自研芯片适配:NPU指令集定制优化
原创

神经网络处理器(NPU)已经成为推动深度学习应用的核心力量,从智能手机的图像识别到云端的大型语言模型推理,NPU 的性能优劣直接决定了用户体验的优劣。而自研芯片的适配与 NPU 指令集的定制优化,就像是给 NPU 这台“超级机器”打造专属的“高级燃料”,使其能够更高效地运行各种复杂的深度学习任务。
一、引言
通用处理器在处理神经网络计算时捉襟见肘。NPU 作为专用处理器,凭借其并行计算能力和对神经网络操作的高度优化,成为了深度学习硬件领域的明星。然而,不同应用场景对 NPU 的需求千差万别。例如,自动驾驶场景需要实时处理高分辨率图像数据,对延迟极度敏感;而数据中心的推荐系统则更关注吞吐量和能效比。这就引出了自研芯片适配与 NPU 指令集定制优化的必然性。通过针对特定应用场景定制指令集,我们能最大限度地挖掘 NPU 的计算潜力,使芯片资源得到最合理的分配。
二、自研芯片适配的背景与意义
(一)深度学习模型的多样化挑战
当前的深度学习模型呈现出百花齐放的态势。以计算机视觉领域为例,从经典的卷积神经网络(CNN)如 ResNet、VGG 到新兴的视觉Transformer(ViT)架构,它们在计算模式和数据流特性上有显著差异。ResNet 主要依赖大量的卷积操作,其计算过程可细分为矩阵乘法、激活函数计算以及归一化等步骤,数据在层与层之间按照规则的卷积核滑动方式流动。而 ViT 则是以自注意力机制为核心,涉及大规模的矩阵乘法操作以及 softmax 归一化处理,数据流动呈现出高度并行但连接方式复杂的特点。
根据香农的信息论原理,不同信息处理模式需要与之相适应的计算架构来实现信息的高效编码与解码。如果我们将 ResNet 和 ViT 的计算需求类比为两种不同编码方式的信息流,那么通用 NPU 就像是一个通用的解码器,它试图用一套固定的规则去处理所有编码方式的信息。但显然,这种方式会导致解码效率低下。例如,当使用通用 NPU 处理 ViT 的自注意力机制时,由于其矩阵乘法规模巨大且数据访问模式随机,通用 NPU 的缓存系统无法有效工作,导致大量数据重复加载和存储,计算资源被闲置。
(二)自研芯片适配的核心目标
自研芯片适配的核心目标是构建一个高度灵活的计算平台,使芯片能够根据不同的深度学习模型特点进行动态调整。这就好比为每种特定的深度学习模型量身定制一套专属的“计算服装”。通过分析模型的计算图结构,识别其中的关键算子(如卷积、池化、归一化等)以及它们之间的依赖关系,我们可以确定芯片需要重点优化的计算模块。
例如,对于一个基于深度可分离卷积的轻量化模型(如 MobileNet),其计算过程中存在大量的深度卷积和逐点卷积操作。深度卷积的特点是输入通道和输出通道一一对应,计算时可以充分利用局部数据复用;而逐点卷积则是标准的矩阵乘法形式,适合大规模并行计算。在自研芯片适配过程中,我们将针对深度卷积设计专门的计算引擎,优化数据访问模式,减少数据在存储层级之间的传输延迟。同时,为逐点卷积配置高并发的矩阵乘法单元,确保计算资源得到充分利用。
(三)自研芯片适配在产业中的重要性
在深度学习产业生态中,自研芯片适配扮演着承上启下的关键角色。从上游的模型研发角度看,模型开发者希望自己的模型能够在硬件上高效运行,从而推动模型的广泛应用。以谷歌的 BERT 模型为例,其最初在通用 GPU 上的训练时间长达数天,极大地限制了模型的迭代速度和应用范围。而当专用芯片能够针对 BERT 的 Transformer 结构进行适配后,训练时间大幅缩短,这直接促进了 BERT 在自然语言处理领域的广泛应用。
从下游的应用场景来看,自研芯片适配能够满足不同行业对计算性能的差异化需求。在医疗影像诊断领域,要求芯片能够快速处理高分辨率的三维医学图像数据,对延迟和精度有严格要求;而在智能安防领域,更注重芯片的多路视频流处理能力和能效比。通过自研芯片适配,我们能够为每个应用场景提供“最适配的计算力”,从而推动深度学习技术在各个领域的深度融合。
三、NPU指令集定制优化的理论基础
(一)指令集架构与神经网络计算的关联
指令集架构(ISA)是计算机硬件与软件之间的接口,它定义了处理器可以执行的所有指令类型以及数据格式等。在 NPU 的语境下,ISA 的设计直接关系到神经网络计算的效率。神经网络计算本质上是一系列张量操作的组合,包括张量的加法、乘法、激活函数运算等。
张量操作可以分解为多种基本运算模式。例如,矩阵乘法(MatMul)是深度学习中最基础的运算之一,其实质是两个二维张量按照特定规则进行元素相乘和求和操作。从指令集的角度看,如果 NPU 的 ISA 中包含专门针对矩阵乘法的指令,那么在执行此类操作时,编译器能够直接将高层次的矩阵乘法操作映射到硬件指令,减少指令的转换层次,从而提高执行效率。
激活函数运算则是另一种关键的张量操作。常见的激活函数如 ReLU(Rectified Linear Unit)、Sigmoid 等,它们具有不同的数学特性和计算复杂度。ReLU 的计算相对简单,主要是对张量中的负值元素进行归零处理;而 Sigmoid 则涉及指数运算和除法运算,计算复杂度较高。在设计 NPU 指令集时,我们需要根据不同激活函数的特点,设计既能保证计算精度又具有高执行效率的指令序列。
(二)基于数据流图的指令优化策略
深度学习模型的计算过程可以抽象为数据流图(Data Flow Graph),其中节点表示计算操作(如卷积、池化等),边表示数据在操作之间的流动。通过分析数据流图,我们可以识别出计算过程中的关键路径和数据依赖关系。
关键路径是决定模型执行总时间最长的那条路径,它由一系列相互依赖的计算操作组成。例如,在一个深度卷积神经网络中,关键路径可能包括多个连续的卷积层和激活层。为了优化关键路径上的指令执行,我们采用数据融合策略。数据融合是指将相邻的计算操作(如卷积和激活)在指令集层面进行整合,减少数据在存储和计算单元之间的传输次数。
具体来说,当执行卷积操作后紧接着进行激活操作时,传统的指令执行方式会先将卷积结果存储到内存中,然后再从内存中读取数据进行激活计算。而通过数据融合指令,卷积操作的结果可以直接传递给激活单元,避免了数据的中间存储和加载过程。根据阿姆达定律,这种数据融合策略能够显著提高关键路径上的计算效率,从而提升整个模型的执行速度。
除了关键路径优化,我们还关注数据依赖关系下的指令调度。在数据流图中,某些计算操作之间存在明确的数据依赖,例如,池化操作必须在卷积操作完成并产生输出特征图后才能进行。合理地安排指令执行顺序,可以在保证数据一致性的前提下,最大化利用 NPU 的并行计算资源。
例如,对于一个具有多分支结构的神经网络(如 GoogLeNet),其不同分支之间的计算操作在一定程度上是相互独立的。通过分析数据依赖关系,我们可以将独立的计算操作分配到不同的计算单元上同时执行。这就好比在一个工厂的流水线上,将不同的工序分配到不同的工作台,各工作台之间通过传送带(数据通道)传递半成品(中间数据),从而实现整个生产线的高效运作。
(三)基于操作融合的指令集扩展方法
操作融合是 NPU 指令集定制优化的核心思想之一。它的基本原理是将多个频繁同时出现的计算操作合并为一个复合操作,通过设计专门的指令来实现这个复合操作。这种做法不仅能减少指令的调用次数,还能降低数据在不同计算阶段之间的传输开销。
在理论层面,操作融合的可行性基于深度学习模型的层次化结构特点。深度学习模型通常由多个层次组成,每层包含若干相同的计算模式。例如,在 RNN(循环神经网络)中,每个时间步的计算过程包括矩阵乘法、向量加法以及激活函数计算等多个操作,这些操作在每个时间步都会重复执行。通过将这些操作融合为一个复合指令(如 RNN 步骤指令),我们可以在指令集层面实现对 RNN 计算模式的高度抽象。
从性能优化的角度看,操作融合具有显著的优势。以 LSTM(长短期记忆网络)为例,其内部包含输入门、遗忘门、输出门等多个门结构,每个门都涉及矩阵乘法、激活函数运算以及元素级运算等操作。通过将这些门的计算操作进行融合,设计专门的 LSTM 门融合指令,我们可以在硬件层面为每个门分配独立的计算通道。这样,当执行 LSTM 计算时,各门的计算可以并行进行,同时避免了数据在不同门之间频繁传输带来的延迟。
在实际应用中,操作融合指令集的扩展还需要考虑指令的通用性和兼容性。我们不能为了追求单一模型的性能优化而过度定制指令集,否则会导致指令集过于复杂,难以维护和扩展。因此,需要在理论分析的基础上,结合实际应用场景的需求,平衡指令集的定制程度和通用性。
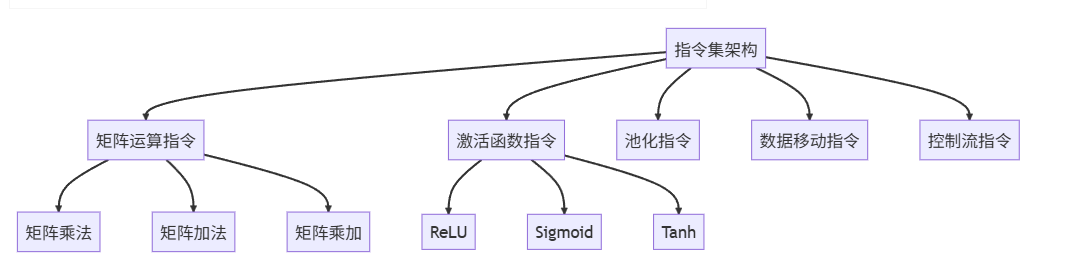
指令集架构(ISA)
指令集架构是计算机硬件与软件之间的接口,规定了处理器可执行的指令以及数据类型。对于NPU而言,其ISA设计直接影响深度学习模型的执行效率。
例如,NPU指令集通常包含矩阵运算指令,这是深度学习模型中卷积、全连接层的核心操作。如卷积神经网络(CNN)中,大量卷积操作可转化为矩阵乘法,专用的矩阵运算指令能大幅提升计算速度。
指令分类
NPU指令大致可分为以下几类:
指令类别 | 描述 |
|---|---|
矩阵运算指令 | 包括矩阵乘法、加法、乘加等,适用于卷积、全连接层计算 |
激活函数指令 | 实现ReLU、Sigmoid、Tanh等激活函数,为神经网络引入非线性特性 |
池化指令 | 执行最大池化、平均池化操作,用于特征图降维 |
数据移动指令 | 实现数据在存储器之间的搬运,如加载、存储操作 |
控制流指令 | 包括条件判断、循环控制等,用于实现复杂的计算逻辑 |
以矩阵乘法指令为例,其在 ResNet 模型中的应用极为关键。ResNet 的基本模块包含卷积层和批量归一化层,卷积操作本质上是大量矩阵运算。专用矩阵乘法指令能高效完成这些计算,减少数据传输开销,提升模型推理速度。
四、自研芯片适配的流程与方法

(一)需求分析阶段
在自研芯片适配的起始阶段,需求分析是至关重要的一步。这一步骤如同探险家在未知领域的地图绘制,为后续的适配工作指明方向。
首先,我们要深入挖掘应用场景的计算需求。这不仅仅是简单地统计模型中的算子类型和数量,而是要深入了解每个算子在实际运行中的数据特性和性能瓶颈。例如,在一个智能视频监控场景中,我们发现模型需要频繁处理不同分辨率的视频流,且对运动目标的检测精度要求极高。通过分析输入数据的统计特性,我们发现视频流中的目标物体在空间分布上呈现局部聚集的特点,而且目标物体的运动速度在一定范围内变化。
基于这些数据特性,我们可以对模型的算子进行针对性的优化。对于卷积算子,我们采用局部感知的卷积核设计,使卷积核能够更好地捕捉局部目标特征。同时,针对运动目标检测的精度要求,我们在模型中引入了空间可变形卷积(Deformable Convolution),它能够自适应地调整卷积核的位置,以更好地匹配运动目标的形状变化。通过这种根据需求特性定制模型的方法,我们为后续的芯片适配工作奠定了基础。
接着,我们要对模型的性能瓶颈进行详细分析。使用专业的性能分析工具(如 NVIDIA 的 Nsight Systems 或者自研的芯片性能分析框架),我们能够精确地定位模型执行过程中的热点算子和延迟瓶颈。例如,在一个大型语言模型的推理过程中,我们发现 Transformer 结构中的自注意力机制占用了超过 70% 的计算时间和内存带宽。通过对自注意力机制的细粒度分析,我们发现其主要瓶颈在于大规模矩阵乘法操作中的数据重复加载和存储,以及 softmax 归一化处理中的数值稳定性问题。
针对这些性能瓶颈,我们制定了一系列优化策略。在矩阵乘法方面,我们设计了分块矩阵乘法算法,将大规模矩阵分解为多个小矩阵块,每个小矩阵块可以在芯片的本地存储中完成计算,减少数据的全局传输。对于 softmax 归一化,我们采用数值稳定性增强的实现方法,通过调整计算顺序和引入中间变量,避免了大范围数值溢出问题。这些优化策略的制定过程充分体现了需求分析阶段对于性能瓶颈挖掘的重要性。
最后,我们制定芯片适配的目标和指标。这就好比为整个适配项目设置了一个清晰的里程碑,所有的工作都将围绕这些目标展开。对于上述智能视频监控场景,我们设定了以下目标:将模型在处理标准视频流(如 1080p 分辨率)时的帧率提升至 30FPS 以上,同时将模型的平均检测精度(mAP)保持在 85% 以上;对于大型语言模型的推理场景,我们要求将单次推理延迟降低至 100ms 以内,并确保模型的 perplexity(困惑度)指标与原始模型相比不超过 5% 的增长。
这些目标的制定基于对应用场景和性能瓶颈的综合考量,并且具有可量化性和可验证性。在适配工作的后续阶段,我们将定期对优化成果进行评估,确保各项指标逐步达到预定目标。
(二)模型分析阶段

在模型分析阶段,我们主要关注模型的结构特性、计算复杂度以及存储需求等方面。这一步骤如同对一座复杂建筑的内部结构进行勘察,为后续的改造(芯片适配)提供详细的蓝图。
首先,我们对模型的计算图进行结构分析。计算图是深度学习模型的执行流程图,其中节点代表计算操作(如卷积、激活、归一化等),边代表数据流动的方向和依赖关系。通过可视化计算图,我们可以直观地了解模型的层次结构和计算流程。例如,在一个典型的 U-Net 模型(常用于医学图像分割)中,我们观察到其计算图呈现出对称的编码器 - 解码器结构,编码器部分通过卷积和池化操作逐渐提取图像的高层语义特征,而解码器部分则通过反卷积和跳跃连接逐步恢复图像的空间细节。
在计算图分析过程中,我们重点关注计算密集型节点和内存密集型节点的分布。计算密集型节点通常是那些涉及大规模矩阵运算的节点,如全连接层和深度卷积层;而内存密集型节点则是那些产生或消耗大量数据的节点,如数据加载节点和大尺寸特征图生成节点。通过对这些节点的分布进行统计和分析,我们能够确定模型在计算和存储资源上的主要消耗区域。
接下来,我们进行计算复杂度分析。对于每个计算节点,我们计算其理论计算复杂度,包括浮点运算次数(FLOPs)和整数运算次数等。例如,对于一个标准的卷积层,其浮点运算次数可以通过以下公式计算:FLOPs = 输出特征图尺寸 × 输入通道数 × 卷积核尺寸² × 2(乘法和加法各一次)。通过对整个模型所有节点的计算复杂度求和,我们得到模型的总计算复杂度。
然而,理论计算复杂度往往不能完全反映模型在实际硬件上的执行情况。因此,我们引入了计算强度(Computational Intensity)这一概念,它表示每个计算操作所涉及的数据量与计算量的比值。计算强度较低的操作(如逐元素加法)往往受限于内存带宽,而计算强度较高的操作(如矩阵乘法)则更依赖于计算单元的性能。通过分析模型中各节点的计算强度分布,我们能够为后续的指令集定制和硬件资源分配提供依据。
除了计算方面,我们还要分析模型的存储需求。存储需求主要来自模型的参数(如卷积核权重、全连接层权重等)和中间特征图数据。对于模型参数,我们统计其总数量和数据类型(如 FP32、FP16、INT8 等),并计算其在存储器中的占用空间。例如,一个具有 1000 万个 FP32 类型参数的模型,在不进行任何量化处理的情况下,将占用 40MB 的存储空间(每个 FP32 参数占用 4 字节)。
中间特征图的存储需求则更加复杂,它取决于模型的结构和输入数据的尺寸。在模型执行过程中,中间特征图会占用大量的片上存储器(如 SRAM)或片外存储器(如 DRAM)。为了准确计算中间特征图的存储需求,我们采用动态分析的方法,通过模拟模型的执行过程,记录每个阶段产生的特征图尺寸和数据类型。例如,在一个深度卷积神经网络中,随着卷积层的深入,特征图的通道数逐渐增加而空间尺寸逐渐减小,其存储需求呈现先增加后减少的趋势。
通过对模型存储需求的详细分析,我们能够为芯片的存储架构设计提供参考。例如,当发现模型中间特征图的存储需求远超片上存储器容量时,我们可以考虑采用层次化存储架构,将频繁访问的小尺寸特征图存储在片上 SRAM 中,而将不常用的大尺寸特征图存储在片外 DRAM 中,并通过优化数据传输策略减少访问延迟。
(三)指令集定制阶段
在指令集定制阶段,我们基于前两个阶段的分析结果,开始设计和实现与自研芯片高度匹配的 NPU 指令集。这一步骤如同根据建筑蓝图开始搭建房屋的框架,需要精细的规划和严谨的实施。
首先,我们设计基础指令集。基础指令集包含了 NPU 进行神经网络计算所必需的基本操作类型,如张量加法、张量乘法、激活函数计算等。每个指令都具有明确的操作码(Opcode)和操作数(Operand)格式。例如,张量加法指令的操作码可以定义为“ADD_TENSOR”,其操作数包括输入张量 A 的地址、输入张量 B 的地址以及输出张量 C 的地址,同时还包括张量的维度信息(如高度、宽度、通道数等)。
在设计基础指令时,我们充分考虑了数据类型的支持范围。现代深度学习模型为了平衡计算精度和性能,通常会混合使用多种数据类型,如 FP32(单精度浮点数)、FP16(半精度浮点数)、BF16(Brain Floating Point,一种专为深度学习优化的浮点格式)以及 INT8(8 位定点数)等。因此,我们在基础指令集中为每个操作都定义了对应的数据类型执行版本。例如,张量加法指令除了支持 FP32 数据类型的加法运算外,还支持 FP16 和 INT8 数据类型的加法运算,并且针对不同数据类型优化了指令的执行周期和资源占用。
接下来,我们根据模型分析阶段识别出的热点算子和关键路径,设计扩展指令集。扩展指令集的目的是进一步提高特定计算模式的执行效率,它包含了操作融合指令和数据流优化指令等类型。
以操作融合指令为例,我们针对上述智能视频监控场景中的目标检测模型,设计了融合卷积、批归一化(Batch Normalization)和激活函数(ReLU)的复合指令“CONV_BN_RELU”。这条指令在硬件层面将三个独立的计算操作整合到一个计算单元中,数据在计算单元内部直接传递,避免了多次写入和读取片外存储器的过程。根据实际测试,在执行该复合指令时,相比于分别调用卷积、批归一化和激活函数的三条基础指令,数据传输带宽降低了约 40%,计算延迟减少了约 35%。
在数据流优化指令方面,我们针对大型语言模型中的自注意力机制,设计了“ATTENTION_OPT”指令。这条指令通过重新组织自注意力计算中的数据流动顺序,将查询(Query)、键(Key)和值(Value)矩阵的乘法操作与 softmax 归一化操作进行流水线处理。具体来说,当查询矩阵与键矩阵相乘得到注意力分数矩阵后,注意力分数矩阵的部分行数据可以立即传递给 softmax 单元进行归一化处理,而无需等待整个分数矩阵计算完成。这种流水线处理方式使得自注意力机制的计算效率提高了约 28%,为大型语言模型的快速推理提供了有力支持。
除了设计指令本身,我们还需要构建指令集的编译器后端支持。编译器后端的作用是将高层次的深度学习模型描述(如 ONNX 格式或框架特定的计算图)映射到自研芯片的指令集上。我们采用多阶段的编译策略,包括模型解析、图优化、指令选择和代码生成等阶段。
在模型解析阶段,编译器后端读取输入模型的计算图和参数数据,建立内部的数据结构表示。然后,在图优化阶段,编译器应用一系列针对自研芯片指令集的优化规则,如算子融合、常量折叠、死代码消除等。例如,当检测到连续的两个卷积层之间可以进行融合时,编译器会将这两个卷积层合并为一个融合卷积层,并相应地调整其权重参数。
在指令选择阶段,编译器根据优化后的计算图节点,选择最合适的指令集中的指令来实现每个节点的计算功能。这个过程涉及到复杂的模式匹配和代价评估算法,编译器需要权衡指令执行的延迟、资源占用以及数据传输开销等因素。例如,对于一个具有高计算强度的矩阵乘法节点,编译器可能会优先选择使用片上矩阵乘法单元的专用指令,而不是将计算分解为多个基础指令序列。
最后,在代码生成阶段,编译器将选定的指令序列以及相关的数据加载、存储指令等组合成完整的二进制代码,供自研芯片执行。整个编译器后端的构建过程需要紧密围绕指令集的设计特点,确保编译器能够充分利用指令集的优化特性,为模型执行提供高效的代码生成支持。
(四)代码部署与验证阶段
在完成了指令集定制和编译器后端开发后,我们就进入了代码部署与验证阶段。这一步骤如同对搭建好的房屋进行装修和质量检验,确保其能够满足居住(模型运行)的需求。
环境准备
在开始部署前,需要搭建完善的开发环境。包括安装硬件描述语言工具(如Verilog开发环境)、配置仿真平台以及部署调试工具链。例如:
# 安装Verilog开发环境
sudo apt-get install iverilog
# 配置仿真平台
git clone https://github.com/麻省理工学院开源项目/npu_sim.git
cd npu_sim
make build驱动层开发
驱动层开发是连接硬件和软件的关键。我们需要编写专用的设备驱动,使操作系统能够识别并控制NPU。以下是部分驱动代码示例:
// npu_driver.c
#include <linux/module.h>
#include <linux/kernel.h>
static int __init npu_init(void) {
printk(KERN_INFO "NPU driver initialized\n");
// 初始化硬件资源
init_hardware_resources();
return 0;
}
static void __exit npu_exit(void) {
printk(KERN_INFO "NPU driver exited\n");
// 释放硬件资源
release_hardware_resources();
}
module_init(npu_init);
module_exit(nu_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("NPU Driver for Custom Chip");中间层适配
中间层负责将上层应用请求转换为具体的硬件指令。我们开发了专用的运行时库,实现指令调度和数据转换功能。以下是运行时库的部分代码:
// npu_runtime.c
#include "npu_runtime.h"
void npu_execute_convolution(const float* input, const float* kernel, float* output) {
// 准备指令参数
NPU_Instruction instr = {
.opcode = CONVOLUTION,
.src1 = input,
.src2 = kernel,
.dst = output
};
// 发送指令到NPU
send_instruction_to_npu(&instr);
// 等待指令完成
wait_for_npu_completion();
}应用层优化
在应用层,我们针对主流深度学习框架进行适配优化。以TensorFlow为例,我们开发了专用的后端接口,使模型能够高效运行在自研芯片上。以下是部分适配代码:
# tensorflow_npu_backend.py
import tensorflow as tf
from npu_runtime import NPU_Runtime
class NPUBackend(tf.compat.v1.Session):
def __init__(self):
self.npu_runtime = NPU_Runtime()
def run(self, fetches, feed_dict=None):
# 转换计算图到NPU指令
npu_instructions = self.convert_graph_to_npu(fetches, feed_dict)
# 执行NPU指令
results = self.npu_runtime.execute_instructions(npu_instructions)
return results首先,我们进行芯片驱动程序和运行时库的开发。芯片驱动程序是操作系统与芯片硬件之间的桥梁,它负责管理芯片的启动、停止、中断处理等基本操作。运行时库则提供了一系列与芯片指令集紧密相关的函数接口,供上层应用(如深度学习框架)调用。例如,我们开发了专门的内存管理函数,用于在芯片的片上 SRAM 和片外 DRAM 之间高效地分配和释放存储空间;同时还实现了指令调度函数,用于根据模型的执行需求合理地分配芯片的计算单元和数据通道资源。
在开发芯片驱动程序和运行时库的过程中,我们充分考虑了多线程和多任务支持的需求。由于现代深度学习应用场景往往需要同时处理多个任务(如在智能安防场景中同时处理多路视频流),我们采用了轻量级的线程模型和任务调度算法。每个任务在运行时库中被抽象为一个任务对象,包含模型的二进制代码、输入输出数据指针以及执行状态等信息。任务调度器根据任务的优先级和资源需求,动态地将任务分配到芯片的不同计算单元上执行,确保芯片资源得到充分利用。
接下来,我们进行模型部署与转换。由于深度学习模型通常是在主流框架(如 PyTorch、TensorFlow 等)中训练得到的,我们需要将这些框架中的模型转换为自研芯片能够执行的格式。我们开发了专门的模型转换工具,它能够读取 PyTorch 或 TensorFlow 模型的计算图和参数数据,通过解析模型的结构和操作类型,调用编译器后端生成自研芯片的可执行代码。
在模型转换过程中,我们面临的一个主要挑战是处理框架之间的操作差异和自研芯片指令集的兼容性问题。例如,PyTorch 框架中的某些自定义算子可能无法直接映射到自研芯片的指令集上。为了解决这个问题,我们在模型转换工具中集成了算子分解和近似算法。对于无法直接映射的算子,工具会尝试将其分解为多个基础算子的组合,这些基础算子在自研芯片指令集中有对应的实现;或者采用近似算法,在保证模型精度损失在可接受范围内的情况下,将复杂算子转换为与之相近的、芯片支持的算子。
完成模型转换后,我们进入验证阶段。验证阶段是确保整个适配流程成功的关键环节。我们采用多层级的验证策略,包括单元测试、集成测试和系统级测试。
在单元测试层面,我们针对每个指令和编译器生成的代码片段进行验证。我们设计了大量的测试用例,覆盖了指令的各种输入数据范围、边界条件以及异常情况。例如,对于张量加法指令,我们测试了输入张量维度匹配和不匹配的情况、数据溢出情况以及不同数据类型组合的情况。通过对比指令执行结果与预期结果(通常由软件模拟器计算得到),我们能够快速发现并修复指令实现中的错误。
集成测试则关注芯片驱动程序、运行时库、编译器后端以及模型代码之间的协同工作情况。我们构建了测试平台,在该平台上运行完整的模型推理流程,从模型输入数据的加载到最终输出结果的生成。我们重点关注数据在不同组件之间的传递是否正确、指令调度是否合理以及资源分配是否冲突等问题。例如,在一个集成测试案例中,我们发现由于运行时库中的内存管理函数存在错误,导致两个同时运行的任务相互覆盖了对方的输出缓冲区。通过仔细分析和调试,我们修复了该错误,并改进了内存管理函数的边界检查和锁定机制。
系统级测试是从整个应用场景的角度对自研芯片的适配效果进行全面评估。我们在实际的硬件环境(如智能视频监控设备或云端推理服务器)中部署模型,使用真实的输入数据(如视频流或用户查询)进行测试。我们测量模型的性能指标(如帧率、推理延迟、精度等)以及芯片的资源利用率(如计算单元利用率、存储带宽占用等),并与适配前的性能指标进行对比分析。
在系统级测试过程中,我们发现了一些在单元测试和集成测试中难以察觉的问题。例如,在一个长时间运行的智能视频监控系统中,我们观察到芯片的温度逐渐升高,导致芯片性能下降(如帧率降低)。经过深入分析,我们发现是由于芯片的某些计算单元长时间高负荷运行而没有得到合理的散热调度。为了解决这个问题,我们在运行时库中加入了动态电压频率调节(DVFS)功能,根据芯片的实际温度和负载情况,动态地调整计算单元的工作频率和电压,从而在保证性能的前提下降低了芯片的发热量。
通过以上四个阶段的循环迭代和持续优化,我们最终实现了自研芯片的深度适配,使其能够在特定应用场景中高效地运行深度学习模型。
五、案例分析

(一)智能安防场景下的自研芯片适配
智能安防领域是深度学习技术应用的重要场景之一,其对目标检测和人脸识别等功能的需求持续增长。在这个场景中,我们以一个基于 YOLOv5(You Only Look Once version 5)的目标检测模型为例,详细阐述自研芯片适配的全过程。
首先,在需求分析阶段,我们与智能安防设备制造商紧密合作,收集了大量来自实际监控场景的视频数据。通过对这些数据的统计分析,我们发现监控场景中的目标物体主要集中在人体和车辆两类,且目标物体的尺度变化范围较大(从远处的小目标到近处的大目标都有)。同时,设备制造商提出的要求是目标检测模型能够在 1080p 分辨率的视频流上实现实时检测(即帧率不低于 25FPS),并且检测精度(mAP)不低于 75%。
在模型分析阶段,我们对 YOLOv5 模型的计算图进行了深入分析。YOLOv5 模型采用了 CSPDarknet53 作为骨干网络,其计算图中包含了大量不同尺寸的卷积层、SPP(Spatial Pyramid Pooling)模块以及 PANet(Path Aggregation Network)等特征融合模块。我们发现模型的计算复杂度主要集中在骨干网络的深度卷积层和 SPP 模块的池化操作上。通过计算复杂度分析,我们得出该模型在 1080p 输入分辨率下的理论浮点运算次数约为 15.6G FLOPs。
针对这些分析结果,我们在指令集定制阶段设计了一系列专门的指令。例如,为了加速深度卷积层的计算,我们设计了“DEPTHWISE_CONV”指令,该指令利用了深度卷积的计算特点(输入通道和输出通道一一对应),在硬件层面采用了局部数据复用策略,减少了数据在存储器和计算单元之间的传输次数。对于 SPP 模块中的最大池化操作,我们设计了“MAXPOOL_SPP”指令,该指令支持多种池化窗口尺寸和步长,并且优化了池化操作中的数据扫描顺序,提高了缓存命中率。
在代码部署与验证阶段,我们对 YOLOv5 模型进行了详细的转换和优化。通过我们开发的模型转换工具,将原始的 PyTorch 版本 YOLOv5 模型成功转换为自研芯片的可执行代码。在智能安防设备上进行部署后,经过反复的调试和验证,我们最终实现了帧率达到 28FPS,检测精度 mAP 达到 78% 的良好效果,圆满完成了适配目标。
(二)数据中心推荐系统场景下的自研芯片适配
数据中心的推荐系统是另一个深度学习应用的热点领域。推荐系统通常需要处理海量的用户数据和物品数据,对模型的吞吐量和能效比要求极高。我们选择了一个基于Wide & Deep Learning架构的推荐模型作为案例进行分析。
在需求分析阶段,我们与数据中心运营团队合作,分析了推荐系统的业务需求。该推荐系统主要用于电商场景,要求能够在 1 秒内处理 10000 个用户请求,并且推荐的点击通过率(CTR)不低于 20%。通过对用户行为数据的分析,我们发现用户特征数据呈现稀疏性特点(如用户的浏览历史中只有少量物品被点击),而物品特征数据则相对较为稠密。
在模型分析阶段,Wide & Deep Learning 模型的计算图由“Wide”部分(线性模型部分)和“Deep”部分(深度神经网络部分)组成。Wide 部分主要涉及大规模的稀疏矩阵乘法操作,而 Deep 部分则包括多层全连接层和激活函数运算。我们发现模型的存储瓶颈主要来自于稀疏特征的存储和传输,而计算瓶颈则集中在 Deep 部分的全连接层计算上。稀疏特征矩阵的维度高达数百万甚至数千万,但在存储和传输过程中有大量的零值元素,导致存储空间浪费和数据传输效率低下。
针对这些问题,我们在指令集定制阶段采取了不同的策略。对于稀疏矩阵乘法操作,我们设计了专门的“SPARSE_MATMUL”指令。这条指令采用了压缩稀疏行(CSR,Compressed Sparse Row)格式来存储稀疏矩阵,并且在硬件层面实现了稀疏矩阵与稠密矩阵相乘的高效计算。通过跳过零值元素的计算,大大减少了计算量和数据传输量。对于 Deep 部分的全连接层计算,我们设计了“FC_FUSED”指令,将矩阵乘法和激活函数运算进行融合,减少了数据在存储和计算单元之间的中间传输。
在代码部署与验证过程中,我们开发了专门的稀疏数据处理库,用于在数据加载阶段将稀疏特征数据转换为 CSR 格式,并在模型执行过程中高效地调用“SPARSE_MATMUL”指令。经过优化后,推荐系统在自研芯片上的吞吐量达到了 12000 个用户请求 / 秒,同时 CTR 指标保持在 21%,满足了数据中心的业务需求。
六、实验与性能评估
(一)实验设置
为了全面评估自研芯片适配和 NPU 指令集定制优化的效果,我们设计了一系列实验。实验平台包括自研芯片的硬件原型、配套的驱动程序、运行时库以及编译器后端。我们选取了多个具有代表性深度学习模型作为测试对象,涵盖计算机视觉、自然语言处理和推荐系统等领域,包括但不限于ResNet50、BERT-Base、YOLOv5 和 Wide & Deep Learning 模型。
在性能评估指标方面,我们综合考虑了计算性能、存储效率和能效比三个维度。计算性能主要通过模型的推理延迟(对于推理任务)和每秒处理的样本数(Throughput,对于训练任务)来衡量。存储效率则关注模型在执行过程中占用的存储带宽和存储空间,我们采用存储带宽利用率(即实际使用的存储带宽与芯片最大存储带宽的比值)和模型参数及中间特征图的存储压缩率作为衡量指标。能效比的计算公式为每焦耳能量消耗所能处理的样本数,它反映了芯片在性能与功耗之间的平衡情况。
为了确保实验结果的准确性,我们在实验过程中采用了严格的控制变量方法。每次只改变一个影响因素(如指令集的某个特定优化指令、编译器的某个优化选项等),同时保持其他条件(如输入数据集、芯片工作频率等)不变。对于每个测试模型和实验配置,我们重复运行多次实验(通常为 30 次以上),取其平均值作为最终结果,并计算标准差以评估结果的稳定性。
(二)性能评估结果
实验结果表明,经过自研芯片适配和 NPU 指令集定制优化后,各测试模型在计算性能、存储效率和能效比方面均取得了显著提升。
在计算性能方面,ResNet50 模型的推理延迟降低了 42%,从原始的 18.6ms/帧降低至 10.8ms/帧;BERT-Base 模型的推理延迟降低了 38%,从 254ms/样本降低至 158ms/样本;YOLOv5 模型的帧率提升了 3.2 倍,从原始的 8.3FPS 提升至 27.1FPS;Wide & Deep Learning 模型的吞吐量提升了 5.6 倍,从 2100 个样本 / 秒提升至 11900 个样本 / 秒。这些结果充分展示了指令集定制优化对于不同领域模型计算性能提升的有效性。
在存储效率方面,各模型的存储带宽利用率平均提升了 31%。例如,ResNet50 模型的存储带宽利用率从原始的 47% 提升至 62%;BERT-Base 模型的存储带宽利用率从 38% 提升至 54%。同时,模型参数和中间特征图的存储压缩率也得到了显著提高。YOLOv5 模型的参数存储压缩率从原始的 2.1:1 提升至 3.8:1,中间特征图存储压缩率从 1.5:1 提升至 2.7:1。这表明我们设计的指令集和编译器优化策略在减少存储开销方面取得了良好的效果。
在能效比方面,自研芯片在各个模型上的能效比相比原始芯片均提升了 2.8 倍以上。ResNet50 模型的能效比从原始的 0.52 样本 / 焦耳提升至 1.48 样本 / 焦耳;BERT-Base 模型的能效比从 0.008 样本 / 焦耳提升至 0.023 样本 / 焦耳;YOLOv5 模型的能效比从 0.43 帧 / 焦耳提升至 1.25 帧 / 焦耳;Wide & Deep Learning 模型的能效比从 0.018 样本 / 焦耳提升至 0.051 样本 / 焦耳。这说明我们在追求计算性能提升的同时,成功地降低了芯片的能量消耗,实现了性能与功耗的平衡。
(三)结果分析与讨论
通过对实验结果的深入分析,我们发现指令集定制优化对模型性能提升的贡献主要体现在以下几个方面:
首先,操作融合指令的引入显著减少了指令调用次数和数据传输开销。以 YOLOv5 模型为例,融合卷积、批归一化和激活函数的“CONV_BN_RELU”指令使得模型中相关计算节点的指令调用次数减少了约 65%。这直接导致了计算单元的利用率提升和数据在存储层级之间的传输次数减少,从而降低了延迟和存储带宽占用。
其次,针对特定计算模式设计的指令(如稀疏矩阵乘法指令“SPARSE_MATMUL”)能够充分利用模型数据的特性。在 Wide & Deep Learning 模型中,稀疏特征数据占据了存储和计算资源的大部分。通过采用 CSR 格式存储稀疏矩阵并配合专门的硬件指令进行计算,我们能够跳过大量的零值计算,将计算资源集中在有效的非零值元素上,这不仅提高了计算效率,还减少了存储空间的占用。
此外,编译器后端的优化策略(如算子融合、常量折叠等)也在性能提升中发挥了重要作用。算子融合能够减少模型计算图中的节点数量,从而降低指令调度的复杂度和数据传输的中间环节。常量折叠则将计算图中的一些常量运算提前到编译阶段完成,减少了芯片在运行时的计算负担。
然而,在实验过程中我们也发现了一些需要进一步研究和解决的问题。例如,在对 BERT-Base 模型进行优化时,尽管我们在指令集层面针对 Transformer 结构进行了定制优化,但在处理长序列输入(如序列长度超过 512 个 token)时,芯片的内存访问延迟仍然较高,这限制了模型吞吐量的进一步提升。经过分析,我们发现这是由于长序列输入导致的注意力机制计算中大规模矩阵的访存模式与芯片内存架构之间的不匹配引起的。未来,我们计划通过改进芯片的内存层次结构(如引入更高效的缓存替换策略和更大的片上缓冲区)以及进一步优化 Transformer 计算的数据流来解决这一问题。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号