红薯搜索流量关键词采集,流量嘎嘎猛!
原创
红薯搜索流量关键词采集,流量嘎嘎猛!
原创
用户11763451
发布于 2025-07-27 01:36:56
发布于 2025-07-27 01:36:56
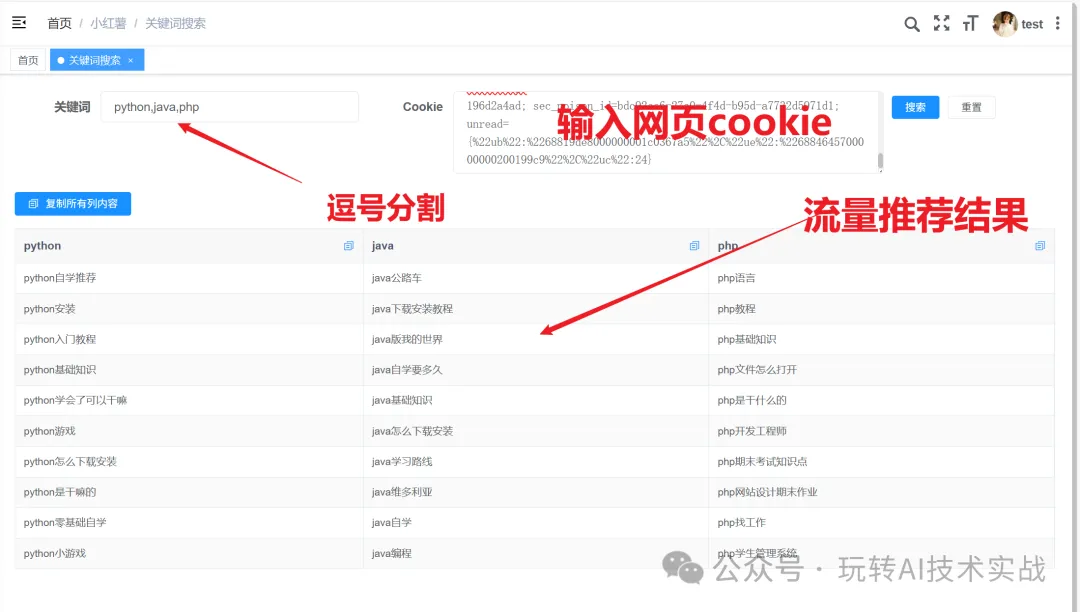
功能支持
1.支持输入多个关键词
2.支持一键复制流量关键词推荐结果
3.刷新页面,无需要重新输入cookie
界面如下
实现技术
python java node
Python 网络爬虫(Web Crawler)是一种自动化程序,它通过模拟浏览器的行为,从互联网上抓取信息。爬虫通过请求网页、分析页面内容并提取有用数据,广泛用于搜索引擎、数据分析、情报收集、价格监控等领域。
网络爬虫的基本工作原理
- 发送 HTTP 请求:爬虫向目标网站发送 HTTP 请求,获取网页内容。
- 解析网页内容:抓取到的网页一般是 HTML 格式的,通过解析 HTML 内容,提取出所需的数据。
- 提取数据:利用正则表达式、BeautifulSoup、lxml 或 Selenium 等工具从网页中提取有用信息,如文本、图片、链接等。
- 数据存储:将爬取到的数据存储到文件、数据库或其他存储媒介中,以供后续分析或使用
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号