数学方法中模糊综合评价如何模块化的转化成代码
原创

模型简介
模型名称:模糊综合评价
- 核心问题类型:评价类
- 核心思想和适用场景
- 核心思想1. \*\*先拆 “大目标”\*\*:把要评价的事儿(比如 “选哪个手机好”)拆成多个小维度(比如 “性价比”“续航”“拍照”);2. \*\*给 “小维度” 称重\*\*:按重要程度给每个小维度分配权重(比如你更看重续航,就给续航更高的权重);3. \*\*“柔性打分 + 综合算账”\*\*:对每个小维度,不打固定分(比如 80 分),而是说 “属于‘好’的程度有 70%,‘一般’的程度有 30%”(这就是 “模糊” 的体现),最后结合权重算出综合评价结果。- 适用场景: - - 个人决策:选专业、选工作、选家电(无统一客观标准,需权衡多个主观关注的点)。 - 企业 / 项目决策:项目选址(需考虑成本、交通、政策)、供应商选择(需对比质量、价格、交付速度)。 - 综合评价:评选优秀员工(需兼顾业绩、团队协作、考勤)、评估城市宜居度(需考虑教育、医疗、环境)。- 核心步骤与流程图:
- 步骤 1:确定 “评价目标” 与 “评价对象” 先明确两个核心: - \*\*评价目标\*\*:最终要判断的事儿(如 “奶茶口感优劣”“手机性价比高低”); - \*\*评价对象\*\*:具体要打分的事物(如 “奶茶 A、奶茶 B”“手机 X、手机 Y”)。- 步骤 2:构建 “评价指标体系”(拆维度) - 把抽象的 “目标” 拆成可具体判断的小维度(即 “评价指标”),形成层级结构。 - 示例:“奶茶口感” 可拆为 3 个指标 ——甜度合适度、茶底香味、小料口感。- 步骤 3:确定 “指标权重”(给维度称重) - 不同指标的重要性不同,需用方法(如层次分析法、专家打分法)给每个指标分配 “权重”(所有指标权重之和为 1)。 - 示例:若更看重茶底,权重可设为 ——甜度(0.2)、茶底(0.5)、小料(0.3)。- 步骤 4:建立 “模糊评价矩阵”(柔性打分) 1. \*\*确定评价等级\*\*:定义打分的 “等级标准”(如 “优秀、良好、一般、差”); 2. \*\*单指标模糊评价\*\*:对每个 “评价对象”,判断它在每个 “指标” 上属于各 “等级” 的 “隶属度”(即 “符合程度”,所有等级隶属度之和为 1); 3. \*\*整理成矩阵\*\*:将所有单指标评价结果整理成 “模糊评价矩阵”。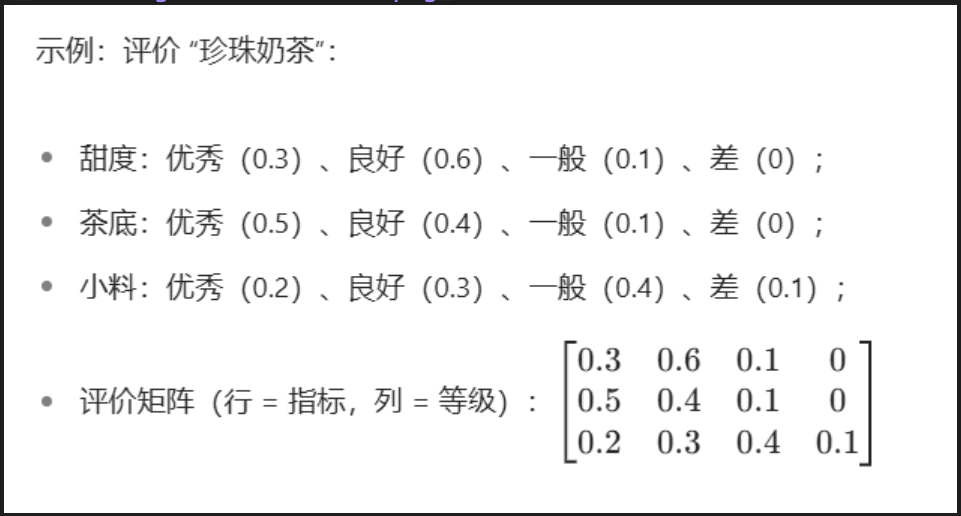- 步骤 5:进行 “模糊合成运算”(算综合分) - “指标权重向量” 与 “模糊评价矩阵” 相乘(常用 “加权平均法”),得到 “综合模糊评价向量” - 权重([0.2, 0.5, 0.3])× 评价矩阵 = 综合向量([0.38, 0.41, 0.17, 0.03]) - 含义是:珍珠奶茶 “良好”(0.41)的符合度最高,其次是 “优秀”(0.38)。- 步骤 6:去模糊化(出最终结论) - \*\*最大隶属度法\*\*:选综合向量中数值最大的等级(如示例中 “良好”,因 0.41 最大); - \*\*加权平均法\*\*:给各等级赋值(如优秀 = 4、良好 = 3、一般 = 2、差 = 1),用综合向量加权计算得分(示例:4×0.38 + 3×0.41 + 2×0.17 + 1×0.03 = 3.2)。‘关键公式:

image.png

image.png
- 二、核心 1:模糊评价矩阵(单指标柔性打分)

image.png
- 三、核心 2:模糊合成运算(综合评价)

image.png
四、核心 3:去模糊化(明确结论)
将综合向量 B 转化为具体结果,常用两种公式:

image.png
总结逻辑链

image.png
% 模糊综合评价示例:评价三款奶茶的口感
% 步骤1:定义基本要素
clear; clc;
% 评价对象(3款奶茶)
object\_names = {'珍珠奶茶', '果茶', '奶盖茶'};
m = length(object\_names); % 对象数量
% 评价指标(4个维度)
index\_names = {'甜度合适度', '茶底香味', '小料口感', '顺滑度'};
n = length(index\_names); % 指标数量
% 评价等级及赋值(4个等级)
grade\_names = {'优秀', '良好', '一般', '差'};
grade\_values = [4, 3, 2, 1]; % 用于去模糊化的量化值
k = length(grade\_names); % 等级数量
% 步骤2:确定指标权重(可通过层次分析法或专家打分获取)
% 这里假设权重向量(总和为1)
W = [0.25, 0.3, 0.25, 0.2]; % 甜度:25%, 茶底:30%, 小料:25%, 顺滑度:20%
disp('指标权重向量 W = ');
disp(W);
% 步骤3:建立模糊评价矩阵(每行是一个指标对各等级的隶属度,每行和为1)
% 这里为3款奶茶分别构建评价矩阵(实际应用中可通过调研/打分获取)
% R{i} 表示第i款奶茶的评价矩阵(n行k列)
R{1} = [0.3 0.6 0.1 0; % 珍珠奶茶的4个指标隶属度
0.5 0.4 0.1 0;
0.2 0.3 0.4 0.1;
0.4 0.5 0.1 0];
R{2} = [0.6 0.3 0.1 0; % 果茶的4个指标隶属度
0.4 0.5 0.1 0;
0.1 0.2 0.5 0.2;
0.5 0.4 0.1 0];
R{3} = [0.2 0.3 0.4 0.1; % 奶盖茶的4个指标隶属度
0.3 0.5 0.2 0;
0.6 0.3 0.1 0;
0.2 0.4 0.3 0.1];
% 步骤4:模糊合成运算(加权平均法)
for i = 1:m
% 综合评价向量 B = W \* R(加权求和)
B = W \* R{i}; % 1×k向量,每个元素是对应等级的综合隶属度
comprehensive\_result{i} = B;
% 步骤5:去模糊化(两种方法)
% 方法1:最大隶属度法
[max\_value, max\_idx] = max(B);
max\_grade{i} = grade\_names{max\_idx};
% 方法2:加权平均法(量化得分)
score{i} = B \* grade\_values'; % 与等级赋值向量相乘得到得分
end
% 输出结果
disp('------------------------ 评价结果 ------------------------');
for i = 1:m
fprintf('\n【%s】的评价结果:\n', object\_names{i});
fprintf('1. 综合隶属度向量:'); disp(comprehensive\_result{i});
fprintf('2. 最大隶属度等级:%s\n', max\_grade{i});
fprintf('3. 加权量化得分:%.2f\n', score{i});
end
% 比较所有对象的得分并排序
scores = cell2mat(score);
[~, rank\_idx] = sort(scores, 'descend');
fprintf('\n------------------------ 排名结果 ------------------------\n');
for i = 1:m
fprintf('第%d名:%s(得分:%.2f)\n', i, object\_names{rank\_idx(i)}, scores(rank\_idx(i)));
end1. B = W \* R{i}; % 1×k向量,每个元素是对应等级的综合隶属度
- **作用**:执行模糊合成运算,得到 “综合评价向量”
- **原理**:
- `W` 是 1×n 的指标权重向量(如 `[0.25, 0.3, 0.25, 0.2]`)- `R{i}` 是 n×k 的模糊评价矩阵(n 个指标,k 个等级,每行是该指标对各等级的隶属度)- 矩阵乘法 `W \* R{i}` 本质是\*\*加权求和\*\*:每个等级的综合隶属度 = 各指标权重 × 该指标对该等级的隶属度,再求和- **结果**:
B是 1×k 的向量(如[0.38, 0.41, 0.17, 0.03]),每个元素代表评价对象 “属于某等级的综合程度”
2. comprehensive\_result{i} = B;
- **作用**:保存综合评价向量,便于后续分析或输出
- 例如:对 “珍珠奶茶”,
comprehensive\_result{1}就存储着它的综合隶属度向量[0.38, 0.41, 0.17, 0.03]
3. 方法 1:最大隶属度法([max\_value, max\_idx] = max(B); max\_grade{i} = grade\_names{max\_idx};)
- **作用**:从综合向量中找到 “最符合的等级”
- **步骤**:
- `max(B)` 找到 `B` 中数值最大的元素(如 `0.41`),并返回其位置 `max\_idx`(如 2)- `grade\_names{max\_idx}` 对应到等级名称(如 `grade\_names{2} = "良好"`)- **意义**:直接给出评价对象 “最接近哪个等级”,简单直观
4. 方法 2:加权平均法(score{i} = B \* grade\_values';)
- **作用**:将模糊结果转化为具体分数,便于横向比较
- **原理**:
- `grade\_values` 是等级的量化赋值(如 `[4, 3, 2, 1]` 代表优秀 = 4 分、良好 = 3 分...)- `B \* grade\_values'` 是\*\*加权平均计算\*\*:用综合隶属度作为权重,对等级分数加权求和- **示例**:
若 `B = [0.38, 0.41, 0.17, 0.03]`,`grade\_values = [4,3,2,1]`,则: `score = 0.38×4 + 0.41×3 + 0.17×2 + 0.03×1 = 3.2`(接近 “良好” 等级)- **意义**:将模糊评价转化为可比较的数字,方便排序(如比较三款奶茶的得分高低)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号