ICML25|TQNet:如何把时序中的周期性纳入注意力机制

ICML25|TQNet:如何把时序中的周期性纳入注意力机制

科学最Top
发布于 2025-08-25 11:01:26
发布于 2025-08-25 11:01:26

论文标题:Temporal Query Network for Efficient Multivariate Time Series Forecasting
论文链接:https://arxiv.org/abs/2505.12917
(后台回复“交流”加入讨论群,回复“资源”获取2024年度论文讲解合集)
CycleNet与TQNet的关系
最近一直在看CycleNet的论文和代码实现,这边刚看完CycleNet立马发现了这篇ICML25的文章,两个工作相差一年,可以肯定第二篇TQNet十有八九是受到了CycleNet的启发,并把周期循环的思想继承下来运用到了Transformer网络结构中。
01 CycleNet
为了更好地理解TQNet,我们有必要先回顾一下CycleNet的思路和模型结构。如图1所示,其核心思路是建模数据中的周期性模式,并假定未来还会重复这种周期模式。
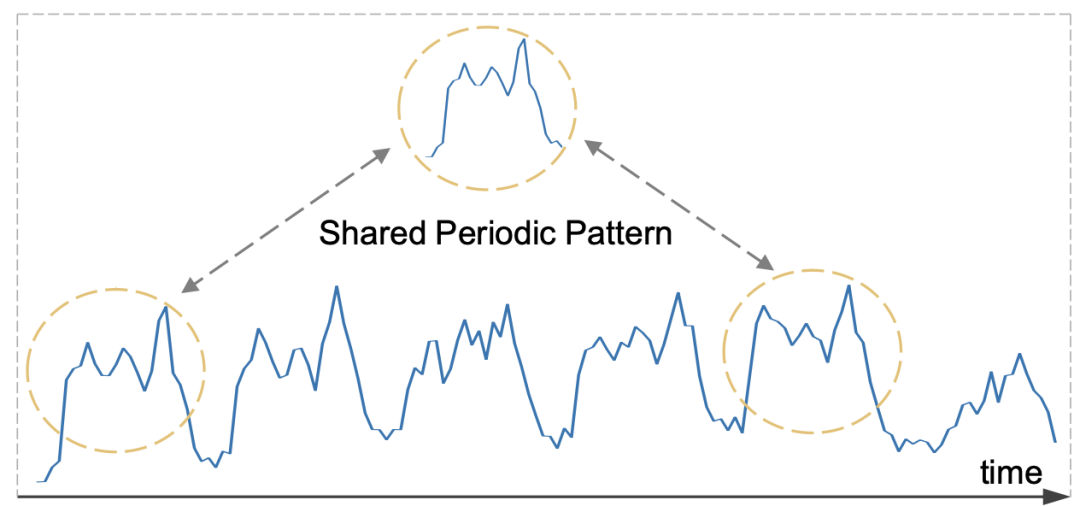
图1 具有显著周期模式的时间序列数据可视化
在这样的前提下,CycleNet构造了以线性模型为骨干网络的预测模型。通过构造一个可学习的网络层拟合时序中的周期特性,然后用原始序列减去周期项;然后,用MLP/Linear模型预测残差;最后把残差预测结果和未来的周期项相加得到预测结果。思路非常容易理解。
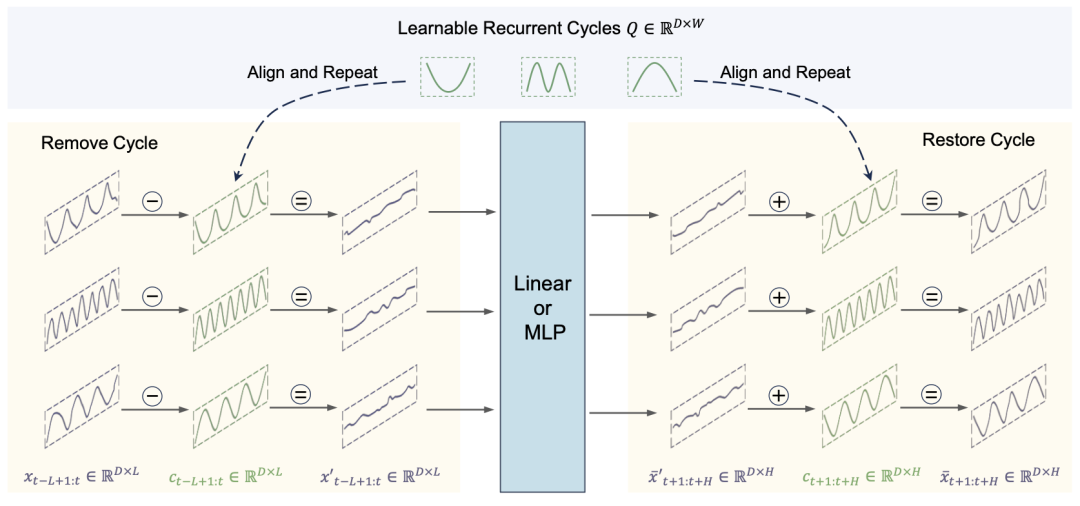
图2 CycleNet的模型结构图
此外,代码实现过程也很简单清晰,如图下所示,首先,CycleNet对输入的时间序列数据实例归一化(RevIN);然后,学习循环周期项,并从输入序列中移除该周期分量得到残差分量,随后将残差分量输入Linear或MLP骨干网络,得到残差分量的预测结果;最后,生成与预测 horizon匹配的周期分量,与残差预测结果叠加,最终得到预测值。
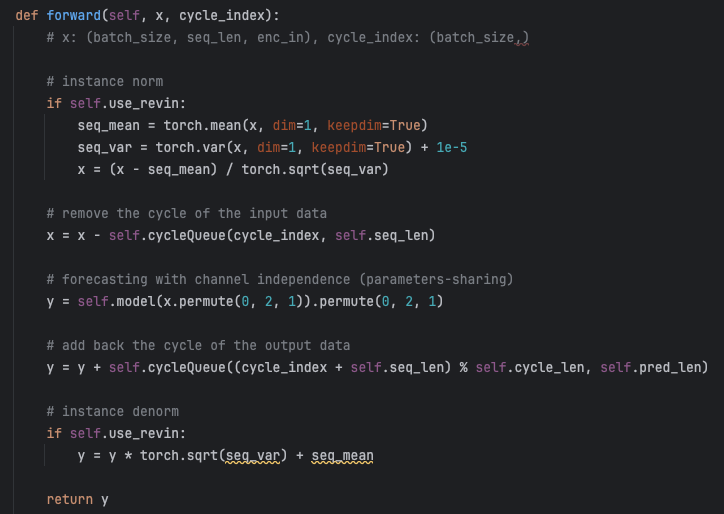
图3 CycleNet的核心代码实现
CycleNet的不足是假设所有样本共享一个周期,但实际每个样本周期往往不一致;其次依赖于先验特征确定周期长度,缺乏自动确定最优周期的能力,原文使用ACF技术确定周期,但该方法存在一定局限性,我自己实验的结果是ACF并不能找到最佳周期(这块我计划单独出一篇文章总结ACF的使用~)。
02 TQNet
TQNet继承了CycleNet的思路,但在骨干网络、注意力机制设计方面进行改进,在注意力机制中引入周期性偏移的可学习向量作为查询(Query),同时从原始输入数据中提取键(Key)和值(Value),实现全局与局部相关性的融合,两者的异同可总结为以下表格。
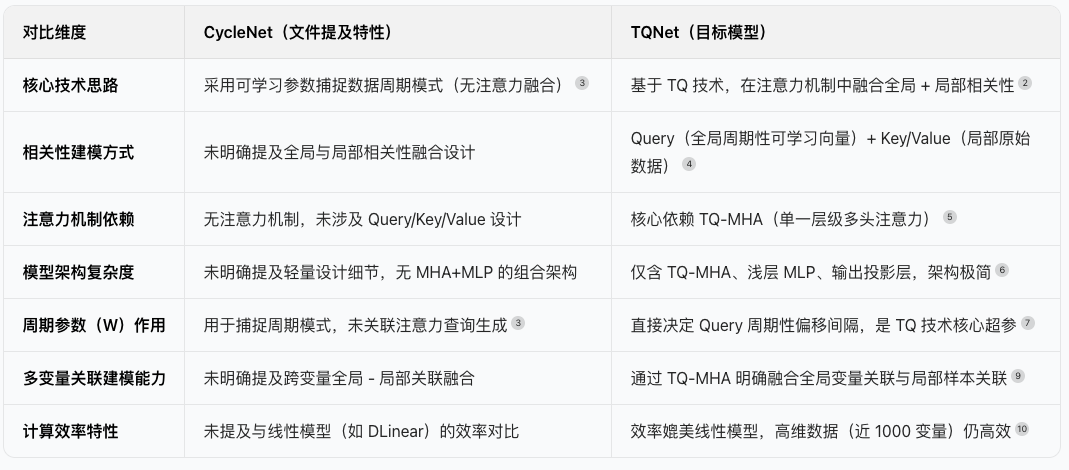
TQNet模型
01 问题引入
首先,TQNet的全称是时间查询网络(Temporal Query Network, TQNet),TQNet解决的是多变量时间序列预测(MTSF)中变量间相关性建模困难(受非平稳扰动导致局部与全局相关性偏差)及模型精度与计算效率难以平衡的问题。
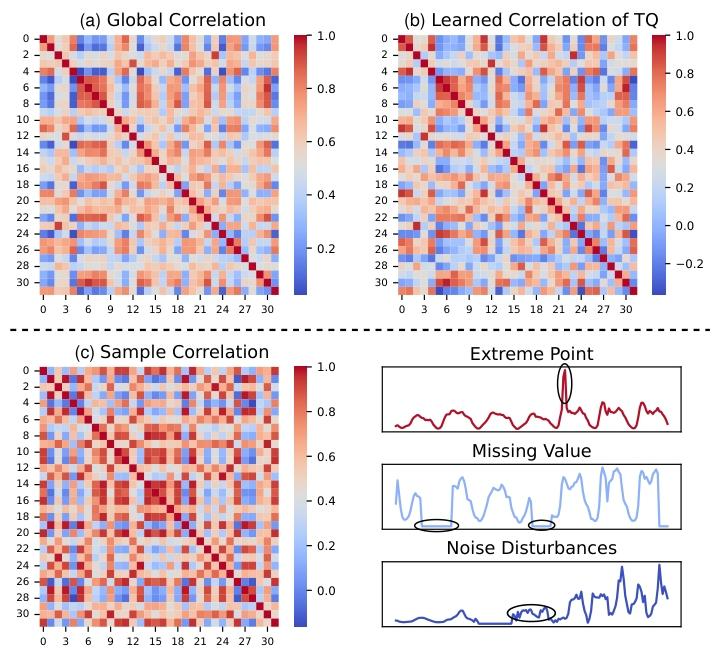
图4 变量间相关性可视化建模
上图4中,(a)基于整个训练集得出的全局相关性;(b)是TQNet学习到的相关性;(c)单个样本的相关性 —— 这类相关性可能会受到非平稳扰动的干扰,例如极端值、缺失数据与噪声。通过对比(a)图与(b)图可发现,TQ 技术能有效捕捉全局相关性结构;而(c)图则体现了样本级相关性的不稳定性。
02 模型结构
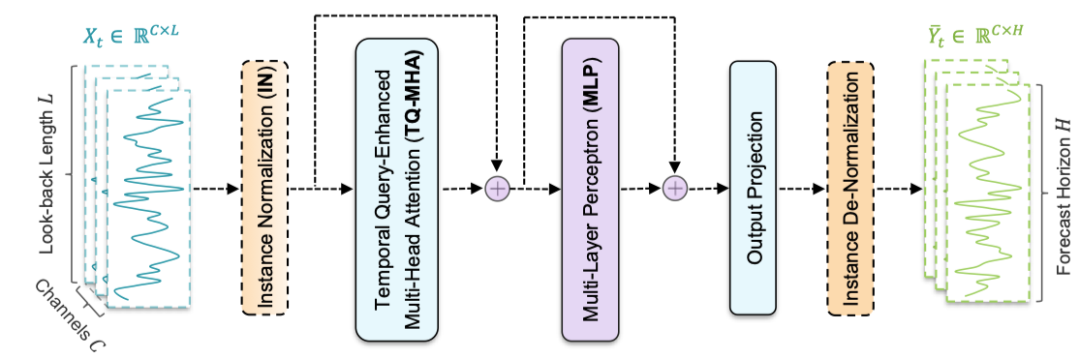
图5 TQNet的模型结构
如图5所示,TQNet模型结构可拆解为以下关键模块,输入数据会先经过实例归一化处理,使得数据更加平稳,减少数据分布偏移的干扰;然后是时间查询增强的多头注意力(TQ-MHA),工作逻辑如下:
- Query 生成:依据数据集周期性(超参数 W 定义,如日 / 周周期),从可学习参数矩阵中,通过 “当前时间步 t 对 W 取余” 确定起始索引,截取与输入回溯窗口长度一致的片段作为 Query,用于捕捉全局稳定的变量相关性。
- Key 与 Value 生成:直接从经实例归一化的原始输入序列中提取 Key 和 Value,保留单一样本的局部特异性变量相关性,为全局与局部相关性融合提供基础。
- 注意力计算与融合:通过单一层级多头注意力机制,计算 Query 与 Key 的相似性以确定权重、加权 Value 得到初步输出,再引入残差连接(叠加原始输入序列),增强训练稳定性并保留原始特征,最终输出多变量关联特征。
最后,多层感知机(MLP)模块接收 TQ-MHA 输出的多变量关联特征,通过两个全连接层(层间插入 GeLU 激活函数)且带残差连接的结构、构,建模时间维度依赖关系;进行投影和输出。
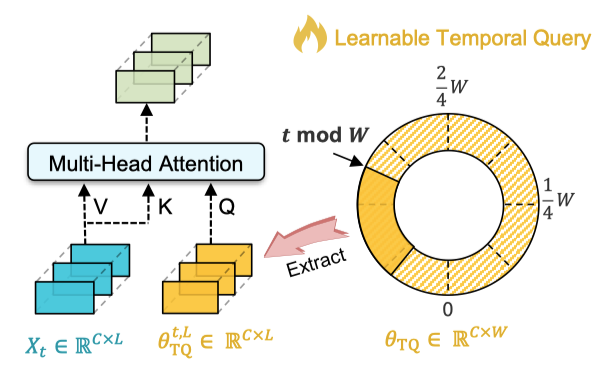
图6 时间查询增强的多头注意力(TQ-MHA)结构
图 6 呈现 TQ 技术构建查询(Query)的过程:先初始化与变量数、周期长度相关的可学习参数,再依据 “当前时间步对周期长度取余” 确定起始索引,从可学习参数中截取与输入回溯窗口长度一致的片段作为 Query,同时以原始输入序列生成键(Key)和值(Value),三者共同参与多头注意力计算。
模型结果
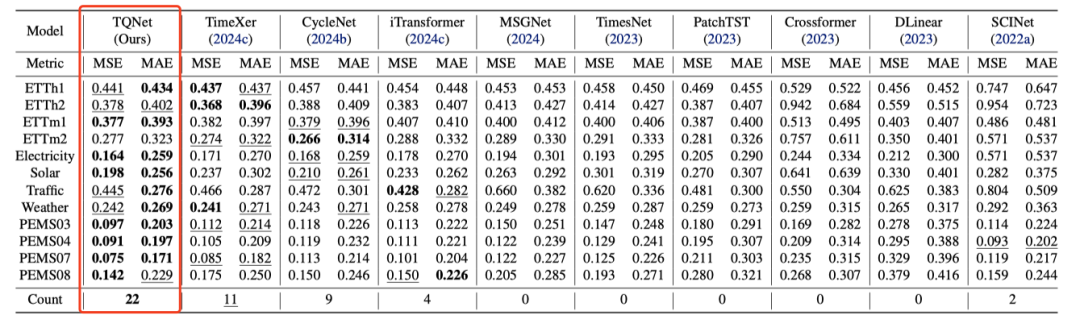
TQNet 整体实现当前最优预测精度,尤其在 Electricity、PEMS 系列等高维数据集(变量数超 100)上优势显著,凸显其处理复杂多变量数据的能力。
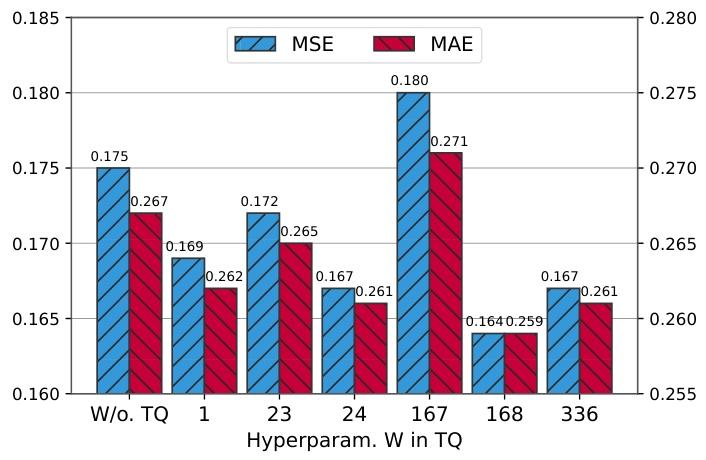
图7 周期长度W的影响
图7讨论了周期长度W的影响。W=168时,TQNet性能最优;W匹配日周期(W=24)时性能次之,W为非真实周期(如23、167)时性能下降,W为1或周周期整数倍(336)时仍有一定竞争力。
W怎么来的?一是依据数据集的先验知识(如已知的日、周等周期性规律,参考 CycleNet 的设定逻辑);二是借助计算方法(如自相关函数 ACF)识别数据的稳定周期。
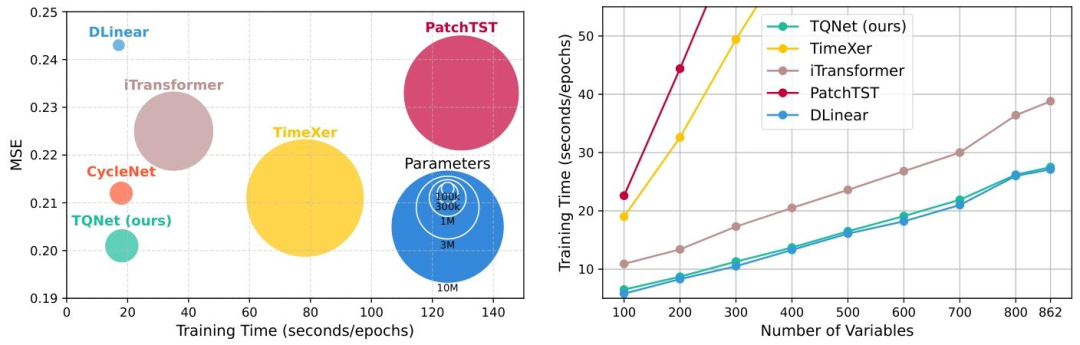
图8 参数量与训练时间对比
参数量与训练时间对比。TQNet精度最优且参数、训练时间远少于 iTransformer 等模型;右侧在 Traffic 数据集上,TQNet 即便变量数达 862,训练时间仍接近线性模型 DLinear,验证其兼顾精度与效率。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号