距离上代才5个月,Grok 4竟用20万张GPU卡生生“堆”出来!
原创
距离上代才5个月,Grok 4竟用20万张GPU卡生生“堆”出来!
原创
算法一只狗
修改于 2025-07-13 21:42:10
修改于 2025-07-13 21:42:10
距离 Grok 3 发布仅5个月,Grok 4 正式面世。这一超短迭代周期离不开背后庞大的计算资源和技术积累。据官方披露,Grok 4 的训练总算力消耗达到 20 万张 GPU 卡·天量级,训练规模与先前主流大模型相比堪称史无前例。

这说明只要屯卡屯得足够多,什么大模型都能够快速训练出来。简直就是一个暴力美学的代名词。
一、发布了什么模型?
在发布会上,官方同步推出两款模型:
- Grok 4:基于单代理推理架构,依靠精细调优的Transformer网络实现高效推理。其在多个裸机基准测试中均超越前代版本。
- Grok 4 Heavy:进一步升级为四个并行 Agent 协同求解的混合架构,每个 Agent 可独立运行不同子任务,再通过投票机制凝聚多方结果,最终输出最优答案。针对复杂推理场景与多人协作任务,Heavy 版本具备更强的容错与稳定性。
由于资源和成本考量,普通用户暂时无法直接调用完整模型。如需体验,需先充值对应额度,官方将按使用量实时计费,并在后期根据反馈逐步开放免费试用或限时体验活动。
二、核心能力升级细节
综合基准测试结果显著提升:
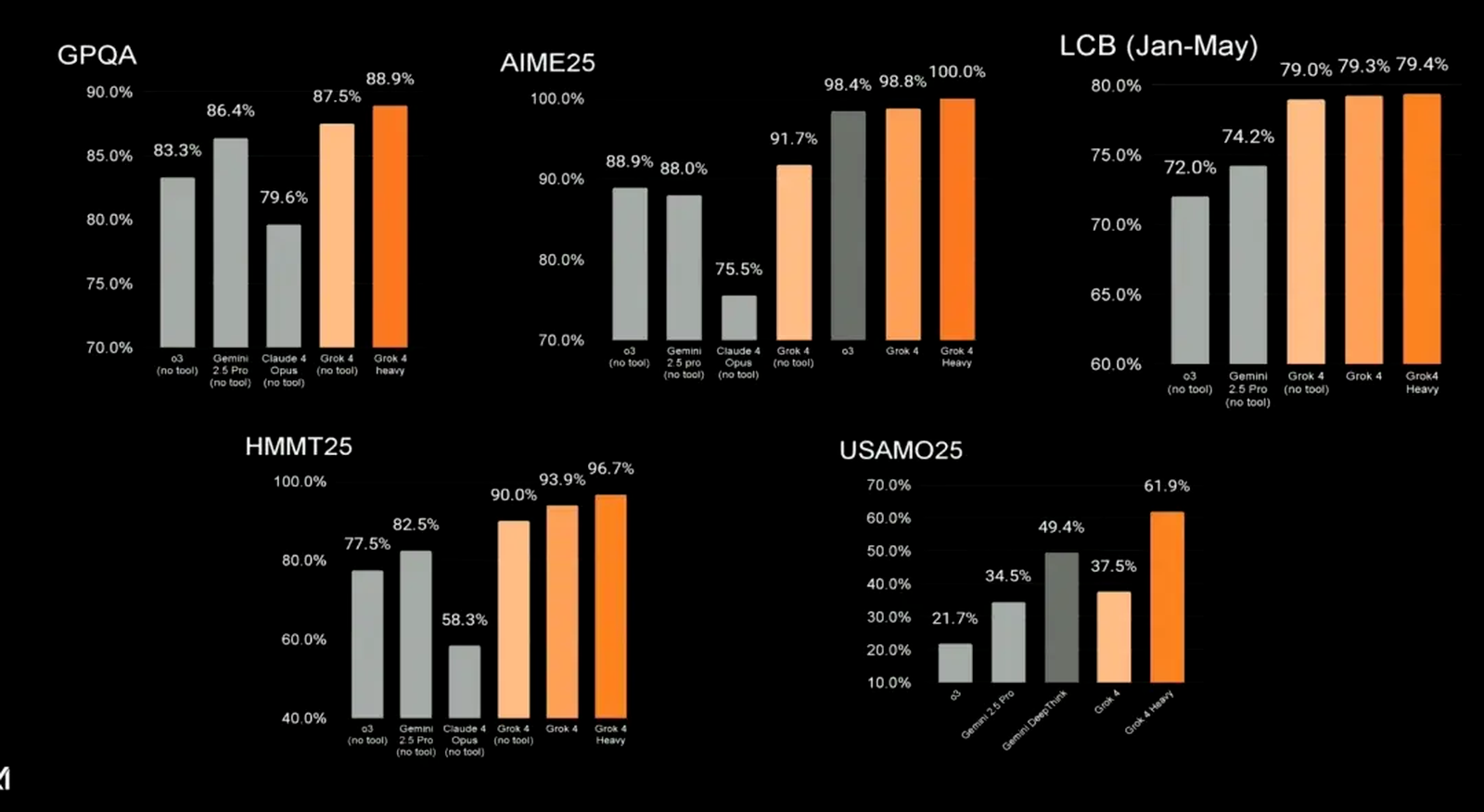
- GPQA:Grok 4(no tool)得分 87.5%,位列所有测试模型中第二,仅次于自身 Heavy 版本的 88.9%。这一成绩在数学与逻辑推理题库中展现了极佳的稳定性和准确率。
- AIME25:Grok 4 单机版本取得满分 100 分,全面压制 o3 和 Gemini 系列等竞品,尤其在题目类别切换及上下文联动解题方面表现尤为出色。
- USAMO25:对于美国数学奥林匹克题库,Grok 4(无工具)得分 21.7%,相比于普通问答型数据仍有提升空间;Grok 4 Heavy 借助多代理协同与分工能力,成绩飙升至 61.9%。
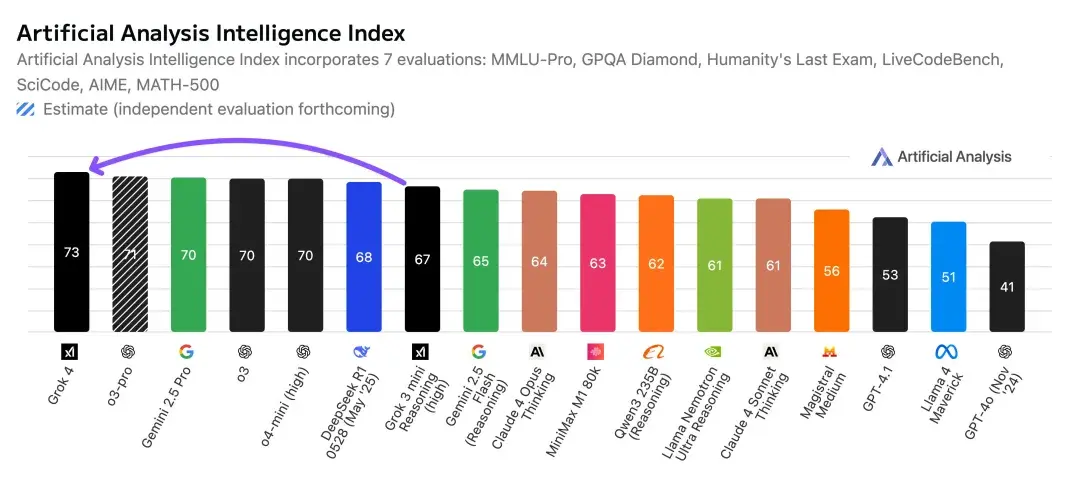
在权威评测机构 Artificial Analysis 的综合打分中,Grok 4 从上一代 67 分提升至 73 分,超越 o3 与 Gemini 2.5,尤其在语言理解、代码生成与多轮对话保持一致性方面获得高分。
Grok 4的API调用价格来说,算是比较昂贵的,每百万token输入$3,输出为$15。从下图可以看到,它的价格排到了前3。这说明它本身模型确实很大,导致价格都降低不下来。
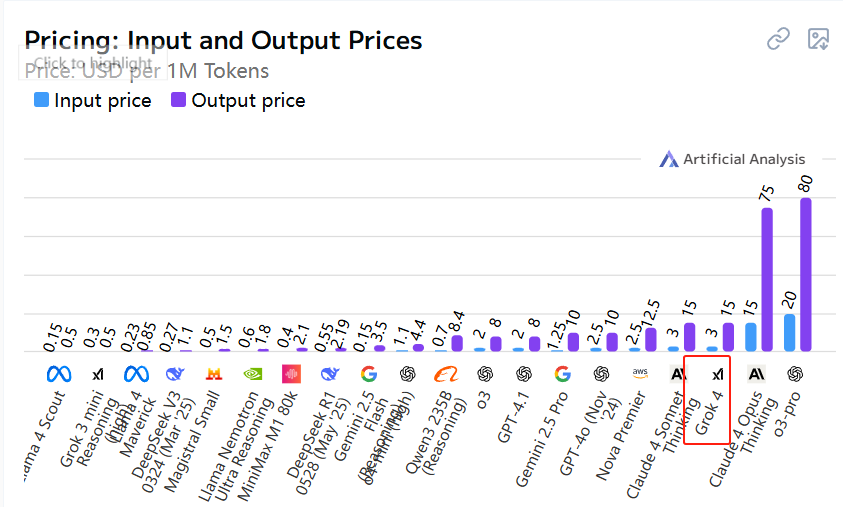
如果预算敏感或者需要大批量离线:目前DeepSeek系列模型还是比较划算的存在(这里再次吹一波国产大模型)
总的来说,Grok 4 通过“多代理 + 工具链 + 超长上下文”组合,显著拔高了推理与竞赛类基准的天花板,但其高昂价格和内容安全缺陷将成为商业化推广的主要阻力。如果后续能够推出免费使用的Grok 4版本,同时把API价格打下来,或许有机会在企业与开发者生态中占据一席之地。
三、测试效果
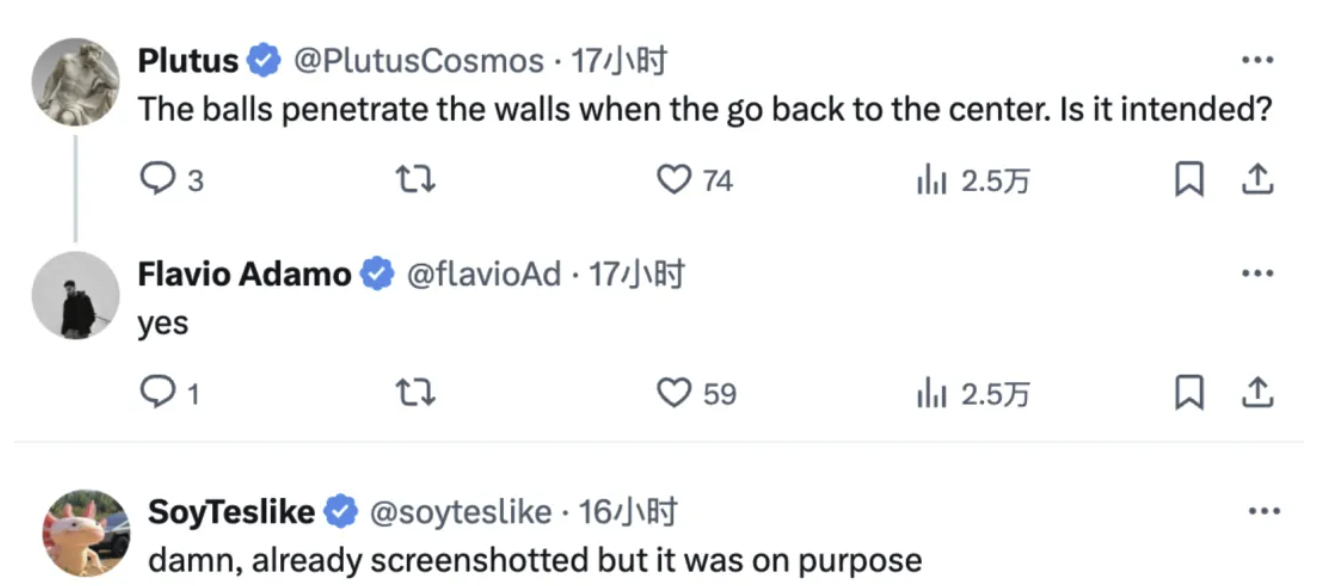
任务1:小球碰撞实验
有网友测试了一下 Grok 4 的小球滚动的代码实验。小球从多层六边形开口处落下,旋转过程中错落有致;
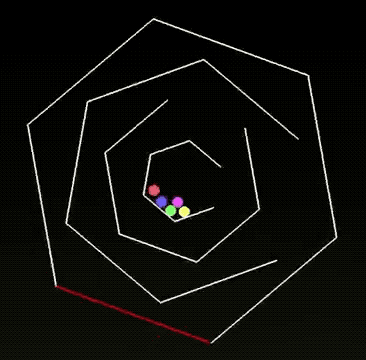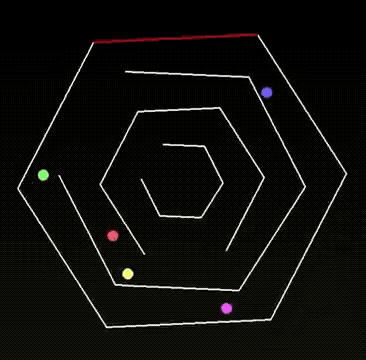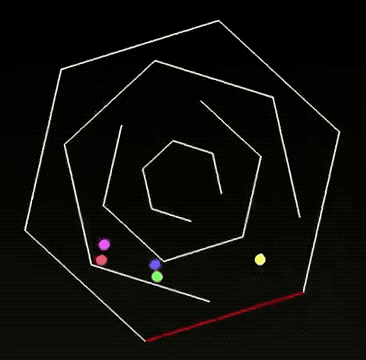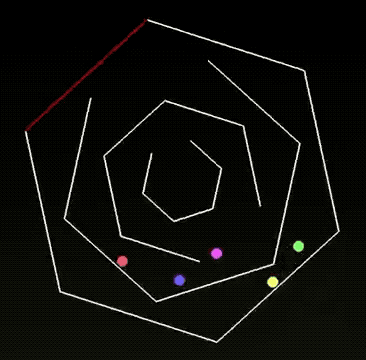
在返回中心时还会“穿墙”,但是从作者解释上来看,他说这是这是刻意设计的效果,既符合想象又颇具美感。
任务2:文字与表情塗鸦:从随机跑动到 Hello World
除了小球,网友们还让 Grok4 Heavy 制作了更加复杂的动画:一群小人在随机移动中,先后排列出“Hello World”“I am grok”的字样,最后又齐刷刷蹦出一个大大的笑脸——其他模型在这类动态排版上,无一能及。

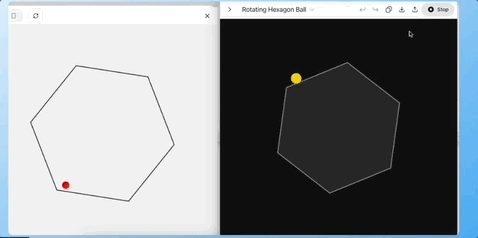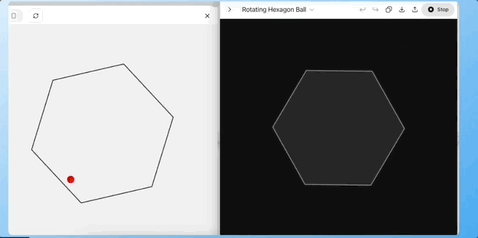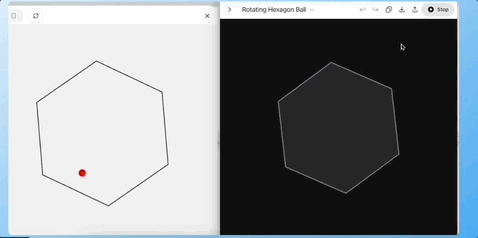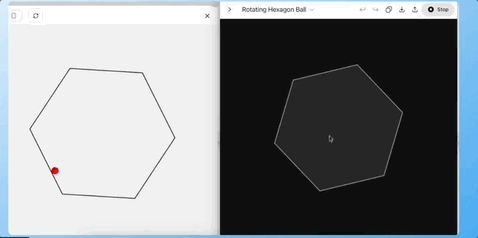
任务 3:单层六边形小球测试(物理规律理解)
让模型根据给定的 SVG 图形,预测小球在单层六边形中滚落、反弹、回到中心的轨迹是否合理。
Grok4 一次性生成了符合预期的运动描述和示例代码,o3 的预测效果在下面黑色中,基本预测错了
任务 4:多层推理的法律财务题
假设 A 公司收购 B 公司,B 公司持有 C 公司的债务,若 C 违约,要求模型分析各方法律责任与财务影响。主要测试模型在跨领域(法律+财务)问题上的层级推理与条理化表达能力。
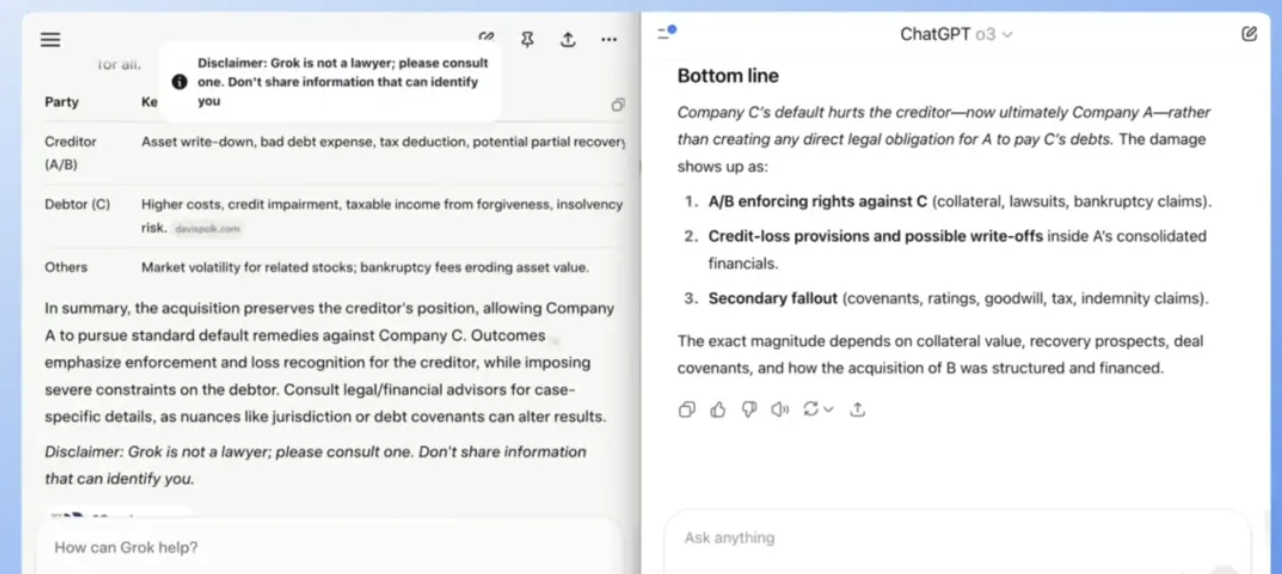
从结果上来看:Grok4 以表格+分步总结的形式罗列了各方影响;o3 回答与法律关联度低,缺乏系统性。
任务 5:代码翻译(Python → Go,附西班牙语注释)
将一个用于解决迷宫问题的 Python 递归函数翻译成 Go 语言,并逐行用西班牙语注释。主要用来验证模型的多语言编程能力及对算法逻辑的理解。
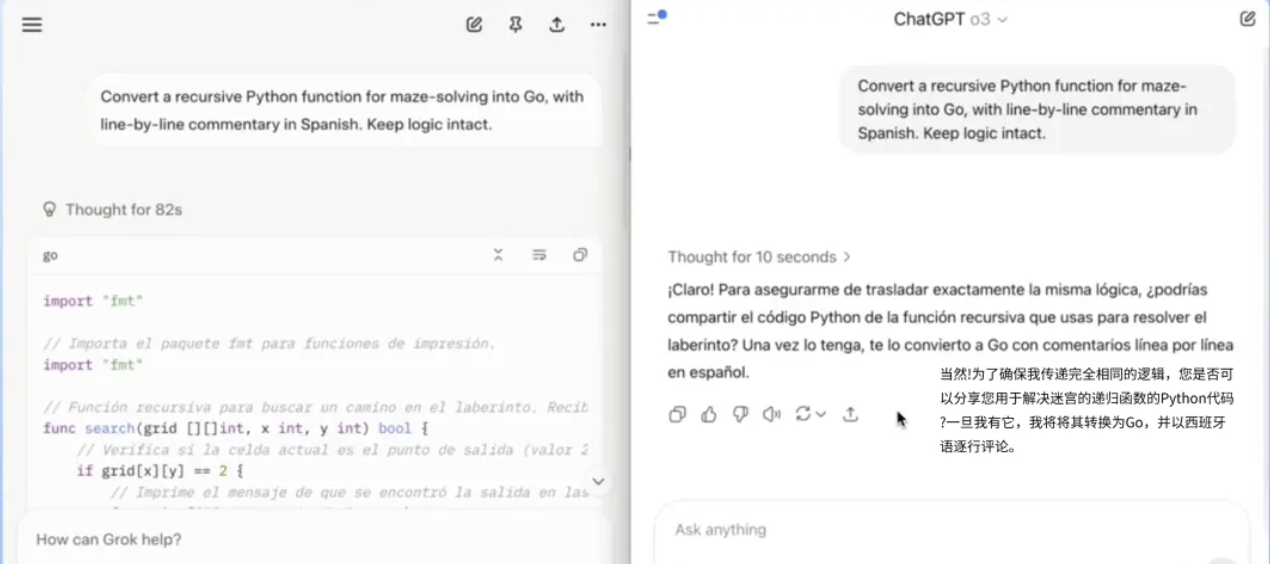
Grok4 正确生成可运行的 Go 代码并添加了详尽注释;o3 则要求用户先提供代码示例,无法主动完成翻译。
任务 6:向博士生与十岁儿童分别解释 Transformer
别让模型用面向机器学习博士生和面向 10 岁小朋友的方式,讲解 Transformer 的核心原理。用来测试模型根据受众调整技术深度和表达风格的能力。
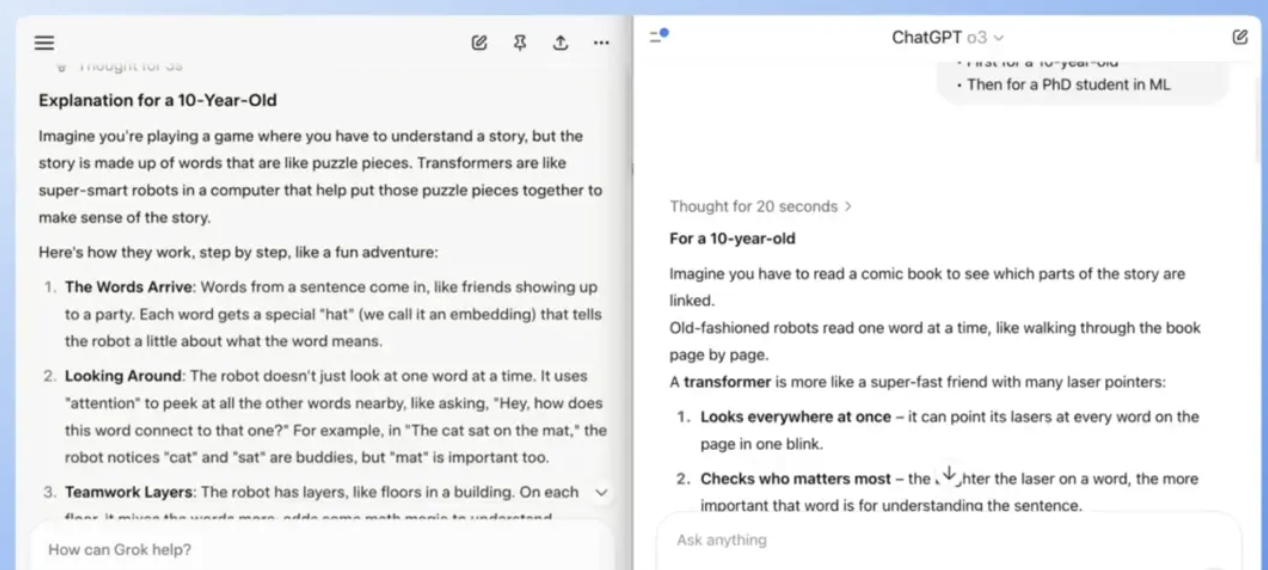
Grok4 针对两种受众提供了恰当的层次化解释;o3 在简化科普上出现用词不当或过于笼统的问题。
四、其他网友测试
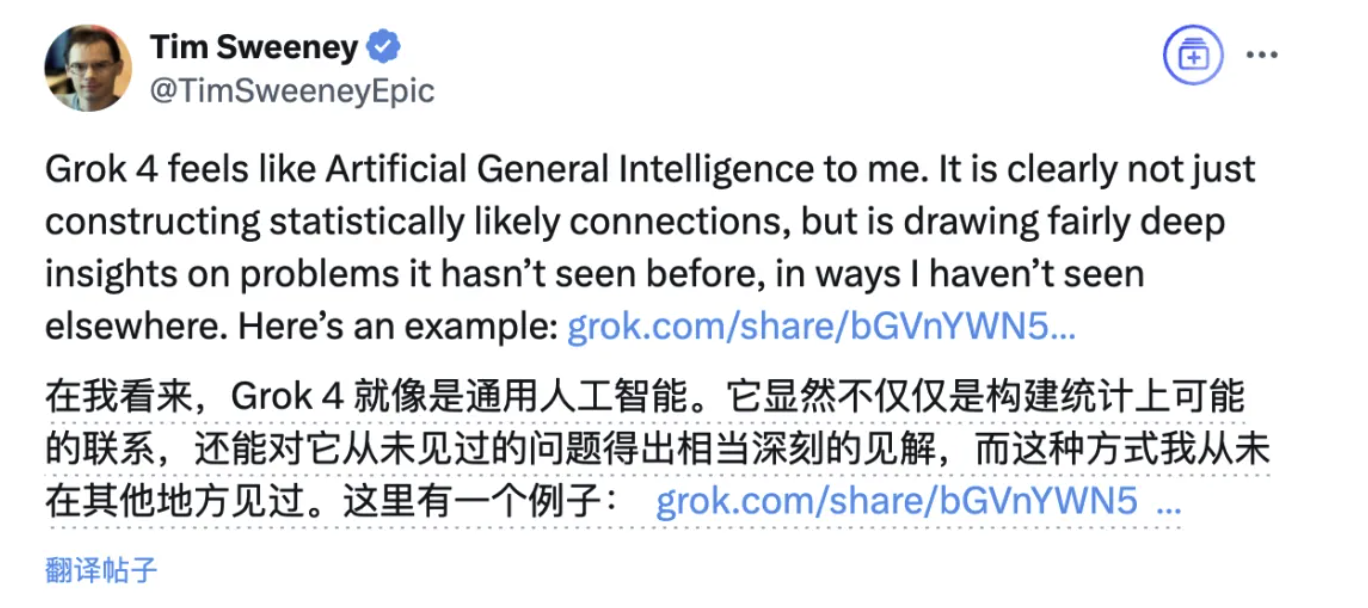
Epic 创始人下场称:Grok4 就是 AGI
Epic 创始人 Tim Sweeney 亲自上场,把一篇他自认为模型从未见过的论文“喂”给 Grok4,要它对文中新问题给出见解。结果模型不仅条理清晰,还提出了深刻洞见,让 Tim 直呼:“这就是 AGI!”马斯克也在社交平台转发并赞同这一评价。
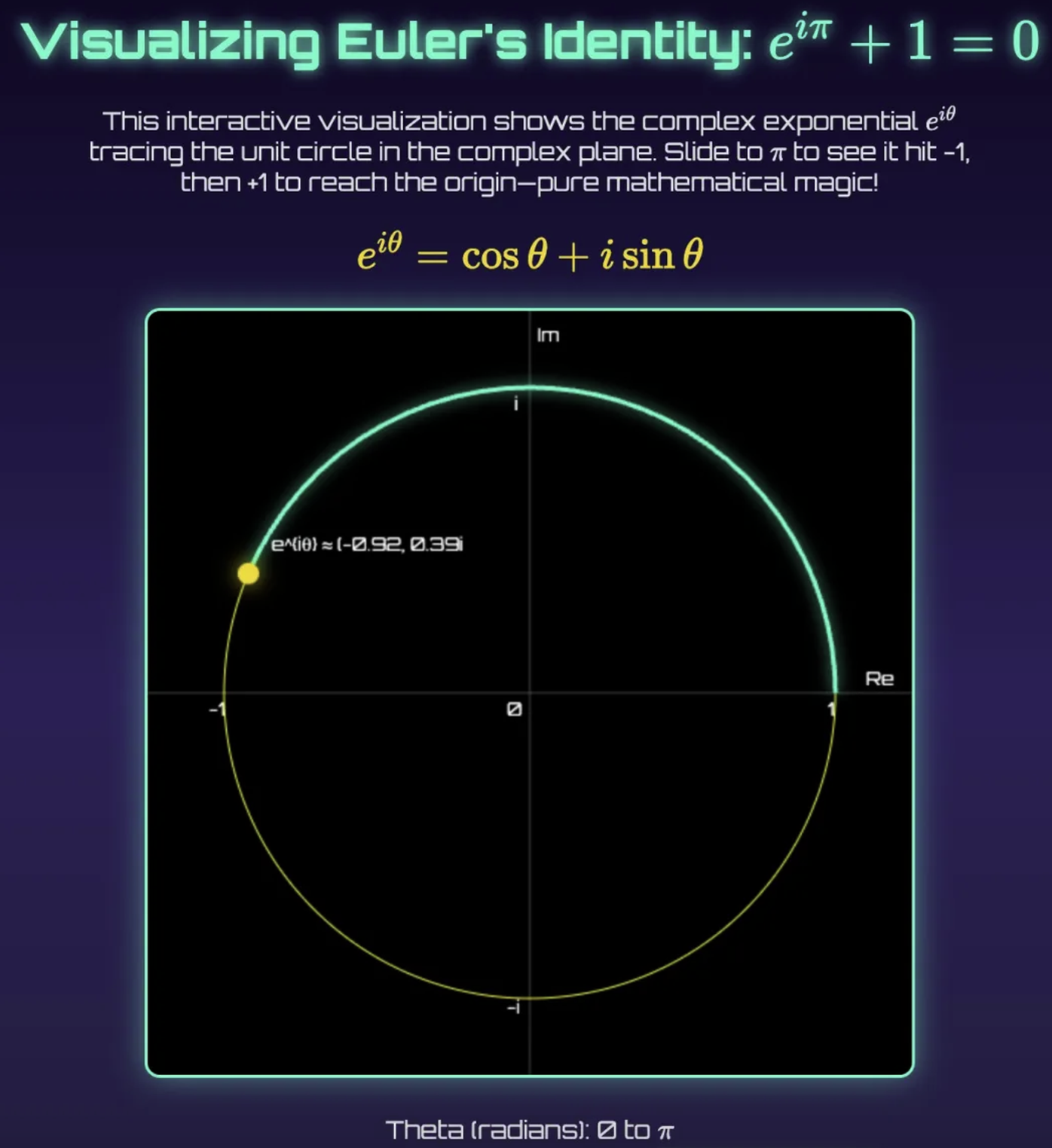
欧拉恒等式的可视化展示
一位网络开发者 Dan 问 Grok4 最喜欢哪个数学公式,模型答出“e^iπ + 1 = 0”。接着它在四轮对话中,用代码和网页展示了公式的可视化效果,让 Dan——一位学了五个学期高数却一直没弄懂欧拉恒等式的资深数学 党——终于通过可视化的方式理解了这个数学公式。
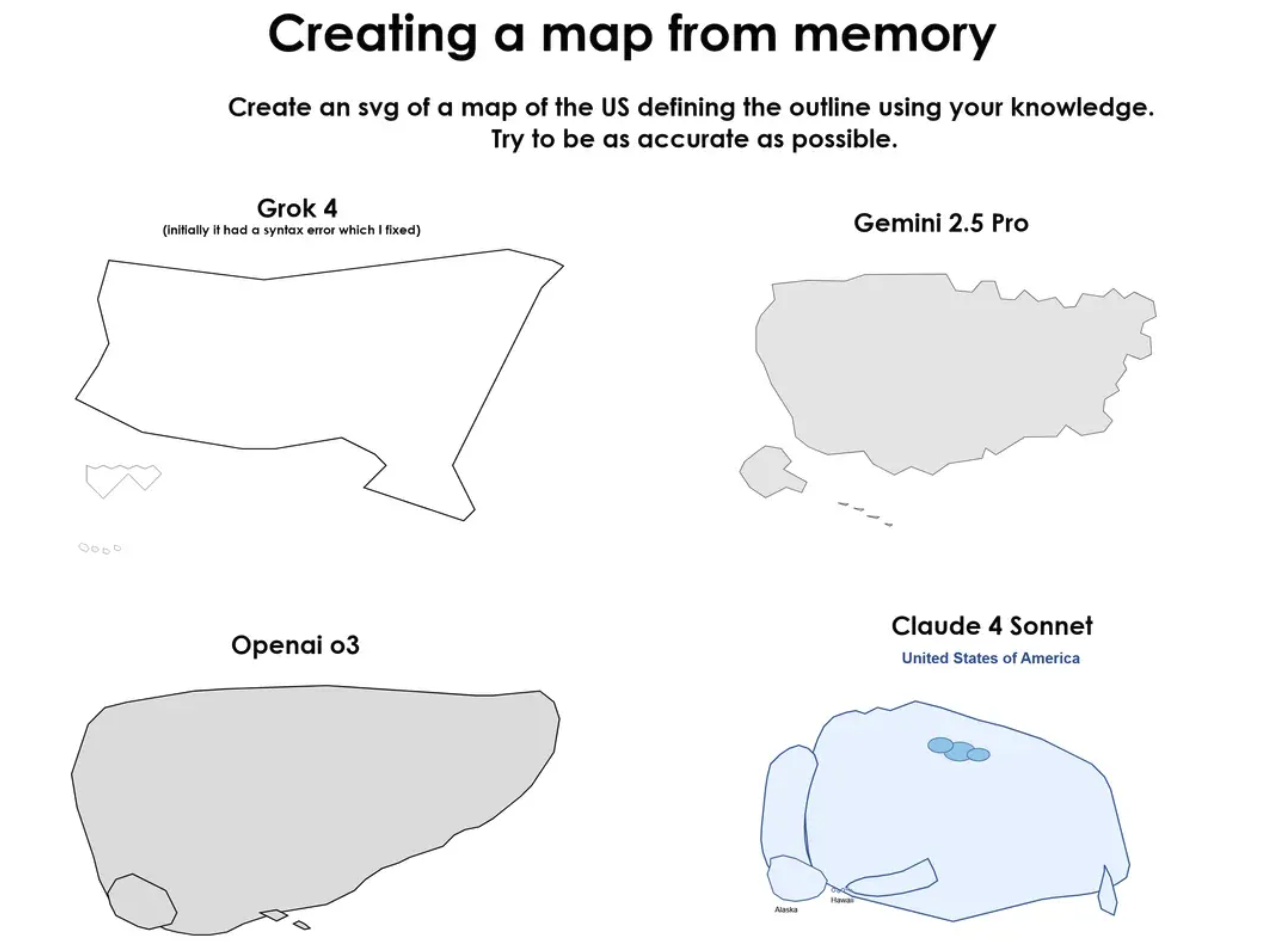
SVG 绘图大比拼:测试视觉与空间推理
在 Reddit 上很多网友对 Grok4 和其他模型进行对比,让他们做 SVG 绘图测试:
比如让测试每个模型对美国地图进行重绘,Gemini 2.5 Pro中最接近真实地图,但少数州界线略有偏
Grok4 Heavy的整体轮廓准确,没有出现州块重叠,但细节上稍显简化;o3 & Claude 4则多次出现相邻州块在代码中重叠或位置错位的问题。
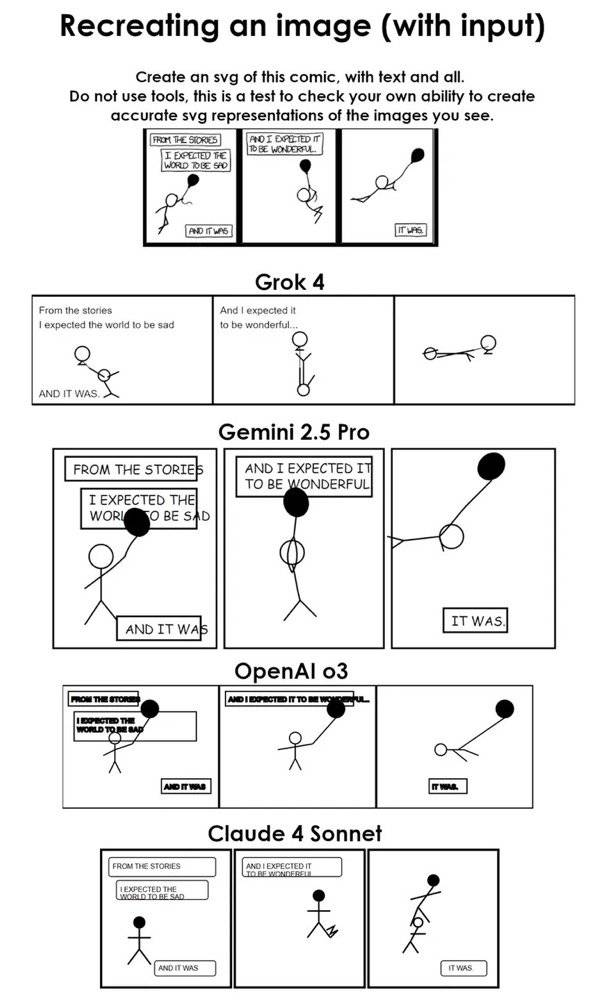
在漫画场景再现过程中,要求模型将一幅简单的漫画场景(人物、对话气泡、背景元素)用 SVG 代码还原出来。
- Grok4 Heavy:能正确还原大部分人物轮廓和对话框位置,但背景细节略有缺失;
- o3:线条扭曲严重,对话框往往缺失或文本位置错误;
- Gemini & Claude 4:在色块与线条连接处出现断裂或偏移,各有不同程度的失误。
进行专辑封面原创设计中,让模型自主设计一款专辑封面,用 SVG 代码表达构图、色块和文字排版。
- Grok4 Heavy:设计风格简洁,结构合理,所有元素在渲染时都能正确显示;
- Gemini 2.5 Pro & Claude 4:创意较抽象,但部分元素坐标或大小偏离预期;
- o3:封面布局松散,元素重叠,整体视觉效果一般。

五、写在最后
Grok 4 的发布,标志着多代理架构与多模态工具链结合的人工智能系统,正在向通用人工智能(AGI)稳步迈进。在数学推理、法律逻辑、多语种编程、跨领域知识整合、空间想象与绘图表达等任务中,Grok 4 Heavy 展现出了高度一致性与可解释性,逐步突破以往大模型“会说不会做”“回答浮于表面”的桎梏。
但是目前来看,Grok 4 系列模型还是存在不足的地方。主要是调用成本过高,限制了中小开发者和个人用户的广泛接入。
如果 Grok 系列能够在架构上持续优化计算效率,在推理成本上能够再降低一下,在生态策略上向开发者社区开放更多接口与能力模块,可能Grok 4 能够被更多人去使用
而这,也许正是马斯克所憧憬的——“一个能与人类并肩工作的智能伙伴”,而非仅仅是一个对话机器人。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号