
此外,混合 NeRF 方法 扩展了 4D 建模,引入平面和体素特征网格,结合 MLP 实现高效的新视角合成,并通过时间平面拓展到动态场景。可变形 NeRFs 通过将几何与运动分离,简化了运动学习,支持图像到 4D 视频生成和多视角重建等应用。总体而言,这些进展反映了在计算效率和高质量时间建模方面的持续突破。
3.4.2 算法
(1) 前馈方法
前馈方法提供了一种高效的替代方案,在单次前向传播中生成 4D 内容,绕过 SDS 需要的迭代优化。这些方法依赖于预训练模型,利用时空先验实现快速且一致的生成。例如:
- Control4D ** 和 Animate3D ** 可直接从文本或视觉输入合成动态场景,支持交互式媒体和个性化内容创作。
- Vidu4D 通过整合时间先验来优化运动轨迹,确保帧间一致性和平滑过渡。
- Diffusion4D 扩展扩散模型以处理 4D 场景合成,结合时空特征提取与高效推理机制。
- L4GM 进一步增强前馈技术,集成隐空间几何建模,在保证高质量的同时保持计算效率。
讨论:前馈方法在实时内容生成和轻量级设备部署等场景中表现优异。然而,它们依赖预训练模型,难以处理复杂动态,难以达到优化方法的细节和多样性水平。尽管如此,这些技术在计算效率和可扩展性方面的优势,使其成为推动 4D 生成实用化的重要步骤。
(2) 优化方法
优化方法是 4D 生成的基础,利用评分蒸馏采样(SDS)等迭代技术,使预训练的扩散模型适应动态 4D 场景合成。这些方法借助文本到图像、多视角图像和文本到视频生成模型的强大先验,实现时间一致性强、运动动态丰富的场景。例如:
- MAV3D 针对 SDS 损失优化 NeRF 或 HexPlane 特征,以文本提示引导 4D 生成。
- 4D-fy 和 Dream-in-4D 通过整合图像、多视角和视频扩散模型提升 3D 一致性与运动动态。
- AYG 使用可变形 3DGS 作为内在表示,利用简单的增量变形场分离静态几何与动态运动,提高灵活性。
在这些基础上,最近的研究从多个方面进一步提升 4D 生成:
- TC4D 和 SC4D 允许用户自由控制 4D 物体的运动轨迹。
- STAG4D 采用多视角融合增强帧间的空间和时间对齐,确保平滑过渡和一致性。
- DreamScene4D 和 DreamMesh4D 采用解耦策略,局部优化计算量,降低计算开销的同时保持高保真度。
此外,4Real 和 C3V 结合组合式场景生成与高效优化,将动态场景拆分为静态几何与运动场等模块化组件,支持灵活更新与多样化内容生成。尽管优化方法在生成质量和时间一致性上表现卓越,但计算需求较高,难以支持实时应用。当前研究正致力于在可扩展性与低延迟方面取得突破,同时保持视觉质量和动态真实感。
3.4.3 应用
(1) 4D 编辑
基于指令引导的编辑允许用户通过自然语言编辑场景,提升可用性。例如:
- Instruct 4D-to-4D 将 4D 场景视为伪 3D 场景,采用视频编辑方法逐步生成一致的编辑数据集。
- Control4D 结合 GAN 和扩散模型,实现基于文本指令的动态 4D 人像编辑。
(2) 人体动画
4D 生成的重要应用之一是人体运动生成,其目标是在数字世界中模拟 4D 人体角色。研究方向包括:
- 基于稀疏控制信号 生成运动,例如运动补全和运动预测。
- 多模态条件生成,例如文本到动作、音乐驱动舞蹈等。
随着扩散模型的快速发展,许多研究已将其引入文本到动作和音乐到舞蹈生成任务,取得了良好的生成质量。
4 数据集与评估
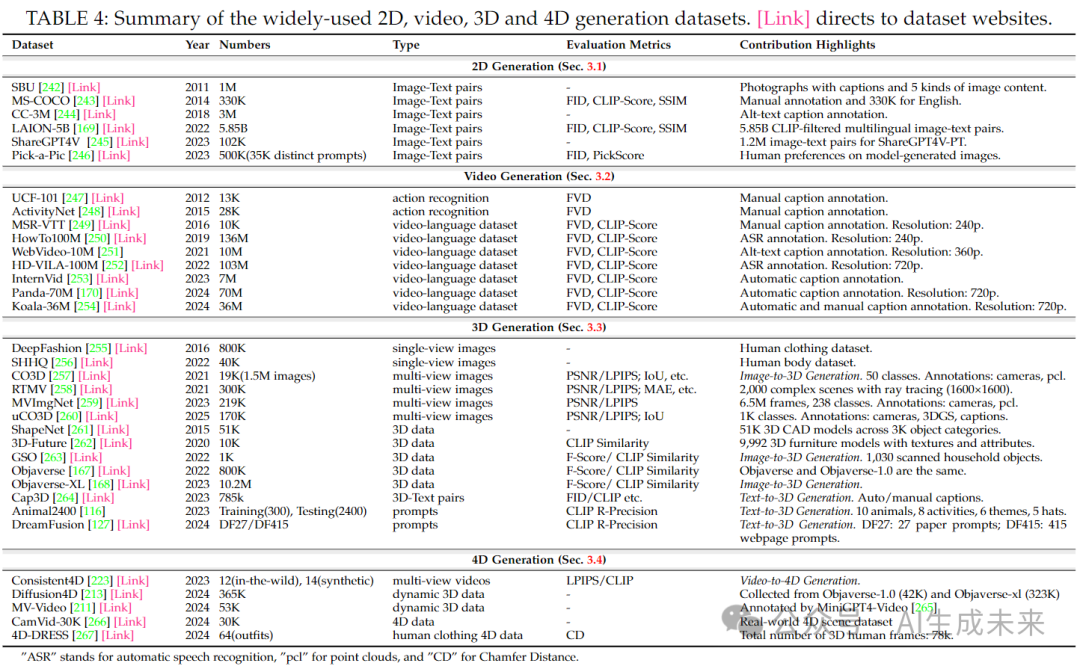
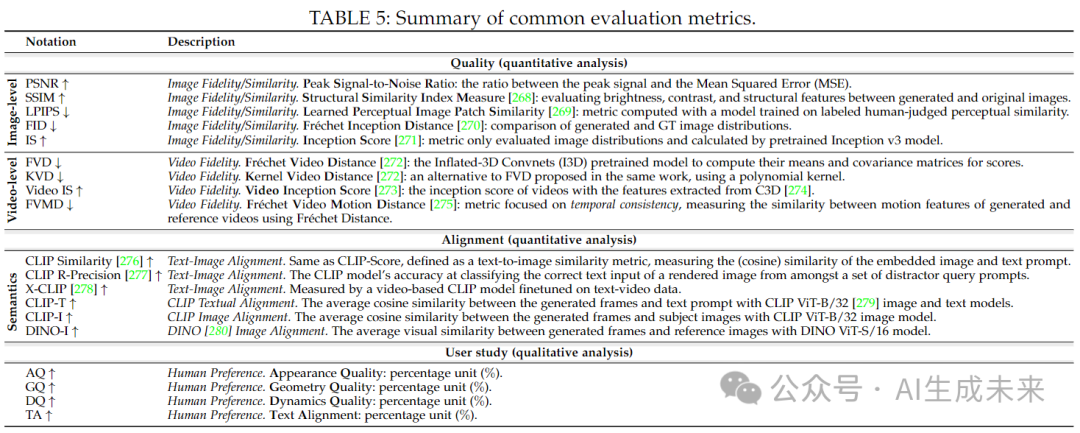
在本节中,总结了 2D、视频、3D 和 4D 生成中常用的数据集(见表 4)。随后,我们在表 5 中呈现了统一且全面的评估指标总结。
对于定量分析,从两个角度评估指标:
- 质量(Quality):评估合成数据的感知质量,与输入条件(如文本提示)无关。
- 一致性(Alignment):衡量生成数据与用户期望输入之间的匹配程度。
对于定性分析,生成结果的视觉质量在评估方法中起着关键作用。因此,引入了一些基于人类偏好的指标,以作为用户研究的参考,从而更有效地进行定性分析,提供更具说服力的评估结果。
5 未来方向
尽管 2D、视频和 3D 生成取得了重大进展,但 4D 生成仍面临重大挑战。这些困难源于空间和时间维度的复杂结合。在 2D 生成中,主要挑战仍然是提高现实感和生成内容的多样性。在视频生成中,关键问题在于建模长期的时间动态,并确保帧之间的平滑过渡。在 3D 生成中,平衡高质量输出与计算效率仍然是核心问题。解决这些挑战对于 4D 生成至关重要,因为它建立在这些既有技术的基础上。
以下是 4D 生成的主要未来方向,说明了如何解决这些问题不仅有助于 4D 模型的发展,同时也推动 2D、视频和 3D 生成的进步。
多模态生成
生成多样且合理的 4D 内容,并捕捉现实世界动态的固有变化性,是一个重大挑战。由于现实世界的场景通常是多模态的,当前的生成模型往往难以捕捉这种多样性,并倾向于生成不真实的结果。尽管条件生成(Conditional Generation)或隐空间建模(Latent Space Modeling)等技术正在被探索,但在 4D 生成中同时实现多样性与现实感仍然是一个未解决的问题。
时间一致性与连贯性
确保帧之间的平滑、真实过渡是 4D 生成中的重要挑战。与静态 3D 生成不同,4D 生成需要在多个时间步中保持形状、纹理和运动的一致性。特别是在长序列中,闪烁(Flickering)或不自然的变形等伪影(Artifacts)很容易出现。如何开发既能强制执行时间一致性、又不会牺牲细节和真实感的方法,仍然是一个悬而未决的问题。
物理与动态建模
真实的 4D 生成需要准确建模物理交互,如碰撞、形变和流体动力学。在生成模型中引入物理约束极具挑战性,因为这通常涉及求解复杂的微分方程或实时模拟交互。如何在真实性与计算效率之间取得平衡,仍然是一个开放性问题。
场景泛化能力
4D 生成模型通常难以在不同场景下泛化,例如面对不同的物体类型、运动模式或环境条件时。这是因为动态 3D 内容的变化性极高,而训练数据集的多样性却较为有限。如何开发无需大量重新训练就能适应未知场景的模型,是一个亟待解决的挑战。
控制与可编辑性
赋予用户灵活的 4D 生成控制能力(如指定运动轨迹或编辑动态内容)是一个具有挑战性的问题。当前的方法往往缺乏细粒度控制,导致难以生成满足特定需求的内容。开发直观的交互式编辑界面和高效的 4D 编辑算法,仍然是一个开放研究领域。
高计算成本
4D 生成涉及同时建模空间和时间维度,需要处理和存储大量数据。这导致高昂的计算和内存需求,使得实时或大规模 4D 生成变得困难。为了克服这一挑战,需要高效的压缩技术和可扩展的架构。
6 结论
本综述回顾了跨外观(Appearance)、动态(Dynamics)和几何(Geometry)维度的多模态生成模型在模拟现实世界方面的最新进展和挑战。还总结了常用数据集、其特性以及从不同角度评估生成质量的方法。
尽管该领域取得了重要进展,但在可扩展性(Scalability)、时间一致性(Temporal Coherence)和动态适应性(Dynamic Adaptability)方面仍然存在挑战。提出了一些开放性问题,以引导未来的研究朝着更逼真的真实世界模拟方向发展。
参考文献
[1] Simulating the Real World: A Unified Survey of Multimodal Generative Models
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号