AI 程序员的学习与发展方向你应该学习的知识


每个开发人员都应该知道的数据库索引类型
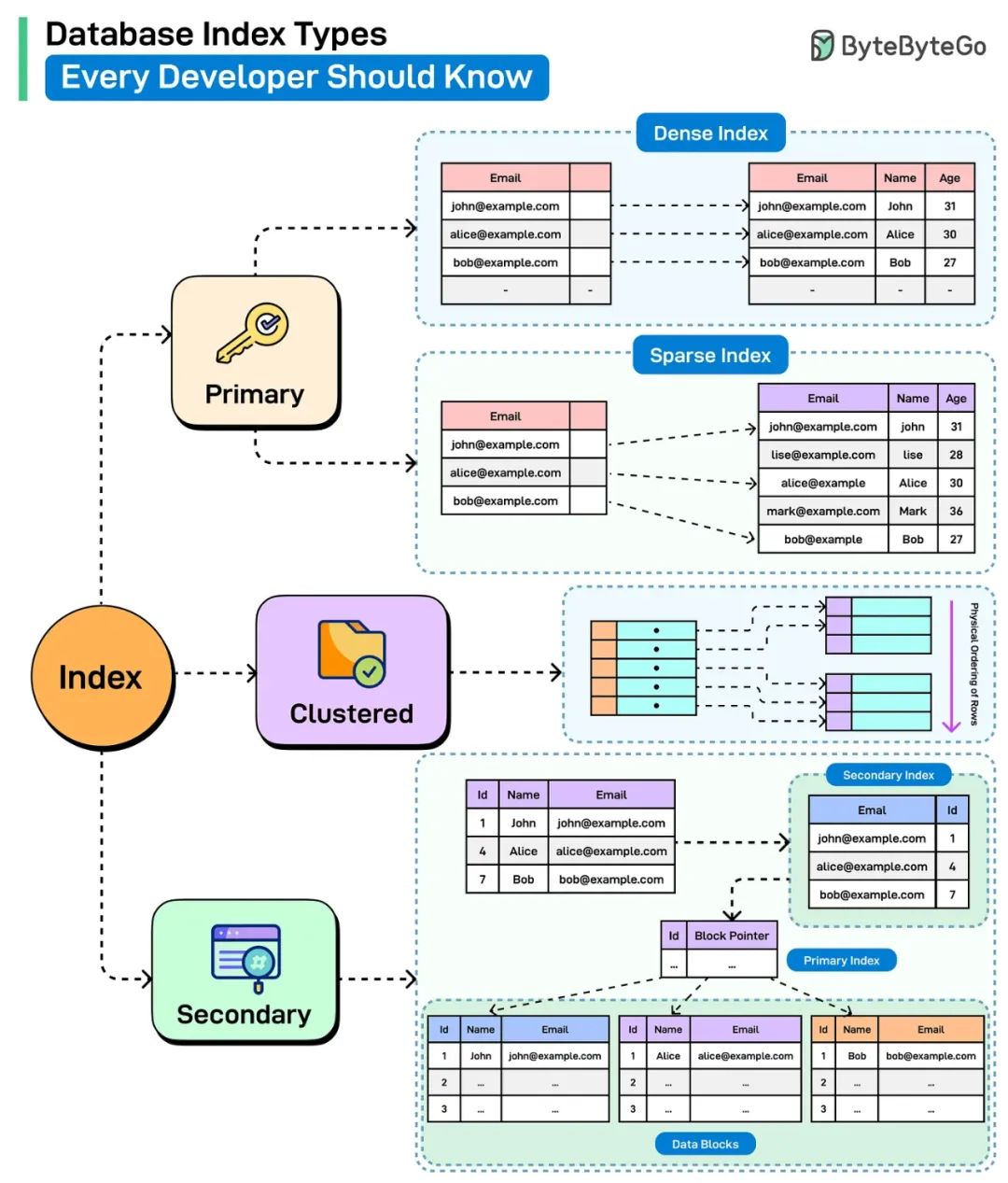
数据库索引是一种派生结构,它将列值映射到表中行的物理位置。让我们看看一些关键的索引类型:
- 主索引
在表上定义主键时,会自动创建此索引。此类索引可以是密集索引,也可以是稀疏索引,但在大多数情况下,稀疏索引是首选索引。
密集索引包含表中每一行的一个条目。另一方面,稀疏索引仅包含表中某些行的条目。
- 聚集索引
聚集索引确定表中行的物理顺序。一个表上只能存在一个聚集索引,因为数据一次只能按一个顺序存储。它非常适合范围查询、有序扫描和 I/O 效率。
- 二级索引
非聚集索引是一种单独的结构,它保存一个或多个列的副本以及指向表中实际行的指针。它不会影响数据的物理存储方式,并且可以使用主索引来查找记录。
Agentic AI 学习路线图
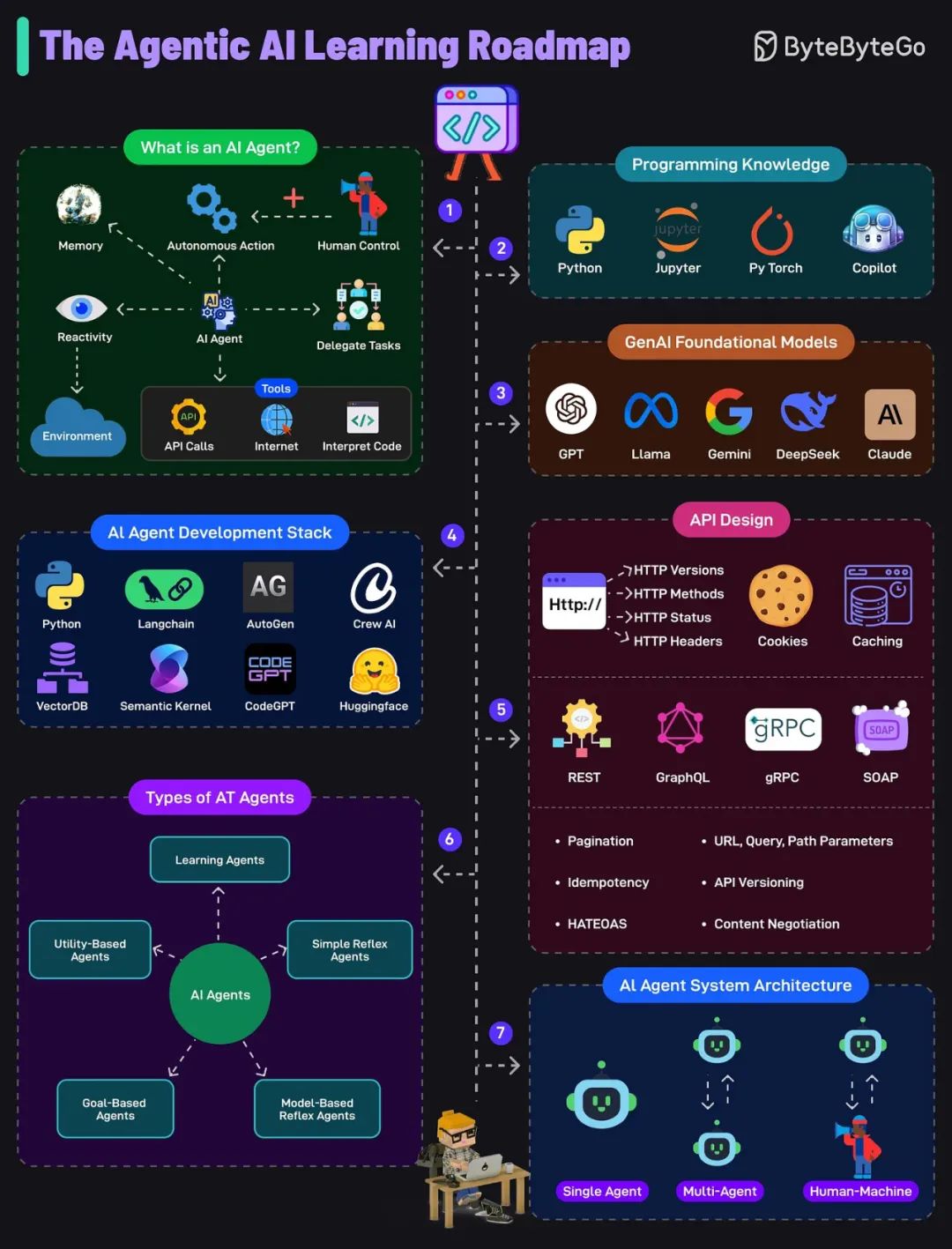
AI 代理是一个能够使用工具(API、互联网、代码等)自主行动、对环境做出反应的系统,并且可以在人类指导下工作。
要构建 AI 代理,必须了解 Python、Jupyter、PyTorch 和 GitHub Copilot 等工具。这些支持编码、实验以及与 AI 库和 API 的集成。
GenAI 基础模型熟悉 GPT、Gemini、 LLaMa、DeepSeek 和 Claude 等大型模型至关重要。这些模型提供了代理可用于推理、生成和理解的基本智能。
- AI 代理开发堆栈
工具(如 Langchain、AutoGen、Crew AI)以及 Semantic Kernel 和 Hugging Face 等框架为代理工作流程提供动力。这些组件管理代理管道中的任务、内存和外部工具集成。
- API 设计
了解 REST、GraphQL、gRPC 和 SOAP 等 API 设计方法对于构建可互作的代理至关重要。关键概念包括 HTTP 方法、状态代码、版本控制、Cookie、标头和缓存。
- AI 代理
类型 了解几种类型的 AI 代理,例如简单反射、基于模型的反射、基于目标的反射、基于效用的代理和学习代理。每个的复杂程度各不相同。
- AI 代理系统架构
AI 代理可以作为单代理、多代理系统或人机协作运行。体系结构取决于用例。
AI VS 机器学习 VS 深度学习 VS 生成式 AI
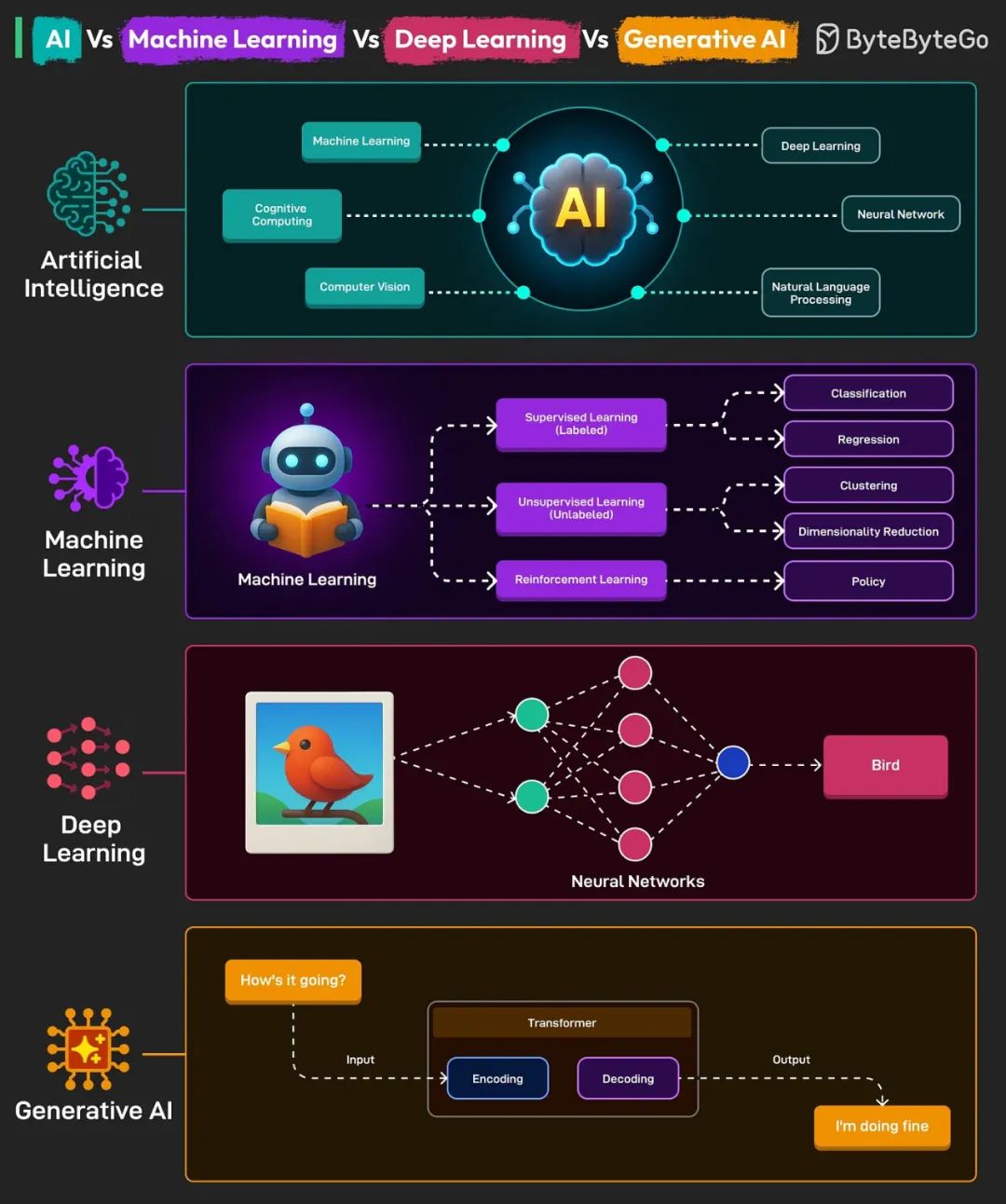
- 人工智能 (AI)
这是一个专注于创建机器或系统的总体领域,这些机器或系统可以执行通常需要人类智能的任务,例如推理、学习、解决问题和语言理解。人工智能由各个子领域组成,包括机器学习、自然语言处理、机器人技术和计算机视觉
- 机器学习 (ML)
它是 AI 的一个子集,专注于开发算法,使计算机能够从数据中学习并根据数据做出决策。
ML 系统不是为每个任务都显式编程,而是在接触更多数据时提高其性能。常见应用程序包括垃圾邮件检测、推荐系统和预测分析。
- 深度学习
它是 ML 的一个特殊子集,它利用具有多层的人工神经网络对数据中的复杂模式进行建模。
神经网络是受人脑神经元网络启发的计算模型。深度神经网络可以自动发现未来检测所需的表示。用例包括图像和语音识别、NLP 和自动驾驶汽车。
- 生成式人工智能
它是指能够生成与训练数据相似的新内容(例如文本、图像、音乐或代码)的人工智能系统。它们依赖于 Transformer 架构。
著名的生成式人工智能模型包括用于文本生成的 GPT 和用于图像创建的 DALL-E。
应该知道的 20 大人工智能概念

- 机器学习:核心算法、统计学和模型训练技术。
- 深度学习:分层神经网络自动学习复杂的表示。
- 神经网络:分层架构可以有效地准确地对非线性关系进行建模。
- NLP:处理和理解自然语言文本的技术。
- 计算机视觉:有效解释和分析视觉数据的算法
- 强化学习:跨多个服务器分布流量以提高可靠性。
- 生成模型:使用学习的数据创建新的数据样本。
- LLM:使用海量预训练数据生成类似人类的文本。
- Transformers:为现代 AI 模型提供支持的基于自注意力的架构。
- 特征工程:设计信息丰富的特征以显着提高模型性能。
- 监督学习:在没有标记数据的情况下学习有用的表示。
- 贝叶斯学习:使用概率模型方法合并不确定性。
- 提示工程:制定有效的输入来指导生成模型输出。
- AI 代理:感知、决策和行动的自主系统。
- 微调模型:为特定领域的任务定制预训练模型。
- 多模态模型:跨图像、视频和文本等多种数据类型进行处理和生成。
- 嵌入:将输入转换为机器可读的矢量格式。
- 向量搜索:使用密集向量嵌入查找相似的项目。
- 模型评估:使用验证技术评估预测性能。
- 人工智能基础设施:部署可扩展的系统来支持人工智能运营。
用于构建 RAG 应用程序的 AI 应用程序堆栈

- 大型语言模型
这些是检索增强生成 (RAG) 背后的核心引擎,负责理解查询并生成连贯且上下文相关的响应。一些常见的 LLM 选项包括 OpenAI GPT 模型、Llama、Claude、Gemini、Mistral、DeepSeek、Qwen 2.5、Gemma 等。
- 框架和模型访问
这些工具通过处理提示编排、模型切换、内存、链接和路由,简化了 LLM 与应用程序的集成。常见的工具有 Langchain、LlamaIndex、Haystack、Ollama、Hugging Face 和 OpenRouter。
- 数据库
RAG 应用程序依赖于存储和检索相关信息。这些矢量数据库针对相似性搜索进行了优化,而 Postgres 等关系选项则提供结构化存储。工具有 Postgres、FAISS、Milvus、pgVector、Weaviate、Pinecone、Chroma 等。
- 数据提取
为了填充您的知识库,这些工具有助于从 PDF、网站和 API 等非结构化来源中提取结构化信息。一些常用工具是 Llamaparse、Docking、Megaparser、Firecrawl、ScrapeGraph AI、Document AI 和 Claude API。
- 文本嵌入
嵌入将文本转换为支持语义相似性搜索的高维向量,这是在 RAG 中将查询与相关上下文连接起来的关键步骤。常用工具包括 Nomic、OpenAI、Cognita、Gemini、LLMWare、Cohere、JinaAI 和 Ollama。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号