时序代码精读:NIPS24|CycleNet代码的精读笔记

时序代码精读:NIPS24|CycleNet代码的精读笔记

科学最Top
发布于 2025-08-11 10:21:42
发布于 2025-08-11 10:21:42
之前写过patch TST的代码精读笔记反响不错,趁着最近刚刚看完Cycle Net论文的代码,也一并记录一下这篇文章的核心代码实现过程,一来为了分享,二来也是为了沉淀学习笔记。
CycleNet概述
CycleNet这篇论文我反复读过多次,之前还做过论文解读,是我非常喜欢的一类拼idea新颖性的文章。先来回顾一下论文核心出发点,通过引入可学习的循环周期来显式建模时间序列数据中的固有周期模式,并对已建模周期的残差分量进行预测。
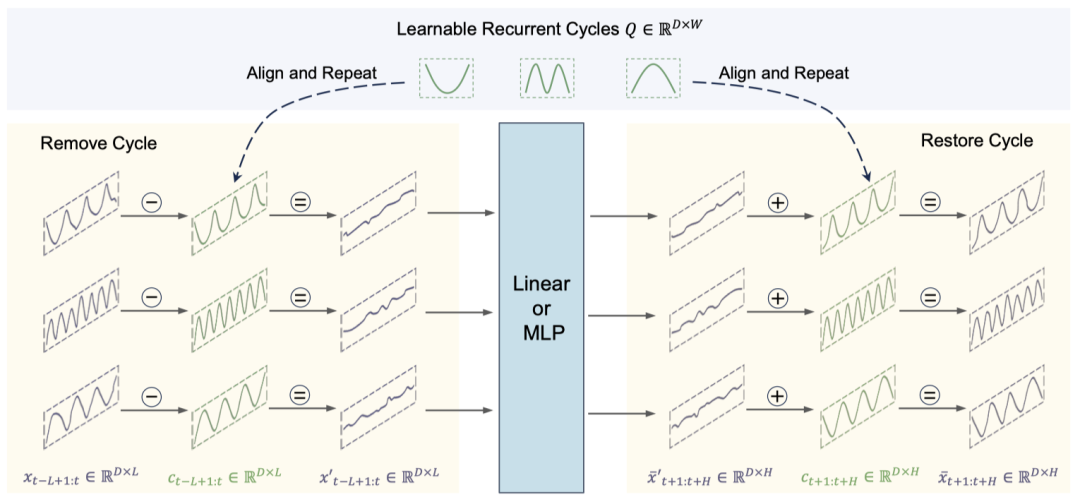
如图所示,说人话就是:先把原始时间序列分成循环项+残差项,假设周期是不变的,那么可以单独建模循环项,然后从原始序列减去循环项,只预测剩余的残差项,得到结果后再对齐未来的循环项并相加,就得到了最终的预测项。这里有一个前提,就是我们要预测的时间序列存在显著的周期性模式,并且这种周期性模式具有相对稳定性。
此外,论文还有一个特点是基于MLP/Linear,所以参数量极少、训练快,我自己跑下来效果确实比Patch TST、FITS等模型效果好,但不如今年的timeMixer++。不过综合考虑模型复杂程度,CycleNet绝对算四两拨千斤了,这也是吸引我去阅读论文源码的原因~
源代码
def forward(self, x, cycle_index):
# x: (batch_size, seq_len, enc_in), cycle_index: (batch_size,)
# instance norm
if self.use_revin:
seq_mean = torch.mean(x, dim=1, keepdim=True)
seq_var = torch.var(x, dim=1, keepdim=True) + 1e-5
x = (x - seq_mean) / torch.sqrt(seq_var)
# remove the cycle of the input data
x = x - self.cycleQueue(cycle_index, self.seq_len)
# forecasting with channel independence (parameters-sharing)
y = self.model(x.permute(0, 2, 1)).permute(0, 2, 1)
# add back the cycle of the output data
y = y + self.cycleQueue((cycle_index + self.seq_len) % self.cycle_len, self.pred_len)
# instance denorm
if self.use_revin:
y = y * torch.sqrt(seq_var) + seq_mean
return y先看forward函数,其中输入特征x的形状为(batch_size, seq_len, enc_in),分别表示batch大小、序列长度、输入特征维度;cycle_index是周期索引,形状为(batch_size,),表示每个样本在周期中的起始位置。这个cycle_index 很重要,作用是用来对齐周期。
x = x - self.cycleQueue(cycle_index, self.seq_len)
这一步就是从原始序列减去周期项,但是周期项需要单独建模,并且很容易理解,建模周期项需要两个参数:周期的起始位置cycle_index和周期的长度seq_len。
如何建模周期项?
class RecurrentCycle(torch.nn.Module):
# Thanks for the contribution of wayhoww.
# The new implementation uses index arithmetic with modulo to directly gather cyclic data in a single operation,
# while the original implementation manually rolls and repeats the data through looping.
# It achieves a significant speed improvement (2x ~ 3x acceleration).
# See https://github.com/ACAT-SCUT/CycleNet/pull/4 for more details.
def __init__(self, cycle_len, channel_size):
super(RecurrentCycle, self).__init__()
self.cycle_len = cycle_len
self.channel_size = channel_size
self.data = torch.nn.Parameter(torch.zeros(cycle_len, channel_size), requires_grad=True)
def forward(self, index, length):
gather_index = (index.view(-1, 1) + torch.arange(length, device=index.device).view(1, -1)) % self.cycle_len
return self.data[gather_index]首先,self.data是一个可学习的参数矩阵,形状为(cycle_len, channel_size),用于存储每个周期位置上的特征模式。
其次,由于index存储了每个序列的起始位置,那么通过index.view(-1,1)+
torch.arange(length).view(1, -1)就得到(cycle_len, channel_size)的索引矩阵,表示每个样本需要提取的周期位置,% self.cycle_len:确保索引在周期范围内循环。
最终,通过self.data[gather_index]提取对应位置的周期模式。
如何预测残差项?
这里比较简单,作者设计两类模型,分别是MLP和Linear,从效果来看MLP效果明显要好一些,预测得到未来的残差项后,通过cycle_index+seq_len 对齐得到未来的周期索引位置,就得到了最终的预测结果。
y = y + self.cycleQueue((cycle_index + self.seq_len) % self.cycle_len, self.pred_len)一些实验与思考
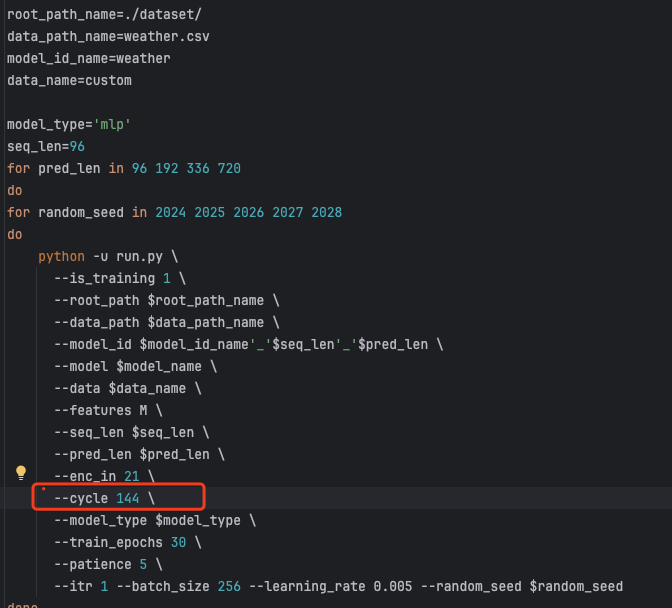
周期的敏感性问题
多数数据集的结果我都跑过,结果复现没有问题的,但通过做实验的过程中我也发现了一些可改进的点,比如我发现cyclenet对循环周期的设定异常敏感,以weather数据集为例,周期设置为144的效果是最好的,我猜测作者是花了时间测试出来的结果,并且你稍微修改一下周期,比如改成96,效果明显就不行。
复杂数据集适应性问题
对于复杂数据集,如交通数据集,效果不太理想(不如itransformer),可能是因为交通数据具有时空特征和时滞特征,需要更复杂的多通道关系建模,而 CycleNet 单层线性层或双层 MLP,无法充分捕捉复杂数据中的关系。
异常值/极值处理问题
如果数据跳变,破坏了原有周期性,效果不理想。
总结
anyway,cyclenet主要解决的是周期性模式的时序建模,并且实验可复现。其核心设计 —— 先从输入中移除学习到的周期模式,让模型专注于预测残差,再将周期成分回加到输出中,降低了预测任务的复杂度,且通过索引算术优化周期数据提取的方式,显著提升了计算效率,思路很新颖,推荐大家阅读论文和学习源码。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号