浅析藏文OCR技术的核心难点及其应用领域
原创
浅析藏文OCR技术的核心难点及其应用领域
原创
中科逸视OCR专家
修改于 2025-06-24 08:54:44
修改于 2025-06-24 08:54:44
藏文作为我国重要的少数民族语言文字之一,广泛分布于西藏、青海、四川、甘肃、云南等地的文化、宗教、教育及行政领域。然而,由于藏文结构的特殊性(如上下叠加的字母组合、复杂的连写规则),传统OCR技术在藏文识别上存在较大挑战。
藏文OCR的核心难点在于以下几点
藏文字符的复杂结构:
上下叠加的拼写规则
藏文属于拼音文字,一个完整的音节(字)通常由 基字(根字)、上加字、下加字、前加字、后加字 和 元音符号 组合而成,形成 垂直叠加结构。例如:"གྲུབ"(意为“成就”)由 基字“ག” + 下加字“ྲ” + 后加字“ུ” + 元音符号“བ” 组成。
所以难点在于,传统藏文OCR通常按水平方向分割字符,但藏文需要 垂直分割+上下文关联分析,否则容易误识别为独立字符。不同组合可能导致视觉相似但语义不同的字(如 "ག" vs. "གྲ"),增加误识别率。
连写变体
藏文在书写时,部分字符组合会形成 连写变体(类似阿拉伯文的连字),如:
"ཀྲ"(基字“ཀ”+下加字“ྲ”)→ 写作“ཀྲ”
"སྒ"(前加字“ས”+基字“ག”)→ 写作“སྒ”
难点在于连写后的字形与独立字符差异较大,传统藏文OCR可能无法正确拆分。
多字体适配问题
藏文主流字体包括:
印刷体:乌金体(Uchen,标准体)、簇仁体(Chuyig,手写风格)。
手写体:个人书写习惯差异大,连笔、变形较多。
古籍字体:木刻本、贝叶经等存在特殊字形和磨损。
所以造成的难点是不同字体的同一字符可能形态迥异(如 "ཀ" 在乌金体和手写体中的写法不同)。
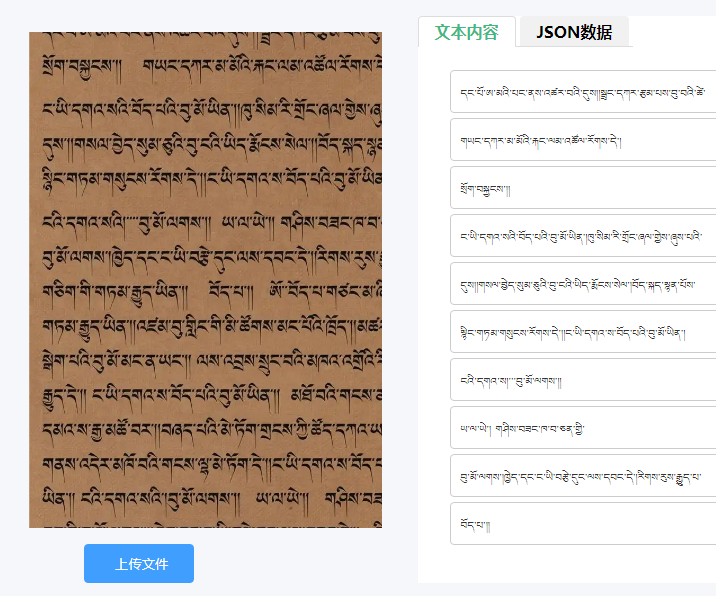
藏文OCR识别效果
藏文OCR技术特点:采用深度学校算法,基于CNN(卷积神经网络)、RNN/LSTM(循环神经网络)、Transformer模型。
1. 高精度识别:支持印刷体+手写体,识别率高达98%以上,支持混合文本(藏文+汉字+英文)识别。
2. 多场景适配:支持扫描件、PDF、图片(JPG/PNG)等多种输入格式。
3.多格式输出: 支持识别后输出为TXT、JSON、XML、Word等格式
4.跨平台支持:提供Windows、Linux及国产化平台应用,支持API接口集成。支持离线模式,保障数据安全。
藏文OCR应用场景
文化保护:藏文古籍、佛经、历史档案的数字化存档。
教育领域:教材电子化、试卷自动批改、藏文学习APP开发。
政务办公:公文扫描、档案管理、多语言信息处理。
出版与传媒:藏文书籍、报刊的快速录入与电子出版。
移动应用:旅游翻译、藏文拍照识别、社交媒体内容处理。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号