Go 语言中的指针
原创

1、指针的定义和使用
指针是 C-like 语言中的一个核心概念,对于理解内存管理和函数参数传递至关重要。Go 语言保留了指针,但对其进行了优化和限制,使其在保证灵活性的同时,也提高了安全性。本文将深入探讨 Go 语言中指针的本质、用法及其特性。
1、指针的本质:为何需要指针?
在编程中,我们经常会遇到一个需求:在函数内部修改传入的参数,并希望这些修改能够反映到原始变量上。
让我们从一个常见的场景开始。假设有一个 Person 结构体:
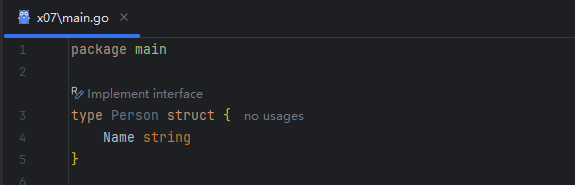
image.png
我们希望创建一个函数 changeName,用于修改 Person 实例的 Name 字段。如果采用常规的值传递方式:
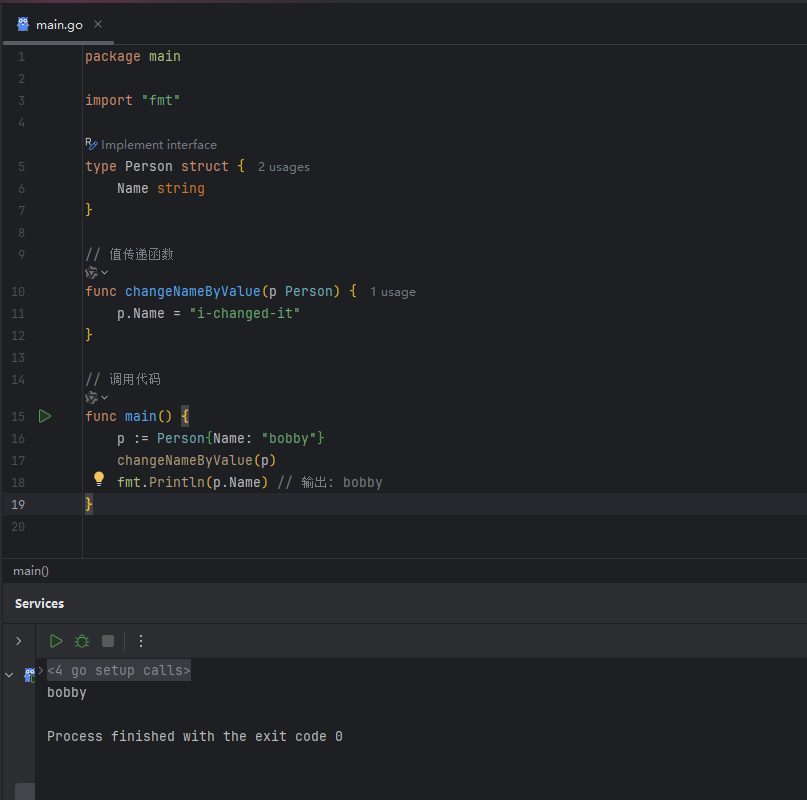
image.png
运行以上代码会发现,p.Name 的值并未改变。这是因为 Go 语言中函数参数默认是值传递(Pass by Value)。当 p 被传入 changeNameByValue 函数时,函数内部实际操作的是 p 的一个副本,对副本的任何修改都不会影响到函数外部的原始变量 p。
为了解决这个问题,我们需要使用指针。
2、指针的应用:实现引用传递
通过传递变量的内存地址(即指针),函数就可以直接操作原始变量,而不是其副本。
下面是使用指针修改 changeName 函数的示例:
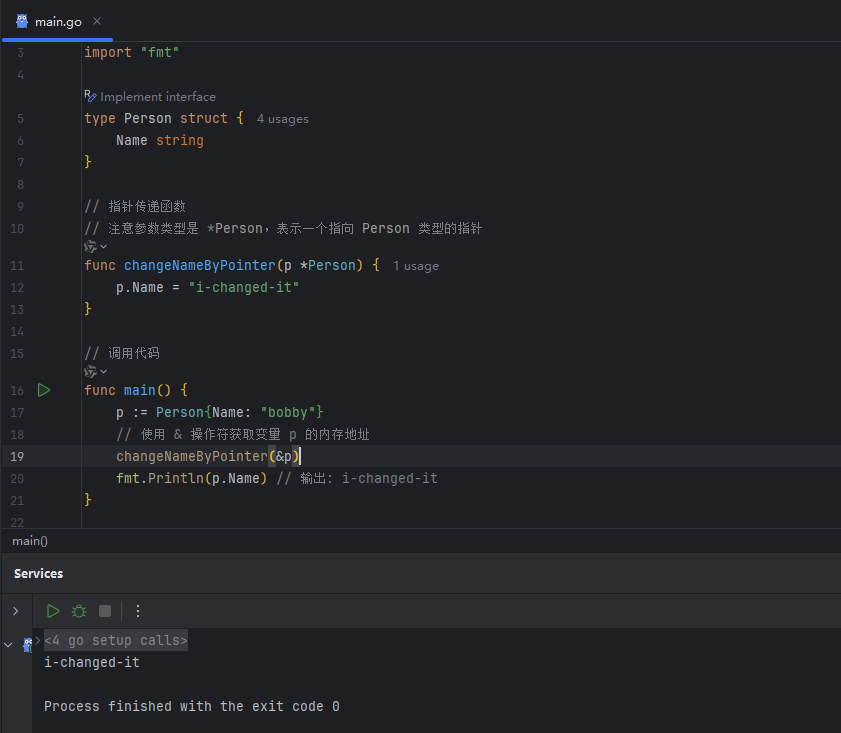
image.png
这次,p.Name 的值被成功修改了。我们来解析一下这个过程:
&p:&是取址运算符,&p表示获取变量p在内存中的地址。*Person:*在类型声明中表示这是一个指针类型。*Person指的是一个指向Person结构体的指针。- 函数
changeNameByPointer接收一个指针作为参数。在函数内部,p存储的是原始Person对象的内存地址。因此,通过这个地址修改p.Name,实际上是直接在原始对象上进行操作。
3、深入理解指针的工作原理
为了更清晰地理解指针,我们可以构建一个内存模型:
3.1 普通变量 (Normal Variable)
当您声明 var a int = 5 时,内存状态如下:
- 计算机在内存中找到一个地址(例如
0x1000)。 - 分配一个足以存放
int的空间。 - 将数值
5存入该空间。 - 变量名
a成为地址0x1000的别名。
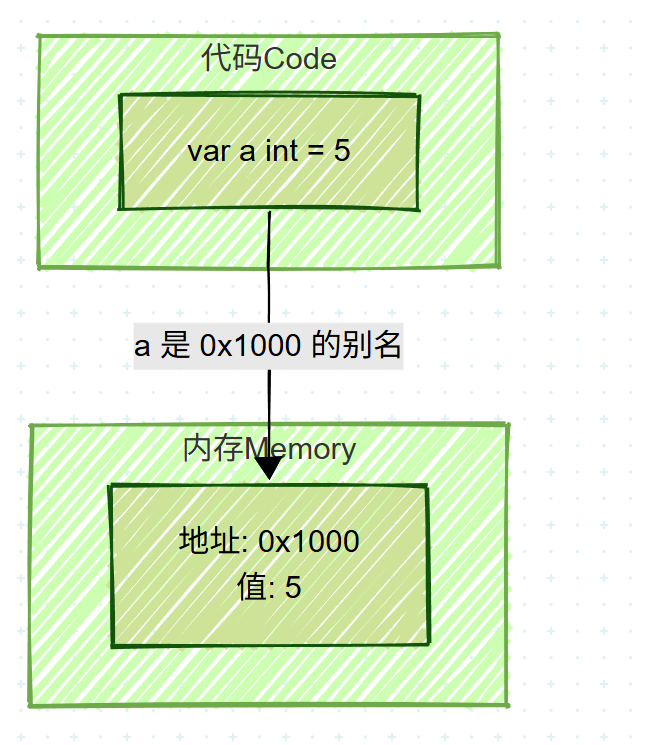
image.png
3.2 指针变量 (Pointer Variable)
接着,您声明一个指针变量 var ptr *int:
- 计算机会为指针变量
ptr本身分配内存空间(例如,在地址0x2000)。 - 这个空间用于存放另一个变量的内存地址。
- 此时,
ptr尚未指向任何地方,其值为nil(空)。
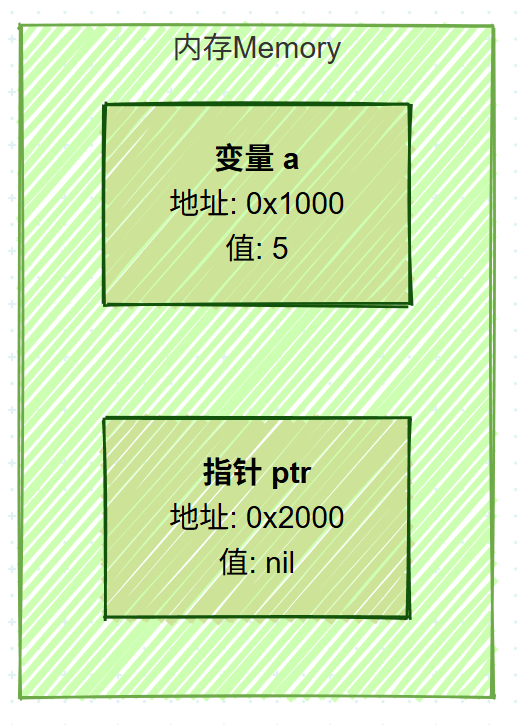
image.png
3.3 赋值操作 (Assignment: ptr = &a)
执行 ptr = &a 后,a 的内存地址被赋给了 ptr:
- 指针变量
ptr的内容(值)被更新为变量a的地址0x1000。 - 现在,
ptr“指向”了a。
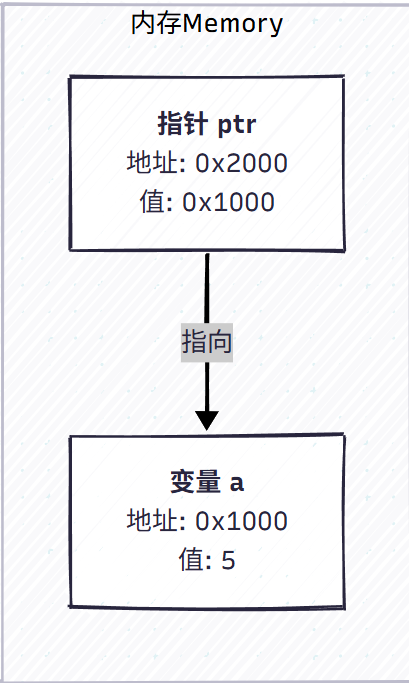
image.png
3.4 解引用 (Dereferencing: *ptr)
当您通过 *ptr 访问数据时,会发生两步操作:
- 读取
ptr的值:程序首先访问地址0x2000,读取到里面存储的内容是0x1000。 - 访问目标地址:程序接着跳转到地址
0x1000,读取或修改那里的数据(即变量a的数据)。
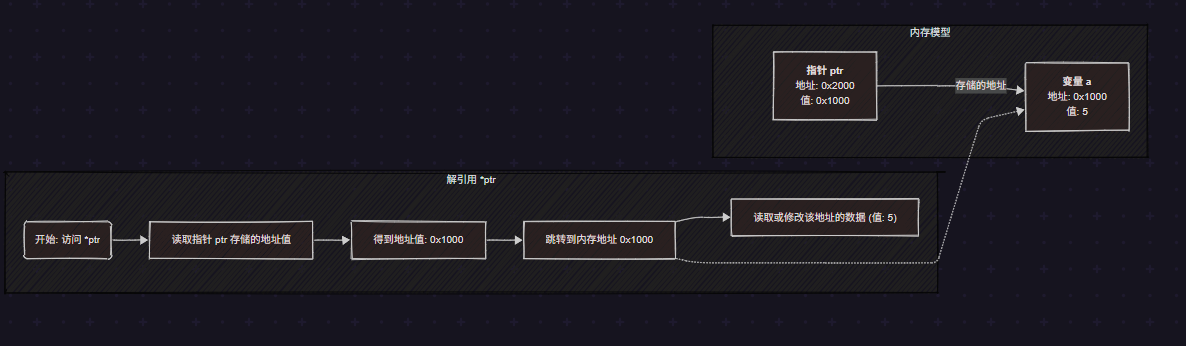
image.png
3.5 指针复制 (Pointer Copying)
如果您将指针 ptr 复制给另一个指针 ptr_copy,例如在函数传参时:
- 会创建一个新的指针变量
ptr_copy,它也有自己的内存地址(例如0x3000)。 ptr中存储的地址值 (0x1000) 被复制到ptr_copy中。- 因此,
ptr_copy和ptr都存储着a的地址,它们都指向同一个原始数据。
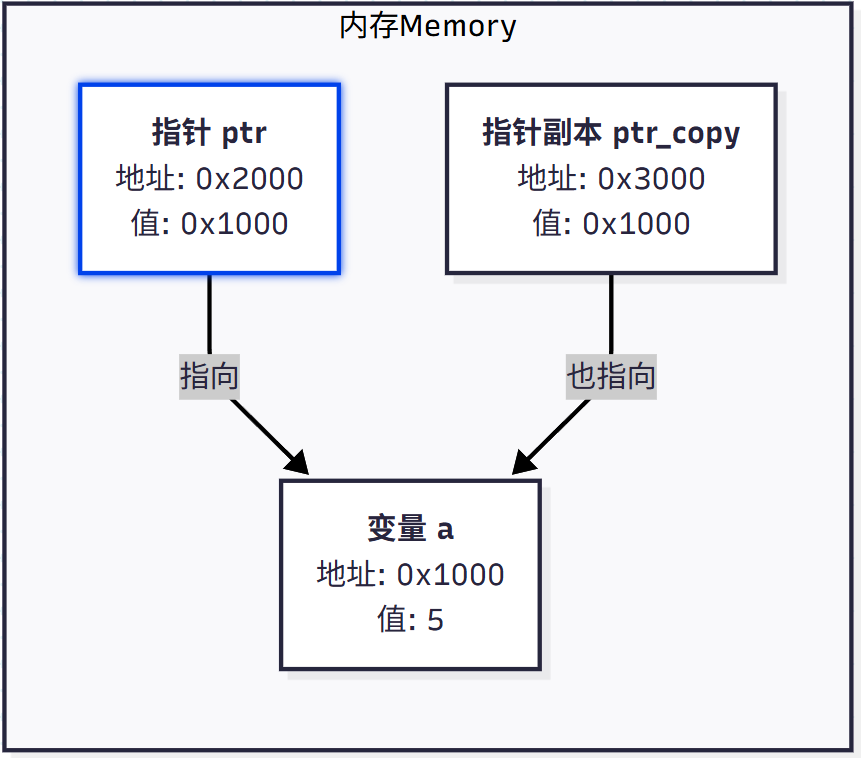
image.png
正是因为这种机制,即使将指针变量复制一份(例如在函数传参时),副本和原指针变量都存储着相同的目标地址,因此它们都能修改同一个原始数据。
4、Go 中指针的定义与使用
4.1 指针的定义与初始化
定义一个指针变量的语法是在类型前加上 *。
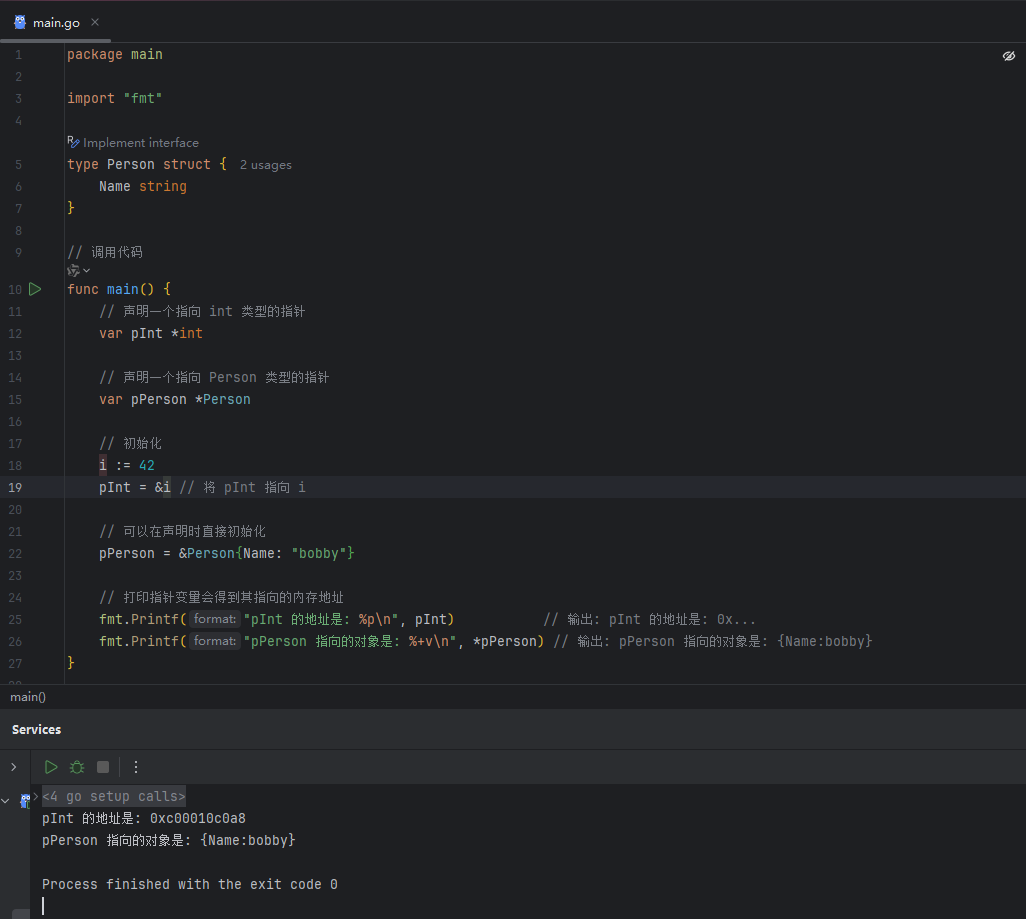
image.png
4.2 通过指针访问成员
Go 语言为指针的成员访问提供了语法糖,使其变得非常便捷。按照传统方式,访问指针指向的结构体成员需要先解引用,再访问:
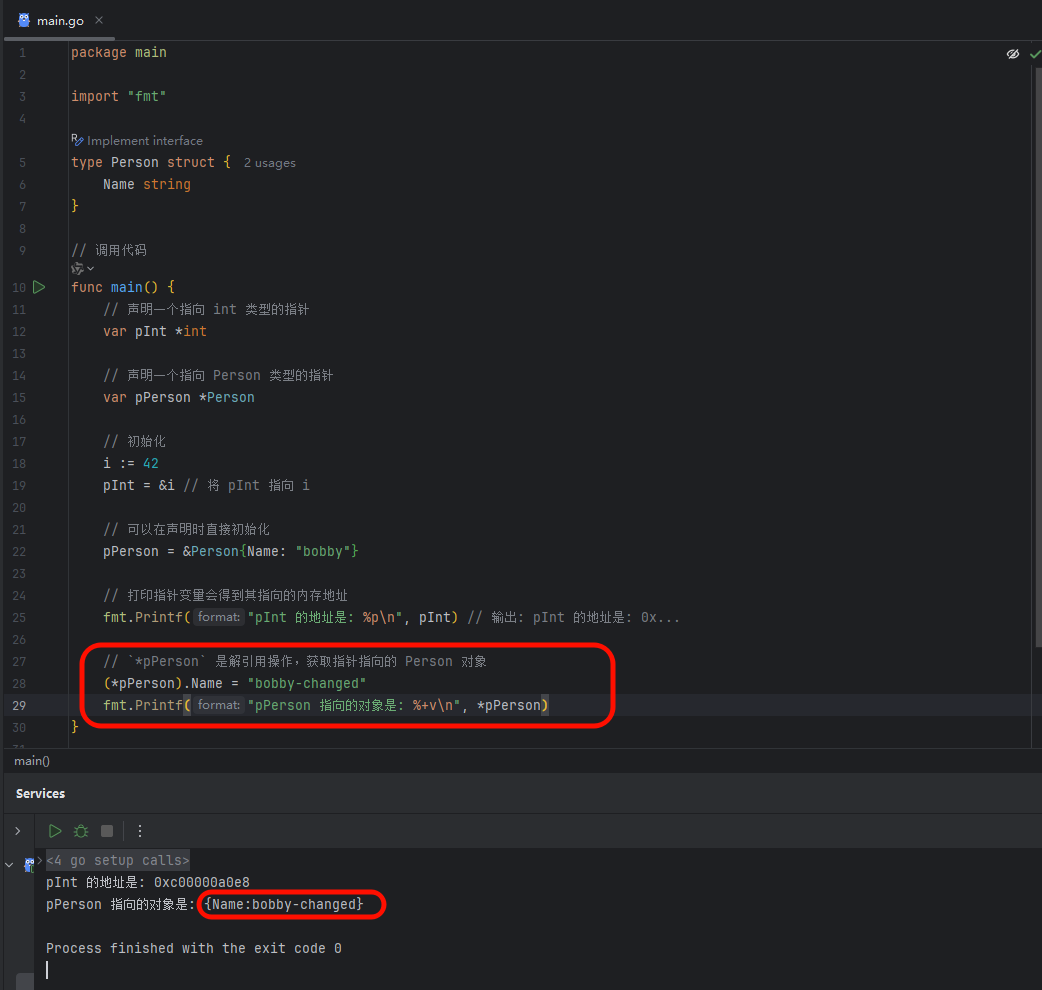
image.png
然而,Go 语言允许我们省略繁琐的 (*),直接使用点号 . 来访问,编译器会自动处理:
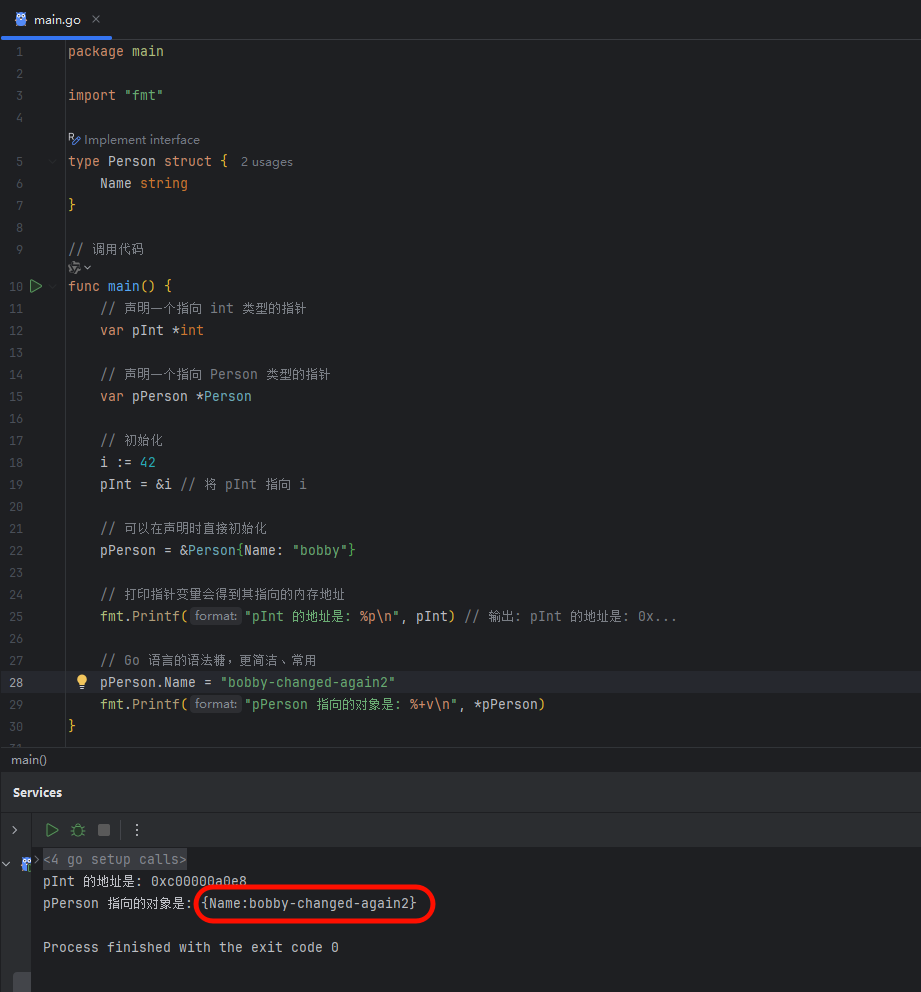
image.png
这种设计极大地简化了代码,让操作指针类型和操作普通结构体类型看起来几乎一样。
5、Go 指针的特性与限制
Go 语言的指针与 C/C++ 的指针相比,有两个显著的不同点,这些设计旨在提升代码的安全性和简洁性。
1. 不支持指针运算
在 C/C++ 中,可以对指针进行算术运算,例如 p++ 会让指针指向相邻的下一个内存单元。这种灵活性是一把双刃剑,它使得底层内存操作成为可能,但同时也极易引发野指针、内存越界等严重 Bug。
Go 语言从设计上禁止了指针运算。你不能对一个指针进行加减操作来改变它指向的地址。这从根本上杜绝了上述风险,使 Go 的指针更加安全。
2. unsafe 包:一个特殊通道
尽管 Go 在常规层面限制了指针运算,但它也提供了一个名为 unsafe 的特殊包。顾名思义,unsafe 包中的操作是不受类型系统安全检查的,它允许你进行类似 C 语言的指针类型转换和指针运算。
unsafe 包的存在是为了满足一些非常底层或对性能有极致要求的特殊场景。它的命名本身就是一种警告:使用它意味着你正在绕过 Go 的安全机制,必须清楚地知道自己在做什么,并自行承担风险。对于绝大多数日常开发而言,我们应该避免使用 unsafe 包。
2、指针的初始化
1、指针的声明与 nil 值
一个指针变量在被声明后,如果没有进行任何初始化,它的默认值是 nil。nil 是 Go 语言中指针、接口、map、slice、channel 和函数类型的零值。
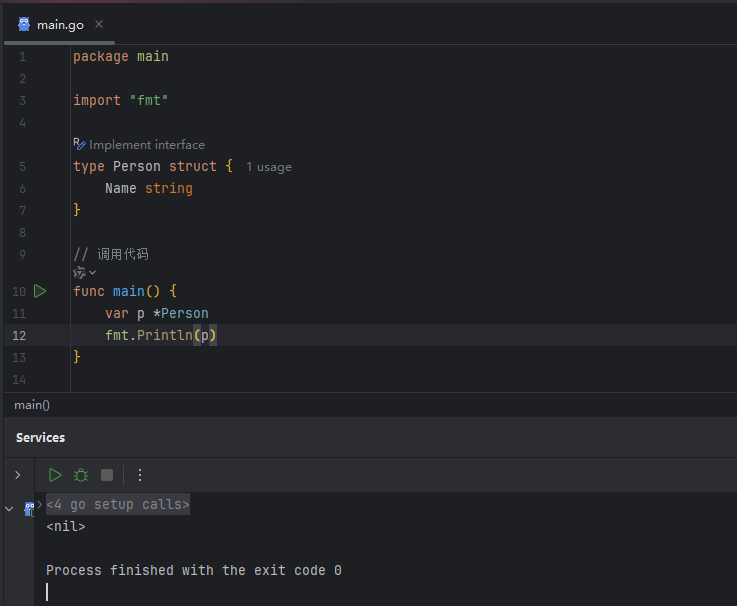
image.png
对一个 nil 指针进行解引用操作(即尝试访问它所指向的内存地址中的数据)是无效且危险的,这会导致程序运行时产生一个panic。
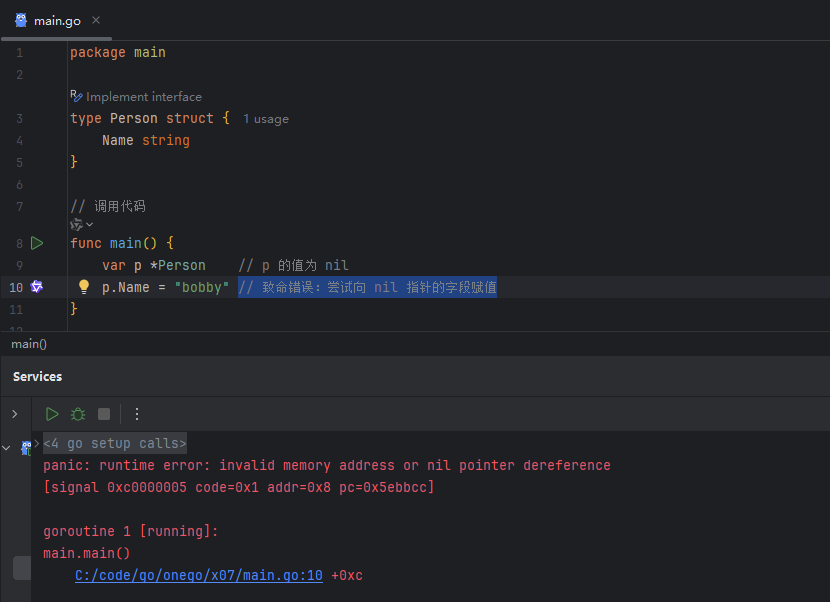
image.png
这个错误是 Go 开发中非常常见的一类问题,类似于 Java 中的 NullPointerException 或 Python 中的 AttributeError: 'NoneType' object has no attribute ...。因此,在使用指针之前,必须确保它已经被正确初始化,即指向一个合法的内存地址。
2、 指针的初始化方法
为了避免 nil 指针错误,我们需要在声明后或使用前对指针进行初始化。主要有以下三种方式:
方式一:使用 & 取址运算符作用于一个已存在的变量
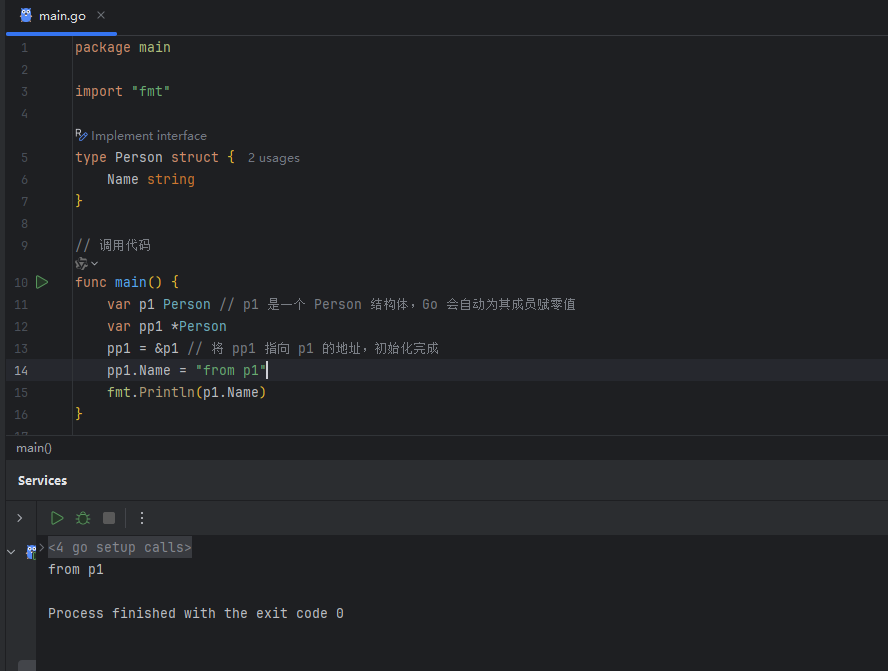
image.png
方式二:在声明时直接使用 & 对结构体字面量取址
这是最常用、最简洁的方式。
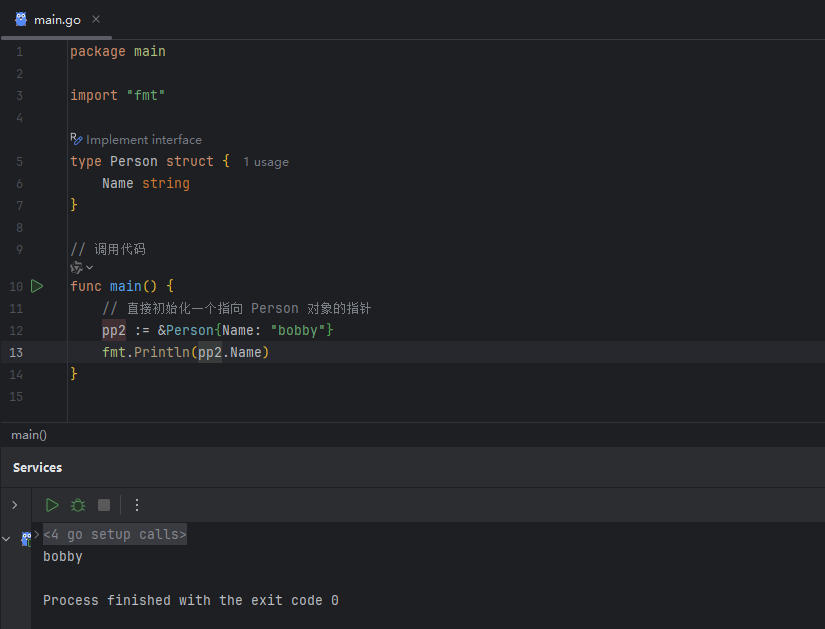
image.png
方式三:使用 new 内建函数
new(T) 函数会为一个 T 类型的新项分配一块内存空间,将此空间初始化为 T 类型的零值,并返回指向这块内存的地址,即 *T 类型的指针。
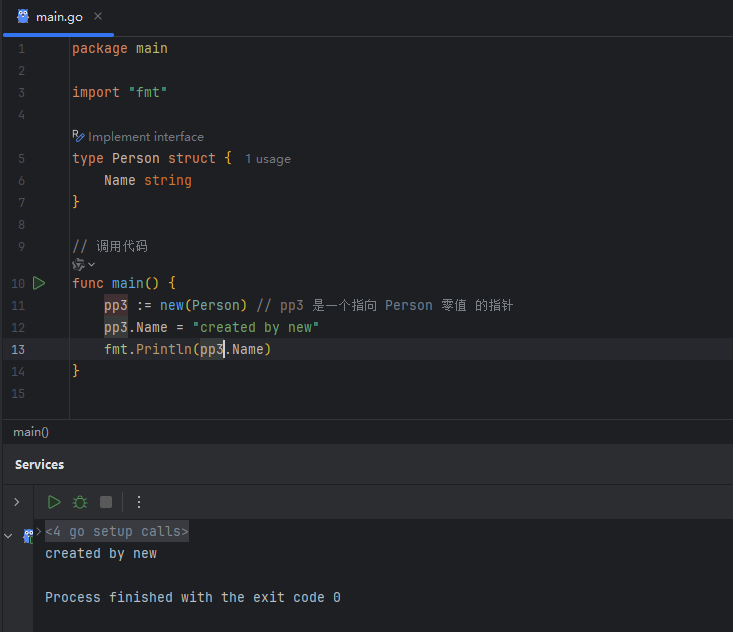
image.png
使用 new(Person) 的效果等同于 var p Person; pp3 := &p。
3、new 与 make 的区别
初学者容易混淆 new 和 make。它们的核心区别在于:
new(T): 主要用于分配内存。它为任何给定的类型T分配空间,并返回一个指向该内存的指针*T。返回的指针指向的是一个对应类型的零值。make(T, ...): 仅用于初始化 slice、map 和 channel 这三种引用类型。它返回的是一个已初始化好的、可以直接使用的类型实例T,而不是指针*T。make不仅分配了内存,还完成了这几种复杂数据结构的内部初始化工作。
简而言之:为指针分配内存请用 new,初始化 slice、map、channel 请用 make。
3、指针在方法和函数中的应用
1、 方法接收者:值类型 vs. 指针类型
在 Go 中,我们可以为任何自定义类型(包括结构体)定义方法。定义方法时,需要指定一个“接收者”(Receiver),它类似于面向对象语言中的 this 或 self。接收者可以是值类型,也可以是指针类型。
- 值接收者 (**
func (p Person) Method()**):方法操作的是接收者的一个副本,就像值传递的函数参数一样。在方法内部对接收者成员的修改不会影响原始值。 - 指针接收者 (**
func (p *Person) Method()**):方法操作的是指向原始值的指针。在方法内部的修改会影响原始值。
命名约定:按照 Go 社区的惯例,接收者的变量名通常是其类型名首字母的小写形式,例如 p 代表 Person,b 代表 Buffer。
// 指针接收者:可以修改原始 Person 对象
func (p *Person) SetName(newName string) {
p.Name = newName
}
// 值接收者:无法修改原始 Person 对象
func (p Person) SetNameByValue(newName string) {
p.Name = newName
}选择指针接收者的两个主要原因:
- 需要修改接收者的状态。
- 避免复制大对象。如果结构体非常大,使用指针接收者可以提高性能,因为它只复制一个指针(通常是 8 字节),而不是整个结构体。
2、 案例分析:通过指针交换两个变量的值
这是一个经典的面试题,也是理解指针传递本质的绝佳案例。我们的目标是编写一个函数 swap,用于交换两个 int 变量的值。
错误的尝试:交换指针本身
一个常见的直觉是直接交换传入的两个指针:
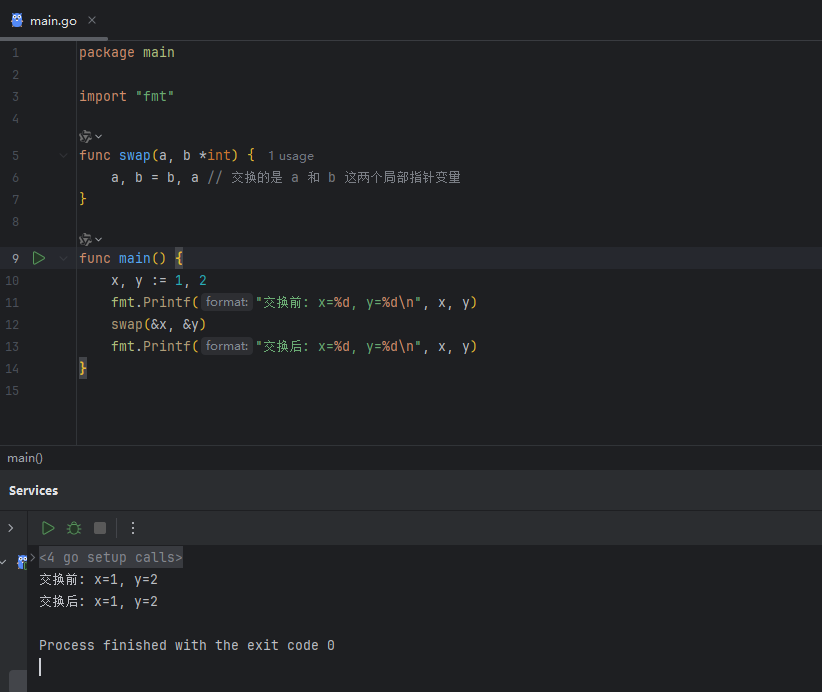
image.png
结果令人意外:x 和 y 的值并未改变!
深入分析:为何交换失败?
要理解失败的原因,我们必须再次回到“值传递”的核心。在 Go 中,一切皆为值传递。当你把指针 &x 和 &y 传入 swap 函数时,函数内部的参数 a 和 b 实际上是 &x 和 &y 的副本。
a 和 b 拥有与 &x 和 &y 相同的地址值,它们都指向 main 函数中的 x 和 y。但是,a 和 b 本身是 swap 函数栈上的局部变量,它们有自己独立的内存空间。
a, b = b, a 这行代码仅仅是交换了 swap 函数内部 a 和 b 这两个副本所持有的地址,而 main 函数中的原始变量 x 和 y 以及指向它们的指针从未受到影响。
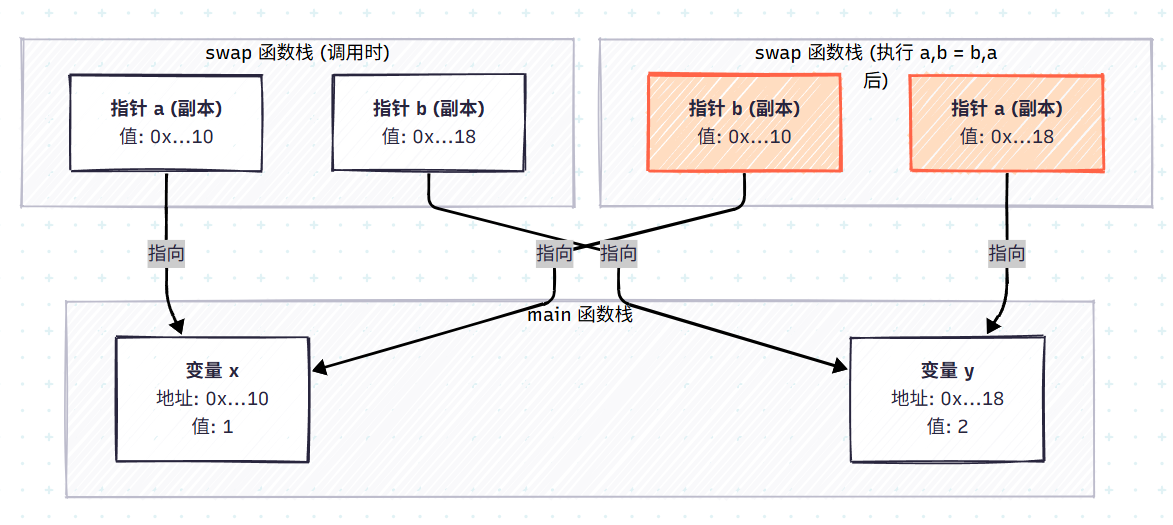
image.png
上图清晰地展示了,交换只发生在 swap 函数的局部变量上。函数返回后,这些局部变量被销毁,main 函数中的一切保持原样。
正确的解法:交换指针指向的值
要真正实现交换,我们不能改变指针本身,而应该通过指针去改变它们所指向的内存地址中的值。
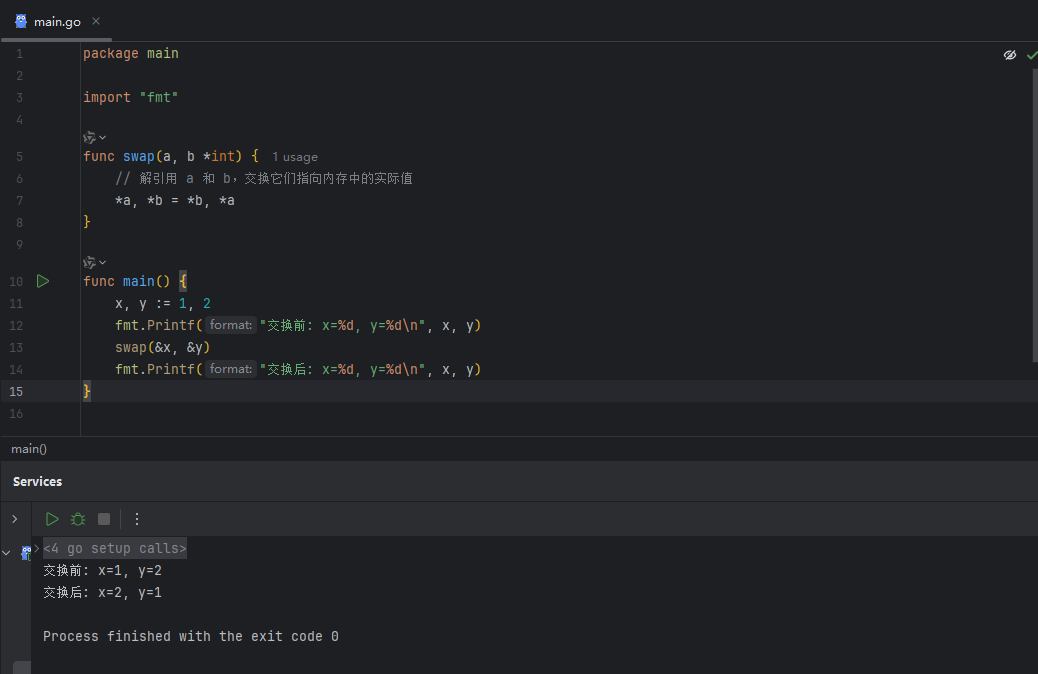
image.png
使用 * 操作符(解引用)可以直接访问到 a 和 b 所指向的 main 函数中的 x 和 y 的内存空间,从而成功地交换了它们的值。
4、深度解析 Go 语言中的 nil
nil 是 Go 语言中一个至关重要但又常常引起混淆的关键字。它并不仅仅是其他语言中 null 或 None 的简单对等物。对 nil 的理解不够深入,很容易在开发中写出潜在的 bug,或者在排查问题时感到困惑。本文将深入探讨 nil 的本质、适用类型以及在实践中需要注意的细节。
1、nil:特定类型的零值
在 Go 语言中,“零值”(Zero Value)是一个核心概念,即变量在声明但未显式初始化时所拥有的默认值。nil 正是某些特定引用类型的零值。
不同类型的零值各不相同:
- 布尔类型 (**
bool**):false - 数值类型 (**
int**,float64**, 等)**:0 - 字符串类型 (**
string**):""(空字符串)
以下类型的零值是 nil:
- 指针 (**
pointer**) - 切片 (**
slice**) - 映射 (**
map**) - 通道 (**
channel**) - 函数 (**
func**) - 接口 (**
interface**)
需要特别注意的是,结构体 (**struct**) 的零值不是 nil。它的零值是其所有字段都取各自零值的状态。
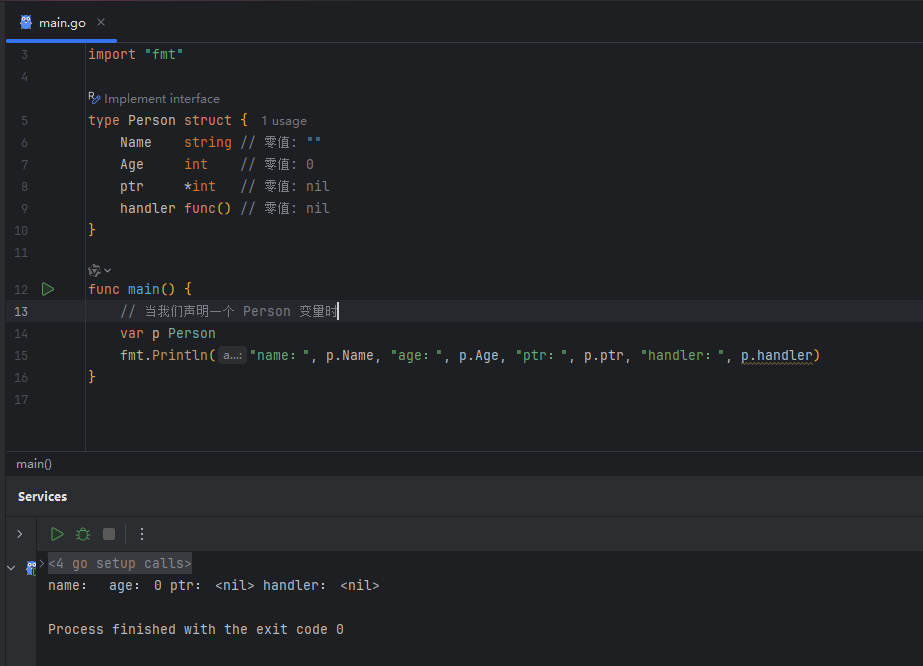
image.png
Go 语言允许直接对结构体实例进行判等操作,但有一个前提:该结构体的所有字段都必须是可比较的类型。像 slice, map, func 这样的类型是不可比较的。如果一个结构体包含了这些类型的字段,那么它本身也是不可比较的。
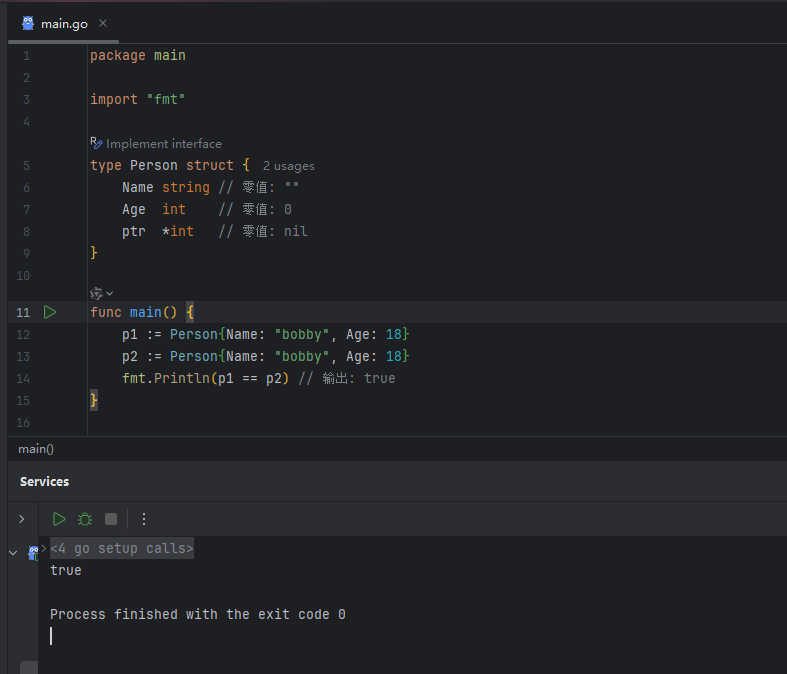
image.png
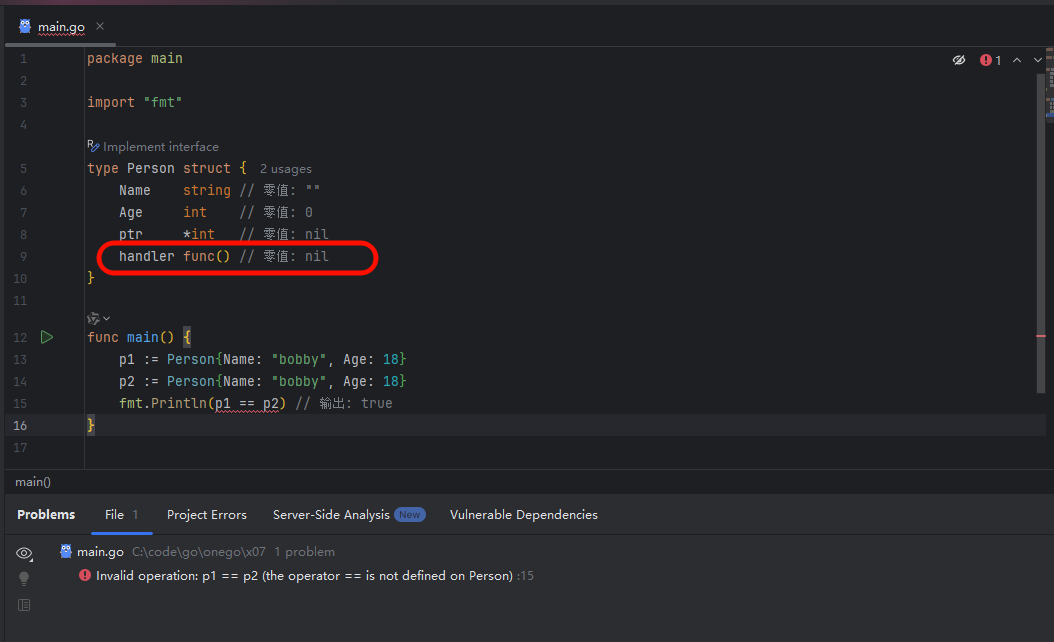
image.png
2、nil 的判断
我们可以使用 == 或 != 直接与 nil 进行比较。最常见的应用场景就是判断 error:
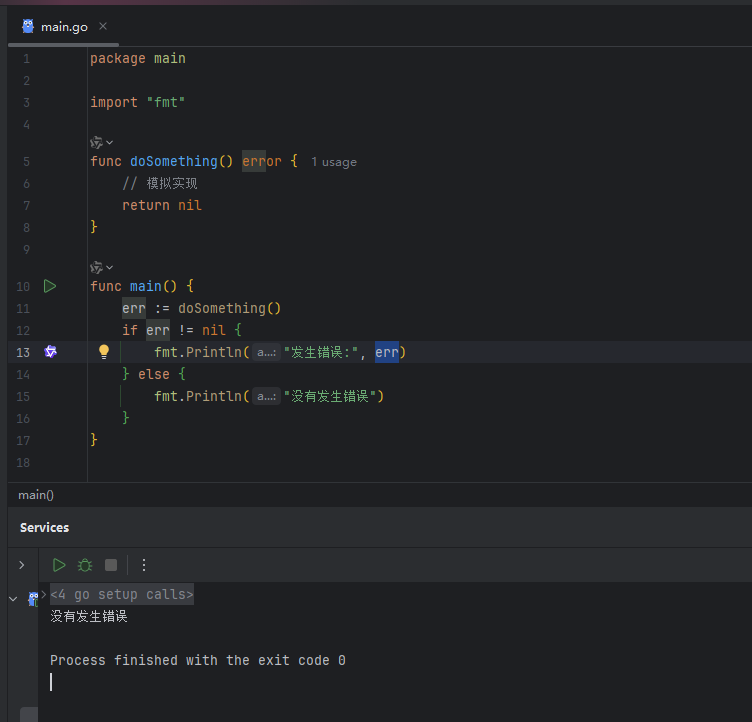
image.png
error 本质上是一个接口类型,其零值正是 nil,所以这种判断方式既直接又高效。 然而,并非所有类型都可以和 nil 比较。例如,一个 int 类型的变量就不能与 nil 比较,这会在编译时报错。通常,只有那些零值为 nil 的类型才能进行此类比较。
3、nil 切片 vs. 空切片
这是 nil 最容易引起混淆的地方之一。让我们来看两种切片的声明方式:
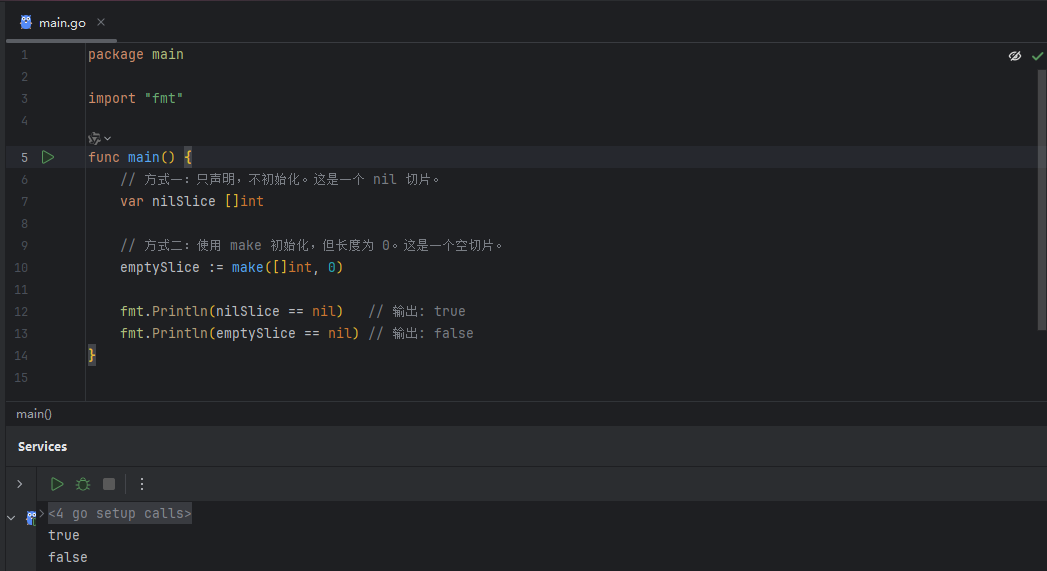
image.png
为什么 make 创建的零长度切片不等于 nil?
答案在于切片的底层数据结构。一个切片实际上是一个包含三个字段的头部结构(Slice Header):
Ptr: 指向底层数组的指针。Len: 切片的长度。Cap: 切片的容量。- 对于
var nilSlice []int,它的头部结构是{Ptr: nil, Len: 0, Cap: 0}。由于其内部指针是nil,所以这个切片本身就是nil。 - 对于
emptySlice := make([]int, 0),Go 会为其分配一个头部结构,并使其内部指针指向一个全局唯一的、长度为零的底层数组地址(zerobase)。此时其头部结构是{Ptr: &zerobase, Len: 0, Cap: 0}。因为内部指针不是nil,所以这个切片不是nil。
尽管两者在大多数操作上表现一致(例如,len() 和 cap() 都返回0,for-range 循环都可以安全执行),但在需要严格区分“未初始化”和“为空”的场景下,这个差别至关重要。
4、nil 映射 vs. 空映射
与切片类似,映射 (map) 也存在 nil 和空的区别。
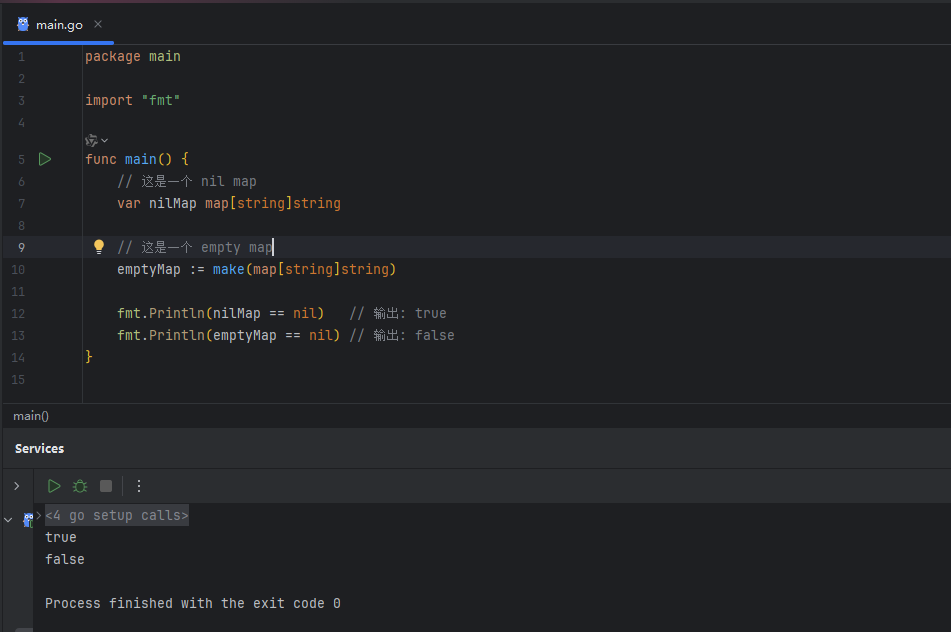
image.png
nil map 和 empty map 的行为有相似之处,但存在一个致命的区别: 读取和遍历:对 nil map 进行读取或 for-range 遍历是安全的,不会引发 panic。读取一个不存在的键会返回该值类型的零值。
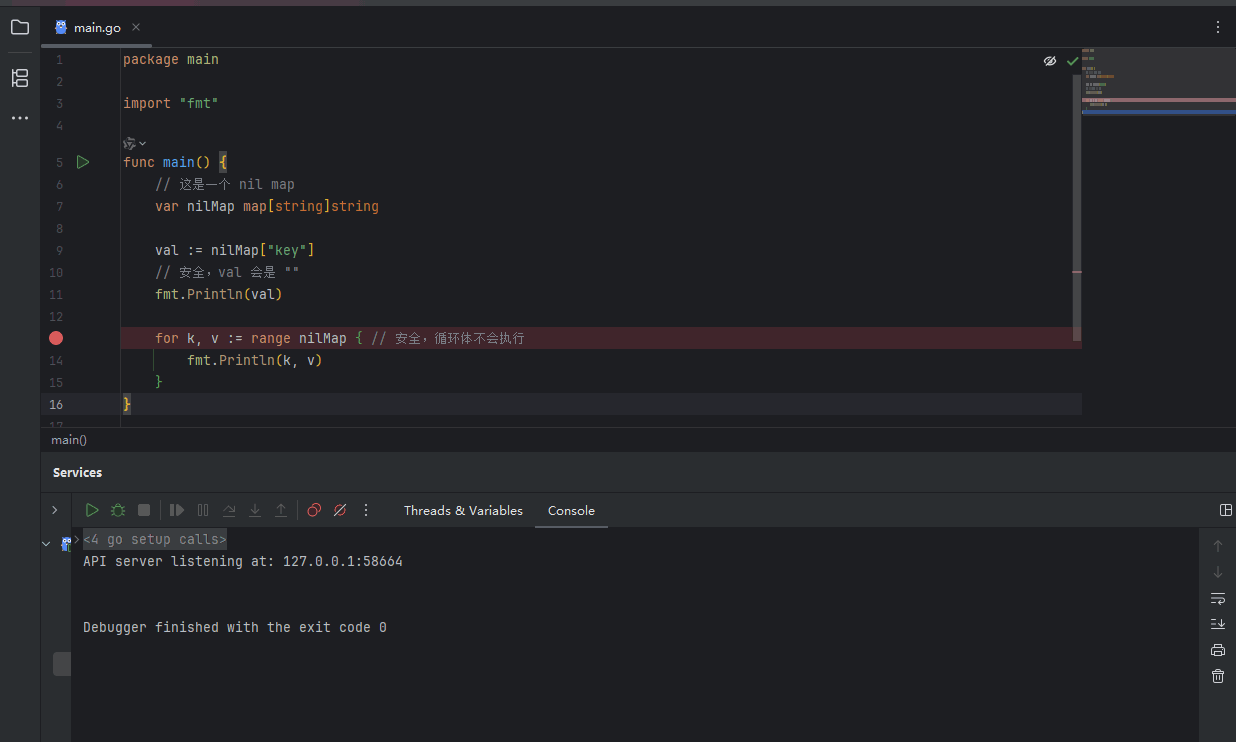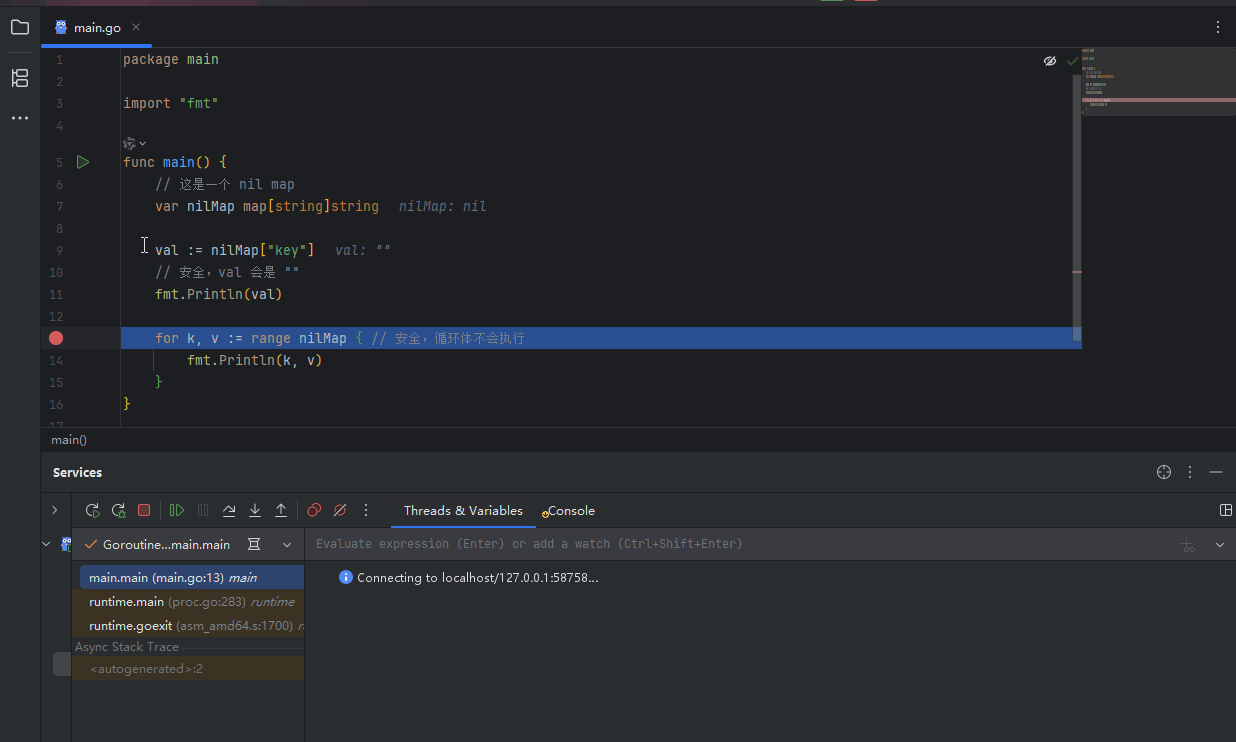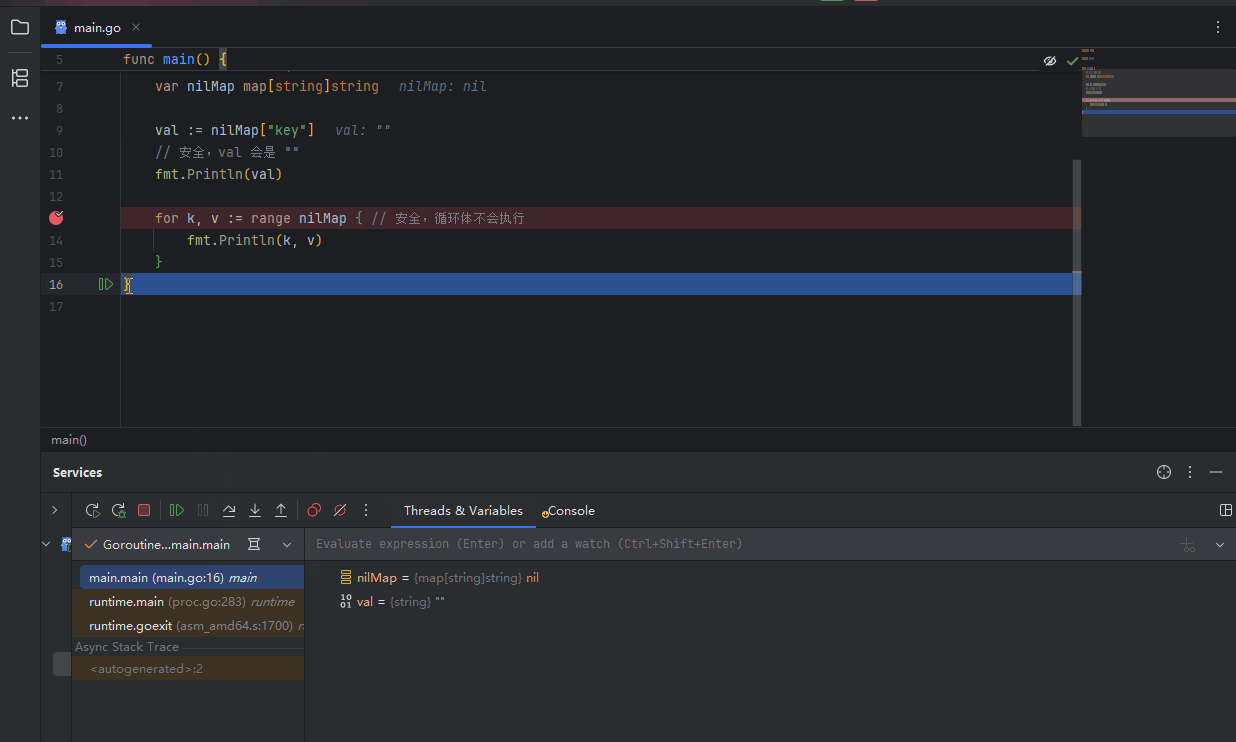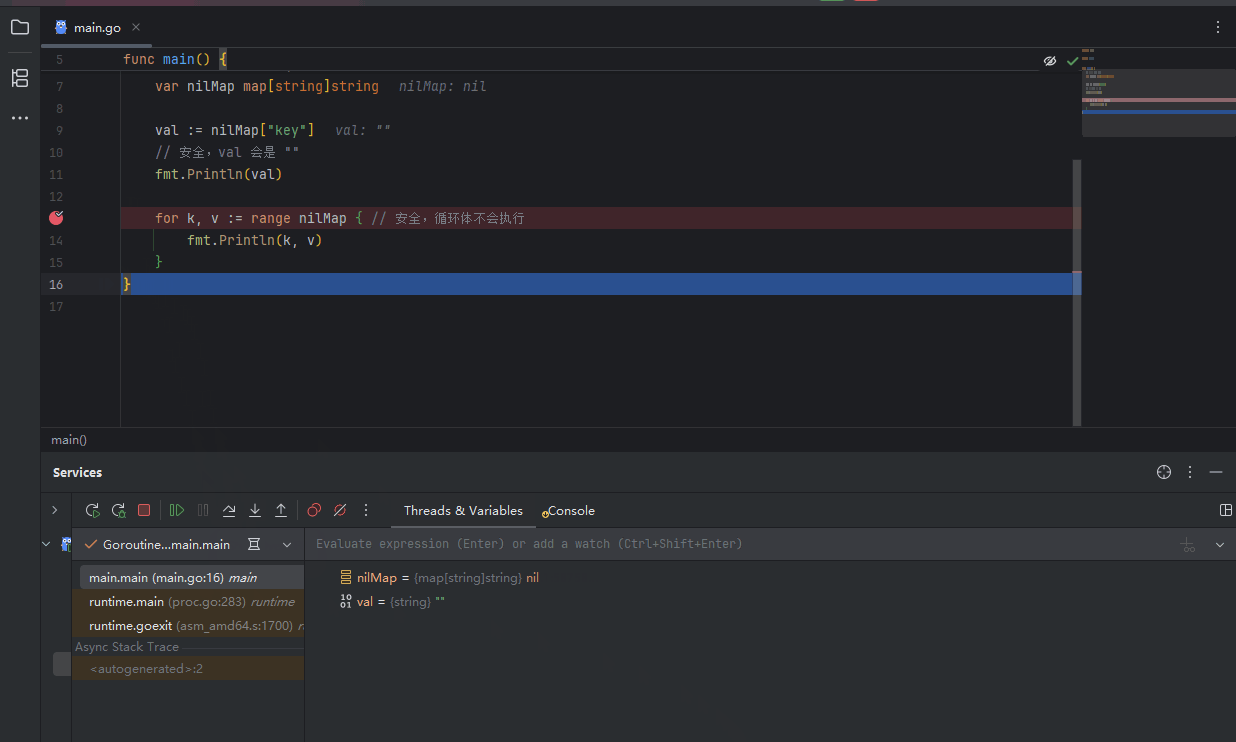
PixPin_2025-06-22_10-01-40.gif
*
写入:对 nil map 进行写入操作会引发 panic!
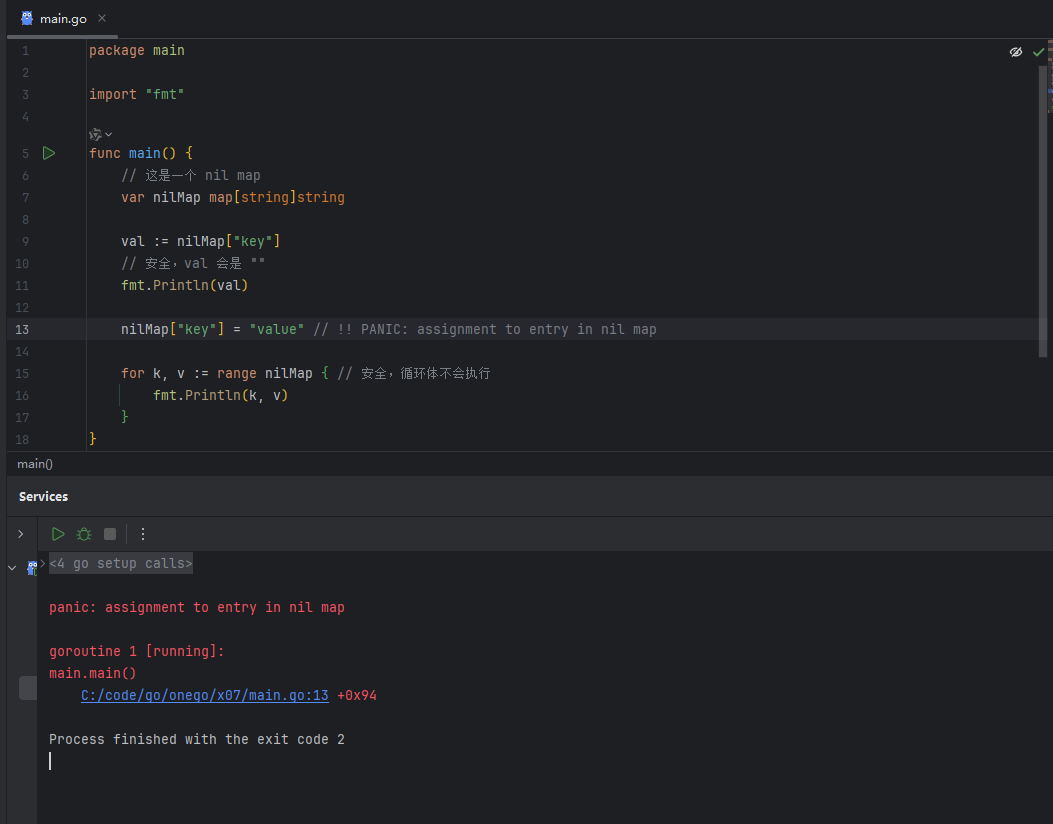
image.png
而对于使用 make 初始化的空 map,所有读写操作都是安全的。
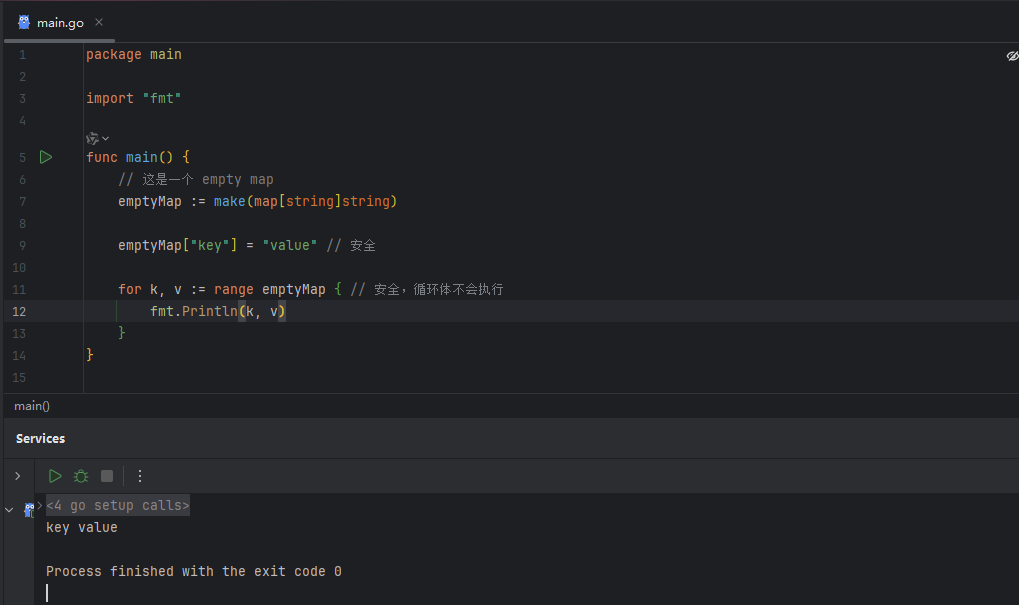
image.png
5、结论与最佳实践
nil是 Go 中多种引用类型的零值,但并非所有类型(如struct)的零值都是nil。nil切片/映射 与 空切片/映射在底层实现和某些行为上是不同的。- 对
nilmap 进行写入是导致运行时 panic 的常见原因。 - 安全原则:除非你有意要区分“未初始化”和“空”这两种状态,否则在声明 map 后,应立即使用
make进行初始化,以避免对nilmap 进行写入操作。
深刻理解 nil 的工作机制,有助于我们编写出更健壮、更可靠的 Go 代码。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号