day 6
原创
day 6
原创
用户11775359
发布于 2025-08-12 11:42:10
发布于 2025-08-12 11:42:10
复习
ggplot2特殊语法:列名不带引号,函数之间用+号
ggplot2 属性设置的统一设置和映射设置
统一设置 参数是geom_foution的参数
映射设置 参数是aes的参数
1、玩转字符串
字符串长度 str_length()
字符串拆分 str_split()
按照位置提取字符 str_sub()
字符检测 str_detect()
字符替换 :
str_replace(只替换字符串里第一个对象)
str_replace_all(替换字符串里所有满足的对象)
字符删除 :
str_rempove()
str_rempove_all()
2、玩转数据框
arrange(test, Sepal.Length) #数据框整体根据某列数值从小到大排序;必须无双引号,不然不报错也不执行
arrange(test, desc(Sepal.Length)) #从大到小
unique()#向量去重复的函数
duplicated()#判断向量中每一个值是否发生重复的函数;重复定义:从左往右第二次到第多次出现算重复
# 1.多次赋值,产生多个中间的变量
x1 = select(iris,-5)#减去第5列
x2 = as.matrix(x1)
x3 = head(x2,50)#截取前50行
pheatmap::pheatmap(x3)
# 2. 嵌套,代码不易读
pheatmap::pheatmap(head(as.matrix(select(iris,-5)),50))
# 3.管道符号传递,简洁明了
iris %>%
select(-5) %>%
as.matrix() %>%
head(50) %>%
pheatmap::pheatmap()
#弊端:当数据量超级大时,管道符号导致运算较慢一丢丢3、条件与循环
#模版:if(条件判断得出一个逻辑值,**不支持逻辑值向量**,不能批量){执行的命令}
#if(){代码块1}else{代码块2}
#R语言三大精华:向量化运算,%in%,ifelse函数(**支持逻辑值或逻辑值向量**)
ifelse(x,yes,no)
# ifelse()+str_detect(),王炸 实现试验组及对照组的分组,重要
samples = c("tumor1","tumor2","tumor3","normal1","normal2","normal3")
k1 = str_detect(samples,"tumor");k1
ifelse(k1,"tumor","normal")
k2 = str_detect(samples,"normal");k2
ifelse(k2,"normal","tumor")4、长脚本管理方式

if函数可折叠
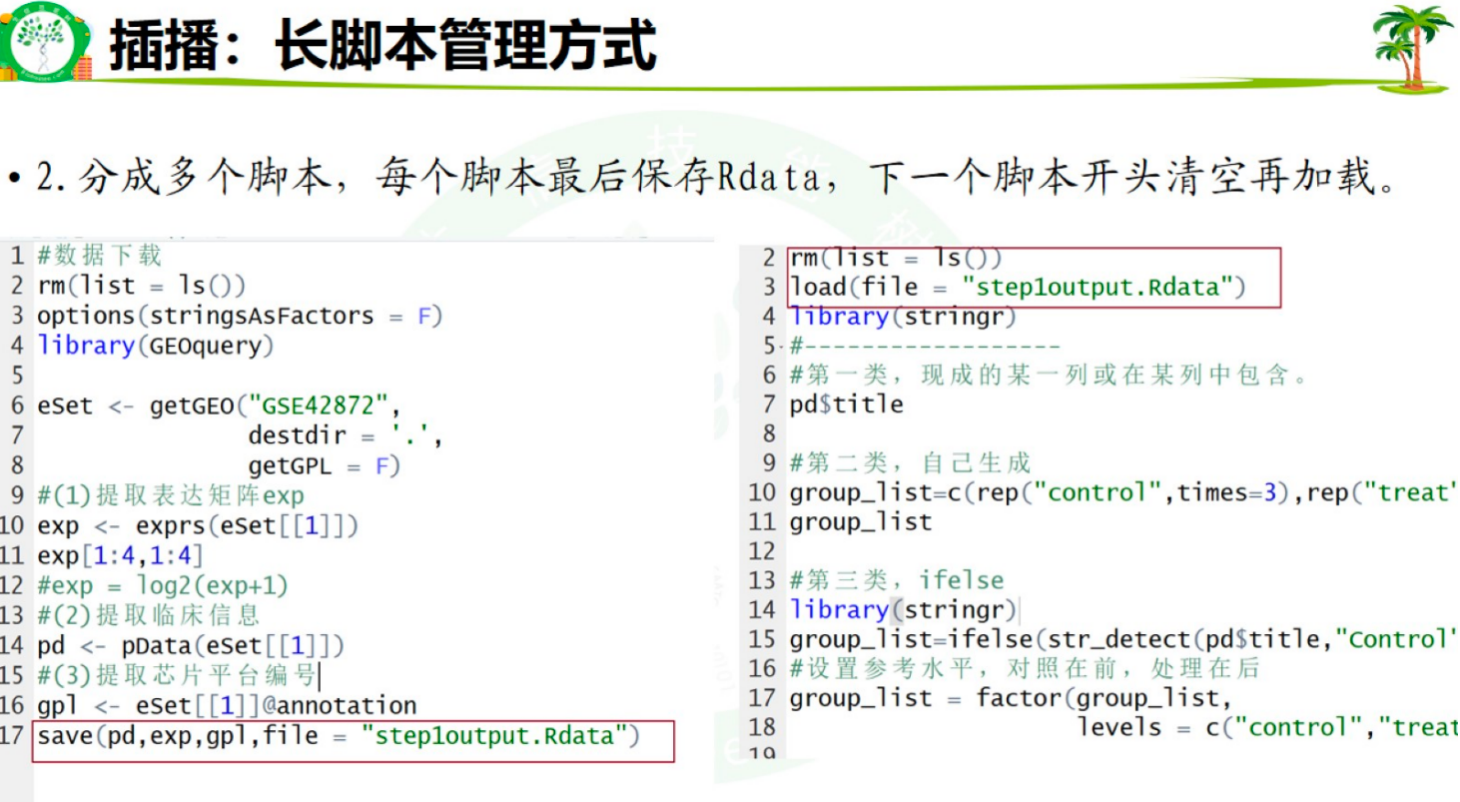
每个脚本最后保存Rdata,下一个脚本清空再加载Rdata

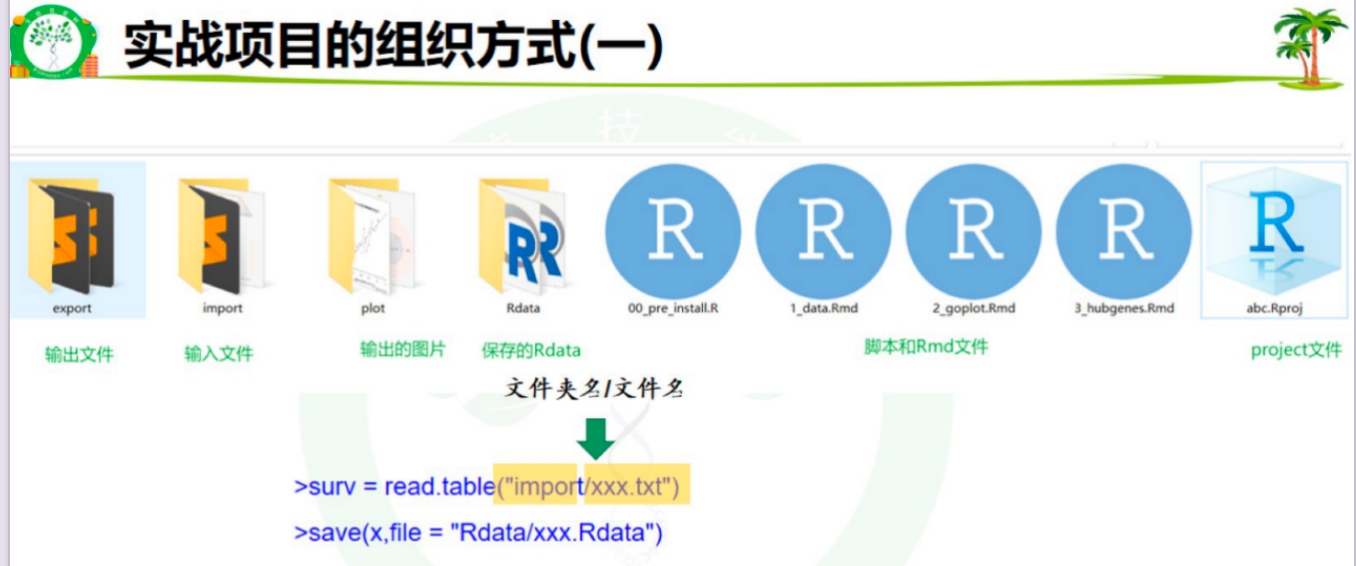
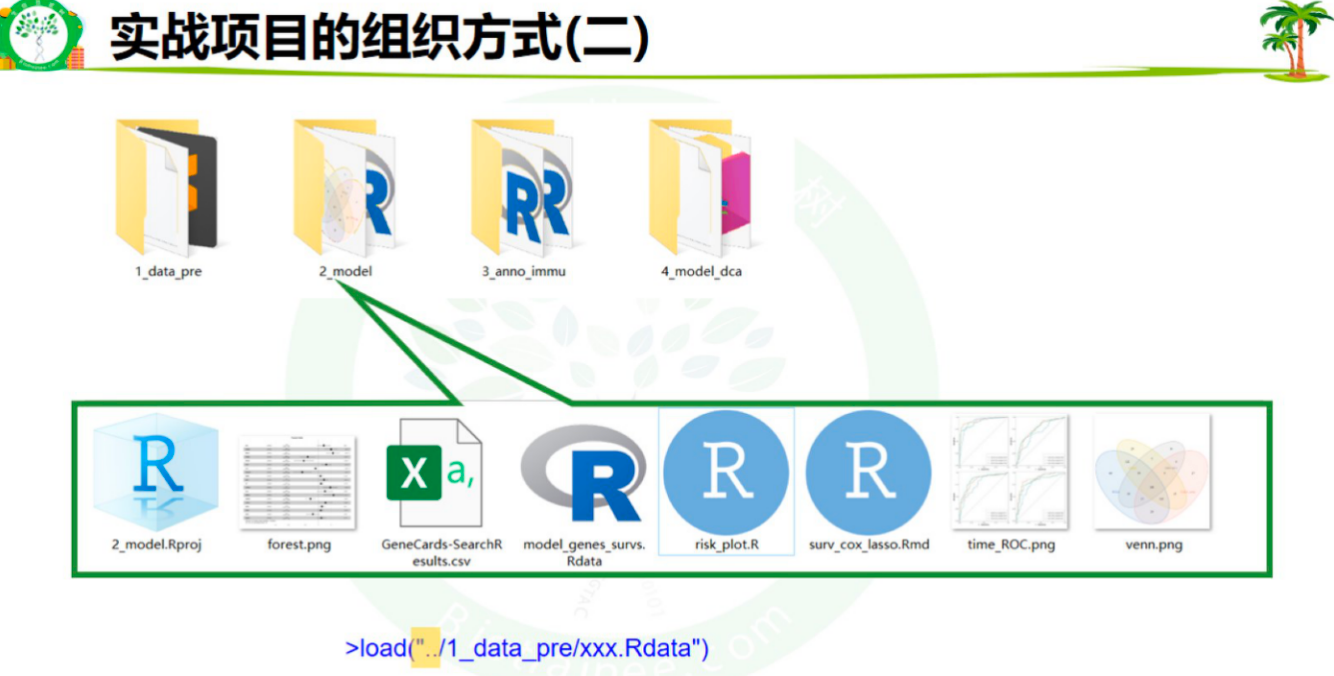
4、实际项目的组织方式
注意:放在工作目录的子文件夹 不能直接读取 不过tab及空格补全时 会自动添加子文件夹名称
工作目录(项目名)
工作目录下的子文件及文件夹:
1/输入文件:import;
2/输出图片:plot ;
3/Rdata文件夹 ;
4/脚本: x.R;
5/Rmd文件 x.Rmd ;
6/project文件 x.Proj
说明:Rmd文件(R Markdown文件)是R语言环境中用于创建动态文档的核心文件格式,其核心功能是将代码、文本、图表和计算结果集成在一个文档中,并支持一键输出为多种格式的报告
管理项目使用相对工作目录是最佳方式
5、for循环
使用场景:批量装包;批量画图。
for( i in 1:4){
print(i)
}
#批量画图
par(mfrow = c(2,2))#画布分成2行2列
> for(i in 1:4){
+ plot(iris[,i],col = iris[,5])
+ }
#批量装包
pks = c("tidyr","dplyr","stringr")
for(g in pks){
if(!require(g,character.only = T))
install.packages(g,ask = F,update = F)
}6、两个数据框的链接
inner_join 取交集
full_join 全连接
left_join 左连接 左边的表更重要
right_join 右链接 右边的表更重要
表达矩阵画箱线图(老师跳过了)
7、一些优秀函数
1)match和order的使用场景
match函数:查找第一个向量(x)中的元素在第二个向量(table)中的首次出现位置,未匹配时返回NA或自定义值。
使用场景:1、数据对齐;2、值存在性检查(返回位置)
order函数功能:返回向量元素排序后的索引位置(从小到大),支持多列排序
使用场景:数据框排序、向量排序、多级排序
2)函数操作文件:file.create
8、常见报错
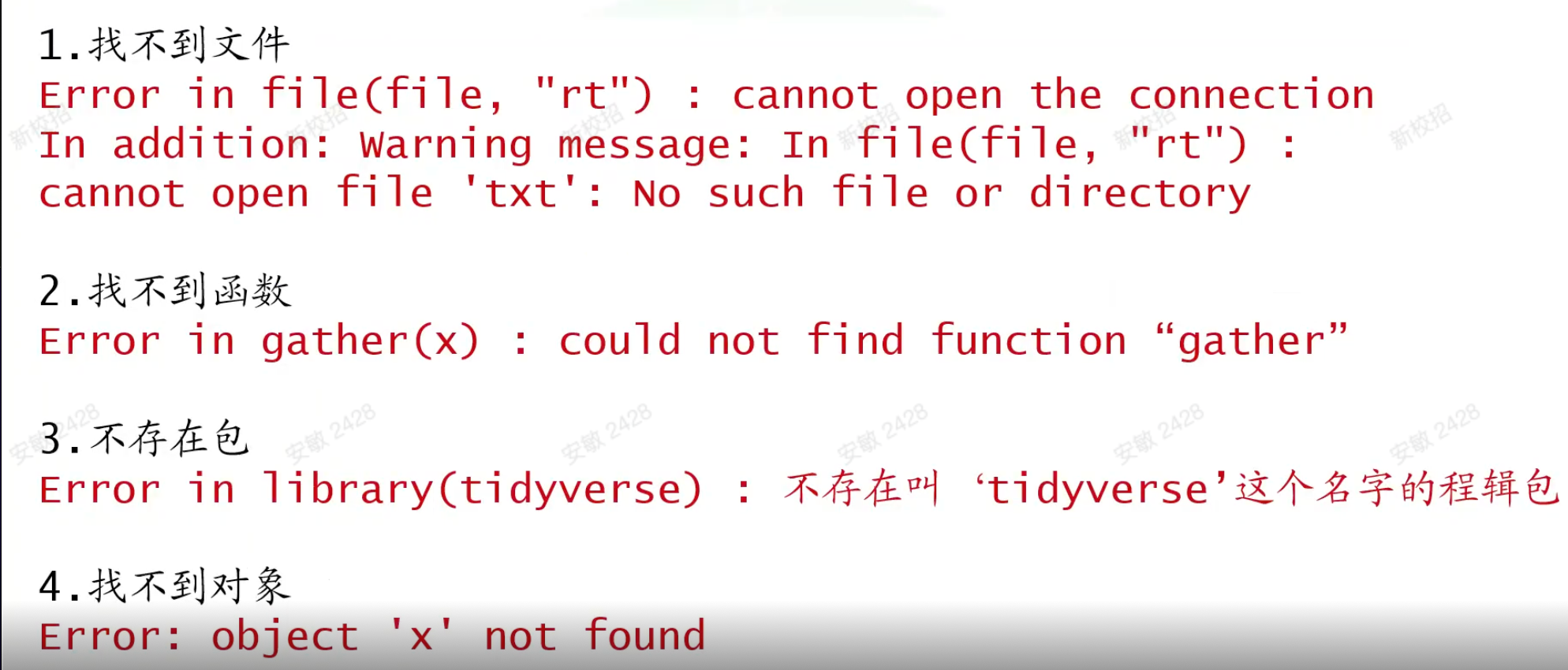
1. 找不到文件(Error in file(file, "rt"))
- 可能原因:
- 文件路径错误:文件不在当前工作目录下,或路径拼写错误。
- 文件名错误:文件名或扩展名输入错误(如应为"data.txt"却输入"txt")。
- 权限问题:文件被其他程序占用,或用户无读取权限。
- 解决方法:
- 使用
getwd()和setwd()确认并设置正确的工作目录。 - 检查文件名是否完整(包括扩展名),如
read.csv("data.csv")。 - 使用
file.exists("文件名")验证文件是否存在。
- 使用
2. 找不到函数(Error: could not find function "gather")
- 可能原因:
- 未加载包:函数所属的包未通过
library(tidyr)加载。 - 函数名拼写错误:如将
gather误输为Gather(R区分大小写)。 - 包未安装:未安装包含该函数的包。
- 函数已弃用:
gather()在tidyr中已被pivot_longer()替代。
- 未加载包:函数所属的包未通过
3. 不存在包(Error: 不存在叫‘tidyverse’这个名字的程辑包)
- 可能原因:
- 包未安装:从未安装过
tidyverse。 - 安装失败:网络问题或依赖包缺失导致安装未完成。
- 拼写错误:包名输入错误(如
tidyverse误写为tydiverse)。
- 包未安装:从未安装过
4. 找不到对象(Error: object 'x' not found)
- 可能原因:
- 对象未创建:变量
x未被赋值或创建。 - 作用域问题:在函数内尝试访问全局变量(或反之)。
- 拼写错误:对象名拼写不一致(如创建
X却调用x)。 - 数据框列名错误:尝试用
$访问不存在的列(如df$x但df无x列)。
- 对象未创建:变量

今日查缺补漏tips
代码的运行不能撤销,但是可以执行之前的步骤再来一次。
向量可以有名字,每个元素对应一个
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号